") 一種基于prompt和對(duì)比學(xué)習(xí)的句子表征學(xué)習(xí)模型
一種基于prompt和對(duì)比學(xué)習(xí)的句子表征學(xué)習(xí)模型
雖然BERT等語(yǔ)言模型有很大的成果,但在對(duì)句子表征方面(sentence embeddings)上表現(xiàn)依然不佳,因?yàn)锽ERT存在 sentence bias 、 anisotropy 問(wèn)題;
我們發(fā)現(xiàn)prompt,再給定不同的template時(shí)可以生成不同方面的positive pair,且避免embedding bias。
相關(guān)工作
Contrastive Learning(對(duì)比學(xué)習(xí)) 可以利用BERT更好地學(xué)習(xí)句子表征。其重點(diǎn)在于如何尋找正負(fù)樣本。例如,使用inner dropout方法構(gòu)建正樣本。
現(xiàn)有的研究表明,BERT的句向量存在一個(gè) 坍縮現(xiàn)象 ,也就是句向量受到高頻詞的影響,進(jìn)而坍縮在一個(gè)凸錐,也就是各向異性,這個(gè)性質(zhì)導(dǎo)致度量句子相似性的時(shí)候存在一定的問(wèn)題,這也就是 anisotropy 問(wèn)題。
發(fā)現(xiàn)
(1)Original BERT layers fail to improve the performance.
對(duì)比兩種不同的sentence embedding方法:
對(duì)BERT的輸入input embedding進(jìn)行平均;
對(duì)BERT的輸出(last layer)進(jìn)行平均
評(píng)價(jià)兩種sentence embedding的效果,采用sentence level anisotropy評(píng)價(jià)指標(biāo):
anisotropy :將corpus里面的sentence,兩兩計(jì)算余弦相似度,求平均。
對(duì)比了不同的語(yǔ)言模型,預(yù)實(shí)驗(yàn)如下所示:
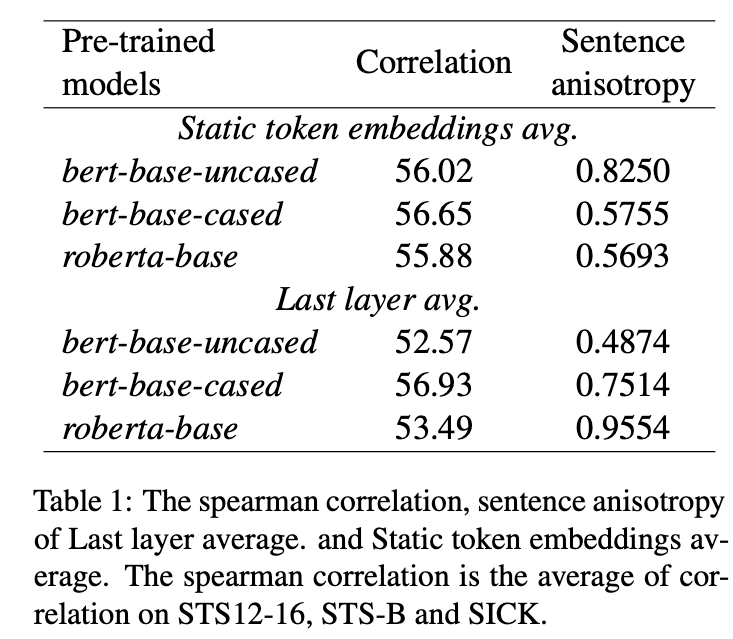
從上表可以看出,貌似anisotropy對(duì)應(yīng)的spearman系數(shù)比較低,說(shuō)明相關(guān)性不大。比如bert-base-uncased,
可以看出static token embedding的anisotropy很大,但是最終的效果也差不多。
(2)Embedding biases harms the sentence embeddings performance.
token embedding會(huì)同時(shí)受到token frequency和word piece影響
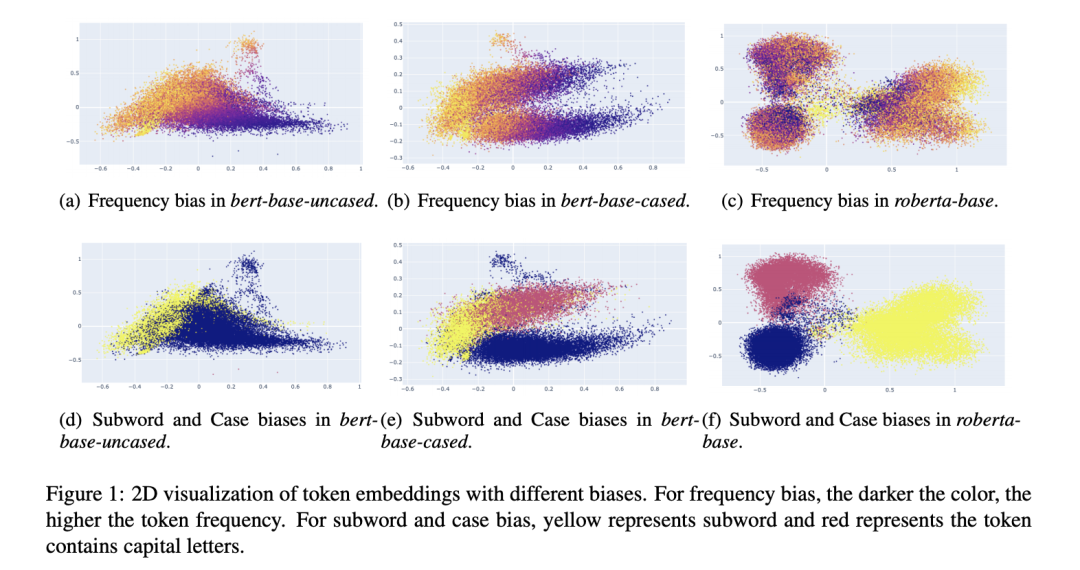
不同的語(yǔ)言模型的token embedding高度受到詞頻、subword的影響;
通過(guò)可視化2D圖,高頻詞通常會(huì)聚在一起,低頻詞則會(huì)分散
For frequency bias, we can observe that high fre- quency tokens are clustered, while low frequency tokens are dispersed sparsely in all models (Yan et al., 2021). The begin-of-word tokens are more vulnerable to frequency than subword tokens in BERT. However, the subword tokens are more vul- nerable in RoBERTa.
三、方法
如何避免BERT在表征句子時(shí)出現(xiàn)上述提到的問(wèn)題,本文提出使用Prompt來(lái)捕捉句子表征。但不同于先前prompt的應(yīng)用(分類或生成),我們并不是獲得句子的標(biāo)簽,而是獲得句子的向量,因此關(guān)于prompt-based sentence embedding,需要考慮兩個(gè)問(wèn)題:
如何使用prompt表征一個(gè)句子;
如何尋找恰當(dāng)?shù)膒rompt;
本文提出一種基于prompt和對(duì)比學(xué)習(xí)的句子表征學(xué)習(xí)模型。
3.1 如何使用prompt表征一個(gè)句子
本文設(shè)計(jì)一個(gè)template,例如“[X] means [MASK]”,[X] 表示一個(gè)placehoder,對(duì)應(yīng)一個(gè)句子,[MASK]則表示待預(yù)測(cè)的token。給定一個(gè)句子,并轉(zhuǎn)換為prompt后喂入BERT中。有兩種方法獲得該句子embedding:
方法一:直接使用[MASK]對(duì)應(yīng)的隱狀態(tài)向量:;
方法二:使用MLM在[MASK]位置預(yù)測(cè)topK個(gè)詞,根據(jù)每個(gè)詞預(yù)測(cè)的概率,對(duì)每個(gè)詞的word embedding進(jìn)行加權(quán)求和來(lái)表示該句子:
方法二將句子使用若干個(gè)MLM生成的token來(lái)表示,依然存在bias,因此本文只采用第一種方法
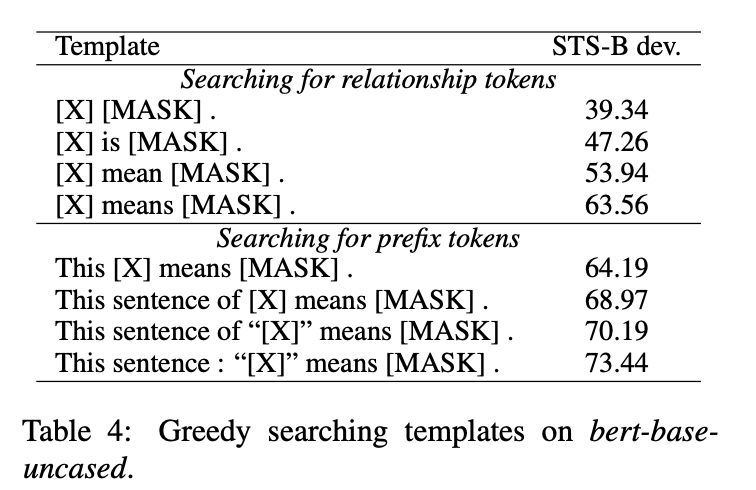
3.2 如何尋找恰當(dāng)?shù)膒rompt
關(guān)于prompt設(shè)計(jì)上,可以采用如下三種方法:
manual design:顯式設(shè)計(jì)離散的template;
使用T5模型生成;
OptiPrompt:將離散的template轉(zhuǎn)換為continuous template;
3.3 訓(xùn)練
采用對(duì)比學(xué)習(xí)方法,對(duì)比學(xué)習(xí)中關(guān)于positive的選擇很重要,一種方法是采用dropout。本文采用prompt方法,為同一個(gè)句子生成多種不同的template,以此可以獲得多個(gè)不同的positive embedding。
The idea is using the different templates to repre- sent the same sentence as different points of view, which helps model to produce more reasonable pos- itive pairs.
為了避免template本身對(duì)句子產(chǎn)生語(yǔ)義上的偏向。作者采用一種trick:
喂入含有template的句子,獲得[MASK]對(duì)應(yīng)的embedding ;
只喂入template本身,且template的token的position id保留其在原始輸入的位置,此時(shí)獲得[MASK]對(duì)應(yīng)的embeding:
最后套入對(duì)比學(xué)習(xí)loss中進(jìn)行訓(xùn)練:
四、實(shí)驗(yàn)
作者在多個(gè)文本相似度任務(wù)上進(jìn)行了測(cè)試,實(shí)驗(yàn)結(jié)果如圖所示:
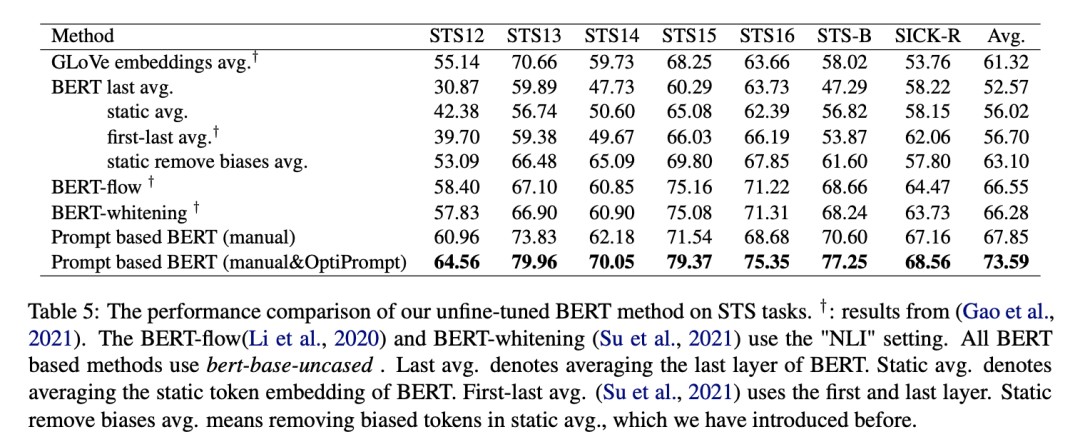
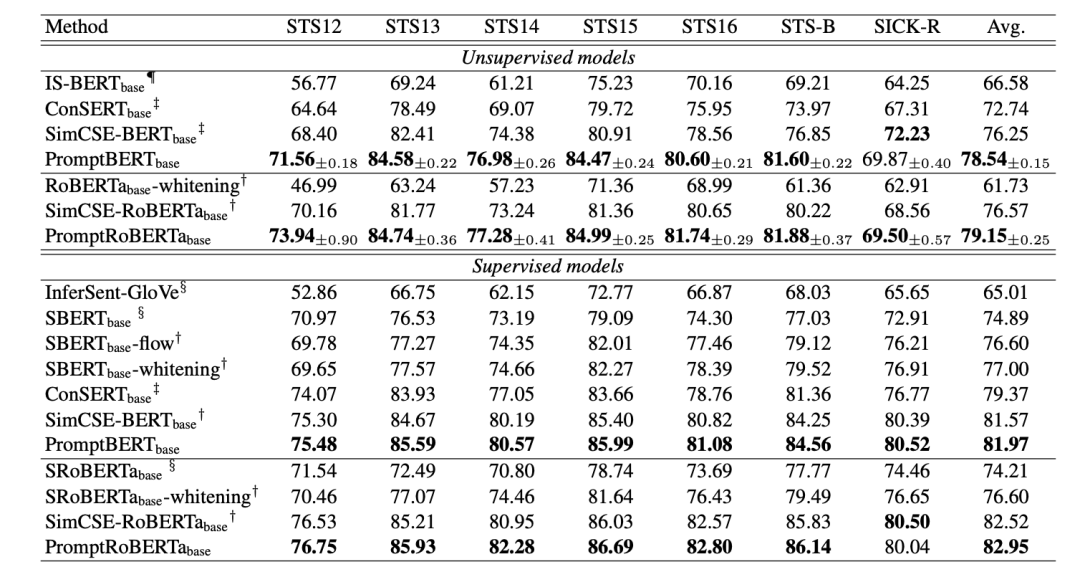
驚奇的發(fā)現(xiàn),PromptBERT某些時(shí)候竟然比SimCSE高,作者也提出使用對(duì)比學(xué)習(xí),也許是基于SimCSE之上精細(xì)微調(diào)后的結(jié)果。
審核編輯:劉清
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10714
原文標(biāo)題:Prompt+對(duì)比學(xué)習(xí),更好地學(xué)習(xí)句子表征
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一種改進(jìn)的句子相似度計(jì)算模型
基于分層組合模式的句子組合模型
一種新的目標(biāo)分類特征深度學(xué)習(xí)模型
深度學(xué)習(xí)模型介紹,Attention機(jī)制和其它改進(jìn)
語(yǔ)義表征的無(wú)監(jiān)督對(duì)比學(xué)習(xí):一個(gè)新理論框架
一種新型的AI模型可以提升學(xué)生的學(xué)習(xí)能力
一種注意力增強(qiáng)的自然語(yǔ)言推理模型aESIM

一種基于間隔準(zhǔn)則的多標(biāo)記學(xué)習(xí)算法
一種可分享數(shù)據(jù)和機(jī)器學(xué)習(xí)模型的區(qū)塊鏈






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論