") 面向智能移動平臺的語義定位與建圖
面向智能移動平臺的語義定位與建圖

一、背景
1、智能移動平臺的定義平臺包含兩大特征,第一個是能夠自主地對它周圍的環(huán)境進行感知,基于感知信息自主運行,實現(xiàn)特定的任務,常見的移動平臺是移動機器人和無人車。 為了實現(xiàn)或構建機器人或無人車,通常在算法方面有四大技術難點,即感知、狀態(tài)估計、預測和執(zhí)行控制。我的博士論文關注前面兩點:感知和狀態(tài)估計,總結為讓無人車或機器人看見這個世界。
2、如何使用激光雷達傳感器對周圍環(huán)境感知通常來說基于機載或車載的傳感器,圖 1 是實驗室自己的感知采集平臺,平臺上搭載了不同傳感器,包括激光雷達、相機和 GPS。對于成熟的產(chǎn)品,需要融合各種傳感器的不同模態(tài)信息,最后構建一個非常魯棒和安全的感知系統(tǒng)。

圖 1 感知采集平臺 我的博士課題僅僅使用激光雷達傳感器的數(shù)據(jù)作為算法輸入,動機是測試使用單一傳感器的感知性能。如果把所有的基于單一傳感器的感知算法優(yōu)化到最好,結合在一起就可以得到更加魯棒、更加安全的感知系統(tǒng)。 64線激光雷達的數(shù)據(jù)如圖 2 所示,旋轉式的激光雷達實際是對環(huán)境進行深度掃描。在數(shù)據(jù)中,每一行實際是每一束激光旋轉 360 度過程中采集的環(huán)境深度信息,每一列實際就是多線激光雷達在某一時刻采集的深度信息。

圖 2 64 線激光雷達數(shù)據(jù) 在給定激光雷達激光束的標定參數(shù)以后,比如它的發(fā)射角和分辨率,也可以對每個距離采集信息的 3D 坐標進行解算,最后得到一個 3D 點云。我的博士論文就是使用這樣的傳感器的數(shù)據(jù)作為所有算法的輸入。
3、為什么語義信息于激光雷達感知非常重要語義信息實際上是人類對環(huán)境的更高級別的理解。圖 3 是原始點云信息和帶有語義的點云信息對比,人類可以對環(huán)境有所理解,經(jīng)過長時間的學習訓練,對于機器人來說就是 3D 坐標,對于幾何信息很難對周圍環(huán)境進行理解,語義信息標注以后,無人車和機器人就能夠更好的對環(huán)境進行理解,識別可通行區(qū)域的道路。我的博士論文就是想要利用語義信息使機器人的感知性能提升,實現(xiàn)機器人的感知。
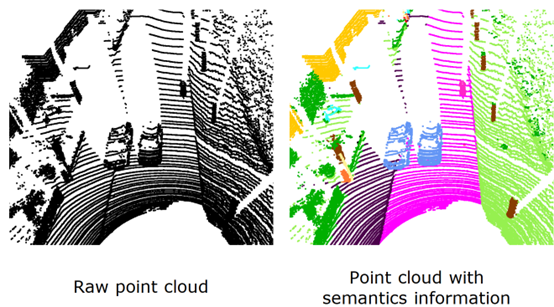
圖 3 原始點云和語義信息點云對比
4、論文簡介為了實現(xiàn)語義感知性能,論文主要是從三個方面進行: (1)如何利用現(xiàn)有的多類別的語義分割結果去提升機器人的感知和狀態(tài)估計的性能,比如說提升定位和建圖的性能; (2)對于不同的任務,不同的語義類別實際上是有不同的影響。針對不同的任務,可以提出更加刻意的語義信息來進一步提高算法的性能; (3)對語義信息進行簡化后提出自動生成的語義算法,減輕對于人工標注的依賴。
二、使用多類別語義信息提高定位和建圖性能基于語義信息的同時定位和建圖(SLAM),SLAM 對于機器人自主導航非常重要,主要實現(xiàn)的是機器人在自主運行中,對環(huán)境地圖進行構建,然后同時在所構建的地圖環(huán)境中找到機器人當前位置。這是所有上游任務或下游任務的基礎,要實現(xiàn)導航和規(guī)劃,首先要知道環(huán)境長什么樣子,知道當前環(huán)境中的位置,才能夠實現(xiàn)下游任務,所以 SLAM 是機器人導航的基礎。在第一個例子里面,想要在 SLAM 的過程中加入這樣的多類別的語義信息,從而對 SLAM 的精度進行一個提升,如圖 4 所示。
圖 4 SLAM 過程增加多類別語義信息
1、為什么需要語義信息提升 SLAM 精度?當前的車輛的無人車行駛環(huán)境,在一個非常擁堵的高速路入口,圖 5 左邊展示的是傳統(tǒng)的基于幾何信息的 SLAM 結果,紅色車輛代表的是位姿估計的真值,藍色車輛代表傳統(tǒng)的基于幾何信息 SLAM 的估計出來的位姿值。可以看到在這樣的一個具有挑戰(zhàn)的場景中,傳統(tǒng)的基于幾何信息的 SLAM 沒有辦法很好的對當前車輛的位姿進行估計的,甚至給出了一個完全相反的運動方向,這樣的算法在真實產(chǎn)品應用中會帶來非常大的一個麻煩。

圖 5 基于幾何信息的 SLAM 但當擁有語義信息后,提出了語義 SLAM,如圖 6 所示。可以更好的對車輛的位姿進行估計,最后可以看到估計出來的位姿的值和真值非常接近,同時也可以對環(huán)境的語義信息進行描述。

圖 6 語義 SLAM 結果
2、具體如何實現(xiàn)語義 SLAM 的呢?圖7是語義 SLAM 的實現(xiàn)框圖,總共包含五個部分,在第一個部分展示的是 Raw Scan 算法,僅僅使用激光雷達點云作為輸入,然后在第二個部分使用現(xiàn)有的語義分割結果,輸出是每一個點對應的語義標簽,這里采用的是提出的 RangeNet++方法,然后在第三個部分把語義信息和激光雷達的幾何信息結合作為定位建圖的輸入,在建圖部分使用動態(tài)物體去除算法,圖 8 的左圖展示不做任何處理時把語義觀測疊加,可以看到由于當前場景中有動態(tài)的物體,會造成鬼影污染,污染會使地圖沒辦法用于下一步的定位和導航,提出的算法就是把當?shù)挠^測和歷史累積的語義地圖進行語義標簽一致性的檢測,如果當前觀測里面的語義標簽和地圖中的語義標簽不一樣時,就把這樣的語義標簽當做運動的物體,對它進行去除,最后可以看到使用去除算法可以得到一個非常干凈的語義地圖。
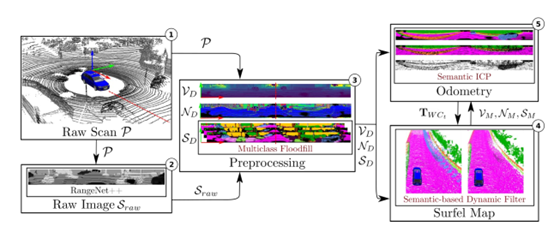
圖 7 語義 SLAM 實現(xiàn)框圖

圖 8 語義動態(tài)去除 基于語義地圖,進一步提出了基于語義信息的位姿估計算法,叫做 Semantic ICP。ICP 就是把當前觀測和語義地圖對齊,從而估計當前車輛或傳感器的位姿,實現(xiàn)了累積定位。如圖 9 所示,可以看到當前觀測里面有動態(tài)物體,中間這幅圖展示的是清理之后的語義地圖,第三幅圖展示的是在位姿估計過程中的每一個匹配,當前觀測和地圖的匹配之前的權值,顏色越深代表權值越低,可以清楚看到動態(tài)物體的權值,降低了它的權值,通過操作可以降低動態(tài)物體在位姿估計過程中對位姿估計帶來的負面結果,從而提升位姿估計精度。

圖 9 語義 ICP 圖 10 展示的是算法在線運行的結果,可以看到語義 SLAM 可以實時的對環(huán)境的云地圖進行構建,同時也可以準確的估計自身車的位姿,對動態(tài)物體進行去除,然后保留靜態(tài)的語義地圖。
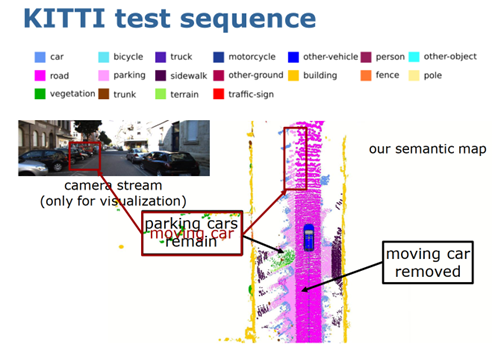
圖 10 算法在線運行的結果 圖 11 是第一個示例,在第一個示例中利用多類別的語義信息對 SLAM 的定位和建圖性能提升。SLAM 實質上包含三個部分,定位、建圖和閉環(huán)檢測,閉環(huán)檢測主要是機器人回到之前已經(jīng)歷過地方的時候,能不能判斷出這個地方是已經(jīng)歷過的,如果能判斷的話,可以加入閉環(huán)約束,通過約束消除長期運行的累積誤差,從而構建出全局一致的地圖和更加精確的位姿估計,所以閉環(huán)對于 SLAM 是非常重要的。傳統(tǒng)的基于幾何信息的閉環(huán)檢測算法在一些挑戰(zhàn)環(huán)境中無法正常工作,比如,當一個車從反方向開回到之前經(jīng)歷過的十字路口時,由于視角變換太大,所以無法識別十字路口是之前經(jīng)歷過的。
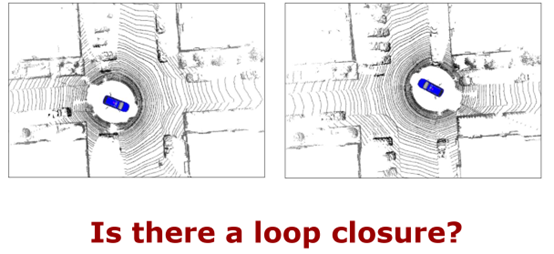
圖 11 第一個示例 針對這個問題,在第二個示例中提出了利用深度學習和語義信息幫助機器人 SLAM 更好的找到閉環(huán),提高全局地圖構建精度和位姿估計的精度。 第二個例子的算法流程圖如圖 12 所示,左邊所展示的就是算法把兩幀激光雷達當做輸入,然后除了使用激光雷達傳統(tǒng)的幾何信息,比如深度、法向量信息以外,也使用了語義信息,通過語義信息對地圖點的描述性更強,所以可以更好找到閉環(huán)。右邊是算法網(wǎng)絡的流程圖,是比較經(jīng)典的編碼器和解碼器結構,首先編碼器對兩幀激光雷達進行提取,生成一個比較的特征,在第一個解碼器中對兩個激光雷達的加速度進行估計,可以更好的判斷當前的觀測是不是已經(jīng)經(jīng)歷過的地方,如果已經(jīng)找到了一個閉環(huán),當車輛從反方向駛入時,當偏航角過大的時候,還是無法很好地閉環(huán),所以針對這個任務設計了一個偏航角估計的解碼器,解碼器可以估計出兩個激光雷達的相對偏航角,在找到閉環(huán)之后用偏航角估計可以更好的初始化位姿估計,從而更好的實現(xiàn)閉環(huán)。
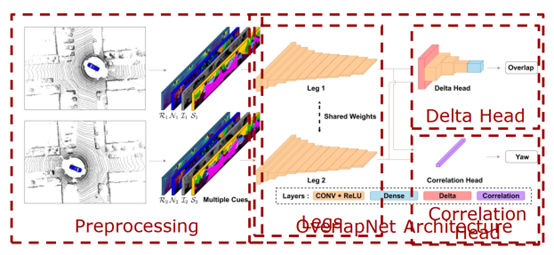
圖 12 第二個例子的算法流程圖 圖 13 展示的是算法在線運行的結果,可以看到在經(jīng)過長時間的運行之后,右邊展示的是位姿估計的累積誤差,顏色越紅代表誤差越大。紅色點表示算法找到的閉環(huán),在閉環(huán)后可以對累積誤差進行消除。當機器人反方向駛入的時候,也能夠找到閉環(huán)。
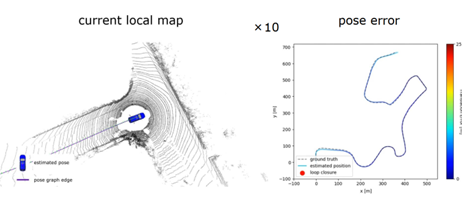
圖 13 算法在線運行結果 圖 14 展示的是在加入的閉環(huán)檢測算法和沒有加入閉環(huán)檢測算法的定位和建圖精度的比較,可以看到方法 SLAM 可以得到一個更加精確的定位和建圖結果,相對于沒有使用閉環(huán)檢測的算法。
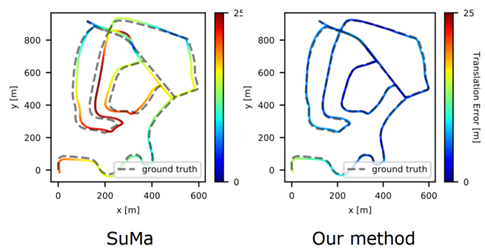
圖 14 加入閉環(huán)檢測和沒有加入閉環(huán)檢測算法 SLAM 對比 小結:第一部分實際上回答了要如何使用現(xiàn)有的語義信息多類別的從語義分割網(wǎng)絡里得到的點云信息來對感知任務進行系統(tǒng)的提升,在第一個部分中以 SLAM 的閉環(huán)做了一個示例,在論文中也嘗試了對全局定位算法進行深度學習的嘗試,但是由于時間關系,在我的答辯過程中,每部分只提供了一個或兩個示例。 在第一個問題中主要回答的是利用語義信息提高感知性能,在進行這個研究的過程中實際上也發(fā)現(xiàn)了對于定位和建圖而言,更加在意的是當前的環(huán)境中這些物體是運動還是靜止的,所以實質上對于特定的感知任務,每一個類別或者不同的語義信息帶來的影響是不一樣的。那么在第二個部分里面,就想要回答對于特定的感知任務是不是能夠提出更加特意的語義信息從而進一步提高感知任務的精度。
三、對于特定的感知任務,提出更加特意的語義信息從而進一步提高感知任務的精度同樣的以激光雷達 SLAM 為基礎,提出了動態(tài)物體分割的算法,如圖 15 所示。和現(xiàn)有的語義分割不一樣的是,在動態(tài)物體分割中不是要區(qū)分一個物體的具體類別,而是要區(qū)分是運動物體還是靜態(tài)物體,為了實現(xiàn)動態(tài)物體分割,提出了一個新的基于深度學習的利用序列信息的算法。
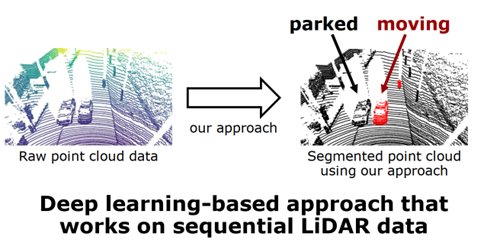
圖 15 基于深度學習方法的序列雷達數(shù)據(jù) 動態(tài)物體分割的流程圖如圖 16 所示,可以看到使用的這個網(wǎng)絡結構也是傳統(tǒng)的編碼器解碼器結構。和傳統(tǒng)的語義分割不一樣的是,輸出不是多類別語義分割,而是更加特意的二值分割動和不動的結果。這樣的好處是把一個復雜的多類別的語義分割任務簡化為二值的分類任務,可以更容易的得到這樣一個結果,之后再對定位和建圖進行提升。然后和多類別語義分割還有一個不同的就是,不使用單一的當前觀測作為輸入,而使用一系列的連續(xù)時空的觀測作為網(wǎng)絡的輸入。為了更好的使用這樣的時空信息,提出了一個所謂的殘差圖像。接下來具體介紹怎么生成和使用殘差圖像的。
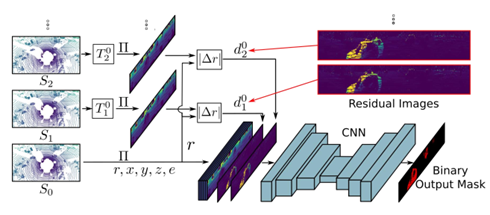
圖 16 動態(tài)物體分割流程圖 如圖 17 所示,其中第一個圖展示的是當前的觀測,第二個圖展示的是當前觀測中動態(tài)物體的真值,下面的圖像都是提出的殘差圖像,j=1 代表利用過去的第一幀和當前幀所比較得到的殘差圖像,以此類推。為了生成殘差圖像,首先把過去的觀測投影到當前的坐標系,對于每一個過去觀測中的點 rij→0投影到當前的坐標系,和對應的觀測進行比較,從而生成殘差圖像。利用殘差圖像,這是一個非常直觀的使用已有的人類先驗知識引導網(wǎng)絡如何識別動態(tài)物體,可以清楚看到在哪個位置有動態(tài)物體。利用這樣連續(xù)多幀的去檢測也是一個非常自然而言的想法,比如作為人類來說看一張圖片沒有很好的判斷,如果看視頻的話能夠看到物體運動的性質。將連續(xù)多幀的物體作為輸入可以更好的識別動態(tài)物體。
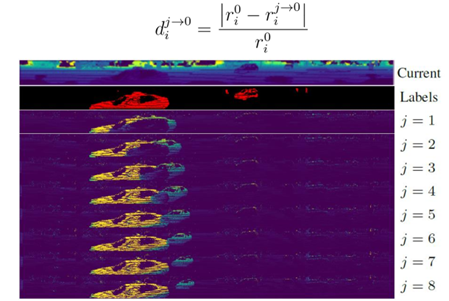
圖 17 殘差圖像 圖 18 展示的是算法在線運行的結果,可以看到算法可以很好的對正在運動的車輛和行人進行識別,也可以識別到靜態(tài)背景,可以在不同環(huán)境中使用。
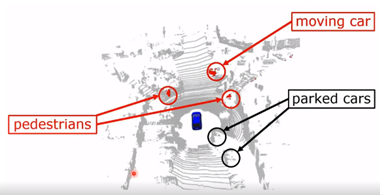
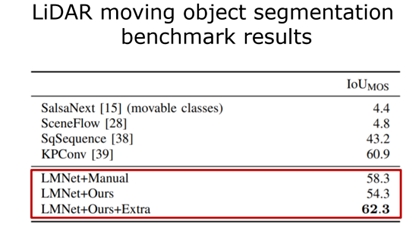
圖 18 算法在線運行的結果 接下來是更多的數(shù)值的一個比較,如表 1 所示。那么對三個不同算法的定位結果進行對比,第一個只是用幾何信息,第二個使用多類別的語義信息來對 SLAM 性能進行增強的結果,第三個算法是使用剛才提出的動態(tài)物體分割的結果。每個方法有兩個數(shù)字,前面是旋轉誤差,后面是平移誤差,可以看出更好的結果,比使用多類別語義信息更好的結果。
表 1 不同算法的定位結果對比
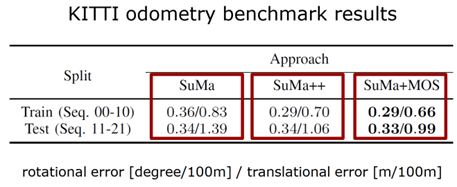
圖 19 展示的是在使用動態(tài)物體分割以后建圖的結果,上面是原始點云建圖結果,存在鬼影,下面是動態(tài)物體分割后的更加干凈的環(huán)境地圖,可以更好的用于下游的任務。
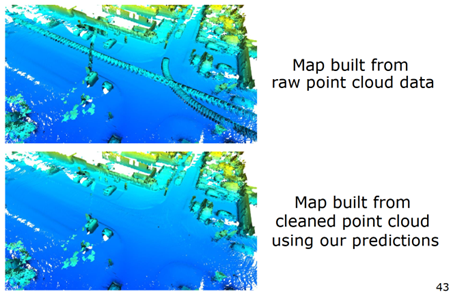
圖 19 使用動態(tài)物體分割后建圖的結果 小結:對于特定的激光雷達的感知任務,可以提出更加特意的語義信息。以 SLAM 為例,提出了動態(tài)物體分割,通過這種方式,對需要的語義信息進行簡化,更加容易的得到語義信息,同時對相對應的任務進行性能提升。 簡化語義信息后,非常大的好處就是可以找一些自動生成語義信息的方法,減輕對于人類手工標注的依賴。
四、特定語義任務自動生成標注自動生成物體標簽的算法,如圖 20 所示,拿一個序列的激光雷達點云作為算法輸入,首先使用傳統(tǒng)的方法進行位姿估計,通過一致性檢測對大概的動態(tài)物體區(qū)域進行標注,然后對標注的可能物體進行實例的分割,最后對可能運動物體進行跟蹤,生成動靜的標簽,根據(jù)速度或距離來確定標簽。這里注意的是方法無法進行在線測試,一步一步進行,離線的生成標簽好處在于中間幀不僅可以使用當前和過去的信息,還可以使用未來的信息,使用時空信息對動態(tài)物體進行檢測,生成標簽,再對網(wǎng)絡進行訓練,自動訓練得到網(wǎng)絡,部署到在線任務中去。
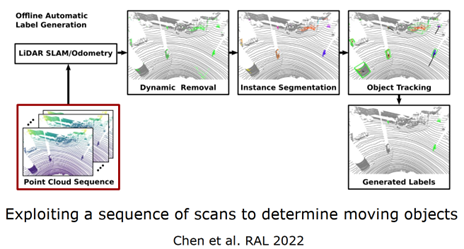
圖 20 自動生成物體標簽算法
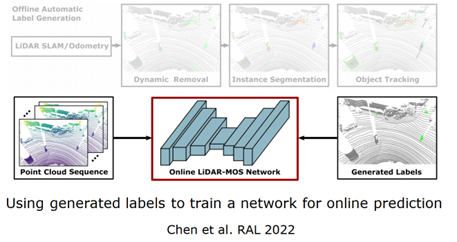
圖 21 自動生成物體標簽算法(續(xù)) 在不同的數(shù)據(jù)集上也可以進行,如圖 22 所示,這是在美國和韓國采集的,算法都能夠達到很好的性能。
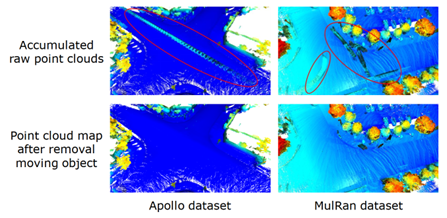
圖 22 數(shù)據(jù)集 表 2 展示的是算法使用自動標簽進行訓練和使用真值訓練得到標簽的結果,IOU 越大效果越好。
表 2 自動標簽和真值標簽結果對比
使用同樣的數(shù)據(jù)集,自動生成標簽當然要比真實標簽性能要差,但生成更多標簽的時候能夠提升網(wǎng)絡的性能。 小結:簡化所需的語義信息后,可以提出自動生成標簽的方法去訓練網(wǎng)絡,減輕對人工標注的網(wǎng)絡,從而使深度學習方法可以泛化到不同環(huán)境中。
五、總結最后,對整個博士論文進行一個總結,它實際上就是回答了三方面的內(nèi)容,第一個方面就是如何使用現(xiàn)有的多類別語義信息提高激光雷達定位和建圖的精度,然后針對于特定的任務,是不是可以提出更加特意的語義信息,從而對于語義信息進行簡化,因為特意化以后能提升性能,第三個可以自動生成標簽降低對手工標注的依賴。 博士期間的研究成果如圖 23 所示。

圖 23 博士期間成果 代碼的公開如圖 24 所示。

圖 24 代碼鏈接
問題 QA:1.semantic ICP 是只區(qū)別了動態(tài)物體還是靜態(tài)物體之后的 ICP 嗎? 除了動態(tài)物體的權值有所降低以外,比如柵欄或其他地方的權值也有所調(diào)整,沒有特別針對靜態(tài)物體或動態(tài)物體調(diào)整,不對動靜進行區(qū)分,只是單純的對每一個類別物體的語義一致性進行檢測。 2.語義的視覺 SLAM 有哪些深挖的點?是否推薦多模態(tài)的語義 SLAM? 多模態(tài)當然是未來發(fā)展的熱門方向,對于一個真正的產(chǎn)品落地肯定最后是多模態(tài)的結果,單一傳感器總有不適用的場景,對于視覺來說黑夜和雨天影響很大,對于激光雷達來說雨霧也有很大的影響,所以大家也會嘗試加入 IMU 和 GPS 以及毫米波雷達等等。對于視覺 SLAM 沒有做特別多的工作,現(xiàn)在的了解的話,和這里的語義不太一樣的定義。 3.激光語義 SLAM 和視覺語義 SLAM 的區(qū)別? 其實就是傳感器的區(qū)別,視覺 SLAM 的信息更加豐富一點,因為有外觀的 RGB 信息,可以更好的實現(xiàn)語義分割,在室外的話,單目沒有深度信息,這是和激光雷達的區(qū)分。激光雷達沒有顏色信息,很難區(qū)分物體。視覺的視角更寬一點。 4.研究語義 SLAM 的過程中需要注意那些內(nèi)容? 按照思路順下來,在答辯時能夠更加了解如何你是一步一步進行研究的,大家可以參考順序。如何獲取更好的無監(jiān)督的語義信息是現(xiàn)在比較難的一個點,還有一個是深度學習的瓶頸,它非常依賴于對語義信息的定義。得到的類別只是訓練的類別,無法得到開放世界的類別。如何對不知道的類別進行檢測,這是一個非常的難點。 5.語義 SLAM 的工程化有什么建議? 在自動駕駛公司用的比較多,和定義的語義不太一樣,在高精地圖中語義的信息使用非常重要。對于語義的定義是多種多樣的,在實際工程的應用中,比如車道線的檢測已經(jīng)是非常好的了。工程化的難點是開放世界,對更多類別進行識別,算例是難點。如何輕量化網(wǎng)絡,還有就是泛化系統(tǒng)的問題,都是城市場景的自動駕駛,在沒有車道線的地方如何提取語義信息進行自動駕駛也是非常關注的。
審核編輯 :李倩
-
傳感器
+關注
關注
2565文章
53008瀏覽量
767458 -
SLAM
+關注
關注
24文章
441瀏覽量
32505 -
激光雷達
+關注
關注
971文章
4236瀏覽量
192872
原文標題:面向智能移動平臺的語義定位與建圖
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
河南移動攜手華為完成智能追焦單元部署
Arm 公司面向移動端市場的 ?Arm Lumex? 深度解讀
基于STM32 人群定位、調(diào)速智能風扇設計(程序、設計報告、視頻演示)
【「# ROS 2智能機器人開發(fā)實踐」閱讀體驗】視覺實現(xiàn)的基礎算法的應用
芯盾時代繼續(xù)深化中建科技統(tǒng)一身份認證平臺建設
【「具身智能機器人系統(tǒng)」閱讀體驗】2.具身智能機器人的基礎模塊
云酷藍牙人員定位系統(tǒng)的優(yōu)勢


工業(yè)智能網(wǎng)關快速接入移動OneNET平臺配置操作
如何部署北斗定位應用,基于國產(chǎn)自主架構LS2K1000LA-i處理器平臺
使用語義線索增強局部特征匹配

一種半動態(tài)環(huán)境中的定位方法
思嵐科技SLAMKit定位與建圖解決方案介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論