") GPT-3、Stable Diffusion一起助攻,讓模型聽懂甲方修圖需求
GPT-3、Stable Diffusion一起助攻,讓模型聽懂甲方修圖需求

AI 可以完全按照甲方意愿修圖?GPT-3、Stable Diffusion 一起助攻,讓模型秒變 PS 高手,改圖隨心所欲。
擴散模型大火之后,很多人將注意力放到了如何利用更有效的 prompt 生成自己想要的圖像。在對于一些 AI 作畫模型的不斷嘗試中,人們甚至總結(jié)出了讓 AI 好好出圖的關(guān)鍵詞經(jīng)驗:

也就是說,如果掌握了正確的 AI 話術(shù),作圖質(zhì)量提升效果將非常明顯(參見:《「羊駝打籃球」怎么畫?有人花了 13 美元逼 DALL·E 2 亮出真本事 》)。
此外,還有一部分研究者在往另一個方向努力:如何動動嘴皮子就把一幅畫改成我們想要的樣子。
前段時間,我們報道了一項來自谷歌研究院等機構(gòu)的研究。只要說出你想讓一幅圖變成什么樣子,它就能基本滿足你的要求,生成照片級的圖像,例如讓一只小狗坐下:

這里給模型的輸入描述是「一只坐下的狗」,但是按照人們的日常交流習慣,最自然的描述應(yīng)該是「讓這只狗坐下」。有研究者認為這是一個應(yīng)該優(yōu)化的問題,模型應(yīng)該更符合人類的語言習慣。
最近,來自 UC 伯克利的研究團隊提出了一種根據(jù)人類指令編輯圖像的新方法 InstructPix2Pix:給定輸入圖像和告訴模型要做什么的文本描述,模型就能遵循描述指令來編輯圖像。

論文地址:https://arxiv.org/pdf/2211.09800.pdf
例如,要把畫中的向日葵換成玫瑰,你只需要直接對模型說「把向日葵換成玫瑰」:

為了獲得訓練數(shù)據(jù),該研究將兩個大型預(yù)訓練模型——語言模型 (GPT-3) 和文本到圖像生成模型 (Stable Diffusion) 結(jié)合起來,生成圖像編輯示例的大型成對訓練數(shù)據(jù)集。研究者在這個大型數(shù)據(jù)集上訓練了新模型 InstructPix2Pix,并在推理時泛化到真實圖像和用戶編寫的指令上。
InstructPix2Pix 是一個條件擴散模型,給定一個輸入圖像和一個編輯圖像的文本指令,它就能生成編輯后的圖像。該模型直接在前向傳播(forward pass)中執(zhí)行圖像編輯,不需要任何額外的示例圖像、輸入 / 輸出圖像的完整描述或每個示例的微調(diào),因此該模型僅需幾秒就能快速編輯圖像。
盡管 InstructPix2Pix 完全是在合成示例(即 GPT-3 生成的文本描述和 Stable Diffusion 生成的圖像)上進行訓練的,但該模型實現(xiàn)了對任意真實圖像和人類編寫文本的零樣本泛化。該模型支持直觀的圖像編輯,包括替換對象、更改圖像風格等等。

方法概覽
研究者將基于指令的圖像編輯視為一個監(jiān)督學習問題:首先,他們生成了一個包含文本編輯指令和編輯前后圖像的成對訓練數(shù)據(jù)集(圖 2a-c),然后在這個生成的數(shù)據(jù)集上訓練了一個圖像編輯擴散模型(圖 2d)。盡管訓練時使用的是生成的圖像和編輯指令,但模型仍然能夠使用人工編寫的任意指令來編輯真實的圖像。下圖 2 是方法概述。

生成一個多模態(tài)訓練數(shù)據(jù)集
在數(shù)據(jù)集生成階段,研究者結(jié)合了一個大型語言模型(GPT-3)和一個文本轉(zhuǎn)圖像模型(Stable Diffusion)的能力,生成了一個包含文本編輯指令和編輯前后對應(yīng)圖像的多模態(tài)訓練數(shù)據(jù)集。這一過程包含以下步驟:
微調(diào) GPT-3 以生成文本編輯內(nèi)容集合:給定一個描述圖像的 prompt,生成一個描述要進行的更改的文本指令和一個描述更改后圖像的 prompt(圖 2a);
使用文本轉(zhuǎn)圖像模型將兩個文本 prompt(即編輯之前和編輯之后)轉(zhuǎn)換為一對對應(yīng)的圖像(圖 2b)。
InstructPix2Pix
研究者使用生成的訓練數(shù)據(jù)來訓練一個條件擴散模型,該模型基于 Stable Diffusion 模型,可以根據(jù)書面指令編輯圖像。
擴散模型學習通過一系列估計數(shù)據(jù)分布分數(shù)(指向高密度數(shù)據(jù)的方向)的去噪自編碼器來生成數(shù)據(jù)樣本。Latent diffusion 通過在預(yù)訓練的具有編碼器 和解碼器
和解碼器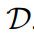 的變分自編碼器的潛空間中操作來提高擴散模型的效率和質(zhì)量。
的變分自編碼器的潛空間中操作來提高擴散模型的效率和質(zhì)量。
對于一個圖像 x,擴散過程向編碼的 latent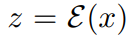 中添加噪聲,它產(chǎn)生一個有噪聲的 latent z_t,其中噪聲水平隨時間步 t∈T 而增加。研究者學習一個網(wǎng)絡(luò)
中添加噪聲,它產(chǎn)生一個有噪聲的 latent z_t,其中噪聲水平隨時間步 t∈T 而增加。研究者學習一個網(wǎng)絡(luò)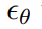 ,它在給定圖像調(diào)節(jié) C_I 和文本指令調(diào)節(jié) C_T 的情況下,預(yù)測添加到帶噪 latent z_t 中的噪聲。研究者將以下 latent 擴散目標最小化:
,它在給定圖像調(diào)節(jié) C_I 和文本指令調(diào)節(jié) C_T 的情況下,預(yù)測添加到帶噪 latent z_t 中的噪聲。研究者將以下 latent 擴散目標最小化:
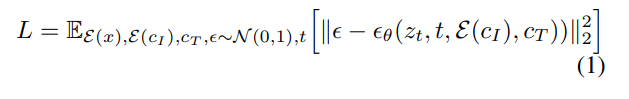
此前,曾有研究(Wang et al.)表明,對于圖像翻譯(image translation)任務(wù),尤其是在成對訓練數(shù)據(jù)有限的情況下,微調(diào)大型圖像擴散模型優(yōu)于從頭訓練。因此在新研究中,作者使用預(yù)訓練的 Stable Diffusion checkpoint 初始化模型的權(quán)重,利用其強大的文本到圖像生成能力。
為了支持圖像調(diào)節(jié),研究人員向第一個卷積層添加額外的輸入通道,連接 z_t 和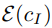 。擴散模型的所有可用權(quán)重都從預(yù)訓練的 checkpoint 初始化,同時在新添加的輸入通道上運行的權(quán)重被初始化為零。作者在這里重用最初用于 caption 的相同的文本調(diào)節(jié)機制,而沒有將文本編輯指令 c_T 作為輸入。
。擴散模型的所有可用權(quán)重都從預(yù)訓練的 checkpoint 初始化,同時在新添加的輸入通道上運行的權(quán)重被初始化為零。作者在這里重用最初用于 caption 的相同的文本調(diào)節(jié)機制,而沒有將文本編輯指令 c_T 作為輸入。
實驗結(jié)果
在下面這些圖中,作者展示了他們新模型的圖像編輯結(jié)果。這些結(jié)果針對一組不同的真實照片和藝術(shù)品。新模型成功地執(zhí)行了許多具有挑戰(zhàn)性的編輯,包括替換對象、改變季節(jié)和天氣、替換背景、修改材料屬性、轉(zhuǎn)換藝術(shù)媒介等等。




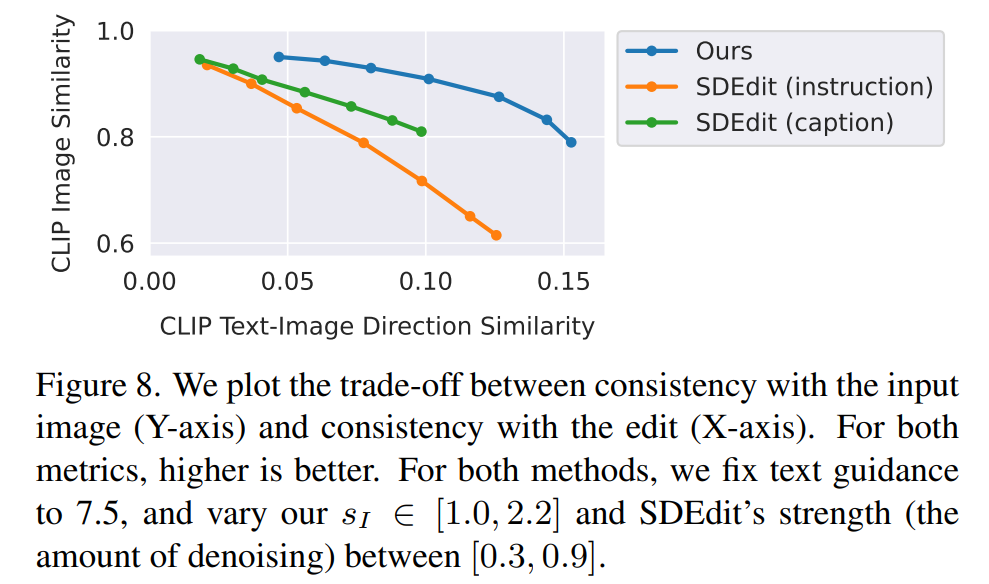
研究人員將新方法與最近的一些技術(shù),如 SDEdit、Text2Live 等進行了比較。新模型遵循編輯圖像的說明,而其他方法(包括基準方法)需要對圖像或編輯層進行描述。因此在比較時,作者對后者提供「編輯后」的文本標注代替編輯說明。作者還把新方法和 SDEdit 進行定量比較,使用兩個衡量圖像一致性和編輯質(zhì)量的指標。最后,作者展示了生成訓練數(shù)據(jù)的大小和質(zhì)量如何影響模型性能的消融結(jié)果。

審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41132 -
AI
+關(guān)注
關(guān)注
88文章
34781瀏覽量
277150 -
模型
+關(guān)注
關(guān)注
1文章
3504瀏覽量
50208
原文標題:GPT-3、Stable Diffusion一起助攻,讓模型聽懂甲方修圖需求
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
?Diffusion生成式動作引擎技術(shù)解析
使用OpenVINO GenAI和LoRA適配器進行圖像生成
為什么Caffe模型可以直接與OpenVINO?工具套件推斷引擎API一起使用,而無法轉(zhuǎn)換為中間表示 (IR)?
OpenAI即將推出GPT-5模型
AN-166:與Linduino一起飛行中更新

將UCC39002與3個PT4484模塊一起使用

深信服發(fā)布安全GPT4.0數(shù)據(jù)安全大模型
Llama 3 與 GPT-4 比較
英偉達預(yù)測機器人領(lǐng)域或迎“GPT-3時刻”
Jim Fan展望:機器人領(lǐng)域即將迎來GPT-3式突破
Pura 70系列AI修圖大師再上新!小藝AI擴圖開啟魔幻新體驗
普通門電路的輸出端能否連在一起
實操: 如何在AirBox上跑Stable Diffusion 3

OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論