 國內最大自動駕駛智算中心發布,為何車企紛紛自建智算中心?
國內最大自動駕駛智算中心發布,為何車企紛紛自建智算中心?

電子發燒友網報道(文/李彎彎)前不久,毫末智行與火山引擎共同發布了中國自動駕駛行業最大的智算中心——毫末“雪湖·綠洲”(MANA OASIS)。據毫末智行CEO顧維灝介紹,MANA OASIS的算力高達67億億次/秒,存儲帶寬可達2T/秒,通信帶寬達到800G/秒,可以為自動駕駛技術的持續迭代提供充足動力。
不僅僅是自動駕駛車自身算力,智算中心也成為車企和自動駕駛公司競爭的焦點。眾所周知,自動駕駛行業的領軍企業特斯拉在幾年前就已經建立自己的智算中心,并且還自研芯片以提升效率。國內除了毫末智行,小鵬汽車在今年8月也宣布已經建成自動駕駛智算中心。
多方面優化,MANA OASIS訓練效率提升100倍
結合自動駕駛近十年的發展歷史,毫末智行認為,可以將近十年的自動駕駛技術發展分成三個階段:最早的硬件驅動方式,可以稱為自動駕駛的1.0時代;最近幾年的軟件驅動方式,可稱之為自動駕駛的2.0時代;即將發生,并將持續發展的數據驅動方式,是自動駕駛的3.0時代。數據驅動也是自動駕駛發展公認的方向,而它對智算中心的要求很高。
因此毫末和火山引擎共同定制了一個屬于自動駕駛的智算中心。具體來看,在系統架構方面,如下圖,左邊是高性能存儲,基于高性能并行文件系統VePFS,可以提供高達2T/s的讀取速度,并且支持百億級小文件高速讀寫。右邊是計算平臺,提供了充沛的算力,每臺服務器配置8個GPU卡,通過600G/s的雙向NVSwitch高速互聯,進行通信。服務器之間通過4張200G帶寬的RDMA網絡互聯,提供高達800G/s的網絡帶寬。
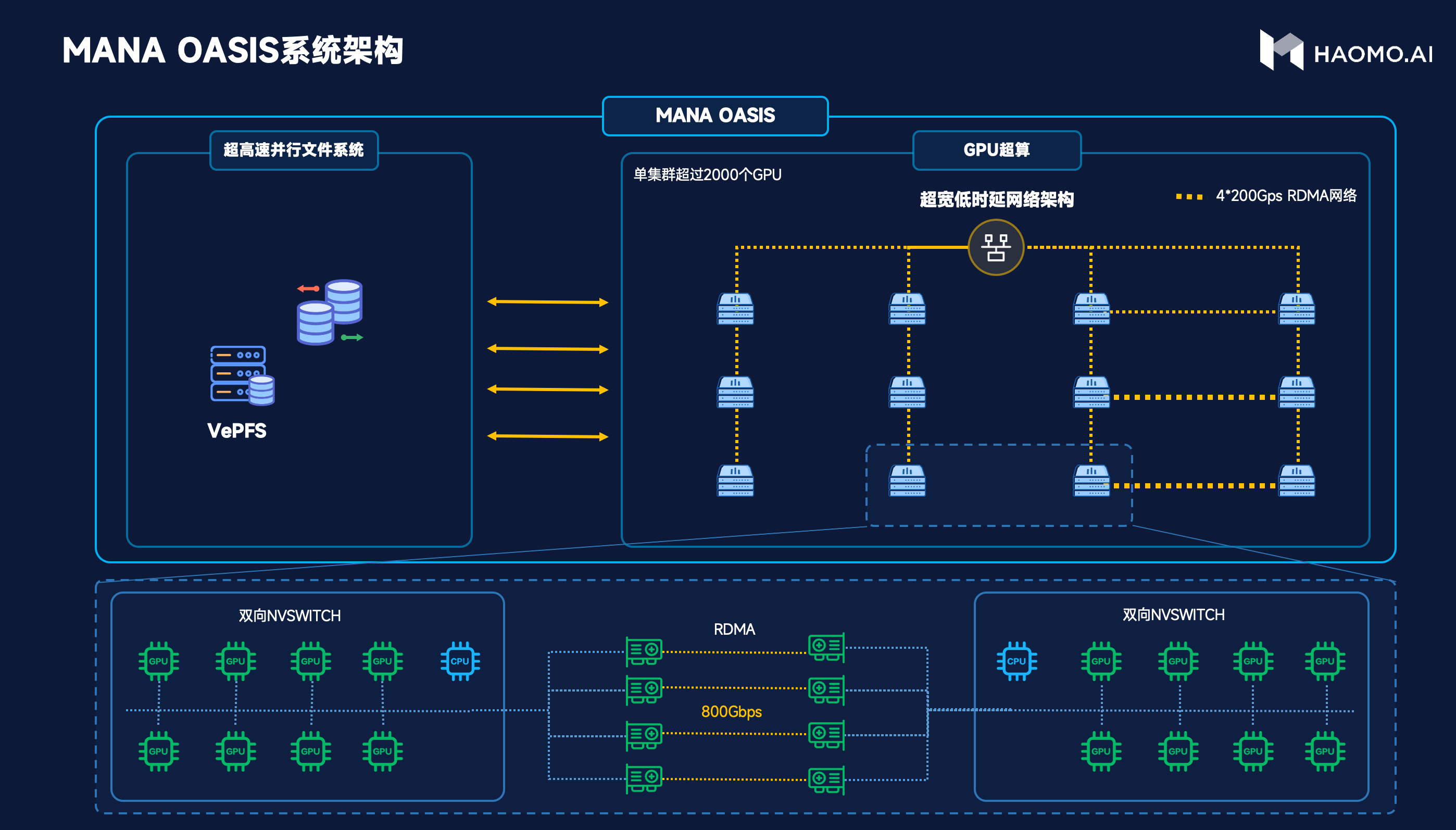
在數據管理上,為了充分發揮智算中心的價值,讓GPU持續飽和運行,毫末經過2年多研發,建立了全套面向大規模AI訓練的毫末文件系統。在采集端,把數據按照訓練的要求,以4D Clip為單位組織文件形態;在傳輸端,基于毫末場景庫,對數據進行場景化分析,打上各類Tag,方便模型基于Tag從不同維度對數據進行采樣、分布統計、語料提取;在訓練端,基于分級存儲理念,把對象存儲、高性能、顯存充分整合,實現高容量與高性能并存。
最終實現了百P數據篩選速度提升10倍、百億小文件隨機讀寫延遲小于500us。在毫末文件系統的加持下,消除數據瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓練加速上也做了大量優化。大家都知道,transformer大模型的訓練成本非常高,訓練一個大模型有時成本高達幾千萬。毫末在此方向深入研究,借鑒了學術界最新的研究成果,基于Sparse MoE,可以根據計算特點,進行稀疏激活,提高計算效率,實現單機8卡就能訓練百億參數大模型的效果。
毫末智算中心也實現了跨機共享expert的方法,完成千億參數規模大模型的訓練,而且訓練成本降低到百卡周級別。在此基礎上,毫末基于自己的業務特點,設計并實現了業界領先的多任務并行訓練系統,能同時處理圖片、點云、結構化文本等多種模態的信息,既保證了模型的稀疏性,又提升了計算效率。結合多方面的優化,毫末智算中心的訓練效率提升了100倍。
為何小鵬、特斯拉等車企要建立自己的智算中心
除了毫末智行,小鵬汽車、特斯拉等車企也已建設自己的智算中心。今年8月,小鵬汽車宣布在烏蘭察布建成當時中國最大的自動駕駛智算中心“扶搖”,用于自動駕駛模型訓練。“扶搖”基于阿里云智能計算平臺,算力可達600PFLOPS(每秒浮點運算60億億次),將小鵬自動駕駛核心模型的訓練速度提升了近170倍。
通過與阿里云合作,“扶搖”以更低成本實現了更強算力。具體來看,對GPU資源進行細粒度切分、調度,將GPU資源虛擬化利用率提高3倍,支持更多人同時在線開發,效率提升十倍以上。在通訊層面,端對端通信延遲降低80%至2微秒。
整體計算效率上,實現了算力的線性擴展。存儲吞吐比業界20GB/s的普遍水準提升了40倍,數據傳輸能力相當于從送快遞的微型面包車,換成了20多米長的40噸集裝箱重卡。此外,阿里云機器學習平臺PAI提供了模型訓練部署、推理優化等AI工程化工具,比開源框架訓練性能提升30%以上。
“扶搖”支持小鵬自動駕駛核心模型的訓練時長從7天,縮短至1小時內,大幅提速近170倍。據介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統的算法模型訓練。和高速道路相比,城市路段的交通狀況更為復雜,自動駕駛特殊場景的數據集規模增加了上百倍。
早幾年前,特斯拉就已經建立了自己的AI計算中心——Dojo,總計使用了1.4萬個英偉達的GPU來訓練AI模型。為了進一步提升效率,特斯拉在2021年發布了自研的AI加速芯片D1,25個D1封裝在一起組成一個訓練模塊(Training tile),然后再將訓練模塊組成一個機柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計算中心的最新進展,用自研的D1芯片打造的計算設備能夠提升30%的模型訓練效率。
可以看到,車企和自動駕駛公司自建智算中心,能夠在性能上進行多方面的優化,提升效率。此外在成本上也會更有利,何小鵬此前談到,對于智能汽車公司來說,算力成本將會從今天的億元級別上升到將來的十億元級別。因此,如果持續使用公有云服務,邊際成本將會不斷上漲。如果自行組建智算中心,一次性投資約在數千萬到1億元以內,長期來看性價比更高。
不僅僅是自動駕駛車自身算力,智算中心也成為車企和自動駕駛公司競爭的焦點。眾所周知,自動駕駛行業的領軍企業特斯拉在幾年前就已經建立自己的智算中心,并且還自研芯片以提升效率。國內除了毫末智行,小鵬汽車在今年8月也宣布已經建成自動駕駛智算中心。
多方面優化,MANA OASIS訓練效率提升100倍
結合自動駕駛近十年的發展歷史,毫末智行認為,可以將近十年的自動駕駛技術發展分成三個階段:最早的硬件驅動方式,可以稱為自動駕駛的1.0時代;最近幾年的軟件驅動方式,可稱之為自動駕駛的2.0時代;即將發生,并將持續發展的數據驅動方式,是自動駕駛的3.0時代。數據驅動也是自動駕駛發展公認的方向,而它對智算中心的要求很高。
因此毫末和火山引擎共同定制了一個屬于自動駕駛的智算中心。具體來看,在系統架構方面,如下圖,左邊是高性能存儲,基于高性能并行文件系統VePFS,可以提供高達2T/s的讀取速度,并且支持百億級小文件高速讀寫。右邊是計算平臺,提供了充沛的算力,每臺服務器配置8個GPU卡,通過600G/s的雙向NVSwitch高速互聯,進行通信。服務器之間通過4張200G帶寬的RDMA網絡互聯,提供高達800G/s的網絡帶寬。
在數據管理上,為了充分發揮智算中心的價值,讓GPU持續飽和運行,毫末經過2年多研發,建立了全套面向大規模AI訓練的毫末文件系統。在采集端,把數據按照訓練的要求,以4D Clip為單位組織文件形態;在傳輸端,基于毫末場景庫,對數據進行場景化分析,打上各類Tag,方便模型基于Tag從不同維度對數據進行采樣、分布統計、語料提取;在訓練端,基于分級存儲理念,把對象存儲、高性能、顯存充分整合,實現高容量與高性能并存。
最終實現了百P數據篩選速度提升10倍、百億小文件隨機讀寫延遲小于500us。在毫末文件系統的加持下,消除數據瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓練加速上也做了大量優化。大家都知道,transformer大模型的訓練成本非常高,訓練一個大模型有時成本高達幾千萬。毫末在此方向深入研究,借鑒了學術界最新的研究成果,基于Sparse MoE,可以根據計算特點,進行稀疏激活,提高計算效率,實現單機8卡就能訓練百億參數大模型的效果。
毫末智算中心也實現了跨機共享expert的方法,完成千億參數規模大模型的訓練,而且訓練成本降低到百卡周級別。在此基礎上,毫末基于自己的業務特點,設計并實現了業界領先的多任務并行訓練系統,能同時處理圖片、點云、結構化文本等多種模態的信息,既保證了模型的稀疏性,又提升了計算效率。結合多方面的優化,毫末智算中心的訓練效率提升了100倍。
為何小鵬、特斯拉等車企要建立自己的智算中心
除了毫末智行,小鵬汽車、特斯拉等車企也已建設自己的智算中心。今年8月,小鵬汽車宣布在烏蘭察布建成當時中國最大的自動駕駛智算中心“扶搖”,用于自動駕駛模型訓練。“扶搖”基于阿里云智能計算平臺,算力可達600PFLOPS(每秒浮點運算60億億次),將小鵬自動駕駛核心模型的訓練速度提升了近170倍。
通過與阿里云合作,“扶搖”以更低成本實現了更強算力。具體來看,對GPU資源進行細粒度切分、調度,將GPU資源虛擬化利用率提高3倍,支持更多人同時在線開發,效率提升十倍以上。在通訊層面,端對端通信延遲降低80%至2微秒。
整體計算效率上,實現了算力的線性擴展。存儲吞吐比業界20GB/s的普遍水準提升了40倍,數據傳輸能力相當于從送快遞的微型面包車,換成了20多米長的40噸集裝箱重卡。此外,阿里云機器學習平臺PAI提供了模型訓練部署、推理優化等AI工程化工具,比開源框架訓練性能提升30%以上。
“扶搖”支持小鵬自動駕駛核心模型的訓練時長從7天,縮短至1小時內,大幅提速近170倍。據介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統的算法模型訓練。和高速道路相比,城市路段的交通狀況更為復雜,自動駕駛特殊場景的數據集規模增加了上百倍。
早幾年前,特斯拉就已經建立了自己的AI計算中心——Dojo,總計使用了1.4萬個英偉達的GPU來訓練AI模型。為了進一步提升效率,特斯拉在2021年發布了自研的AI加速芯片D1,25個D1封裝在一起組成一個訓練模塊(Training tile),然后再將訓練模塊組成一個機柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計算中心的最新進展,用自研的D1芯片打造的計算設備能夠提升30%的模型訓練效率。
可以看到,車企和自動駕駛公司自建智算中心,能夠在性能上進行多方面的優化,提升效率。此外在成本上也會更有利,何小鵬此前談到,對于智能汽車公司來說,算力成本將會從今天的億元級別上升到將來的十億元級別。因此,如果持續使用公有云服務,邊際成本將會不斷上漲。如果自行組建智算中心,一次性投資約在數千萬到1億元以內,長期來看性價比更高。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
自動駕駛
+關注
關注
788文章
14259瀏覽量
170096 -
智算中心
+關注
關注
0文章
89瀏覽量
2019
發布評論請先 登錄
相關推薦
熱點推薦
新能源車軟件單元測試深度解析:自動駕駛系統視角
的潛在風險增加,尤其是在自動駕駛等安全關鍵系統中。根據ISO 26262標準,自動駕駛系統的安全完整性等級(ASIL-D)要求單點故障率必須低于10^-8/小時,這意味著每小時的故障概率需控制在億
發表于 05-12 15:59
信而泰CCL仿真:解鎖AI算力極限,智算中心網絡性能躍升之道
引言 隨著AI大模型訓練和推理需求的爆發式增長,智算中心網絡的高效性與穩定性成為決定AI產業發展的核心要素。信而泰憑借自主研發的 CCL(集合通信庫)評估工具 與 DarYu-X系列測試儀 ,為智算
智算中心的核心硬件是什么?
智算中心,作為人工智能時代的關鍵基礎設施,其核心硬件的構成與性能直接影響著智能計算的效率與質量。以下是對智算中心核心硬件的詳細闡述:一、AI芯片AI芯片是專門為加速人工智能計算而設計的

算智算中心的算力如何衡量?
作為當下科技發展的重要基礎設施,其算力的衡量關乎其能否高效支撐人工智能、大數據分析等智能應用的運行。以下是對智算中心算力衡量的詳細闡述:一、算力的基本定義與單位1、
智算中心會取代通用算力中心嗎?
隨著人工智能(AI)技術的飛速發展,計算需求不斷攀升,數據中心行業正經歷著前所未有的變革。傳統的通用算力中心與新興的智算中心之間的競爭日益激
智算中心崛起:數字化時代的新核心基礎設施
隨著數字化時代的到來,我們的生活、工作、甚至整個社會的運行都離不開“算力”的支撐。為了更高效地處理這些海量的計算需求,一種新的基礎設施應運而生——智算中心。那么,智算
寧暢助推智算中心發展邁入新階段
在“全局智算”戰略下,寧暢正式發布“全棧全液”AI基礎設施方案 ,在業內首先實現了“全棧全液”的智算中心建設能力,助推智算
OCTC發布"算力工廠"!力促智算中心高效規劃建設投運
創新提出面向未來數據中心的"算力工廠"模式,核心是以規(劃)、建(設)、運(營)一體化的交鑰匙工程,實現智算中心快速投運、綠色低碳,在當前AIGC算

中國移動智算中心(哈爾濱)成為最大單集群智算中心
9月6日最新資訊,中國移動智算中心(哈爾濱)正式宣告投入運營,這一里程碑事件不僅標志著中國移動在智能計算領域的又一重大突破,更確立了其在全球運營商中擁有最大規模單集群智算
FPGA在自動駕駛領域有哪些應用?
FPGA(Field-Programmable Gate Array,現場可編程門陣列)在自動駕駛領域具有廣泛的應用,其高性能、可配置性、低功耗和低延遲等特點為自動駕駛的實現提供了強有力的支持。以下
發表于 07-29 17:09
中國算力中心市場持續增長,智能算力規模快速崛起
7月24日,中國信息通信研究院(簡稱“中國信通院”)權威發布了《中國算力中心服務商分析報告(2024年)》,該報告深入剖析了中國算力中心市場
智算中心加速布局,上游計算、存儲、互聯都涉及哪些芯片技術
的人工智能應用需求。 ? 近期,中國各地紛紛加快數字基建項目的建設步伐,智算中心成為布局重點。從北京到四川,從寧夏到河南,多地智算中心項目相
壁仞科技為中國移動呼和浩特智算中心提供強大算力
? 隨著人工智能技術的飛速發展,高性能計算中心成為推動AI創新和應用的關鍵基礎設施。近日,中國移動智算中心(呼和浩特)成功上線運營。國內領先的GPU企業壁仞科技的壁礪系列通用GPU





 工商網監
工商網監
評論