 人工智能中的訓練與推理
人工智能中的訓練與推理

在想要訓練一個能區分蘋果和香蕉的模型,你需要搜索一些蘋果和香蕉的圖片,將這些圖片放在一起構成訓練數據集(Training Dataset),訓練數據集是有標簽的,蘋果圖片的標簽是蘋果,香蕉圖片的標簽是香蕉。
通過對初始的神經網絡參數不斷地優化來讓模型變得更準確。可能開始對于20張蘋果的照片,只有10張被判斷為蘋果,對另外10張沒有做出正確判斷,這時可以通過優化參數讓神經網絡對20張圖片都做出正確判斷,這個過程就是訓練過程。訓練后的模型能對訓練數據集中所有蘋果圖片準確地加以識別,但是我們的期望是它可以對以前沒看過的圖片進行正確識別。
重新拍一張蘋果的圖片讓神經網絡判斷時,這種圖片叫作現場數據(Live Data),如果神經網絡對現場數據識別的準確率非常高,就證明你的網絡訓練是非常成功的。我們把用訓練好的模型識別新圖片的過程稱為推理。圖中給出了深度學習中訓練和推理的關系。
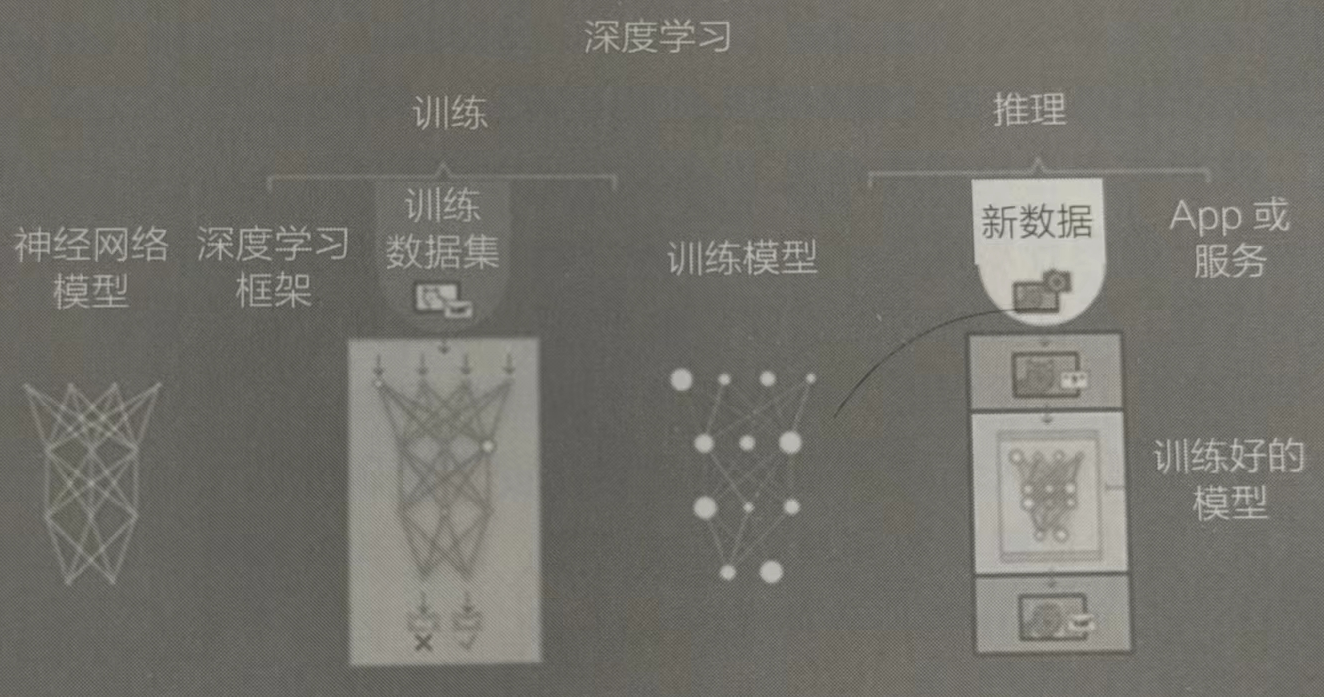 推理是模型的應用過程
推理是模型的應用過程訓練是利用已有數據進行學習的過程,對計算的精度要求較高,會直接影響推理的準確度。而推理是在新的輸入數據下,應用訓練形成的模型完成特定的任務,如圖像識別、自然語言處理等,通常數據量會比訓練小很多,可以放到移動終端設備上進行。
這又涉及一個概念-—部署(Deployment)。把一個訓練好的模型應用起來,使它能夠在移動終端上運行推理,這個過程就稱為部署。
審核編輯黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
神經網絡
+關注
關注
42文章
4812瀏覽量
103198 -
人工智能
+關注
關注
1805文章
48898瀏覽量
247850
發布評論請先 登錄
相關推薦
熱點推薦
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
嵌入式人工智能(EAI)將人工智能集成到機器人等物理實體中,使它們能夠感知、學習環境并與之動態交互。這種能力使此類機器人能夠在人類社會中有效地提供商品及服務。
數據是一種貨幣化工具
數據是互聯網
發表于 12-24 00:33
人工智能推理及神經處理的未來
人工智能行業所圍繞的是一個受技術進步、社會需求和監管政策影響的動態環境。機器學習、自然語言處理和計算機視覺方面的技術進步,加速了人工智能的發展和應用。包括醫療保健、金融和制造業在內的各個行業對自動化

嵌入式和人工智能究竟是什么關系?
嵌入式和人工智能究竟是什么關系?
嵌入式系統是一種特殊的系統,它通常被嵌入到其他設備或機器中,以實現特定功能。嵌入式系統具有非常強的適應性和靈活性,能夠根據用戶需求進行定制化設計。它廣泛應用于各種
發表于 11-14 16:39
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
、優化等方面的應用有了更清晰的認識。特別是書中提到的基于大數據和機器學習的能源管理系統,通過實時監測和分析能源數據,實現了能源的高效利用和智能化管理。
其次,第6章通過多個案例展示了人工智能在能源科學中
發表于 10-14 09:27
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
農業、環保等,為人類社會的可持續發展做出貢獻。
總結
《AI for Science:人工智能驅動科學創新》第4章關于AI與生命科學的部分,為我們展示了一個充滿希望和機遇的未來。在這個未來中,人工智能
發表于 10-14 09:21
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
人工智能在科學研究中的核心技術,包括機器學習、深度學習、神經網絡等。這些技術構成了AI for Science的基石,使得AI能夠處理和分析復雜的數據集,從而發現隱藏在數據中的模式和規律。
2. 高性能
發表于 10-14 09:16
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
的效率,還為科學研究提供了前所未有的洞察力和精確度。例如,在生物學領域,AI能夠幫助科學家快速識別基因序列中的關鍵變異,加速新藥研發進程。
2. 跨學科融合的新范式
書中強調,人工智能的應用促進了多個
發表于 10-14 09:12
人工智能云計算是什么
人工智能云計算,簡而言之,是指將人工智能技術與云計算平臺相結合,利用云計算的強大計算力、存儲能力和靈活可擴展性,來加速AI模型的訓練、推理和優化過程,同時實現AI服務的廣泛部署和按需使
risc-v在人工智能圖像處理應用前景分析
定制性。這些特點使得RISC-V在多個領域,包括人工智能圖像處理領域,具有顯著的優勢。
二、RISC-V在人工智能圖像處理中的優勢
開源性和靈活性 :
RISC-V的開源性意味著任何人都可以自由研究
發表于 09-28 11:00
人工智能ai4s試讀申請
目前人工智能在繪畫對話等大模型領域應用廣闊,ai4s也是方興未艾。但是如何有效利用ai4s工具助力科研是個需要研究的課題,本書對ai4s基本原理和原則,方法進行描訴,有利于總結經驗,擬按照要求準備相關體會材料。看能否有助于入門和提高ss
發表于 09-09 15:36
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
材料基因組工程的推動下,人工智能如何與材料科學結合,加快傳統材料和新型材料的開發過程。
第4章介紹了人工智能在加快藥物研發、輔助基因研究方面及在合成生物學中的普遍應用。
第5章介紹了人工智能
發表于 09-09 13:54
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
,得到了華為、騰訊、優必選、中煤科工、中國聯通、云天勵飛、考拉悠然、智航、力維智聯等國內人工智能企業的深度參與和大力支持。
報名后即可到現場領取禮品,總計5000份,先到先選!
點擊報名:https://bbs.elecfans.com/jishu_2447254_1
發表于 08-22 15:00
FPGA在人工智能中的應用有哪些?
FPGA(現場可編程門陣列)在人工智能領域的應用非常廣泛,主要體現在以下幾個方面:
一、深度學習加速
訓練和推理過程加速:FPGA可以用來加速深度學習的訓練和
發表于 07-29 17:05
OpenAI草莓項目:引領人工智能向類人推理新紀元邁進
在人工智能技術的浩瀚星海中,OpenAI正以其獨特的“草莓”項目,引領著一場前所未有的智能革命。據權威媒體路透社的最新揭秘,這家由微軟鼎力支持的初創企業,正秘密醞釀一項旨在極大提升人工智能推理





 工商網監
工商網監
評論