") 什么是CPU、GPU、TPU、DPU、NPU、BPU?有什么區(qū)別?
什么是CPU、GPU、TPU、DPU、NPU、BPU?有什么區(qū)別?
技術(shù)日新月異,物聯(lián)網(wǎng)、人工智能、深度學(xué)習(xí)等遍地開(kāi)花,各類(lèi)芯片名詞GPU, TPU, NPU,DPU層出不窮…它們都是什么鬼?又有什么不一樣?
01
CPU,作為機(jī)器的“大腦”,它是布局謀略、發(fā)號(hào)施令、控制行動(dòng)的“總司令官”,擔(dān)負(fù)著整個(gè)計(jì)算機(jī)系統(tǒng)的核心任務(wù)。
CPU由多個(gè)結(jié)構(gòu)組成,其中包括運(yùn)算器(ALU, Arithmetic and Logic Unit)、控制單元(CU, Control Unit)、寄存器(Register)、高速緩存器(Cache),它們之間通過(guò)數(shù)據(jù)、控制及狀態(tài)總線(xiàn)進(jìn)行通訊。這些結(jié)構(gòu)和通訊方式是CPU完成各種任務(wù)的必要基礎(chǔ),也是提高計(jì)算機(jī)運(yùn)算效率的關(guān)鍵因素。
簡(jiǎn)單來(lái)說(shuō):CPU架構(gòu)由計(jì)算單元、控制單元和存儲(chǔ)單元三部分組成,如下圖所示:
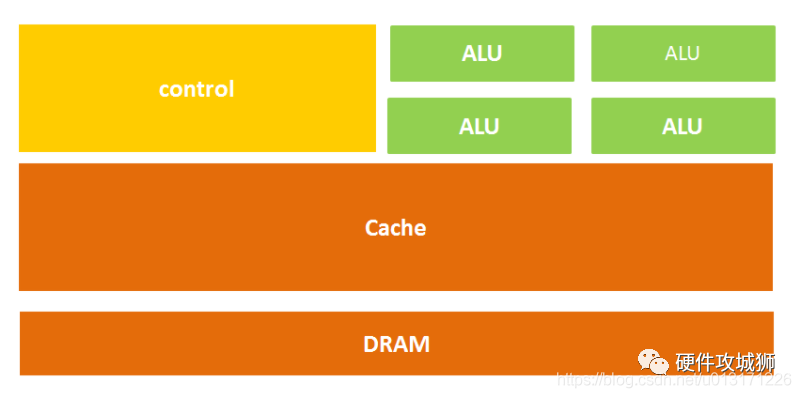

從字面上我們也很好理解,計(jì)算單元主要執(zhí)行算術(shù)運(yùn)算、移位等操作以及地址運(yùn)算和轉(zhuǎn)換;存儲(chǔ)單元主要用于保存運(yùn)算中產(chǎn)生的數(shù)據(jù)以及指令等;控制單元?jiǎng)t對(duì)指令譯碼,并且發(fā)出為完成每條指令所要執(zhí)行的各個(gè)操作的控制信號(hào)。
所以一條指令在CPU中執(zhí)行的過(guò)程是這樣的:讀取到指令后,通過(guò)指令總線(xiàn)送到控制器(黃色區(qū)域)中進(jìn)行譯碼,并發(fā)出相應(yīng)的操作控制信號(hào);然后運(yùn)算器(綠色區(qū)域)按照操作指令對(duì)數(shù)據(jù)進(jìn)行計(jì)算,并通過(guò)數(shù)據(jù)總線(xiàn)將得到的數(shù)據(jù)存入數(shù)據(jù)緩存器(大塊橙色區(qū)域)。過(guò)程如下圖所示:
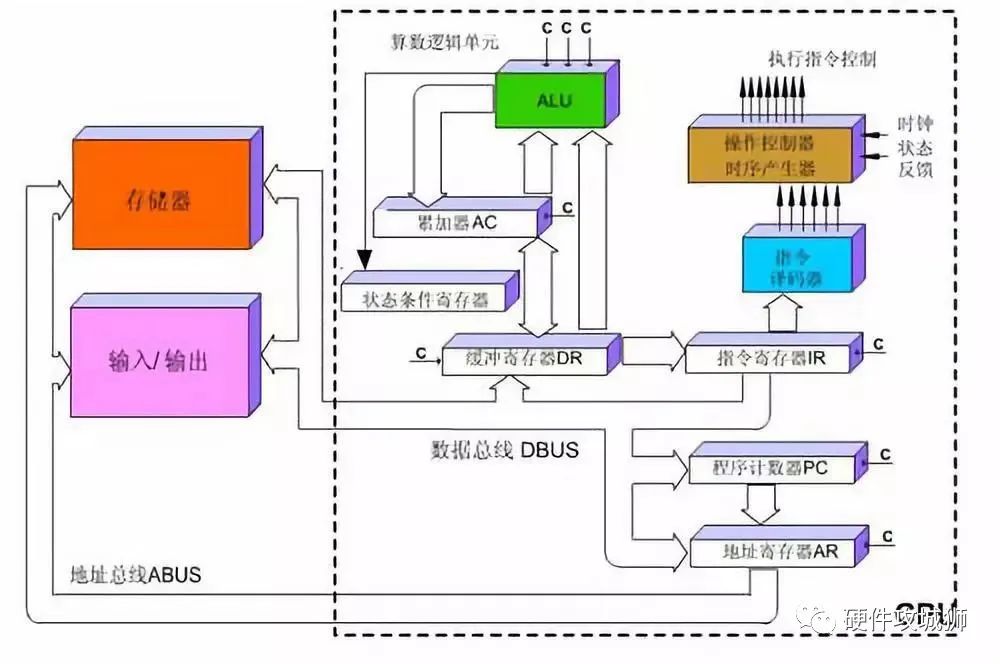
圖:CPU執(zhí)行指令圖?
?
CPU遵循的是馮諾依曼架構(gòu),其核心就是:存儲(chǔ)程序,順序執(zhí)行。在這個(gè)結(jié)構(gòu)圖中,負(fù)責(zé)計(jì)算的綠色區(qū)域占的面積似乎太小了,而橙色區(qū)域的緩存Cache和黃色區(qū)域的控制單元占據(jù)了大量空間。
因?yàn)镃PU的架構(gòu)中需要大量的空間去放置存儲(chǔ)單元(橙色部分)和控制單元(黃色部分),相比之下計(jì)算單元(綠色部分)只占據(jù)了很小的一部分,所以它在大規(guī)模并行計(jì)算能力上極受限制,而更擅長(zhǎng)于邏輯控制。
另外,因?yàn)樽裱T諾依曼架構(gòu)(存儲(chǔ)程序,順序執(zhí)行),CPU就像是個(gè)一板一眼的管家,人們吩咐的事情它總是一步一步來(lái)做。但是隨著人們對(duì)更大規(guī)模與更快處理速度的需求的增加,這位管家漸漸變得有些力不從心。
于是,能不能把多個(gè)處理器放在同一塊芯片上,讓它們一起來(lái)做事,這樣效率不就提高了嗎?GPU便由此誕生了。
02
GPU
GPU全稱(chēng)為Graphics Processing Unit,中文為圖形處理器,就如它的名字一樣,GPU最初是用在個(gè)人電腦、工作站、游戲機(jī)和一些移動(dòng)設(shè)備(如平板電腦、智能手機(jī)等)上運(yùn)行繪圖運(yùn)算工作的微處理器。
為什么GPU特別擅長(zhǎng)處理圖像數(shù)據(jù)呢?這是因?yàn)閳D像上的每一個(gè)像素點(diǎn)都有被處理的需要,而且每個(gè)像素點(diǎn)處理的過(guò)程和方式都十分相似,也就成了GPU的天然溫床。
GPU簡(jiǎn)單架構(gòu)如下圖所示:
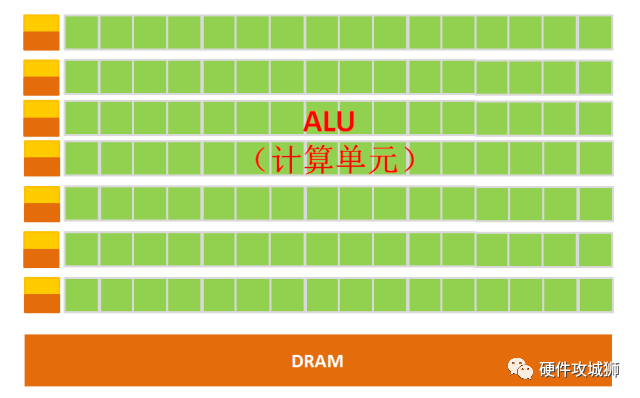
圖:GPU微架構(gòu)示意圖
從架構(gòu)圖我們就能很明顯的看出,GPU的構(gòu)成相對(duì)簡(jiǎn)單,有數(shù)量眾多的計(jì)算單元和超長(zhǎng)的流水線(xiàn),特別適合處理大量的類(lèi)型統(tǒng)一的數(shù)據(jù)。
但GPU無(wú)法單獨(dú)工作,必須由CPU進(jìn)行控制調(diào)用才能工作。CPU可單獨(dú)作用,處理復(fù)雜的邏輯運(yùn)算和不同的數(shù)據(jù)類(lèi)型,但當(dāng)需要大量的處理類(lèi)型統(tǒng)一的數(shù)據(jù)時(shí),則可調(diào)用GPU進(jìn)行并行計(jì)算。
注:GPU中有很多的運(yùn)算器ALU和很少的緩存cache,緩存的目的不是保存后面需要訪(fǎng)問(wèn)的數(shù)據(jù)的,這點(diǎn)和CPU不同,而是為線(xiàn)程thread提高服務(wù)的。如果有很多線(xiàn)程需要訪(fǎng)問(wèn)同一個(gè)相同的數(shù)據(jù),緩存會(huì)合并這些訪(fǎng)問(wèn),然后再去訪(fǎng)問(wèn)dram。
再把CPU和GPU兩者放在一張圖上看下對(duì)比,就非常一目了然了。
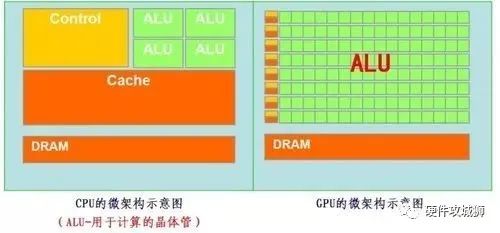
GPU的工作大部分都計(jì)算量大,但沒(méi)什么技術(shù)含量,而且要重復(fù)很多很多次。
借用知乎上某大神的說(shuō)法,就像你有個(gè)工作需要計(jì)算幾億次一百以?xún)?nèi)加減乘除一樣,最好的辦法就是雇上幾十個(gè)小學(xué)生一起算,一人算一部分,反正這些計(jì)算也沒(méi)什么技術(shù)含量,純粹體力活而已;而CPU就像老教授,積分微分都會(huì)算,就是工資高,一個(gè)老教授資頂二十個(gè)小學(xué)生,你要是富士康你雇哪個(gè)?
GPU就是用很多簡(jiǎn)單的計(jì)算單元去完成大量的計(jì)算任務(wù),純粹的人海戰(zhàn)術(shù)。這種策略基于一個(gè)前提,就是小學(xué)生A和小學(xué)生B的工作沒(méi)有什么依賴(lài)性,是互相獨(dú)立的。
有一點(diǎn)需要強(qiáng)調(diào),雖然GPU是為了圖像處理而生的,但是我們通過(guò)前面的介紹可以發(fā)現(xiàn),它在結(jié)構(gòu)上并沒(méi)有專(zhuān)門(mén)為圖像服務(wù)的部件,只是對(duì)CPU的結(jié)構(gòu)進(jìn)行了優(yōu)化與調(diào)整,所以現(xiàn)在GPU不僅可以在圖像處理領(lǐng)域大顯身手,它還被用來(lái)科學(xué)計(jì)算、密碼**、數(shù)值分析,海量數(shù)據(jù)處理(排序,Map-Reduce等),金融分析等需要大規(guī)模并行計(jì)算的領(lǐng)域。
所以GPU也可以認(rèn)為是一種較通用的芯片。
03
TPU
按照上文所述,CPU和GPU都是較為通用的芯片,但是有句老話(huà)說(shuō)得好:萬(wàn)能工具的效率永遠(yuǎn)比不上專(zhuān)用工具。
隨著人們的計(jì)算需求越來(lái)越專(zhuān)業(yè)化,人們希望有芯片可以更加符合自己的專(zhuān)業(yè)需求,這時(shí),便產(chǎn)生了ASIC(專(zhuān)用集成電路)的概念。
ASIC是指依產(chǎn)品需求不同而定制化的特殊規(guī)格集成電路,由特定使用者要求和特定電子系統(tǒng)的需要而設(shè)計(jì)、制造。當(dāng)然這概念不用記,簡(jiǎn)單來(lái)說(shuō)就是定制化芯片。
因?yàn)锳SIC很“專(zhuān)一”,只做一件事,所以它就會(huì)比CPU、GPU等能做很多件事的芯片在某件事上做的更好,實(shí)現(xiàn)更高的處理速度和更低的能耗。但相應(yīng)的,ASIC的生產(chǎn)成本也非常高。
而TPU(Tensor Processing Unit, 張量處理器)就是谷歌專(zhuān)門(mén)為加速深層神經(jīng)網(wǎng)絡(luò)運(yùn)算能力而研發(fā)的一款芯片,其實(shí)也是一款A(yù)SIC。
原來(lái)很多的機(jī)器學(xué)習(xí)以及圖像處理算法大部分都跑在GPU與FPGA(半定制化芯片)上面,但這兩種芯片都還是一種通用性芯片,所以在效能與功耗上還是不能更緊密的適配機(jī)器學(xué)習(xí)算法,而且Google一直堅(jiān)信偉大的軟件將在偉大的硬件的幫助下更加大放異彩,所以Google便想,我們可不可以做出一款專(zhuān)用機(jī)機(jī)器學(xué)習(xí)算法的專(zhuān)用芯片,TPU便誕生了。
據(jù)稱(chēng),TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云來(lái)實(shí)時(shí)收集數(shù)據(jù)并產(chǎn)生結(jié)果,而訓(xùn)練過(guò)程還需要額外的資源;而第二代TPU既可以用于訓(xùn)練神經(jīng)網(wǎng)絡(luò),又可以用于推理。
看到這里你可能會(huì)問(wèn)了,為什么TPU會(huì)在性能上這么牛逼呢?
嗯,谷歌寫(xiě)了好幾篇論文和博文來(lái)說(shuō)明這一原因,所以?xún)H在這里拋磚引玉一下。
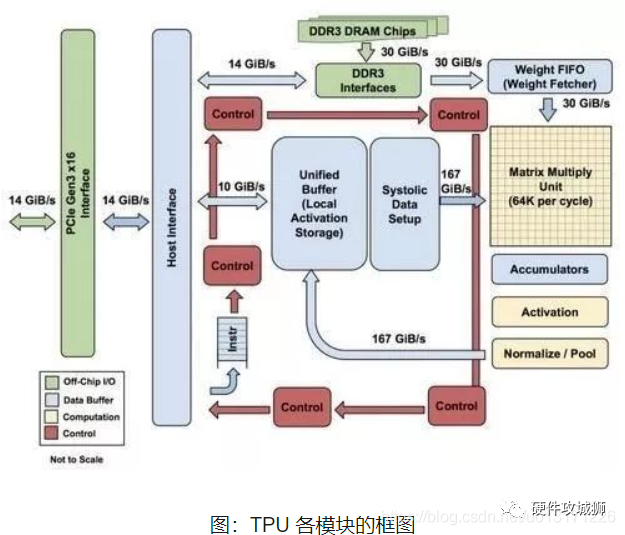
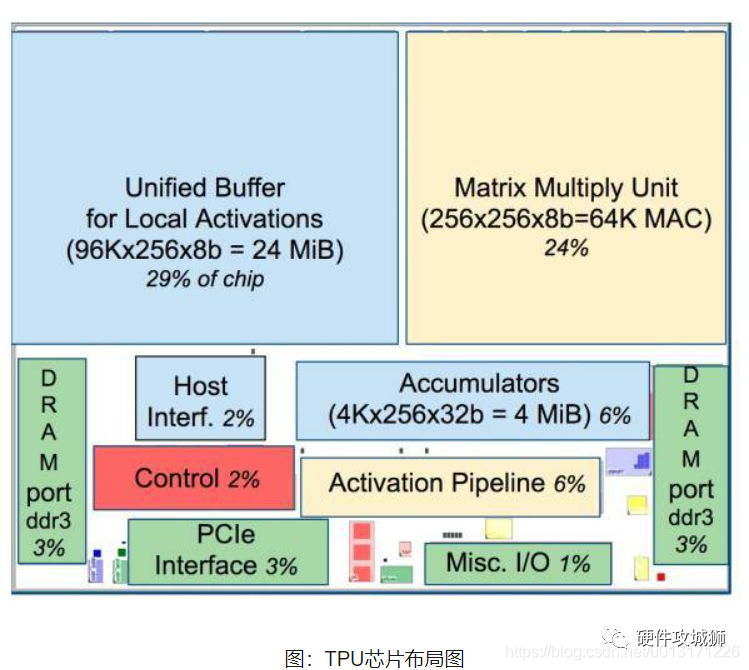
如上圖所示,TPU在芯片上使用了高達(dá)24MB的局部?jī)?nèi)存,6MB的累加器內(nèi)存以及用于與主控處理器進(jìn)行對(duì)接的內(nèi)存,總共占芯片面積的37%(圖中藍(lán)色部分)。
這表示谷歌充分意識(shí)到了片外內(nèi)存訪(fǎng)問(wèn)是GPU能效比低的罪魁禍?zhǔn)祝虼瞬幌С杀镜脑谛酒戏帕司薮蟮膬?nèi)存。相比之下,英偉達(dá)同時(shí)期的K80只有8MB的片上內(nèi)存,因此需要不斷地去訪(fǎng)問(wèn)片外DRAM。
另外,TPU的高性能還來(lái)源于對(duì)于低運(yùn)算精度的容忍。研究結(jié)果表明,低精度運(yùn)算帶來(lái)的算法準(zhǔn)確率損失很小,但是在硬件實(shí)現(xiàn)上卻可以帶來(lái)巨大的便利,包括功耗更低、速度更快、占芯片面積更小的運(yùn)算單元、更小的內(nèi)存帶寬需求等...TPU采用了8比特的低精度運(yùn)算。
到目前為止,TPU其實(shí)已經(jīng)干了很多事情了,例如機(jī)器學(xué)習(xí)人工智能系統(tǒng)RankBrain,它是用來(lái)幫助Google處理搜索結(jié)果并為用戶(hù)提供更加相關(guān)搜索結(jié)果的;還有街景Street View,用來(lái)提高地圖與導(dǎo)航的準(zhǔn)確性的;當(dāng)然還有下圍棋的計(jì)算機(jī)程序AlphaGo!
04
NPU
講到這里,相信大家對(duì)這些所謂的“XPU”的套路已經(jīng)有了一定了解,我們接著來(lái)。
所謂NPU(Neural network Processing Unit), 即神經(jīng)網(wǎng)絡(luò)處理器。顧名思義,這家伙是想用電路模擬人類(lèi)的神經(jīng)元和突觸結(jié)構(gòu)啊!
怎么模仿?那就得先來(lái)看看人類(lèi)的神經(jīng)結(jié)構(gòu)——生物的神經(jīng)網(wǎng)絡(luò)由若干人工神經(jīng)元結(jié)點(diǎn)互聯(lián)而成,神經(jīng)元之間通過(guò)突觸兩兩連接,突觸記錄了神經(jīng)元之間的聯(lián)系。
如果想用電路模仿人類(lèi)的神經(jīng)元,就得把每個(gè)神經(jīng)元抽象為一個(gè)激勵(lì)函數(shù),該函數(shù)的輸入由與其相連的神經(jīng)元的輸出以及連接神經(jīng)元的突觸共同決定。
為了表達(dá)特定的知識(shí),使用者通常需要(通過(guò)某些特定的算法)調(diào)整人工神經(jīng)網(wǎng)絡(luò)中突觸的取值、網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)等。該過(guò)程稱(chēng)為“學(xué)習(xí)”。
在學(xué)習(xí)之后,人工神經(jīng)網(wǎng)絡(luò)可通過(guò)習(xí)得的知識(shí)來(lái)解決特定的問(wèn)題。
這時(shí)不知道大家有沒(méi)有發(fā)現(xiàn)問(wèn)題——原來(lái),由于深度學(xué)習(xí)的基本操作是神經(jīng)元和突觸的處理,而傳統(tǒng)的處理器指令集(包括x86和ARM等)是為了進(jìn)行通用計(jì)算發(fā)展起來(lái)的,其基本操作為算術(shù)操作(加減乘除)和邏輯操作(與或非),往往需要數(shù)百甚至上千條指令才能完成一個(gè)神經(jīng)元的處理,深度學(xué)習(xí)的處理效率不高。
這時(shí)就必須另辟蹊徑——突破經(jīng)典的馮·諾伊曼結(jié)構(gòu)!
神經(jīng)網(wǎng)絡(luò)中存儲(chǔ)和處理是一體化的,都是通過(guò)突觸權(quán)重來(lái)體現(xiàn)。而馮·諾伊曼結(jié)構(gòu)中,存儲(chǔ)和處理是分離的,分別由存儲(chǔ)器和運(yùn)算器來(lái)實(shí)現(xiàn),二者之間存在巨大的差異。當(dāng)用現(xiàn)有的基于馮·諾伊曼結(jié)構(gòu)的經(jīng)典計(jì)算機(jī)(如X86處理器和英偉達(dá)GPU)來(lái)跑神經(jīng)網(wǎng)絡(luò)應(yīng)用時(shí),就不可避免地受到存儲(chǔ)和處理分離式結(jié)構(gòu)的制約,因而影響效率。這也就是專(zhuān)門(mén)針對(duì)人工智能的專(zhuān)業(yè)芯片能夠?qū)鹘y(tǒng)芯片有一定先天優(yōu)勢(shì)的原因之一。
05
ASIC
ASIC(Application Specific Integrated Circuit)是一種為專(zhuān)門(mén)目的而設(shè)計(jì)的集成電路。無(wú)法重新編程,效能高功耗低,但價(jià)格昂貴。近年來(lái)涌現(xiàn)出的類(lèi)似TPU、NPU、VPU、BPU等令人眼花繚亂的各種芯片,本質(zhì)上都屬于ASIC。ASIC不同于 GPU 和 FPGA 的靈活性,定制化的 ASIC 一旦制造完成將不能更改,所以初期成本高、開(kāi)發(fā)周期長(zhǎng)的使得進(jìn)入門(mén)檻高。目前,大多是具備 AI 算法又擅長(zhǎng)芯片研發(fā)的巨頭參與,如 Google 的 TPU。由于完美適用于神經(jīng)網(wǎng)絡(luò)相關(guān)算法,ASIC 在性能和功耗上都要優(yōu)于 GPU 和 FPGA,TPU1 是傳統(tǒng) GPU 性能的 14-16 倍,NPU 是 GPU 的 118 倍。寒武紀(jì)已發(fā)布對(duì)外應(yīng)用指令集,預(yù)計(jì) ASIC 將是未來(lái) AI 芯片的核心。
06
BPU
(Brain Processing Unit,大腦處理器)
是由地平線(xiàn)科技提出的嵌入式人工智能處理器架構(gòu)。第一代是高斯架構(gòu),第二代是伯努利架構(gòu),第三代是貝葉斯架構(gòu)。目前地平線(xiàn)已經(jīng)設(shè)計(jì)出了第一代高斯架構(gòu),并與英特爾在2017年CES展會(huì)上聯(lián)合推出了ADAS系統(tǒng)(高級(jí)駕駛輔助系統(tǒng))。
07
DPU
(Deep learning Processing Unit, 即深度學(xué)習(xí)處理器)
最早由國(guó)內(nèi)深鑒科技提出,基于Xilinx可重構(gòu)特性的FPGA芯片,設(shè)計(jì)專(zhuān)用的深度學(xué)習(xí)處理單元(可基于已有的邏輯單元,設(shè)計(jì)并行高效的乘法器及邏輯電路,屬于IP范疇),且抽象出定制化的指令集和編譯器(而非使用OpenCL),從而實(shí)現(xiàn)快速的開(kāi)發(fā)與產(chǎn)品迭代。事實(shí)上,深鑒提出的DPU屬于半定制化的FPGA。
嵌入式神經(jīng)網(wǎng)絡(luò)處理器(NPU)采用“數(shù)據(jù)驅(qū)動(dòng)并行計(jì)算”的架構(gòu),特別擅長(zhǎng)處理視頻、圖像類(lèi)的海量多媒體數(shù)據(jù)。
NPU處理器專(zhuān)門(mén)為物聯(lián)網(wǎng)人工智能而設(shè)計(jì),用于加速神經(jīng)網(wǎng)絡(luò)的運(yùn)算,解決傳統(tǒng)芯片在神經(jīng)網(wǎng)絡(luò)運(yùn)算時(shí)效率低下的問(wèn)題。
在GX8010中,CPU和MCU各有一個(gè)NPU,MCU中的NPU相對(duì)較小,習(xí)慣上稱(chēng)為SNPU。
NPU處理器包括了乘加、激活函數(shù)、二維數(shù)據(jù)運(yùn)算、解壓縮等模塊。
乘加模塊用于計(jì)算矩陣乘加、卷積、點(diǎn)乘等功能,NPU內(nèi)部有64個(gè)MAC,SNPU有32個(gè)。
激活函數(shù)模塊采用最高12階參數(shù)擬合的方式實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)中的激活函數(shù),NPU內(nèi)部有6個(gè)MAC,SNPU有3個(gè)。
二維數(shù)據(jù)運(yùn)算模塊用于實(shí)現(xiàn)對(duì)一個(gè)平面的運(yùn)算,如降采樣、平面數(shù)據(jù)拷貝等,NPU內(nèi)部有1個(gè)MAC,SNPU有1個(gè)。
解壓縮模塊用于對(duì)權(quán)重?cái)?shù)據(jù)的解壓。為了解決物聯(lián)網(wǎng)設(shè)備中內(nèi)存帶寬小的特點(diǎn),在NPU編譯器中會(huì)對(duì)神經(jīng)網(wǎng)絡(luò)中的權(quán)重進(jìn)行壓縮,在幾乎不影響精度的情況下,可以實(shí)現(xiàn)6-10倍的壓縮效果。
不,據(jù)說(shuō)每過(guò)18天,集成電路領(lǐng)域就會(huì)多出一個(gè)XPU,直到26個(gè)字母被用完。
這被戲稱(chēng)為AI時(shí)代的XPU版摩爾定律。
據(jù)不完全統(tǒng)計(jì),已經(jīng)被用掉的有:
▍APU
Accelerated Processing Unit。目前還沒(méi)有 AI 公司將自己的處理器命名為 APU,因?yàn)?AMD 早就用過(guò) APU 這個(gè)名字了。APU 是 AMD 的一個(gè)處理器品牌。AMD 在一顆芯片上集成傳統(tǒng) CPU 和圖形處理器 GPU,這樣主板上將不再需要北橋,任務(wù)可以靈活地在 CPU 和 GPU 間分配。AMD 將這種異構(gòu)結(jié)構(gòu)稱(chēng)為加速處理單元,即 APU。
Audio Processing Unit。聲音處理器,顧名思義,處理聲音數(shù)據(jù)的專(zhuān)用處理器。不多說(shuō),生產(chǎn) APU 的芯片商有好多家。聲卡里都有。
▍BPU
Brain Processing Unit。地平線(xiàn)機(jī)器人(Horizon Robotics)以 BPU 來(lái)命名自家的 AI 芯片。相比于國(guó)內(nèi)外其他 AI 芯片 start-up 公司,地平線(xiàn)的第一代 BPU 走的相對(duì)保守的 TSMC 的 40nm 工藝。BPU 已經(jīng)被地平線(xiàn)申請(qǐng)了注冊(cè)商標(biāo),其他公司就別打 BPU 的主意了。
▍CPU
上文也進(jìn)行了詳細(xì)的介紹。也不會(huì)有 AI 公司將自己的處理器命名為 CPU 的。不過(guò),CPU 與 AI 處理器并不沖突。
▍DPU
Deep-Learning Processing Unit。深度學(xué)習(xí)處理器。創(chuàng)立于 2010 年的 wave computing 公司將其開(kāi)發(fā)的深度學(xué)習(xí)加速處理器稱(chēng)為 Dataflow Processing Unit(DPU),應(yīng)用于數(shù)據(jù)中心。
▍EPU
Emotion Processing Unit伴隨機(jī)情緒機(jī)器人而生,可以讓機(jī)器人具有情緒。從官方渠道消息看,EPU 本身并不復(fù)雜,也不需要做任務(wù)量巨大的神經(jīng)網(wǎng)絡(luò)計(jì)算,是基于 MCU 的芯片。
▍FPU
Floating Point Unit。浮點(diǎn)單元,不多做解釋了。現(xiàn)在高性能的 CPU、DSP、GPU 內(nèi)都集成了 FPU 做浮點(diǎn)運(yùn)算。
▍GPU
Graphics Processing Unit。圖形處理器。GPU 原來(lái)最大的需求來(lái)自 PC 市場(chǎng)上各類(lèi)游戲?qū)D形處理的需求。但是隨著移動(dòng)設(shè)備的升級(jí),在移動(dòng)端也逐漸發(fā)展起來(lái)。
▍HPU
Holographic Processing Unit。全息處理器。Microsoft 專(zhuān)為自家 Hololens 應(yīng)用開(kāi)發(fā)的。
▍IPU
Intelligence Processing Unit。智能處理器。以 IPU 命名芯片的有兩家公司——Graphcore和Mythic。
Image Cognition Processor。圖像認(rèn)知處理器 ICP,加拿大公司 CogniVue 開(kāi)發(fā)的用于視覺(jué)處理和圖像認(rèn)知的 IP。
Image Processing Unit。圖像處理器。一些 SOC 芯片中將處理靜態(tài)圖像的模塊稱(chēng)為 IPU。但是,IPU 不是一個(gè)常用的縮寫(xiě),更常見(jiàn)的處理圖像信號(hào)的處理器的縮寫(xiě)為下面的 ISP。
Image Signal Processor。圖像信號(hào)處理器。這個(gè)話(huà)題也不是一個(gè)小話(huà)題。ISP 的功能,簡(jiǎn)單的來(lái)說(shuō)就是處理 camera 等攝像設(shè)備的輸出信號(hào),實(shí)現(xiàn)降噪、Demosaicing、HDR、色彩管理等功能。
▍KPU
Knowledge Processing Unit。嘉楠耘智(canaan)號(hào)稱(chēng) 2017 年將發(fā)布自己的 AI 芯片 KPU。嘉楠耘智要在 KPU 單一芯片中集成人工神經(jīng)網(wǎng)絡(luò)和高性能處理器,主要提供異構(gòu)、實(shí)時(shí)、離線(xiàn)的人工智能應(yīng)用服務(wù)。這又是一家向 AI 領(lǐng)域擴(kuò)張的不差錢(qián)的礦機(jī)公司。作為一家做礦機(jī)芯片(自稱(chēng)是區(qū)塊鏈專(zhuān)用芯片)和礦機(jī)的公司,嘉楠耘智累計(jì)獲得近 3 億元融資,估值近 33 億人民幣。據(jù)說(shuō)嘉楠耘智近期將啟動(dòng)股改并推進(jìn) IPO。
另:Knowledge Processing Unit 這個(gè)詞并不是嘉楠耘智第一個(gè)提出來(lái)的,早在 10 年前就已經(jīng)有論文和書(shū)籍講到這個(gè)詞匯了。只是,現(xiàn)在嘉楠耘智將 KPU 申請(qǐng)了注冊(cè)商標(biāo)。
▍MPU
Micro Processing Unit。微處理器。MPU,CPU,MCU,這三個(gè)概念差不多,知道就行了。
Mind Processing Unit。意念處理器,聽(tīng)起來(lái)不錯(cuò)。「解讀腦電波」,「意念交流」,永恒的科幻話(huà)題。如果采集大量人類(lèi)「思考」的腦電波數(shù)據(jù),通過(guò)深度學(xué)習(xí),再加上強(qiáng)大的意念處理器 MPU,不知道能否成為 mind-reader。如果道德倫理上無(wú)法接受,先了解一下家里寵物貓寵物狗的「想法」也是可以的嗎。再進(jìn)一步,從 mind-reader 發(fā)展為 mind-writer,持續(xù)升級(jí)之后,是不是就可以成為冰與火中的 Skinchanger?
▍NPU
Neural-Network Processing Unit。與 GPU 類(lèi)似,神經(jīng)網(wǎng)絡(luò)處理器 NPU 已經(jīng)成為了一個(gè)通用名詞,而非某家公司的專(zhuān)用縮寫(xiě)。由于神經(jīng)網(wǎng)絡(luò)計(jì)算的類(lèi)型和計(jì)算量與傳統(tǒng)計(jì)算的區(qū)別,導(dǎo)致在進(jìn)行 NN 計(jì)算的時(shí)候,傳統(tǒng) CPU、DSP 甚至 GPU 都有算力、性能、能效等方面的不足,所以激發(fā)了專(zhuān)為 NN 計(jì)算而設(shè)計(jì) NPU 的需求。這里羅列幾個(gè)以 NPU 名義發(fā)布過(guò)產(chǎn)品的公司,以及幾個(gè)學(xué)術(shù)圈的神經(jīng)網(wǎng)絡(luò)加速器。
▍OPU
Optical-Flow Processing Unit。光流處理器。有需要用專(zhuān)門(mén)的芯片來(lái)實(shí)現(xiàn)光流算法嗎?不知道,但是,用 ASIC IP 來(lái)做加速應(yīng)該是要的。
▍PPU
Physical Processing Unit。物理處理器。要先解釋一下物理運(yùn)算,就知道物理處理器是做什么的了。物理計(jì)算,就是模擬一個(gè)物體在真實(shí)世界中應(yīng)該符合的物理定律。具體的說(shuō),可以使虛擬世界中的物體運(yùn)動(dòng)符合真實(shí)世界的物理定律,可以使游戲中的物體行為更加真實(shí),例如布料模擬、毛發(fā)模擬、碰撞偵測(cè)、流體力學(xué)模擬等。開(kāi)發(fā)物理計(jì)算引擎的公司有那么幾家,使用 CPU 來(lái)完成物理計(jì)算,支持多種平臺(tái)。但是,Ageia 應(yīng)該是唯一一個(gè)使用專(zhuān)用芯片來(lái)加速物理計(jì)算的公司。Ageia 于 2006 年發(fā)布了 PPU 芯片 PhysX,還發(fā)布了基于 PPU 的物理加速卡,同時(shí)提供 SDK 給游戲開(kāi)發(fā)者。2008 年被 NVIDIA 收購(gòu)后,PhysX 加速卡產(chǎn)品被逐漸取消,現(xiàn)在物理計(jì)算的加速功能由 NVIDIA 的 GPU 實(shí)現(xiàn),PhysX SDK 被 NVIDIA 重新打造。
▍QPU
Quantum Processing Unit。量子處理器。量子計(jì)算機(jī)也是近幾年比較火的研究方向。作者承認(rèn)在這方面所知甚少。可以關(guān)注這家成立于 1999 年的公司 D-Wave System。DWave 大概每?jī)赡昕梢詫⑵?QPU 上的量子位個(gè)數(shù)翻倍一次。
▍RPU
Resistive Processing Unit。阻抗處理單元 RPU。這是 IBM Watson Research Center 的研究人員提出的概念,真的是個(gè)處理單元,而不是處理器。RPU 可以同時(shí)實(shí)現(xiàn)存儲(chǔ)和計(jì)算。利用 RPU 陣列,IBM 研究人員可以實(shí)現(xiàn) 80TOPS/s/W 的性能。
Ray-tracing Processing Unit。光線(xiàn)追蹤處理器。Ray tracing 是計(jì)算機(jī)圖形學(xué)中的一種渲染算法,RPU 是為加速其中的數(shù)據(jù)計(jì)算而開(kāi)發(fā)的加速器。現(xiàn)在這些計(jì)算都是 GPU 的事情了。
▍SPU
Streaming Processing Unit。流處理器。流處理器的概念比較早了,是用于處理視頻數(shù)據(jù)流的單元,一開(kāi)始出現(xiàn)在顯卡芯片的結(jié)構(gòu)里。可以說(shuō),GPU 就是一種流處理器。甚至,還曾經(jīng)存在過(guò)一家名字為「Streaming Processor Inc」的公司,2004 年創(chuàng)立,2009 年,隨著創(chuàng)始人兼董事長(zhǎng)被挖去 NVIDIA 當(dāng)首席科學(xué)家,SPI 關(guān)閉。
Speech-Recognition Processing Unit。語(yǔ)音識(shí)別處理器,SPU 或 SRPU。這個(gè)縮寫(xiě)還沒(méi)有公司拿來(lái)使用。現(xiàn)在的語(yǔ)音識(shí)別和語(yǔ)義理解主要是在云端實(shí)現(xiàn)的,比如科大訊飛。科大訊飛最近推出了一個(gè)翻譯機(jī),可以將語(yǔ)音傳回云端,做實(shí)時(shí)翻譯,內(nèi)部硬件沒(méi)有去專(zhuān)門(mén)了解。和語(yǔ)音識(shí)別相關(guān)的芯片如下。
Space Processing Unit。空間處理器。全景攝像,全息成像,這些還都是處理我們的生活空間。當(dāng)面對(duì)廣闊的太陽(yáng)系、銀河系這些宇宙空間,是不是需要新的更強(qiáng)大的專(zhuān)用處理器呢?飛向 M31 仙女座星系,對(duì)抗黑暗武士,只靠 x86 估計(jì)是不行的。
▍TPU
Tensor Processing Unit。Google 的張量處理器。2016 年 AlphaGo 打敗李世石,2017 年 AlphaGo 打敗柯潔,兩次人工智能催化事件給芯片行業(yè)帶來(lái)的沖擊無(wú)疑就是 TPU 的出現(xiàn)和解密。Google 在 2017 年 5 月的開(kāi)發(fā)者 I/O 大會(huì)上正式公布了 TPU2,又稱(chēng) Cloud TPU。
▍UPU
Universe Processing Unit。宇宙處理器。和 Space Processing Unit 相比,你更喜歡哪個(gè)?
▍VPU
Vision Processing Unit。視覺(jué)處理器 VPU 也有希望成為通用名詞。作為現(xiàn)今最火熱的 AI 應(yīng)用領(lǐng)域,計(jì)算機(jī)視覺(jué)的發(fā)展的確能給用戶(hù)帶來(lái)前所未有的體驗(yàn)。為了處理計(jì)算機(jī)視覺(jué)應(yīng)用中遇到的超大計(jì)算量,多家公司正在為此設(shè)計(jì)專(zhuān)門(mén)的 VPU。
Visual Processing Unit。
Video Processing Unit。視頻處理器。處理動(dòng)態(tài)視頻而不是圖像,例如進(jìn)行實(shí)時(shí)編解碼。
Vector Processing Unit。向量處理器。標(biāo)量處理器、向量處理器、張量處理器,這是以處理器處理的數(shù)據(jù)類(lèi)型進(jìn)行的劃分。
▍WPU
Wearable Processing Unit。一家印度公司 Ineda Systems 在 2014 年大肆宣傳了一下他們針對(duì) IOT 市場(chǎng)推出的 WPU 概念,獲得了高通和三星的注資。Ineda Systems 研發(fā)的這款「Dhanush WPU」分為四個(gè)級(jí)別,可適應(yīng)普通級(jí)別到高端級(jí)別的可穿戴設(shè)備的運(yùn)算需求,可以讓可穿戴設(shè)備的電池達(dá)到 30 天的持續(xù)續(xù)航、減少 10x 倍的能耗。但是,一切似乎在 2015 年戛然而止,沒(méi)有了任何消息。只在主頁(yè)的最下端有文字顯示,Ineda 將 WPU 申請(qǐng)了注冊(cè)商標(biāo)。
Wisdom Processing Unit。智慧處理器。
▍ZPU
Zylin CPU。挪威公司 Zylin 的 CPU 的名字。為了在資源有限的 FPGA 上能擁有一個(gè)靈活的微處理器,Zylin 開(kāi)發(fā)了 ZPU。ZPU 是一種 stack machine(堆棧結(jié)構(gòu)機(jī)器),指令沒(méi)有操作數(shù),代碼量很小,并有 GCC 工具鏈支持,被稱(chēng)為「The worlds smallest 32 bit CPU with GCC toolchain」。Zylin 在 2008 年將 ZPU 在 opencores 上開(kāi)源。有組織還將 Arduino 的開(kāi)發(fā)環(huán)境進(jìn)行了修改給 ZPU 用。
▍其他非 xPU 的 AI 芯片
寒武紀(jì)科技(Cambricon)中科院背景的寒武紀(jì)并沒(méi)有用 xPU 的方式命名自家的處理器。媒體的文章既有稱(chēng)之為深度學(xué)習(xí)處理器 DPU 的,也有稱(chēng)之為神經(jīng)網(wǎng)絡(luò)處理器 NPU 的。陳氏兄弟的 DianNao 系列芯片架構(gòu)連續(xù)幾年在各大頂級(jí)會(huì)議上刷了好幾篇 best paper,為其公司的成立奠定了技術(shù)基礎(chǔ)。寒武紀(jì) Cambricon-X 指令集是其一大特色。目前其芯片 IP 已擴(kuò)大范圍授權(quán)集成到手機(jī)、安防、可穿戴設(shè)備等終端芯片中。據(jù)流傳,2016 年就已拿到一億元訂單。在一些特殊領(lǐng)域,寒武紀(jì)的芯片將在國(guó)內(nèi)具有絕對(duì)的占有率。最新報(bào)道顯示,寒武紀(jì)又融了 1 億美元。
Intel Intel 在智能手機(jī)芯片市場(chǎng)的失利,讓其痛定思痛,一改當(dāng)年的猶豫,在 AI 領(lǐng)域的幾個(gè)應(yīng)用方向上接連發(fā)了狠招。什么狠招呢,就是三個(gè)字:買(mǎi),買(mǎi),買(mǎi)。在數(shù)據(jù)中心/云計(jì)算方面,167 億美金收購(gòu)的 Altera,4 億美金收購(gòu) Nervana;在移動(dòng)端的無(wú)人機(jī)、安防監(jiān)控等方面,收購(gòu) Movidius(未公布收購(gòu)金額);在 ADAS 方面,153 億美金收購(gòu) Mobileye。Movidius 在前面 VPU 部分進(jìn)行了介紹,這里補(bǔ)充一下 Nervana 和 Mobileye(基于視覺(jué)技術(shù)做 ADAS 方案,不是單純的視覺(jué)處理器,所以沒(méi)寫(xiě)在 VPU 部分)。
Nervana Nervana 成立于 2014 年,總部在 SanDiego,以提供 AI 全棧軟件平臺(tái) Nervana Cloud 為主要業(yè)務(wù)。和硬件扯上關(guān)系的是,Nervana Cloud 除了支持 CPU、GPU 甚至 Xeon Phi 等后臺(tái)硬件外,還提供有自家定制的 Nervana Engine 硬件架構(gòu)。根據(jù) The Next Platform 的報(bào)道「Deep Learning Chip Upstart Takes GPUs to Task」,Nervana Engine 使用 TSMC 28nm 工藝,算力 55 TOPS。報(bào)道發(fā)布不到 24 小時(shí),就被 Intel 收購(gòu)了,全部 48 位員工并入 Intel。Intel 以 Nervana Engine 為核心打造了 Crest Family 系列芯片。項(xiàng)目代碼為「Lake Crest」的芯片是第一代 Nervana Engine,「Knights Crest」為第二代。哦,對(duì)了,Nervana 的 CEO 在創(chuàng)立 Nervana 之前,在高通負(fù)責(zé)一個(gè)神經(jīng)形態(tài)計(jì)算的研究項(xiàng)目,就是上面提到的 Zeroth。
Mobileye 一家基于計(jì)算機(jī)視覺(jué)做 ADAS 的以色列公司,成立于 1999 年,總部在耶路撒冷。Mobileye 為自家的 ADAS 系統(tǒng)開(kāi)發(fā)了專(zhuān)用的芯片——EyeQ 系列。2015 年,Tesla 宣布正在使用 Mobileye 的芯片(EyeQ3)和方案。但是,2016 年 7 月,Tesla 和 Mobileye 宣布將終止合作。隨后,Mobile 于 2017 年被 Intel 以$153 億收入囊中,現(xiàn)在是 Intel 的子公司。Mobileye 的 EyeQ4 使用了 28nm SOI 工藝,其中用了 4 個(gè) MIPS 的大 CPU core 做主控和算法調(diào)度以及一個(gè) MIPS 的小 CPU core 做外設(shè)控制,集成了 10 個(gè)向量處理器(稱(chēng)為 VMP,Vector Microcode Processor)來(lái)做數(shù)據(jù)運(yùn)算(有點(diǎn)眼熟,回去看看 Movidius 部分)。Mobileye 的下一代 EyeQ5 將使用 7nm FinFET 工藝,集成 18 個(gè)視覺(jué)處理器,并且為了達(dá)到自動(dòng)駕駛的 level 5 增加了硬件安全模塊。
比特大陸 Bitmain 比特大陸設(shè)計(jì)的全定制礦機(jī)芯片性能優(yōu)越,讓其大賺特賺。在賣(mài)礦機(jī)芯片之余,比特大陸自己也挖挖礦。總之,芯片設(shè)計(jì)能力非凡、土豪有錢(qián)的比特大陸對(duì)標(biāo) NVIDIA 的高端 GPU 芯片,任性地用 16nm 的工藝開(kāi)啟了自家的 AI 芯片之路。芯片測(cè)試已有月余,據(jù)傳功耗 60W 左右,同步在招攬產(chǎn)品、市場(chǎng)人員。最近的推文爆出了這款 AI 芯片的名字:「智子(Sophon)」,來(lái)自著名的《三體》,可見(jiàn)野心不小,相信不就即將正式發(fā)布。
華為&海思市場(chǎng)期待華為的麒麟 970 已經(jīng)很長(zhǎng)時(shí)間了,內(nèi)置 AI 加速器已成公開(kāi)的秘密,據(jù)傳用了寒武紀(jì)的 IP,就等秋季發(fā)布會(huì)了。還是據(jù)傳,海思的 HI3559 中用了自己研發(fā)的深度學(xué)習(xí)加速器。
蘋(píng)果蘋(píng)果正在研發(fā)一款 AI 芯片,內(nèi)部稱(chēng)為「蘋(píng)果神經(jīng)引擎」(Apple Neural Engine)。這個(gè)消息大家并不驚訝,大家想知道的就是,這個(gè) ANE 會(huì)在哪款 iphone 中用上。
高通高通除了維護(hù)其基于 Zeroth 的軟件平臺(tái),在硬件上也動(dòng)作不斷。收購(gòu) NXP 的同時(shí),據(jù)傳高通也一直在和 Yann LeCun 以及 Facebook 的 AI 團(tuán)隊(duì)保持合作,共同開(kāi)發(fā)用于實(shí)時(shí)推理的新型芯片。
還有一些諸如 Leapmind、REM 這樣的 start-up,就不一一列舉。
-
cpu
+關(guān)注
關(guān)注
68文章
11038瀏覽量
216024 -
人工智能
+關(guān)注
關(guān)注
1804文章
48726瀏覽量
246565 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122489
原文標(biāo)題:什么是CPU、GPU、TPU、DPU、NPU、BPU?有什么區(qū)別?
文章出處:【微信號(hào):mcu168,微信公眾號(hào):硬件攻城獅】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一文理清CPU、GPU和TPU的關(guān)系
CPU,GPU,TPU,NPU都是什么
MCU、DSP、GPU、MPU、CPU、DPU、FPGA、ASIC、SOC、ECU、NPU、TPU、VPU、APU、BPU、ECU、FPU、EPU、這些主控異同點(diǎn)有哪些?
一文了解CPU、GPU和TPU的區(qū)別
CPU和GPU與TPU是如何工作的到底有什么區(qū)別
一文知道CPU和GPU的區(qū)別
GPU和CPU有什么區(qū)別GPU的詳細(xì)介紹
MPU、MCU、CPU、GPU、DSP、MMU、TPU、NPU大雜燴

什么是CPU、GPU、TPU、DPU、NPU、BPU?有什么區(qū)別?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論