 Merlin HugeCTR 分級參數服務器系列之三——集成到 TensorFlow
Merlin HugeCTR 分級參數服務器系列之三——集成到 TensorFlow
前兩期中我們介紹了 HugeCTR 分級參數服務器 (HPS)的三級存儲結構的設計,相關配置使用,數據后端以及流式在線模型更新方案。本期將為大家介紹如何將 HPS 集成到 TensorFlow 中,從而實現在 TensorFlow 中利用分級存儲來部署包含龐大 Embedding Tables 的模型。
引言
當需要基于 TensorFlow 來部署包含龐大 Embedding Tables 的深度學習模型時,數據科學家和機器學習工程師需要面對以下挑戰:
-
龐大的 Embedding Tables:訓練好的 Embedding Tables 的大小往往達到幾百GB,使用 TensorFlow 原生的 Layers 或 Variable 無法放入 GPU 內存;
-
低延時需求: 在線推理要求 Embedding 查詢的延時要足夠低(幾毫秒級),以保證體驗質量和維持用戶粘度;
-
多 GPU 擴展能力:分布式推理框架需要將多個模型部署在多個 GPU上,每個模型包含一個或多個 Embedding Tables;
-
支持加載為 Pre-trained Embeddings:對于遷移學習等任務,需要支持以 Pre-trained Embeddings 的形式加載龐大的 Embedding Tables。
針對以上挑戰,我們為 HPS 提供了一個面向 TensorFlow 的 Python 定制化插件,以方便用戶將 HPS 集成到 TensorFlow 模型圖中,實現包含龐大 Embedding Tables 的模型的高效部署:
-
HPS 通過使用集群中可用的存儲資源來擴展 GPU 內存,包含 CPU RAM 以及非易失性存儲如 HDD 和 SSD,從而實現龐大 Embedding Tables 的分級存儲,如圖 1 所示;
-
HPS 通過使用 GPU Embedding Cache 來利用 embedding key 的長尾特性,當查詢請求持續不斷涌入時,緩存機制保證 GPU 內存可以自動存儲熱門(高頻訪問)key 的 Embeddings,從而可以提供低延遲的查詢服務;
-
在 GPU 內存,CPU 內存以及 SSD 組成的存儲層級中,HPS 以層級結構化的方式來管理多個模型的 Embedding Tables,實現參數服務器的功能;
-
HPS 的查詢服務通過 Custom TensorFlow Layers 來接入,無論是推理還是類似遷移學習的任務,都可以有效支持。
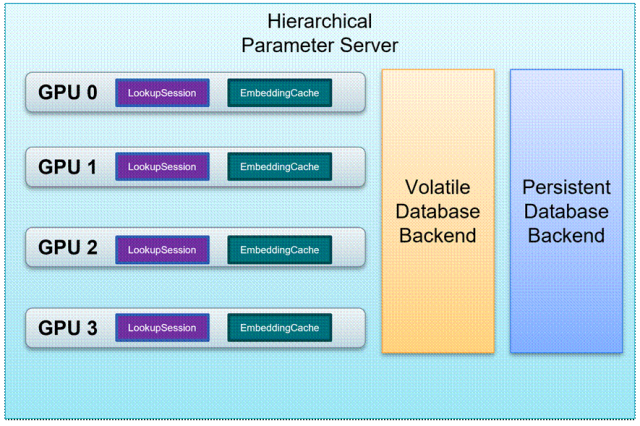
圖 1:HPS 的分級存儲架構
TensorFlow 用戶可以使用我們提供的 Python APIs,輕松利用 HPS 的上述特性,我們將在下文中進一步介紹。
工作流程
利用 HPS 來部署包含龐大 Embedding Tables 的 TensorFlow 模型的工作流程如圖 2 所示:
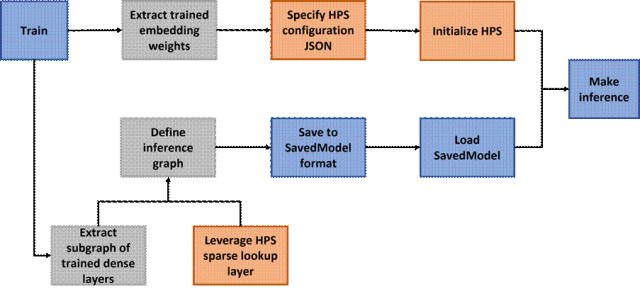
圖 2:利用 HPS 部署 TensorFlow 模型的工作流程
流程中的步驟可以總結如下:
-
訓練階段:用戶可以用原生的 TensorFlow Embedding Layers(例如 tf.nn.embedding_lookup_sparse)或者支持模型并行的 SOK[1] Embedding Layers(例如 sok.DistributedEmbedding)來搭建模型圖并進行訓練。只要模型可以用 TensorFlow 進行訓練,則無論密集層以及模型圖的拓撲結構如何,HPS 都可以在推理階段集成進來。
-
分解訓練的模型圖:用戶需要從訓練的模型圖中提取由密集層組成的子圖,并將其單獨保存下來。至于訓練好的 Embedding Weights,如果使用的是原生 TensorFlow Embedding Layers,則需要提取 Embedding Weights 并將其轉換成 HPS 支持的格式;如果使用的是 SOK Embedding Layers,可以利用 sok.Saver.dump_to_file 來直接得到所需的格式。HPS 的格式要求為:每個 Embedding Table 都被保存在一個文件夾中,包含兩個二進制文件,key (int64)和 emb_vector(float32)。舉例來說,如果一共有 1000 個訓練好的鍵值對,并且 embedding vector 的長度是 16,那么 key 文件和 emb_vector 文件的大小分別為 1000*8 bytes 和 1000*16*4 bytes。
-
搭建并保存推理圖:推理圖由 HPS Layers(如 hps.SparseLookupLayer)和保存好的密集層子圖搭建而成。只需將訓練圖中的 Embedding Layer 用 HPS Layers 加以替換,便可以得到推理圖。該推理圖保存后便可在生產環境中部署。
-
部署推理圖:為了利用 HPS,用戶需要提供一個 JSON 文件,來指定待部署模型的配置信息,用以啟動 HPS 查詢服務。接下來便可以部署保存好的推理圖來執行在線推理任務,在此過程中有效地利用 HPS Embedding 查詢的優化設計。關于配置信息的更多細節,請參考 HPS Configuration[2]。
API
HPS 提供了簡潔易用的 Python API,可以與 TensorFlow 無縫地銜接。用戶只需幾行代碼,便可以啟動 HPS 查詢服務以及將 HPS 集成到 TensorFlow 模型圖中。
-
hierarchical_parameter_server.Init:該方法用來針對待部署的模型啟動 HPS 查詢服務,需要在執行推理任務前被調用一次。必須提供的參數為:
-
global_batch_size:整型,待部署模型的全局批大小。例如模型部署在 4 個 GPUs 上,每個 GPU 上批大小為 4096,則全局批大小為 16384
-
ps_config_file:字符串,HPS 初始化所需的 JSON 配置文件
該方法支持顯式調用或隱式調用。顯式調用用于基于 Python 腳本的測試工作;隱式調用則用于在生產環境中部署模型,要求待部署的推理模型中的 hps.SparseLookupLayer 或 hps.LookupLayer 指定好 global_batch_size 和 ps_config_file,當模型首次接收到推理請求時,會以 call_once 且線程安全的方式觸發 HPS 的初始化
-
hierarchical_parameter_server.SparseLookupLayer:繼承自 tf.keras.layers.Layer,通過指定模型名和 table id 訂閱到 HPS 查詢服務。該層執行與 tf.nn.embedding_lookup_sparse 基本相同的功能。構造時必須提供的參數為:
-
model_name:字符串,HPS 部署的模型名
-
table_id:整型,指定的 model_name 的 Embedding Tables 的索引
-
emb_vec_size:整型,指定的 model_name 和 table_id 的 Embedding Vector 的長度
-
emb_vec_dtype:返回的 Embedding Vector 的數據類型,目前只支持為 tf.float32
-
ps_config_file:字符串,HPS 隱式初始化所需的 JSON 配置文件
-
global_batch_size:整型,待部署模型的全局批大小
執行時的輸入和返回值為:
-
sp_ids:輸入,int64 類型的 id 的 N x M SparseTensor,其中 N 通常是批次大小,M 是任意的
-
sp_weights:輸入,可以是具有 float/double weight 的 SparseTensor,或者是 None 以表示所有 weight 應為 1。如果指定,則 sp_weights 必須具有與 sp_ids 完全相同的 shape 和 indice
-
combiner:輸入,指定 reduction 操作的字符串。目前支持“mean”,“sqrtn”和“sum”
-
max_norm:輸入,如果提供,則在 combine 之前將每個 embedding 規范化為具有等于 max_norm 的 l2 范數
-
emb_vector: 返回值,表示 combined embedding 的密集張量。對于由 sp_ids 表示的密集張量中的每一行,通過 HPS 來查找該行中所有 id 的 embedding,將它們乘以相應的 weight,并按指定的方式組合這些 embedding
-
hierarchical_parameter_server.LookupLayer:繼承自 tf.keras.layers.Layer,通過指定模型名和 table id 訂閱到 HPS 查詢服務。該層執行與 tf.nn.embedding_lookup 基本相同的功能。構造時的參數與 hierarchical_parameter_server.SparseLookupLayer 相同。執行時的輸入和返回值為:
-
inputs:輸入,保存在 Tensor 中的鍵。數據類型必須為 tf.int64
-
emb_vector: 返回值,查詢到的 Embedding Vector。數據類型為 tf.float32
部署方案
按照圖 2 的工作流程得到集成了 HPS 的推理模型后,用戶可以根據生產環境選擇多種部署方案:
-
Triton TensorFlow backend[3]:Triton 推理服務器是開源推理服務軟件,可簡化 AI 推理流程,支持部署不同深度學習框架的推理模型。集成了 HPS 的 TensorFlow 推理模型可以基于 Triton TensorFlow backend 進行部署,只需將 HPS 的 embedding lookup 視作 custom op,并在啟動 tritonserver 前用 LD_PRELOAD 將其 shared library 加載到 Triton 即可
-
TensorFlow Serving[4]:集成了 HPS 的 TensorFlow 推理模型也可方便地部署在 TensorFlow Serving 這一靈活高性能的推理服務系統上,HPS 的 embedding lookup 同樣可作為 custom op 被加載到 TensorFlow Serving中
如果用戶希望進一步對集成了 HPS 的推理模型中的密集網絡層進行優化,還可以使用 tensorflow.python.compiler.tensorrt.trt_convert 對 SavedModel 進行轉換,HPS 的 embedding lookup 可自動 fallback 到其 TensorFlow plugin 對應的 kernels,而可被優化的密集網絡層則會生成 TensorRT engine 來執行。轉換后的 SavedModel 仍然可以使用 Triton TensorFlow backend 或 TensorFlow Serving 進行部署。
除了使用 HPS 的 TensorFlow plugin 外,用戶還可使用 Triton HPS backend[5]。利用 Triton Ensemble Model[6],用戶可以方便地將 HPS backend 和其他 Triton backend 連接起來,搭建出 HPS 用于 embedding lookup、其他 backend 用于密集網絡層前向傳播的推理服務流水線。使用該方案來部署模型的工作流程如圖 3 所示:
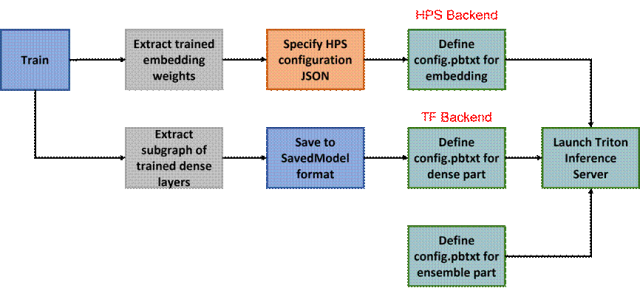
圖 3:利用 Triton Emsemble Model 部署模型的工作流程
這里密集網絡層部分除了可以使用 TensorFlow backend 進行部署外,還可以使用 TensorRT backend 進行部署,此時需要將密集網絡層的 SavedModel 通過 TensorFlow->ONNX->TensorRT 的轉化,得到性能優化的 TensorRT engine。
結語
在這一期的 HugeCTR 分級參數服務器文章中,我們介紹了使用 HPS 部署包含龐大 Embedding Tables 的 TensorFlow 模型的解決方案,工作流程以及 API。更多信息,請參考 HPS 官方文檔:
https://nvidia-merlin.github.io/HugeCTR/master/hierarchical_parameter_server/index.html
在下一期中,我們將著重介紹 HugeCTR 分級參數服務器中最關鍵的組件:Embedding Cache 的設計細節,敬請期待。
以下是 HugeCTR 的 Github repo 以及其他發布的文章,歡迎感興趣的朋友閱讀和反饋。Github:
https://github.com/NVIDIA-Merlin/HugeCTR (更多文章詳見 README)
[1]SOK
https://nvidia-merlin.github.io/HugeCTR/sparse_operation_kit/master/index.html
[2]HPS Configuration
https://nvidia-merlin.github.io/HugeCTR/master/hugectr_parameter_server.html#configuration
[3]Triton TensorFlow backend
https://github.com/triton-inference-server/tensorflow_backend
[4]TensorFlow Serving
https://github.com/tensorflow/serving
[5]Triton HPS backend
https://github.com/triton-inference-server/hugectr_backend/tree/main/hps_backend
[6]Triton Ensemble Model
https://github.com/triton-inference-server/server/blob/main/docs/user_guide/architecture.md#ensemble-models
點擊查看關于 HugeCTR 分級參數服務器的更多內容
????Merlin HugeCTR 分級參數服務器簡介
?
Merlin HugeCTR 分級參數服務器簡介之二
原文標題:Merlin HugeCTR 分級參數服務器系列之三——集成到 TensorFlow
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3926瀏覽量
93209
原文標題:Merlin HugeCTR 分級參數服務器系列之三——集成到 TensorFlow
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄




如何選擇 邊緣計算服務器




ftp服務器怎么搭建
雙北斗校時服務器、雙北斗授時服務器、雙北斗對時服務器、雙北斗NTP服務器

使用API連接SMTP服務器的方法
獨立服務器與云服務器的區別

SOK在手機行業的應用案例





 工商網監
工商網監
評論