") 牛津劍橋研究警告:AI訓(xùn)AI成「劇毒」,會(huì)讓模型崩潰!
牛津劍橋研究警告:AI訓(xùn)AI成「劇毒」,會(huì)讓模型崩潰!
【導(dǎo)讀】最差的人類(lèi)語(yǔ)料,也要?jiǎng)龠^(guò)AI生成的文本。
隨著GPT-4、Stable Diffusion和Midjourney的爆火,越來(lái)越多的人開(kāi)始在工作和生活中引入生成式AI技術(shù)。
甚至,有人已經(jīng)開(kāi)始嘗試用AI生成的數(shù)據(jù)來(lái)訓(xùn)練AI了。難道,這就是傳說(shuō)中的「數(shù)據(jù)永動(dòng)機(jī)」?
然而,來(lái)自牛津、劍橋、帝國(guó)理工等機(jī)構(gòu)研究人員發(fā)現(xiàn),如果在訓(xùn)練時(shí)大量使用AI內(nèi)容,會(huì)引發(fā)模型崩潰(model collapse),造成不可逆的缺陷。
也就是,隨著時(shí)間推移,模型就會(huì)忘記真實(shí)基礎(chǔ)數(shù)據(jù)部分。即使在幾乎理想的長(zhǎng)期學(xué)習(xí)狀態(tài)下,這個(gè)情況也無(wú)法避免。
因此研究人員呼吁,如果想要繼續(xù)保持大規(guī)模數(shù)據(jù)帶來(lái)的模型優(yōu)越性,就必須認(rèn)真對(duì)待人類(lèi)自己寫(xiě)出來(lái)的文本。

論文地址:https://arxiv.org/abs/2305.17493v2
但現(xiàn)在的問(wèn)題在于——你以為的「人類(lèi)數(shù)據(jù)」,可能并不是「人類(lèi)」寫(xiě)的。
洛桑聯(lián)邦理工學(xué)院(EPFL)的最新研究稱(chēng),預(yù)估33%-46%的人類(lèi)數(shù)據(jù)都是由AI生成的。

訓(xùn)練數(shù)據(jù),都是「垃圾」
毫無(wú)疑問(wèn),現(xiàn)在的大語(yǔ)言模型已經(jīng)進(jìn)化出了相當(dāng)強(qiáng)大的能力,比如GPT-4可以在某些場(chǎng)景下生成與人類(lèi)別無(wú)二致的文本。
但這背后的一個(gè)重要原因是,它們的訓(xùn)練數(shù)據(jù)大部分來(lái)源于過(guò)去幾十年人類(lèi)在互聯(lián)網(wǎng)上的交流。
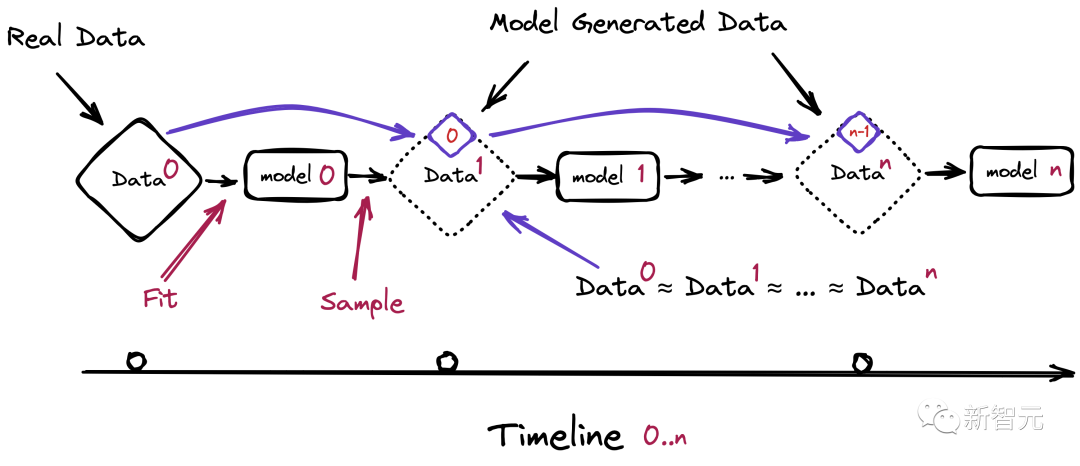
如果未來(lái)的語(yǔ)言模型仍然依賴(lài)于從網(wǎng)絡(luò)上爬取數(shù)據(jù)的話(huà),就不可避免地要在訓(xùn)練集中引入自己生成的文本。
對(duì)此,研究人員預(yù)測(cè),等GPT發(fā)展到第n代的時(shí)候,模型將會(huì)出現(xiàn)嚴(yán)重的崩潰問(wèn)題。
那么,在這種不可避免會(huì)抓取到LLM生成內(nèi)容的情況下,為模型的訓(xùn)練準(zhǔn)備由人類(lèi)生產(chǎn)的真實(shí)數(shù)據(jù),就變得尤為重要了。
大名鼎鼎的亞馬遜數(shù)據(jù)眾包平臺(tái)Mechanical Turk(MTurk)從2005年啟動(dòng)時(shí)就已經(jīng)成為許多人的副業(yè)選擇。
科研人員可以發(fā)布各種瑣碎的人類(lèi)智能任務(wù),比如給圖像標(biāo)注、調(diào)查等,應(yīng)有盡有。
而這些任務(wù)通常是計(jì)算機(jī)和算法無(wú)法處理的,甚至,MTurk成為一些預(yù)算不夠的科研人員和公司的「最佳選擇」。
就連貝佐斯還將MTurk的眾包工人戲稱(chēng)為「人工人工智能」。

除了MTurk,包括Prolific在內(nèi)的眾包平臺(tái)已經(jīng)成為研究人員和行業(yè)實(shí)踐者的核心,能夠提供創(chuàng)建、標(biāo)注和總結(jié)各種數(shù)據(jù)的方法,以便進(jìn)行調(diào)查和實(shí)驗(yàn)。
然而,來(lái)自EPFL的研究發(fā)現(xiàn),在這個(gè)人類(lèi)數(shù)據(jù)的關(guān)鍵來(lái)源上,有近乎一半的數(shù)據(jù)都是標(biāo)注員用AI創(chuàng)建的。

論文地址:https://arxiv.org/abs/2306.07899v1
模型崩潰
而最開(kāi)始提到的「模型崩潰」,就是在給模型投喂了太多來(lái)自AI的數(shù)據(jù)之后,帶來(lái)的能夠影響多代的退化。
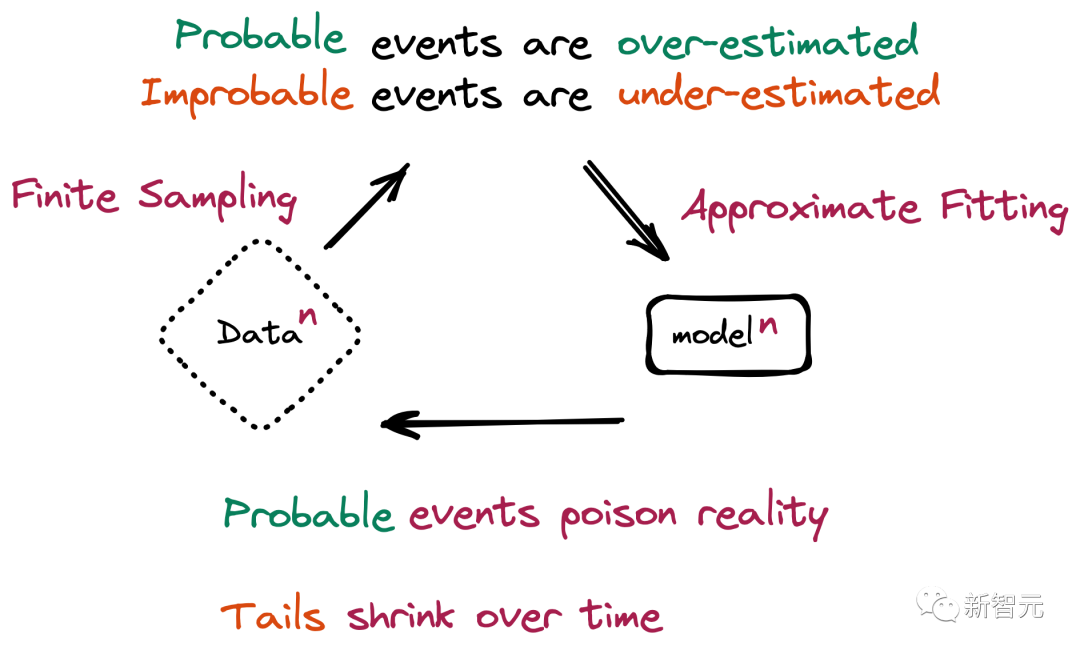
也就是,新一代模型的訓(xùn)練數(shù)據(jù)會(huì)被上一代模型的生成數(shù)據(jù)所污染,從而對(duì)現(xiàn)實(shí)世界的感知產(chǎn)生錯(cuò)誤的理解。
更進(jìn)一步,這種崩潰還會(huì)引發(fā)比如基于性別、種族或其他敏感屬性的歧視問(wèn)題,尤其是如果生成AI隨著時(shí)間的推移學(xué)會(huì)在其響應(yīng)中只生成某個(gè)種族,而「忘記」其他種族的存在。
而且,除了大語(yǔ)言模型,模型崩潰還會(huì)出現(xiàn)在變分自編碼器(VAE)、高斯混合模型上。
需要注意的是,模型崩潰的過(guò)程與災(zāi)難性遺忘(catastrophic forgetting)不同,模型不會(huì)忘記以前學(xué)過(guò)的數(shù)據(jù),而是開(kāi)始把模型的錯(cuò)誤想法曲解為現(xiàn)實(shí),并且還會(huì)強(qiáng)化自己對(duì)錯(cuò)誤想法的信念。

舉個(gè)例子,比如模型在一個(gè)包含100張貓圖片的數(shù)據(jù)集上進(jìn)行訓(xùn)練,其中有10張藍(lán)毛貓,90張黃毛貓。
模型學(xué)到的結(jié)論是,黃毛貓更普遍,同時(shí)會(huì)傾向于把藍(lán)毛貓想象的比實(shí)際更偏黃,所以在被要求生成新數(shù)據(jù)時(shí)可能會(huì)返回一些類(lèi)似綠毛貓的結(jié)果。
而隨著時(shí)間的推移,藍(lán)毛的原始特征在多個(gè)訓(xùn)練epoch中逐漸被侵蝕,直接從藍(lán)色變成了綠色,最終再演變?yōu)辄S色,這種漸進(jìn)的扭曲和丟失少數(shù)特征的現(xiàn)象就是模型崩潰。

具體來(lái)說(shuō),模型崩潰可以分為兩種情況:
1. 早期模型崩潰(early model collapse),模型開(kāi)始丟失有關(guān)分布尾部的信息;
2. 后期模型崩潰(late model collapse),模型與原始分布的不同模式糾纏在一起,并收斂到一個(gè)與原始分布幾乎沒(méi)有相似之處的分布,往往方差也會(huì)非常小。
與此同時(shí),研究人員也總結(jié)出了造成模型崩潰的兩個(gè)主要原因:
其中,在更多的時(shí)候,我們會(huì)得到一種級(jí)聯(lián)效應(yīng),即單個(gè)不準(zhǔn)確的組合會(huì)導(dǎo)致整體誤差的增加。
1. 統(tǒng)計(jì)近似誤差(Statistical approximation error)
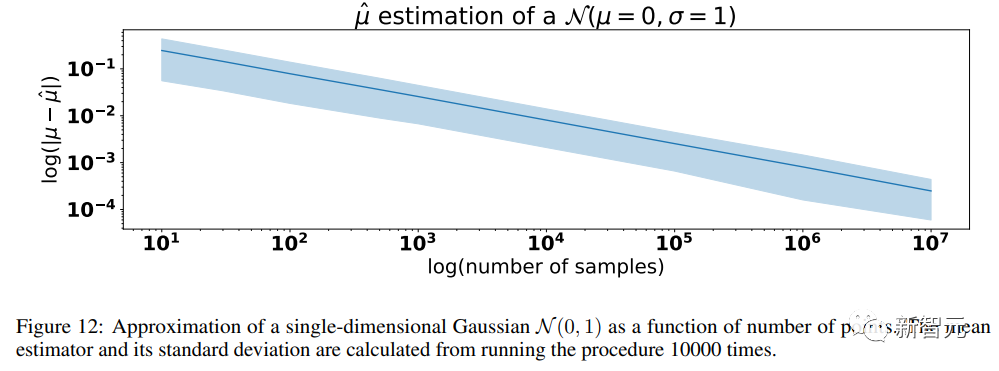
在重采樣的每一步中,信息中非零概率都可能會(huì)丟失,導(dǎo)致出現(xiàn)統(tǒng)計(jì)近似誤差,當(dāng)樣本數(shù)量趨于無(wú)限會(huì)逐漸消失,該誤差是導(dǎo)致模型崩潰的主要原因。
2. 函數(shù)近似誤差(Functional approximation error)
該誤差主要源于模型中的函數(shù)近似器表達(dá)能力不足,或者有時(shí)在原始分布支持之外的表達(dá)能力太強(qiáng)。
眾所周知,神經(jīng)網(wǎng)絡(luò)在極限情況下是通用的函數(shù)近似器,但實(shí)際上這種假設(shè)并不總是成立的,特別是神經(jīng)網(wǎng)絡(luò)可以在原始分布的支持范圍之外引入非零似然。
舉個(gè)簡(jiǎn)單例子,如果我們?cè)噲D用一個(gè)高斯分布來(lái)擬合兩個(gè)高斯的混合分布,即使模型具有關(guān)于數(shù)據(jù)分布的完美信息,模型誤差也是不可避免的。
需要注意的是,在沒(méi)有統(tǒng)計(jì)誤差的情況下,函數(shù)近似誤差只會(huì)發(fā)生在第一代,一旦新的分布能被函數(shù)近似器描述出來(lái),就會(huì)在各代模型中保持完全相同的分布。
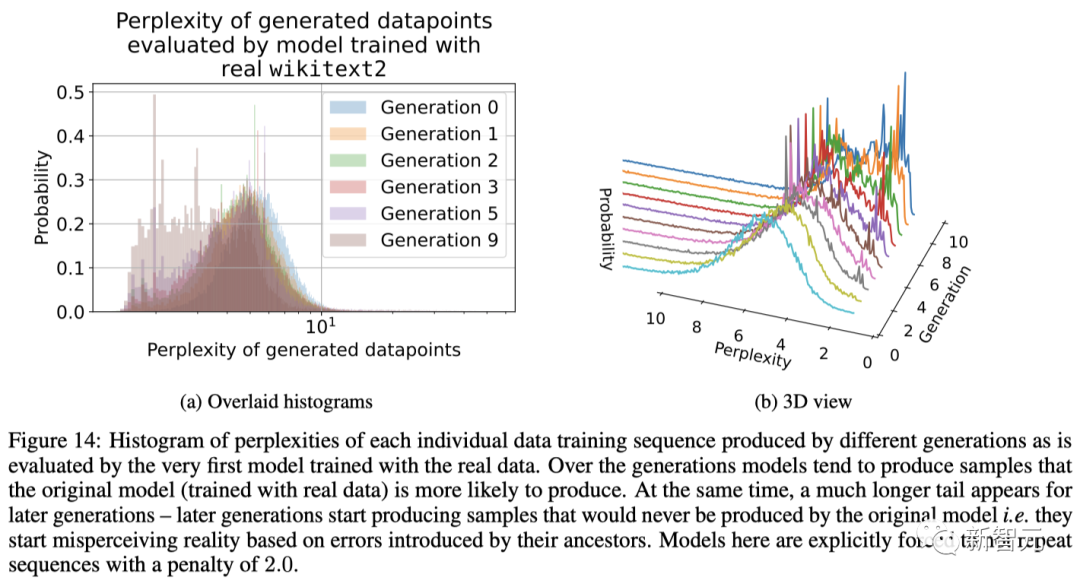
可以說(shuō),模型強(qiáng)大的近似能力是一把雙刃劍:其表達(dá)能力可能會(huì)抵消統(tǒng)計(jì)噪聲,從而更好地?cái)M合真實(shí)分布,但同樣也會(huì)使噪聲復(fù)雜化。
對(duì)此,論文共同一作Ilia Shumailov表示:「生成數(shù)據(jù)中的錯(cuò)誤會(huì)累積,最終迫使從生成數(shù)據(jù)中學(xué)習(xí)的模型進(jìn)一步錯(cuò)誤地理解現(xiàn)實(shí)。而且模型崩潰發(fā)生得非常快,模型會(huì)迅速忘記最初學(xué)習(xí)的大部分原始數(shù)據(jù)。」
解決方法
好在,研究人員發(fā)現(xiàn),我們還是有辦法來(lái)避免模型崩潰的。
第一種方法是保留原始的、完全或名義上由人類(lèi)生成的數(shù)據(jù)集的高質(zhì)量副本,并避免與AI生成的數(shù)據(jù)混合,然后定期使用這些數(shù)據(jù)對(duì)模型進(jìn)行重新訓(xùn)練,或者完全從頭訓(xùn)練一遍模型。
第二種避免回復(fù)質(zhì)量下降并減少AI模型中的錯(cuò)誤或重復(fù)的方法是將全新的、干凈的、由人類(lèi)生成的數(shù)據(jù)集重新引入訓(xùn)練中。
為了防止模型崩潰,開(kāi)發(fā)者需要確保原始數(shù)據(jù)中的少數(shù)派在后續(xù)數(shù)據(jù)集中得到公正的表征。
數(shù)據(jù)需要仔細(xì)備份,并覆蓋所有可能的邊界情況;在評(píng)估模型的性能時(shí),需要考慮到模型將要處理的數(shù)據(jù),甚至是最不可信的數(shù)據(jù)。
隨后,當(dāng)重新訓(xùn)練模型時(shí),還需要確保同時(shí)包括舊數(shù)據(jù)和新數(shù)據(jù),雖然會(huì)增加訓(xùn)練的成本,但至少在某種程度上有助于緩解模型崩潰。
不過(guò),這些方法必須要內(nèi)容制作者或AI公司采取某種大規(guī)模的標(biāo)記機(jī)制,來(lái)區(qū)分AI生成的內(nèi)容和人類(lèi)生成的內(nèi)容。
目前,有一些開(kāi)箱即用的解決方案,比如GPTZero,OpenAI Detector,或Writer在簡(jiǎn)單的文本上工作得很好。

然而,在一些特殊的文本中,這些方法并不能有效執(zhí)行。比如,在EPFL研究中有ChatGPT合成的10個(gè)總結(jié),而GPTZero只檢測(cè)到6個(gè)是合成的。
對(duì)此,研究人員通過(guò)微調(diào)自己的模型來(lái)檢測(cè)AI的使用,發(fā)現(xiàn)ChatGPT在編寫(xiě)本文時(shí)是最常用的LLM。
對(duì)于構(gòu)建的檢測(cè)AI數(shù)據(jù)的方法,研究人員利用原始研究中的答案和用ChatGPT合成的數(shù)據(jù),訓(xùn)練了一個(gè)定制的「合成-真實(shí)分類(lèi)器」。
然后用這個(gè)分類(lèi)器來(lái)估計(jì)重新進(jìn)行的任務(wù)中合成答案的普遍性。
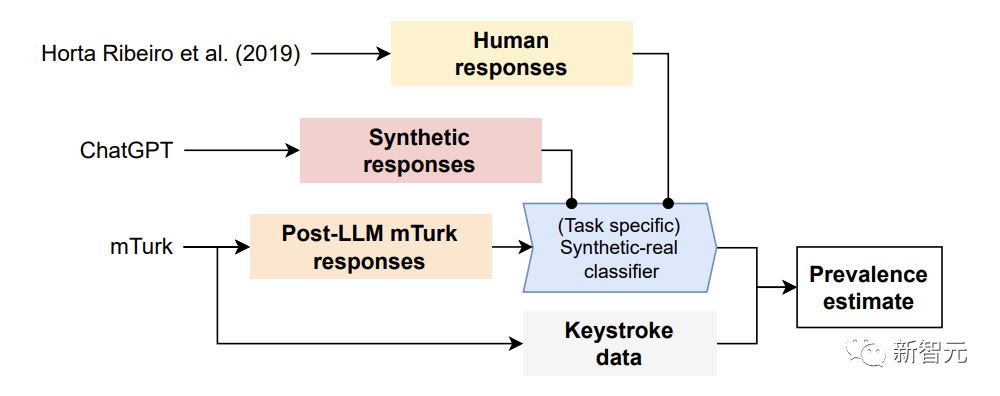
具體來(lái)講,研究人員首先使用真正由人類(lèi)撰寫(xiě)的MTurk回應(yīng),和合成LLM生成的回應(yīng),來(lái)訓(xùn)練特定任務(wù)的「合成-真實(shí)分類(lèi)器」。
其次,將這個(gè)分類(lèi)器用于MTurk的真實(shí)回應(yīng)(其中眾包人可能使用,也可能沒(méi)有依賴(lài)LLM),以估計(jì)LLM使用的普遍性。
最后,研究者確認(rèn)了結(jié)果的有效性,在事后比較分析擊鍵數(shù)據(jù)與MTurk的回應(yīng)。
實(shí)驗(yàn)結(jié)果顯示,這個(gè)模型在正確識(shí)別人工智能文本方面高達(dá)99%的準(zhǔn)確率。
此外,研究人員用擊鍵數(shù)據(jù)驗(yàn)證了結(jié)果,發(fā)現(xiàn):
- 完全在MTurk文本框中寫(xiě)的總結(jié)(不太可能是合成的)都被歸類(lèi)為真實(shí)的;
- 在粘貼的總結(jié)中,提取式總結(jié)和LLM的使用有明顯區(qū)別。
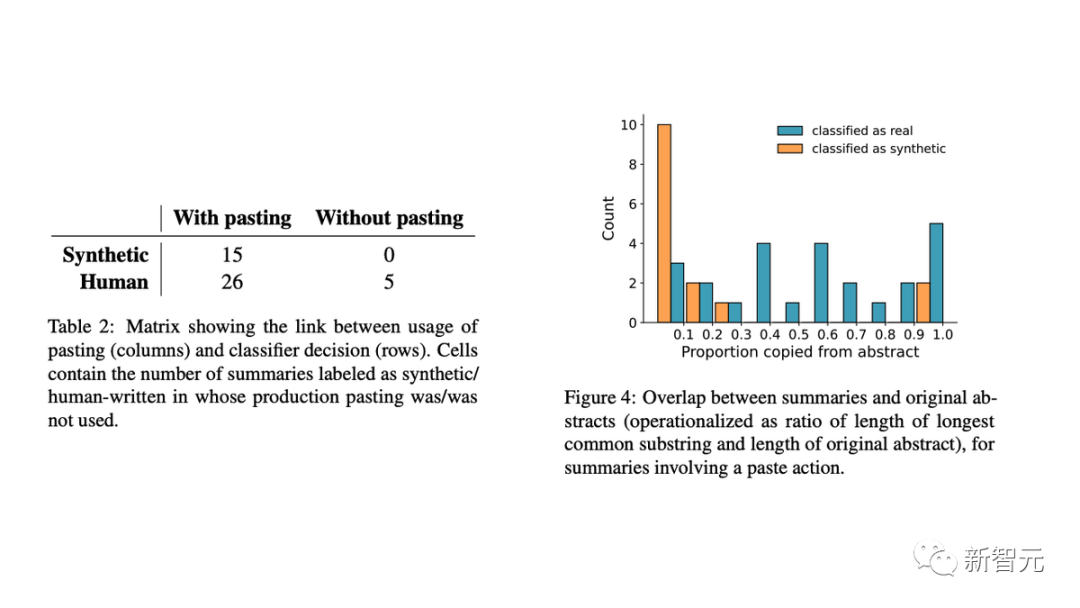
具體來(lái)講,人工智能生成的文本通常與原始總結(jié)幾乎沒(méi)有相似之處。這表明AI模型正在生成新文本,而不是復(fù)制和粘貼原始內(nèi)容的一部分。
「人類(lèi)數(shù)據(jù)」很重要
現(xiàn)在,人們普遍擔(dān)心LLM將塑造人類(lèi)的「信息生態(tài)系統(tǒng)」,也就是說(shuō),在線可獲得的大部分信息都是由LLM生成的。
使用綜合生成數(shù)據(jù)訓(xùn)練的LLM的性能明顯降低,就像Ilia Shumailov所稱(chēng)會(huì)讓模型患上「癡呆癥」。
而這個(gè)問(wèn)題將會(huì)變得更加嚴(yán)重,因?yàn)殡S著LLM的普及,眾包工作者們已經(jīng)廣泛使用ChatGPT等各種LLM。
但對(duì)于人類(lèi)內(nèi)容創(chuàng)作者來(lái)說(shuō),這是一個(gè)好消息,提高工作效率的同時(shí),還賺到了錢(qián)。
但是,若想挽救LLM不陷于崩潰的邊緣,還是需要真實(shí)的「人類(lèi)數(shù)據(jù)」。
1. 人類(lèi)數(shù)據(jù)在科學(xué)中仍然是至關(guān)重要的
2. 在合成數(shù)據(jù)上訓(xùn)練模型可能會(huì)帶來(lái)偏見(jiàn)和意識(shí)形態(tài)永久化
3. 隨著模型變得流行和更好/多模態(tài),采用率只會(huì)增加
總的來(lái)說(shuō),由人類(lèi)生成的原始數(shù)據(jù)可以更好地表示世界,雖然也可能包含某些劣質(zhì)、概率較低的數(shù)據(jù);而生成式模型往往只會(huì)過(guò)度擬合流行數(shù)據(jù),并對(duì)概率更低的數(shù)據(jù)產(chǎn)生誤解。
那么,在充斥著生成式AI工具和相關(guān)內(nèi)容的未來(lái),人類(lèi)制作的內(nèi)容或許會(huì)比今天更有價(jià)值,尤其是作為AI原始訓(xùn)練數(shù)據(jù)的來(lái)源。
-
AI
+關(guān)注
關(guān)注
88文章
34378瀏覽量
275616 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
559瀏覽量
10689 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15958
原文標(biāo)題:GPT-5將死于GPT-4背刺?牛津劍橋研究警告:AI訓(xùn)AI成「劇毒」,會(huì)讓模型崩潰!
文章出處:【微信號(hào):AI智勝未來(lái),微信公眾號(hào):AI智勝未來(lái)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論