") 使用神經(jīng)處理單元集群轉(zhuǎn)換邊緣AI
使用神經(jīng)處理單元集群轉(zhuǎn)換邊緣AI

隨著人工智能領(lǐng)域獲得牽引力,這些設(shè)備變得越來越計算和耗電。隨后,邊緣設(shè)備上的處理負載隨著系統(tǒng)架構(gòu)的性能和復(fù)雜性而顯著增加。因此,在系統(tǒng)中灌輸了更高分辨率的圖像和更復(fù)雜的算法,隨著對AI處理的需求不斷增長,以實現(xiàn)高TOPS性能,這需要進一步優(yōu)化。
Synopsys 發(fā)布了神經(jīng)處理單元 (NPU)、知識產(chǎn)權(quán) (IP) 內(nèi)核和工具鏈,以滿足 AI 片上系統(tǒng) (SoC) 中日益復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型的性能需求。其新的設(shè)計軟件 ARC NPX6 和 NPX6FS NPU IP 可處理實時計算的需求,同時為 AI 應(yīng)用消耗超低功耗。此外,該公司的新 MetaWare MX 開發(fā)工具提供了一個完整的編譯環(huán)境,具有自動化神經(jīng)網(wǎng)絡(luò)算法分區(qū),可最大限度地提高最新 NPU 上應(yīng)用軟件開發(fā)的資源效率。
使用新的設(shè)計軟件 ARC NPX6 和 NPX6FS NPU IP 以及元軟件 MX 開發(fā)工具包,設(shè)計人員可以利用最新的神經(jīng)網(wǎng)絡(luò)模型,滿足不斷升級的性能期望,并加快其下一代智能 SoC 的上市時間。ARC NPX6 NPU IP 系列包括許多處理深度學(xué)習(xí)算法覆蓋的產(chǎn)品,包括對象識別、圖像質(zhì)量增強和場景分割等計算機視覺任務(wù),以及音頻和自然語言處理等大型 AI 應(yīng)用。設(shè)計中的單個內(nèi)核可以從 4K MAC 擴展到 96K MAC,以實現(xiàn)超過 250 TOPS 和超過 440 TOPS 的單個 AI 引擎性能,并且很少。
NPX6 NPU IP 包含對多達 8 個 NPU 的多 NPU 群集的硬件和軟件支持,稀疏性為 3500 TOPS。由于硬件和軟件中的高級帶寬功能以及內(nèi)存層次結(jié)構(gòu)(每個內(nèi)核中包含L1內(nèi)存以及用于訪問常見L2內(nèi)存的高性能,低延遲連接),可以擴展到大量MAC數(shù)量。對于受益于神經(jīng)網(wǎng)絡(luò)內(nèi)部 BF16 或 FP16 的應(yīng)用,提供了可選的張量浮點單元。
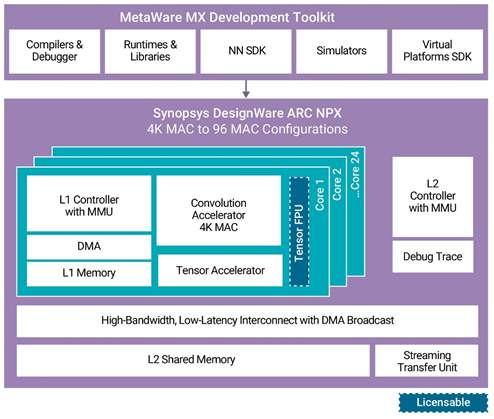
MetaWare MX 開發(fā)工具包為應(yīng)用軟件開發(fā)提供了軟件編程環(huán)境,包括神經(jīng)網(wǎng)絡(luò)軟件開發(fā)工具包 (NN SDK) 和虛擬模型支持。NN SDK 會自動將使用流行框架(如巨炬、張量流或 ONNX)訓(xùn)練的神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)換為 NPX 優(yōu)化的可執(zhí)行代碼。
這個概念是,NPX6 NPU處理器IP隨后可用于制造各種產(chǎn)品,從幾個TOPS到數(shù)千個TOPS,所有這些都可以使用單個工具鏈編寫。
NPX6 網(wǎng)絡(luò)輸出電源的主要特性:
可擴展的實時 AI/神經(jīng)處理器 IP,具有多達 3,500 個 TOPS 的性能,支持 CNN、RNN/LSTM、變壓器、推薦器網(wǎng)絡(luò)和其他神經(jīng)網(wǎng)絡(luò)。
功率效率(高達 30 TOPS/W)在業(yè)界無與倫比。
卷積加速器的 1-24 個內(nèi)核,增加了 4K MAC/內(nèi)核
張量加速器,支持張量運算符集體系結(jié)構(gòu)并允許變量激活 (TOSA)
軟件開發(fā)套件
用于自動混合模式量化的工具
降低帶寬的架構(gòu)和軟件工具特性
通過并行處理各個層來減少延遲。
設(shè)計軟件 ARC VPX 矢量 DSP 無縫集成。
生產(chǎn)力很高。張量流和巨炬框架,以及ONNX交換標準,由元軟件MX開發(fā)工具包支持。
此外,ARC NPX6FS NPU IP 符合 ISO 26262 ASIL D 標準,用于隨機硬件故障檢測和系統(tǒng)功能安全開發(fā)流程。這些處理器具有符合 ISO 26262 的特定安全機制,可處理下一代區(qū)域性設(shè)計的混合關(guān)鍵性和虛擬化需求,以及全面的安全文檔。
ARC 元軟件 MX 開發(fā)工具包包括神經(jīng)網(wǎng)絡(luò)軟件開發(fā)工具包 (SDK)、編譯器和調(diào)試器、虛擬平臺 SDK、運行時和庫以及高級仿真模型。它提供了一個統(tǒng)一的工具鏈環(huán)境來加速應(yīng)用程序開發(fā),并在MAC資源之間智能地劃分算法以實現(xiàn)最佳處理。MetaWare MX 安全開發(fā)工具包包含安全手冊和安全指南,可幫助開發(fā)人員滿足 ISO 26262 標準,并為安全關(guān)鍵型汽車應(yīng)用的 ISO 26262 合規(guī)性測試做準備。
利用 NPU 集群加速邊緣 AI 應(yīng)用
為了滿足人工智能應(yīng)用不斷增長的性能和復(fù)雜需求,恩智浦NPU IP核提供高性能、可擴展的實時人工智能和神經(jīng)處理IP,具有多達3500個TOPS,支持各種神經(jīng)網(wǎng)絡(luò),如CNN、RNN/LSTM、變壓器和推薦器網(wǎng)絡(luò)。
此外,它通過并行處理各個層來減少延遲。此外,高生產(chǎn)力的元軟件 MX 開發(fā)工具包支持張量流和巨魔框架以及 ONNX 交換格式。
審核編輯:郭婷
-
處理器
+關(guān)注
關(guān)注
68文章
19896瀏覽量
235318 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103663 -
人工智能
+關(guān)注
關(guān)注
1807文章
49029瀏覽量
249614
發(fā)布評論請先 登錄
Nordic收購 Neuton.AI 關(guān)于產(chǎn)品技術(shù)的分析
大聯(lián)大世平推出基于恩智浦產(chǎn)品的邊緣AI加速方案

FPGA在邊緣AI中的應(yīng)用
Deepseek海思SD3403邊緣計算AI產(chǎn)品系統(tǒng)
Synaptics發(fā)布高性能AI MCU,推動邊緣計算新突破

FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
恩智浦擬收購邊緣AI企業(yè)Kinara
AI賦能邊緣網(wǎng)關(guān):開啟智能時代的新藍海
恩智浦3.07億美元收購Kinara,強化邊緣AI布局
AI模型部署邊緣設(shè)備的奇妙之旅:如何實現(xiàn)手寫數(shù)字識別
HZHY-AI100G:適配鴻蒙系統(tǒng)的AI邊緣計算智能盒

使用 ADI 的 MAX78002 MCU 開發(fā)邊緣 AI 應(yīng)用

NVIDIA IGX平臺加速實時邊緣AI應(yīng)用
使用邏輯和轉(zhuǎn)換優(yōu)化數(shù)字駕駛艙處理單元






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論