") 18種接口優(yōu)化方案匯總2
18種接口優(yōu)化方案匯總2
6. 事件回調(diào)思想:拒絕阻塞等待。
如果你調(diào)用一個系統(tǒng)B的接口,但是它處理業(yè)務(wù)邏輯,耗時需要10s甚至更多。然后你是一直 阻塞等待,直到系統(tǒng)B的下游接口返回 ,再繼續(xù)你的下一步操作嗎?這樣 顯然不合理 。
我們參考 IO多路復(fù)用模型 。即我們不用阻塞等待系統(tǒng)B的接口,而是先去做別的操作。等系統(tǒng)B的接口處理完,通過事件回調(diào)通知,我們接口收到通知再進行對應(yīng)的業(yè)務(wù)操作即可。
如果大家忘記了IO模型,可以復(fù)習一下我的文章:看一遍就理解:IO模型詳解
7. 遠程調(diào)用由串行改為并行
假設(shè)我們設(shè)計一個APP首頁的接口,它需要查用戶信息、需要查banner信息、需要查彈窗信息等等。如果是串行一個一個查,比如查用戶信息200ms,查banner信息100ms、查彈窗信息50ms,那一共就耗時350ms了,如果還查其他信息,那耗時就更大了。
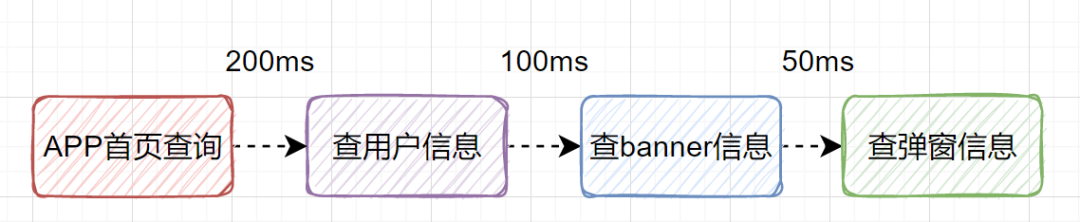
其實我們可以改為并行調(diào)用,即查用戶信息、查banner信息、查彈窗信息,可以同時 并行發(fā)起 。
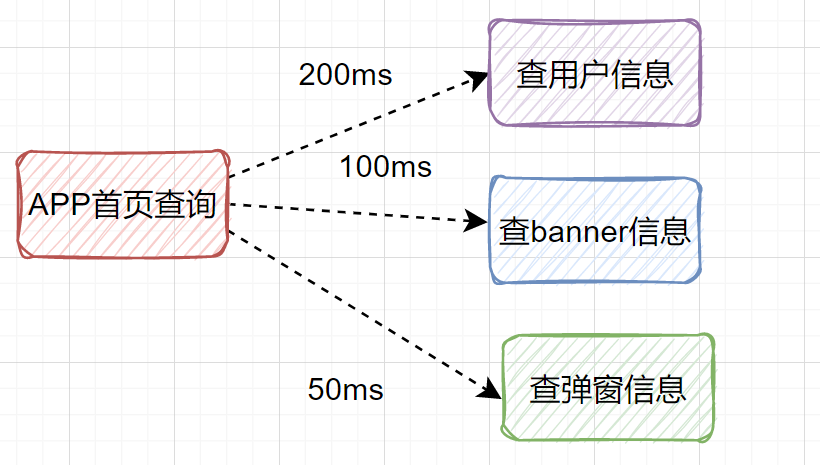
最后接口耗時將大大降低 。有些小伙伴說,不知道如何使用并行優(yōu)化接口?
我之前寫過一篇文章并行優(yōu)化接口的文章,保姆級別的!大家可以看一下,看完會有用的:后端思維篇,手把手教你寫一個并行調(diào)用模板
8. 鎖粒度避免過粗
在高并發(fā)場景,為了防止 超賣等情況 ,我們經(jīng)常需要 加鎖來保護共享資源 。但是,如果加鎖的粒度過粗,是很影響接口性能的。
什么是加鎖粒度呢?
其實就是就是你要鎖住的范圍是多大。 比如你在家上衛(wèi)生間,你只要鎖住衛(wèi)生間就可以了吧 ,不需要將整個家都鎖起來不讓家人進門吧,衛(wèi)生間就是你的加鎖粒度。
不管你是synchronized加鎖還是redis分布式鎖,只需要在共享臨界資源加鎖即可,不涉及共享資源的,就不必要加鎖。這就好像你上衛(wèi)生間,不用把整個家都鎖住,鎖住衛(wèi)生間門就可以了。
比如,在業(yè)務(wù)代碼中,有一個ArrayList因為涉及到多線程操作,所以需要加鎖操作,假設(shè)剛好又有一段比較耗時的操作(代碼中的slowNotShare方法)不涉及線程安全問題。 反例加鎖,就是一鍋端,全鎖住 :
//不涉及共享資源的慢方法
private void slowNotShare() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
}
}
//錯誤的加鎖方法
public int wrong() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
//加鎖粒度太粗了,slowNotShare其實不涉及共享資源
synchronized (this) {
slowNotShare();
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
正例:
public int right() {
long beginTime = System.currentTimeMillis();
IntStream.rangeClosed(1, 10000).parallel().forEach(i -> {
slowNotShare();//可以不加鎖
//只對List這部分加鎖
synchronized (data) {
data.add(i);
}
});
log.info("cosume time:{}", System.currentTimeMillis() - beginTime);
return data.size();
}
9. 切換存儲方式:文件中轉(zhuǎn)暫存數(shù)據(jù)
如果數(shù)據(jù)太大,落地數(shù)據(jù)庫實在是慢的話, 就可以考慮先用文件的方式暫存 。先保存文件,再異步 下載文件,慢慢保存到數(shù)據(jù)庫 。
這里可能會有點抽象,給大家分享一個,我之前的一個真實的優(yōu)化案例吧。
之前開發(fā)了一個轉(zhuǎn)賬接口。如果是并發(fā)開啟,10個并發(fā)度,每個批次
1000筆轉(zhuǎn)賬明細數(shù)據(jù),數(shù)據(jù)庫插入會特別耗時, 大概6秒左右 ;這個跟我們公司的數(shù)據(jù)庫同步機制有關(guān),并發(fā)情況下,因為優(yōu)先保證同步,所以并行的插入變成串行啦,就很耗時。
優(yōu)化前 ,1000筆明細轉(zhuǎn)賬數(shù)據(jù),先落地DB數(shù)據(jù)庫,返回處理中給用戶,再異步轉(zhuǎn)賬。如圖:
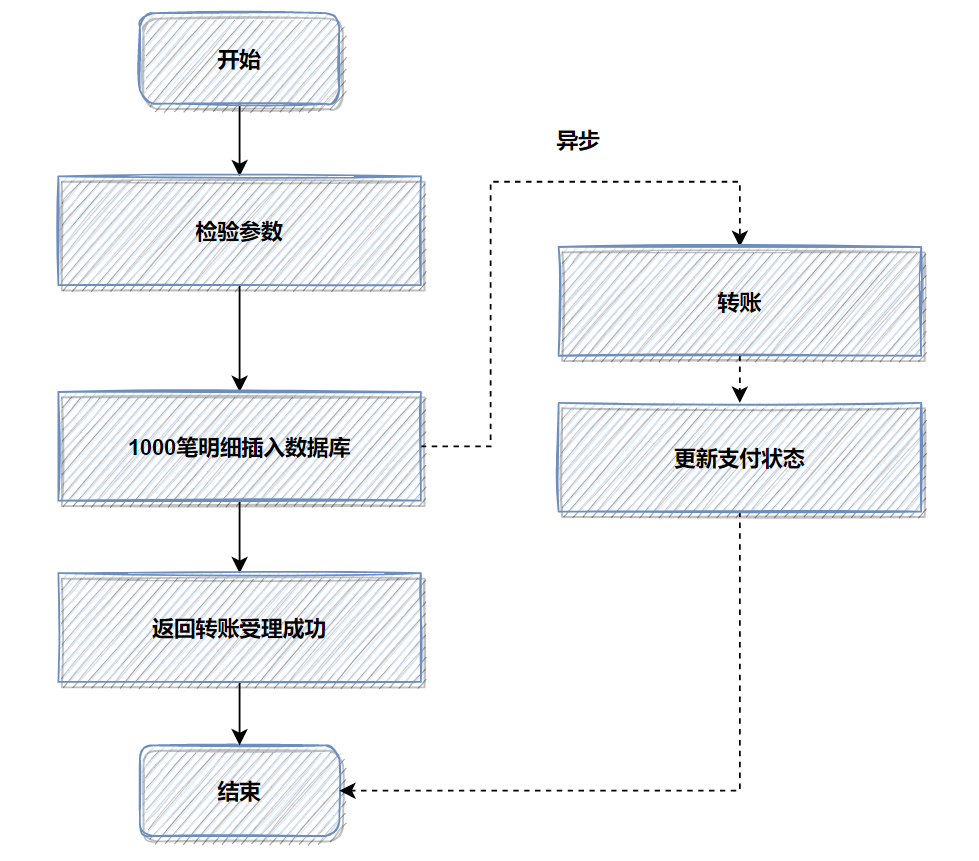
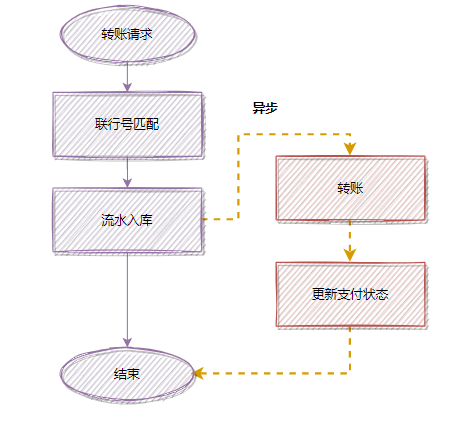
記得當時壓測的時候,高并發(fā)情況,這1000筆明細入庫,耗時都比較大。所以我轉(zhuǎn)換了一下思路, 把批量的明細轉(zhuǎn)賬記錄保存的文件服務(wù)器,然后記錄一筆轉(zhuǎn)賬總記錄到數(shù)據(jù)庫即可 。接著異步再把明細下載下來,進行轉(zhuǎn)賬和明細入庫。最后優(yōu)化后,性能提升了 十幾倍 。
優(yōu)化后 ,流程圖如下:
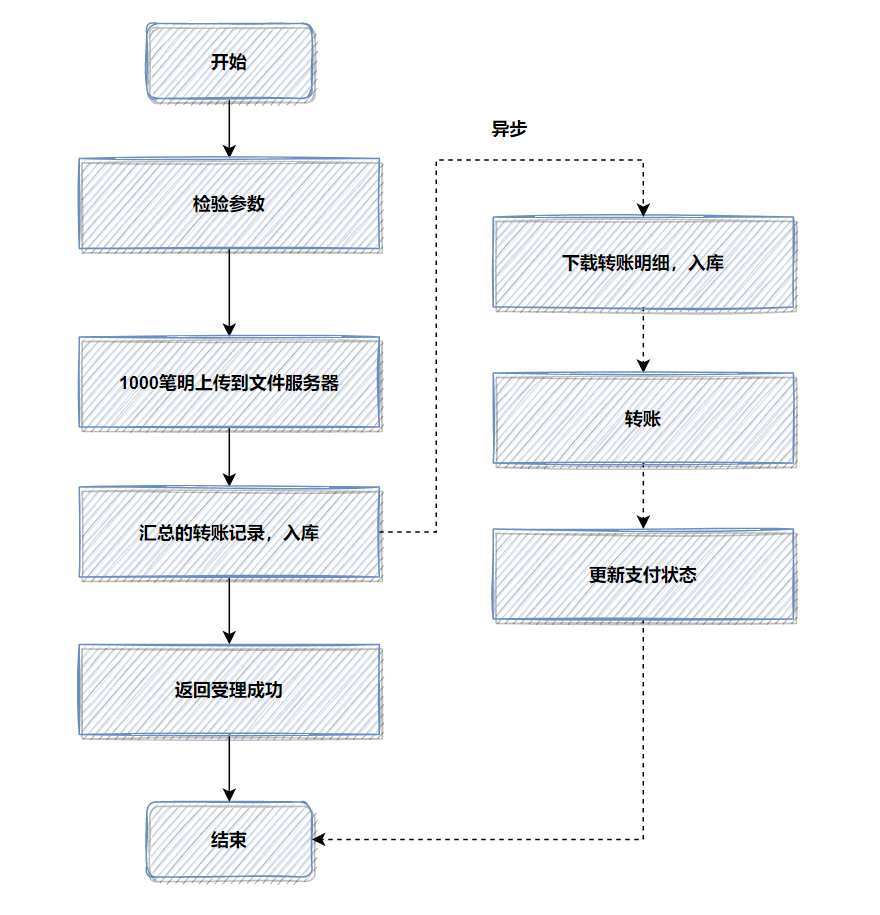
如果你的接口耗時瓶頸就 在數(shù)據(jù)庫插入操作這里 ,用來批量操作等,還是效果還不理想,就可以考慮用文件或者MQ等暫存。有時候批量數(shù)據(jù)放到文件,會比插入數(shù)據(jù)庫效率更高。
10. 索引
提到接口優(yōu)化,很多小伙伴都會想到 添加索引 。沒錯, 添加索引是成本最小的優(yōu)化 ,而且一般優(yōu)化效果都很不錯。
索引優(yōu)化這塊的話,一般從這幾個維度去思考:
- 你的SQL加索引了沒?
- 你的索引是否真的生效?
- 你的索引建立是否合理?
10.1 SQL沒加索引
我們開發(fā)的時候,容易疏忽而忘記給SQL添加索引。所以我們在寫完SQL的時候,就順手查看一下 explain執(zhí)行計劃。
explain select * from user_info where userId like '%123';
你也可以通過命令show create table ,整張表的索引情況。
show create table user_info;
如果某個表忘記添加某個索引,可以通過alter table add index命令添加索引
alter table user_info add index idx_name (name);
一般就是:SQL的where條件的字段,或者是order by 、group by后面的字段需需要添加索引。
10.2 索引不生效
有時候,即使你添加了索引,但是索引會失效的。 田螺哥整理了索引失效的常見原因 :
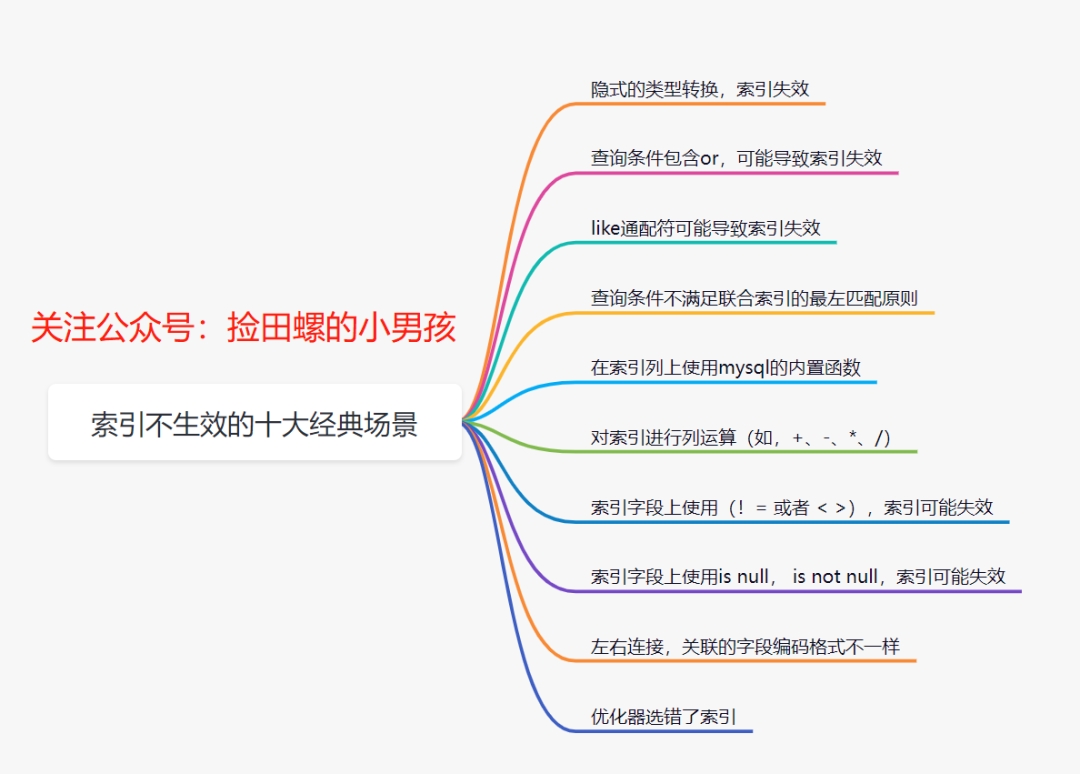
10.3 索引設(shè)計不合理
我們的索引不是越多越好,需要合理設(shè)計。比如:
- 刪除冗余和重復(fù)索引。
- 索引一般不能超過
5個 - 索引不適合建在有大量重復(fù)數(shù)據(jù)的字段上、如性別字段
- 適當使用覆蓋索引
- 如果需要使用
force index強制走某個索引,那就需要思考你的索引設(shè)計是否真的合理了
11. 優(yōu)化SQL
處了索引優(yōu)化,其實SQL還有很多其他有優(yōu)化的空間。
-
接口優(yōu)化
+關(guān)注
關(guān)注
0文章
4瀏覽量
1398
發(fā)布評論請先 登錄
介紹一種基于FIFO結(jié)構(gòu)的優(yōu)化端點設(shè)計方案
分享一種基于littlevgl2rtt軟件包的RGB屏幕接口優(yōu)化方案
使用MSSP模塊進行I2C串行EEPROM與PIC18器件的接口設(shè)計
18種接口優(yōu)化方案匯總1





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論