 解開車輛檢測算法之謎
解開車輛檢測算法之謎
車輛檢測看似神秘,其實本質上是通過數學公式計算出圖像指定區域的像素特征,然后根據相應的特征判斷物體所屬的類別。目標檢測方法一般可分為特征提取和類別確定兩個步驟,常用的支持向量機(SVM)和方向梯度直方圖(HOG)方法相互配合使用。
本文將介紹常用的車輛檢測算法,重點從以下幾個方面來揭開這些算法背后的奧秘,讓讀者對機器學習的過程有一個清晰的認識。
應用場景概覽
HOG特征計算詳解
SVM 工作流程概述
比較與總結
應用場景概覽
車輛檢測技術在現實世界中得到廣泛應用,如下例所示。我們定期駕駛的私家車有時會配備一個或多個車載后視攝像頭。當另一輛車即將從后方一定距離內通過時,該系統將被激活。一旦檢測到車輛后方有車輛,就會發出警報并提示駕駛員減速(圖 1)。另一個例子可以在與自動駕駛領域相關的應用中找到,在該應用中,周圍汽車的位置被用來分析它們的速度、距離和其他因素,然后自動調整汽車的路徑作為響應。
車輛檢測系統還廣泛用于交通控制和道路狀況監測(圖 2)。例如,圖中的系統被放置在隧道口,統計特定時間段內每天的車流量,并適當執行相應的限制政策,從而減少交通事故的發生,并為司機提供交通擁堵或暢通的信息。這允許司機選擇避免交通的最佳路線。此外,交通流量統計也可以用于機場或火車站的停車場,通過大數據分析來判斷車位是否供不應求,以便工作人員做出相應的響應和分配資源。
車輛檢測系統產生的信號可以與其他技術相結合來檢測給定交通信號周圍的交通流量,工作人員可以利用大數據和人工智能來計算和確定交通信號燈的合理時間間隔。
聯合 HOG 和 SVM 算法
(40 ? 16) / 8 + 1 = 4
一種使用HOG結合SVM的行人檢測方法最初是由法國研究員Dalal于2005年在美國加州圣地亞哥舉行的計算機視覺與模式識別會議上提出的。現在HOG+SVM的方法已經發展到可以檢測各種行人。對象,包括車輛和車道的位置。
HOG 特征計算
1. HOG是一種局部特征提取算法,因此即使提取更多的特征,該算法也達不到在包含復雜背景的大圖像中檢測目標的目的。需要對圖像進行裁剪才能獲取目標對象。實驗證明,作為目標物體的車輛必須占圖像的80%以上才能獲得良好的效果。裁剪后的局部圖像被分成塊,每個塊都被提取出由單個細胞組成的特征。
(在每個圖像中,多個像素形成一個單元格,多個單元格組成一個塊。)
下面以圖3為例說明HOG特征計算過程。
首先對整張圖片進行裁剪,得到一張40px x 40px的圖片,之后我們必須定義如下變量:
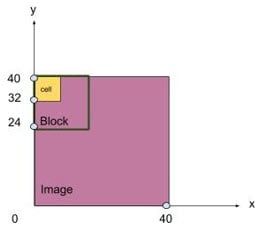
圖 3:為了說明塊在裁剪圖像中的移動,此圖顯示 4 個單元格形成一個邊長為 16px 的塊,然后圖像被裁剪以獲得 40px x 40px 的長和寬。相應的步長為 1,表示一次移動一個像素。(來源:為貿澤創作的原創藝術作品)
我們定義運動步長s,如:s =1。
我們進一步以像素為單位定義單元格大小,例如:8 x 8。
我們進一步定義塊大小,例如:每個塊由 2 x 2 = 4 個單元格組成。
最后,我們定義bin的個數,根據需要設置值,比如:bin = 9。每個bin用來存儲計算出的直方圖梯度方向的累加值,下面會進一步說明。
2. 對輸入圖像和顏色進行標準化處理,以減少光影對圖像中物體檢測精度的干擾,通過伽瑪校正,將圖像轉為灰度(伽瑪校正原理為出于本文的目的而忽略)。
3.計算梯度的大小。
以屬于cell的部分塊為例說明計算方法(圖4),像素值為25時計算中點的公式如下所示。
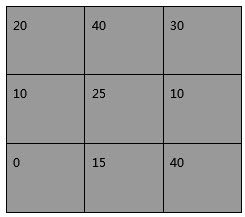
圖 4:單個單元格的部分塊大小和像素值。(來源:為貿澤創作的原創藝術作品)
使用基于卷積核方法的合理定義,我們可以通過實驗證明 [-1, 0, 1] 效果最好。卷積核[-1,0,1]可以理解為一個矩陣,用于計算每個像素的梯度幅度方向。因此,我們可以對水平(x軸正向,向右)使用[-1,0,1],對垂直(y軸正向,向上)使用[-1,0,1]T來進行水平以及圖像區域中每個像素的垂直梯度分量計算。兩者的平方和和根號給出了該點梯度的方向,因此使用的公式如下:
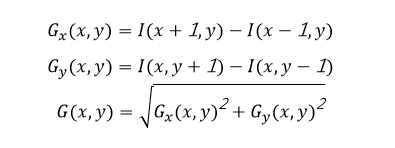
因此像素值為25的點的水平方向計算如下圖5所示:
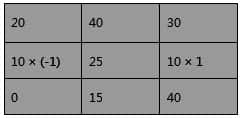
圖 5:計算像素值為 25 的中點水平方向的像素值。(來源:為貿澤創作的原創作品)
公式:
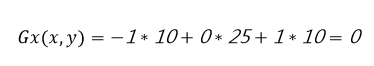
因此,像素值為25的點的垂直方向計算如圖6所示:
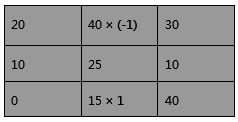
圖 6:計算像素值為 25 的中點水平方向的像素值。(來源:為貿澤創作的原創作品)
公式:
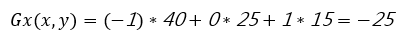 ??
??
4. 相應的梯度方向使用以下公式計算:
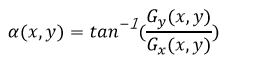
5. 通過對每個單元格中的所有像素重復計算過程中的步驟3至4并求和,我們得到每個單元格在九個梯度方向上的梯度積分圖(圖7)。
6. 我們求解圖像塊的 HOG 特征,這意味著我們將包含的單元格特征連接在一起。
7. 然后我們求解整個圖像的 HOG 特征,這意味著我們連接包含的圖像塊特征。
8.特征維度的計算方法:
上例中的塊在 x 和 y 方向上各移動了四步:
(40-16)/8+1=4
每個塊包括四個單元格:
2*2=4
特征維度計算公式:
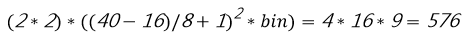
因此,為當前圖像示例計算的特征維度對應于 576。
9. 然后我們對獲得的梯度向量進行歸一化。歸一化的關鍵目標是防止過度擬合,這會導致訓練集分類良好但測試集檢測率極低,這種情況對于我們的目的來說顯然是不可接受的。使用我們用于機器學習特征歸一化的相同方法,如果我們獲得分布在 (0, 200) 之間的特征值,例如,我們需要防止 200 以下的數字影響特征的整體分布(模型會偏離從整體趨勢去擬合200,導致過擬合),所以我們需要將特征分布歸一化到一定區間。Dalal 在他的論文中提到,使用 L2-norm 獲得的結果非常令人滿意。
(這里,0、200代表特征值的取值范圍)
10. 特征連同相應的標簽被發送到 SVM 以訓練分類器。
直方圖梯度方向和 Bin 值
Dalal 在他的論文中提到,“這一步的目的是為局部圖像區域提供函數量化梯度方向的指示,同時保持對圖像中檢測到的對象的外觀保持較弱的靈敏度。 “
根據梯度的方向將梯度大小插入到相應的bin中,定義方向有兩種可能的方法。
無符號方法適用于車輛或其他物體檢測,而有符號方法已被實驗證明不適用于車輛或其他物體檢測。然而,當圖像被放大、縮小或旋轉時,這種方法會很有用,之后像素會返回到它們的原始位置。請參閱參考資料中包含的第五個鏈接以獲得更深入的了解。
1. 無符號:(0, π)
下面我們仔細看看無符號插值。
在這篇文章中,我們將使用三個表格來解釋插值是如何進行的。在每個表中,第一行顯示計算的振幅,第二行指定 bin 的方向值,該值是通過將 180 度除以定義的 bin 數獲得的。第三行顯示 bin 序號,從 0 開始。
圖像可以根據需要分成盡可能多的箱子。例如,當分為九個bins時,即使用每個cell有九個方向的梯度直方圖時,每個bins覆蓋20度的區域。振幅(上面計算的)被插入到每個 bin 中,每個 bin 中振幅的最終總和對應于直方圖的垂直軸,而水平軸對應于 bin 值的范圍,在本例中為 (0, 8) .
插值法:
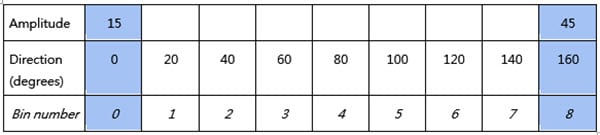
如果像素的振幅為 80 度,方向為 20 度,則將這些值插入到表 1藍色區域中的相應位置。
表 1:如果像素的振幅為 80,方向為 20 度,則插入相應位置的值。

如果振幅為80度,方向為10度,則將這些值分別插入表2中藍色區域的兩個位置。
表 2:如果像素的振幅為 80,方向為 10 度,則插入相應位置的值。
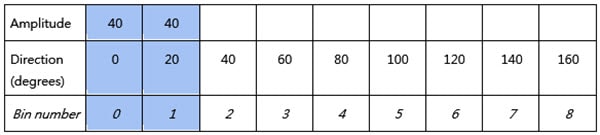
如果振幅為60度,方向為165度,則將這些值分別插入表3中藍色區域的兩個位置。
(180 度和 0 度在方向上是等效的,所以振幅以每個 1:3 的比例插入兩個 bin 中)
表3:振幅為60,方向為165度時對應位置插入的值。
上表1為方向值與bin對應值完全相同時采用的插值方法,表2為方向值落在兩個bin值之間時采用的插值方法,表3顯示方向值大于最大 bin 值時使用的插值方法。根據三種方法在以單元格為度量單位進行計算時的原理,遍歷后累加一個單元格中所有像素點的幅值。例如,在上面的示例中,我們在 bin 0 處獲得了 40 和 15 的兩個振幅值,因此我們的 bin 0 直方圖到目前為止已經累積到 55。從 bin 1 到 8 的每個單元格的振幅在同樣的方式。我們最終得到了類似于下圖的直方圖(圖 7),橫坐標 X 表示梯度方向,縱坐標 Y 表示梯度幅度。
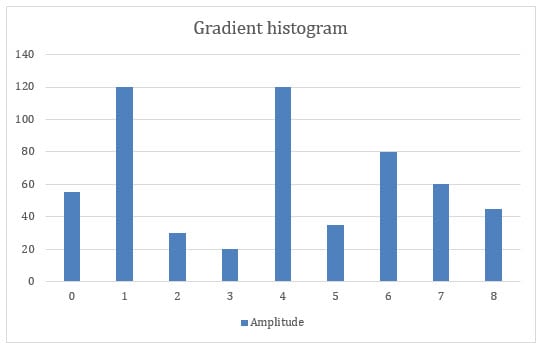
圖 7:梯度直方圖示例:橫軸對應 bin 數,縱軸對應計算出的振幅。對應于圖的縱軸的數字僅用于說明目的。例如,將上面三個表中的bin 1幅度值相加得到80 + 40 + 0 = 120作為最終結果,我們得到直方圖縱坐標為120。隨著我們繼續計算 bin 1 的值,該值將不斷累加。(來源:為貿澤創作的原創藝術作品)
實驗結果表明,當使用九個箱子進行目標檢測和單向插值時,可以獲得最好的結果。
2. 有符號:(0, 2π)
當在方向值前加上正負號時,如果同時定義了九個bin,則分配給每個bin的角度范圍為:(0, π/9°)。例如,對于第二個 bin,它有一個正值插值到 20-40 范圍內(藍色區域),負值應該插值到 200-220 范圍內(藍色區域)。(圖8)
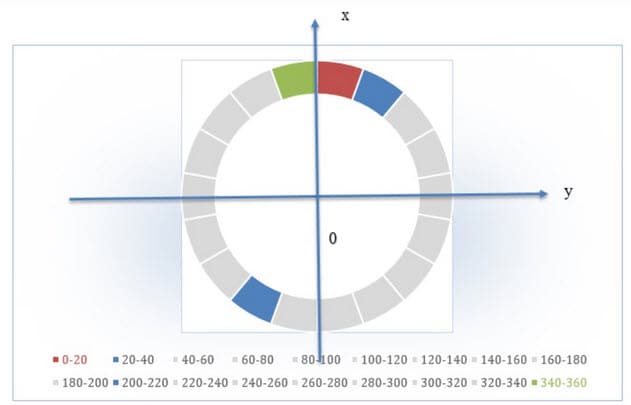
圖 8:在有符號插值中,每個扇區代表一個 bin 覆蓋角范圍值。紅色對應一號 bin,涵蓋 0 到 20 度。按順時針方向移動,綠色標記 340–360 度的終點。藍色區域表示兩個方向上對應的 bin。(來源:為貿澤創作的原創藝術作品)
SVM 工作流程概述
SVM(支持向量機)通過一個超平面將空間中的兩個類分開,二維空間可以簡單理解為求y且y滿足的空間:
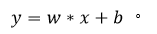
y 值決定樣本是分類為陽性還是陰性。然而,為了確定最優超平面,這里我們引入支持向量和最大間隔。我們的目標是找到一個超平面,使最靠近超平面的點之間的距離最大(圖 9)。
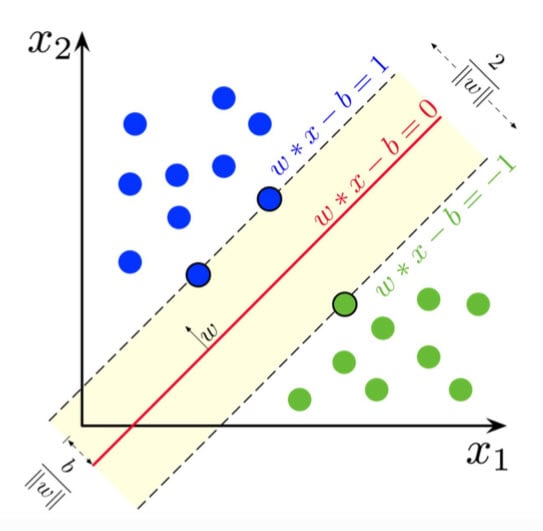
圖9:紅線對應超平面,虛線兩邊的點為支持向量,計算值為1(正類)或-1(負類)。藍色點對應正樣本,綠色點對應負樣本。目標是找到顯示虛線之間最大距離的值,因為較大的距離表示更好的二元分類模型。(來源:維基百科)
由于真實情況下呈現的數據非常復雜,有時會根據需要引入核函數,以便將低維映射到高維,并通過找到最優超平面使線性不可分的數據(圖 10 )線性可分。
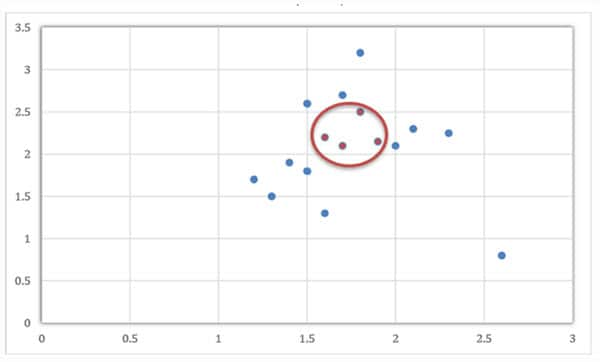
圖10:紅圈中的點在二維空間中與藍圈中的點線性不可分,因此需要一個核函數將這些點映射到更高維的坐標系中。(來源:為貿澤創作的原創藝術作品)
SVM 計算量大且訓練耗時,因為要為每個點計算與其他所有點的相似性。因此,支持向量機適合訓練數據量較小的二元分類模型,如果涉及多個類別,通常會單獨訓練多個模型。此外,由臺灣大學教授開發的兩個開源工具現在非常受科學家歡迎。第一個是 LibSVM,另一個是 Liblinear,它是基于 SVM 技術針對大量數據開發的。
SVM 對參數極其敏感。在 LibSVM 或 LibLinear 的訓練過程中,密切關注懲罰項 C 和權重因子 w 非常重要。C為懲罰項,越大表示訓練過程中的分類效果越好。但是,當C過大時,會出現過擬合,即訓練樣本分類準確率極高,而測試準確率極低。不可避免地會存在遠離集合中心集群的數據點,C 的大小表明我們愿意丟棄這些異常值。較大的 C 值表示我們不愿意丟棄這些異常值,因此該模型特別適合訓練集而不是測試集。W,即權重,代表正負樣本的系數,如果我們想要檢測更多的目標,我們可以增加正樣本權重。但是,這樣做會導致誤檢率(FP)特別高。反之,增加負樣本權重會降低誤檢率(FP),但目標檢出率(TP)自然也會降低。
筆者做了一個簡單的實驗發現,使用百萬數據點和1152維特征,在運行Windows 10的情況下,使用兩個CPU和60G RAM,開啟18個線程進行訓練需要20分鐘。因此,建議要么使用 Liblinear 庫在非常大的語料庫上進行訓練或增加可用的計算機內存。
比較與總結
在本文中,我們重點了解車輛檢測背景下的特征計算,并簡要探討了 SVM 分類策略。當HOG特征用于車輛檢測時,建議使用9個bin中1000維以上特征的無符號插值,并且必須對不均勻的特征分布進行歸一化。對于SVM,可以根據需要選擇核函數,必要時可以使用LibSVM庫基于非常大量的數據訓練模型。SVM 將低維空間映射到高維空間的核函數機制有效地解決了線性不可分性問題。SVM 的計算復雜度由支持向量的數量決定,最終的決策函數幸運地由少量的支持向量決定。SVM 也有其局限性。如果不使用 LiBSVM/Liblinear 開源庫,單獨使用 SVM 時處理大量數據會非常困難。這是因為SVM計算過程涉及矩陣計算,行數和列數由樣本數決定。因此,大樣本在計算過程中會消耗大量的時間和空間。同樣,在實踐中,選擇是否利用 HOG 應該基于對技術優缺點的雙向考慮。這些優點和缺點總結在這里供讀者參考。SVM 也有其局限性。如果不使用 LiBSVM/Liblinear 開源庫,單獨使用 SVM 時處理大量數據會非常困難。這是因為SVM計算過程涉及矩陣計算,行數和列數由樣本數決定。因此,大樣本在計算過程中會消耗大量的時間和空間。同樣,在實踐中,選擇是否利用 HOG 應該基于對技術優缺點的雙向考慮。這些優點和缺點總結在這里供讀者參考。SVM 也有其局限性。如果不使用 LiBSVM/Liblinear 開源庫,單獨使用 SVM 時處理大量數據會非常困難。這是因為SVM計算過程涉及矩陣計算,行數和列數由樣本數決定。因此,大樣本在計算過程中會消耗大量的時間和空間。同樣,在實踐中,選擇是否利用 HOG 應該基于對技術優缺點的雙向考慮。這些優點和缺點總結在這里供讀者參考。這是因為SVM計算過程涉及矩陣計算,行數和列數由樣本數決定。因此,大樣本在計算過程中會消耗大量的時間和空間。同樣,在實踐中,選擇是否利用 HOG 應該基于對技術優缺點的雙向考慮。這些優點和缺點總結在這里供讀者參考。這是因為SVM計算過程涉及矩陣計算,行數和列數由樣本數決定。因此,大樣本在計算過程中會消耗大量的時間和空間。同樣,在實踐中,選擇是否利用 HOG 應該基于對技術優缺點的雙向考慮。這些優點和缺點總結在這里供讀者參考。的優點和缺點。這些優點和缺點總結在這里供讀者參考。的優點和缺點。這些優點和缺點總結在這里供讀者參考。
優點:HOG是以局部為單位進行的,可以更好的捕捉局部的形狀信息,同時忽略光照、顏色等因素。例如,在車輛檢測過程中可以忽略汽車的顏色,從而減少所需的特征維度數量,并且由于該技術對光的敏感度較弱,即使在視線被部分遮擋的情況下仍然可以檢測到車輛。
缺點:HOG不太擅長處理遮擋,車輛方向的變化不易察覺。由于梯度的性質,HOG對噪聲相當敏感,所以在block和cells被分割成局部區域單元后,在實踐中往往需要進行高斯平滑來去除噪聲。特征維度(cell、block、step size)的確定要求很高,在實踐中需要多次嘗試才能獲得最優解。
我希望本文能讓您更清楚地了解車輛檢測的最新技術水平。結合SVM和HOG雖然計算量大,但相應的成本低,模型的訓練可以在標準CPU上完成,這使得這種方法在中小型產品開發公司中非常流行。例如,車載攝像頭等小部件的開發和輸出可能會繼續產生更好的性價比,同時還能確保可接受的可用性水平。
審核編輯hhy
-
檢測
+關注
關注
5文章
4620瀏覽量
92599 -
機器學習
+關注
關注
66文章
8497瀏覽量
134226 -
汽車
+關注
關注
14文章
3810瀏覽量
39328
發布評論請先 登錄
基于RK3576開發板的車輛檢測算法
基于RK3576開發板的安全帽檢測算法
基于RV1126開發板的車輛檢測算法開發
基于RV1126開發板的安全帽檢測算法開發
軒轅智駕紅外目標檢測算法在汽車領域的應用
睿創微納推出新一代目標檢測算法
bq2750x系列中的Impedance Track?電池電量監測算法的理論及實現

旗晟機器人環境檢測算法有哪些?

opencv圖像識別有什么算法
口罩佩戴檢測算法

人員跌倒識別檢測算法

安全帽佩戴檢測算法






 工商網監
工商網監
評論