 聊聊自動駕駛感知系統
聊聊自動駕駛感知系統

感知是什么?
在自動駕駛賽道中,感知的目的是為了模仿人眼采集相關信息,為后續做決策提供必要的信息。根據所做決策的任務不同,感知可以包括很多子任務:如車道線檢測、3D目標檢測、障礙物檢測、紅綠燈檢測等等;再根據感知預測出的結果,完成決策;最后根據決策結果執行相應的操作(如變道、超車等);
如何進行感知?
由于感知是為了模仿人眼獲取周圍的環境信息,那就必然需要用到傳感器來完成信息的采集工作;目前在自動駕駛領域中用到的傳感器包括:攝像頭(camera)、激光雷達(lidar)、毫米波雷達(radar)等;
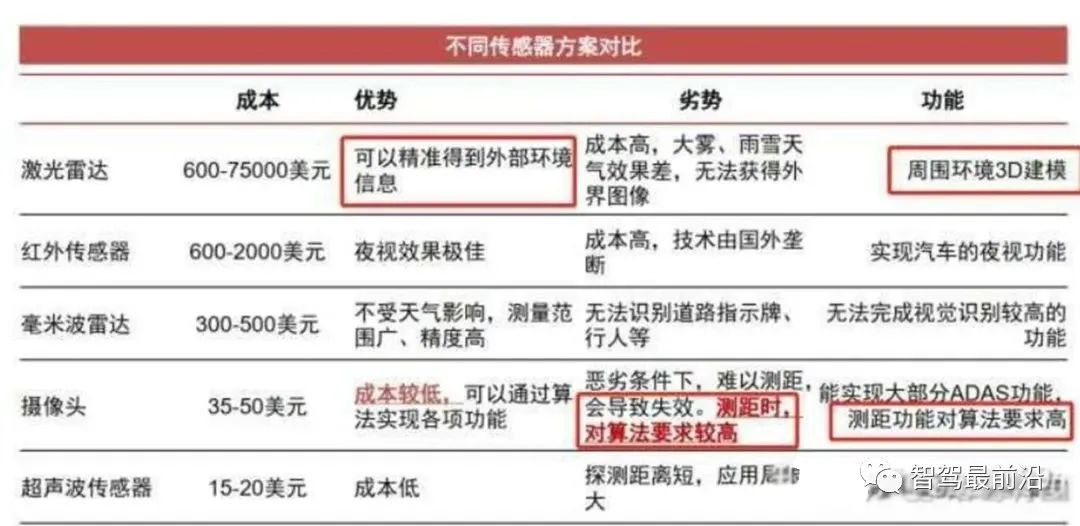
可以看到傳感器的種類眾多且成本參差不齊,所以如何使用這些傳感器進行感知任務,各個自動駕駛廠商都有各自的解決方案;
純視覺的感知方案
目前Tesla是純視覺感知方案的典型代表;
純視覺感知方案的優缺點也很明顯:優點:價格成本很低;缺點:攝像頭采集到的圖片是2D的,缺少深度信息,深度信息需要靠算法學習得到,缺少魯棒性;
多傳感器融合的感知方案
目前大多數廠商采用的都是多傳感器融合的解決方案;其優缺點是:優點:能夠充分利用不同工作原理的傳感器,提升對不同場景下的整體感知精度,也可以在某種傳感器出現失效時,其他傳感器可以作為冗余備份,提高系統的魯棒性;缺點:由于采用多種傳感器價格相比純視覺高很多;
多傳感器融合的感知方案
傳感器后融合
所謂后融合,是指各傳感器針對目標物體單獨進行深度學習模型推理,從而各自輸出帶有傳感器自身屬性的結果;每種傳感器的識別結果輸入到融合模塊,融合模塊對各傳感器在不同場景下的識別結果,設置不同的置信度,最終根據融合策略進行決策。
整體流程圖如下:
 圖源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA
圖源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA
優點:不同的傳感器都獨立進行目標識別,解耦性好,且各傳感器可以互為冗余備份;同時后融合方案便于做標準的模塊化開發,把接口封裝好,提供給主機廠“即插即用”;對于主機廠來說,每種傳感器的識別結果輸入到融合模塊,融合模塊對各傳感器在不同場景下的識別結果,設置不同的置信度,最終根據融合策略進行決策。
缺點:存在“時間上的感知不連續”及“空間上的感知碎片化”
空間上的感知碎片化
由于車身四周的lidar、camera角度的安裝問題,多個傳感器實體無法實現空間域內的連續覆蓋和統一識別,導致攝像頭只捕捉到了目標的一小部分,無法根據殘缺的信息作出正確的檢測結果,從而使得后續的融合效果無法保證。
時間上的感知不連續
攝像頭采集到的結果是以幀為單位的,常用的感知方法是把連續單幀的檢測結果串聯起來,類似后融合的策略,無法充分利用時序上的有用信息。
傳感器前融合
所謂前融合,是將各個傳感器采集到的數據匯總到一起,經過數據同步后,對這些原始數據進行融合。
整體流程圖如下:
 圖源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA
圖源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA
優點:讓數據更早的做融合,使數據更有關聯性;比如把激光雷達的點云數據和攝像頭的像素級數據進行融合,數據的損失也會比較少。
缺點:由于不同傳感器獲取的數據(攝像圖獲取的像素數據以及激光雷達獲取的點云數據),其坐標系是不同的;視覺數據是2D空間,而激光雷達的點云數據是3D空間。所以在異構數據的融合時,有兩種途徑:途徑一:在圖像空間利用點云數據提供深度信息;途徑二:在點云空間利用視覺數據提供語義特征,進行點云染色或特征渲染;
所以為了保證將不同坐標系下的數據(像素數據、點云數據)轉換到同一坐標系下進行數據融合方便后續的感知任務,BEV(Bird Eye View)視角下的感知逐漸受到廣泛的關注。
傳感器中融合
所謂中融合,就是先將各個傳感器采集到的數據通過神經網絡提取數據的特征,再對神經網絡提取到的多種傳感器特征進行特征級的融合,從而更有可能得到最佳感知結果。對異構數據提取到的特征在BEV空間進行特征級的融合,一來數據損失少,二來算力消耗也較少(相對于前融合),所以針對BEV視角下的感知任務,采用中融合的策略比較多。
BEV視角下的感知任務范式
- 將攝像頭數據(2D圖片)輸入到特征提取網絡中完成多個攝像頭數據的特征提取;
- 將所有攝像頭數據提取到的特征通過網絡學習的方式映射到BEV空間下;
- 在BEV空間下,進行異構數據的融合,將圖像數據在BEV空間下映射的特征與激光雷達點云特征進行融合;(可選,如BEVFormer僅用6個攝像頭構建BEV空間特征)
- 進行時序融合,融合前幾個時刻的特征,增強感知能力;(個人認為:引入時序特征后可以在一定程度上解決遮擋問題)
- 根據獲得到BEV特征,用于下游任務;(車道線檢測、障礙物檢測、3D目標檢測等子任務,相當于整個模型是一個多任務學習模型)
BEV視角下的感知具有的優勢
- 跨攝像頭融合和異構數據融合更容易實現
跨攝像頭融合或者異構數據進行融合時,由于不同數據其表示的坐標系不同,需要用很多后處理規則去關聯不同傳感器的感知結果,流程非常復雜。在BEV空間內做融合后,通過網絡自主學習映射規則,產生BEV特征用于感知下游任務,算法實現更加簡單,并且BEV空間內視覺感知到的物體大小和朝向也都能直接得到表達。
- 時序融合更容易實現
在構建BEV空間時,可以很容易地融合時序信息,使得獲取的BEV特征可以更好地實現下游的一些感知任務,如測速任務。
- 一定程度上緩解感知任務中的遮擋問題
傳統的2D感知任務只能感知看得見的目標,對于遮擋完全無能為力,而在BEV空間內,可以基于先驗知識或者利用時序融合,對被遮擋的區域進行預測,從而“腦補”出被遮擋區域可能存在物體。雖然“腦補”出的物體,有一定“想象”的成分,但這對于下游的規控模塊仍有很多好處。
- 方便多任務學習
使用傳統方法做感知任務時,需要依次做目標識別、追蹤和運動預測,更像是個“串行系統”,上游的誤差會傳遞到下游從而造成誤差累積;而在BEV空間內,感知和運動預測在統一空間內完成,因而可以通過神經網絡直接做端到端優化,“并行”出結果,這樣既可以避免誤差累積,也大大減少了人工邏輯的作用,讓感知網絡可以通過數據驅動的方式來自學習,從而更好地實現功能迭代。
-
目標檢測
+關注
關注
0文章
224瀏覽量
15996 -
感知系統
+關注
關注
1文章
77瀏覽量
16209 -
自動駕駛
+關注
關注
788文章
14304瀏覽量
170489
發布評論請先 登錄





 工商網監
工商網監
評論