 Hungtask原理及分析
Hungtask原理及分析
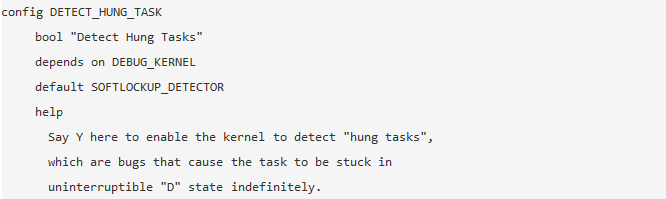
一、簡介
Linux系統在運行過程中,可能發生各種各樣的卡死情況。有的表現為某個或某些CPU無法調度其他進程或無法響應中斷,如正在CPU上運行的進程禁止了搶占或禁止了本地中斷后,但其需要的資源一直無法獲得(如發生了死鎖等情況),而一直占據著CPU;有的表現為某些重要進程一直不能運行,雖然不至于使某個或某些CPU上無法調度其他進程,但由于重要進程運行異常,系統已無法正常進行業務處理,例如重要進程長期處于uninterruptible sleep狀態(也就是常說的D狀態)或android systemserver的watchdog超時等情況。
本文主要討論進程長期處于D狀態或重要進程異常卡住的檢測方法,即hungtask detect機制。而恢復機制,一般就是在檢測到異常時,直接觸發整機重啟。
二、hungtask detect原理及流程
hungtask detect方法有多種,原理都很簡單。比如:
A、可以定時輪詢系統中的所有task,然后判斷處于D狀態的task的上下文切換次數是否和之前輪詢時的相等,如果相等則表明該task兩個輪詢間隔期間一直處于D狀態,可以認為該task有hang的情況。當然,task hang住的情況,對于有些task來說沒有關系,可能其本身的邏輯就是如此,不會對系統中其它task產生影響;但對于一些我們認為重要的進程,如android中的systemserver、surfaceflinger等進程,如果發生hang的情況,則一定會對用戶使用產生影響;還有task長時間處于io wait狀態,同樣是一種異常狀態,因為一般來說io應盡快結束,而時間過長則表明io子系統很可能已經異常。
B、如果只是判斷系統中的重要進程是否卡住,也可以不檢查系統中所有task的狀態,只需要關注重要進程的運行情況。可以讓這個重要進程在規定時間內模擬喂狗操作,若發現沒有及時喂狗,則認為該重要進程已經卡住。
以下分別討論上面所述的兩種hungtask detect實現方式,所列代碼均為開源代碼,代碼鏈接見附錄參考文檔。
1、輪詢系統中的所有任務
這里對輪詢系統中的所有任務的hungtask detect方式進行分析,代碼見參考文檔1,主要涉及代碼:
kernelhung_task.c (linux系統默認實現)
driverssocqcomhung_task_enh.c (在默認實現上進行vendor hook)
KCONFIG
libKconfig.debug (對應hung_task.c )
driverssocqcomKconfig (對應hung_task_enh.c)

代碼分析
kernelhung_task.c
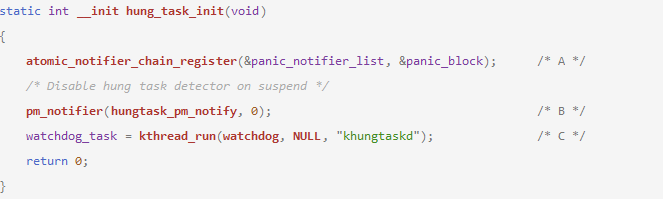
A. 將panic_block(notifier_block結構體)掛到panic_notifier_list通知鏈,當系統發生panic時,會通過該通知鏈通知注冊到該鏈的所有notifier_block,調用每個notifier_block的notifier_call成員函數。
對于這里的hungtask,就是在panic時調用hung_task_panic函數置did_panic為1,在hungtask檢測流程中發現did_panic為1,則直接退出。

B. hungtask_pm_notify_nb(notifier_block結構體)掛到pm_chain_head通知鏈,當系統發生pm狀態變化時調用hungtask_pm_notify,設置hung_detector_suspended變量。

C. 起內核線程,運行D狀態檢測函數watchdog(),下面分析。
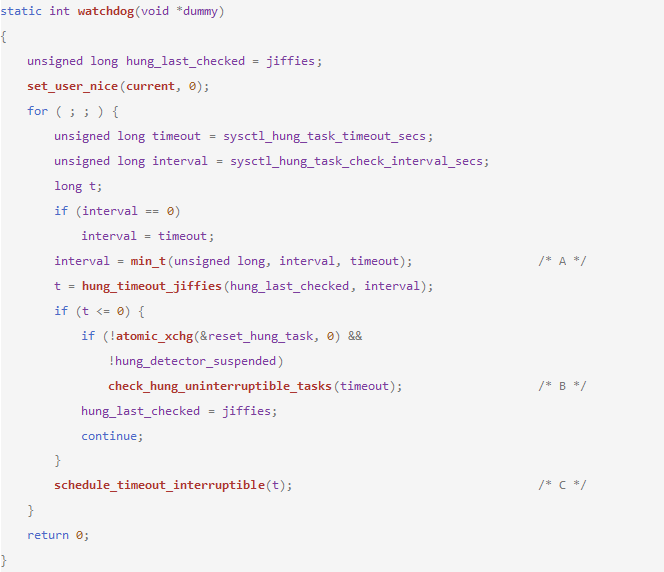
A. 取sysctl_hung_task_timeout_secs和sysctl_hung_task_check_interval_secs最小值作為檢測時的interval,加上次檢測時間hung_last_checked,如達到或超過當前時間jiffies則進行hungtask check。
B. hungtask check函數,下面詳細分析。
C. 進入可中斷休眠,如有信號提前中斷喚起該線程,會在A處的時間判斷中確定是否進行hungtask check。

A. 限制進行hung check的task數量,本輪檢測的task數量達到該值后退出。
B. 如已經運行了HUNG_TASK_LOCK_BREAK時間,調用rcu_lock_break() 短暫退出rcu臨界區并調度出去,避免一次rcu grace period的時間過長,之后再調度回來時再次進入rcu臨界區。由于調度出去再回來時,正在檢測的task可能已經釋放,所以在調度出去之前,需要使用get_task_struct增加task的task_struct結構體的引用計數,防止其被釋放,在通過pid_alive判斷task是否dead后,再調用put_task_struct減小引用計數。如果調度回來時發現task已經dead,則退出本輪hung check。

C. 為符合GKI規范,此處通過vendor hook函數,調用vendor實現的hook函數,這里的實現是調用register函數注冊對應hook函數,qcom_before_check_tasks() 和qcom_check_tasks_done(),后面會有分析,主要就是判斷該task是否需要hungtask檢查,并獲得當前iowait task的數量。
vendor hook函數注冊如下所示:
driverssocqcomhung_task_enh.c

D. 根據C處返回的need_check,如判斷需要進行hungtask檢查,則調用check_hung_task(),后面會有分析。
E. 此處調用qcom_check_tasks_done,判斷在對所有task進行hung_task_enh.max_iowait_timeout_cnt輪的檢測,如果連續地每輪都有大于等于hung_task_enh.max_iowait_task_cnt數量的task處于iowait狀態,則直接觸發panic。
F. 之后的流程就是在本輪hungtask檢測結束后,跟蹤標志狀態顯示task的鎖狀態及當前各CPU上的棧。
接下來看下hook函數的具體內容。
driverssocqcomhung_task_enh.c

A. 一個task根據其task_struct中的walt_task_struct的hung_detect_status成員判斷,如果在白名單(白名單模式)或不在黑名單(黑名單模式),則置need_check標志,然后繼續判斷是否要增加iowait task數量的統計值。
B. 如果task處于iowait狀態,且為D狀態、暫停狀態、跟蹤狀態之一,且到了檢查hungtask的時間,且為用戶空間進程主線程,則增加iowait task數量的統計值。
接下來看check_hung_task()的具體內容。

A. 如果task已凍結或為調用vfork的進程(會處于D狀態直到等子進程調用exit或exec)則跳過hungtask檢查。
B. task的自愿(nvcsw )和非自愿(nivcsw)上下文切換次數的和如果在檢測interval之間變動過,則說明該task沒有hung住,即使task當前為D狀態。直接返回,跳過該task。
C.打印sysctl_hung_task_warnings次task block信息后就不再打印,也就是說,更多的hungtask信息有可能不會再被看到。打印task block信息時,會置hung_task_show_lock和hung_task_show_all_bt標志,在退出本輪所有task的hungtask檢查后,會根據這些標志打印task的鎖情況以及各CPU的backtrace。之后就退出了本輪的所有task的hungtask檢查。
2.只關注重要進程
這里對第二種hungtask detect實現方式進行分析,只判斷系統中的重要進程是否卡住,代碼見參考文檔2,主要涉及驅動代碼:
driversmiscmediatekmonitor_hanghang_detect.c
KCONFIG定義
driversmiscmediatekmonitor_hangKconfig (對應hung_task.c )
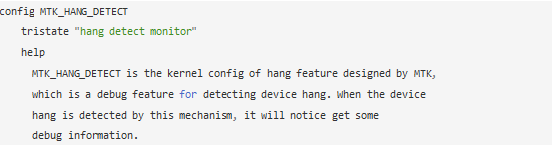
代碼分析
driversmiscmediatekmonitor_hanghang_detect.c

A. 注冊hang monitor的misc device,名稱為RT_Monitor,通過其write接口控制hang monitor的使能,通過ioctl設置(類似watchdog kick操作)hang_detect_counter(后面分析的hang_detect線程會定時遞減這個counter,也就是說,如果不重置,一定時間之后就會認為重要任務 hang住了)和hang monitor的使能(hd_detect_enabled)。

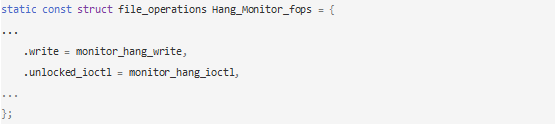
B. 啟動hang_detect和hang_detect1線程。hang_detect線程為檢測線程,下面分析。hang_detect1用來在檢測到hang時dump系統狀態。

繼續看下hang_detect線程的工作。


A處啟動循環,當hang detect使能,且白名單中的task均在系統中時,每HD_INTER秒(默認為30秒)會對hang_detect_counter減一,減一前會檢查hang_detect_counter,當小于等于0時,會dump系統狀態或觸發BUG死機。
當系統持續hang住時,hang_detect_counter會先減到0,這時Hang_first_done是false(表示hang后的第一次處理還沒完成),所以會運行wake_up_dump()(hang_detect線程)喚醒hang_detect1線程,hang_detect1線程dump系統狀態之后,置dump_bt_done為1,表示已經完成dump backtrace,再喚醒wake_up_dump()(hang_detect線程),之后E處設置Hang_first_done為true,表示hang后的第一次處理已經完成,之后hang_detect_counter會減到-1。
若系統還持續hang住,會走到B處,此處判斷條件時的意思是,如果之前hang_detect1線程dump系統狀態沒有正常執行完成,則這里會再啟動hang_detect2;否則,還會再喚醒hang_detect1線程,再次dump系統狀態,方便和之前的進行對比。之后走到D處,調用BUG觸發死機重啟以復位系統,否則關鍵進程可能一直卡住而不能自動恢復。
wake_up_dump()

hang_detect1線程

hang_detect2線程

三、問題分析
上面介紹了兩種hungtask檢測的原理及方法,我們知道了不同系統可以如何判斷task已經hang住,進而觸發系統去顯示或保存現場狀態(如發現重要task持續hang住時,會多次打印D狀態task的棧信息、或系統最終因為hungtask無法恢復而重啟時保存ramdump)及異常恢復。
一般可以通過kernel log中的task棧信息打印,看到hang住的關鍵task及其對應的棧,并對比相隔一定時間的多次該task的棧情況,明確該task確實已經異常,之后就可以根據棧的情況推測及尋找線索。如果開啟了ramdump,異常重啟時保存的ramdump也會對問題分析產生很大的幫助。
實際遇到的大多數問題,通過log中的task棧信息,一般只能粗略知道task hang住的大致現場及方向,還需要結合log中的其他信息、ramdump等進行分析,可能還需要判斷問題發生場景、編譯調試版本復現問題抓取更多信息,或者排查可疑修改。
由hungtask原理可知,產生hungtask異常的直接原因是所關注的task長時間處于D狀態或無法調度運行,一般就是task本身有異常或系統有異常影響到了該task。以系統異常的情況居多,常見的可能原因有內存不足、內存分配異常、UFS器件異常、文件系統異常、spinlock或rwsem等各種鎖死鎖、中斷風暴等等;task本身的異常,可能是其本身邏輯問題,需要具體分析。針對每種原因,大都有對應的判斷及定位方法,可以輸出相應的調試版本壓測復現分析。
以下舉兩個實際的例子看下hungtask問題發生的現象及分析方法。
1、開關機測試時死機
在開關機測試及各項功能測試時均出現了低概率死機問題,由于故障機分散,判斷為非硬件個體問題。查看故障機kernel log,發現死機之前,有hungtask打印。下面是其中一例死機前輸出的hungtask情況。

hungtask檢測輸出的hang住的其中幾個task的棧情況如下,該例中init進程阻塞在了io上。

分析多例故障現場,hang住的task不一致,用T32分析對應的ramdump,task會卡在對不同文件的io操作;出問題時hang住的task數量均較多。
解析ramdump得到cpu上的任務隊列情況,

發現一個swr irq(音頻功放注冊的中斷)在運行,一個swr irq在pending,還有多個cfs task也在pending。查看系統中斷狀態,觀察到開機的短時間內,產生了大量中斷,引起中斷風暴,可能會嚴重影響系統中其他任務的執行,包括io操作,由此導致比較隨機的開機時不同任務卡io的問題的發生。
之后去掉該音頻功放注冊的中斷(實際上這個中斷對應的音頻功放并沒有使用,中斷引腳輸入狀態不定導致隨機的中斷異常),進行開關機壓測,沒有復現問題。
2、Monkey測試時死機
某項目發現低概率hungtask問題,過一段時間就會有一、兩例出現,在Money測試中概率有所上升,每輪中能穩定出現一到兩例。每次出現問題的task不一定相同。下面舉一個例子:

這里時surfaceflinger出現了hungtask情況,其一直在嘗試獲取 kworker/u16:14 進程所持的mutex。再查看kworker/u16:14,

可以看到該task在等rpm(處理系統中時鐘和電源請求的子系統)操作的completion,但這里rpm ack一直沒有返回。查看其它異常時現場,共性都是rpm ack一直沒有返回。最后分析到,雖然系統還有足夠的H memory(HighAtomic),但ap和rpm通信用的glink分配內存時無法使用這種遷移類型的memory;系統同時有許多zs_malloc失敗的情況,因為zram功能本身在進行內存分配時,也沒有使用H memory,從而導致anon page回收異常。
最后,調整內存回收參數,該問題得以優化。
四、總結
本文主要描述了什么是hungtask、hungtask檢測方法以及hungtask產生的原因,并通過兩個案例,展示了具體問題分析方法。
hungtask表現為某些重要進程一直不能運行,如長期處于uninterruptible sleep狀態(也就是常說的D狀態。可以采取多種方法檢測:定時輪詢系統中的所有task,然后判斷處于D狀態的task的上下文切換次數是否和之前輪詢時的相等,如果相等則表明該task兩個輪詢間隔期間一直處于D狀態,可以認為該task有hang的情況;或只關注重要進程的運行情況,讓這個重要進程在規定時間內模擬喂狗操作,若發現沒有及時喂狗,則認為其有hang的情況。產生hungtask的直接原因是所關注的task長時間處于D狀態或無法調度運行,task本身有異常或系統有異常影響到了該task:對于系統異常,常見的可能原因有內存不足、內存分配異常、UFS器件異常、文件系統異常、spinlock或rwsem等各種鎖死鎖、中斷風暴等等;task本身的異常,為其本身邏輯問題。
審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
11049瀏覽量
216167 -
Linux
+關注
關注
87文章
11469瀏覽量
212926 -
Detect
+關注
關注
0文章
6瀏覽量
7279
原文標題:Hungtask原理及分析
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
matlab fft頻譜分析與分析程序
什么是失效分析?失效分析原理是什么?
基于MATLAB的系統分析與設計——時頻分析
SPICE仿真的類型:DC分析、AC分析、瞬態分析
金屬分析、成分分析、分析
失效分析方法---PCB失效分析
【九聯科技Unionpi Tiger開發板試用體驗】HarmonyOS系統中UART串口通信調試
友商(深圳)科技—光學仿真分析、電磁分析、高頻分析
什么是靜態代碼分析?靜態代碼分析概述







 工商網監
工商網監
評論