") ICLR 2023 Spotlight:2D圖像轉(zhuǎn)換3D
ICLR 2023 Spotlight:2D圖像轉(zhuǎn)換3D
背景
利用 NeRF 提供的可微渲染算法,三維生成算法,例如 EG3D、StyleSDF,在靜態(tài)物體類別的生成上已經(jīng)有了非常好的效果。但是人體相較于人臉或者 CAD 模型等類別,在外觀和幾何上有更大的復(fù)雜度,并且人體是可形變的,因此從二維圖片中學(xué)習(xí)三維人體生成仍然是非常困難的任務(wù)。研究人員在這個(gè)任務(wù)上已經(jīng)有了一些嘗試,例如 ENARF-GAN、GNARF,但是受限于低效的人體表達(dá),他們無(wú)法實(shí)現(xiàn)高分辨率的生成,因此生成質(zhì)量也非常低。
為了解決這個(gè)問題,本文提出了高效的組合的三維人體 NeRF 表示,用以實(shí)現(xiàn)高分辨率的(512x256)三維人體 GAN 訓(xùn)練與生成。下面將介紹本文提出的人體 NeRF 表示,以及三維人體 GAN 訓(xùn)練框架。
高效的人體 NeRF 表示
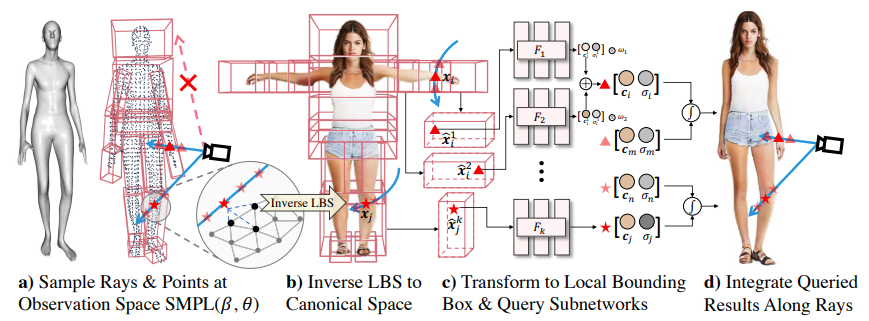
本文提出的人體 NeRF 基于參數(shù)化人體模型 SMPL,它提供了方便的人體姿勢(shì)以及形狀的控制。進(jìn)行 NeRF 建模時(shí),如下圖所示,本文將人體分為 16 個(gè)部分。每一個(gè)部分對(duì)應(yīng)于一個(gè)小的 NeRF 網(wǎng)絡(luò)進(jìn)行局部的建模。在渲染每一個(gè)局部的時(shí)候,本文只需要推理局部 NeRF。這種稀疏的渲染方式,在較低的計(jì)算資源下,也可以實(shí)現(xiàn)原生高分辨率的渲染。
例如,渲染體型動(dòng)作參數(shù)分別為的人體時(shí),首先根據(jù)相機(jī)參數(shù)采樣光線;光線上的采樣點(diǎn)根據(jù)與 SMPL 模型的相對(duì)關(guān)系進(jìn)行反向蒙皮操作(inverse linear blend skinning),將 posed 空間中的采樣點(diǎn)轉(zhuǎn)化到 canonical 空間中。接著計(jì)算 Canonical 空間的采樣點(diǎn)屬于某個(gè)或者某幾個(gè)局部 NeRF 的 bounding box 中,再進(jìn)行 NeRF 模型的推理,得到每個(gè)采樣點(diǎn)對(duì)應(yīng)的顏色與密度;當(dāng)某個(gè)采樣點(diǎn)落到多個(gè)局部 NeRF 的重疊區(qū)域,則會(huì)對(duì)每個(gè) NeRF 模型進(jìn)行推理,將多個(gè)結(jié)果用 window function 進(jìn)行插值;最后這些信息被用于光線的積分,得到最終的渲染圖。
三維人體 GAN 框架
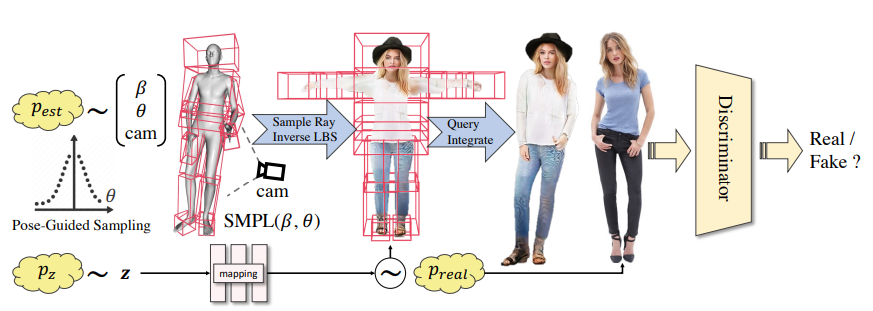
基于提出的高效的人體 NeRF 表達(dá),本文實(shí)現(xiàn)了三維人體 GAN 訓(xùn)練框架。在每一次訓(xùn)練迭代中,本文首先從數(shù)據(jù)集中采樣一個(gè) SMPL 的參數(shù)以及相機(jī)參數(shù),并隨機(jī)生成一個(gè)高斯噪聲 z。利用本文提出的人體 NeRF,本文可以將采樣出的參數(shù)渲染成一張二維人體圖片,作為假樣本。再利用數(shù)據(jù)集中的真實(shí)樣本,本文進(jìn)行 GAN 的對(duì)抗訓(xùn)練。
極度不平衡的數(shù)據(jù)集
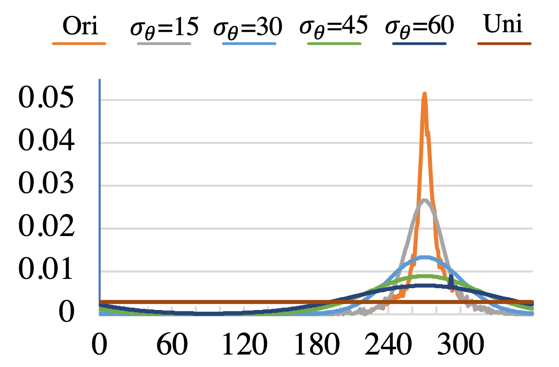
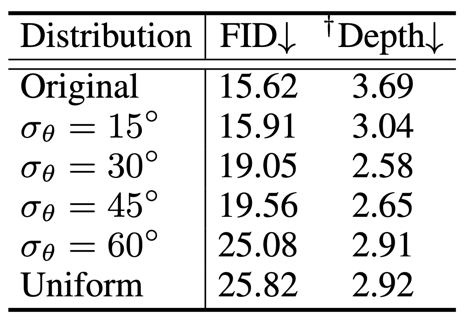
二維人體數(shù)據(jù)集,例如 DeepFashion,通常是為二維視覺任務(wù)準(zhǔn)備的,因此人體的姿態(tài)多樣性非常受限。為了量化不平衡的程度,本文統(tǒng)計(jì)了 DeepFashion 中模特臉部朝向的頻率。如下圖所示,橙色的線代表了 DeepFashion 中人臉朝向的分布,可見是極度不平衡的,對(duì)于學(xué)習(xí)三維人體表征造成了困難。為了緩解這一問題,我們提出了由人體姿態(tài)指導(dǎo)的采樣方式,將分布曲線拉平,如下圖中其他顏色的線所示。這可以讓訓(xùn)練過程中的模型見到更多樣以及更大角度的人體圖片,從而幫助三維人體幾何的學(xué)習(xí)。我們對(duì)采樣參數(shù)進(jìn)行了實(shí)驗(yàn)分析,從下面的表格中可見,加上人體姿態(tài)指導(dǎo)的采樣方式后,雖然圖像質(zhì)量(FID)會(huì)有些微下降,但是學(xué)出的三維幾何(Depth)顯著變好。
高質(zhì)量的生成結(jié)果
下圖展示了一些 EVA3D 的生成結(jié)果,EVA3D 可以隨機(jī)采樣人體樣貌,并可控制渲染相機(jī)參數(shù),人體姿勢(shì)以及體型。

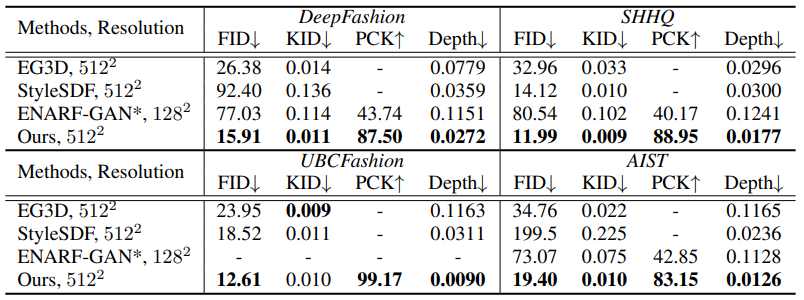
本文在四個(gè)大規(guī)模人體數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),分別是 DeepFashion,SHHQ,UBCFashion,AIST。該研究對(duì)比了最先進(jìn)的靜態(tài)三維物體生成算法 EG3D 與 StyleSDF。同時(shí)研究者也比較了專門針對(duì)三維人生成的算法 ENARF-GAN。在指標(biāo)的選擇上,本文兼顧渲染質(zhì)量的評(píng)估(FID/KID)、人體控制的準(zhǔn)確程度(PCK)以及幾何生成的質(zhì)量(Depth)。如下圖所示,本文在所有數(shù)據(jù)集,所有指標(biāo)上均大幅超越之前的方案。
應(yīng)用潛力
最后,本文也展示了 EVA3D 的一些應(yīng)用潛力。首先,該研究測(cè)試了在隱空間中進(jìn)行差值。如下圖所示,本文能夠在兩個(gè)三維人之間進(jìn)行平滑的變化,且中間結(jié)果均保持較高的質(zhì)量。此外,本文也進(jìn)行了 GAN inversion 的實(shí)驗(yàn),研究者使用二維 GAN inversion 中常用的算法 Pivotal Tuning Inversion。如下面右圖所示,該方法可以較好的還原重建目標(biāo)的外觀,但是幾何部分丟失了很多細(xì)節(jié)。可見,三維 GAN 的 inversion 仍然是一個(gè)很有挑戰(zhàn)性的任務(wù)。

結(jié)語(yǔ)
本文提出了首個(gè)高清三維人體 NeRF 生成算法 EVA3D,并且僅需使用二維人體圖像數(shù)據(jù)即可訓(xùn)練。EVA3D 在多個(gè)大規(guī)模人體數(shù)據(jù)集上性能達(dá)到最佳,并且展現(xiàn)出了在下游任務(wù)上進(jìn)行應(yīng)用的潛力。EVA3D 的訓(xùn)練與測(cè)試代碼均已經(jīng)開源,歡迎大家前去試用!
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4699瀏覽量
94763 -
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41033 -
GaN
+關(guān)注
關(guān)注
19文章
2177瀏覽量
76178
原文標(biāo)題:ICLR 2023 Spotlight | 2D圖像轉(zhuǎn)換3D
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何同時(shí)獲取2d圖像序列和相應(yīng)的3d點(diǎn)云?
請(qǐng)問怎么才能將AD中的3D封裝庫(kù)轉(zhuǎn)換為2D的封裝庫(kù)?
為什么3D與2D模型不能相互轉(zhuǎn)換?
全球首款2D/3D視頻轉(zhuǎn)換實(shí)時(shí)處理芯片:DA8223
2D到3D視頻自動(dòng)轉(zhuǎn)換系統(tǒng)
如何把OpenGL中3D坐標(biāo)轉(zhuǎn)換成2D坐標(biāo)
微軟新AI框架可在2D圖像上生成3D圖像
阿里研發(fā)全新3D AI算法,2D圖片搜出3D模型
谷歌發(fā)明的由2D圖像生成3D圖像技術(shù)解析

3d人臉識(shí)別和2d人臉識(shí)別的區(qū)別
如何直接建立2D圖像中的像素和3D點(diǎn)云中的點(diǎn)之間的對(duì)應(yīng)關(guān)系
使用Python從2D圖像進(jìn)行3D重建過程詳解

2D與3D視覺技術(shù)的比較
一文了解3D視覺和2D視覺的區(qū)別
AN-1249:使用ADV8003評(píng)估板將3D圖像轉(zhuǎn)換成2D圖像






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論