 GPU和CPU誰最強呢?
GPU和CPU誰最強呢?
近幾個月,幾乎每個行業的小伙伴都了解到了ChatGPT的可怕能力。你知道么,ChatGPT之所以如此厲害,是因為它用到了幾萬張NVIDA Tesla A100顯卡做AI推理和圖形計算。
本文就簡單分享下GPU的相關內容,歡迎閱讀。
GPU是什么?
GPU的英文全稱Graphics Processing Unit,圖形處理單元。
說直白一點:GPU是一款專門的圖形處理芯片,做圖形渲染、數值分析、金融分析、密碼破解,以及其他數學計算與幾何運算的。GPU可以在PC、工作站、游戲主機、手機、平板等多種智能終端設備上運行。
GPU和顯卡的關系,就像是CPU和主板的關系。前者是顯卡的心臟,后者是主板的心臟。有些小伙伴會把GPU和顯卡當成一個東西,其實還有些差別的,顯卡不僅包括GPU,還有一些顯存、VRM穩壓模塊、MRAM芯片、總線、風扇、外圍設備接口等等。
GPU和CPU誰最強呢?
這個其實不好說,好點的GPU內部的晶體管數量可以超過CPU,CPU的強項是做邏輯運算,GPU的強項是做數學運算和圖形渲染。這就ChatGPT用大量高性能顯卡做AI推理的原因。
接下來,我們做個簡單的對比。
結構組成不同
CPU和GPU都是運算的處理器,在架構組成上都包括3個部分:運算單元ALU、控制單元Control和緩存單元Cache。
但是,三者的組成比例卻相差很大。
在CPU中緩存單元大概占50%,控制單元25%,運算單元25%;
在GPU中緩存單元大概占5%,控制單元5%,運算單元90%。
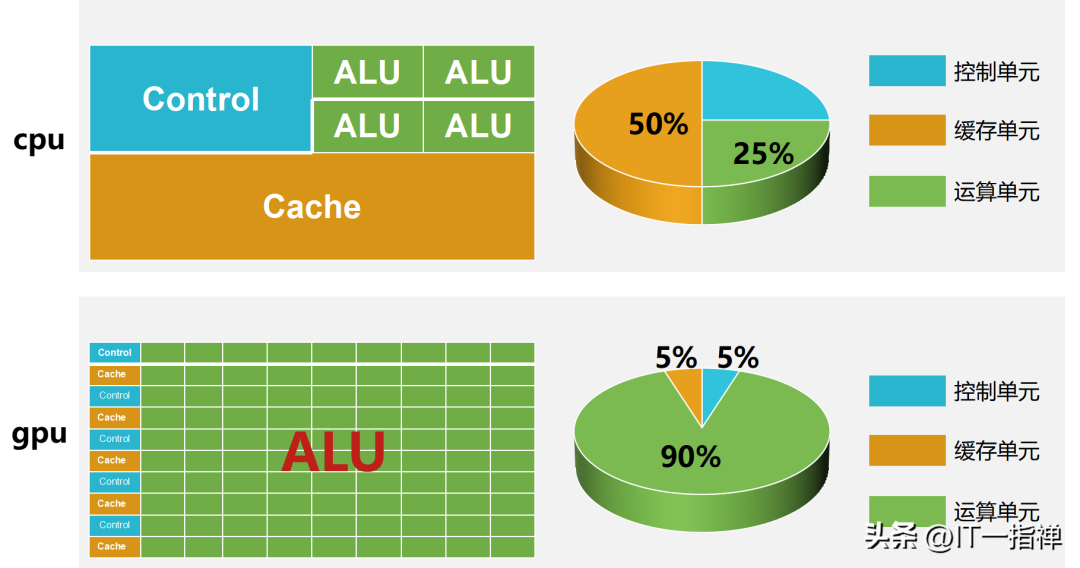
結構組成上的巨大差異說明:CPU的運算能力更加均衡,但是不適合做大量的運算;GPU更適合做大量運算。
這倒不是說GPU更牛X,實際上GPU更像是一大群工廠流水線上的工人,適合做大量的簡單運算,很復雜的搞不了。但是簡單的事情做得非常快,比CPU要快得多。
相比GPU,CPU更像是技術專家,可以做復雜的運算,比如邏輯運算、響應用戶請求、網絡通信等。但是因為ALU占比較少、內核少,所以適合做相對少量的復雜運算。
在CPU里面,大概50%是緩存單元,并且是四級緩存結構;而在GPU中,緩存是一級或者二級的。
CPU性能更加注重線程的性能,在控制部分做的事情較多,這樣做就是為了確保控制指令不能中斷,在浮點計算上功耗少。
相較于CPU,GPU的結構更為簡單,基本上它也只做單精度或雙精度浮點運算。GPU的運算速度更快,吞吐量也更高。
CPU基本上是實時響應,采用多級緩存來保障多個任務的響應速度。
GPU往往采用的是批處理的機制,即:任務先排好隊,挨個處理。
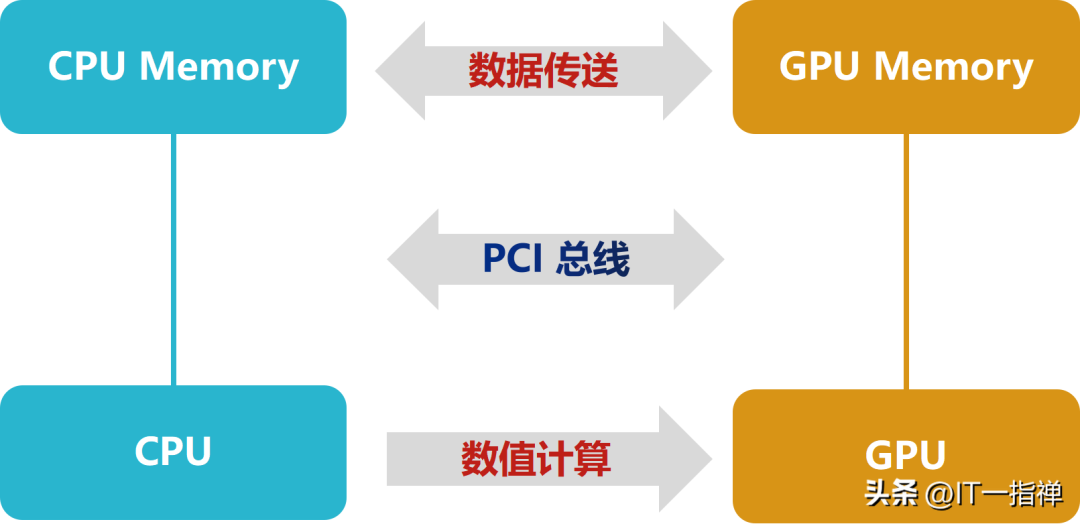
GPU對于圖形處理
我們假設在實時渲染中,一幀1080*720P的圖片,那么這張圖就有大概777600個像素點。如果按照最基本的24幀/秒的幀率計算。1秒鐘就要求計算機處理18662400個,即:1866.24萬個像素點。
這還是高清的情況下,如果是1090*1080、2K、4K甚至8K的視頻渲染,可想而知,這個計算量是何其巨大。尤其是在像游戲這樣的實時渲染場景下,顯然僅僅依靠CPU渲染是會超時的。
實際上,在屏幕中顯示的三維物體都要經過多重的坐標變換,并且物體的表面會受到環境中各種光線的影響,呈現不同的顏色和陰影。這就包括了光線的漫射、折射、透射、散射等。

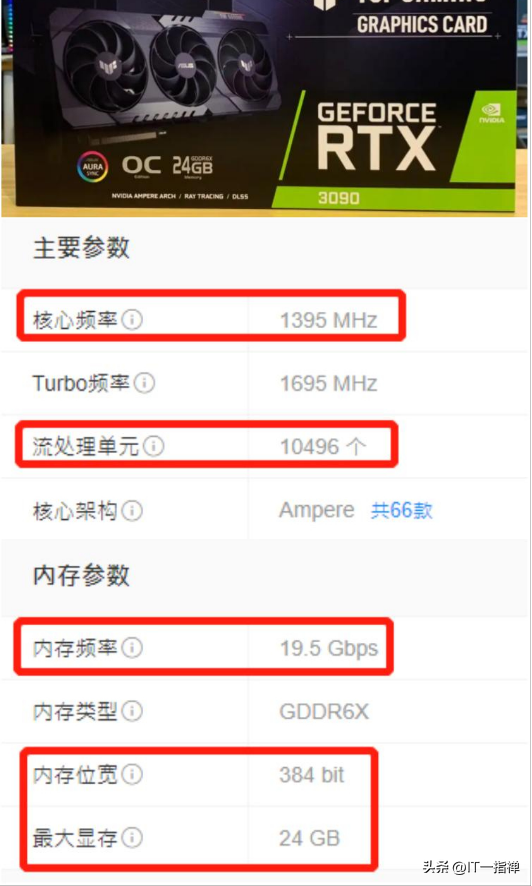
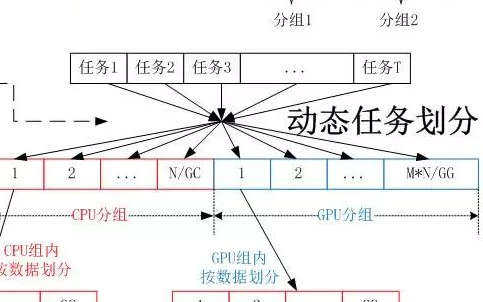
接下來,我們以英偉達NVIDIA RTX3090 為例,看下GPU是如何進行渲染的。
RTX3090的流式多處理器有10496個,每個內核都有具備整數運算和浮點運算的部分,還有用于在操作數中排隊和收集結果的部分。
所謂流式多處理器可以認為是一個獨立的任務處理單元,也可以認為一顆GPU包含了10496個CPU同時處理各個圖片處理任務。
我們就可以通過算法和程序,對1秒鐘18662400個像素點的整體任務進行切割分片,讓10496顆處理器并行計算。
這樣的話,每個處理器負責大概每秒處理18662400/10496,即1778個像素點的渲染任務就行了。
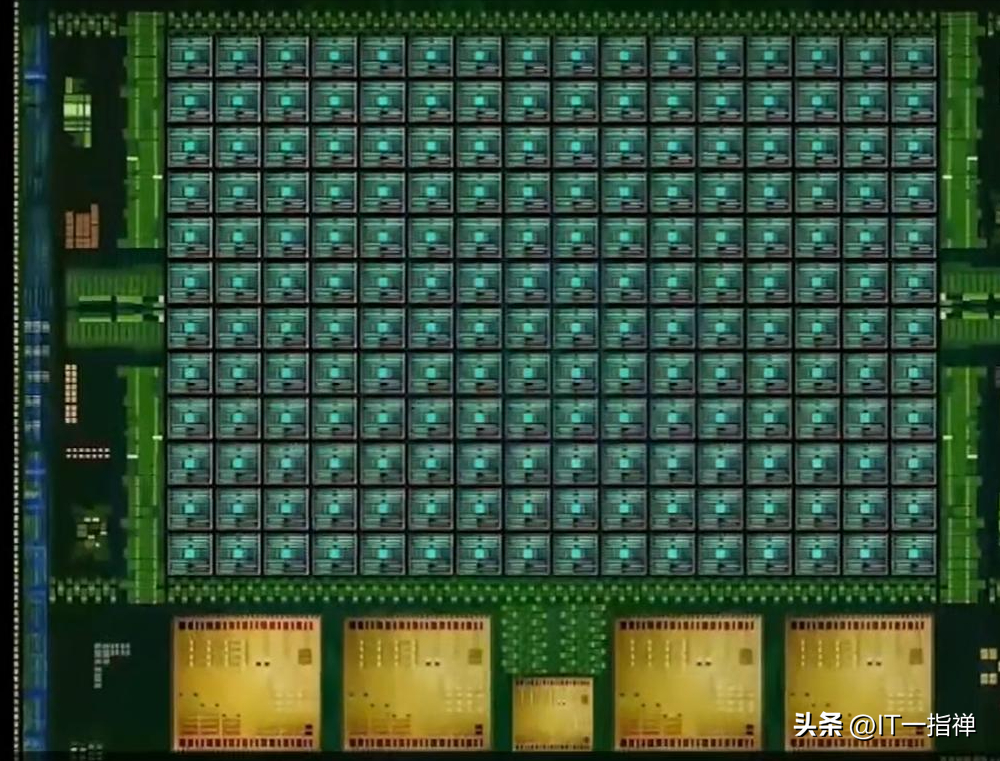
如下圖所示,在GPU中會劃分為多個流式處理區,每個處理區包含數百個內核,每個內核相當于一顆簡化版的CPU,具備整數運算和浮點運算的功能,以及排隊和結果收集功能。

注意,除了流處理器CUDA以外,影響GPU性能的還有
緩存不同
浮點運算方式不同
響應方式不同
核心頻率:頻率越高,性能越強、功耗也越高。
顯示位寬:單位是bit,位寬決定了顯卡同時可以處理的數據量,越大越好。
顯存容量:顯存容量越大,代表能緩存的數據就越多。
顯存頻率:單位是MHz或bps,顯存頻率越高,圖形數據傳輸速度就越快。
總結
一言以蔽之,GPU不管是處理圖形渲染、數值分析,還是處理AI推理。底層邏輯都是將極為繁重的數學進行任務拆解,化繁為簡。
然后,利用GPU多流處理器的機制,將大量的運算拆解為一個個小的、簡單的運算,并行處理。我們也可以認為一個GPU就是一個集群,里面每個流處理器都是一顆CPU,這樣就容易理解了。

以上是關于GPU概念、工作原理的簡要介紹。說是簡單,其實在圖形處理方面,還有很多深層次的處理邏輯沒有展開,比如像素位置變換、三角原理等等。感興趣的小伙伴可以深入研究下。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4919瀏覽量
130769 -
主板
+關注
關注
53文章
2102瀏覽量
72748 -
顯卡
+關注
關注
16文章
2503瀏覽量
69253
原文標題:總結
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

買CPU送GPU的Intel可能砍掉最強核顯Iris Pro

CPU、GPU和內存知識科普

誰才是CPU和GPU融合的領先者?

CPU 的浮點運算能力比 GPU 差,為什么不提高 CPU 的浮點運算能力呢
華為Nova5Pro遇上華為P30Pro后,誰才是最強的華為旗艦呢?
gpu和cpu有什么區別?
cpu gpu npu的區別 NPU與GPU哪個好?gpu是什么意思?
為什么GPU比CPU更快?






 工商網監
工商網監
評論