 大模型參數高效微調技術原理綜述
大模型參數高效微調技術原理綜述
背景
神經網絡包含很多全連接層,其借助于矩陣乘法得以實現,然而,很多全連接層的權重矩陣都是滿秩的。當針對特定任務進行微調后,模型中權重矩陣其實具有很低的本征秩(intrinsic rank),因此,論文的作者認為權重更新的那部分參數矩陣盡管隨機投影到較小的子空間,仍然可以有效的學習,可以理解為針對特定的下游任務這些權重矩陣就不要求滿秩。
技術原理
LoRA(論文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),該方法的核心思想就是通過低秩分解來模擬參數的改變量,從而以極小的參數量來實現大模型的間接訓練。
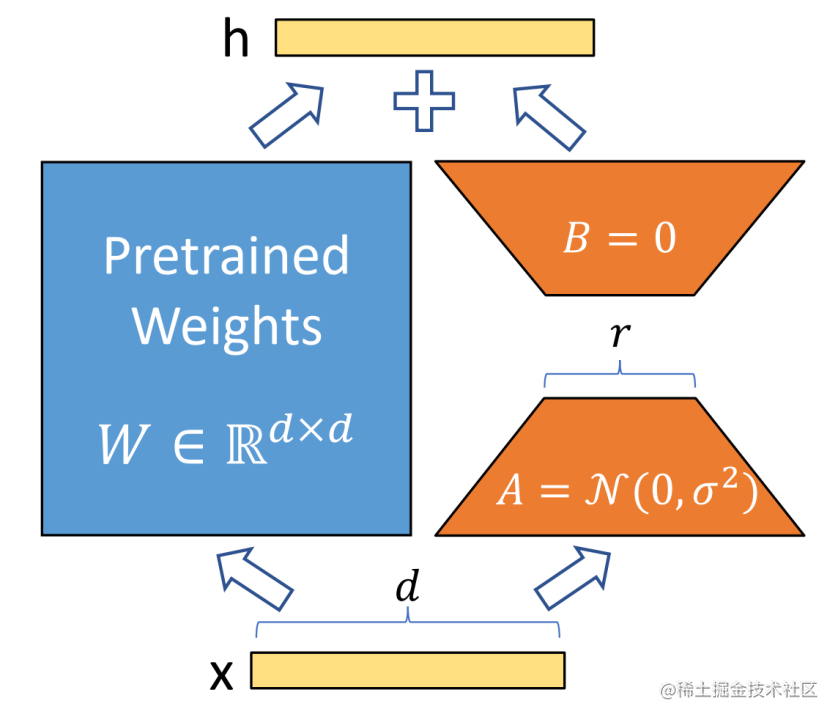
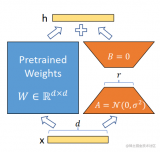
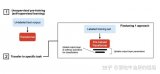
在涉及到矩陣相乘的模塊,在原始的PLM旁邊增加一個新的通路,通過前后兩個矩陣A,B相乘,第一個矩陣A負責降維,第二個矩陣B負責升維,中間層維度為r,從而來模擬所謂的本征秩(intrinsic rank)。
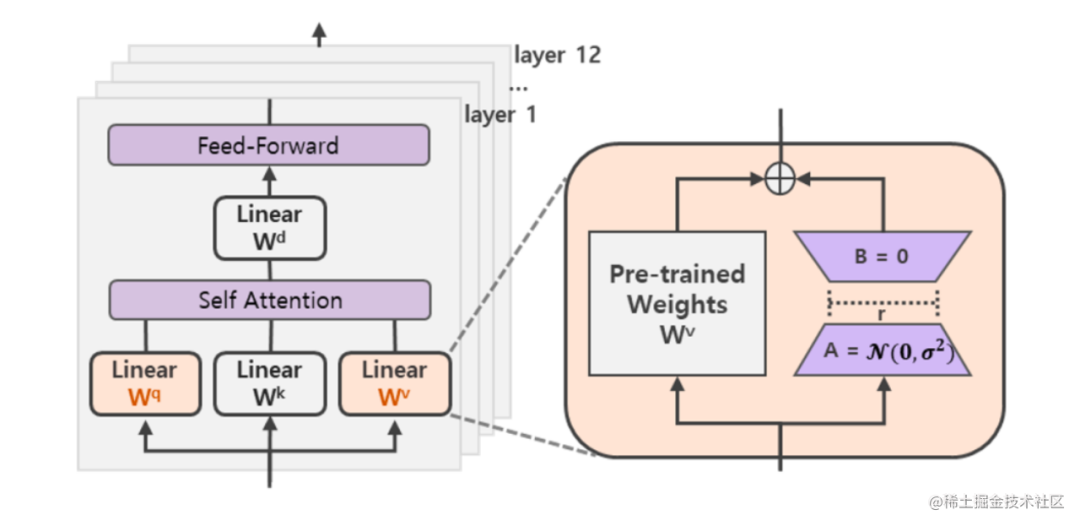
可訓練層維度和預訓練模型層維度一致為d,先將維度d通過全連接層降維至r,再從r通過全連接層映射回d維度,其中,r<
在下游任務訓練時,固定模型的其他參數,只優化新增的兩個矩陣的權重參數,將PLM跟新增的通路兩部分的結果加起來作為最終的結果(兩邊通路的輸入跟輸出維度是一致的),即h=Wx+BAx。第一個矩陣的A的權重參數會通過高斯函數初始化,而第二個矩陣的B的權重參數則會初始化為零矩陣,這樣能保證訓練開始時新增的通路BA=0從而對模型結果沒有影響。
在推理時,將左右兩部分的結果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要將訓練完成的矩陣乘積BA跟原本的權重矩陣W加到一起作為新權重參數替換原本PLM的W即可,對于推理來說,不會增加額外的計算資源。
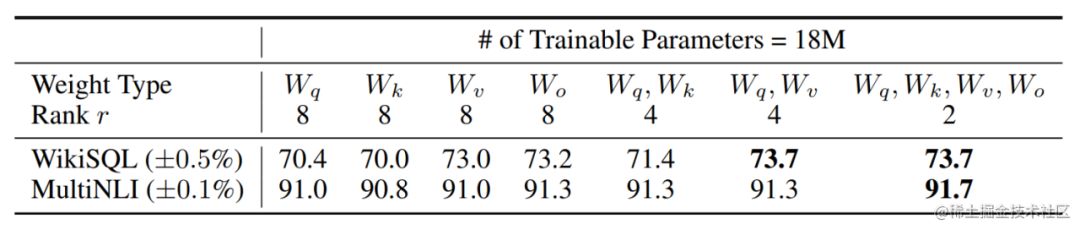
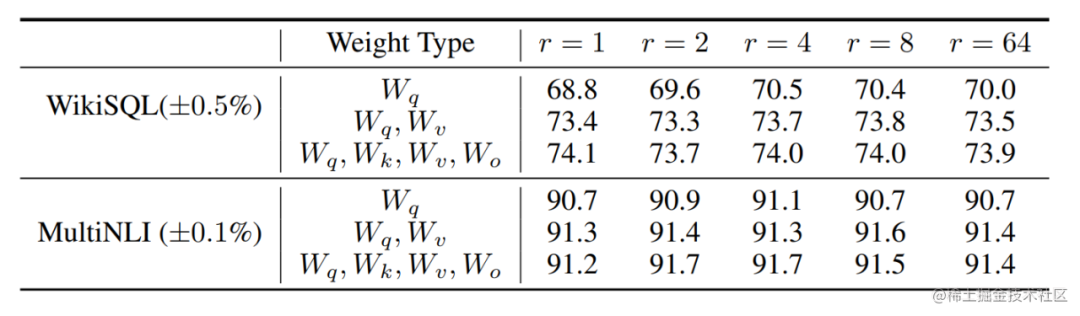
此外,Transformer的權重矩陣包括Attention模塊里用于計算query, key, value的Wq,Wk,Wv以及多頭attention的Wo,以及MLP層的權重矩陣,LoRA只應用于Attention模塊中的4種權重矩陣,而且通過消融實驗發現同時調整 Wq 和 Wv 會產生最佳結果。
實驗還發現,保證權重矩陣的種類的數量比起增加隱藏層維度r更為重要,增加r并不一定能覆蓋更加有意義的子空間。
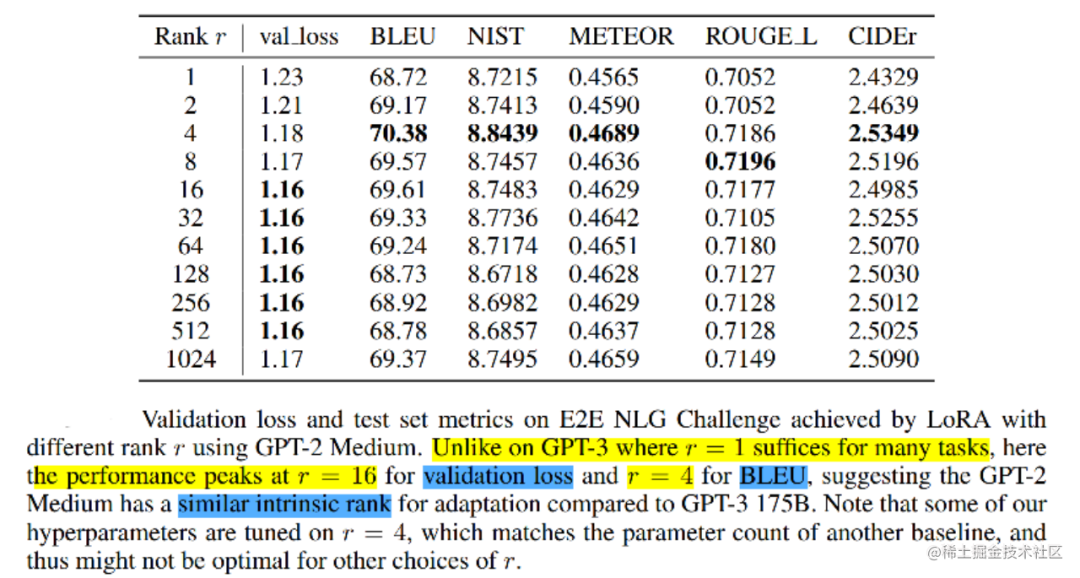
那么關于秩的選擇,通常情況下,rank為4,8,16即可。
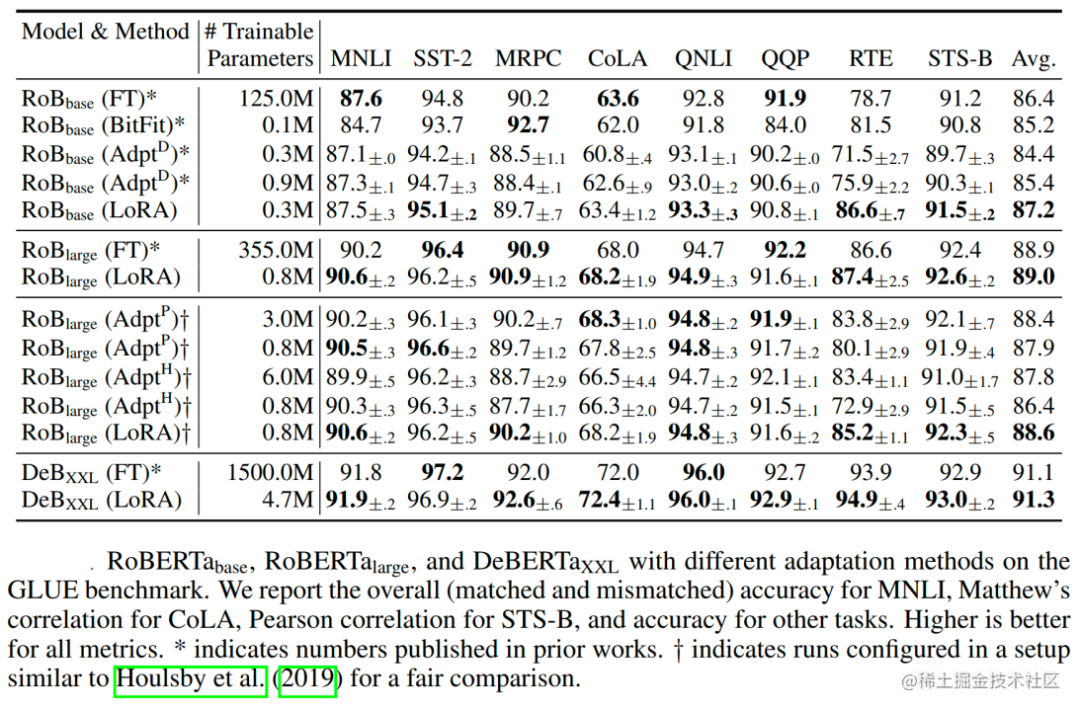
通過實驗也發現,在眾多數據集上LoRA在只訓練極少量參數的前提下,最終在性能上能和全量微調匹配,甚至在某些任務上優于全量微調。
AdaLoRA
背景
在NLP領域,對于下游任務進行大型預訓練語言模型的微調已經成為一種重要的做法。一般而言,我們會采用對原有的預訓練模型進行全量微調的方法來適配下游任務,但這種方法存在兩個問題。
訓練階段。對于預訓練模型進行微調的時候,為了更新權重參數,需要大量的顯存來存儲參數的梯度和優化器信息,在當今預訓練模型的參數變得越來越大的情況下,針對下游任務微調門檻變得越來越高。
推理階段。由于我們訓練的時候是對于模型參數進行全量的更新,所以多個下游任務需要為每個任務維護一個大型模型的獨立副本,這樣就導致我們在實際應用的時候浪費了不必要的存儲。
為了解決這些問題,研究者提出了兩個主要研究方向,以減少微調參數的數量,同時保持甚至提高預訓練語言模型的性能。
方向一:添加小型網絡模塊:將小型網絡模塊添加到PLMs中,保持基礎模型保持不變的情況下僅針對每個任務微調這些模塊,可以用于所有任務。這樣,只需引入和更新少量任務特定的參數,就可以適配下游的任務,大大提高了預訓練模型的實用性。如:Adapter tuning、Prefix tuning、Prompt Tuning等,這類方法雖然大大減少了內存消耗。但是這些方法存在一些問題,比如:Adapter tuning引入了推理延時;Prefix tuning或Prompt tuning直接優化Prefix和Prompt是非單調的,比較難收斂,并且消耗了輸入的token。
方向二:下游任務增量更新:對預訓練權重的增量更新進行建模,而無需修改模型架構,即W=W0+△W。比如:Diff pruning、LoRA等,此類方法可以達到與完全微調幾乎相當的性能,但是也存在一些問題,比如:Diff pruning需要底層實現來加速非結構化稀疏矩陣的計算,不能直接使用現有的框架,訓練過程中需要存儲完整的?W矩陣,相比于全量微調并沒有降低計算成本。LoRA則需要預先指定每個增量矩陣的本征秩 r 相同,忽略了在微調預訓練模型時,權重矩陣的重要性在不同模塊和層之間存在顯著差異,并且只訓練了Attention,沒有訓練FFN,事實上FFN更重要。
基于以上問題進行總結:
第一,我們不能預先指定矩陣的秩,需要動態更新增量矩陣的R,因為權重矩陣的重要性在不同模塊和層之間存在顯著差異。
第二,需要找到更加重要的矩陣,分配更多的參數,裁剪不重要的矩陣。找到重要的矩陣,可以提升模型效果;而裁剪不重要的矩陣,可以降低參數計算量,降低模型效果差的風險。
為了彌補這一差距,作者提出了AdaLoRA,它根據權重矩陣的重要性得分,在權重矩陣之間自適應地分配參數預算。
技術原理
AdaLoRA(論文:ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING),是對LoRA的一種改進,它根據重要性評分動態分配參數預算給權重矩陣。具體做法如下:
調整增量矩分配。AdaLoRA將關鍵的增量矩陣分配高秩以捕捉更精細和任務特定的信息,而將較不重要的矩陣的秩降低,以防止過擬合并節省計算預算。
以奇異值分解的形式對增量更新進行參數化,并根據重要性指標裁剪掉不重要的奇異值,同時保留奇異向量。由于對一個大矩陣進行精確SVD分解的計算消耗非常大,這種方法通過減少它們的參數預算來加速計算,同時,保留未來恢復的可能性并穩定訓練。
在訓練損失中添加了額外的懲罰項,以規范奇異矩陣P和Q的正交性,從而避免SVD的大量計算并穩定訓練。
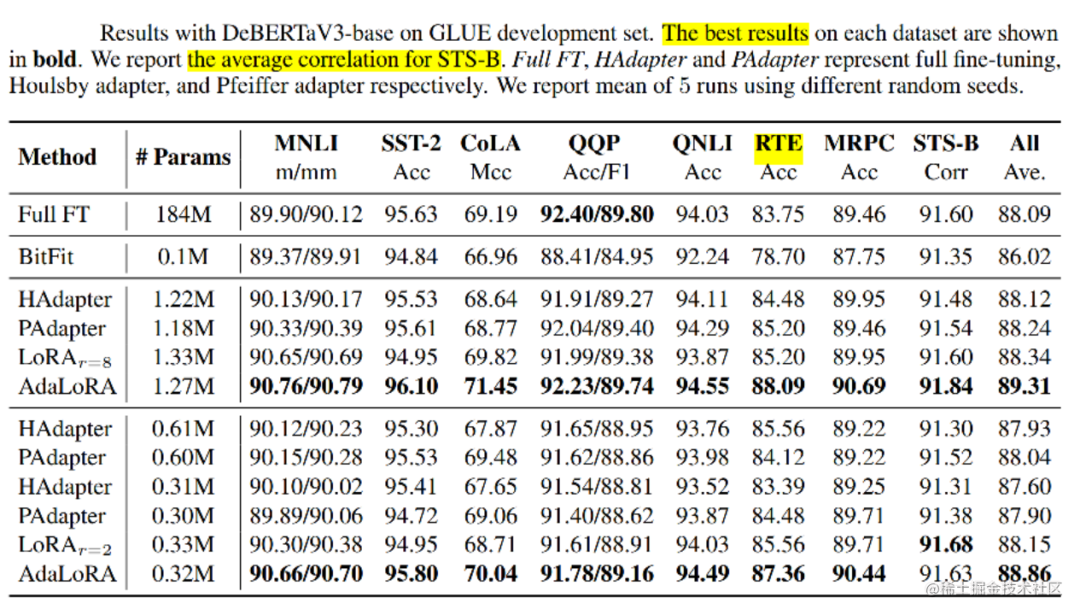
通過實驗證明,AdaLoRA 實現了在所有預算、所有數據集上與現有方法相比,性能更好或相當的水平。例如,當參數預算為 0.3M 時,AdaLoRA 在RTE數據集上,比表現最佳的基線(Baseline)高 1.8%。
QLoRA
背景
微調大型語言模型 (LLM) 是提高其性能以及添加所需或刪除不需要的行為的一種非常有效的方法。然而,微調非常大的模型非常昂貴;以 LLaMA 65B 參數模型為例,常規的 16 bit微調需要超過 780 GB 的 GPU 內存。
雖然最近的量化方法可以減少 LLM 的內存占用,但此類技術僅適用于推理場景。
基于此,作者提出了QLoRA,并首次證明了可以在不降低任何性能的情況下微調量化為 4 bit的模型。
技術原理
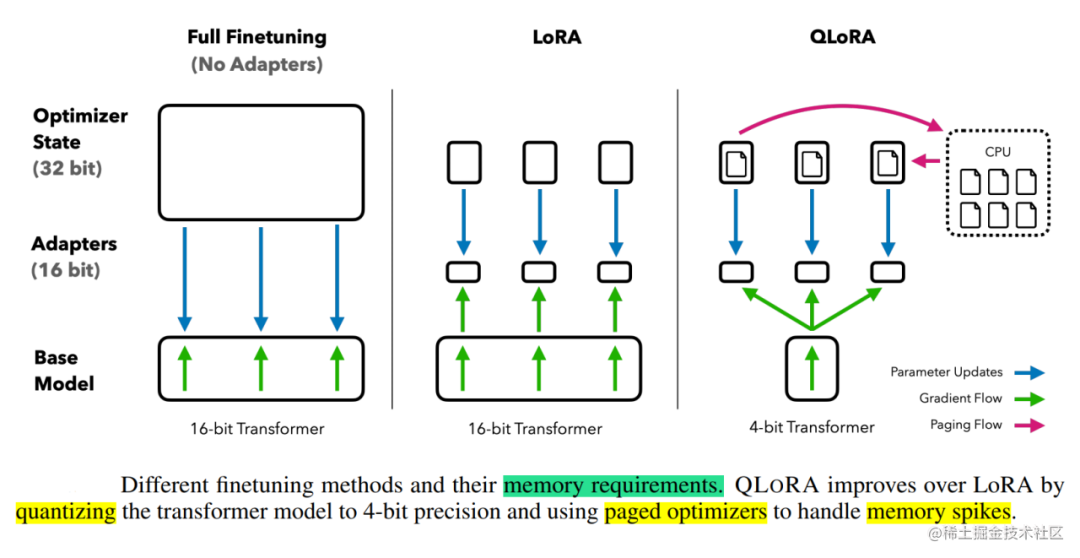
QLoRA(論文:QLORA: Efficient Finetuning of Quantized LLMs),使用一種新穎的高精度技術將預訓練模型量化為 4 bit,然后添加一小組可學習的低秩適配器權重,這些權重通過量化權重的反向傳播梯度進行微調。QLORA 有一種低精度存儲數據類型(4 bit),還有一種計算數據類型(BFloat16)。實際上,這意味著無論何時使用 QLoRA 權重張量,我們都會將張量反量化為 BFloat16,然后執行 16 位矩陣乘法。QLoRA提出了兩種技術實現高保真 4 bit微調——4 bit NormalFloat(NF4) 量化和雙量化。此外,還引入了分頁優化器,以防止梯度檢查點期間的內存峰值,從而導致內存不足的錯誤,這些錯誤在過去使得大型模型難以在單臺機器上進行微調。具體說明如下:
4bitNormalFloat(NF4):對于正態分布權重而言,一種信息理論上最優的新數據類型,該數據類型對正態分布數據產生比 4 bit整數和 4bit 浮點數更好的實證結果。
雙量化:對第一次量化后的那些常量再進行一次量化,減少存儲空間。
分頁優化器:使用NVIDIA統一內存特性,該特性可以在在GPU偶爾OOM的情況下,進行CPU和GPU之間自動分頁到分頁的傳輸,以實現無錯誤的 GPU 處理。該功能的工作方式類似于 CPU 內存和磁盤之間的常規內存分頁。使用此功能為優化器狀態(Optimizer)分配分頁內存,然后在 GPU 內存不足時將其自動卸載到 CPU 內存,并在優化器更新步驟需要時將其加載回 GPU 內存。
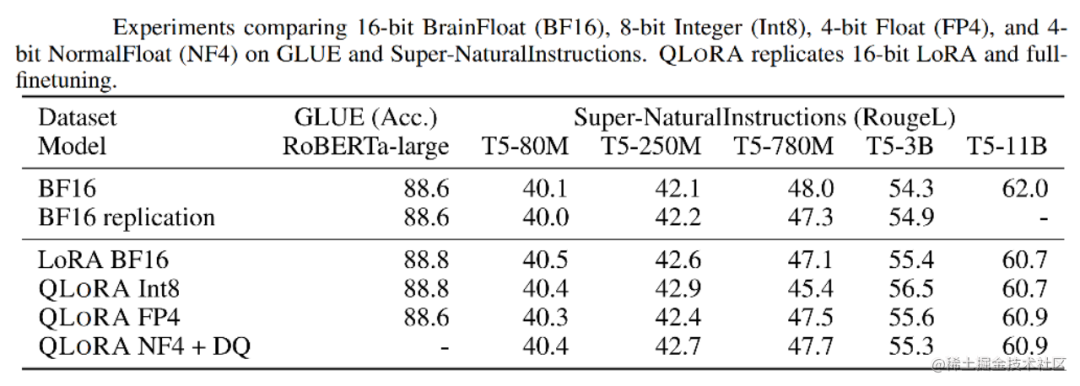
實驗證明,無論是使用16bit、8bit還是4bit的適配器方法,都能夠復制16bit全參數微調的基準性能。這說明,盡管量化過程中會存在性能損失,但通過適配器微調,完全可以恢復這些性能。
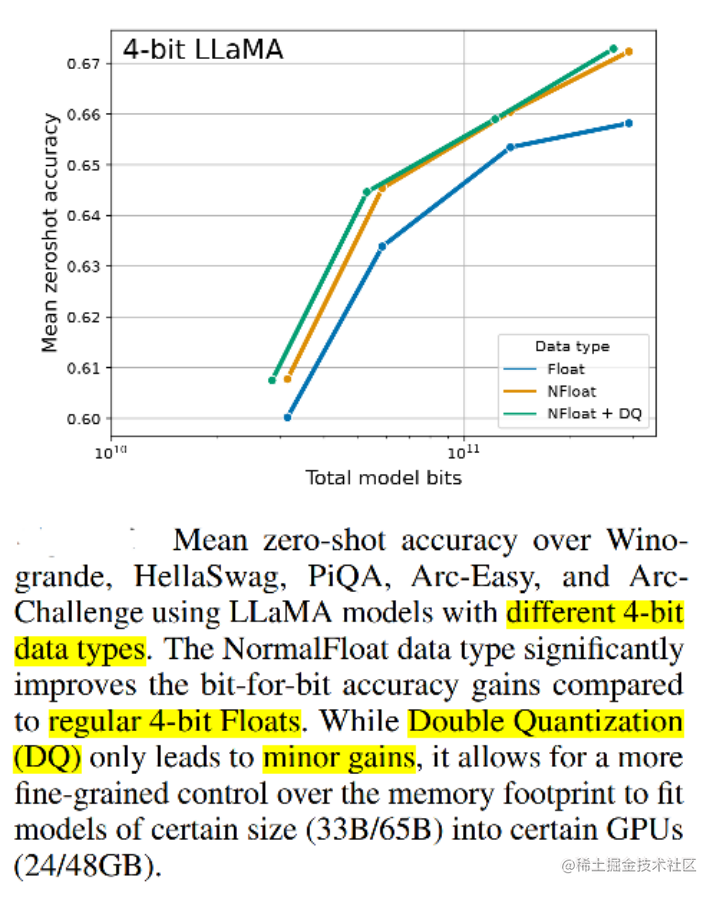
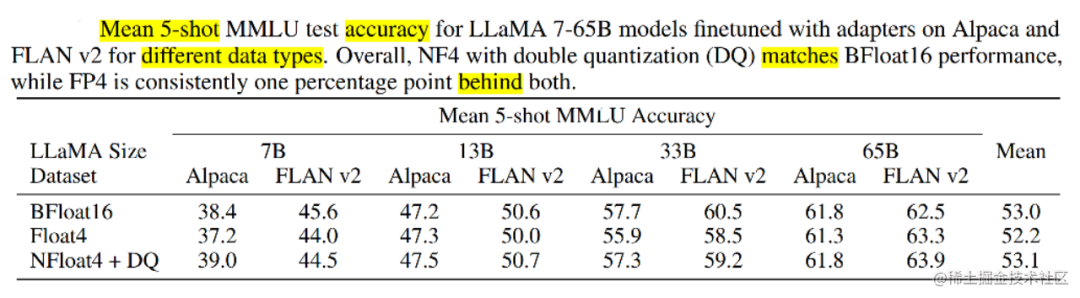
實驗還比較了不同的4bit數據類型對效果(zero-shot均值)的影響,其中,NFloat 顯著優于Float,而NFloat + DQ略微優于NFloat,雖然DQ對精度提升不大,但是對于內存控制效果更好。
除此之外,論文中還對不同大小模型、不同數據類型、在 MMLU數據集上的微調效果進行了對比。使用QLoRA(NFloat4 + DQ)可以和Lora(BFloat16)持平,同時,使用QLORA( FP4)的模型效果落后于前兩者一個百分點。
作者在實驗中也發現了一些有趣的點,比如:指令調優雖然效果比較好,但只適用于指令相關的任務,在聊天機器人上效果并不佳,而聊天機器人更適合用Open Assistant數據集去進行微調。通過指令類數據集的調優更像是提升大模型的推理能力,并不是為聊天而生的。
總之,QLoRA的出現給大家帶來一些新的思考,不管是微調還是部署大模型,之后都會變得更加容易。每個人都可以快速利用自己的私有數據進行微調;同時,又能輕松的部署大模型進行推理。
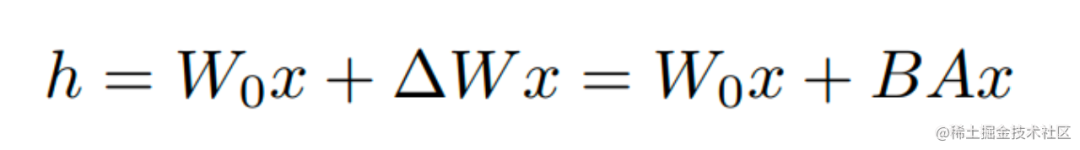
 ?
?
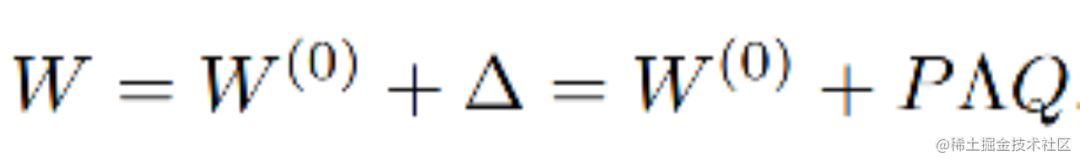
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103031 -
SVD
+關注
關注
0文章
21瀏覽量
12308 -
電源優化器
+關注
關注
0文章
11瀏覽量
5469 -
LoRa技術
+關注
關注
3文章
102瀏覽量
16823 -
nlp
+關注
關注
1文章
490瀏覽量
22527
原文標題:大模型參數高效微調技術原理綜述 之 LoRA、AdaLoRA、QLoRA
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【大語言模型:原理與工程實踐】核心技術綜述
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
永磁同步電機參數辨識研究綜述
基于模型設計的HDL代碼自動生成技術綜述
有哪些省內存的大語言模型訓練/微調/推理方法?
使用LoRA和Hugging Face高效訓練大語言模型
使用Alpaca-Lora進行參數高效模型微調
iPhone都能微調大模型了嘛
GLoRA:一種廣義參數高效的微調方法
大模型為什么要微調?大模型微調的原理
高效大模型的推理綜述






 工商網監
工商網監
評論