") 李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜

【導(dǎo)讀】2022年有哪些人工智能的突破?今天,李飛飛高徒Jim Fan盤點了年度十大AI亮點。
人工智能的爆炸正在扭曲我們的時間感。
你能相信Stable Diffusion只有4個月大,而ChatGPT的出現(xiàn)還不到一個月嗎?
打個形象的比喻,只要眨一下眼,你就會錯過一個全新的行業(yè)。2022年的AI領(lǐng)域,大規(guī)模的生成模型像雨后春筍一樣地冒出,改變了整個AI界的格局。
而且,這些模型正在迅速走出實驗室,在現(xiàn)實中被應(yīng)用。
比如,LLM技術(shù)就啟發(fā)了兩個新興的領(lǐng)域——決策代理(游戲、機(jī)器人等等)和 AI4Science。
李飛飛高徒Jim Fan為我們總結(jié)了2022年的十大AI高光時刻。讓我們把時間倒轉(zhuǎn),看看2022年都有哪些令人驚嘆的AI突破。 一、文字-圖像生成
一、文字-圖像生成DALLE-2是第一個可以從任意標(biāo)題生成逼真的高分辨率圖像的大規(guī)模擴(kuò)散模型。
它啟動了AI的藝術(shù)革命,催生了許多新的應(yīng)用程序、初創(chuàng)公司和思維方式。

但 DALLE-2被保護(hù)在OpenAI的圍墻后面,并沒有開源。
在OpenAI之后,LMU的StabilityAI和runwayml邁出了英勇的一步,基于「潛在擴(kuò)散」算法訓(xùn)練了他們自己的互聯(lián)網(wǎng)規(guī)模的text2image模型。他們稱該模型為「穩(wěn)定擴(kuò)散」,并開源了代碼和權(quán)值(weighs)。 事實證明,Stable Diffusion的開放性,讓它給游戲帶來了巨變。現(xiàn)在,許多初創(chuàng)公司和研究實驗室都在Stable Diffusion的基礎(chǔ)上創(chuàng)建新的應(yīng)用程序,Stable Diffusion本身也被開源社區(qū)不斷改進(jìn)。最近,Stable Diffusion已經(jīng)達(dá)到了v2.1版本,可以在單個GPU上運行了。
事實證明,Stable Diffusion的開放性,讓它給游戲帶來了巨變。現(xiàn)在,許多初創(chuàng)公司和研究實驗室都在Stable Diffusion的基礎(chǔ)上創(chuàng)建新的應(yīng)用程序,Stable Diffusion本身也被開源社區(qū)不斷改進(jìn)。最近,Stable Diffusion已經(jīng)達(dá)到了v2.1版本,可以在單個GPU上運行了。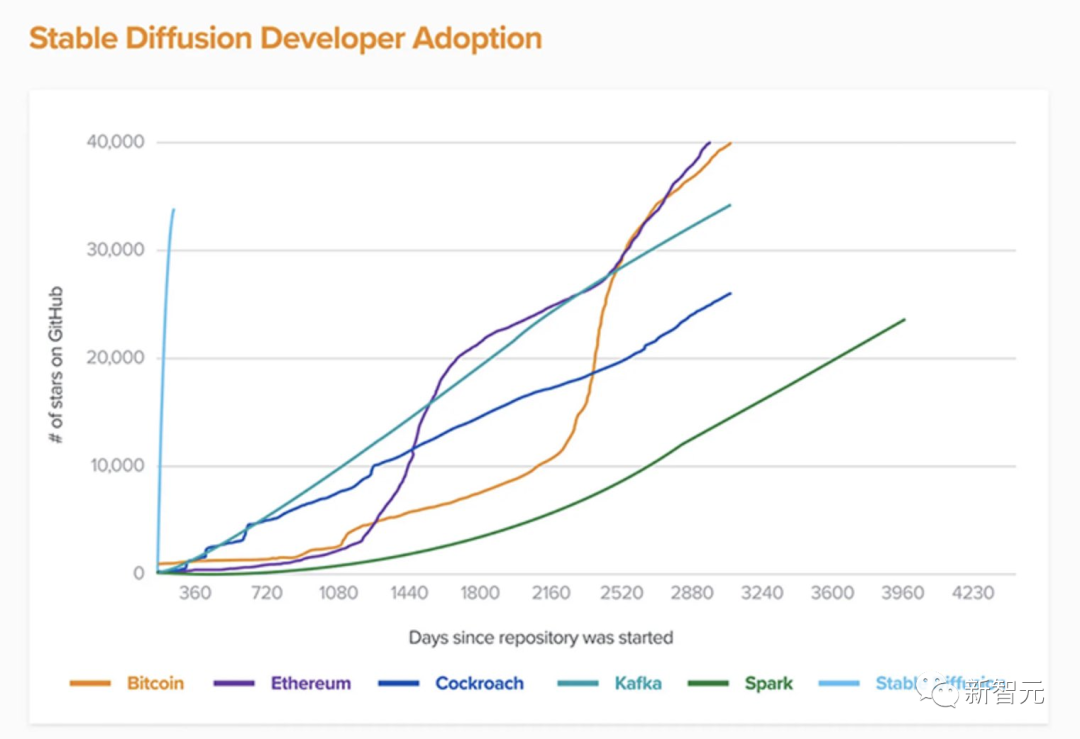
另外,今年還有來自GoogleAI的兩個image2text模型。GoogleAI既沒有發(fā)布模型也沒有發(fā)布API,但從論文中,我們?nèi)匀豢梢钥吹讲簧儆腥さ囊娊狻?/span>
Imagen
https://imagen.research.google

Parti
https://parti.research.google。它是一個沒有diffusion的Transformer模型。

ChatGPT和GPT-3.5都使用了一種叫做RLHF(「從人類反饋中強(qiáng)化學(xué)習(xí)」)的新技術(shù)。
這也就意味著,提示工程或許很快就會消失了。
ChatGPT的流行,已經(jīng)催生了一波新的創(chuàng)業(yè)公司和競爭者,比如Jasper Chat、YouChat、Replit的Ghostwriter chat,以及perplexity_ai。
這些競爭者提供了如此直觀的搜索方式,連谷歌的高管們都開始出汗了! 三、文本- 機(jī)器人模型如何給GPT提供胳膊和腿,讓它們能打掃你混亂的廚房?與NLP不同,機(jī)器人模型需要與物理世界互動。
在今年,大的預(yù)訓(xùn)練Transformer終于開始解決機(jī)器人領(lǐng)域最難的問題了!VIMA
10月,我和同事創(chuàng)建了一個 「機(jī)器人GPT 」——名為VIMA的tranformer。它可以接收任何混合的文本、圖像和視頻作為prompt,并輸出機(jī)器人手臂的控制。我們的模型被稱為VIMA(「VisuoMotor Attention」),已經(jīng)完全開源了。現(xiàn)在,單個智能體已經(jīng)能夠解決視覺目標(biāo)、視頻的一次性模仿、新概念基礎(chǔ)、視覺約束等,具有了模型容量和數(shù)據(jù)的強(qiáng)大擴(kuò)展性。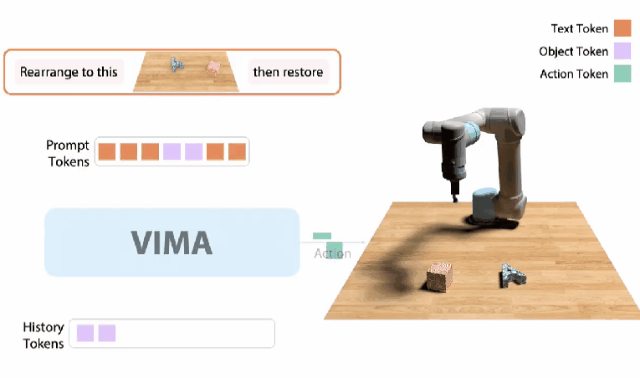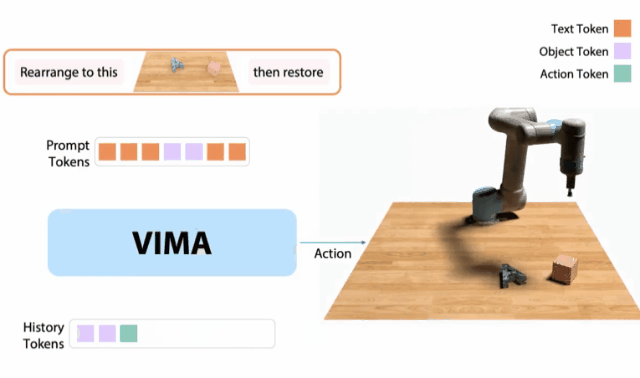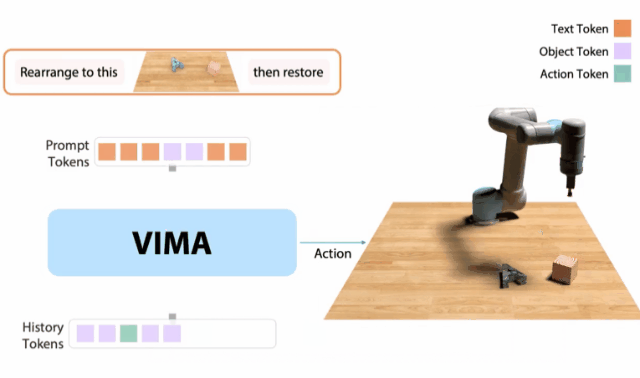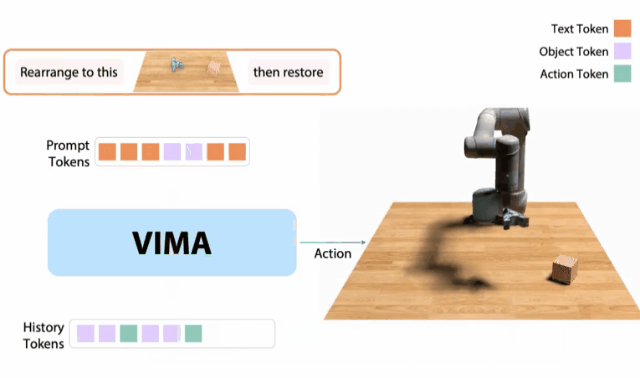
RT-1
沿著與VIMA類似的路徑,來自GoogleAI的研究人員發(fā)布了RT-1,這是一種在700項任務(wù)和130K的人類演示上訓(xùn)練的機(jī)器人transformer。
這些數(shù)據(jù)是由13個機(jī)器人在17個月內(nèi)收集的,是字面意義上的鋼鐵部隊!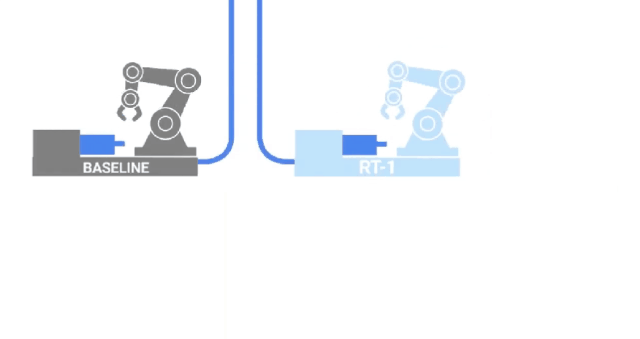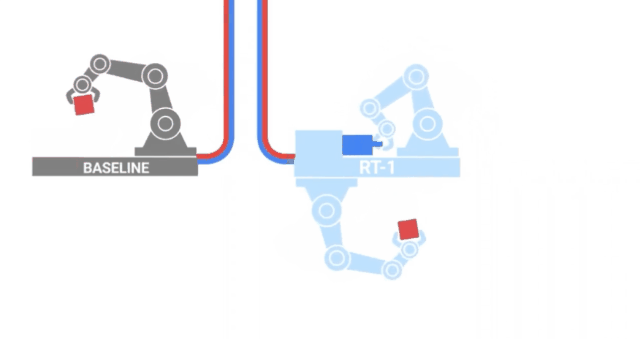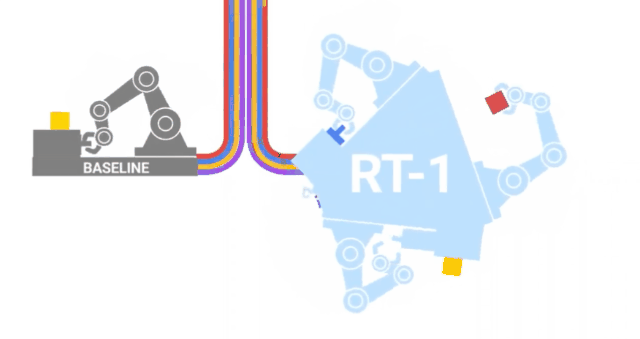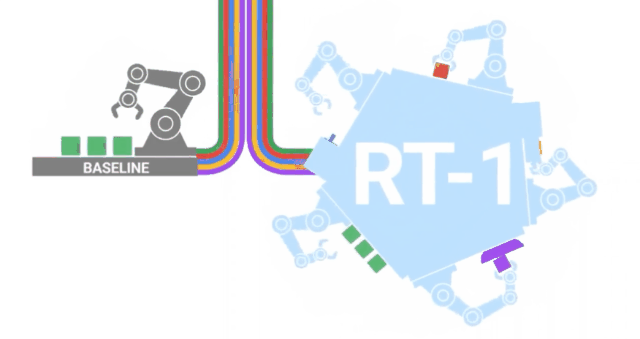 四、文本 - 視頻本質(zhì)上說,視頻就是隨著時間的推移捆綁在一起的一系列圖像,給我們創(chuàng)造了運動的錯覺。
四、文本 - 視頻本質(zhì)上說,視頻就是隨著時間的推移捆綁在一起的一系列圖像,給我們創(chuàng)造了運動的錯覺。如果我們可以做text2image,那為什么不在里面加上時間軸,來獲得額外的樂趣呢?
目前,文本 - 視頻領(lǐng)域有3個重大的工作,但沒有一個是開源的。Make-A-Video
首先是Meta AI的Make-A-Video:不需要成對的文本-視頻數(shù)據(jù),就可以得到文本-視頻的生成。
您可以在此處注冊試用訪問權(quán)限:https://makeavevideo.studio
 論文鏈接:https://arxiv.org/abs/2209.14792
論文鏈接:https://arxiv.org/abs/2209.14792
Imagen Video
Google AI的Imagen Video:它能使用擴(kuò)散模型生成高清視頻,基于Imagen靜態(tài)圖像生成器。
演示:http://imagen.research.google/video/
 論文鏈接:https://arxiv.org/abs/2210.02303
論文鏈接:https://arxiv.org/abs/2210.02303
Phenaki
來自谷歌AI的Phenaki: 從開放領(lǐng)域的文本描述中生成可變長度的視頻。
演示:https://phenaki.video 論文鏈接:https://arxiv.org/abs/2210.02399
論文鏈接:https://arxiv.org/abs/2210.02399 五、文本-3D建模從設(shè)計創(chuàng)新產(chǎn)品到在電影和游戲中創(chuàng)造奇妙的視覺效果,3D建模正成為文本-X生成模型的下一片藍(lán)海。令人驚喜的是,2022年出現(xiàn)了許多卓有前途的3D生成模型。在此,F(xiàn)an列舉了3個模型。
五、文本-3D建模從設(shè)計創(chuàng)新產(chǎn)品到在電影和游戲中創(chuàng)造奇妙的視覺效果,3D建模正成為文本-X生成模型的下一片藍(lán)海。令人驚喜的是,2022年出現(xiàn)了許多卓有前途的3D生成模型。在此,F(xiàn)an列舉了3個模型。DreamFusion
首先登場的,是Google AI研究團(tuán)隊與UC Berkeley聯(lián)合開發(fā)的DreamFusion。
 論文鏈接:https://arxiv.org/pdf/2209.14988.pdf
論文鏈接:https://arxiv.org/pdf/2209.14988.pdf該模型使用二維文本到圖像的擴(kuò)散模型來執(zhí)行文本到三維的合成。
基于NeRF算法,DreamFusion可以通過給定文本生成3D模型。

Magic3D
第二項成果,是英偉達(dá)AI團(tuán)隊的兩個項目,名為GET3D和Magic3D。
 GET3D論文鏈接:https://nv-tlabs.github.io/GET3D/assets/paper.pdf
GET3D論文鏈接:https://nv-tlabs.github.io/GET3D/assets/paper.pdf
Magic3D論文鏈接:https://arxiv.org/pdf/2211.10440.pdf
GET3D僅使用二維圖像進(jìn)行訓(xùn)練,可生成具有高保真紋理和復(fù)雜幾何細(xì)節(jié)的三維圖形。

該模型允許用戶立即將其形體導(dǎo)入3D渲染器和游戲引擎,以便進(jìn)行后續(xù)編輯。
Magic3D與DreamFusion類似,使用文本到圖像模型生成2D圖像,然后優(yōu)化為體積NeRF(神經(jīng)輻射場)數(shù)據(jù),將低分辨率生成的粗略模型優(yōu)化為高分辨率的精細(xì)模型。

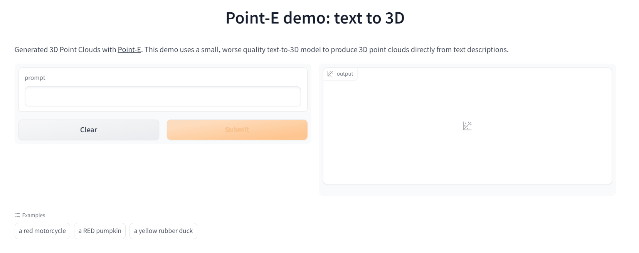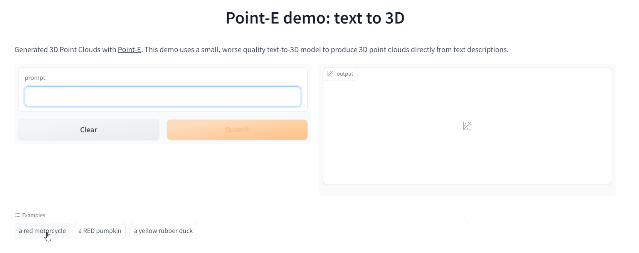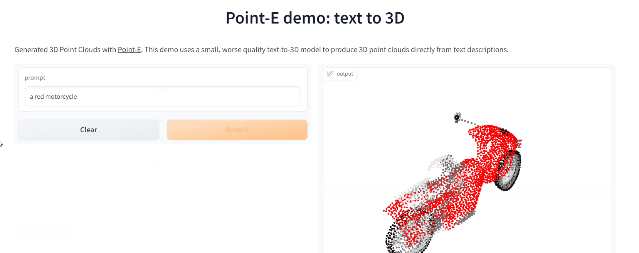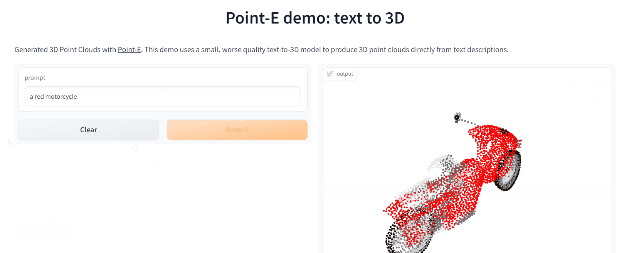
Point-E
繼年初推出的DALL-E 2用天才畫筆驚艷所有人之后,周二OpenAI發(fā)布了最新的圖像生成模型「POINT-E」,它可通過文本直接生成3D模型。

論文鏈接:https://arxiv.org/pdf/2212.08751.pdf
相比競爭對手們(如谷歌的DreamFusion)需要幾個GPU工作數(shù)個小時,POINT-E只需單個GPU便可在幾分鐘內(nèi)生成3D圖像。
《我的世界》是一款測試AI通用智能的絕佳游戲。首先,它是一款無限開放的沙盒游戲,極度體現(xiàn)玩家的創(chuàng)造力。
其次,該游戲有1.4億的玩家群體,是英國總?cè)丝诘膬杀丁S脩艋A(chǔ)如此龐大,供AI學(xué)習(xí)的游戲數(shù)據(jù)可謂是源源不絕。
那么,AI能否和人類一樣盡情揮灑想象力呢?
Jim Fan和同事合作開發(fā)了第一個玩《我的世界》的AI「MineDojo」,它可以在自然語言提示下解決許多任務(wù)。

論文鏈接:https://arxiv.org/pdf/2206.08853.pdf
Fan的最終目標(biāo)是建立一個「具身的ChatGPT」。目前,MineDojo平臺已經(jīng)完全開源。
與此同時,Jeff Clune的團(tuán)隊宣布了一個名為視頻預(yù)訓(xùn)練(VPT)的模型,該模型可以直接輸出鍵盤和鼠標(biāo)的動作。

論文鏈接:https://arxiv.org/pdf/2206.11795.pdf
VPT擁有更廣闊的視野,但不受語言條件的限制。在這點上,MineDojo和VPT恰好相輔相成。 七、AI外交官Meta AI推出的CICERO是第一個在《外交》游戲中實現(xiàn)人類水平表現(xiàn)的人工智能智能體。

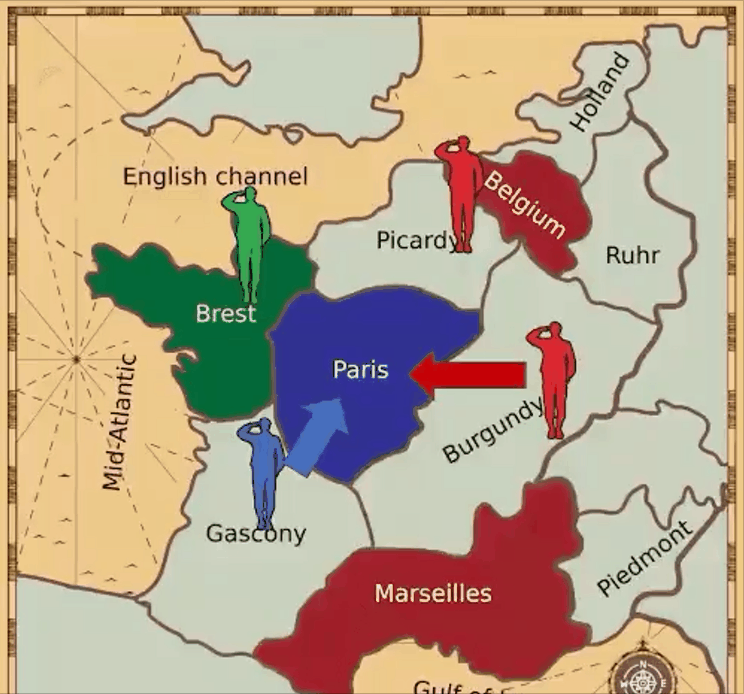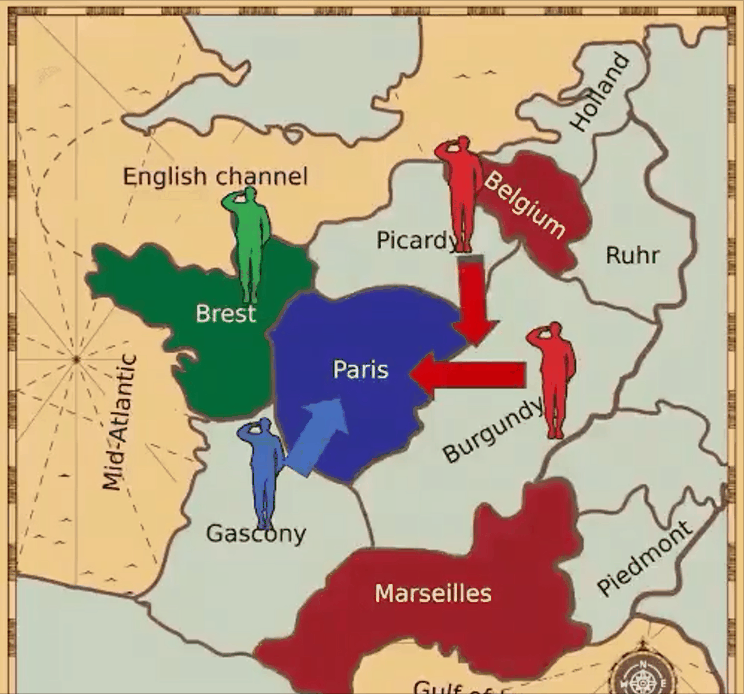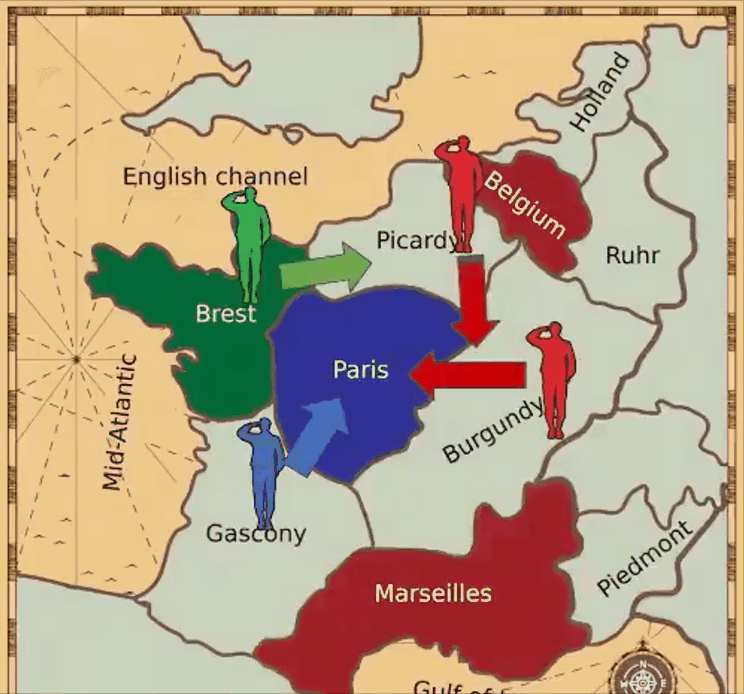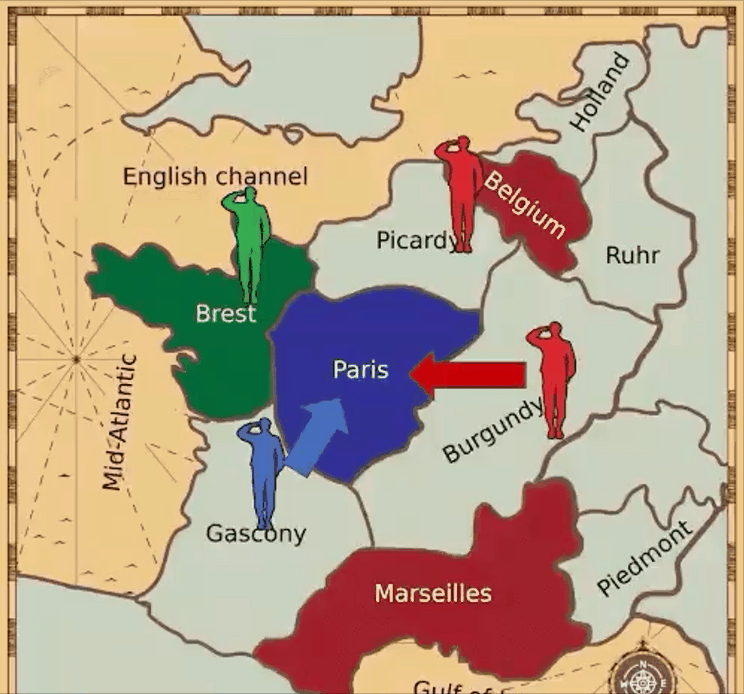

論文鏈接:https://arxiv.org/pdf/2212.04356.pdf
Whisper經(jīng)過了來自網(wǎng)絡(luò)的680,000小時音頻數(shù)據(jù)的訓(xùn)練。Open AI強(qiáng)調(diào),Whisper的語音識別能力已達(dá)到人類水準(zhǔn)。
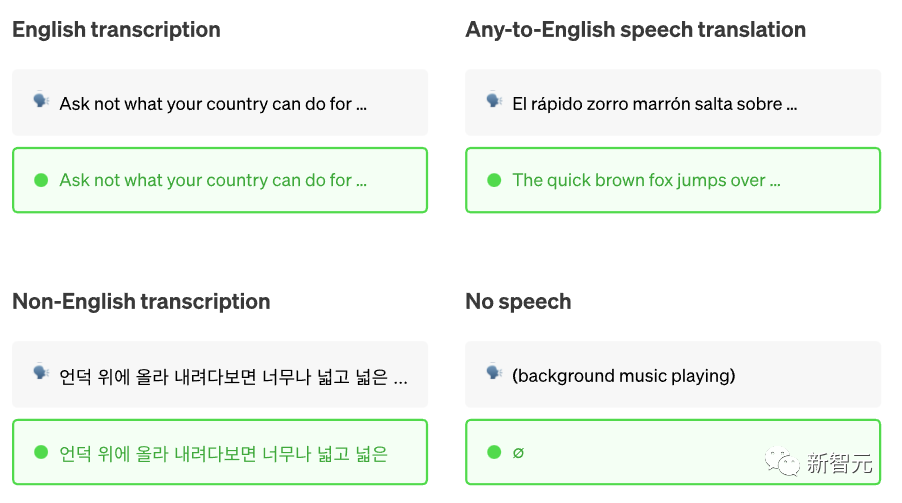

論文鏈接:https://www.nature.com/articles/s41586-021-04301-9
同樣在本月,美國能源部宣布了一項巨大的突破:人類首次實現(xiàn)了核聚變反應(yīng)的凈能量增益!
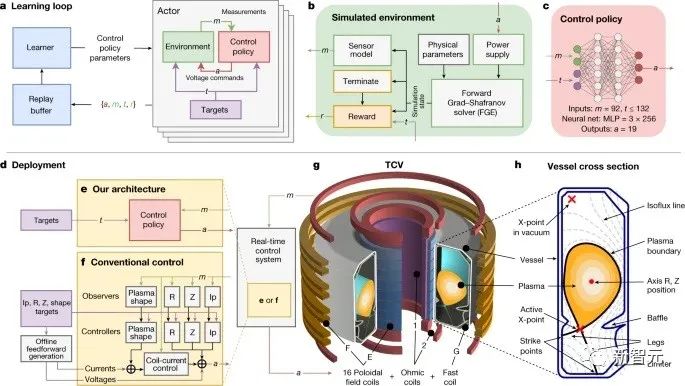
7月,DeepMind宣布了「蛋白質(zhì)宇宙」——將AlphaFold的蛋白質(zhì)數(shù)據(jù)庫擴(kuò)展到2億個結(jié)構(gòu)!
此外,英偉達(dá)AI研究團(tuán)隊還拓展了BioNeMo大型語言模型的框架,以幫助生物技術(shù)公司和研究人員生成、預(yù)測和理解生物分子數(shù)據(jù)。

視頻講解:https://www.youtube.com/watch?v=PWcNlRI00jo&t=4399s
以上便是Jim Fan對2022年十大AI亮點的盤點。當(dāng)然,F(xiàn)an也表示,還有無數(shù)令人興奮的作品為人工智能的進(jìn)步做出了貢獻(xiàn)。每篇論文都是AI大廈里的一磚一瓦,所有的努力都應(yīng)該慶祝。
不過,F(xiàn)an在最后也強(qiáng)調(diào),隨著人工智能系統(tǒng)變得越來越強(qiáng)大,我們必須意識到潛在的危險和風(fēng)險,并采取措施減輕它們。
無論是通過仔細(xì)的培訓(xùn)設(shè)計、適當(dāng)?shù)谋O(jiān)督還是全新的保障方法,人工智能的安全與倫理成為越來越的AI專家所討論的議程。
毫無疑問,2022年是充滿奇跡的一年,也是令人驚嘆的一年。未來一年又會有什么震驚世界的突破?我們與你一起關(guān)注。參考資料:
https://twitter.com/drjimfan/status/1607746957753057280?s=46&t=OVM_4zdRW2rQwqLohMdPpw
END
歡迎加入Imagination GPU與人工智能交流2群 入群請加小編微信:eetrend89
入群請加小編微信:eetrend89(添加請備注公司名和職稱)
推薦閱讀 對話Imagination中國區(qū)董事長:以GPU為支點加強(qiáng)軟硬件協(xié)同,助力數(shù)字化轉(zhuǎn)型ICCAD 2022圓滿落幕,Imagination異構(gòu)計算引領(lǐng)“芯”未來
 Imagination Technologies是一家總部位于英國的公司,致力于研發(fā)芯片和軟件知識產(chǎn)權(quán)(IP),基于Imagination IP的產(chǎn)品已在全球數(shù)十億人的電話、汽車、家庭和工作場所中使用。獲取更多物聯(lián)網(wǎng)、智能穿戴、通信、汽車電子、圖形圖像開發(fā)等前沿技術(shù)信息,歡迎關(guān)注 Imagination Tech!
Imagination Technologies是一家總部位于英國的公司,致力于研發(fā)芯片和軟件知識產(chǎn)權(quán)(IP),基于Imagination IP的產(chǎn)品已在全球數(shù)十億人的電話、汽車、家庭和工作場所中使用。獲取更多物聯(lián)網(wǎng)、智能穿戴、通信、汽車電子、圖形圖像開發(fā)等前沿技術(shù)信息,歡迎關(guān)注 Imagination Tech!
原文標(biāo)題:李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
文章出處:【微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
imagination
+關(guān)注
關(guān)注
1文章
599瀏覽量
62181 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1589瀏覽量
9036
原文標(biāo)題:李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
2024年存儲行業(yè)十大事件盤點

人造太陽再升級!中國核聚變實現(xiàn)「雙億度」突破

核聚變商用加速丨電源控制系統(tǒng)國產(chǎn)化解決方案
托卡馬克裝置:探索可控核聚變的前沿利器
托卡馬克裝置:探索可控核聚變的前沿利器

兆芯KX-7000榮獲2024年度十大信創(chuàng)CPU產(chǎn)品
年度電解槽十大品牌+年度制氫十大供應(yīng)商,穩(wěn)石氫能榮獲兩大獎項!
東軟三家客戶入選2024年度推進(jìn)醫(yī)改服務(wù)百姓健康十大新舉措
比亞迪海豹榮獲日本年度風(fēng)云車十大最佳車型獎
敦泰榮獲車載顯示年度十大知名品牌
全國產(chǎn)PSM高壓電源控制系統(tǒng),助力核聚變技術(shù)發(fā)展
可控核聚變解決方案
解決方案丨持續(xù)注能人造太陽裝置,助力我國可控核聚變技術(shù)研究

解決方案丨持續(xù)注能人造太陽裝置,助力我國可控核聚變技術(shù)研究
業(yè)務(wù)資訊丨森木磊石持續(xù)發(fā)力加速器、核聚變;PPEC電源控制核心走入高校課堂






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論