") 一文讀懂Redis
一文讀懂Redis
Redis 管道
我們通常使用 Redis 的方式是,發(fā)送命令,命令排隊(duì),Redis 執(zhí)行,然后返回結(jié)果,這個過程稱為Round trip time(簡稱RTT, 往返時間)。但是如果有多條命令需要執(zhí)行時,需要消耗 N 次 RTT,經(jīng)過 N 次 IO 傳輸,這樣效率明顯很低。
于是 Redis 管道(pipeline)便產(chǎn)生了,一次請求/響應(yīng)服務(wù)器能實(shí)現(xiàn)處理新的請求即使舊的請求還未被響應(yīng)。這樣就可以將多個命令發(fā)送到服務(wù)器,而不用等待回復(fù),最后在一個步驟中讀取該答復(fù)。這就是管道(pipelining),減少了 RTT,提升了效率
重要說明: 使用管道發(fā)送命令時,服務(wù)器將被迫回復(fù)一個隊(duì)列答復(fù),占用很多內(nèi)存。所以,如果你需要發(fā)送大量的命令,最好是把他們按照合理數(shù)量分批次的處理,例如10K的命令,讀回復(fù),然后再發(fā)送另一個10k的命令,等等。這樣速度幾乎是相同的,但是在回復(fù)這10k命令隊(duì)列需要非常大量的內(nèi)存用來組織返回數(shù)據(jù)內(nèi)容。
Redis 發(fā)布訂閱
發(fā)布訂閱是一種消息模式,發(fā)送者(sub)發(fā)送消息,訂閱者(pub)接收消息
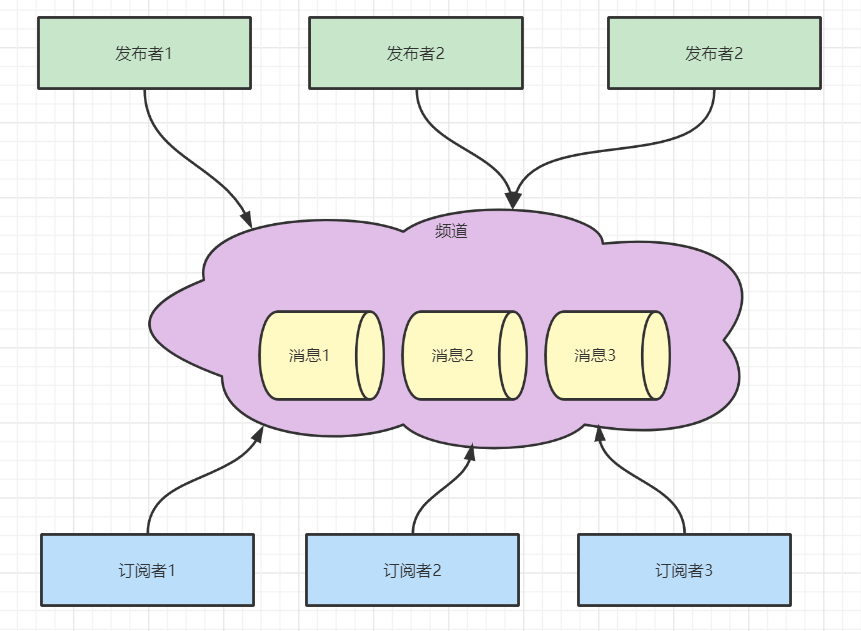
如上圖所示,發(fā)布訂閱基于頻道實(shí)現(xiàn)的,同一個頻道可以有多個訂閱者,多個發(fā)布者。其中任意一個發(fā)布者發(fā)布消息到頻道中,所以訂閱者都可以收到該消息。
發(fā)布訂閱 Redis 演示
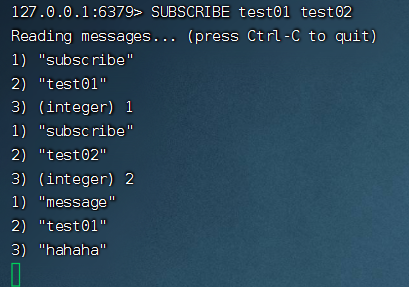
我在服務(wù)器上啟動了 4 個 Redis 客戶端,2 個訂閱者,2 個發(fā)布者,訂閱者訂閱的頻道為 channel01
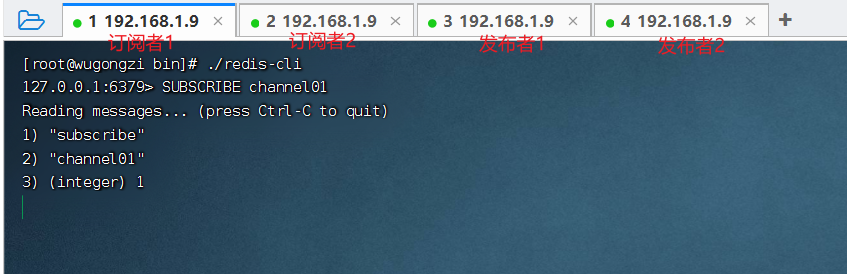
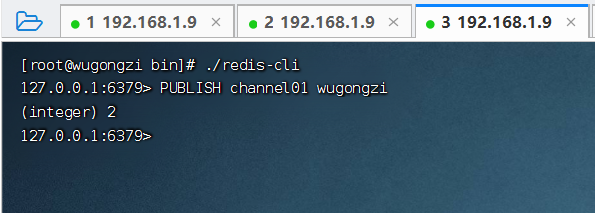
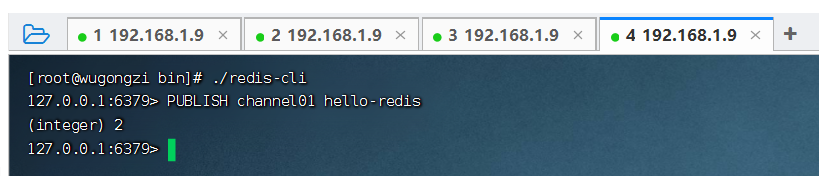
第一步:發(fā)布者 1 往 channel01 中發(fā)送消息 "wugongzi"
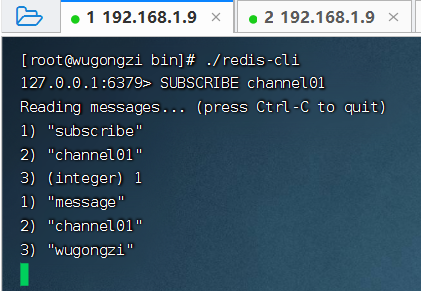
訂閱者 1 收到消息:
訂閱者 2 收到消息:
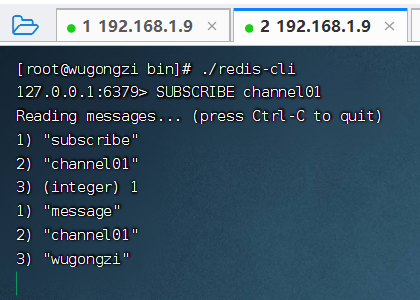
第二步:發(fā)布者 2 往頻道中發(fā)布消息 "hello-redis"
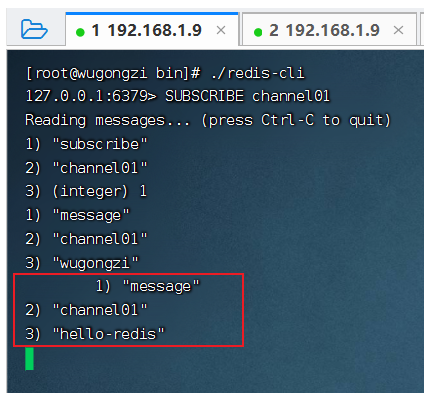
訂閱者 1 收到消息:
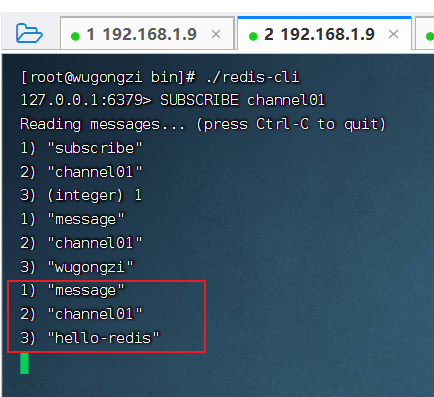
訂閱者 2 收到消息:
Redis 同時支持訂閱多個頻道:
Redis 過期策略
過期時間使用
Redis 可以給每個 key 都設(shè)置一個過期時間,過期時間到達(dá)后,Redis 會自動刪除這個 key。
實(shí)際生產(chǎn)中,我們還是要求必須要為每個 Redis 的 Key 設(shè)置一個過期時間,如果不設(shè)置過期時間,時間一久,Redis 內(nèi)存就會滿了,有很多冷數(shù)據(jù),依然存在。
設(shè)置過期時間的命令:EXPIRE key seconds
在使用過程中有一點(diǎn)需要注意,就是在每次更新 Redis 時,都需要重新設(shè)置過期時間,如果不設(shè)置,那個 key 就是永久的,下面給大家演示一下如何使用:

過期刪除策略
Redis keys過期有兩種方式:被動和主動方式。
當(dāng)一些客戶端嘗試訪問過期 key 時,Redis 發(fā)現(xiàn) key 已經(jīng)過期便刪除掉這些 key
當(dāng)然,這樣是不夠的,因?yàn)橛行┻^期的 keys,可能永遠(yuǎn)不會被訪問到。 無論如何,這些 keys 應(yīng)該過期,所以 Redis 會定時刪除這些 key
具體就是Redis每秒10次做的事情:
測試隨機(jī)的20個keys進(jìn)行相關(guān)過期檢測。
刪除所有已經(jīng)過期的keys。
如果有多于25%的keys過期,重復(fù)步奏1
這是一個平凡的概率算法,基本上的假設(shè)是,Redis的樣本是這個密鑰控件,并且我們不斷重復(fù)過期檢測,直到過期的keys的百分百低于25%,這意味著,在任何給定的時刻,最多會清除1/4的過期keys。
Redis 事務(wù)
事務(wù)基本使用
Redis 事務(wù)可以一次執(zhí)行多條命令,Redis 事務(wù)有如下特點(diǎn):
事務(wù)是一個單獨(dú)的隔離操作:事務(wù)中的所有命令都會序列化、按順序地執(zhí)行。事務(wù)在執(zhí)行的過程中,不會被其他客戶端發(fā)送來的命令請求所打斷。
事務(wù)是一個原子操作:事務(wù)中的命令要么全部被執(zhí)行,要么全部都不執(zhí)行。
Redis 事務(wù)通過 MULTI 、EXEC、DISCARD、WATCH 幾個命令來實(shí)現(xiàn),MULTI 命令用于開啟事務(wù),EXEC 用于提交事務(wù),DISCARD 用于放棄事務(wù),WATCH 可以為 Redis 事務(wù)提供 check-and-set (CAS)行為。
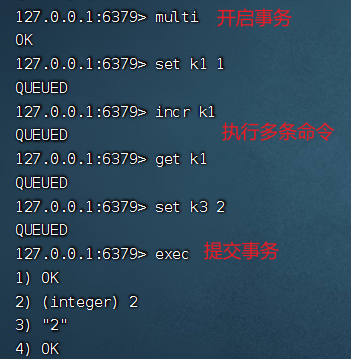
事務(wù)發(fā)生錯誤
Reids 事務(wù)發(fā)生錯誤分為兩種情況。
第一種:事務(wù)提交前發(fā)生錯誤,也就是在發(fā)送命令過程中發(fā)生錯誤,看演示
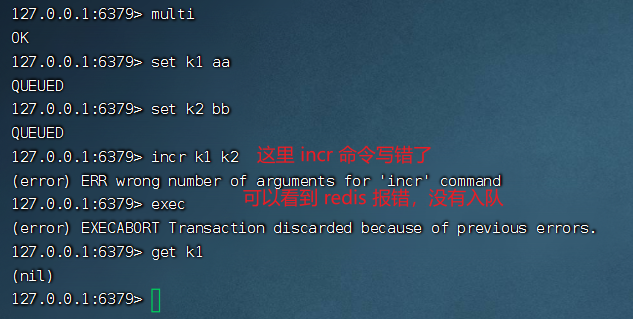
上面我故意將 incr 命令寫錯,從結(jié)果我們可以看到,這條 incr 沒有入隊(duì),并且事務(wù)執(zhí)行失敗,k1 和 k2 都沒有值
第二種:事務(wù)提交后發(fā)生錯誤,也就是在執(zhí)行命令過程中發(fā)生錯誤,看演示
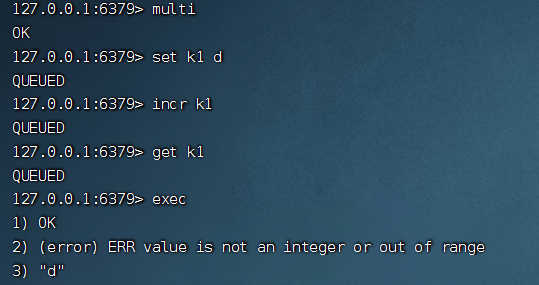
上面的事務(wù)命令中,我給 k1 設(shè)置了一個 d,然后執(zhí)行自增命令,最后獲取 k1 的值,我們發(fā)現(xiàn)第二條命令執(zhí)行發(fā)生了錯誤,但是整個事務(wù)依然提交成功了,從上面現(xiàn)象中可以得出,Redis 事務(wù)不支持回滾操作。如果支持的話,整個事務(wù)的命令都不應(yīng)該被執(zhí)行。
為什么 Redis 不支持回滾
如果你有使用關(guān)系式數(shù)據(jù)庫的經(jīng)驗(yàn), 那么 “Redis 在事務(wù)失敗時不進(jìn)行回滾,而是繼續(xù)執(zhí)行余下的命令”這種做法可能會讓你覺得有點(diǎn)奇怪。
以下是這種做法的優(yōu)點(diǎn):
Redis 命令只會因?yàn)殄e誤的語法而失敗(并且這些問題不能在入隊(duì)時發(fā)現(xiàn)),或是命令用在了錯誤類型的鍵上面:這也就是說,從實(shí)用性的角度來說,失敗的命令是由編程錯誤造成的,而這些錯誤應(yīng)該在開發(fā)的過程中被發(fā)現(xiàn),而不應(yīng)該出現(xiàn)在生產(chǎn)環(huán)境中。
因?yàn)椴恍枰獙貪L進(jìn)行支持,所以 Redis 的內(nèi)部可以保持簡單且快速。
有種觀點(diǎn)認(rèn)為 Redis 處理事務(wù)的做法會產(chǎn)生 bug , 然而需要注意的是, 在通常情況下, 回滾并不能解決編程錯誤帶來的問題。 舉個例子, 如果你本來想通過 incr 命令將鍵的值加上 1 , 卻不小心加上了 2 , 又或者對錯誤類型的鍵執(zhí)行了 incr , 回滾是沒有辦法處理這些情況的。
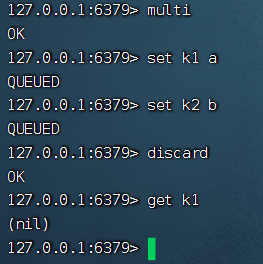
放棄事務(wù)
當(dāng)執(zhí)行 discard 命令時, 事務(wù)會被放棄, 事務(wù)隊(duì)列會被清空, 并且客戶端會從事務(wù)狀態(tài)中退出
WATCH 命令使用
watch 使得 exec 命令需要有條件地執(zhí)行: 事務(wù)只能在所有被監(jiān)視鍵都沒有被修改的前提下執(zhí)行, 如果這個前提不能滿足的話,事務(wù)就不會被執(zhí)行
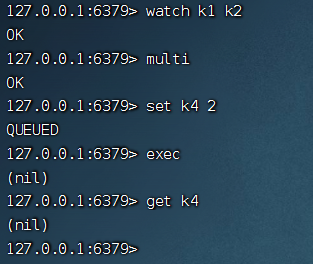
上面我用 watch 命令監(jiān)聽了 k1 和 k2,然后開啟事務(wù),在事務(wù)提交之前,k1 的值被修改了,watch 監(jiān)聽到 k1 值被修改,所以事務(wù)沒有被提交。
Redis 腳本和事務(wù)
從定義上來說, Redis 中的腳本本身就是一種事務(wù), 所以任何在事務(wù)里可以完成的事, 在腳本里面也能完成。 并且一般來說, 使用腳本要來得更簡單,并且速度更快。
因?yàn)槟_本功能是 Redis 2.6 才引入的, 而事務(wù)功能則更早之前就存在了, 所以 Redis 才會同時存在兩種處理事務(wù)的方法。
Reids 持久化
為什么需要持久化
我們知道 Redis 是內(nèi)存數(shù)據(jù)庫,主打高性能,速度快。相比 Redis 而言,MySQL 的數(shù)據(jù)則是保存再硬盤中(其實(shí)也有內(nèi)存版的 MySQL 數(shù)據(jù)庫,但是價格極其昂貴,一般公司不會使用),速度慢,但是穩(wěn)定性好。你想想 Redis 數(shù)據(jù)保存在內(nèi)存中,一旦服務(wù)器宕機(jī)了,數(shù)據(jù)豈不是全部都沒了,這將會出現(xiàn)很大問題。所以 Redis 為了彌補(bǔ)這一缺陷,提供數(shù)據(jù)持久化機(jī)制,即使服務(wù)器宕機(jī),依然可以保證數(shù)據(jù)不丟失。
持久化簡介
Redis 提供了兩種持久化機(jī)制 RDB 和 AOF,適用于不同場景
RDB持久化方式能夠在指定的時間間隔能對你的數(shù)據(jù)進(jìn)行快照存儲
AOF持久化方式記錄每次對服務(wù)器寫的操作,當(dāng)服務(wù)器重啟的時候會重新執(zhí)行這些命令來恢復(fù)原始的數(shù)據(jù),AOF命令以redis協(xié)議追加保存每次寫的操作到文件末尾.Redis還能對AOF文件進(jìn)行后臺重寫,使得AOF文件的體積不至于過大
RDB
RDB 持久化是通過在指定時間間隔對數(shù)據(jù)進(jìn)行快照,比如在 8 點(diǎn)鐘對數(shù)據(jù)進(jìn)行持久化,那么 Redis 會 fork 一個子進(jìn)程將 8 點(diǎn)那一刻內(nèi)存中的數(shù)據(jù)持久化到磁盤上。觸發(fā) RDB 持久化有以下幾種方法
RDB 持久化方式
1、執(zhí)行 save 命令
執(zhí)行 save 命令進(jìn)行持久會阻塞 Redis,備份期間 Redis 無法對外提供服務(wù),一般不建議使用,使用場景為 Redis 服務(wù)器需要停機(jī)維護(hù)的情況下。
2、執(zhí)行 bgsave 命令
bgsave 命令不會阻塞 Redis 主進(jìn)程,持久化期間 Redis 依然可以正常對外提供服務(wù)
3、通過配置文件中配置的 save 規(guī)則來觸發(fā)
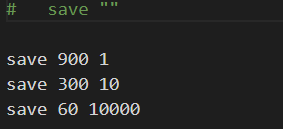
save 900 1:900s 內(nèi)有 1 個 key 發(fā)生變化,則觸發(fā) RDB 快照
save 300 10:300s 內(nèi)有 10 個 key 發(fā)生變化,則觸發(fā) RDB 快照
save 60 10000:60s 內(nèi)有 10000 個 key 發(fā)生變化(新增、修改、刪除),則觸發(fā) RDB 快照
save "":該配置表示關(guān)閉 RDB 持久化
RDB 持久化原理
Redis 進(jìn)行 RDB 時,會 fork 一個子進(jìn)程來進(jìn)行數(shù)據(jù)持久化,這樣不妨礙 Redis 繼續(xù)對外提供服務(wù),提高效率。
曾經(jīng)面試官出過這樣面試題:
假如 Redis 在 8 點(diǎn)觸發(fā)了 RDB 持久化,持久化用時 2 分鐘,在持久化期間,Redis 中有 100 個 key 被修改了,那么 RDB 文件中的 key 是 8 點(diǎn)那一刻的數(shù)據(jù),還是變化的呢?
先不要看答案,自己思考 1 分鐘,一個問題只有你自己思考了,才能印象深刻。
好,下面我們一起來看下這張圖:
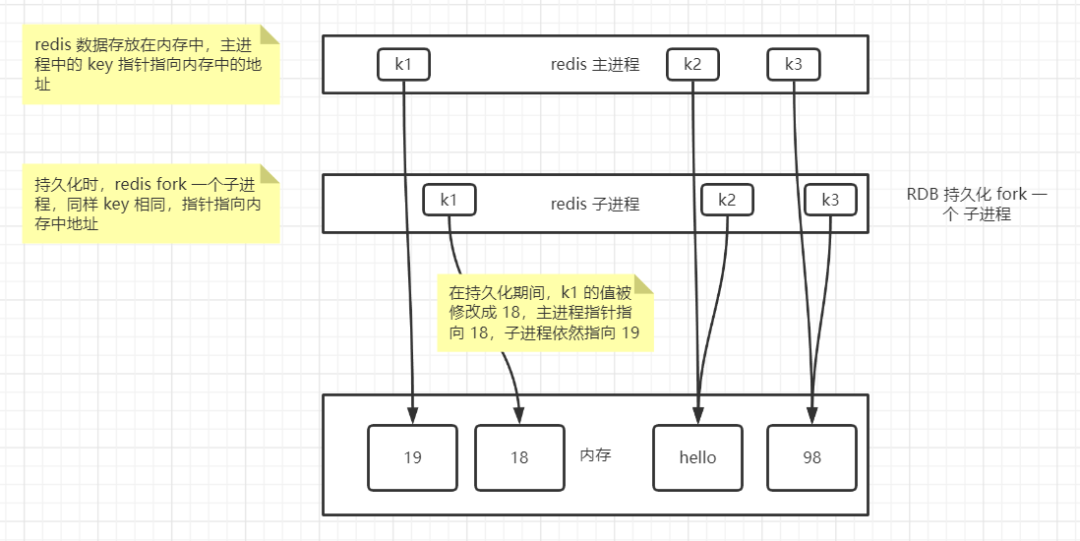
從圖中我們可以清晰的看到,Redis 備份時,fork 了一個子進(jìn)程,子進(jìn)程去做持久化的工作,子進(jìn)程中的 key 指向了 8 點(diǎn)那一刻的數(shù)據(jù),后面 k1 的值修改了,redis 會在內(nèi)存中創(chuàng)建一個新的值,然后主進(jìn)程 k1 指針指向新的值,子進(jìn)程 k1 指針依然指向 19,這樣 Redis 持久化的就是 8 點(diǎn)那一刻的數(shù)據(jù),不會發(fā)生變化。同時,從圖中我們也可以看到,Redis 持久化時并不是將內(nèi)存中數(shù)據(jù)全部拷貝一份進(jìn)行備份。
RDB 優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
RDB是一個非常緊湊的文件,它保存了某個時間點(diǎn)得數(shù)據(jù)集,非常適用于數(shù)據(jù)集的備份,比如你可以在每個小時報保存一下過去24小時內(nèi)的數(shù)據(jù),同時每天保存過去30天的數(shù)據(jù),這樣即使出了問題你也可以根據(jù)需求恢復(fù)到不同版本的數(shù)據(jù)集
RDB在保存RDB文件時父進(jìn)程唯一需要做的就是fork出一個子進(jìn)程,接下來的工作全部由子進(jìn)程來做,父進(jìn)程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能
與AOF相比,在恢復(fù)大的數(shù)據(jù)集的時候,RDB方式會更快一些
缺點(diǎn)
如果備份間隔時間較長,RDB 會丟失較多的數(shù)據(jù)。比如 8 點(diǎn)備份一次,8 點(diǎn)半服務(wù)器宕機(jī),那么這半小時內(nèi)的數(shù)據(jù)就會丟失了
AOF
AOF 持久化是通過日志的方式,記錄每次 Redis 的寫操作。當(dāng)服務(wù)器重啟的時候會重新執(zhí)行這些命令來恢復(fù)原始的數(shù)據(jù),AOF 命令以Redis 協(xié)議追加保存每次寫的操作到文件末尾。Redis 還能對 AOF 文件進(jìn)行后臺重寫,使得 AOF 文件的體積不至于過大
AOF 持久化配置
#是否開啟aofno:關(guān)閉;yes:開啟 appendonlyno #aof文件名 appendfilename"appendonly.aof" #aof同步策略 #appendfsyncalways#每個命令都寫入磁盤,性能較差 appendfsynceverysec#每秒寫一次磁盤,Redis默認(rèn)配置 #appendfsyncno#由操作系統(tǒng)執(zhí)行,默認(rèn)Linux配置最多丟失30秒 #aof重寫期間是否同步 no-appendfsync-on-rewriteno #重寫觸發(fā)策略 auto-aof-rewrite-percentage100#觸發(fā)重寫百分比(指定百分比為0,將禁用aof自動重寫功能) auto-aof-rewrite-min-size64mb#觸發(fā)自動重寫的最低文件體積(小于64mb不自動重寫) #加載aof時如果有錯如何處理 #如果該配置啟用,在加載時發(fā)現(xiàn)aof尾部不正確是,會向客戶端寫入一個log,但是會繼續(xù)執(zhí)行,如果設(shè)置為no,發(fā)現(xiàn)錯誤就會停止,必須修復(fù)后才能重新加載。 aof-load-truncatedyes #aof中是否使用rdb #開啟該選項(xiàng),觸發(fā)AOF重寫將不再是根據(jù)當(dāng)前內(nèi)容生成寫命令。而是先生成RDB文件寫到開頭,再將RDB生成期間的發(fā)生的增量寫命令附加到文件末尾。 aof-use-rdb-preambleyes
AOF 文件寫入
aof 文件是命令追加的方式,先將命令寫入緩沖區(qū),時間到了再寫如磁盤中
appendfsyncalways#每個命令都寫入磁盤,性能較差 appendfsynceverysec#每秒寫一次磁盤,Redis默認(rèn)配置 appendfsyncno#由操作系統(tǒng)執(zhí)行,默認(rèn)Linux配置最多丟失30秒
上面配置就是何時寫入磁盤中
AOF 重寫
aof 文件雖然丟失的數(shù)據(jù)少,但是隨著時間的增加,aof 文件體積越來越大,占用磁盤空間越來越大,恢復(fù)時間長。所以 redis 會對 aof 文件進(jìn)行重寫,以減少 aof 文件體積
下面以一個例子說明
--重寫前的aof setk120 setk240 setk135 setk334 setk219 --這里k1最終的值為35,k2最終值為19,所以不需要寫入兩個命令 --重寫后 setk135 setk334 setk219
混合持久化
從 Redis 4.0 版本開始,引入了混合持久化機(jī)制,純AOF方式、RDB+AOF方式,這一策略由配置參數(shù)aof-use-rdb-preamble(使用RDB作為AOF文件的前半段)控制,默認(rèn)關(guān)閉(no),設(shè)置為yes可開啟
no:按照AOF格式寫入命令,與4.0前版本無差別;
yes:先按照RDB格式寫入數(shù)據(jù)狀態(tài),然后把重寫期間AOF緩沖區(qū)的內(nèi)容以AOF格式寫入,文件前半部分為RDB格式,后半部分為AOF格式。
混合持久化優(yōu)點(diǎn)如下:
大大減少了 aof 文件體積
加快了 aof 文件恢復(fù)速度,前面是 rdb ,恢復(fù)速度快
AOF 數(shù)據(jù)恢復(fù)
第一種:純 AOF
恢復(fù)時,取出 AOF 中命令,一條條執(zhí)行恢復(fù)
第二種:RDB+AOF
先執(zhí)行 RDB 加載流程,執(zhí)行完畢后,再取出余下命令,開始一條條執(zhí)行
AOF 優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
AOF 實(shí)時性更好,丟失數(shù)據(jù)更少
AOF 已經(jīng)支持混合持久化,文件大小可以有效控制,并提高了數(shù)據(jù)加載時的效率
缺點(diǎn)
對于相同的數(shù)據(jù)集合,AOF 文件通常會比 RDB 文件大
在特定的 fsync 策略下,AOF 會比 RDB 略慢
AOF 恢復(fù)速度比 RDB 慢
Redis 分布式鎖
分布式鎖介紹
學(xué)習(xí)過 Java 的同學(xué),應(yīng)該對鎖都不陌生。Java 中多個線程訪問共享資源時,會出現(xiàn)并發(fā)問題,我們通常利用 synchronized 或者 Lock 鎖來解決多線程并發(fā)訪問從而出現(xiàn)的安全問題。細(xì)心的同學(xué)可能已經(jīng)發(fā)現(xiàn)了, synchronized 或者 Lock 鎖解決線程安全問題在單節(jié)點(diǎn)情況下是可行的,但是如果服務(wù)部署在多臺服務(wù)器上,本地鎖就失效了。
分布式場景下,需要采用新的解決方案,就是今天要說的 Redis 分布式鎖。日常業(yè)務(wù)中,類似搶紅包,秒殺等場景都可以使用 Redis 分布式鎖來解決并發(fā)問題。
分布式鎖特點(diǎn)
分布式在保障安全、高可用的情況下需要具備以下特性
互斥性:任意一個時刻,只能有一個客戶端獲取到鎖
安全性:鎖只能被持久的客戶端刪除,不能被其他人刪除
高可用,高性能:加鎖和解鎖消耗的性能少,時間短
鎖超時:當(dāng)客戶端獲取鎖后出現(xiàn)故障,沒有立即釋放鎖,該鎖要能夠在一定時間內(nèi)釋放,否則其他客戶端無法獲取到鎖
可重入性:客戶端獲取到鎖后,在持久鎖期間可以再次獲取到該鎖
解決方案
方案一:SETNX 命令
Redis 提供了一個獲取分布式鎖的命令 SETNX
setnxkeyvalue
如果獲取鎖成功,redis 返回 1,獲取鎖失敗 redis 返回 0
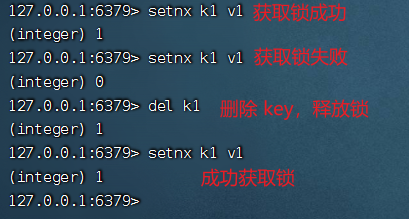
客戶端使用偽代碼
if(setnx(k1,v1)==1){
try{
//執(zhí)行邏輯
....
}catch(){
}finally{
//執(zhí)行完成后釋放鎖
delk1;
}
}
這個命令看似可以達(dá)到我們的目的,但是不符合分布式鎖的特性,如果客戶端在執(zhí)行業(yè)務(wù)邏輯過程中,服務(wù)器宕機(jī)了,finally 中代碼還沒來得及執(zhí)行,鎖沒有釋放,也就意味其他客戶端永遠(yuǎn)無法獲取到這個鎖
方案二:SETNX + EXPIRE
該方案獲取鎖之后,立即給鎖加上一個過期時間,這樣即使客戶端沒有手動釋放鎖,鎖到期后也會自動釋放
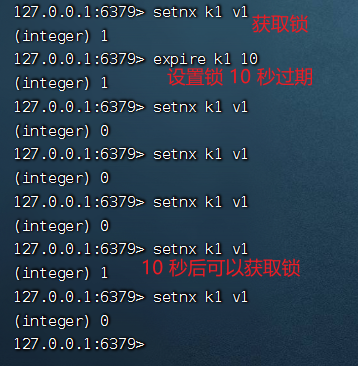
我們來看下偽代碼
if(setnx(k1,v1)==1){
expire(key,10);
try{
//....你的業(yè)務(wù)邏輯
}finally{
del(key);
}
}
這個方案很完美,既可以獲取到,又不用擔(dān)心客戶端宕機(jī)。等等,這里面真的沒有問題嗎?再仔細(xì)瞅瞅,一瞅就瞅出問題來了
if(setnx(k1,v1)==1){
//再剛獲取鎖之后,想要給鎖設(shè)置過期時間,此時服務(wù)器掛了
expire(key,10);//這條命令沒有執(zhí)行
try{
//....你的業(yè)務(wù)邏輯
}finally{
del(key);
}
}
這里的 setnx 命令和 expire 命令不是原子性的,他們之間執(zhí)行需要一定的等等時間,雖然這個時間很短,但是依然有極小概率出現(xiàn)問題
使用 Lua 腳本
既然 setnx 和 expire 兩個命令非原子性,那么我們讓其符合原子性即可,通過 Lua 腳本即可實(shí)現(xiàn)。Redis 使用單個 Lua 解釋器去運(yùn)行所有腳本,并且, Redis 也保證腳本會以原子性(atomic)的方式執(zhí)行: 當(dāng)某個腳本正在運(yùn)行的時候,不會有其他腳本或 Redis 命令被執(zhí)行
具體實(shí)現(xiàn)如下:
ifredis.call('setnx',KEYS[1],ARGV[1])==1then
redis.call('expire',KEYS[1],ARGV[2])
else
return0
end;
這樣應(yīng)該沒問題了吧,看似上面的幾個問題都很好解決了。不對,再想想,肯定還有沒考慮到的
我們再來看一段偽代碼
//執(zhí)行l(wèi)ua腳本
//獲取k1鎖,過期時間10s
if(execlua()==1){
try{
buyGoods();
}finally{
del(key);
}
}
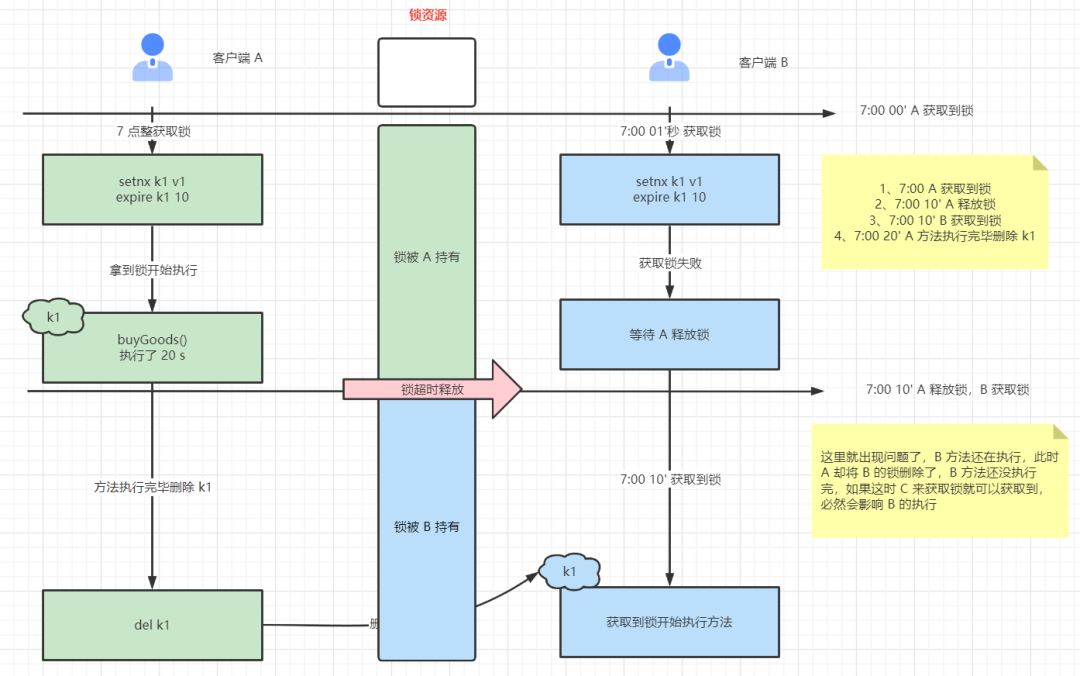
從圖中我們可以很清晰發(fā)現(xiàn)問題所在
客戶端 A 還未執(zhí)行完畢,客戶端 B 就獲取到了鎖,這樣就可能導(dǎo)致并發(fā)問題
客戶端 A 執(zhí)行完畢,開始刪除鎖。但此時的鎖為 B 所有,相當(dāng)于刪除了屬于客戶端 B 的鎖,這樣肯定會發(fā)生問題
方案四:SET EX PX NX + 校驗(yàn)唯一隨機(jī)值,再刪除
既然鎖有可能被別的客戶端刪除,那么在刪除鎖的時候我們加上一層校驗(yàn),判斷釋放鎖是當(dāng)前客戶端持有的,如果是當(dāng)前客戶端,則允許刪除,否則不允許刪除。
EX second :設(shè)置鍵的過期時間為 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :設(shè)置鍵的過期時間為 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
NX :只在鍵不存在時,才對鍵進(jìn)行設(shè)置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在鍵已經(jīng)存在時,才對鍵進(jìn)行設(shè)置操作。
使用示例:
if(jedis.set(resource_name,random_value,"NX","EX",100s)==1){//加鎖,value傳入一個隨機(jī)數(shù)
try{
dosomething//業(yè)務(wù)處理
}catch(){
}
finally{
//判斷value是否相等,相等才釋放鎖,這里判斷和刪除是非原子性,真實(shí)場景下可以將這兩步放入Lua腳本中執(zhí)行
if(random_value.equals(jedis.get(resource_name))){
jedis.del(lockKey);//釋放鎖
}
}
}
Lua 腳本如下:
ifredis.call("get",KEYS[1])==ARGV[1]then
returnredis.call("del",KEYS[1])
else
return0
end
此方案解決了鎖被其他客戶端解除的問題,但是依然沒有解決鎖過期釋放,但是業(yè)務(wù)還沒有執(zhí)行完成的問題
Redisson框架
方案四中并沒有解決方法未執(zhí)行完成,鎖就超時釋放的問題。這里有個方案大家比較容易想到,那就是鎖的超時時間設(shè)置長一點(diǎn),比如2min,一個接口執(zhí)行時間總不能比 2 min 還長,那你就等著領(lǐng)盒飯吧,哈哈哈。但是這么做,一來是不能每個鎖都設(shè)置這么久超時時間,二來是如果接口出現(xiàn)異常了,鎖只能 2 min 后才能釋放,其他客戶端等待時間較長。
這個問題早就有人想到了,并給出了解決方案,開源框架 Redisson 解決了這個問題。
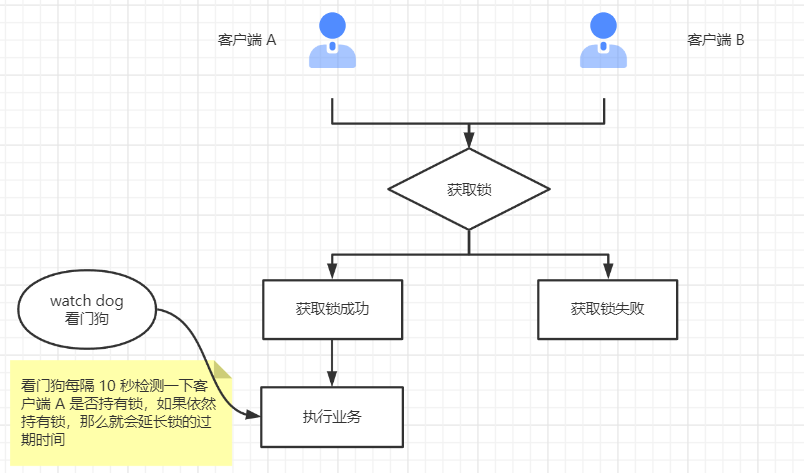
Redisson 在方法執(zhí)行期間,會不斷的檢測鎖是否到期,如果發(fā)現(xiàn)鎖快要到期,但是方法還沒有執(zhí)行完成,便會延長鎖的過期時間,從而解決了鎖超時釋放問題。
Redlock
上面所介紹的分布式鎖,都是在單臺 Redis 服務(wù)器下的解決方案。真實(shí)的生產(chǎn)環(huán)境中,我們通常會部署多臺 Redis 服務(wù)器,也就是集群模式,這種情況上述解決方案就失效了。
對于集群 Redis,Redis 的作者 antirez 提出了另一種解決方案,Redlock 算法
Redlock 算法大致流程如下:
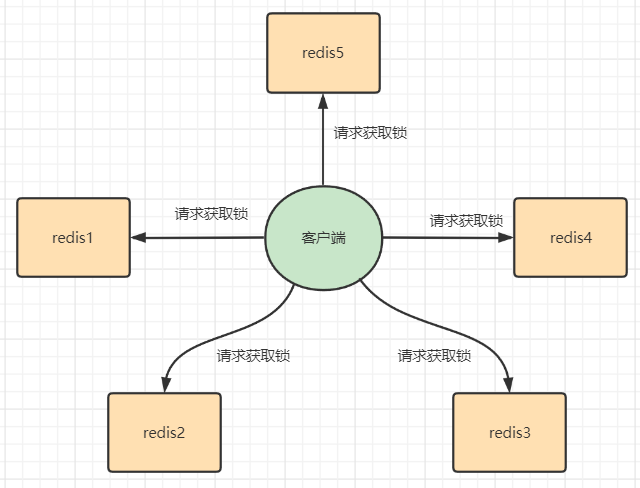
1、獲取當(dāng)前Unix時間,以毫秒為單位。
2、依次嘗試從N個實(shí)例,使用相同的key和隨機(jī)值獲取鎖。在步驟2,當(dāng)向Redis設(shè)置鎖時,客戶端應(yīng)該設(shè)置一個網(wǎng)絡(luò)連接和響應(yīng)超時時間,這個超時時間應(yīng)該小于鎖的失效時間。例如你的鎖自動失效時間為10秒,則超時時間應(yīng)該在5-50毫秒之間。這樣可以避免服務(wù)器端Redis已經(jīng)掛掉的情況下,客戶端還在死死地等待響應(yīng)結(jié)果。如果服務(wù)器端沒有在規(guī)定時間內(nèi)響應(yīng),客戶端應(yīng)該盡快嘗試另外一個Redis實(shí)例。
3、客戶端使用當(dāng)前時間減去開始獲取鎖時間(步驟1記錄的時間)就得到獲取鎖使用的時間。當(dāng)且僅當(dāng)從大多數(shù)(這里是3個節(jié)點(diǎn))的Redis節(jié)點(diǎn)都取到鎖,并且使用的時間小于鎖失效時間時,鎖才算獲取成功。
4、如果取到了鎖,key的真正有效時間等于有效時間減去獲取鎖所使用的時間(步驟3計(jì)算的結(jié)果)。
5、如果因?yàn)槟承┰颍@取鎖失敗(沒有在至少N/2+1個Redis實(shí)例取到鎖或者取鎖時間已經(jīng)超過了有效時間),客戶端應(yīng)該在所有的Redis實(shí)例上進(jìn)行解鎖(即便某些Redis實(shí)例根本就沒有加鎖成功)。
總結(jié): 簡單總結(jié)一下就是客戶端向 Redis 集群中所有服務(wù)器發(fā)送獲取鎖的請求,只有半數(shù)以上的鎖獲取成功后,才代表鎖獲取成功,否則鎖獲取失敗。
Redis 集群
Redis 集群的三種模式
在生產(chǎn)環(huán)境中,我們使用 Redis 通常采用集群模式,因?yàn)閱螜C(jī)版 Redis 穩(wěn)定性可靠性較低,而且存儲空間有限。
Redis 支持三種集群模式
主從復(fù)制
哨兵模式
Cluster 模式
主從復(fù)制
主從復(fù)制概念
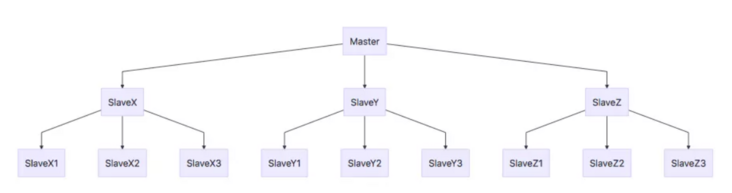
主從復(fù)制模式,有一個主,多個從,從而實(shí)現(xiàn)讀寫分離。主機(jī)負(fù)責(zé)寫請求,從機(jī)負(fù)責(zé)讀請求,減輕主機(jī)壓力
主從復(fù)制原理
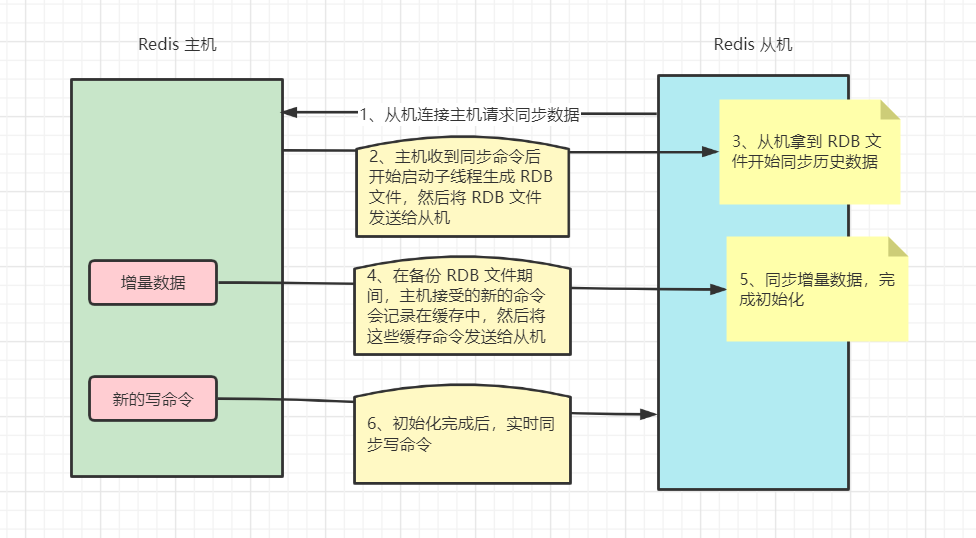
從數(shù)據(jù)庫啟動成功后,連接主數(shù)據(jù)庫,發(fā)送 SYNC 命令;
主數(shù)據(jù)庫接收到 SYNC 命令后,開始執(zhí)行 BGSAVE 命令生成 RDB 文件并使用緩沖區(qū)記錄此后執(zhí)行的所有寫命令;
主數(shù)據(jù)庫 BGSAVE 執(zhí)行完后,向所有從數(shù)據(jù)庫發(fā)送快照文件,并在發(fā)送期間繼續(xù)記錄被執(zhí)行的寫命令;
從數(shù)據(jù)庫收到快照文件后丟棄所有舊數(shù)據(jù),載入收到的快照;
主數(shù)據(jù)庫快照發(fā)送完畢后開始向從數(shù)據(jù)庫發(fā)送緩沖區(qū)中的寫命令;
從數(shù)據(jù)庫完成對快照的載入,開始接收命令請求,并執(zhí)行來自主數(shù)據(jù)庫緩沖區(qū)的寫命令;(從數(shù)據(jù)庫初始化完成)
主數(shù)據(jù)庫每執(zhí)行一個寫命令就會向從數(shù)據(jù)庫發(fā)送相同的寫命令,從數(shù)據(jù)庫接收并執(zhí)行收到的寫命令(從數(shù)據(jù)庫初始化完成后的操作)
出現(xiàn)斷開重連后,2.8之后的版本會將斷線期間的命令傳給重數(shù)據(jù)庫,增量復(fù)制。
主從剛剛連接的時候,進(jìn)行全量同步;全同步結(jié)束后,進(jìn)行增量同步。當(dāng)然,如果有需要,slave 在任何時候都可以發(fā)起全量同步。Redis 的策略是,無論如何,首先會嘗試進(jìn)行增量同步,如不成功,要求從機(jī)進(jìn)行全量同步。
主從復(fù)制優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
支持主從復(fù)制,主機(jī)會自動將數(shù)據(jù)同步到從機(jī),可以進(jìn)行讀寫分離
Slave 同樣可以接受其它 Slaves 的連接和同步請求,這樣可以有效的分載 Master 的同步壓力
Master Server 是以非阻塞的方式為 Slaves 提供服務(wù)。所以在 Master-Slave 同步期間,客戶端仍然可以提交查詢或修改請求
缺點(diǎn)
主從不具備容錯和恢復(fù)能力,一旦主機(jī)掛了,那么整個集群處理可讀狀態(tài),無法處理寫請求,會丟失數(shù)據(jù)
主機(jī)宕機(jī)后無法自動恢復(fù),只能人工手動恢復(fù)
集群存儲容量有限,容量上線就是主庫的內(nèi)存的大小,無法存儲更多內(nèi)容
###哨兵集群
哨兵概念
哨兵,我們經(jīng)常在電視劇中看到一些放哨的,哨兵的作用和這些放哨的差不多,起到監(jiān)控作用。一旦 Redis 集群出現(xiàn)問題了,哨兵會立即做出相應(yīng)動作,應(yīng)對異常情況。
哨兵模式是基于主從復(fù)制模式上搭建的,因?yàn)橹鲝膹?fù)制模式情況下主服務(wù)器宕機(jī),會導(dǎo)致整個集群不可用,需要人工干預(yù),所以哨兵模式在主從復(fù)制模式下引入了哨兵來監(jiān)控整個集群,哨兵模式架構(gòu)圖如下:
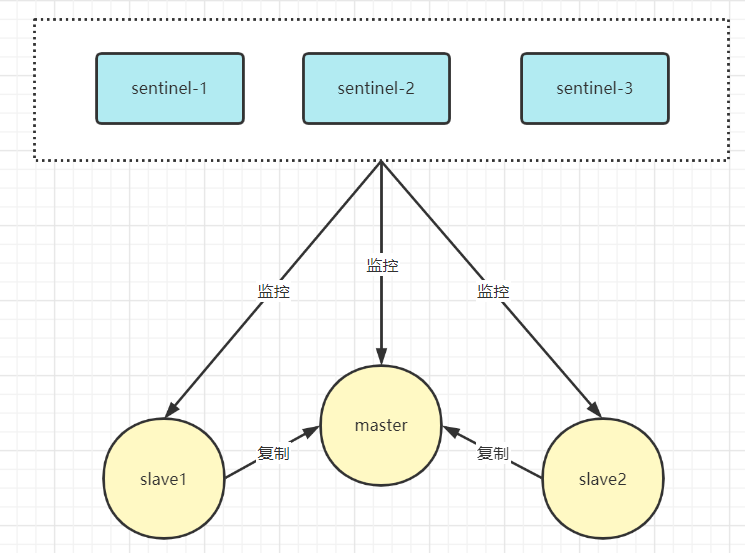
哨兵功能
監(jiān)控(Monitoring):哨兵會不斷地檢查主節(jié)點(diǎn)和從節(jié)點(diǎn)是否運(yùn)作正常。
自動故障轉(zhuǎn)移(Automatic failover):當(dāng)主節(jié)點(diǎn)不能正常工作時,哨兵會開始自動故障轉(zhuǎn)移操作,它會將失效主節(jié)點(diǎn)的其中一個從節(jié)點(diǎn)升級為新的主節(jié)點(diǎn),并讓其他從節(jié)點(diǎn)改為復(fù)制新的主節(jié)點(diǎn)。
配置提供者(Configuration provider):客戶端在初始化時,通過連接哨兵來獲得當(dāng)前Redis服務(wù)的主節(jié)點(diǎn)地址。
通知(Notification):哨兵可以將故障轉(zhuǎn)移的結(jié)果發(fā)送給客戶端。
下線判斷
Redis 下線分為主觀下線和客觀下線兩種
主觀下線:單臺哨兵任務(wù)主庫處于不可用狀態(tài)
客觀下線:整個哨兵集群半數(shù)以上的哨兵都認(rèn)為主庫處于可不用狀態(tài)
哨兵集群中任意一臺服務(wù)器判斷主庫不可用時,此時會發(fā)送命令給哨兵集群中的其他服務(wù)器確認(rèn),其他服務(wù)器收到命令后會確認(rèn)主庫的狀態(tài),如果不可用,返回 YES,可用則返回 NO,當(dāng)有半數(shù)的服務(wù)器都返回 YES,說明主庫真的不可用,此時需要重新選舉
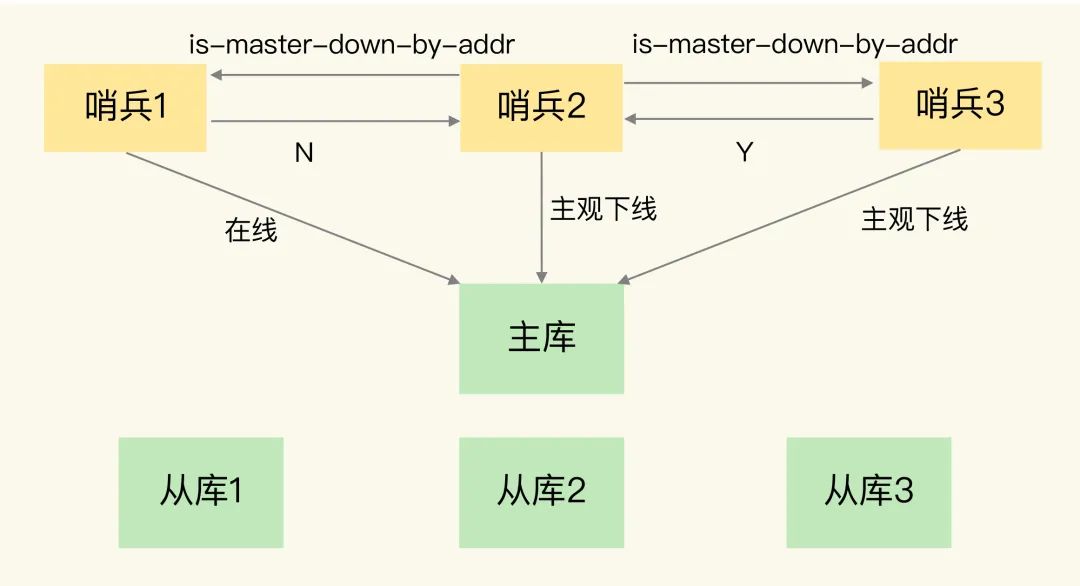
主庫選舉
當(dāng)哨兵集群判定主庫下線了,此時需要重新選舉出一個新的主庫對外提供服務(wù)。那么該由哪個哨兵來完成這個新庫選舉和切換的動作呢?
注意:這里不能讓每個哨兵都去選舉,可能會出現(xiàn)每個哨兵選舉出的新主庫都不同,這樣就沒法判定,所以需要派出一個代表
哨兵代表選擇
哨兵的選舉機(jī)制其實(shí)很簡單,就是一個Raft選舉算法: 選舉的票數(shù)大于等于num(sentinels)/2+1時,將成為領(lǐng)導(dǎo)者,如果沒有超過,繼續(xù)選舉
任何一個想成為 Leader 的哨兵,要滿足兩個條件:
第一,拿到半數(shù)以上的贊成票;
第二,拿到的票數(shù)同時還需要大于等于哨兵配置文件中的 quorum 值。
以 3 個哨兵為例,假設(shè)此時的 quorum 設(shè)置為 2,那么,任何一個想成為 Leader 的哨兵只要拿到 2 張贊成票,就可以了。
新庫選擇
上面已經(jīng)選舉出了哨兵代表,此時代表需要完成新主庫的選擇,新庫的選擇需要滿足以下幾個標(biāo)準(zhǔn)
新庫需要處于健康狀態(tài),也就是和哨兵之間保持正常的網(wǎng)絡(luò)連接
選擇salve-priority從節(jié)點(diǎn)優(yōu)先級最高(redis.conf)的
選擇復(fù)制偏移量最大,只復(fù)制最完整的從節(jié)點(diǎn)
故障轉(zhuǎn)移
上面一小節(jié)哨兵已經(jīng)選舉出了新的主庫,故障轉(zhuǎn)移要實(shí)現(xiàn)新老主庫之間的切換
故障轉(zhuǎn)移流程如下:
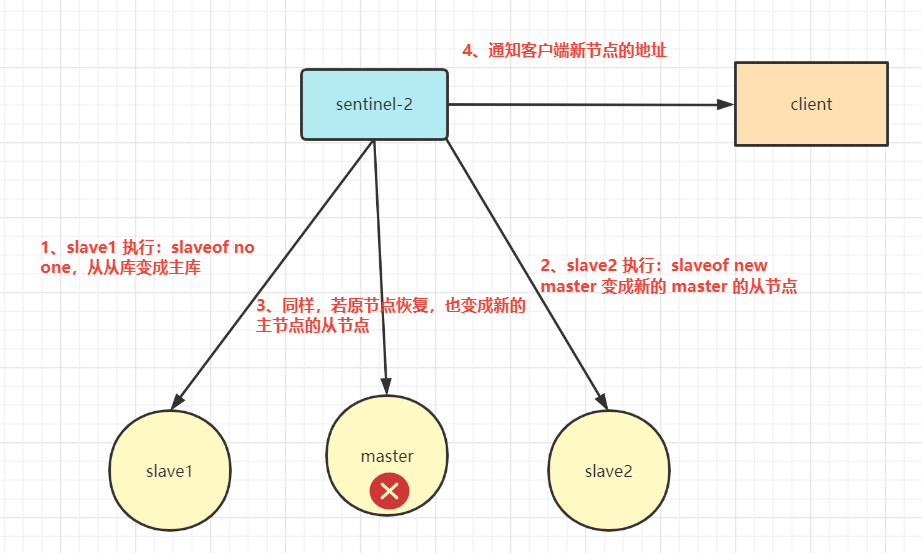
哨兵模式優(yōu)缺點(diǎn)
優(yōu)點(diǎn)
實(shí)現(xiàn)了集群的監(jiān)控,故障轉(zhuǎn)移,實(shí)現(xiàn)了高可用
擁有主從復(fù)制模式的所有優(yōu)點(diǎn)
缺點(diǎn)
集群存儲容量有限,容量上線就是主庫的內(nèi)存的大小,無法存儲更多內(nèi)容
Cluser 集群
Redis 的哨兵模式實(shí)現(xiàn)了高可用了,但是每臺 Redis 服務(wù)器上存儲的都是相同的數(shù)據(jù),浪費(fèi)內(nèi)存,而且很難實(shí)現(xiàn)容量上的擴(kuò)展。所以在 redis3.0上加入了 Cluster 集群模式,實(shí)現(xiàn)了 Redis 的分布式存儲,也就是說每臺 Redis 節(jié)點(diǎn)上存儲不同的內(nèi)容。
Redis 集群的數(shù)據(jù)分片
Redis 集群沒有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384個哈希槽,每個key通過CRC16校驗(yàn)后對16384取模來決定放置哪個槽.集群的每個節(jié)點(diǎn)負(fù)責(zé)一部分hash槽,舉個例子,比如當(dāng)前集群有3個節(jié)點(diǎn),那么:
節(jié)點(diǎn) A 包含 0 到 5500號哈希槽.
節(jié)點(diǎn) B 包含5501 到 11000 號哈希槽.
節(jié)點(diǎn) C 包含11001 到 16384號哈希槽.
這種結(jié)構(gòu)很容易添加或者刪除節(jié)點(diǎn). 比如如果我想新添加個節(jié)點(diǎn)D, 我需要從節(jié)點(diǎn) A, B, C中得部分槽到D上. 如果我想移除節(jié)點(diǎn)A,需要將A中的槽移到B和C節(jié)點(diǎn)上,然后將沒有任何槽的A節(jié)點(diǎn)從集群中移除即可. 由于從一個節(jié)點(diǎn)將哈希槽移動到另一個節(jié)點(diǎn)并不會停止服務(wù),所以無論添加刪除或者改變某個節(jié)點(diǎn)的哈希槽的數(shù)量都不會造成集群不可用的狀態(tài).
Redis 集群實(shí)戰(zhàn)
環(huán)境:
Vmware 虛擬機(jī)
CentOS 7
Redis 6.0.6
因?yàn)槲沂窃诒緳C(jī)上演示的,所以用的虛擬機(jī)
主從復(fù)制
集群信息如下:
| 節(jié)點(diǎn) | 配置文件 | 端口 |
|---|---|---|
| master | redis6379.conf | 6379 |
| slave1 | redis6380.conf | 6380 |
| slave1 | redis6381.conf | 6380 |
第一步:準(zhǔn)備三個 redis.conf 配置文件,配置文件信息如下
#redis6379.confmaster #包含命令,有點(diǎn)復(fù)用的意思 include/soft/redis6.0.6/bin/redis.conf pidfileredis_6379.pid port6379 dbfilenamedump6379.rdb logfile"redis-6379.log" #redis6380.confslave1 include/soft/redis6.0.6/bin/redis.conf pidfileredis_6380.pid port6380 dbfilenamedump6380.rdb logfile"redis-6380.log" #最后一行設(shè)置了主節(jié)點(diǎn)的ip端口 replicaof127.0.0.16379 #redis6381.confslave2 include/soft/redis6.0.6/bin/redis.conf pidfileredis_6381.pid port6381 dbfilenamedump6381.rdb logfile"redis-6381.log" #最后一行設(shè)置了主節(jié)點(diǎn)的ip端口 replicaof127.0.0.16379 ##注意redis.conf要調(diào)整一項(xiàng),設(shè)置后臺運(yùn)行,對咱們操作比較友好 daemonizeyes
第二步:啟動服務(wù)器
--首先啟動6379這臺服務(wù)器,因?yàn)樗侵鲙欤▎用钤趓edis安裝目錄的bin目錄下) ../bin/redis-serverredis6379.conf --接口啟動6380和6381 ../bin/redis-serverredis6380.conf ../bin/redis-serverredis6381.conf
第三步:用客戶端連接服務(wù)器
cdbin redis-cli-p6379 redis-cli-p6380 redis-cli-p6381 這里我開了三個窗口分別連接三臺redis服務(wù)器,方便查看
在 6379 客戶端輸入命令: info replication 可用查看集群信息
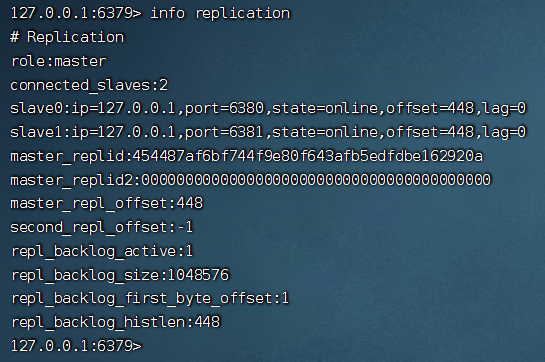
第四步:數(shù)據(jù)同步
現(xiàn)在集群已經(jīng)搭建好了,我們在 6379 服務(wù)器寫入幾條數(shù)據(jù),看下可不可以同步到 6380 和 6381
6379:
6380:
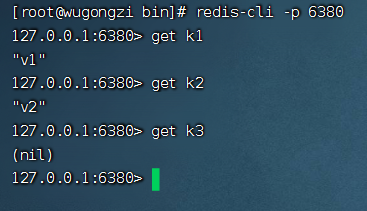
6381:
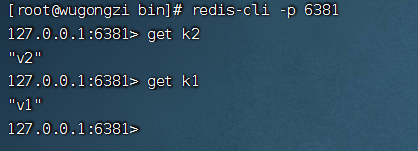
從圖中可用看出,數(shù)據(jù)已經(jīng)成功同步了
哨兵模式
哨兵集群是在主從復(fù)制的基礎(chǔ)上構(gòu)建的,相當(dāng)于是主從+哨兵
搭建哨兵模式分為兩步:
搭建主從復(fù)制集群
添加哨兵配置
哨兵模式節(jié)點(diǎn)信息如下,一主二從,三個哨兵組成一個哨兵集群
| 節(jié)點(diǎn) | 配置 | 端口 |
|---|---|---|
| master | redis6379.conf | 6379 |
| slave1 | redis6380.conf | 6380 |
| slave2 | redis6381.conf | 6381 |
| sentinel1 | sentinel1.conf | 26379 |
| sentinel2 | sentinel2.conf | 26380 |
| sentinel3 | sentinel3.conf | 26381 |
主從復(fù)制集群的配置同上,這里就不再贅述,下面主要介紹下哨兵的配置,哨兵的配置文件其實(shí)非常簡單
#文件內(nèi)容 #sentinel1.conf port26379 sentinelmonitormymaster127.0.0.163791 #sentinel2.conf port26380 sentinelmonitormymaster127.0.0.163791 #sentinel3.conf port26381 sentinelmonitormymaster127.0.0.163791
配置文件創(chuàng)建好了以后就可以啟動了,首先啟動主從服務(wù)器,然后啟動哨兵
../bin/redis-serverredis6379.conf ../bin/redis-serverredis6380.conf ../bin/redis-serverredis6381.conf --啟動哨兵 ../bin/redis-sentinelsentinel1.conf ../bin/redis-sentinelsentinel2.conf ../bin/redis-sentinelsentinel3.conf
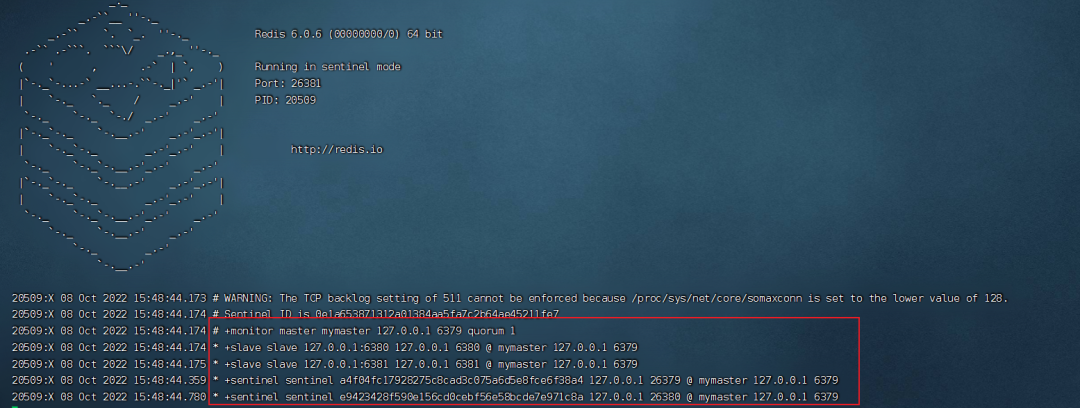
從哨兵的啟動日志中我們可用看到主從服務(wù)器的信息,以及其他哨兵節(jié)點(diǎn)的信息
故障轉(zhuǎn)移
主從同步功能上面已經(jīng)演示過了,這里主要測試一下哨兵的故障轉(zhuǎn)移
現(xiàn)在我手動將主節(jié)點(diǎn)停掉,在 6379 上執(zhí)行 shutdown 命令
此時我們觀察一下哨兵的頁面:
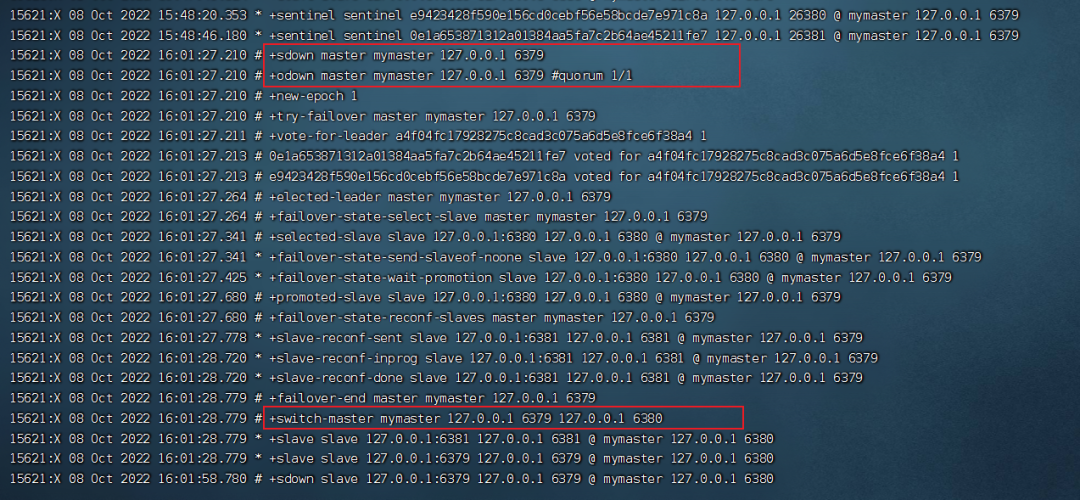
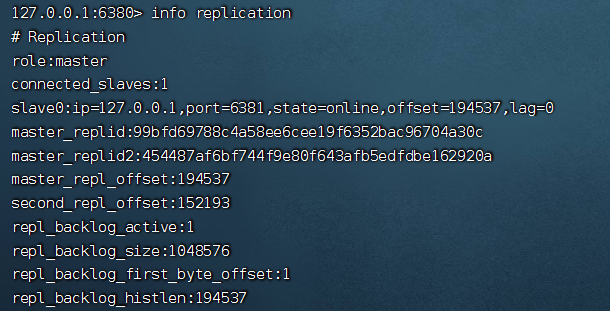
哨兵檢測到了 6379 下線,然后選舉出了新的主庫 6380
此時我們通過 info replication 命令查看集群信息,發(fā)現(xiàn) 6380 已經(jīng)是主庫了,他有一個從節(jié)點(diǎn) 6381
現(xiàn)在我手動將 6379 啟動,看下 6379 會不會重新變成主庫
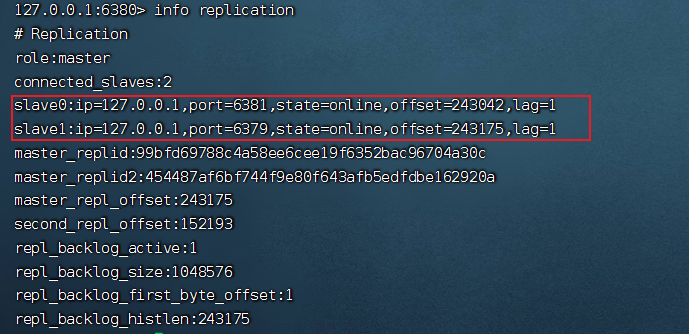
重新啟動后,我們發(fā)現(xiàn) 6379 變成了 80 的從庫
Cluser 集群
官方推薦,Cluser 集群至少要部署 3 臺以上的 master 節(jié)點(diǎn),最好使用 3 主 3 從
| 節(jié)點(diǎn) | 配置 | 端口 |
|---|---|---|
| cluster-master1 | redis7001.conf | 7001 |
| cluster-master2 | redis7002.conf | 7002 |
| cluster-master3 | redis7003.conf | 7003 |
| cluster-slave1 | redis7004.conf | 7004 |
| cluster-slave2 | redis7006.conf | 7005 |
| cluster-slave3 | redis7006.conf | 7006 |
配置文件內(nèi)容如下,6 個配置文件信息基本相同,編輯好一份后其他文件直接復(fù)制修改端口即可
#端口 port7001 #啟用集群模式 cluster-enabledyes #根據(jù)你啟用的節(jié)點(diǎn)來命名,最好和端口保持一致,這個是用來保存其他節(jié)點(diǎn)的名稱,狀態(tài)等信息的 cluster-config-filenodes_7001.conf #超時時間 cluster-node-timeout5000 appendonlyyes #后臺運(yùn)行 daemonizeyes #非保護(hù)模式 protected-modeno pidfileredis_7001.pid
然后分別啟動 6 個節(jié)點(diǎn)
../bin/redis-serverredis7001.conf ../bin/redis-serverredis7002.conf ../bin/redis-serverredis7003.conf ../bin/redis-serverredis7004.conf ../bin/redis-serverredis7005.conf ../bin/redis-serverredis7006.conf
啟動集群
#執(zhí)行命令 #--cluster-replicas1命令的意思是創(chuàng)建master的時候同時創(chuàng)建一個slave $redis-cli--clustercreate127.0.0.1:7001127.0.0.1:7002127.0.0.1:7003127.0.0.1:7004127.0.0.1:7005127.0.0.1:7006--cluster-replicas1
啟動過程有個地方需要輸入 yes 確認(rèn):

啟動成功后可用看到控制臺輸出結(jié)果:

3 個 master 節(jié)點(diǎn),3 個 slave 節(jié)點(diǎn),
master[0]槽位:0-5460
master[1]槽位:5461-10922
master[2]槽位:10923-16383
數(shù)據(jù)驗(yàn)證
連接 7001 服務(wù)器
redis-cli -p 7001 -c 集群模式下需要加上 -c 參數(shù)
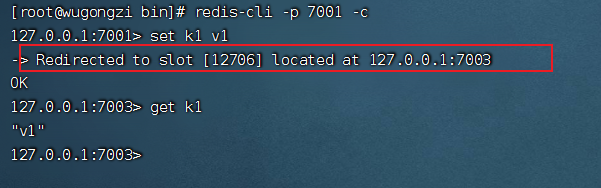
從圖中可用看出,k1 被放到 7003 主機(jī)上了,我們此時獲取 k1 ,可用正常獲取到
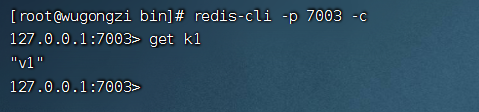
登錄 7003 也可以正常拿到數(shù)據(jù)
Redis 緩存問題
在服務(wù)端中,數(shù)據(jù)庫通常是業(yè)務(wù)上的瓶頸,為了提高并發(fā)量和響應(yīng)速度,我們通常會采用 Redis 來作為緩存,讓盡量多的數(shù)據(jù)走 Redis 查詢,不直接訪問數(shù)據(jù)庫。同時 Redis 在使用過程中也會出現(xiàn)各種各樣的問題,面對這些問題我們該如何處理?
緩存穿透
緩存擊穿
緩存雪崩
緩存污染
緩存穿透
1、定義:
緩存穿透是指,當(dāng)緩存和數(shù)據(jù)中都沒有對應(yīng)記錄,但是客戶端卻一直在查詢。比如黑客攻擊系統(tǒng),不斷的去查詢系統(tǒng)中不存在的用戶,查詢時先走緩存,緩存中沒有,再去查數(shù)據(jù)庫;或者電商系統(tǒng)中,用戶搜索某類商品,但是這類商品再系統(tǒng)中根本不存在,這次的搜索應(yīng)該直接返回空
2、解決方案
網(wǎng)關(guān)層增加校驗(yàn),進(jìn)行用戶鑒權(quán),黑名單控制,接口流量控制
對于同一類查詢,如果緩存和數(shù)據(jù)庫都沒有獲取到數(shù)據(jù),那么可用用一個空緩存記錄下來,過期時間 60s,下次遇到同類查詢,直接取出緩存中的空數(shù)據(jù)返回即可
使用布隆過濾器,布隆過濾器可以用來判斷某個元素是否存在于集合中,利用布隆過濾器可以過濾掉一大部分無效請求
緩存擊穿
1、定義:
緩存擊穿是指,緩存中數(shù)據(jù)失效,在高并發(fā)情況下,所有用戶的請求全部都打到數(shù)據(jù)庫上,短時間造成數(shù)據(jù)庫壓力過大
2、解決方案:
接口限流、熔斷
加鎖,當(dāng)?shù)谝粋€用戶請求到時,如果緩存中沒有,其他用戶的請求先鎖住,第一個用戶查詢數(shù)據(jù)庫后立即緩存到 Redis,然后釋放鎖,這時候其他用戶就可以直接查詢緩存
緩存雪崩
1、定義
緩存雪崩是指 Redis 中大批量的 key 在同一時間,或者某一段時間內(nèi)一起過期,造成多個 key 的請求全部無法命中緩存,這些請求全部到數(shù)據(jù)庫中,給數(shù)據(jù)庫帶來很大壓力。與緩存擊穿不同,擊穿是指一個 key 過期,雪崩是指很多 key 同時過期。
2、解決方案
緩存過期時間設(shè)置成不同時間,不要再統(tǒng)一時間過期
如果緩存數(shù)據(jù)庫是分布式部署,將熱點(diǎn)數(shù)據(jù)均勻分布在不同的緩存數(shù)據(jù)庫中。
緩存污染
1、定義
緩存污染是指,由于歷史原因,緩存中有很多 key 沒有設(shè)置過期時間,導(dǎo)致很多 key 其實(shí)已經(jīng)沒有用了,但是一直存放在 redis 中,時間久了,redis 內(nèi)存就被占滿了
2、解決方案
緩存盡量設(shè)置過期時間
設(shè)置緩存淘汰策略為最近最少使用的原則,然后將這些數(shù)據(jù)刪除。
審核編輯:劉清
-
RTT
+關(guān)注
關(guān)注
0文章
65瀏覽量
17218 -
過濾器
+關(guān)注
關(guān)注
1文章
432瀏覽量
19736 -
Redis
+關(guān)注
關(guān)注
0文章
378瀏覽量
10942
原文標(biāo)題:這次徹底讀透 Redis !
文章出處:【微信號:cxuangoodjob,微信公眾號:程序員cxuan】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論