 分析Hive與Spark分區策略的異同點
分析Hive與Spark分區策略的異同點
隨著技術的不斷的發展,大數據領域對于海量數據的存儲和處理的技術框架越來越多。在離線數據處理生態系統最具代表性的分布式處理引擎當屬Hive和Spark,它們在分區策略方面有著一些相似之處,但也存在一些不同之處。
一、概述
隨著技術的不斷的發展,大數據領域對于海量數據的存儲和處理的技術框架越來越多。在離線數據處理生態系統最具代表性的分布式處理引擎當屬Hive和Spark,它們在分區策略方面有著一些相似之處,但也存在一些不同之處。本篇文章將分析Hive與Spark分區策略的異同點、它們各自的優缺點,以及一些優化措施。
二、Hive和Spark分區概念
在了解Hive和Spark分區內容之前,首先,我們先來回顧一下Hive和Spark的分區概念。在Hive中,分區是指將表中的數據劃分為不同的目錄或者子目錄,這些目錄或子目錄的名稱通常與表的列名相關聯。比如,一個名為“t_orders_name”的表可以按照日期分為多個目錄,每個目錄名稱對應一個日期值。這樣做的好處是可以大大提高查詢效率,因為只有涉及到特定日期的查詢才需要掃描對應的目錄,而不需要去掃描整個表。Spark的分區概念與Hive類似,但是有一些不同之處,我們將在后文中進行討論。
在Hive中,分區可以基于多個列進行,這些列的值組合形成目錄名稱。例如,如果我們將“t_orders_name”表按照日期和地區分區,那么目錄的名稱將包含日期和地區值的組合。在Hive中,數據存儲在分區的目錄下,而不是存儲在表的目錄下。這使得Hive可以快速訪問需要的數據,而不必掃描整個表。另外,Hive的分區概念也可以用于數據分桶,分桶是將表中的數據劃分為固定數量的桶,每個桶包含相同的行。
而與Hive不同的是,Spark的分區是將數據分成小塊以便并行計算處理。在Spark中,分區的數量由Spark執行引擎根據數據大小和硬件資源自動計算得出。Spark的分區數越多,可以并行處理的數據也就越多,因此也能更快的完成計算任務。但是,如果分區數太多,將會導致過多的任務調度和數據傳輸開銷,從而降低整體的性能。因此,Spark分區數的選擇應該考慮數據大小、硬件資源和計算任務復雜度等因素。
三、Hive和Spark分區的應用場景
在了解Hive和Spark的分區概念之后,接下來,我們來看看Hive和Spark分區在不同的應用場景中有哪些不同的優勢。
3.1 Hive分區
Hive分區適用于大數據場景,可以對數據進行多級分區,以便更細粒度地劃分數據,提高查詢效率。例如,在游戲平臺的充值數據中,可以按照道具購買日期、道具付款狀態、游戲用戶ID等多個維度進行分區。這樣可以方便的進行數據統計、分析和查詢操作,同時避免單一分區數據過大導致的性能問題。
3.2 Spark分區
Spark分區適用于大規模數據處理場景,可以充分利用集群資源進行并行計算處理。比如,在機器學習算法的訓練過程中,可以將大量數據進行分區,然后并行處理每個分區的數據,從而提高算法的訓練速度和效率。另外,Spark的分布式計算引擎也可以支持在多個節點上進行數據分區和計算,從而提高整個集群的計算能力和效率。
簡而言之,Hive和Spark分區在大數據處理和分布式計算場景這都有廣泛的應用,可以通過選擇合適的分區策略和優化措施,進一步提高數據處理的效率和性能。
四、如何選擇分區策略
在熟悉了Hive和Spark的分區概念以及應用場景后。接下來,我們來看看在Hive和Spark中如何選擇分區策略。分區策略的選擇對數據處理的效率和性能有著重要的影響。下面將分別闡述Hive和Spark分區策略的優缺點以及如何選擇分區策略。
4.1 Hive分區策略
優點:
Hive的分區策略可以提高查詢效率和數據處理性能,特別是在大數據集上表現突出。另外,Hive還支持多級分區,允許更細粒度的數據劃分。
缺點:
在Hive中,分區是以目錄的形式存在的,這會導致大量的目錄和子目錄,如果分區過多,將會占用過多的存儲空間。此外,Hive的分區策略需要在創建表時進行設置,如果數據分布出現變化,需要重新設置分區策略。
4.2 Spark分區策略
優點:
Spark的分區策略可以根據數據大小和硬件資源自動計算分區數,這使得計算任務可以并行計算處理,從而提高了處理效率和性能。
缺點:
如果分區數設置不當,將會導致過多的任務調度和數據傳輸開銷,從而影響整體性能。此外,Spark的分區策略也需要根據數據大小、硬件資源和計算任務復雜度等因素進行調整。
4.3 分區策略選擇
在實際項目開發使用中,選擇合適的分區策略可以顯著提高數據處理的效率和性能。但是,如何選擇分區策略需要根據具體情況進行考慮,這里總結了一些分區策略選擇的場景:
數據集大小:如果數據集較大,可以考慮使用Hive的多級劃分策略,以便更細粒度的劃分數據,提高查詢效率。如果數據集較小,可以使用Spark自動計算分區策略,以便充分利用硬件資源并提高計算效率。
計算任務復雜度:如果計算任務比較復雜,例如需要進行多個JOIN操作,可以使用Hive的分桶策略,以便加快數據訪問速度,減少JOIN操作的開銷。
硬件資源:分區策略的選擇也需要考慮硬件資源的限制。如果硬件資源比較充足,可以增加分區數以提高計算效率。如果硬件資源比較緊張,需要減少分區數以避免任務調度和數據傳輸的開銷。
綜上所述,選擇合適的分區策略需要根據具體的情況進行考慮,包括數據集大小、計算任務復雜度和硬件資源等因素。在實際使用中,可以通過實驗和調試來找到最佳的分區策略。
五、如何優化分區性能
除了選擇合適的分區策略之外,還可以通過一些優化措施來進一步提高分區的性能。在Spark中,大多數的Spark任務可以通過三個階段來表述,它們分別是讀取輸入數據、使用Spark處理、保持輸出數據。Spark雖然實際數據處理主要發生在內存中,但是Spark使用的是存儲在HDFS上的數據來作為輸入和輸出,任務的調度執行會使用大量的 I/O,存在性能瓶頸。
而Hive分區數據是存儲在HDFS上的,然而HDFS對于大量小文件支持不太友好,因為在每個NameNode內存中每個文件大概有150字節的存儲開銷,而整個HDFS集群的IOPS數量是有上限的。當文件寫入達到峰值時,會對HDFS集群的基礎架構的某些部分產生性能瓶頸。
5.1 通過減少 I/O 帶寬來優化性能
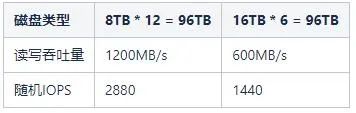
在Hadoop集群中,它依靠大規模并行 I/O 來支持數千個并發任務。比如現有一個大小為96TB的數據節點,磁盤的大小有兩種,它們分別是8TB和16TB。具有8TB磁盤的數據節點有12塊這樣的磁盤,而具有16TB磁盤的數據節點有6塊這樣的磁盤。我們可以假設每個磁盤的平均讀寫吞吐量約為100MB/s,而這兩種不同的磁盤分布,它們對應的帶寬和IOPS,具體詳情如下表所示:
5.2 通過設置參數來優化性能
在Hadoop集群中,每個數據節點為每個卷運行一個卷掃描器,用于掃描塊的狀態。由于卷掃描器與應用程序競爭磁盤資源,因此限制其磁盤帶寬很重要。配置 dfs.block.scanner.volume.bytes.per.second 屬性值來定義卷掃描器每秒可以掃描的字節數,默認為1MB/s。
比如設置帶寬為5MB/s,掃描12TB所需要的時間為
12TB / 5MBps = (12 * 1024 * 1024 / (3600 * 24)) = 29.13天。
5.3 通過優化Spark處理分區任務來提升性能
假如,現在需要重新計算歷史分區的數據表,這種場景通常用于修復錯誤或者數據質量問題。在處理包含一年數據的大型數據集(比如1TB以上)時,可能會將數據分成幾千個Spark分區來進行處理。雖然,從表面上看,這種處理方法并不是最合適的,使用動態分區并將數據結果寫入按照日期分區的Hive表中將產生多達上百萬個文件。
下面,我們將任務分區數縮小,現有一個包含3個分區的Spark任務,并且想將數據寫入到包含3個分區的Hive表。在這種情況下,希望發送的是將3個文件寫入到HDFS中,所有數據都存儲在每個分區的單個文件中。最終會生成9個文件,并且每個文件都有1個記錄。使用動態分區寫入Hive表時,每個Spark分區都由執行程序來并行處理。
處理Spark分區數據時,每次執行程序在給定的Spark分區中遇到新的分區時,它都會打開一個新文件。默認情況下,Spark對數據會使用Hash或者Round Robin分區器。當應用于任意數據時,可以假設這兩種方法在整個Spark分區中相對均勻且隨機分布數據。如下圖所示:

理想情況下,目標文件大小應該大約是HDFS塊大小的倍數,默認情況下是128MB。在Hive中,提供了一些配置參數來自動將結果寫入到合理大小的文件中,從開發者的角度來看幾乎是透明的,比如設置屬性 hive.merge.smallfiles.avgsize 和
hive.merge.size.per.task 。但是,Spark中不存在此類功能,因此,我們需要自己開發實現,來確定一個數據集,應該寫入多少文件。
5.3.1 基于大小的計算
理論上,這是最直接的方法,設置目標大小,估算數據的大小,然后進行劃分。但是,在很多情況下,文件被寫入磁盤時會進行壓縮,并且其格式與存儲在 Java 堆中的記錄格式有所不同。這意味著估算寫入磁盤時內存的記錄大小不是一件容易的事情。雖然可以使用 Spark SizeEstimator應用程序通過內存中的數據的大小進行估算。但是,SizeEstimator會考慮數據幀、數據集的內部消耗,以及數據的大小。總體來說,這種方式不太容易準確實現。
5.3.2 基于行數的計算
這種方法是設置目標行數,計算數據集的大小,然后執行除法來估算目標。我們的目標行數可以通過多種方式確定,或者通過為所有數據集選擇一個靜態數字,或者通過確定磁盤上單個記錄的大小并執行必要的計算。哪種方式最優,取決于你的數據集數量及其復雜性。計算相對來說成本較低,但是需要在計算前緩存以避免重新計算數據集。
5.3.3 靜態文件計算
最簡單的解決方案是,只要求開發者在每個寫入任務的基礎上,告訴Spark總共應該寫入多少個文件。這種方式需要給開發者一些其他方法來獲取具體的數字,可以通過這種方式來替代昂貴的計算。
5.4. 優化Spark分發數據方式來提升性能
即使我們知道了如何將文件寫入磁盤,但是,我們仍須讓Spark以符合實際的方式來構建我們的分區。在Spark中,它提供了許多工具來確定數據在整個分區中的分布方式。但是,各種功能中隱藏著很多復雜性,在某些情況下,它們的含義并不明顯,下面將介紹Spark提供的一些選項來控制Spark輸出文件的數量。
5.4.1 合并
Spark Coalesce是一個特殊版本的重新分區,它只允許減少總的分區,但是不需要完全的Shuffle,因此比重新分區要快得多。它通過有效的合并分區來實現這一點。如下圖所示:
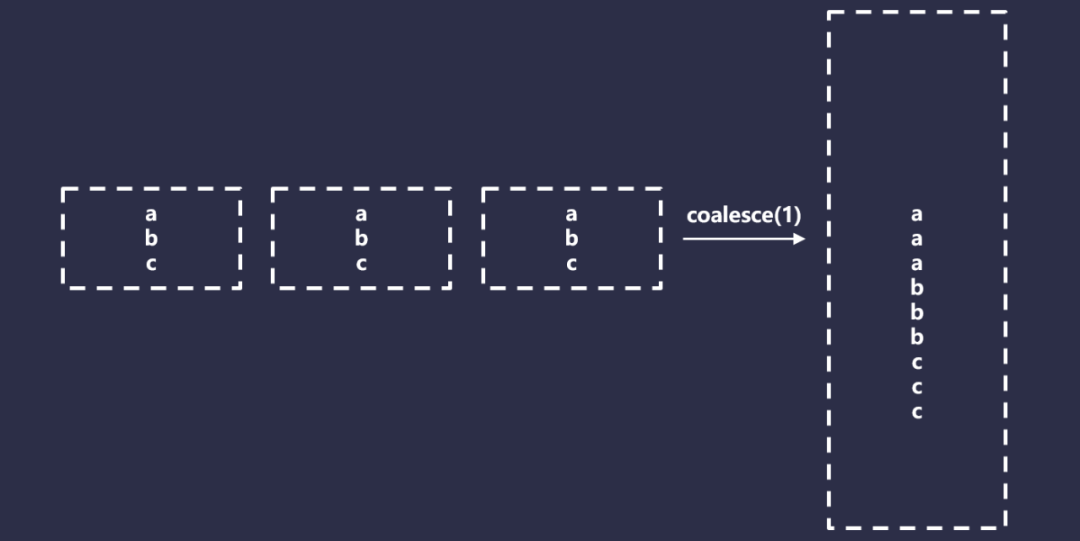
Coalesce在某些情況下看起來是不錯的,但是也有一些問題。首先,Coalesce有一個難以使用的行為,以一個非常基礎的Spark應用程序為例,代碼如下所示:
Spark
load().map(…).filter(…).save()
比如,設置的并行度為1000,但是最終只想寫入10個文件,可以設置如下:
Spark
load().map(…).filter(…).coalesce(10).save()
但是,Spark會盡可能早的有效的將合并操作下推,因此這將執行為如下代碼:
Spark
load().coalesce(10).map(…).filter(…).save()
有效的解決這種問題的方法是在轉換和合并之間強制執行,代碼如下所示:
Spark
val df = load().map(…).filter(…).cache() df.count() df.coalesce(10)
在Spark中,緩存是必須的,否則,你將不得不重新計算數據,這可能會重新消耗計算資源。然后,緩存是需要消費一定資源的,如果你的數據集無法放入內存中,或者無法釋放內存,將數據有效的存儲在內存中兩次,那么必須使用磁盤緩存,這有其自身的局限性和顯著的性能損失。
此外,正如我們看到的,通常需要執行Shuffle來獲得我們想要的更復雜的數據集結果。因此,Coalesce僅適用于特定的情況,比如如下場景:
保證只寫入一個Hive分區;
目標文件數少于你用于處理數據的Spark分區數;
有充足的緩存資源。
5.4.2 簡單重新分區
在Spark中,一個簡單的重新分區,可以通過設置參數來實現,比如df.repartition(100)。在這種情況下,使用循環分區器,這意味著唯一的保證是輸出數據具有大致相同大小的Spark分區,這種分區僅適用于以下情況:
保證只需要寫入一個Hive分區;
正在寫入的文件數大于你的Spark分區數,或者由于某些原因你無法使用合并。
5.4.3 按列重新分區
按列重新分區接收目標Spark分區計數,以及要重新分區的列序列,例如,df.repartition(100,$"date")。這對于強制要求Spark將具有相同鍵的數據,分發到同一個分區很有用。一般來說,這對許多Spark操作(比如JOIN)很有用。
按列重新分區使用HashPartitioner,將具有相同值的數據,分發給同一個分區,實際上,它將執行以下操作:
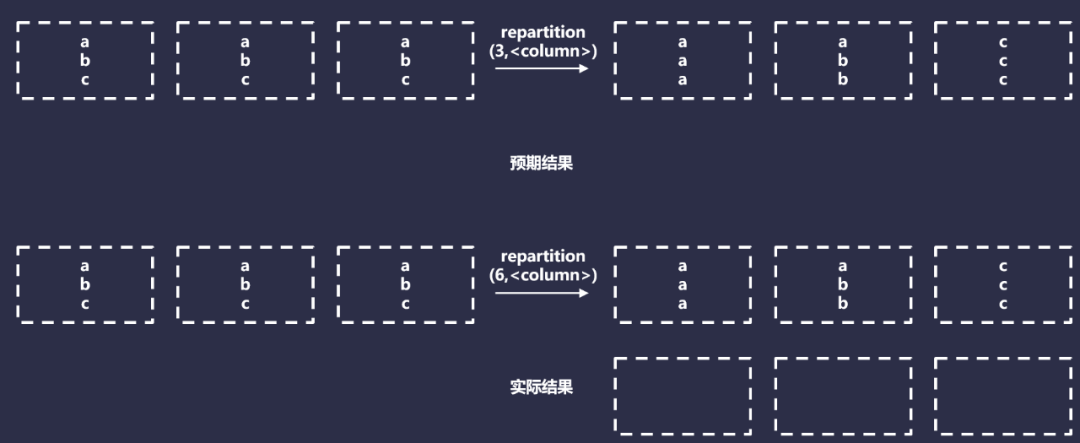
但是,這種方法只有在每個分區鍵都可以安全的寫入到一個文件時才有效。這是因為無論有多少特定的Hash值,它們最終都會在同一個分區中。按列重新分區僅在你寫入一個或者多個小的Hive分區時才有效。在任何其他情況下,它都是無效的,因為每個Hive分區最終都會生成一個文件,僅適用于最小的數據集。
5.4.4 按具有隨機因子的列重新分區
我們可以通過添加約束的隨機因子來按列修改重新分區,具體代碼如下:
Spark
df
.withColumn("rand", rand() % filesPerPartitionKey)
.repartition(100, $"key", $"rand")
理論上,只要滿足以下條件,這種方法應該會產生排序規則的數據和大小均勻的文件:
Hive分區的大小大致相同;
知道每個Hive分區的目標文件數并且可以在運行時對其進行編碼。
但是,即使我們滿足上述這些條件,還有另外一個問題:散列沖突。假設,現在正在處理一年的數據,日期作為分區的唯一鍵。如果每個分區需要5個文件,可以執行如下代碼操作:
Spark
df.withColumn("rand", rand() % 5).repartition(5*365, $"date", $"rand")
在后臺,Scala將構造一個包含日期和隨機因子的鍵,例如(,<0-4>)。然后,如果我們查看HashPartitioner代碼,可以發現它將執行以下操作:
Spark
class HashPartitioner(partitions: Int) extends Partitioner {
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
}
實際上,這里面所做的事情,就是獲取關鍵元組的散列,然后使用目標數量的Spark分區獲取它的mod。我們可以分析一下在這種情況下我們的數據將如何實現分布,具體代碼如下:
Spark
import java.time.LocalDate
def hashCodeTuple(one: String, two: Int, mod: Int): Int = {
val rawMod = (one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def hashCodeSeq(one: String, two: Int, mod: Int): Int = {
val rawMod = Seq(one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def iteration(numberDS: Int, filesPerPartition: Int): (Double, Double, Double) = {
val hashedRandKeys = (0 to numberDS - 1).map(x => LocalDate.of(2019, 1, 1).plusDays(x)).flatMap(
x => (0 to filesPerPartition - 1).map(y => hashCodeTuple(x.toString, y, filesPerPartition*numberDS))
)
hashedRandKeys.size // Number of unique keys, with the random factor
val groupedHashedKeys = hashedRandKeys.groupBy(identity).view.mapValues(_.size).toSeq
groupedHashedKeys.size // number of actual sPartitions used
val sortedKeyCollisions = groupedHashedKeys.filter(_._2 != 1).sortBy(_._2).reverse
val sortedSevereKeyCollisions = groupedHashedKeys.filter(_._2 > 2).sortBy(_._2).reverse
sortedKeyCollisions.size // number of sPartitions with a hashing collision
// (collisions, occurences)
val collisionCounts = sortedKeyCollisions.map(_._2).groupBy(identity).view.mapValues(_.size).toSeq.sortBy(_._2).reverse
(
groupedHashedKeys.size.toDouble / hashedRandKeys.size.toDouble,
sortedKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble,
sortedSevereKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble
)
}
val results = Seq(
iteration(365, 1),
iteration(365, 5),
iteration(365, 10),
iteration(365, 100),
iteration(365 * 2, 100),
iteration(365 * 5, 100),
iteration(365 * 10, 100)
)
val avgEfficiency = results.map(_._1).sum / results.length
val avgCollisionRate = results.map(_._2).sum / results.length
val avgSevereCollisionRate = results.map(_._3).sum / results.length
(avgEfficiency, avgCollisionRate, avgSevereCollisionRate) // 63.2%, 42%, 12.6%
上面的腳本計算了3個數量:
效率:非空的Spark分區與輸出文件數量的比率;
碰撞率:(date,rand)的Hash值發送沖突的Spark分區的百分比;
嚴重沖突率:同上,但是此鍵上的沖突次數為3或者更多。
沖突很重要,因為它們意味著我們的Spark分區包含多個唯一的分區鍵,而我們預計每個Spark分區只有1個。我們從分析的結果可知,我們使用了63%的執行器,并且可能會出現嚴重的偏差,我們將近一半的執行正在處理比預期多2到3倍或者在某些情況下高達8倍的數據。
現在,有一個解決方法,即分區縮放。在之前示例中,輸出的Spark分區數量等于預期的總文件數。如果將N個對象隨機分配給N個插槽,可以預期會有多個插槽包含多個對象,并且有幾個空插槽。因此,需要解決此問題,必須要降低對象與插槽的比率。
我們通過縮放輸出分區計數來實現這一點,通過將輸出Spark分區數乘以一個大因子,類似于:
Spark
df
.withColumn("rand", rand() % 5)
.repartition(5*365*SCALING_FACTOR, $"date", $"rand")
具體分析代碼如下所示:
Spark
import java.time.LocalDate
def hashCodeTuple(one: String, two: Int, mod: Int): Int = {
val rawMod = (one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def hashCodeSeq(one: String, two: Int, mod: Int): Int = {
val rawMod = Seq(one, two).hashCode % mod
rawMod + (if (rawMod < 0) mod else 0)
}
def iteration(numberDS: Int, filesPerPartition: Int, partitionFactor: Int = 1): (Double, Double, Double, Double) = {
val partitionCount = filesPerPartition*numberDS * partitionFactor
val hashedRandKeys = (0 to numberDS - 1).map(x => LocalDate.of(2019, 1, 1).plusDays(x)).flatMap(
x => (0 to filesPerPartition - 1).map(y => hashCodeTuple(x.toString, y, partitionCount))
)
hashedRandKeys.size // Number of unique keys, with the random factor
val groupedHashedKeys = hashedRandKeys.groupBy(identity).view.mapValues(_.size).toSeq
groupedHashedKeys.size // number of unique hashes - and thus, sPartitions with > 0 records
val sortedKeyCollisions = groupedHashedKeys.filter(_._2 != 1).sortBy(_._2).reverse
val sortedSevereKeyCollisions = groupedHashedKeys.filter(_._2 > 2).sortBy(_._2).reverse
sortedKeyCollisions.size // number of sPartitions with a hashing collision
// (collisions, occurences)
val collisionCounts = sortedKeyCollisions.map(_._2).groupBy(identity).view.mapValues(_.size).toSeq.sortBy(_._2).reverse
(
groupedHashedKeys.size.toDouble / partitionCount,
groupedHashedKeys.size.toDouble / hashedRandKeys.size.toDouble,
sortedKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble,
sortedSevereKeyCollisions.size.toDouble / groupedHashedKeys.size.toDouble
)
}
// With a scale factor of 1
val results = Seq(
iteration(365, 1),
iteration(365, 5),
iteration(365, 10),
iteration(365, 100),
iteration(365 * 2, 100),
iteration(365 * 5, 100),
iteration(365 * 10, 100)
)
val avgEfficiency = results.map(_._2).sum / results.length // What is the ratio of executors / output files
val avgCollisionRate = results.map(_._3).sum / results.length // What is the average collision rate
val avgSevereCollisionRate = results.map(_._4).sum / results.length // What is the average collision rate where 3 or more hashes collide
(avgEfficiency, avgCollisionRate, avgSevereCollisionRate) // 63.2% Efficiency, 42% collision rate, 12.6% severe collision rate
iteration(365, 5, 2) // 37.7% partitions in-use, 77.4% Efficiency, 24.4% collision rate, 4.2% severe collision rate
iteration(365, 5, 5)
iteration(365, 5, 10)
iteration(365, 5, 100)
隨著我們的比例因子接近無窮大,碰撞很快接近于0,效率接近100%。但是,這會產生另外一個問題,即大量Spark分區輸出將為空。同時這些空的Spark分區也會帶來一些資源開銷,增加Driver的內存大小,會使我們更容易遇到,由于異常錯誤而導致分區鍵空間意外增大的問題。
這里的一個常見方法,是在使用這種方法時不顯示設置分區(默認并行度和縮放),如果不提供分區計數,則依賴Spark默認的spark.default.parallelism值。雖然,通常并行度自然高于總輸出文件數(因此,隱式提供大于1 的縮放因子)。如果滿足以下條件,這種方式依然是一種有效的方法:
Hive分區的文件數大致相等;
可以確定平均分區文件數應該是多少;
大致知道唯一分區鍵的總數。
5.4.5 按范圍重新分區
按范圍重新分區是一個特列,它不使用RoundRobin和Hash Partitioner,而是使用一種特殊的方法,叫做Range Partitioner。
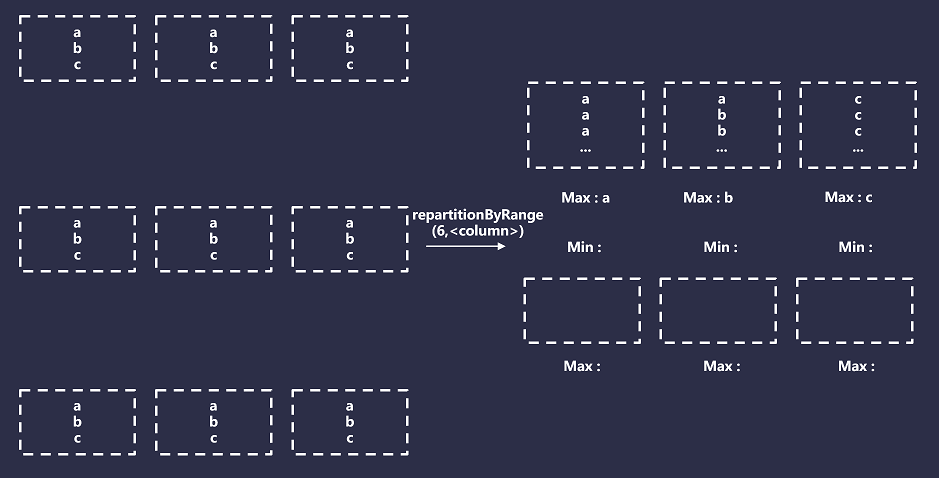
范圍分區器根據某些給定鍵的順序在Spark分區之間進行拆分行,但是,它不僅僅是全局排序,而且還擁有以下特性:
具有相同散列的所有記錄將在同一個分區中結束;
所有Spark分區都將有一個最小值和最大值與之關聯;
最小值和最大值將通過使用采樣來檢測關鍵頻率和范圍來確定,分區邊界將根據這些估計值進行初始設置;
分區的大小不能保證完全相等,它們的相等性基于樣本的準確性,因此,預測的每個Spark分區的最小值和最大值,分區將根據需要增大或縮小來保證前兩個條件。
總而言之,范圍分區將導致Spark創建與請求的Spark分區數量相等的Bucket數量,然后它將這些Bucket映射到指定分區鍵的范圍。例如,如果你的分區鍵是日期,則范圍可能是(最小值2022-01-01,最大值2023-01-01)。然后,對于每條記錄,將記錄的分區鍵與存儲Bucket的最小值和最大值進行比較,并相應的進行分配。如下圖所示:
六、總結
在選擇分區策略時,需要根據具體的應用場景和需求進行選擇。常見的分區策略包括按照時間、地域、用戶ID等多個維度進行分區。在應用分區策略時,還可以通過一些優化措施來進一步提高分區的性能和效率,例如合理設置分區數、避免過多的分區列、減少重復數據等。
總之,分區是大數據處理和分布式計算中非常重要的技術,可以幫助我們更好的管理和處理大規模的數據,提高數據處理的效率和性能,進而幫助我們更好的應對數據分析和業務應用的挑戰。
審核編輯:劉清
-
數據存儲
+關注
關注
5文章
997瀏覽量
51615 -
IOPs
+關注
關注
0文章
12瀏覽量
14386 -
HDFS
+關注
關注
1文章
31瀏覽量
9830 -
SPARK
+關注
關注
1文章
106瀏覽量
20414
原文標題:Hive和Spark分區策略剖析
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
分布式存儲數據恢復—虛擬機上hbase和hive數據庫數據恢復案例
NVIDIA加速的Apache Spark助力企業節省大量成本

永磁同步電機矢量控制策略分析
Nand flash 和SD卡(SD NAND)存儲扇區分配表異同
磁盤分區工具parted的使用方法
電源反接制動和倒拉反接制動有何異同點
使用FAL分區管理與easyflash變量管理

大數據從業者必知必會的Hive SQL調優技巧
電源反接制動和倒拉反接制動有何異同點
RK3568修改eMMC分區大小

spark為什么比mapreduce快?
熱電阻和熱電偶的相同點和不同點
spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案






 工商網監
工商網監
評論