") SENSORO 支撐百萬級(jí)傳感器的延時(shí)隊(duì)列
SENSORO 支撐百萬級(jí)傳感器的延時(shí)隊(duì)列
文/升哲科技劉鵬
摘要:本文主要描述升哲科技在打造物聯(lián)智慧城市平臺(tái)過程中關(guān)于如何實(shí)現(xiàn)延時(shí)隊(duì)列服務(wù)的技術(shù)選型經(jīng)驗(yàn)、延時(shí)隊(duì)列服務(wù)的架構(gòu)設(shè)計(jì)以及延時(shí)隊(duì)列的底層細(xì)節(jié)實(shí)現(xiàn)原理。
背景
升哲科技是一家物聯(lián)網(wǎng)與人工智能領(lǐng)域的國家高新技術(shù)企業(yè)、獨(dú)角獸企業(yè)。
要打造物聯(lián)智慧城市平臺(tái),在業(yè)務(wù)中涉及到各種延時(shí)任務(wù)的需求,例如設(shè)備定時(shí)空氣開關(guān),定時(shí)更新設(shè)備狀態(tài),定時(shí)提醒等等,基于這些需求,需要一個(gè)可靠、實(shí)時(shí)、海量的延時(shí)隊(duì)列服務(wù)作為基礎(chǔ)設(shè)施。
那么延時(shí)隊(duì)列是什么呢?延時(shí)隊(duì)列不同于消息隊(duì)列按照先入先出(FIFO)的順序來消費(fèi),而是根據(jù)消息指定時(shí)間延時(shí)消費(fèi)。延時(shí)隊(duì)列的使用在我們?nèi)粘?yīng)用也非常多,比如:
· 在電商平臺(tái)購物,在30分鐘內(nèi)沒有支付自動(dòng)取消訂單;
· 待處理的工單超過1天未處理,二次發(fā)送提醒。
以上場景往往都需要延時(shí)隊(duì)列實(shí)現(xiàn)。
早期延時(shí)隊(duì)列的實(shí)現(xiàn)采用了數(shù)據(jù)庫掃表方式,服務(wù)定期查詢到期的任務(wù),再通過Kafka來中轉(zhuǎn)消息。當(dāng)任務(wù)量小,延時(shí)精度要求低時(shí)掃表方式還能應(yīng)對(duì),然而隨著業(yè)務(wù)增長、任務(wù)數(shù)量不斷增多,延時(shí)時(shí)間精度要求也變高,掃表的方式已經(jīng)無法滿足我們的業(yè)務(wù),于是我們開始探索新的技術(shù)方案來支撐百萬級(jí)任務(wù)的延時(shí)隊(duì)列。
延時(shí)隊(duì)列的設(shè)計(jì)目標(biāo)
1.高可用:多副本部署,保證服務(wù)不出現(xiàn)單點(diǎn)故障;
2.可擴(kuò)展:可隨著業(yè)務(wù)量增長來擴(kuò)容,同時(shí)生產(chǎn)消費(fèi)的請(qǐng)求延時(shí)也要低;
3.兼容舊接口,保證舊的服務(wù)不需要做任何修改;
4.消息傳遞可靠,至少保證一次送達(dá)。
技術(shù)選型
在開源社區(qū)已經(jīng)存在一些解決方案:
| 方案 | 描述 |
| Beanstalkd | Beanstalkd C語言實(shí)現(xiàn),我們團(tuán)隊(duì)主要采用Golang和Java,二次開發(fā)有難度,beanstalkd不支持集群部署,高可用無法保證。 |
| RabbitMQ延時(shí)隊(duì)列 | RabbitMQ提供了延時(shí)隊(duì)列插件,需要單獨(dú)開啟插件使用,其原理是通過死信隊(duì)列實(shí)現(xiàn)。 |
NSQ | NSQ開源延時(shí)隊(duì)列,NSQ支持延時(shí)隊(duì)列。 |
DelayQueue延時(shí)隊(duì)列 | JDK中提供了一組實(shí)現(xiàn)延時(shí)隊(duì)列的API,位于Java.util.concurrent包下DelayQueue。 |
時(shí)間輪算法 | 時(shí)間輪是一個(gè)算法,在 Netty、Akka、Quartz、ZooKeeper、Kafka等組件中都有使用,適合做統(tǒng)一調(diào)度器。 |
Redis Sorted Set | Redis Sorted Set 利用它的score屬性,啟用一個(gè)線程輪詢,根據(jù)score獲取超時(shí)的數(shù)據(jù),然后觸發(fā)超時(shí)操作。 |
考慮到運(yùn)維難度和可擴(kuò)展性,最終我們選擇了開源項(xiàng)目Lmstfy作為基礎(chǔ)來進(jìn)行二次開發(fā),選擇Lmstfy的原因如下:
● 無狀態(tài)服務(wù),使用Redis來持久化,Redis的高可用方案已經(jīng)非常成熟,在公/私有云都有Paas服務(wù)可使用;
● 支持?jǐn)U容,可以配置多個(gè)Redis集群;
● 提供Java/Go/Rust/PHP客戶端,監(jiān)控面板完善;
● 采用Golang開發(fā),高并發(fā)性能優(yōu)秀,也方便后續(xù)二次開發(fā)。
整體架構(gòu)設(shè)計(jì)
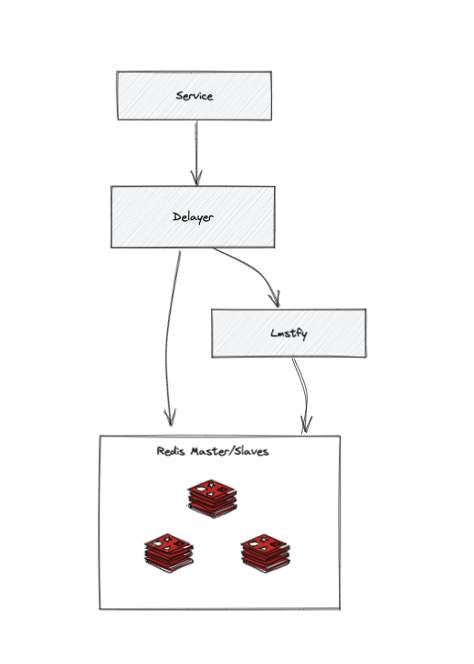
1.Delayer:無狀態(tài)服務(wù),提供給業(yè)務(wù)服務(wù)調(diào)用,兼容舊接口,在Delayer這一層直接操作Redis實(shí)現(xiàn)了任務(wù)刪除和更新任務(wù)等等功能;
2.Lmstfy:無狀態(tài)服務(wù),提供延時(shí)隊(duì)列基礎(chǔ)服務(wù),底層實(shí)現(xiàn)采用;
3.Redis Sentinel集群:保證Redis發(fā)生故障時(shí)自動(dòng)主備切換。
基礎(chǔ)概念
● namespace -用于隔離業(yè)務(wù),也可以通過配置namespace綁定不同的Redis集群;
● queue -隊(duì)列,用區(qū)分同一業(yè)務(wù)不同消息類型;
● job -業(yè)務(wù)定義的業(yè)務(wù),主要包含以下幾個(gè)屬性:
○ id:任務(wù) ID,全局唯一;
○ delay:任務(wù)延時(shí)下發(fā)時(shí)間,單位是秒;
○ tries:任務(wù)最大重試次數(shù),tries = N表示任務(wù)會(huì)最多下發(fā) N次;
○ ttr(time to run):任務(wù)預(yù)期執(zhí)行時(shí)間,超過 ttr則認(rèn)為任務(wù)消費(fèi)失敗,觸發(fā)任務(wù)自動(dòng)重試。
數(shù)據(jù)存儲(chǔ)
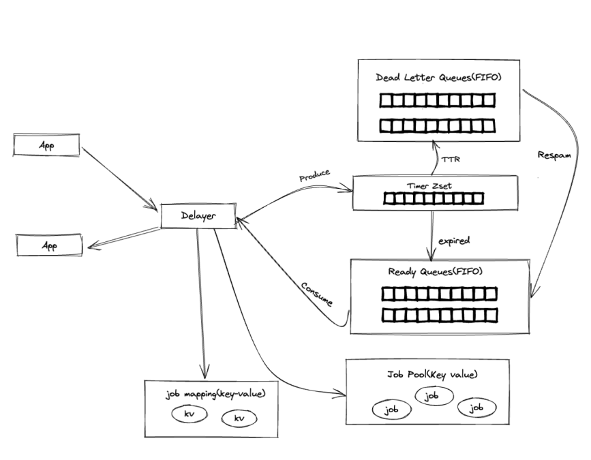
Lmstfy的 Redis存儲(chǔ)由四部分組成:
● Timer:使用ZSET結(jié)構(gòu)來存儲(chǔ)延時(shí)任務(wù),Score即任務(wù)的到期時(shí)間來排序;
● Ready queue - 使用LIST結(jié)構(gòu),存儲(chǔ)已經(jīng)到期的延時(shí)任務(wù),實(shí)現(xiàn)FIFO消費(fèi);
● Deadletter-使用LIST結(jié)構(gòu),消費(fèi)失敗(重試次數(shù)到達(dá)上限)的任務(wù),可以手動(dòng)重新放回到隊(duì)列;
● Job pool– string類型,存儲(chǔ)消息meta信息;
● Job mapping - string -存儲(chǔ)應(yīng)用自定義id和job的關(guān)聯(lián)關(guān)系。
創(chuàng)建任務(wù)
創(chuàng)建任務(wù)會(huì)生成一個(gè)Job ID, Job ID包括寫入時(shí)間戳、隨機(jī)數(shù)和延時(shí)時(shí)長,然后將任務(wù)的meta信息寫入Redis,Key為 j/{namespace}/queue/{id},當(dāng)任務(wù)延時(shí)時(shí)間(delay)= 0,(實(shí)時(shí)消息隊(duì)列我們使用Kafka)表示不需要延時(shí)則直接寫到 Ready Queue(List),當(dāng)延時(shí)時(shí)間(delay) = n(n > 0),表示需要延時(shí),將延時(shí)加上當(dāng)前系統(tǒng)時(shí)間作為絕對(duì)時(shí)間戳寫到 Timer(sorted set),Timer的實(shí)現(xiàn)是利用 ZSET根據(jù)絕對(duì)時(shí)間戳進(jìn)行排序,再由一個(gè)goroutine定期輪詢將到期的任務(wù)通過 redis lua script來將數(shù)據(jù)轉(zhuǎn)移到 Ready Queue(List)中。
任務(wù)消費(fèi)
支持延時(shí)的任務(wù)隊(duì)列本質(zhì)上是兩個(gè)數(shù)據(jù)結(jié)構(gòu)的結(jié)合: Ready Queue(LIST)和 Sorted Set。
Sorted Set用來實(shí)現(xiàn)延時(shí)的部分,將任務(wù)按照到期時(shí)間戳升序存儲(chǔ),隨后定期將到期的任務(wù)遷移至 Ready Queue(LIST)。
任務(wù)的具體內(nèi)容只會(huì)存儲(chǔ)一份在 Job pool里面,其他的如 Ready Queue只是存儲(chǔ)Job id,這樣可以節(jié)省內(nèi)存空間。
任務(wù)更新和刪除
Lmstfy本身不支持刪除和更新,我們在Delayer層中在創(chuàng)建任務(wù)同時(shí)在Redis中創(chuàng)建了一個(gè)Mapping Key,客戶端可以自定一個(gè)ID關(guān)聯(lián)到Job id,Delayer提供了刪除和更新(先刪除再創(chuàng)建)API,我們業(yè)務(wù)還需要支持多次執(zhí)行的功能,在處理Job Ack時(shí)根據(jù)任務(wù)參數(shù)重新插入隊(duì)列,結(jié)合我們二次開發(fā)整體結(jié)構(gòu)如下:
性能表現(xiàn)
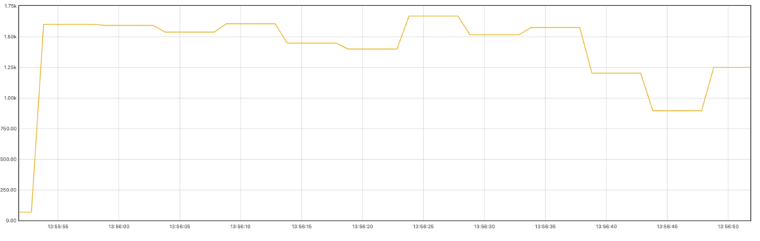
通過本地限定1核CPU壓測生產(chǎn)消息數(shù)據(jù)如下:
200萬任務(wù)量占內(nèi)存600MB+,其中包括mapping key導(dǎo)致key數(shù)量翻倍。
以下是單核CPU的環(huán)境下壓測結(jié)果,任務(wù)創(chuàng)建可高達(dá)1500TPS:
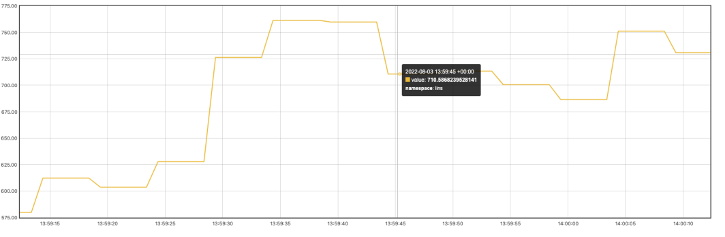
延時(shí)任務(wù)到期時(shí)間比較分散的情況下,消費(fèi)表現(xiàn)如下接800TPS:
總結(jié)
封裝lmstfy的方案已足夠支撐當(dāng)前的使用場景,但還是有一些不足之處,比如:
● 在Delayer中操作Redis中的任務(wù),無法保證原子性;
● 任務(wù)創(chuàng)建和消費(fèi)另外會(huì)多一次網(wǎng)絡(luò)請(qǐng)求,產(chǎn)生不必要的開銷;
● 無法支持循環(huán)任務(wù);
● Lmstfy采用HTTP協(xié)議,無法發(fā)揮更好性能。
未來,我們計(jì)劃融合兩個(gè)服務(wù),完善任務(wù)CRUD功能,減少網(wǎng)絡(luò)開銷,并采用GRPC來替換HTTP協(xié)議通訊。
-
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8953瀏覽量
139678 -
智慧城市
+關(guān)注
關(guān)注
21文章
4348瀏覽量
99479
發(fā)布評(píng)論請(qǐng)先 登錄
stm32f103用freertos對(duì)一個(gè)采樣率為1kHz的傳感器,進(jìn)行采樣,數(shù)據(jù)出差
NVME控制器之隊(duì)列管理模塊
Vishay Opto VEML6031X00汽車級(jí)環(huán)境光傳感器

漢威科技柔彈性傳感器為智能選床墊系統(tǒng)提供支撐
芯閱科技發(fā)布芯片級(jí)水質(zhì)傳感器
干簧管傳感器屬于什么傳感器
盤點(diǎn)五種最有前途的新興傳感器
納芯微發(fā)布兩款車規(guī)級(jí)壓力傳感器新品
mems傳感器是什么意思_mems傳感器原理是什么
霍爾傳感器測電壓會(huì)有延時(shí)嗎
怎么區(qū)分PNP傳感器和NPN傳感器
車載傳感器主要有哪些傳感器
長光辰芯發(fā)布億級(jí)像素CMOS圖像傳感器GMAX64104
TMP275-Q1汽車級(jí)±0.75°C溫度傳感器數(shù)據(jù)表






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論