 Linux內核內存性能調優
Linux內核內存性能調優
前言
在工作生活中,我們時常會遇到一些性能問題:比如手機用久了,在滑動窗口或點擊 APP 時會出現頁面反應慢、卡頓等情況;比如運行在某臺服務器上進程的某些性能指標(影響用戶體驗的 PCT99 指標等)不達預期,產生告警等;造成性能問題的原因多種多樣,可能是網絡延遲高、磁盤 IO 慢、調度延遲高、內存回收等,這些最終都可能影響到用戶態進程,進而被用戶感知。
在 Linux 服務器場景中,內存是影響性能的主要因素之一,本文從內存管理的角度,總結歸納了一些常見的影響因素(比如內存回收、Page Fault 增多、跨 NUMA 內存訪問等),并介紹其對應的調優方法。
內存回收
操作系統總是會盡可能利用速度更快的存儲介質來緩存速度更慢的存儲介質中的內容,這樣就可以顯著的提高用戶訪問速度。比如,我們的文件一般都存儲在磁盤上,磁盤對于程序運行的內存來說速度很慢,因此操作系統在讀寫文件時,都會將磁盤中的文件內容緩存到內存上(也叫做 page cache),這樣下次再讀取到相同內容時就可以直接從內存中讀取,不需要再去訪問速度更慢的磁盤,從而大大提高文件的讀寫效率。
上述情況需要在內存資源充足的前提條件下,然而在內存資源緊缺時,操作系統自身難保,會選擇盡可能回收這些緩存的內存,將其用到更重要的任務中去。這時候,如果用戶再去訪問這些文件,就需要訪問磁盤,如果此時磁盤也很繁忙,那么用戶就會感受到明顯的卡頓,也就是性能變差了。
在 Linux 系統中,內存回收分為兩個層面:整機和 memory cgroup。
在整機層面
設置了三條水線:min、low、high;當系統 free 內存降到 low 水線以下時,系統會喚醒kswapd 線程進行異步內存回收,一直回收到 high 水線為止,這種情況不會阻塞正在進行內存分配的進程;但如果 free 內存降到了 min 水線以下,就需要阻塞內存分配進程進行回收,不然就有 OOM(out of memory)的風險,這種情況下被阻塞進程的內存分配延遲就會提高,從而感受到卡頓。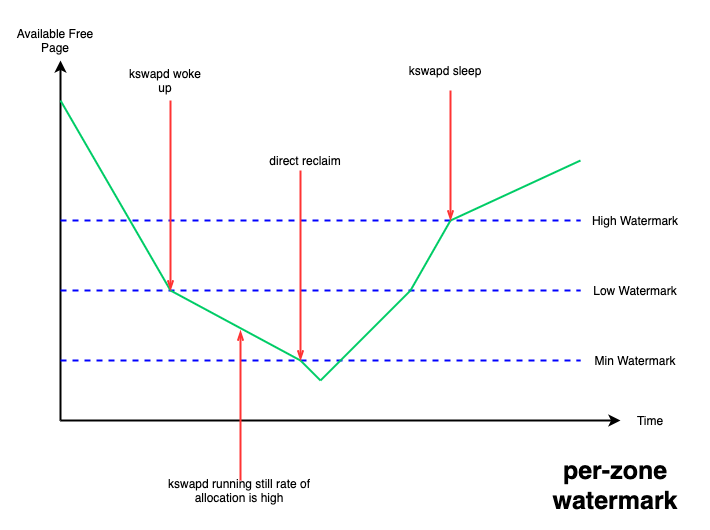
圖 1. per-zone watermark
這些水線可以通過內核提供的 /proc/sys/vm/watermark_scale_factor 接口來進行調整,該接口合法取值的范圍為 [0, 1000],默認為 10,當該值設置為 1000 時,意味著 low 與 min 水線,以及 high 與 low 水線間的差值都為總內存的 10% (1000/10000)。
針對 page cache 型的業務場景,我們可以通過該接口抬高 low 水線,從而更早的喚醒 kswapd 來進行異步的內存回收,減少 free 內存降到 min 水線以下的概率,從而避免阻塞到業務進程,以保證影響業務的性能指標。
在 memory cgroup 層面
目前內核沒有設置水線的概念,當內存使用達到 memory cgroup 的內存限制后,會阻塞當前進程進行內存回收。不過內核在 v5.19內核 中為 memory cgroup提供了 memory.reclaim 接口,用戶可以向該接口寫入想要回收的內存大小,來提早觸發 memory cgroup 進行內存回收,以避免阻塞 memory cgroup 中的進程。
Huge Page
內存作為寶貴的系統資源,一般都采用延遲分配的方式,應用程序第一次向分配的內存寫入數據的時候會觸發 Page Fault,此時才會真正的分配物理頁,并將物理頁幀填入頁表,從而與虛擬地址建立映射。
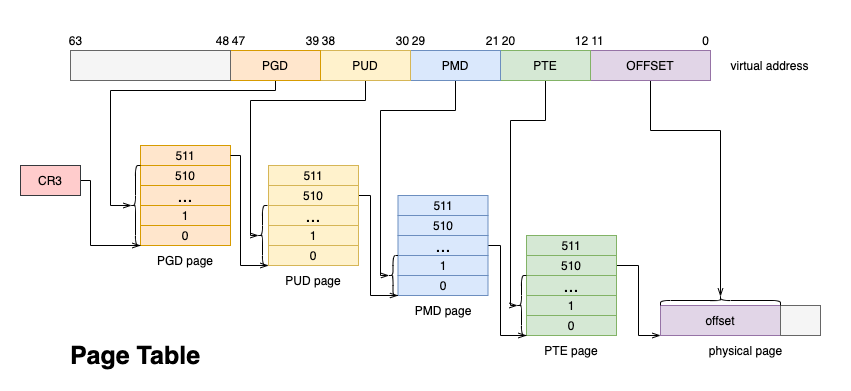
圖 2. Page Table
此后,每次 CPU 訪問內存,都需要通過 MMU 遍歷頁表將虛擬地址轉換成物理地址。為了加速這一過程,一般都會使用 TLB(Translation-Lookaside Buffer)來緩存虛擬地址到物理地址的映射關系,只有 TLB cache miss 的時候,才會遍歷頁表進行查找。
頁的默認大小一般為 4K,隨著應用程序越來越龐大,使用的內存越來越多,內存的分配與地址翻譯對性能的影響越加明顯。試想,每次訪問新的 4K 頁面都會觸發 Page Fault,2M 的頁面就需要觸發 512 次才能完成分配。
另外 TLB cache 的大小有限,過多的映射關系勢必會產生 cacheline 的沖刷,被沖刷的虛擬地址下次訪問時又會產生 TLB miss,又需要遍歷頁表才能獲取物理地址。
對此,Linux 內核提供了大頁機制。上圖的 4 級頁表中,每個 PTE entry 映射的物理頁就是 4K,如果采用 PMD entry 直接映射物理頁,則一次 Page Fault 可以直接分配并映射 2M 的大頁,并且只需要一個 TLB entry 即可存儲這 2M 內存的映射關系,這樣可以大幅提升內存分配與地址翻譯的速度。
因此,一般推薦占用大內存應用程序使用大頁機制分配內存。當然大頁也會有弊端:比如初始化耗時高,進程內存占用可能變高等。
可以使用 perf 工具對比進程使用大頁前后的 PageFault 次數的變化:
perf stat -e page-faults -p-- sleep 5
目前內核提供了兩種大頁機制,一種是需要提前預留的靜態大頁形式,另一種是透明大頁(THP, Transparent Huge Page) 形式。
1. 靜態大頁
首先來看靜態大頁,也叫做 HugeTLB。靜態大頁可以設置 cmdline 參數在系統啟動階段預留,比如指定大頁 size 為 2M,一共預留 512 個這樣的大頁:
hugepagesz=2M hugepages=512
還可以在系統運行時動態預留,但該方式可能因為系統中沒有足夠的連續內存而預留失敗。
預留默認 size(可以通過 cmdline 參數 default_hugepagesz=指定size)的大頁:
echo 20 > /proc/sys/vm/nr_hugepages
預留特定 size 的大頁:
echo 5 > /sys/kernel/mm/hugepages/hugepages-*/nr_hugepages
預留特定 node 上的大頁:
echo 5 > /sys/devices/system/node/node*/hugepages/hugepages-*/nr_hugepages
當預留的大頁個數小于已存在的個數,則會釋放多余大頁(前提是未被使用)。
編程中可以使用 mmap(MAP_HUGETLB) 申請內存。詳細使用可以參考內核文檔 :https://www.kernel.org/doc/Documentation/admin-guide/mm/hugetlbpage.rst
這種大頁的優點是一旦預留成功,就可以滿足進程的分配請求,還避免該部分內存被回收;缺點是: (1) 需要用戶顯式地指定預留的大小和數量。 (2) 需要應用程序適配,比如: - mmap、shmget 時指定 MAP_HUGETLB; - 掛載 hugetlbfs,然后 open 并 mmap
當然也可以使用開源 libhugetlbfs.so,這樣無需修改應用程序
預留太多大頁內存后,free 內存大幅減少,容易觸發系統內存回收甚至 OOM
緊急情況下可以手動減少 nr_hugepages,將未使用的大頁釋放回系統;也可以使用 v5.7 引入的HugeTLB + CMA 方式,細節讀者可以自行查閱。
2. 透明大頁
再來看透明大頁,在 THP always 模式下,會在 Page Fault 過程中,為符合要求的 vma 盡量分配大頁進行映射;如果此時分配大頁失敗,比如整機物理內存碎片化嚴重,無法分配出連續的大頁內存,那么就會 fallback 到普通的 4K 進行映射,但會記錄下該進程的地址空間 mm_struct;然后 THP 會在后臺啟動khugepaged 線程,定期掃描這些記錄的 mm_struct,并進行合頁操作。因為此時可能已經能分配出大頁內存了,那么就可以將此前 fallback 的 4K 小頁映射轉換為大頁映射,以提高程序性能。整個過程完全不需要用戶進程參與,對用戶進程是透明的,因此稱為透明大頁。
雖然透明大頁使用起來非常方便、智能,但也有一定的代價: (1)進程內存占用可能遠大所需:因為每次Page Fault 都盡量分配大頁,即使此時應用程序只讀寫幾KB (2)可能造成性能抖動:
在第 1 種進程內存占用可能遠大所需的情況下,可能造成系統 free 內存更少,更容易觸發內存回收;系統內存也更容易碎片化。
khugepaged 線程合頁時,容易觸發頁面規整甚至內存回收,該過程費時費力,容易造成 sys cpu 上升。
mmap lock 本身是目前內核的一個性能瓶頸,應當盡量避免 write lock 的持有,但 THP 合頁等操作都會持有寫鎖,且耗時較長(數據拷貝等),容易激化 mmap lock 鎖競爭,影響性能。
因此 THP 還支持 madvise 模式,該模式需要應用程序指定使用大頁的地址范圍,內核只對指定的地址范圍做 THP 相關的操作。這樣可以更加針對性、更加細致地優化特定應用程序的性能,又不至于造成反向的負面影響。
可以通過 cmdline 參數和 sysfs 接口設置 THP 的模式:
cmdline 參數:
transparent_hugepage=madvise
sysfs 接口:
echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
詳細使用可以參考內核文檔 :
https://www.kernel.org/doc/Documentation/admin-guide/mm/transhuge.rst
mmap_lock 鎖
上一小節有提到 mmap_lock 鎖,該鎖是內存管理中的一把知名的大鎖,保護了諸如mm_struct 結構體成員、 vm_area_struct 結構體成員、頁表釋放等很多變量與操作。
mmap_lock 的實現是讀寫信號量,當寫鎖被持有時,所有的其他讀鎖與寫鎖路徑都會被阻塞。Linux 內核已經盡可能減少了寫鎖的持有場景以及時間,但不少場景還是不可避免的需要持有寫鎖,比如 mmap 以及 munmap 路徑、mremap 路徑和 THP 轉換大頁映射路徑等場景。
應用程序應該避免頻繁的調用會持有 mmap_lock 寫鎖的系統調用 (syscall),比如有時可以使用 madvise(MADV_DONTNEED)釋放物理內存,該參數下,madvise 相比 munmap 只持有 mmap_lock 的讀鎖,并且只釋放物理內存,不會釋放 VMA 區域,因此可以再次訪問對應的虛擬地址范圍,而不需要重新調用 mmap 函數。
另外對于 MADV_DONTNEED,再次訪問還是會觸發 Page Fault 分配物理內存并填充頁表,該操作也有一定的性能損耗。如果想進一步減少這部分損耗,可以改為 MADV_FREE 參數,該參數也只會持有 mmap_lock 的讀鎖,區別在于不會立刻釋放物理內存,會等到內存緊張時才進行釋放,如果在釋放之前再次被訪問則無需再次分配內存,進而提高內存訪問速度。
一般 mmap_lock 鎖競爭激烈會導致很多 D 狀態進程(TASK_UNINTERRUPTIBLE),這些 D 進程都是進程組的其他線程在等待寫鎖釋放。因此可以打印出所有 D 進程的調用棧,看是否有大量 mmap_lock 的等待。
for i in `ps -aux | grep " D" | awk '{ print $2}'`; do echo $i; cat /proc/$i/stack; done
內核社區專門封裝了 mmap_lock 相關函數,并在其中增加了 tracepoint,這樣可以使用 bpftrace 等工具統計持有寫鎖的進程、調用棧等,方便排查問題,確定優化方向。
bpftrace -e 'tracepointmmap_lock_start_locking /args->write == true/{ @[comm, kstack] = count();}'
跨 numa 內存訪問
在 NUMA 架構下,CPU 訪問本地 node 內存的速度要大于遠端 node,因此應用程序應盡可能訪問本地 node 上的內存。可以通過 numastat 工具查看 node 間的內存分配情況:
觀察整機是否有很多 other_node 指標(遠端內存訪問)上漲:
watch -n 1 numastat -s
查看單個進程在各個node上的內存分配情況:
numastat -p
1. 綁 node
可以通過 numactl 等工具把進程綁定在某個 node 以及對應的 CPU 上,這樣該進程只會從該本地 node 上分配內存。
但這樣做也有相應的弊端,比如:該 node 剩余內存不夠時,進程也無法從其他 node 上分配內存,只能期待內存回收后釋放足夠的內存,而如果進入直接內存回收會阻塞內存分配,就會有一定的性能損耗。
此外,進程組的線程數較多時,如果都綁定在一個 node 的 CPU 上,可能會造成 CPU 瓶頸,該損耗可能比遠端 node 內存訪問還大,比如 ngnix 進程與網卡就推薦綁定在不同的 node 上,這樣雖然網卡收包時分配的內存在遠端 node 上,但減少了本地 node 的 CPU 上的網卡中斷,反而可以獲得更好的性能提升。
2. numa balancing
內核還提供了 numa balancing 機制,可以通過 /proc/sys/kernel/numa_balancing 文件或者 cmdline 參數 numa_balancing=進行開啟。
該機制可以動態的將進程訪問的 page 從遠端 node 遷移到本地 node 上,從而使進程可以盡可能的訪問本地內存。
但該機制實現也有相應的代價,在 page 的遷移是通過 Page Fault 機制實現的,會有相應的性能損耗;另外如果遷移時找不到合適的目標 node,可能還會把進程遷移到正在訪問的 page 的 node 的 CPU 上,這可能還會導致 cpu cache miss,從而對性能造成更大的影響。
因此需要根據業務進程的具體行為,來決定是否開啟 numa balancing 功能。
總結
性能優化一直是大家關注的話題,其優化方向涉及到 CPU 調度、內存、IO等,本文重點針對內存優化提出了幾點思路。但是魚與熊掌不可兼得,文章提到的調優操作都有各自的優點和缺點,不存在一個適用于所有情況的優化方法。針對于不同的 workload,需要分析出具體的性能瓶頸,從而采取對應的調優方法,不能一刀切的進行設置。在沒有發現明顯性能抖動的情況下,往往可以繼續保持當前配置。
審核編輯:劉清
-
Linux系統
+關注
關注
4文章
601瀏覽量
28146 -
TLB電路
+關注
關注
0文章
9瀏覽量
5311 -
LINUX內核
+關注
關注
1文章
317瀏覽量
22083 -
MMU
+關注
關注
0文章
92瀏覽量
18566 -
numa結構
+關注
關注
0文章
4瀏覽量
1197
原文標題:Linux 內核內存性能調優的一些筆記
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
xgboost超參數調優技巧 xgboost在圖像分類中的應用
Linux TCP內核的參數設置與調優

如何使用DevEco Studio性能調優工具Profiler定位應用內存問題

大數據從業者必知必會的Hive SQL調優技巧
Linux內核測試技術





 工商網監
工商網監
評論