 Java并發包之CAS介紹
Java并發包之CAS介紹
一、并發模擬
首先,用1000個客戶端進程來模擬并發,并使用信號量Semaphore 控制同時100個線程并發執行,采用同步器CountDownLatch 確保并發線程總數執行完成。模擬代碼如下:
// 請求總數
public static int clientTotal = 1000;
// 同時并發執行的線程數
public static int threadTotal = 100;
public static int count = 0;
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() - > {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("count:{}", count);
}
private static void add() {
count++;
}
- 同步器CountDownLatch
同步器CountDownLatch是計數器向下減的閉鎖;保證線程執行完再進行其他的處理。工作原理圖如下:
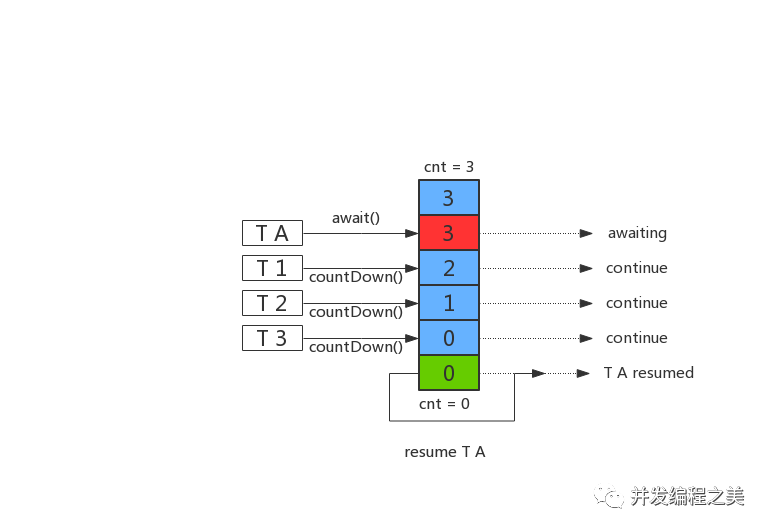
主線程調用await()方法后進入等待狀態,其他線程每次調用countDown()會使同步器計數減1,當同步器計數為0時,主線程繼續執行。
- 同步器Semaphore
同步器Semaphore的作用是阻塞線程,并且控制同一時間的請求的并發量。工作原理同CountDownLatch,不同的是Semaphore計數是向上計數,使用前需要指定一個目標數值。
上述并發模擬代碼我們多次執行,發現是線程不安全的,原因是i++不是原子性的。我們反編譯如下代碼:
public void inc() {
++i;
}
public void inc() {
Code:
0: aload_0
1: dup
2: getfield
5: lconst_1
6: ladd
7: putfield
10: return
}
由此可見,簡單的++i由2,5,6,7四步組成:
- 2是獲取當前i的值并放入棧頂
- 5是把常量1放入棧頂
- 6是把當前棧頂中兩個值相加并把結果放入棧頂
- 7是把棧頂的結果賦給i變量
因此,java中簡單的一句++i被轉換成匯編后就不具有原子性了。這里保證多個操作的原子性可以使用synchronized來實現i的內存可見性,但更好的方式是使用非阻塞的CAS算法實現的原子性操作類。下面我們使用cas把它改造成線程安全的。
二、CAS原理
1.cas保證原子性
并發模擬代碼修改:
public static AtomicLong count = new AtomicLong(0);
private static void add() {
count.incrementAndGet();
}
incrementAndGet源碼:
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
getAndAddLong源碼:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
// 用native標識的方法,代表的是java底層的方法,不是用java實現的
public native long getLongVolatile(Object var1, long var2);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
方法調用過程:
- var1指的是當前傳過來的count對象
- var2指的是當前的值
- var4指的是數字1
- var6指的是調用底層方法得到底層當前的值,如果沒有其他線程處理count變量的時候,正常返回var2的值
對于var1這個對象,如果當前的值var2跟底層的值var6相同的話,就把底層的值var6更新成var6 + var4。那么為什么會出現當前的值var2跟底層的值var6不相同的情況呢?答案是和java內存模型有關,關于java內存模型我們下次再詳細介紹。
2.cas底層原理
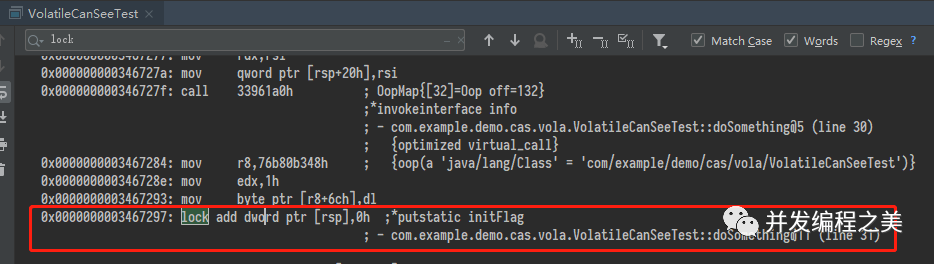
分析getAndAddLong源碼:CAS有四個操作數,分別為:對象內存位置,對象中的變量的偏移量,變量預期值和新值。其操作含義是,如果對象obj中內存偏移量為valueOffset的變量值為expect,則使用新的值update替換舊值expect。此操作具有 volatile 讀和寫的內存語義。
下面分別從編譯器和處理器的角度來分析,CAS 如何同時具有 volatile 讀和 volatile 寫的內存語義。
編譯器
編譯器不會對 volatile 讀與 volatile 讀后面的任意內存操作重排序;編譯器不會對 volatile 寫與 volatile 寫前面的任意內存操作重排序。組合這兩個條件,意味著為了同時實現 volatile 讀和 volatile 寫的內存語義,編譯器不能對 CAS 與 CAS 前面和后面的任意內存操作重排序。
處理器
下面是 sun.misc.Unsafe 類的 compareAndSwapLong() 方法的源代碼:
public final native boolean compareAndSwapLong(Object var1,
long var2,
long var4,
long var6);
下面是對應于 intel x86 處理器的源代碼的片段:
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \\
__asm je L0 \\
__asm _emit 0xF0 \\
__asm L0:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
可以看到調用了“Atomic::cmpxchg”方法:
mp是 os::is_MP() 的返回結果, os::is_MP() 是一個內聯函數,用來判斷當前系統是否為多處理器。如果當前系統是多處理器,該函數返回1。否則,返回0。 LOCK_IF_MP(mp) 會根據mp的值來決定是否 為cmpxchg指令添加lock前綴 。如果通過mp判斷當前系統是多處理器(即mp值為1),則為cmpxchg指令添加lock前綴。否則,不加lock前綴。(單處理器自身會維護單處理器內的順序一致性,不需要 lock 前綴提供的內存屏障效果)。
intel 的手冊對 lock 前綴的說明如下:
- 確保對內存的讀 - 改 - 寫操作原子執行。在 Pentium 及 Pentium 之前的處理器中,帶有 lock 前綴的指令在執行期間會鎖住總線,使得其他處理器暫時無法通過總線訪問內存。很顯然,這會帶來昂貴的開銷。從 Pentium 4,Intel Xeon 及 P6 處理器開始,intel 在原有總線鎖的基礎上做了一個很有意義的優化:如果要訪問的內存區域(area of memory)在 lock 前綴指令執行期間已經在處理器內部的緩存中被鎖定(即包含該內存區域的緩存行當前處于獨占或以修改狀態),并且該內存區域被完全包含在單個緩存行(cache line)中,那么處理器將直接執行該指令。由于在指令執行期間該緩存行會一直被鎖定,其它處理器無法讀 / 寫該指令要訪問的內存區域,因此能保證指令執行的原子性。這個操作過程叫做緩存鎖定(cache locking),緩存鎖定將大大降低 lock 前綴指令的執行開銷,但是當多處理器之間的競爭程度很高或者指令訪問的內存地址未對齊時,仍然會鎖住總線。
- 禁止該指令與之前和之后的讀和寫指令重排序。
- 把寫緩沖區中的所有數據刷新到內存中。
上面的第 2 點和第 3 點所具有的內存屏障效果足以同時實現 volatile 讀和volatile 寫的內存語義。
三、CAS存在的問題
1.ABA問題
ABA問題是指在CAS操作的時候,其他線程將變量的值A改成了B,又改回了A,當前線程使用期望值A與當前變量A進行比較的時候發現A變量值沒有變,于是CAS就將A值進行了交換操作。這個時候,其實該值已經被其他線程改變過,這與設計思想是不符合的。ABA問題的解決思路:每次變量更新的時候,把變量的版本號加1,那么之前的就變成了1A2B3A,從而解決了ABA問題。AtomicStampedReference的compareAndSet:
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair< V > current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
這個方法相對于之前的compareAndSet方法,多了一個stamp的比較,stamp的值由每次更新的時候來維護的。
2.循環時間長開銷大
自旋CAS如果長時間不成功,會給CPU帶來非常大的執行開銷。CAS的底層實現,是在一個死循環內不斷的嘗試修改目標值,直到修改成功。如果競爭不激烈的情況下,它修改成功的幾率很高,競爭激烈的情況下,修改失敗的幾率就很高,在大量修改失敗的時候,這些原子操作就會進行多次的循環嘗試,因此性能會受到影響。
基于這個原因,jdk1.8新增了一個原子類LongAdder用來解決這個問題。新增LongAdder與原始AtomicLong工作原理對比如下如所示:
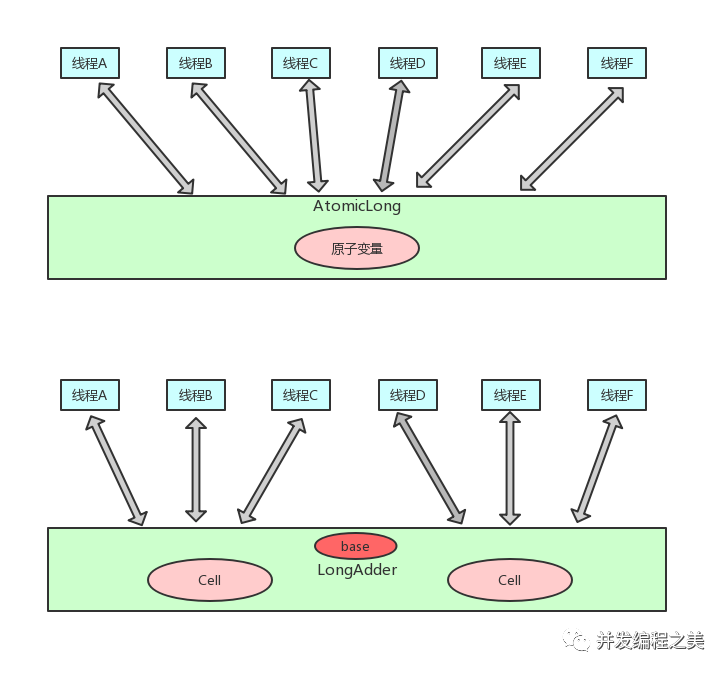
這里有個知識點:對于普通類型的long和double變量,JVM允許將64位的讀操作或寫操作,拆成兩個32位的操作。那么LongAdder的實現是基于什么思想呢?它的核心其實是將熱點數據分離,比如說,它可以將AtomicLong內部核心數據value分離成一個數組,每個線程訪問時,通過hash等算法,定位到其中一個數字進行計數,而最終的計數結果是這個數組的求和累加,其中熱點數據value會被分割成多個單元的cell,每個cell獨自維護內部的值,當前對象的實際值,由多有的cell累計合成,這樣的話熱點就進行了有效的分離,并提高了并行度。這樣一來呢,LongAdder相當于是在AtomicLong的基礎上,將單點的更新壓力,分散到各個節點上;在低并發的時候,通過對base的直接更新,可以很好的保證和AtomicLong性能基本一致,而在高并發的時候,則通過分散提高了性能。
LongAdder缺點:在統計的時候,如果有并發更新,可能會導致統計的數據有些誤差。所以如果是序列號生成等需要準確的數值,全局唯一的AtomicLong才是正確的選擇。
3.只能保證一個共享變量的原子操作
當對一個共享變量執行操作時,我們可以使用循環CAS的方式來保證原子操作,但是對多個共享變量操作時,循環CAS就無法保證操作的原子性,這個時候就可以用鎖,或者有一個取巧的辦法,就是把多個共享變量合并成一個共享變量來操作。比如有兩個共享變量i=2,j=a,合并一下ij=2a,然后用CAS來操作ij。從Java1.5開始JDK提供了**AtomicReference**類來保證引用對象之間的原子性,你可以把多個變量放在一個對象里來進行CAS操作。
四、CAS在鎖機制中的應用
1.樂觀鎖
樂觀鎖在Java中是通過使用無鎖編程來實現,最常采用的是CAS算法,Java原子類中的遞增操作就通過CAS自旋實現的:
public static AtomicLong atomicLong = new AtomicLong();
atomicLong.incrementAndGet();
2.自旋鎖&自適應自旋鎖
自旋鎖的實現原理同樣也是CAS,AtomicInteger中調用unsafe進行自增操作的源碼中的do-while循環就是一個自旋操作,如果修改數值失敗則通過循環來執行自旋,直至修改成功:
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
自適應意味著自旋的時間(次數)不再固定,而是由前一次在同一個鎖上的自旋時間及鎖的擁有者的狀態來決定。如果在同一個鎖對象上,自旋等待剛剛成功獲得過鎖,并且持有鎖的線程正在運行中,那么虛擬機就會認為這次自旋也是很有可能再次成功,進而它將允許自旋等待持續相對更長的時間。如果對于某個鎖,自旋很少成功獲得過,那在以后嘗試獲取這個鎖時將可能省略掉自旋過程,直接阻塞線程,避免浪費處理器資源。
3.無鎖
無鎖沒有對資源進行鎖定,所有的線程都能訪問并修改同一個資源,但同時只有一個線程能修改成功。無鎖的特點就是修改操作在循環內進行,線程會不斷的嘗試修改共享資源。如果沒有沖突就修改成功并退出,否則就會繼續循環嘗試。如果有多個線程修改同一個值,必定會有一個線程能修改成功,而其他修改失敗的線程會不斷重試直到修改成功。CAS原理及應用即是無鎖的實現
4.輕量級鎖
是指當鎖是偏向鎖的時候,被另外的線程所訪問,偏向鎖就會升級為輕量級鎖,其他線程會通過自旋的形式嘗試獲取鎖,不會阻塞,從而提高性能。
這里說明一下,輕量級鎖和偏向鎖都是JDK1.6對synchronized的優化,優化后存在四種鎖狀態。關于java中的鎖我們下次再詳細介紹,下面給出這四種鎖狀態:

5.ReentrantLock
ReentrantLock主要利用CAS+CLH隊列來實現,基本實現可以概括為:先通過CAS嘗試獲取鎖。如果此時已經有線程占據了鎖,那就加入CLH隊列并且被掛起。當鎖被釋放之后,排在CLH隊列隊首的線程會被喚醒,然后CAS再次嘗試獲取鎖。在這個時候,如果:
- 非公平鎖:如果同時還有另一個線程進來嘗試獲取,那么有可能會讓這個線程搶先獲取;
- 公平鎖:如果同時還有另一個線程進來嘗試獲取,當它發現自己不是在隊首的話,就會排到隊尾,由隊首的線程獲取到鎖。
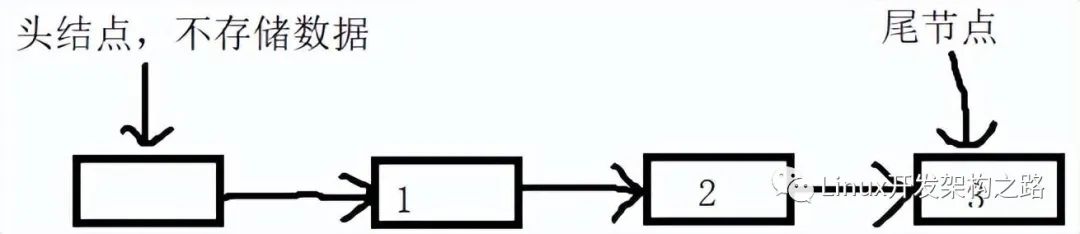
CLH隊列:帶頭結點的雙向非循環鏈表。結構圖如下:
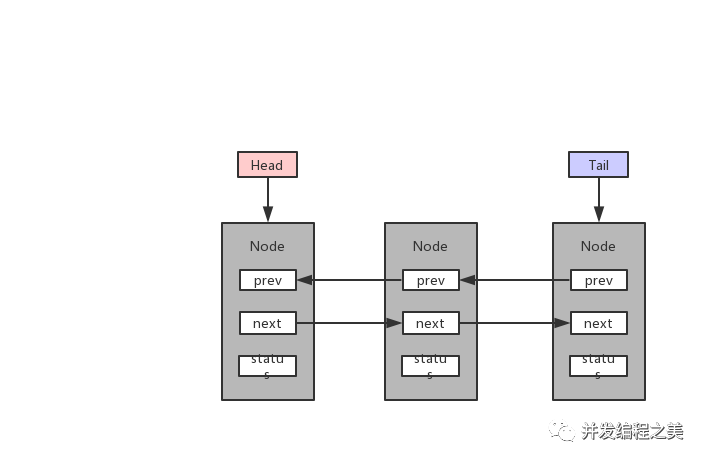
結語
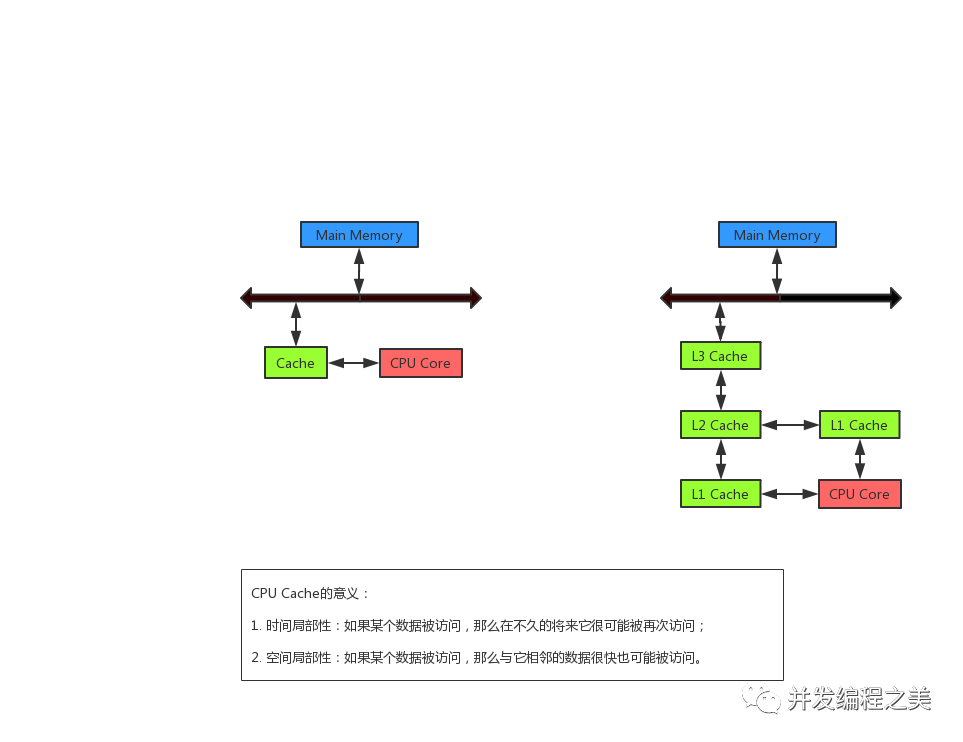
cas原理先介紹這些,關于java線程安全的三個特性:原子性、可見性、有序性以及cas中涉及到的java內存模型以及cpu多級緩存,后面會詳細說明。
-
JAVA
+關注
關注
20文章
2985瀏覽量
107011 -
計數器
+關注
關注
32文章
2286瀏覽量
96072 -
CAS
+關注
關注
0文章
35瀏覽量
15364 -
VaR
+關注
關注
0文章
39瀏覽量
11527 -
同步器
+關注
關注
1文章
106瀏覽量
15071
發布評論請先 登錄
詳細介紹了Java泛型、注解、并發編程

java之volatile并發
詳解java并發機制
java并發編程實戰之輔助類用法
Java程序設計之Java安全技術網絡編程的詳細資料說明

Kali Linux安裝Java 安裝顯卡驅動 安裝網卡補丁 并發線程限制 電源優化

介紹下volatile的底層原理
無鎖CAS如何實現各種無鎖的數據結構





 工商網監
工商網監
評論