 利用Contrastive Loss(對比損失)思想設計自己的loss function
利用Contrastive Loss(對比損失)思想設計自己的loss function

Contrastive Loss簡介
對比損失在非監督學習中應用很廣泛。最早源于 2006 年Yann LeCun的“Dimensionality Reduction by Learning an Invariant Mapping”,該損失函數主要是用于降維中,即本來相似的樣本,在經過降維(特征提取)后,在特征空間中,兩個樣本仍舊相似;而原本不相似的樣本,在經過降維后,在特征空間中,兩個樣本仍舊不相似。同樣,該損失函數也可以很好的表達成對樣本的匹配程度。
在非監督學習時,對于一個數據集內的所有樣本,因為我們沒有樣本真實標簽,所以在對比學習框架下,通常以每張圖片作為單獨的語義類別,并假設:同一個圖片做不同變換后不改變其語義類別,比如一張貓的圖片,旋轉或局部圖片都不能改變其貓的特性。
因此,假設對于原始圖片 X,分別對其做不同變換得到 A 和 B,此時對比損失希望 A、B 之間的特征距離要小于 A 和任意圖片 Y 的特征距離。
Contrastive Loss定義
定義對比損失函數 L 為:
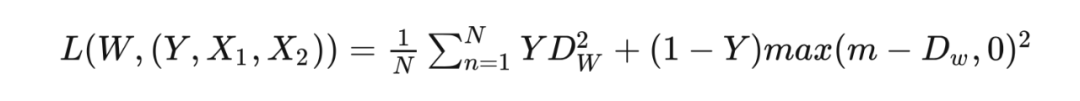
其中,
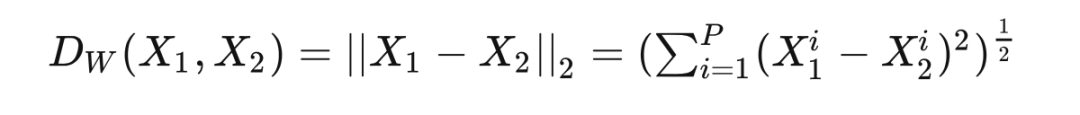
代表兩個樣本特征的歐式距離, 代表特征的維度, 為兩個樣本是否匹配的標簽( 代表兩個樣本相似或匹配, 代表兩個樣本不相似或不匹配), 為設定的閾值(超過 的把其 loss 看作 0,即如果兩個不相似特征離得很遠,那么對比 loss 應該是很低的), 為樣本數量。
通過
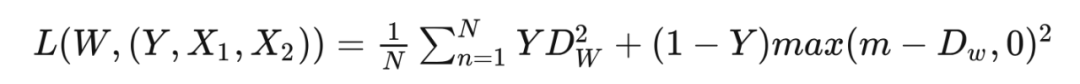
可以發現,對比損失可以很好的描述成對樣本的匹配程度,可以很好的用于訓練提取特征的模型:
當 時,即兩個樣本相似或匹配時,損失函數 ,即如果原本相似或匹配的樣本如果其被模型提取的特征歐氏距離很大,說明模型效果不好導致 loss 很大。 當 時,即兩個樣本不相似或不匹配時,損失函數 ,如果這時兩個樣本被模型提取的特征歐式距離很小,那么 loss 會變大以增大模型的懲罰從而使 loss 減小,如果兩個樣本被模型提取的特征歐式距離很大,說明兩個樣本特征離得很遠,此時如果超過閾值 則把其 loss 看作 0,此時的 loss 很小。
應用了對比損失的工作小結

論文標題:Improved Deep Metric Learning with Multi-class N-pair Loss Objective
論文地址:
https://proceedings.neurips.cc/paper/2016/file/6b180037abbebea991d8b1232f8a8ca9-Paper.pdf
N-pair loss,需要從 N 個不同的類中構造 N 對樣本,自監督學習。
本文是基于 Distance metric learning,目標是學習數據表征,但要求在 embedding space 中保持相似的數據之間的距離近,不相似的數據之間的距離遠。 其實在諸如人臉識別和圖片檢索的應用中,就已經使用了 contrastive loss 和 triplet loss,但仍然存在一些問題,比如收斂慢,陷入局部最小值,相當部分原因就是因為損失函數僅僅只使用了一個 negative 樣本,在每次更新時,與其他的 negative 的類沒有交互。之前 LeCun 提出的對比損失只考慮輸入成對的樣本去訓練一個神經網絡去預測它們是否屬于同一類,上文已經解釋了對比損失。 Triplet loss(三元損失函數)是 Google 在 2015 年發表的 FaceNet 論文中提出的,與前文的對比損失目的是一致的,具體做法是考慮到 query 樣本和 postive 樣本的比較以及 query 樣本和 negative 樣本之間的比較,Triplet Loss 的目標是使得相同標簽的特征在空間位置上盡量靠近,同時不同標簽的特征在空間位置上盡量遠離,同時為了不讓樣本的特征聚合到一個非常小的空間中要求對于同一類的兩個正例和一個負例,負例應該比正例的距離至少遠 m(margin):
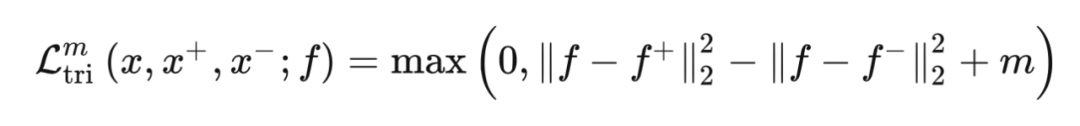
該 loss 將促使 query 樣本和 positive 樣本之間的距離比 query 樣本和 negative 樣本之間的距離大于 m(margin)。
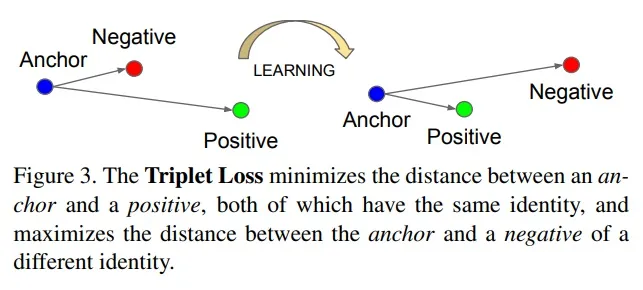
▲ 可以看出經過 Triplet loss 學習以后同類的 Positive 樣本和 Anchor 的距離越來越近而不同類的 Negative 樣本和 Anchor 的距離越來越遠。
但是三元損失函數考慮的 negative 樣本太少了,收斂慢,因此,本文提出了一個考慮多個 negative 樣本的方法:(N+1)-tuplet loss,即訓練樣本為樣本 x 以及(N-1)個 negative 樣本和一個 positive 樣本,當 N=2 時,即是 triplet loss。訓練樣本為 : 是一個 positive 樣本, 是(N-1)個 negative 樣本。
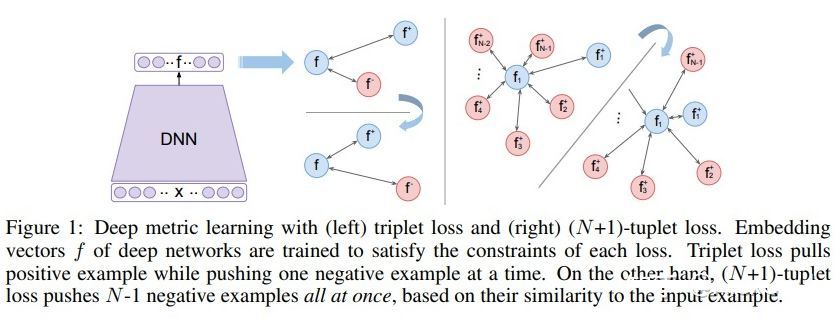
由圖所示(藍色代表 positive 樣本,紅色代表 negative 樣本),Triplet loss 在將 positive 樣本拉近的同時一次只能推離一個 negative 樣本;而 (N+1)-tuplet loss 基于樣本之間的相似性,一次可以將(N-1)個 negative 樣本推離(提高了收斂速度),而且 N 的值越大,負樣本數越多,近似越準確。 但是如果直接采用 (N+1)-tuplet loss,batch size 為 N,那么一次更新需要傳遞 Nx(N+1)個樣本,網絡層數深的時候會有問題,為了避免過大的計算量,本文提出了N-pair loss,如下圖:
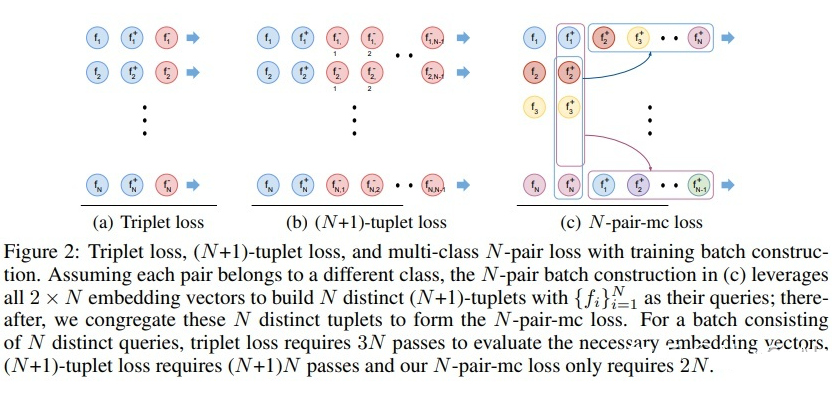
N-pair loss 其實就是重復利用了 embedding vectors 的計算來作為 negative 樣本(把其他樣本的正樣本作為當前樣本的負樣本,這樣就不用重復計算不同樣本的負樣本,只需要計算 N 次即可得出),避免了每一行都要計算新的 negative 樣本的 embedding vectors,從而將 的計算量降低為 2N(batch size=N,需要計算 N 次,之前計算負樣本需要計算 N 次,所以計算量=N+N=2N)。 上述文章的亮點在于,首先提出了需要在三元損失函數中加入更多的負樣本提高收斂速度,然后又想到了一種方式通過將其他樣本的正樣本當作當前樣本的負樣本的方法降低了計算復雜度。

論文標題:Unsupervised Feature Learning via Non-Parametric Instance Discrimination
論文地址:
https://arxiv.org/pdf/1805.01978.pdf
Instance discrimination 區分不同實例,將當前實例于不同實例進行空間劃分 memory bank 由數據集中所有樣本的表示組成。 本文將 instance discrimination 機智地引入了 memory bank 機制,并且真正地把 loss 用到了 unsupervised learning。該論文主要論述如何通過非參數的 instance discrimination 進行無監督的特征學習。主要的思想是將每個單一實例都看作不同的“類”。
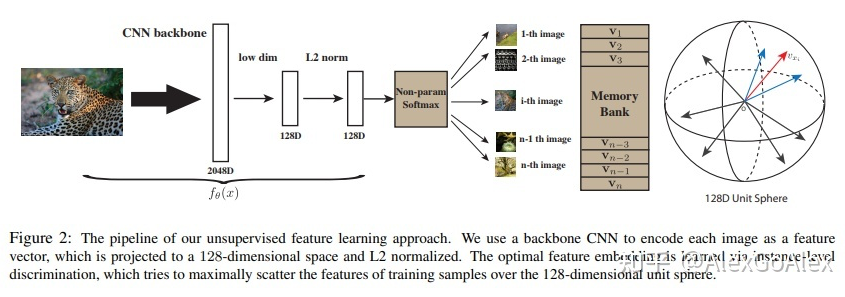
通過 CNN backbone,原始圖片輸入網絡后輸出一個經過 L2 標準化的 128 維向量,通過 Non-Parametric Softmax Classifier 計算每個單一樣本被識別正確的概率,同時使用Memory Bank存儲特征向量,通過 NCE(noise-contrastive estimation,噪音對比估計)來近似估計 softmax 的數值減少計算復雜度,最后使用 Proximal Regularization 穩定訓練過程的波動性。 實例間的相似度直接從特征中以非參數方式計算,即:每個實例的特征存儲在離散的 bank 中,而不是網絡的權重。
噪聲對比估計是一種采樣損失,通常用于訓練具有較大輸出詞匯量的分類器。在大量可能的類上計算 softmax 開銷非常大。使用 NCE,我們可以通過訓練分類器從“真實”分布和人工生成的噪聲分布中區分樣本,從而將問題簡化為二分類問題。
因此,主要有以下三個問題需要考慮:
● 能否僅通過特征表示來區分不同的實例。
●能否通過純粹的判別學習(discriminative learning)反應樣本間的相似性。
●將不同個例都看作不同的“類”,那這個數量將是巨大的,該如何進行處理。
Non-Parametric Softmax Classifier
采用 softmax 的 instance-level 的分類目標,假如有 n 個 images ,即有 n 個類,,它們的特征為 。傳統的 parametric 的softmax 可以表示為:
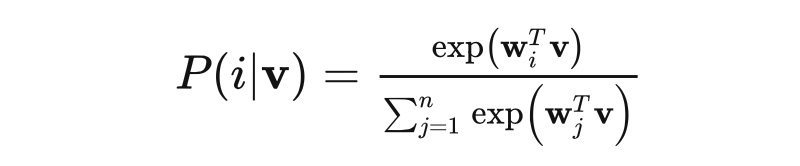
其中 是類別j的權重向量, 用來評價 v 與第 j 個實例的匹配程度。這種 loss 的問題是權重向量只是作為一種類的 prototype,而無法對實例之間進行明確的比較。所以本文通過替換 為 ,并且限制 ,可以得到一種 non-parametric 的 softmax 函數,這樣就不用訓練權重參數:
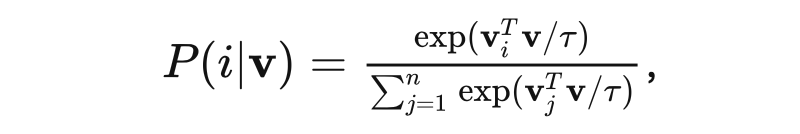
是 temperature 參數,控制 softmax 的平滑程度。 非參數的 softmax 主要思路是每個樣本特征除了可以作為特征之外,也可以起到分類器的作用。因為 L2-norm 之后的特征乘積本身就等于 cos 相似性,。學習的目標就是最大化 joint probability:
,即每一個 越大越好,也等同于最小化 negative log-likelihood:
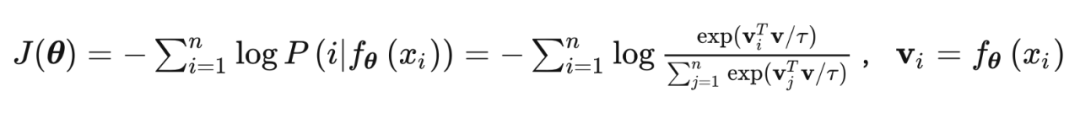
使用 Mermory Bank V 來存儲上述的 ,在每個 iteration 對應修改其值 ,在初始化時通過單位隨機向量對 V 進行初始化。
NCE Loss 如果直接用上述的 loss function 去訓練,當類的數量n很大時,要求的計算量非常大,于是使用 NCE 來估算。其基本思想是將多分類問題轉化為一組二分類問題,其中二分類任務是區分數據樣本和噪聲樣本。關于對 NCE loss 的理解如下:
當我們設計一個模型來擬合數據時,經常會遇上指數族分布:
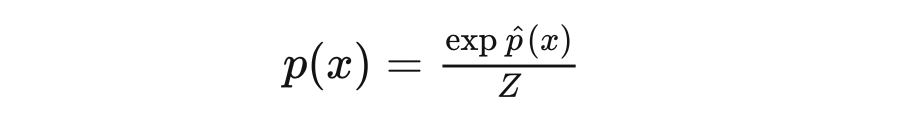
其中分母部分是歸一化常數,一個目的是用來讓這個分布真的成為一個“分布”要求(分布積分=1)。很多時候,比如計算一個巨大(幾十上百萬詞)的詞表在每一個詞上的概率得分的時候,計算這個分母會變得非常非常非常消耗資源。
比如一個 language model 最后 softmax 層中,在 inference 階段其實只要找到 argmax 的那一項就夠了,并不需要歸一化,但在 training stage,由于分母Z中是包含了模型參數的,所以也要一起參與優化,所以這個計算省不了。
而 NCE 做了一件很 intuitive 的事情:用負樣本采樣的方式,不計算完整的歸一化項。讓模型通過負樣本,估算出真實樣本的概率,從而在真實樣本上能做得了極大似然。相當于把任務轉換成了一個分類任務,然后再用類似交叉熵的方式來對模型進行優化(其實本質上是優化了兩個部分:模型本身,和一個負例采樣的分布和參數)。
另一方面,NCE 其實證明了這種采樣在負例足夠多的情況下,對模型梯度優化方向和“完整計算歸一化項進行優化”是一致的,這一點證明了 NCE 在用負采樣方式解決歸一化項的正確性。
“噪聲對比估計”雜談:曲徑通幽之妙 Memory bank 中特征表示 對應于第 個樣例的概率為:
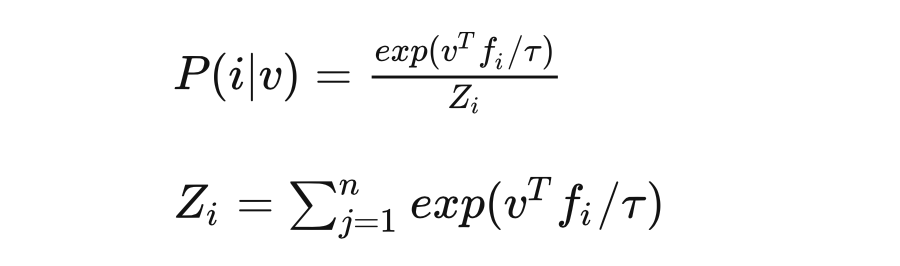
我們設定噪聲分布為一個均勻分布:,假設噪聲樣本的頻率是數據樣本的 倍,那么樣本 及特征 來自數據分布 的后驗概率為:
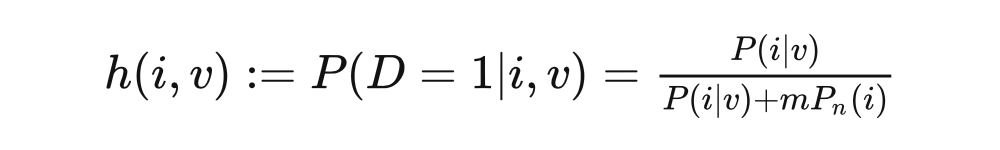
訓練目標為最小化
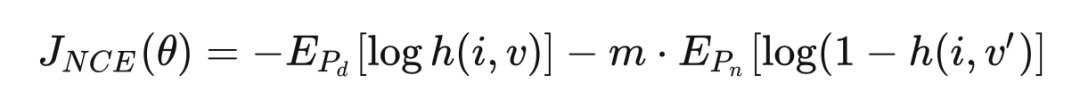
其中, 指代真實數據分布,對 而言 是 的特征; 是來自另一幅圖片,從噪聲分布 中隨機采樣得到。注: 和 都是從 Memory Bank 中采樣得到的。 的計算量過大,我們把它當作常量,由 Monte Carlo 算法估計得到:
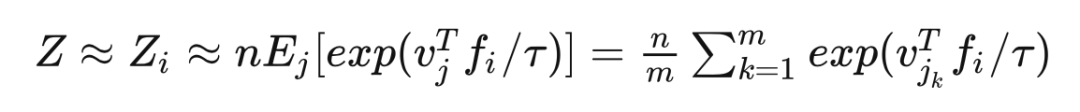
是 indices 的隨機子集,NCE 將每個樣例的計算復雜度從 減少到 。 最后一點是,這篇文章加入了近似正則化項 ,來使訓練過程更加平滑和穩定。 本文引入 memory bank 把前一個 step 學習到的實例特征存儲起來,然后在下一個 step 把這些存儲的 memory 去學習。效率有所提升。但是實際在優化的時候當前的實例特征是跟 outdated memory 去對比的,所以學習效果還不是最優的。

論文標題:Momentum Contrast for Unsupervised Visual Representation Learning
論文地址:
https://arxiv.org/pdf/1911.05722.pdf 解決了一個非常重要的工程問題:如何節省內存節省時間搞到大量的 negative samples?
至于文章的 motivation,之前 contrastive learning 存在兩種問題。在用 online 的 dictionary 時,也就是文章中比較的 end-to-end 情形,constrastive learning 的性能會受制于 batch size,或者說顯存大小。在用 offline 的 dictionary 時,也就是文章中說的 memory bank(InstDisc)情形,dictionary 是由過時的模型生成的,某種程度上可以理解為 supervision 不干凈,影響訓練效果。那么很自然的,我們想要一個 trade-off,兼顧 dictionary 的大小和質量。文章給出的解法是對模型的參數空間做 moving average,相當于做一個非常平滑的 update。
MoCo 完全專注在 Contrastive Loss 上,將這個問題想象成有一個很大的字典,神經網絡的目的就是一個 Encoder 要將圖片 Encode 成唯一的一把 Key,此時要如何做到讓 Key Space Large and Consistent 是最重要的。
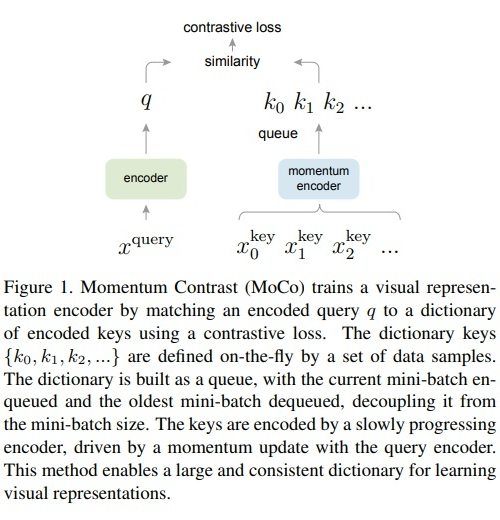
首先借鑒了 instance discrimination 的文章的 Memory Bank,建一個 Bank 來保存所有的 Key (或稱為 Feature)。此方法相對把所有圖塞進 Batch 少用很多內存,但對于很大的 Dataset 依舊難以按比例擴大。 因此,MoCo 改進了 Bank,用一個 Dynamic Queue 來取代,但是單純這樣做的話是行不通的,因為每次個 Key 會受到 Network 改變太多,Contrastive Loss 無法收斂。因此 MoCo 將種子 feature extractor 拆成兩個獨立的 Network:Encoder 和 Momentum Encoder。
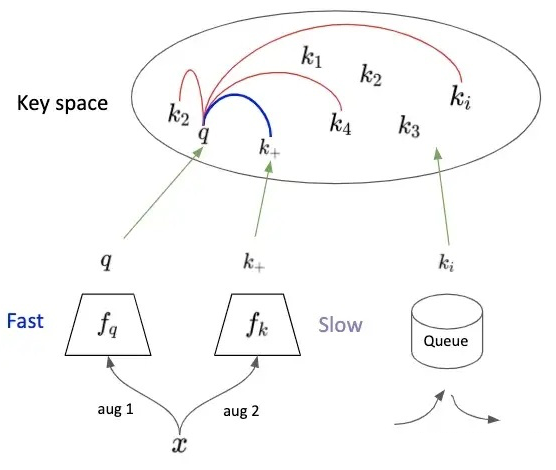
:Encoder,:Momentum Encoder,初始化時,它們的參數值一致。Queue 里 maintain 著最新的 K 個 key。 為了結合圖 5 對文章中的 Algorithm 進行分析,我們假設 Batch size N=1,同樣的 x 經過不同的 augmentation,encode 為 q 和 ,它們倆為 positive pair。將 q 與 Queue 中的 K 個 key (Negative Sample )進行比較,計算 Similarity。 由此,即可按照上述的 N-pair contrastive loss 計算 loss,并對 Encoder 更新parameters。等 Encoder Update 完后,在用 Momentum Update Momentum Encoder。并將這次的 Batch 放入到 Queue 中。
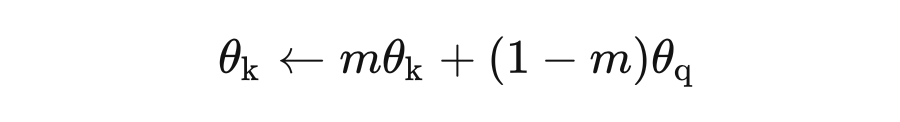
可以看到 key 對應的 Momentum Encoder 是由 query 對應的 Encoder 來更新的,同時受到 key 對應的 Encoder 上一次的狀態(更新后的 Encoder)影響。因此其更新速率,與 query 對應的 encoder 相比要慢,能提供很穩定的 Key,也就是 Momentum Encoder 把這個 Key Space 先擺好。 具體要有多慢呢?慢到 Queue 中最舊 key 依然能夠反映出最新的 Momentum encoder 信息。所以文章給出 m=0.999,要遠好于 m=0.9。直觀的的感受就是,key 對應的 Momentum encoder 基本不動,非常緩慢的更新,Queue 中所有的 key 可以近似的看成由目前的 Momentum encoder 編碼得到。 如果 與 Queue 中原本的 Key 比較遠,如圖 5 所示,再回想一下,MoCo 本質上還是在做 instance discrimination。所以,這時的 Loss 較小,且主要去 Update Encoder,使得 q 更接近 ,而 Momentum Encoder 更新又很緩慢,它更新后, 依然會與 Queue 中原本的 Key 相距較遠。 如果 與 Queue 中原本的 Key容易混淆,這時候的 Loss 較大, Encoder 的更新使得 q 遠離 Queue 中原本的 Key,同時盡可能地距離 較近,隨后 Momentum Encoder 緩慢更新,傾向于使得 遠離 Queue 中原本的 Key,相當于找一個比較空的區域放 , 而不影響原本的 Queue 中原本的 Key。但此處只是直觀上的分析,缺乏嚴謹的理論證明。 近期,何凱明團隊推出了MoCo_V2,效果相對于 V1 有了較大提升,但沒有改變 MoCo_V1 的框架。
審核編輯 :李倩
-
函數
+關注
關注
3文章
4381瀏覽量
64947 -
數據集
+關注
關注
4文章
1224瀏覽量
25463
原文標題:利用Contrastive Loss(對比損失)思想設計自己的loss function
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Analytical Loss Model of Power
VSWR/Return Loss Conversion Ta
Return Loss Headromm
Polarization Dependent Loss Me
Reduced Termination Loss by Ac
Cable-Loss Solutions
LTC4412: Low Loss PowerPath Controller in ThinSOT Data Sheet

表示學習中7大損失函數的發展歷程及設計思路

NLP類別不均衡問題之loss大集合
NLP類別不均衡問題之loss合集
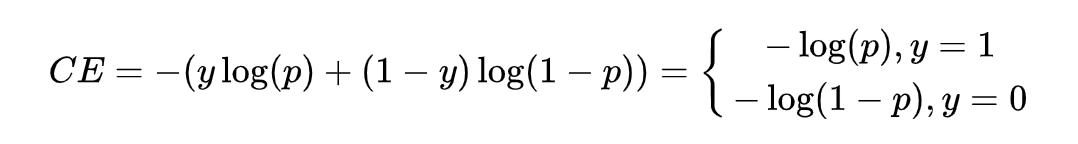





 工商網監
工商網監
評論