") 想要kafka好用你就得知道這些工具
想要kafka好用你就得知道這些工具
前言
工欲善其事,必先利其器。本文主要分享一下消息中間件kafka安裝部署的過程,以及我平時(shí)在工作中針對(duì)kafka用的一些客戶端工具和監(jiān)控工具。
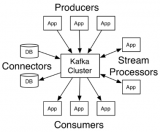
kafka部署架構(gòu)
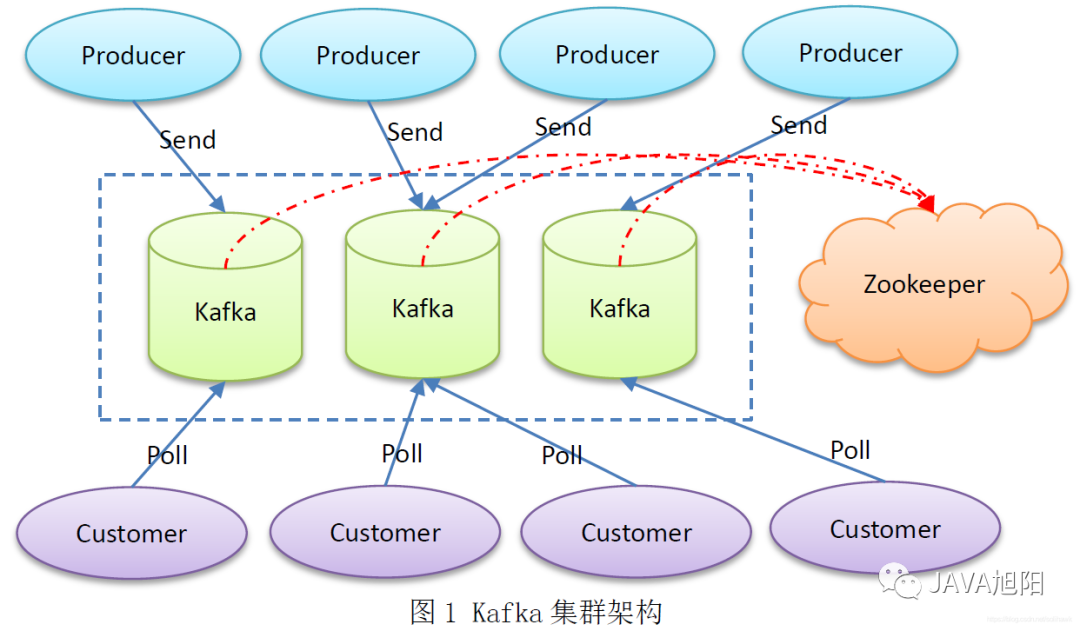
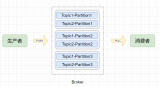
一個(gè)kafka集群由多個(gè)kafka broker組成,每個(gè)broker將自己的元數(shù)據(jù)信息注冊(cè)到zookeeper中,通過zookeeper關(guān)聯(lián)形成一個(gè)集群。
prettyZoo客戶端
既然kafka依賴zookeeper,我難免就需要看看zookeeper中究竟存儲(chǔ)了kafka的哪些數(shù)據(jù),這邊介紹一款高顏值的客戶端工具prettyZoo。PrettyZoo是一款基于Apache Curator 和 JavaFX 實(shí)現(xiàn)的 Zookeeper 圖形化管理客戶端,使用非常簡(jiǎn)單。
下載地址: https://github.com/vran-dev/PrettyZoo
- 連接

- 界面化操作
zookeeper

小tips: kafka部署時(shí)配置文件中配置zookeeper地址的時(shí)候,可以采用如下的方式,帶上目錄,比如xxxx:2181/kafka或者xxxx:2181/kafka1,可以避免沖突。
#配置連接 Zookeeper 集群地址(在 zk 根目錄下創(chuàng)建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/ka
fka
kafka Tool客戶端
Kafka Tool是一個(gè)用于管理和使用Apache Kafka集群的GUI應(yīng)用程序。Kafka Tool提供了一個(gè)較為直觀的UI可讓用戶快速查看Kafka集群中的對(duì)象以及存儲(chǔ)在topic中的消息,提供了一些專門面向開發(fā)人員和管理員的功能。
下載地址: https://www.kafkatool.com/index.html

kafka監(jiān)控工具
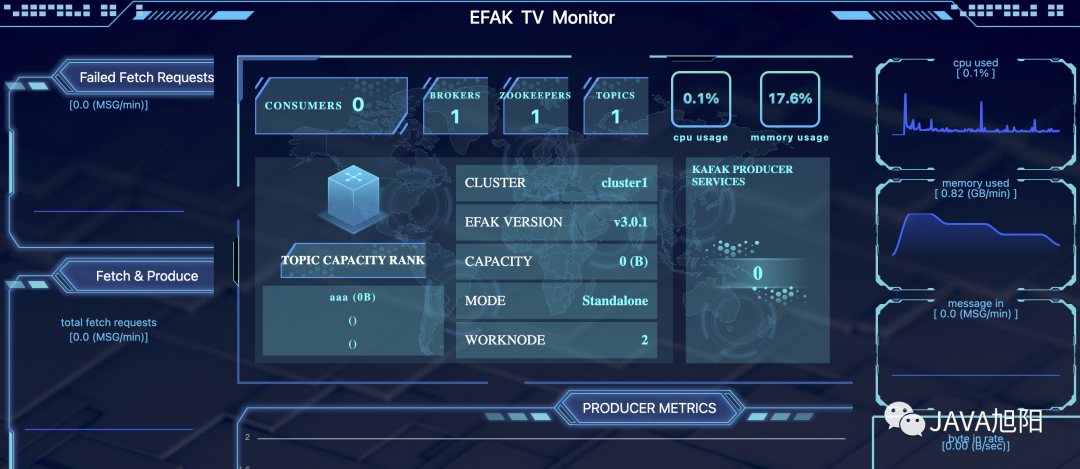
kafka 自身并沒有集成監(jiān)控管理系統(tǒng),因此對(duì) kafka 的監(jiān)控管理比較不便,好在有大量的第三方監(jiān)控管理系統(tǒng)來使用,這里介紹一款優(yōu)秀的監(jiān)控工具Kafka Eagle,可以用監(jiān)控 Kafka 集群的整體運(yùn)行情況。
下載地址 :https://www.kafka-eagle.org/,部署也很簡(jiǎn)單,根據(jù)官方文檔一步一步來即可。
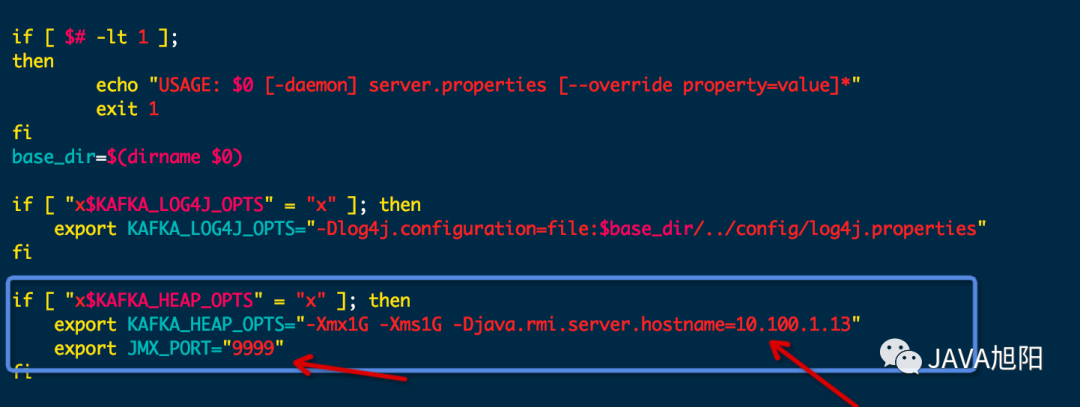
注意,kafka需要開啟JMX端口,即修改kafka的啟動(dòng)命令文件kafka-server-start.sh,如下圖:

kafka集群部署
一、zookeeper集群部署
- 上傳安裝包
- 移動(dòng)到指定文件夾
mv zookeeper-3.4.6.tar.gz /opt/apps/
- 解壓
tar -zxvf zookeeper-3.4.6.tar.gz
- 修改配置文件
- 進(jìn)入配置文件目錄
cd /opt/apps/zookeeper-3.4.6/conf
- 修改配置文件名稱
mv zoo_sample.cfg zoo.cfg
- 編輯配置文件
vi zoo.cfg
## zk數(shù)據(jù)保存位置
dataDir=/opt/apps/data/zkdata
## 集群配置, hadoop1、hadoop2、hadoop3是主機(jī)名,后面是端口,沒有被占用即可
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
- 創(chuàng)建數(shù)據(jù)目錄
mkdir -p /opt/apps/data/zkdata
- 生成一個(gè)
myid文件,內(nèi)容為它的id, 表示是哪個(gè)節(jié)點(diǎn)。
echo 1 > /opt/apps/data/zkdata/myid
- 配置環(huán)境變量
vi /etc/profile
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/apps/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile
- 在其他幾個(gè)節(jié)點(diǎn),即
hadoop2,hadoop3上重復(fù)上面的步驟,但是myid文件的內(nèi)容有所區(qū)別,分別是對(duì)應(yīng)的id。
echo 2 > /opt/apps/data/zkdata/myid
echo 3 > /opt/apps/data/zkdata/myid
- 啟停集群
bin/zkServer.sh start zk 服務(wù)啟動(dòng)
bin/zkServer.sh status zk 查看服務(wù)狀態(tài)
bin/zkServer.sh stop zk 停止服務(wù)
二、kafka集群部署
- 官方下載地址:
http://kafka.apache.org/downloads.html - 上傳安裝包, 移動(dòng)到指定文件夾
mv kafka_2.11-2.2.2.tgz /opt/apps/
- 解壓
tar -zxvf kafka_2.11-2.2.2.tgz
- 修改配置文件
- 進(jìn)入配置文件目錄
cd /opt/apps/kafka_2.11-2.2.2/config
- 編輯配置文件
vi server.properties
#為依次增長(zhǎng)的:0、1、2、3、4,集群中唯一 id
broker.id=0
#數(shù)據(jù)存儲(chǔ)的?錄
log.dirs=/opt/apps/data/kafkadata
#指定 zk 集群地址,注意這里加了一個(gè)目錄
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka
其他的配置內(nèi)容說明如下:
#broker 的全局唯一編號(hào),不能重復(fù),只能是數(shù)字。
broker.id=0
#處理網(wǎng)絡(luò)請(qǐng)求的線程數(shù)量
num.network.threads=3
#用來處理磁盤 IO 的線程數(shù)量
num.io.threads=8
#發(fā)送套接字的緩沖區(qū)大小
socket.send.buffer.bytes=102400
#接收套接字的緩沖區(qū)大小
socket.receive.buffer.bytes=102400
#請(qǐng)求套接字的緩沖區(qū)大小
socket.request.max.bytes=104857600
#kafka 運(yùn)行日志(數(shù)據(jù))存放的路徑,路徑不需要提前創(chuàng)建,kafka 自動(dòng)幫你創(chuàng)建,可以
配置多個(gè)磁盤路徑,路徑與路徑之間可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic 在當(dāng)前 broker 上的分區(qū)個(gè)數(shù)
num.partitions=1
#用來恢復(fù)和清理 data 下數(shù)據(jù)的線程數(shù)量
num.recovery.threads.per.data.dir=1
# 每個(gè) topic 創(chuàng)建時(shí)的副本數(shù),默認(rèn)時(shí) 1 個(gè)副本
offsets.topic.replication.factor=1
#segment 文件保留的最長(zhǎng)時(shí)間,超時(shí)將被刪除
log.retention.hours=168
#每個(gè) segment 文件的大小,默認(rèn)最大 1G
log.segment.bytes=1073741824
# 檢查過期數(shù)據(jù)的時(shí)間,默認(rèn) 5 分鐘檢查一次是否數(shù)據(jù)過期
log.retention.check.interval.ms=300000
#配置連接 Zookeeper 集群地址(在 zk 根目錄下創(chuàng)建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/ka
fka
- 配置環(huán)境變量
vi /etc/profile
export KAFKA_HOME=/opt/apps/kafka_2.11-2.2.2
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
- 在不同的節(jié)點(diǎn)上重復(fù)上面的步驟,但是需要修改配置文件
server.properties中的broker.id。
# broker.id標(biāo)記是哪個(gè)kafka節(jié)點(diǎn),不能重復(fù)
broker.id=1
broker.id=2
- 啟停集群
# 啟動(dòng)集群
bin/kafka-server-start.sh -daemon /opt/apps/kafka_2.11-2.2.2/config/server.properties
# 停止集群
bin/kafka-server-stop.sh stop
kafka命令行工具
1. 主題命令行操作
- 查看操作主題命令參數(shù)
kafka-topics.sh

- 查看當(dāng)前服務(wù)器中的所有
topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
- 創(chuàng)建
first topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first
選項(xiàng)說明:
--topic 定義 topic 名
--replication-factor 定義副本數(shù)
--partitions 定義分區(qū)數(shù)
- 查看
first主題的詳情
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
- 修改分區(qū)數(shù)(注意: 分區(qū)數(shù)只能增加,不能減少 )
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
- 刪除 topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first
2. 生產(chǎn)者命令行操作
- 查看操作生產(chǎn)者命令參數(shù)
kafka-console-producer.sh

- 發(fā)送消息
bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
>hello world
>xuyang hello
3. 消費(fèi)者命令行操作
- 查看操作消費(fèi)者命令參數(shù)
kafka-console-consumer.sh


- 消費(fèi)消息
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
- 把主題中所有的數(shù)據(jù)都讀取出來(包括歷史數(shù)據(jù))。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
總結(jié)
本文分享了平時(shí)我在工作使用kafka以及zookeeper常用的一些工具,同時(shí)分享了kafka集群的部署,值得一提的是kafka部署配置zookeeper地址的時(shí)候,我們可以添加一個(gè)路徑,比如hadoop:2181/kafka這種方式,那么kafka的元數(shù)據(jù)信息都會(huì)放到/kafka這個(gè)目錄下,以防混淆。
-
配置
+關(guān)注
關(guān)注
1文章
191瀏覽量
18830 -
kafka
+關(guān)注
關(guān)注
0文章
53瀏覽量
5376
發(fā)布評(píng)論請(qǐng)先 登錄
緩存有大key?你得知道的一些手段
很好用的工具欄翻譯軟件
Kafka幾個(gè)比較重要的配置參數(shù)
Kafka集群環(huán)境的搭建
Kafka和消息隊(duì)列的關(guān)系
安全工程師的這些事你得知道
2020年最火十大物聯(lián)網(wǎng)應(yīng)用你知道有哪些嗎
Kafka的概念及Kafka的宕機(jī)
監(jiān)控Kafka集群的常用的方法和工具介紹

超詳細(xì)“零”基礎(chǔ)kafka入門篇





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論