") 如何使用CLM自身的embedding來(lái)得到OOD score?
如何使用CLM自身的embedding來(lái)得到OOD score?

背景
OOD現(xiàn)象和OOD檢測(cè)在分類任務(wù)中已經(jīng)被廣泛研究:
OOD score:maximum softmax probability(MSP),K個(gè)類別中最大的概率來(lái)作為衡量OOD的指標(biāo)
selective classification:對(duì)于OOD score太低的輸入,模型拒絕輸出
在conditional language model(CLM)任務(wù)(主要是summarization,translation)中,而由于language generation主要是通過(guò)auto-regressive的方式,錯(cuò)誤更容易積累,因此OOD問(wèn)題可能更嚴(yán)重。
本文的主要貢獻(xiàn):
提出一中輕量的、準(zhǔn)確的基于CLM的embedding的OOD檢測(cè)方法
發(fā)現(xiàn)perplexity(ppx)不適合作為OOD檢測(cè)和文本生成質(zhì)量評(píng)估的指標(biāo)
提出了一套用于OOD檢測(cè)和selective generation的評(píng)測(cè)框架
CLM中的OOD detection
如果直接套用classification任務(wù)中使用MSP作為OOD score的話,那么對(duì)于NLG問(wèn)題我們就應(yīng)該采用perplexity(ppx),然而作者實(shí)驗(yàn)發(fā)現(xiàn)使用ppx的效果很不好:

從上圖可以看到,不用domain來(lái)源的數(shù)據(jù),其ppx的分布重疊程度很高;甚至有些明明是OOD的數(shù)據(jù),但其綜合的ppx比ID的數(shù)據(jù)還要低。因此ppx對(duì)ID vs OOD的區(qū)分能力很差。
如何使用CLM自身的embedding來(lái)得到OOD score?
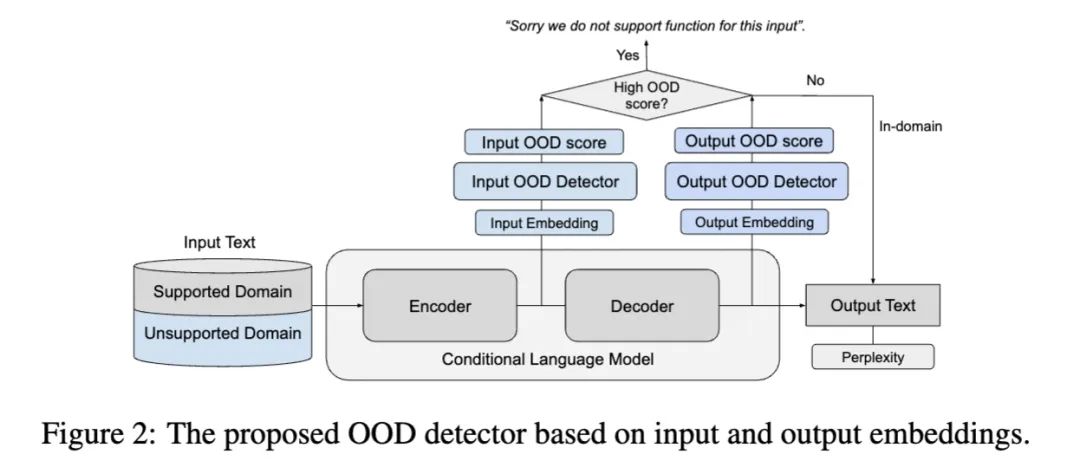
input embedding: encoder最后一層所有hidden states平均
output embedding: decoder最后一層所有hidden states平均(ground truth對(duì)應(yīng)的位置)
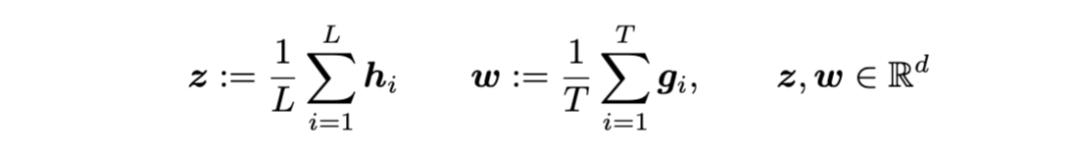
1. 使用兩個(gè)分布的距離來(lái)判斷——RMD score
直覺(jué)上講,當(dāng)一個(gè)樣本的輸入/輸出的embedding跟我訓(xùn)練樣本的embedding分布距離很遠(yuǎn)的話,就很可能是OOD樣本。
因此,可以先用訓(xùn)練數(shù)據(jù)集,對(duì)輸入和輸出空間擬合一個(gè)embedding的高斯分布:
input embedding distribution:
output embedding distribution:
然后,就可以使用馬氏距離(Mahalanobis distance,MD)來(lái)衡量新來(lái)的embedding跟訓(xùn)練集embedding的距離:
馬氏距離是基于樣本分布的一種距離。物理意義就是在規(guī)范化的主成分空間中的歐氏距離。(維基百科)
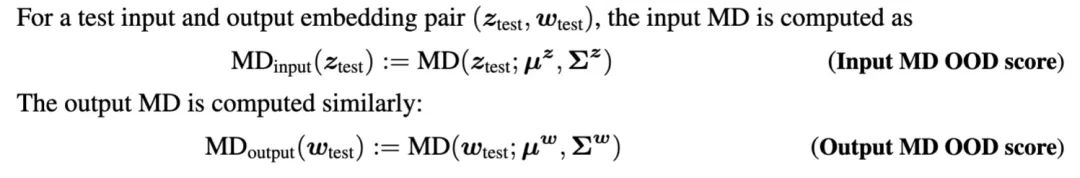
然而,已有一些研究表明,使用相對(duì)馬氏距離(即增加一個(gè)background distribution來(lái)作為一個(gè)參照),可以更好地進(jìn)行OOD檢測(cè)。于是對(duì)上述公式改進(jìn)為:
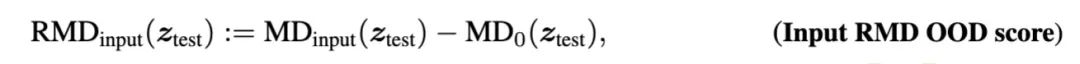
其中是衡量test input跟一個(gè)background高斯分布的距離,這個(gè)background分布,是使用一個(gè)通用語(yǔ)料擬合出來(lái)的,比方使用C4語(yǔ)料庫(kù)。
而對(duì)于CLM這種需要成對(duì)語(yǔ)料的任務(wù),通用語(yǔ)料中一般是沒(méi)有的,所以使用通用文本通過(guò)CLM decode出來(lái)的 outputs來(lái)擬合分布:
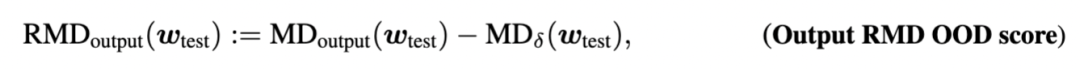
這樣一來(lái),RMD scores實(shí)際上可能為正也可能為負(fù):
當(dāng)RMD score < 0 時(shí),說(shuō)明 test example跟training distribution更接近
當(dāng)RMD score > 0 時(shí),說(shuō)明 test example跟background更接近,因此更有可能是OOD的
因此,RMD score可以直接作為OOD detection的指標(biāo)。
2. 基于embedding訓(xùn)練一個(gè)detector
上面是一種無(wú)監(jiān)督的辦法,作者還提出了一種有監(jiān)督的辦法,使用training samples和general samples作為兩個(gè)類別的數(shù)據(jù),使用embedding作為feature來(lái)訓(xùn)練一個(gè)logistic regressive model,使用background類的logits作為OOD score:
Input Binary logits OOD score
Output Binary logits OOD score
3. OOD detection實(shí)驗(yàn)
以summarization為例,實(shí)驗(yàn)所用數(shù)據(jù)為:
In-domain:10000條 xsum 樣本
General samples:10000條 C4 樣本
OOD datasets:near-OOD數(shù)據(jù)集(cnn dailymail,newsroom)和far-OOD數(shù)據(jù)集(reddit tifu,forumsum,samsum)
OOD detection衡量指標(biāo):area under the ROC curve (AUROC)
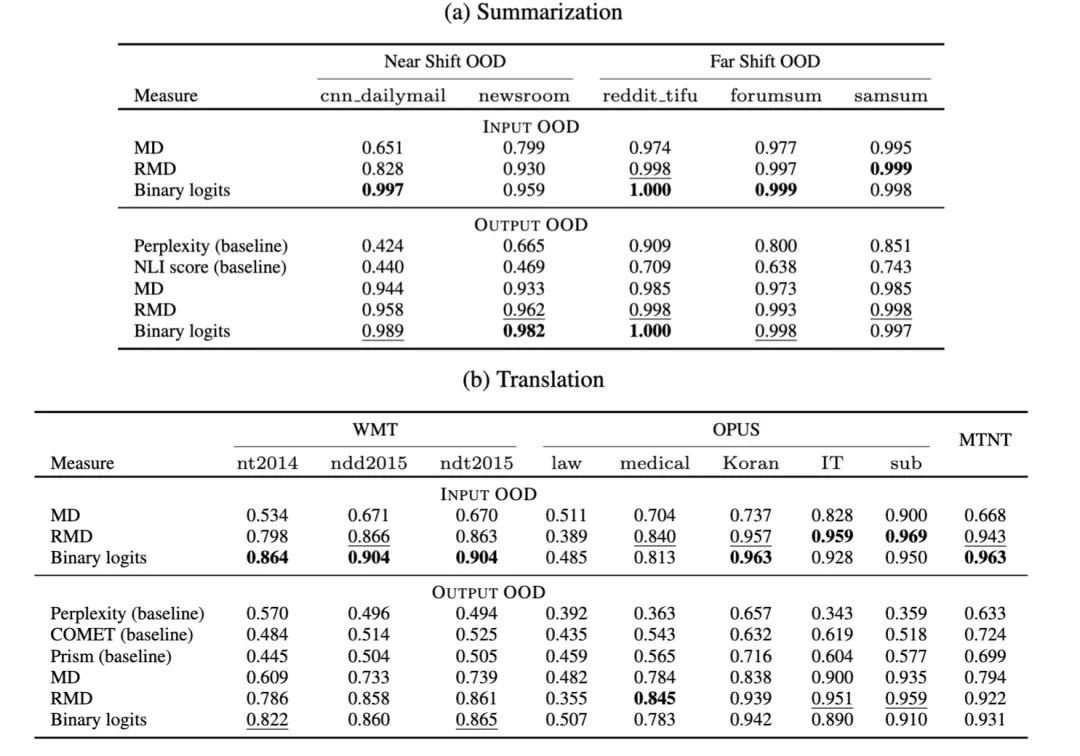
實(shí)驗(yàn)結(jié)論:
本文提出的RMD和Binary classifier都比baseline有更好的OOD檢測(cè)能力
能更好地對(duì)near-OOD這種hard cases進(jìn)行檢測(cè)
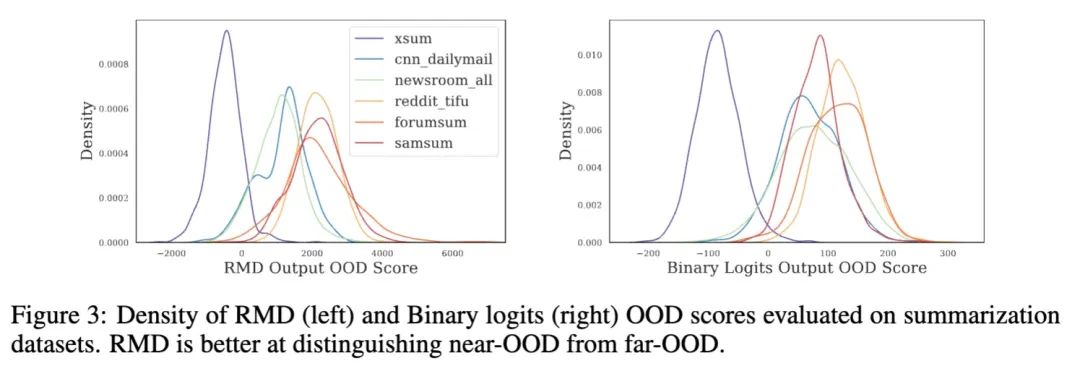
Selective Generation
當(dāng)檢測(cè)到OOD時(shí),一個(gè)最保守的做法就是直接拒絕給出輸出,從而避免潛在的風(fēng)險(xiǎn)。但是,我們依然希望當(dāng)模型的輸出質(zhì)量足夠高時(shí),即使是OOD也能輸出。
當(dāng)有參考答案時(shí),如何衡量輸出文本的質(zhì)量?
對(duì)于translation問(wèn)題,使用BLEURT作為衡量指標(biāo);
對(duì)于summarization,常見是使用ROUGE score,但由于不同數(shù)據(jù)集的摘要模式差別很大,所以只使用ROUGE還不夠,作者使用亞馬遜眾籌平臺(tái)來(lái)對(duì)一批數(shù)據(jù)進(jìn)行人工質(zhì)量打標(biāo)。
能否找到一個(gè)指標(biāo),不需要參考答案也能衡量文本質(zhì)量?
實(shí)驗(yàn)發(fā)現(xiàn),對(duì)于in-domain數(shù)據(jù),ppx跟質(zhì)量有比較好的相關(guān)性,但是對(duì)于OOD數(shù)據(jù),相關(guān)性很差。
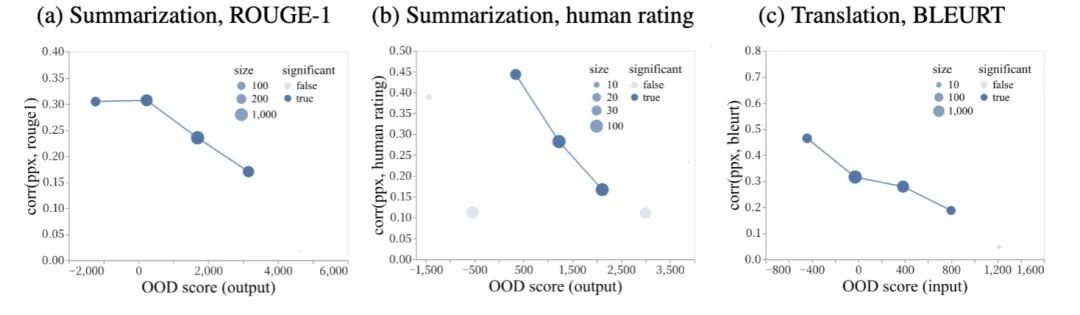
但是OOD score可以跟ppx互相補(bǔ)充,從而形成一個(gè)比較好的對(duì)應(yīng)指標(biāo):
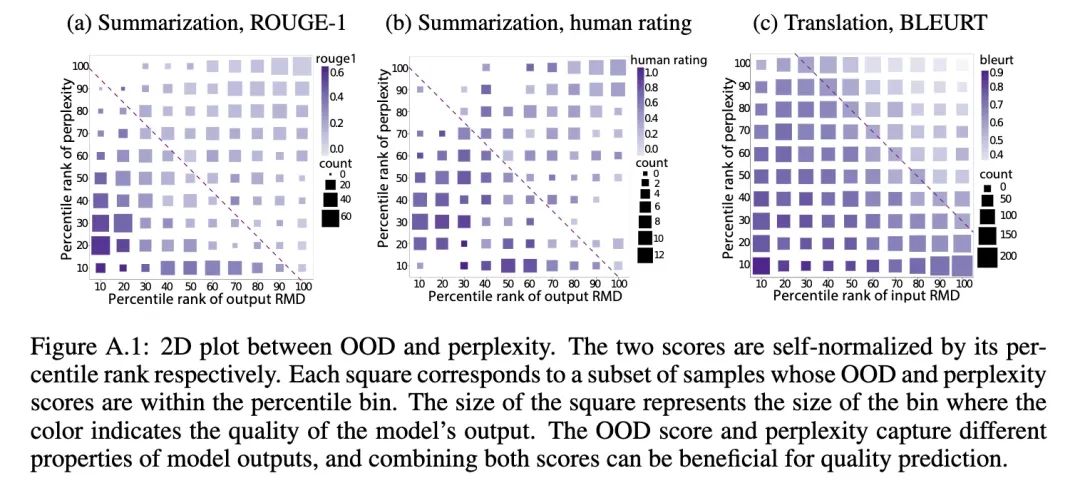
單獨(dú)只考察ppx或者RMD OOD score的話,難以區(qū)分質(zhì)量的高低,但是同時(shí)考察二者,就有較高的區(qū)分度。究其原因,作者這么解釋:
ppx反映的是由于內(nèi)部噪音/模糊造成的的不確定性
RMD score反映的是由于缺乏訓(xùn)練數(shù)據(jù)所造成的不確定性
因此二者是互補(bǔ)的關(guān)系。
那么二者如何結(jié)合呢:
訓(xùn)練一個(gè)linear regression
或者直接使用二者的某種“和”:,其中PR代表percentile ranks
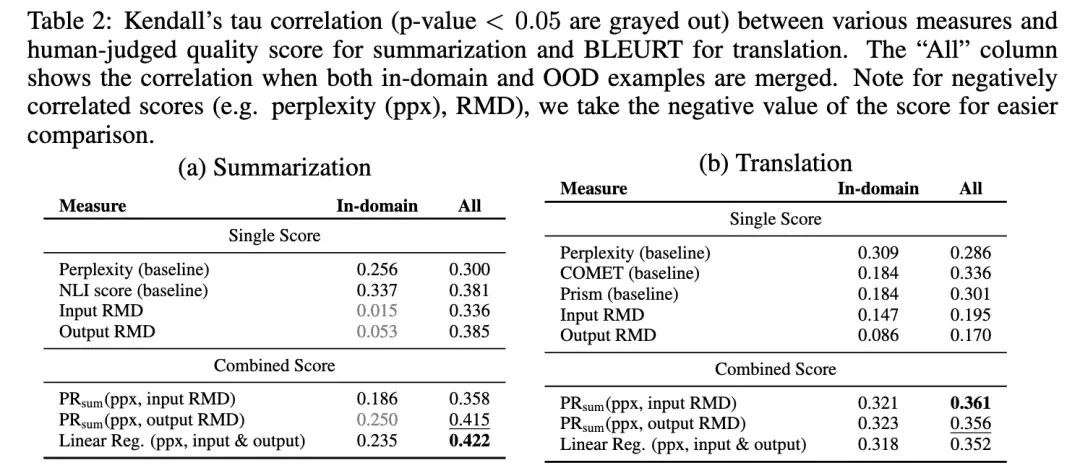
可以看出,這種二者結(jié)合的方法,比各種只用單個(gè)指標(biāo)的baselines都能更好地反映生成的質(zhì)量。
在selective generation階段,設(shè)定一個(gè)遺棄比例,然后把quality score最低的那部分丟棄。
Key takeaways:
在生成模型中,ppx無(wú)論是作為OOD detection還是quality evaluation都是不太好的選擇
基于模型的extracted feature來(lái)做OOD detection更好,文中的RMD score就是一個(gè)例子。
審核編輯:劉清
-
msp
+關(guān)注
關(guān)注
0文章
162瀏覽量
35729
原文標(biāo)題:CMU&Google提出:條件語(yǔ)言模型中的OOD檢測(cè)與選擇性生成
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
求助,關(guān)于muRata 2GF在定制電路板上的集成問(wèn)題求解
ADS1298 FE PDK套件測(cè)ECG信號(hào)求助
如何通過(guò)電源濾波器的優(yōu)化設(shè)計(jì)來(lái)降低其自身的能耗?

如何選擇適合自身需求的貼片電阻?

AD的參數(shù)INL,是不是說(shuō)對(duì)于同一個(gè)輸入電壓,每一次采樣出來(lái)得出的數(shù)字結(jié)果會(huì)差3LSB?
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+Embedding技術(shù)解讀
激光自身空間維度加工系統(tǒng)綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論