 分享一種基于深度圖像梯度的線特征提取算法download
分享一種基于深度圖像梯度的線特征提取算法download

0. 筆者個人體會
在低紋理區域,傳統的基于特征點的SfM/SLAM/三維重建算法很容易失敗。因此很多算法會嘗試去提取線特征來提高點特征的魯棒性,典型操作就是LSD。
但在一些帶噪聲的低光照環境下,LSD很容易失效。而且線特征檢測的難點在于,由于遮擋,線端點的精確定位很難獲得。
它使用深度學習來處理圖像并丟棄不必要的細節,然后使用手工方法來檢測線段。
因此,DeepLSD不僅對光照和噪聲具有更強魯棒性,同時保留了經典方法的準確性。整篇文章的推導和實驗非常詳實,重要的是算法已經開源!
2. 摘要
線段在我們的人造世界中無處不在,并且越來越多地用于視覺任務中。由于它們提供的空間范圍和結構信息,它們是特征點的補充。
基于圖像梯度的傳統線檢測器非常快速和準確,但是在噪聲圖像和挑戰性條件下缺乏魯棒性。他們有經驗的同行更具可重復性,可以處理具有挑戰性的圖像,但代價是精確度較低,偏向線框線。
我們建議將傳統方法和學習方法結合起來,以獲得兩個世界的最佳效果:一個準確而魯棒的線檢測器,可以在沒有真值線的情況下在野外訓練。
我們的新型線段檢測器DeepLSD使用深度網絡處理圖像,以生成線吸引力場,然后將其轉換為替代圖像梯度幅度和角度,再饋入任何現有的手工線檢測器。
此外,我們提出了一個新的優化工具,以完善基于吸引力場和消失點的線段。
這種改進大大提高了當前深度探測器的精度。我們展示了我們的方法在低級線檢測度量上的性能,以及在使用多挑戰數據集的幾個下游任務上的性能。
3. 算法解讀
作者將深度網絡的魯棒性與手工制作的線特征檢測器的準確性結合起來。具體來說,有如下四步:
(1) 通過引導LSD生成真實線距離和角度場(DF/AF)。
(2) 訓練深度網絡以預測線吸引場DF/AF,然后將其轉換為替代圖像梯度。
(3) 利用手工LSD提取線段。
(4) 基于吸引場DF/AF進行細化。
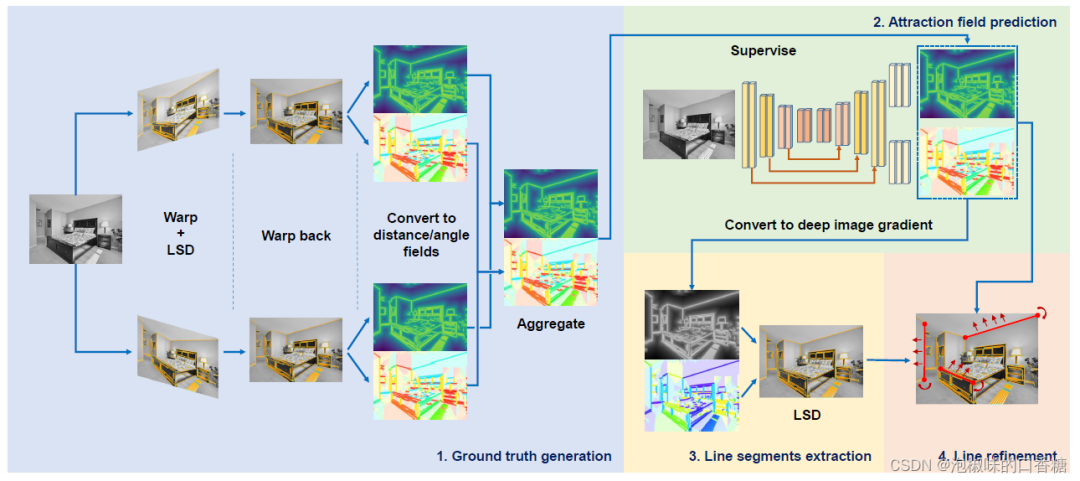
圖1 方法概述
作者所做主要貢獻如下:
(1) 提出了一種自舉當前檢測器的方法來在任意圖像上創建真實線吸引場。
(2) 引入了一個優化過程,可以同時優化線段和消失點。這種優化可以作為一種獨立的細化來提高任何現有的深度線檢測器的精度。
(3) 在多個需要線特征的下游任務中,通過結合深度學習方法的魯棒性和手工方法在單個pipeline中的精度,創造了新的記錄。
3.1 線吸引場
最早通過吸引場表示線段的方法是AFM,為圖像的每個像素回歸一個2D向量場,來表示直線上最近點的相對位置。
該方法允許將離散量(線段)表示為適合深度學習的平滑2通道圖像。然而,這種表示方法并不是獲得精確線段的最佳方法。
如圖2所示,比如HAWP那樣直接預測端點的位置需要很大的感受野,以便能夠從遙遠的端點獲取信息。
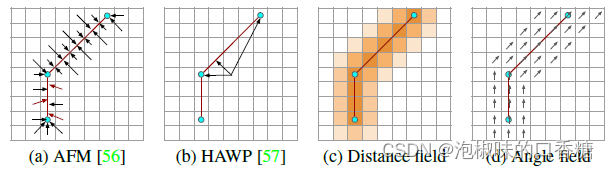
圖2 吸引場參數化。(a)對二維向量進行參數化可能會對小向量模產生噪聲角。(b) 向端點添加偏移量需要長程信息且對噪聲端點不具有魯棒性。作者提出將距離場(c)和線角度場(d)解耦。
而DeepLSD這項工作的巧妙之處在于,作者提出將網絡限制在一個較小的感受野,并使用傳統的啟發式方法來確定端點。
DeepLSD采用和HAWP類似的吸引場,但沒有額外的兩個指向端點的角度,只保留線距離場(DF)和線角度場(AF)。其中線距離場DF給出當前像素到直線上最近點的距離,線角度場AF返回最近直線的方向:
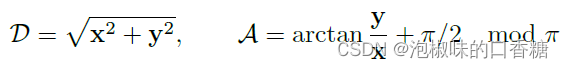
3.2 真值生成
為了學習線吸引場,需要ground truth。AFM和HAWP都是使用線框數據集的真值來監督。但DeepLSD的作者探索了一種新的方法,即通過引導先前的線檢測器來獲取真值。
具體來說,就是通過單應性自適應生成真值吸引場。給定單幅輸入圖像I,將其與N個隨機單應矩陣Hi進行wrap,在所有wrap后的圖像Ii中使用LSD檢測直線段,然后將其wrap回到I來得到線集合Li。
下一步是將所有的線聚合在一起,這一部分是個難點。作者的做法是將線條集合Li轉換為距離場Di和角度場Ai,并通過取所有圖像中每個像素(u, v)的中值來聚合:
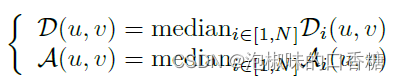
通過取中值,可以去除僅在少數圖像中檢測到的噪聲,結果如圖3所示。

圖3 偽GT可視化
3.3 學習線吸引場
為了回歸距離場和角度場,DeepLSD使用了UNet架構,尺寸為HxW的輸入圖像經多個卷積層處理,并通過連續3次平均池化操作逐步降采樣至8倍。
然后通過另一系列卷積層和雙線性插值將特征放大回原始分辨率。得到的深度特征被分成兩個分支,一個輸出距離場,一個輸出角度場。最后距離場通過反歸一化得到:
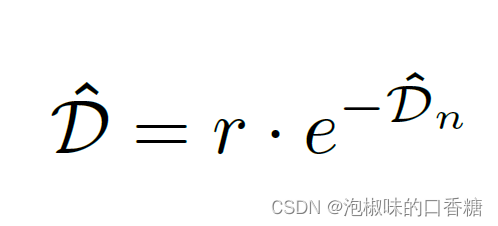
其中r是像素中的一個參數,它定義了每條線周圍的區域。由于手工方法主要需要線段附近的梯度信息,因此DeepLSD只對距離線段小于r個像素的像素進行監督。
總損失為距離場和角度場的損失之和:
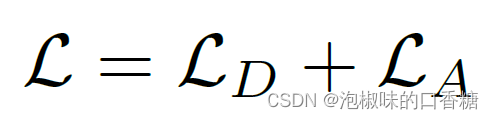
這里就沒啥可說的了,LD為歸一化距離場之間的L1損失,LA為L2角度損失:
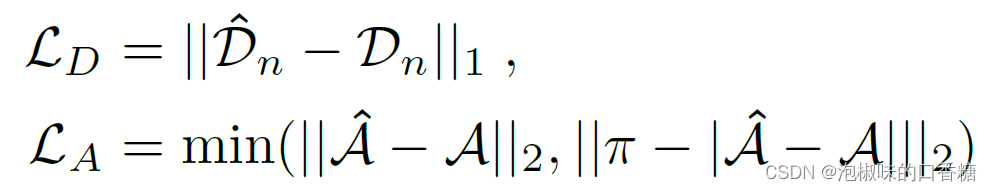
3.4.提取線段
由于LSD是基于圖像梯度的,因此需要將距離場和角度場轉換為替代圖像梯度幅度和角度:
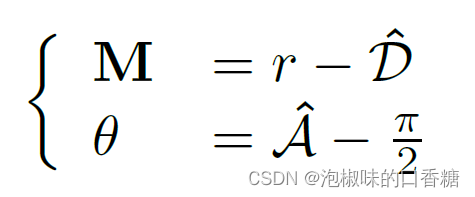
AFM和LSD方法的一個重要區別是梯度方向。對于黑暗與明亮區域分離的邊緣,LSD跟蹤從暗到亮的梯度方向,而AFM不跟蹤。
如圖4所示,當幾條平行線以暗-亮-暗或亮-暗-亮的模式相鄰出現時,這就變得很重要。
為了更好的精度和尺度不變性,DeepLSD檢測這些雙邊緣,并構造角度方向:
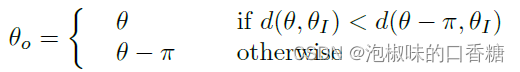
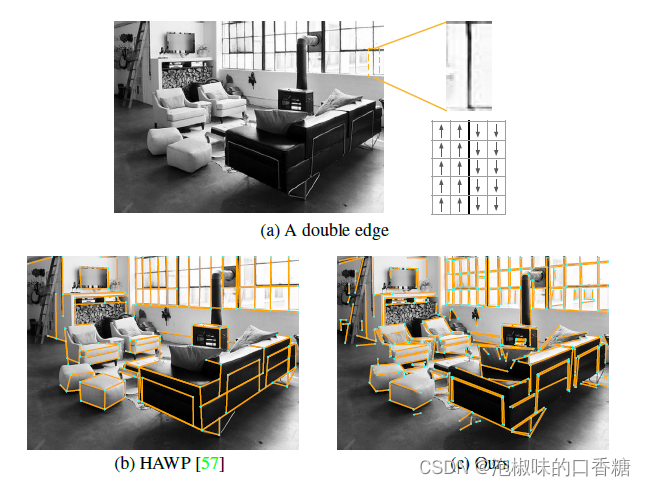
圖4 區分雙邊緣。(a) 亮-暗-亮邊緣和定向角度場的示例。(b) HAWP將其視為一條直線。(c) 為了準確,DeepLSD將其檢測為兩條線。
為了使線特征更加精確,作者還提出了一個優化步驟,即利用第二步預測的DF和AF來細化。需要注意的是,這種優化方法也可以用來增強任何其他深度探測器的線特征。
優化的核心思路是,在3D中平行的線將共享消失點。因此DeepLSD將其作為軟約束融入到優化中,有效地降低了自由度。
首先利用多模型擬合算法Progressive-X計算一組與預測線段相關的消失點(VPs)。然后對每條線段獨立進行優化,損失函數是三種不同成本的加權無約束最小二乘最小化:
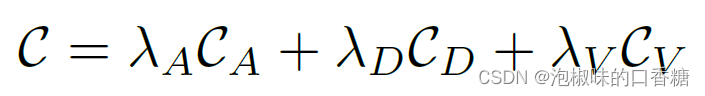
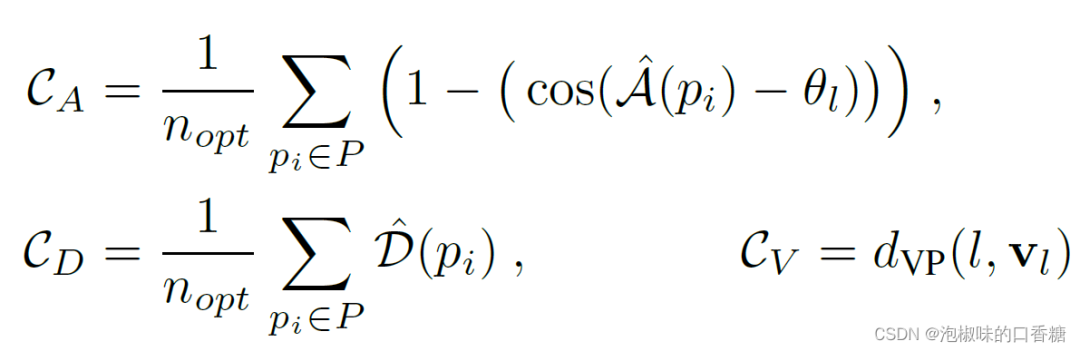
4. 實驗
作者訓練了DeepLSD的兩個版本,一個在室內Wireframe數據集,沒有使用GT線,一個室外MegaDepth數據集。
MegaDepth數據集保留150個場景用于訓練,17個場景用于驗證,每個場景只采集50張圖像。
在實驗細節上,使用Adam優化器和初始學習率為1e3,學習率調整策略為,當損失函數到達一定數值時學習率/10。
硬件條件為,在NVIDIA RTX 2080 GPU上訓練時間12小時。
4.1 直線檢測性能
作者首先在HPatches數據集和RDNIM數據集上評估直線檢測性能,其中HPatches數據集具有不同的光照和視點變化,RDNIM數據集具有挑戰性的晝夜變化相關的圖像對。
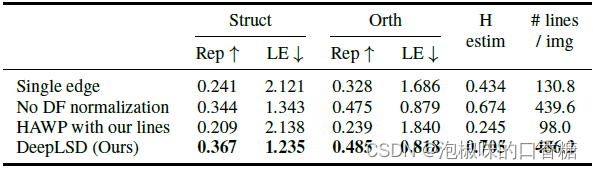
評價指標為重復性、定位誤差以及單應估計分數。重復性(Rep)衡量匹配誤差在3個像素以下的直線的比例,定位誤差(LE)返回50個最準確匹配的平均距離。表1和圖5所示是與經典線特征檢測器的對比結果。
表1 在HPatches和RDNIM數據集上的直線檢測評估
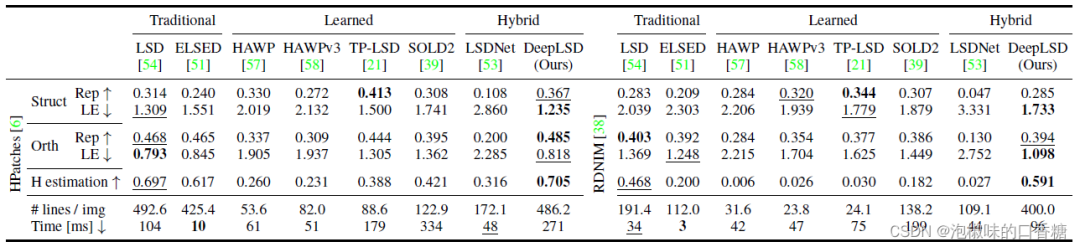

圖5 線段檢測示例
從結果來看,以TPLSD為首的學習方法具有較好的可重復性,但存在較低的定位誤差和不準確的單應矩陣估計。
手工方法和DeepLSD由于不直接對端點進行回歸,而是利用非常低的細節逐步增長線段,因此精度更高。
當變化最具挑戰性時,DeepLSD比LSD表現出最好的改善,即在晝夜變化強烈的RDNIM上。
可以顯著提高定位誤差和單應性估計分數。LSDNet由于通過將圖像縮放到固定的低分辨率而失去了準確性。
總體而言,DeepLSD在手工方法和學習方法之間提供了最佳的權衡,并且在單應性估計的下游任務中始終排名第一。
4.2 重建及定位
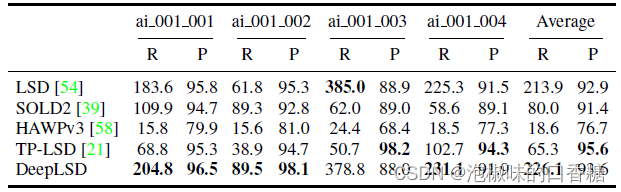
這項工作除了評估自身的線特征生成質量外,還進行了三維重建對比。作者利用Line3D++獲取一組已知姿態的圖像和相關的2D線段,并輸出線條的三維重建。
作者在Hypersim數據集的前4個場景上將DeepLSD與幾個基線進行比較。其中召回R為距離網格5 mm以內的所有線段的長度,單位為米,越高意味著許多線條被重建。精度P是距離網格5毫米以內的預測線的百分比,越高表明大部分預測的直線在真實的三維表面上。
結果如表2所示,DeepLSD總體上獲得了最好的召回和精度。TP-LSD雖然在召回上排名第一,但是能夠恢復的直線很少,其平均精度比DeepLSD小71 %。
值得注意的是,DeepLSD比LSD能夠重建更多的直線,且精度更高。
表2 線三維重建對比結果
作者在7Scenes數據集上進行了定位實驗,估計位姿精度,其中Stairs場景對于特征點的定位非常具有挑戰性。
圖6表明,DeepLSD在這個具有挑戰性的數據集上獲得了最好的性能。
與僅使用點相比,可以突出線特征帶來的性能的大幅提升。在室內環境中,線特征提取并定位的性能良好,即使在低紋理場景中也可以匹配。
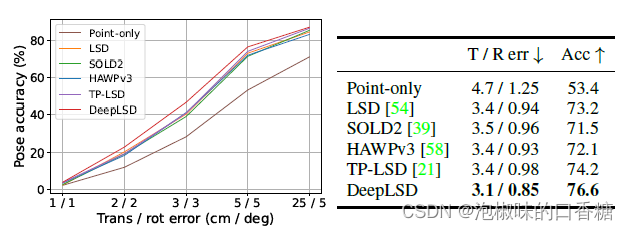
圖6 7Scenes數據集樓梯的視覺定位結果
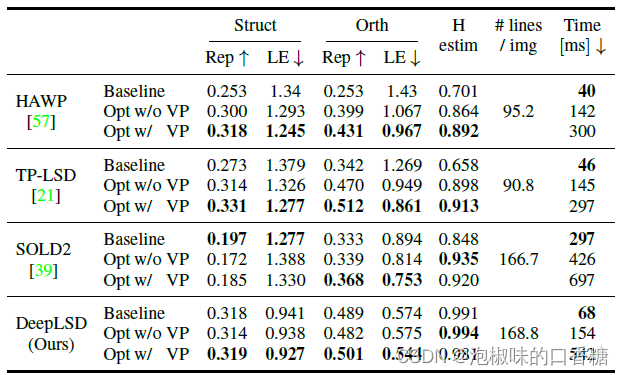
4.3 線優化的影響
作者還研究了優化步驟的影響。對于每種方法,作者將原始線條與優化后的線條和VP進行比較。
表3展示了線檢測器在Wireframe測試集的462張圖像上的檢測結果。結果顯示,優化可以顯著改善不精確方法的定位誤差和單應性得分,并顯著提高評價直線精度的所有指標。
特別是對于HAWP和TP-LSD,兩者的定位誤差都下降了32 %,單應性得分提高了27 %和39 %。
注意,優化并沒有給DeepLSD帶來多大提升,這是因為它的原始預測線已經是亞像素精確的,并且優化受到DF和AF分辨率的限制。
表3 Wireframe數據集上的線優化
4.4 消融研究
作者在HPatches數據集上用低級別檢測器指標驗證了設計選擇,將DeepLSD與單邊相同模型進行比較。表4展示了各組成部分的重要性。
值得注意的是,在DeepLSD上重新訓練HAWP會導致較差的結果,因為與線框線相比,線條的數量更多,而且一般的直線往往有噪聲的端點,因此預測到兩個端點的角度也是有噪聲的。
表4 HPatches數據集上的消融實驗
5. 結論
作者提出了一種混合線段檢測器,結合了深度學習的魯棒性和手工檢測器的準確性,并使用學習的替代圖像梯度作為中間表示。還提出了一種可以應用于現有深度檢測器的優化方法,彌補了深度檢測器和手工檢測器之間的線局部化的差距。
審核編輯:劉清
-
檢測器
+關注
關注
1文章
894瀏覽量
48693 -
SLAM
+關注
關注
24文章
441瀏覽量
32505 -
AFM
+關注
關注
0文章
60瀏覽量
20473
原文標題:DeepLSD:基于深度圖像梯度的線段檢測和細化
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種基于點、線和消失點特征的單目SLAM系統設計

給個思路也可以(不知道這個無線通信模塊怎么實現)
基于高光譜深度特征的油菜葉片鋅含量檢測
人臉識別技術的算法原理解析
使用機器學習改善庫特征提取的質量和運行時間
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
在RK3568教學實驗箱上實現基于YOLOV5的算法物體識別案例詳解
一種基于因果路徑的層次圖卷積注意力網絡

一種基于深度學習的二維拉曼光譜算法

AI大模型在圖像識別中的優勢
特征工程實施步驟






 工商網監
工商網監
評論