") 通往AGI之路:揭秘英偉達(dá)A100、A800、H800、V100在高性能計算與大模型訓(xùn)練中的霸主地位
通往AGI之路:揭秘英偉達(dá)A100、A800、H800、V100在高性能計算與大模型訓(xùn)練中的霸主地位

AGI | NLP | A100 |H100 | Nvidia | Aurora
GPT| LLM | A800 |V100 | Intel | ChatGPT
日前,隨著深度學(xué)習(xí)、高性能計算、大模型訓(xùn)練等技術(shù)的保駕護(hù)航,通用人工智能時代即將到來。各個廠商也都在緊鑼密鼓的布局,如英偉達(dá)前段時間發(fā)布GH 200包含 36 個 NVLink 開關(guān),將 256 個 GH200 Grace Hopper 芯片和 144TB 的共享內(nèi)存連接成一個單元。除此之外,英偉達(dá)A100、A800、H100、V100也在大模型訓(xùn)練中廣受歡迎。AMD MI300X其內(nèi)存遠(yuǎn)超120GB的英偉達(dá)GPU芯片H100,高達(dá)192GB。
6月22日,英特爾(Intel)宣布,美國能源部阿貢國家實驗室已完成新一代超級計算機(jī)"Aurora"的安裝工作。這臺超級計算機(jī)基于英特爾的CPU和GPU,預(yù)計在今年晚些時候上線,將提供超過2 exaflops的FP64浮點性能,超越美國能源部橡樹嶺國家實驗室的"Frontier",有望成為全球第一臺理論峰值性能超過2 exaflops的超級計算機(jī)。
Aurora超級計算機(jī)是英特爾、惠普(HPE)和美國能源部(DOE)的合作項目,旨在充分發(fā)揮高性能計算(HPC)在模擬、數(shù)據(jù)分析和人工智能(AI)領(lǐng)域的潛力。該系統(tǒng)由10624個刀片服務(wù)器組成,每個刀片由兩個英特爾Xeon Max系列CPU(至強(qiáng)Max 9480)和六個英特爾Max系列GPU組成。

GPT-4作為一款先進(jìn)的AI技術(shù),其六項技術(shù)的引入將為人工智能領(lǐng)域帶來巨大的突破和變革。GPU作為算力核心服務(wù)器的重要載體扮演著至關(guān)重要的角色。GPU的高效處理能力與并行計算能力,使其成為實現(xiàn)大型語言模型訓(xùn)練的優(yōu)秀選擇。然而,數(shù)據(jù)中心算力瓶頸成為限制其發(fā)展的主要因素之一。
在中國,各大公司也在爭奪AI入場券,競逐GPU的先機(jī)。這一競爭正迅速推動著中國在人工智能領(lǐng)域的發(fā)展。GPU的廣泛應(yīng)用將為中國企業(yè)提供更多機(jī)會,從而在AI大模型訓(xùn)練場上取得更加優(yōu)勢的地位。
本文將深入探討GPU在AI大模型訓(xùn)練場上的重要性和優(yōu)勢,并分析當(dāng)前面臨的挑戰(zhàn)和機(jī)遇。同時,將探討如何優(yōu)化GPU服務(wù)器適配,以實現(xiàn)大型語言模型訓(xùn)練的突破。在接下來的內(nèi)容中,我們將探索如何解決數(shù)據(jù)中心算力瓶頸、加速AI技術(shù)的進(jìn)步、優(yōu)化GPU服務(wù)器的適配以及推動中國企業(yè)在AI領(lǐng)域的競爭力。這將引領(lǐng)我們進(jìn)入一個全新的AI時代,為人工智能的發(fā)展開創(chuàng)更加廣闊的前景。
GPT-4六項技術(shù)創(chuàng)新
一、大參數(shù)+大數(shù)據(jù)+算法創(chuàng)新
參數(shù)擴(kuò)大是提升大語言模型(LLM)能力的關(guān)鍵因素。GPT-3首次將模型大小擴(kuò)展到175B參數(shù)規(guī)模。在語言模型的早期階段性能與模型規(guī)模大致呈線性關(guān)系,但當(dāng)模型規(guī)模達(dá)到一定程度時,任務(wù)性能會出現(xiàn)明顯的突變。大語言模型的基礎(chǔ)具有很強(qiáng)的可擴(kuò)展性,可以實現(xiàn)反復(fù)自我迭代。
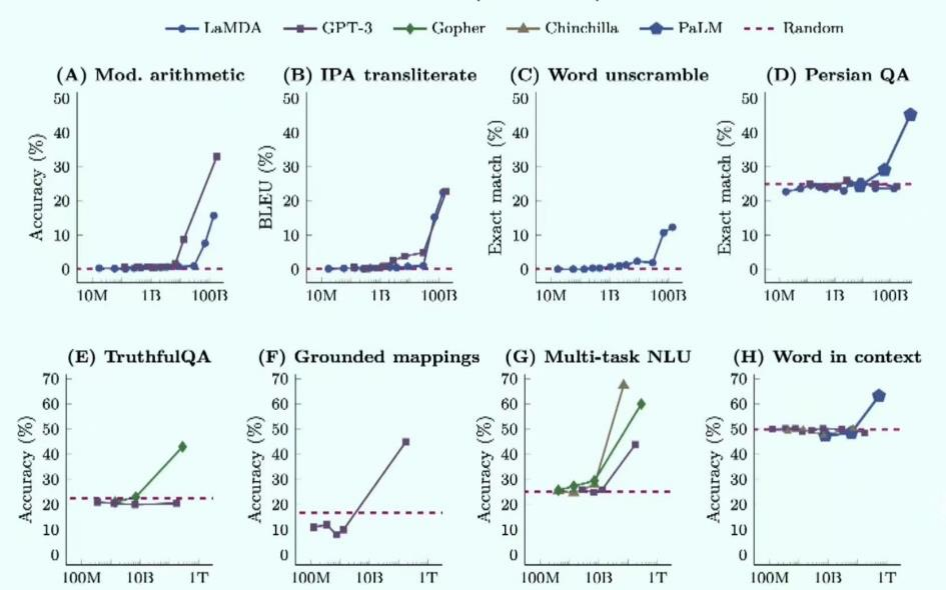
參數(shù)對大模型性能起到明顯作用
模型能力不僅取決于模型大小,還與數(shù)據(jù)規(guī)模和總計算量有關(guān)。此外,預(yù)訓(xùn)練數(shù)據(jù)質(zhì)量對于實現(xiàn)良好性能至關(guān)重要。
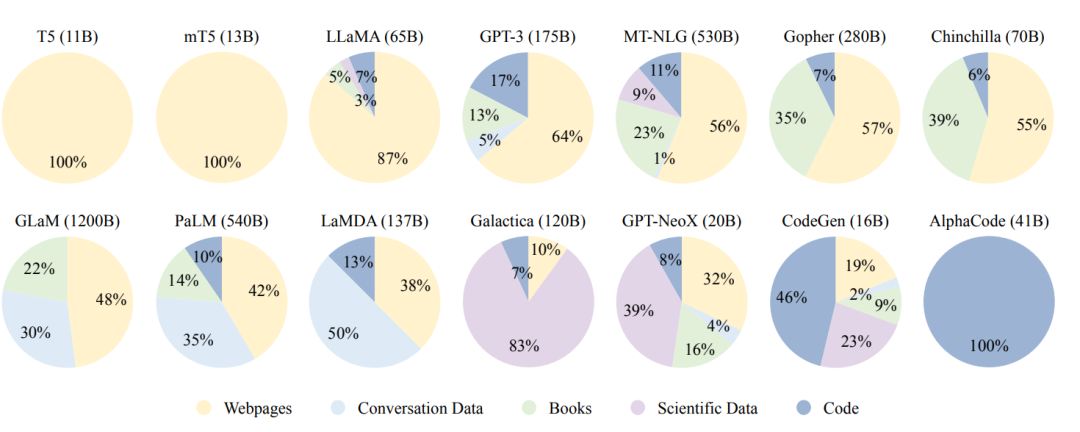
大模型主要利用各種公共文本數(shù)據(jù)集做預(yù)訓(xùn)練
預(yù)訓(xùn)練語料庫來源可以大致分為兩類:通用數(shù)據(jù)和專業(yè)數(shù)據(jù)。通用數(shù)據(jù)包括網(wǎng)頁、書籍和對話文本等,由于其規(guī)模龐大、多樣化且易于獲取,被廣泛用于大型語言模型,可以增強(qiáng)語言建模和泛化能力。專業(yè)數(shù)據(jù)則包括多語言數(shù)據(jù)、科學(xué)數(shù)據(jù)和代碼等,使得語言模型具備解決特定任務(wù)的能力。
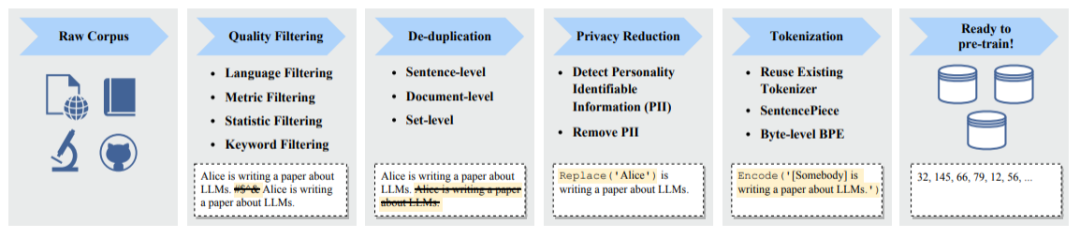
預(yù)訓(xùn)練大語言模型典型的數(shù)據(jù)處理過程
成功訓(xùn)練一個強(qiáng)大的大語言模型(LLM)是具有挑戰(zhàn)性的。為了實現(xiàn)LLM的網(wǎng)絡(luò)參數(shù)學(xué)習(xí),通常需要采用多種并行策略。一些優(yōu)化框架如Transformer、DeepSpeed和Megatron-LM已經(jīng)發(fā)布,以促進(jìn)并行算法的實現(xiàn)和部署。此外,優(yōu)化技巧對于訓(xùn)練的穩(wěn)定性和模型性能也至關(guān)重要。
目前,常用于訓(xùn)練LLM的庫包括Transformers、DeepSpeed、Megatron-LM、JAX、Colossal-AI、BMTrain和FastMoe等。此外,現(xiàn)有的深度學(xué)習(xí)框架如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore和OneFlow也提供對并行算法的支持。

二、Transformer
Transformer是由Google在2017年的論文《Attention is All You Need》中提出的,GPT和BERT都采用Transformer模型。Transformer基于顯著性的注意力機(jī)制為輸入序列中的任何位置提供上下文信息,使得它具有強(qiáng)大的全局表征能力、高度并行性、位置關(guān)聯(lián)操作不受限,通用性強(qiáng),可擴(kuò)展性強(qiáng)等優(yōu)勢,從而使得GPT模型具有優(yōu)異的表現(xiàn)。
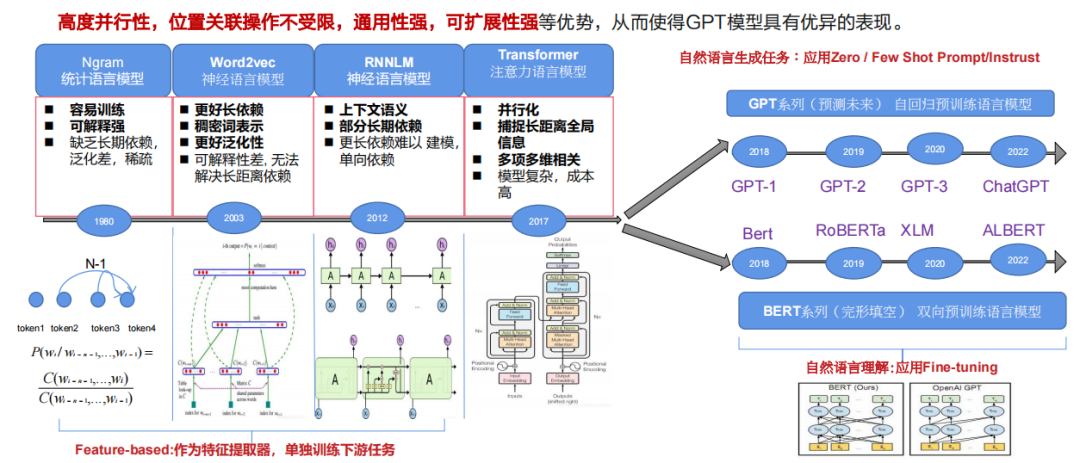
自注意力機(jī)制(Self-Attention)允許模型在處理每個詞(輸入序列中的每個位置)時,不僅關(guān)注當(dāng)前位置的詞,還能關(guān)注句子中其他位置的詞,從而更好地編碼這個詞。這種機(jī)制使得模型能夠記住單詞與哪些單詞在同一句話中共同出現(xiàn)。Transformer模型基于自注意力機(jī)制,學(xué)習(xí)單詞之間共同出現(xiàn)的概率。在輸入語料后,Transformer可以輸出單詞與單詞共同出現(xiàn)的概率,并且能夠捕捉到長距離上下文中詞與詞之間的雙向關(guān)系。
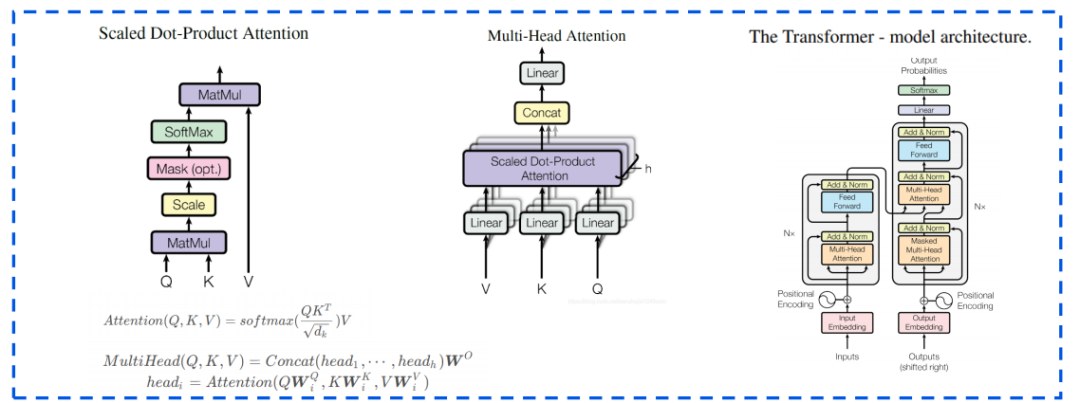
三、RLHF
RLHF(Reinforcement Learning with Human Feedback)是ChatGPT所采用的關(guān)鍵技術(shù)之一。它是強(qiáng)化學(xué)習(xí)(RL)的一個擴(kuò)展分支,將人類的反饋信息融入到訓(xùn)練過程中。通過利用這些反饋信息構(gòu)建一個獎勵模型神經(jīng)網(wǎng)絡(luò),RLHF為RL智能體提供獎勵信號,以幫助其學(xué)習(xí)。這種方法可以更加自然地將人類的需求、偏好和觀念等信息以交互式的學(xué)習(xí)方式傳達(dá)給智能體,以對齊人類和人工智能之間的優(yōu)化目標(biāo),從而產(chǎn)生與人類行為方式和價值觀一致的系統(tǒng)。
四、Prompt
"提示"是一種給予預(yù)訓(xùn)練語言模型的線索,旨在幫助其更好地理解人類的問題。通過在輸入中添加額外的文本(clue/prompt),可以更充分地利用預(yù)訓(xùn)練模型中的知識。
Prompt的案例演示
提示學(xué)習(xí)的基本流程包括四個步驟:提示構(gòu)造、答案構(gòu)造、答案預(yù)測和答案-標(biāo)簽映射。提示學(xué)習(xí)的優(yōu)勢主要體現(xiàn)在以下幾個方面:1)對預(yù)訓(xùn)練模LM的利用率高;2)小樣本場景訓(xùn)練效果提升;3)fine-tune成本大幅度下降等。
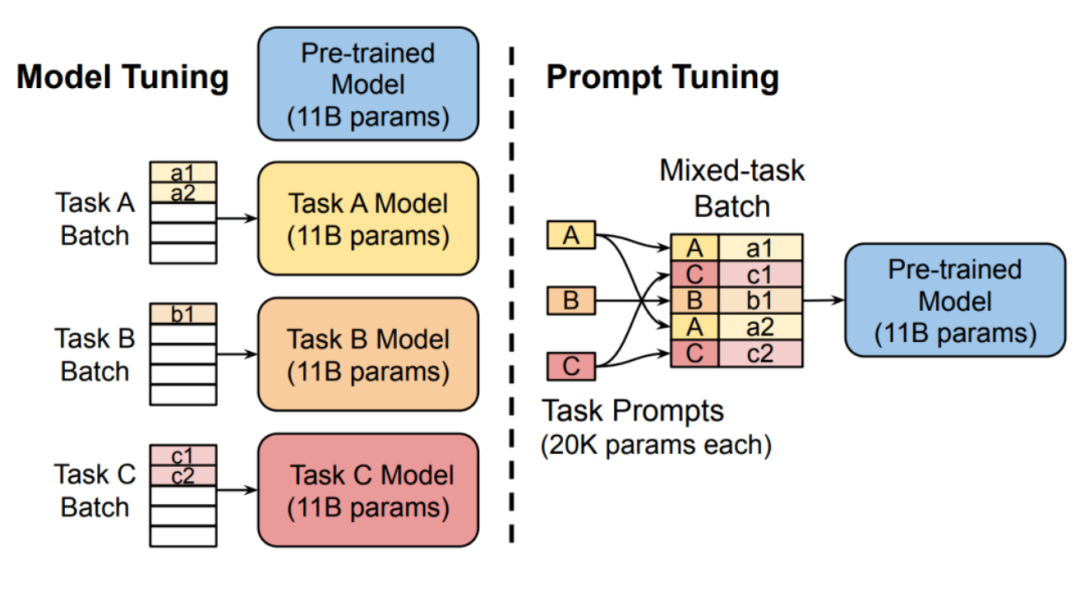
Promtptuning 與 pre-trainandfine-tune 對 比
語境學(xué)習(xí)(in-context learning, ICL)是一種特殊的提示形式,首次與GPT-3一起提出,并已成為一種典型的利用預(yù)訓(xùn)練語言模型的方法。在語境學(xué)習(xí)中,首先從任務(wù)描述中選擇一些示例作為演示。然后,將這些示例按照特定的順序組合起來,形成具有特殊設(shè)計模板的自然語言提示。最后,測試實例被添加到演示中,作為預(yù)訓(xùn)練語言模型生成輸出的輸入。基于這些任務(wù)演示,預(yù)訓(xùn)練語言模型可以在不需要顯式梯度更新的情況下識別并執(zhí)行新任務(wù)。
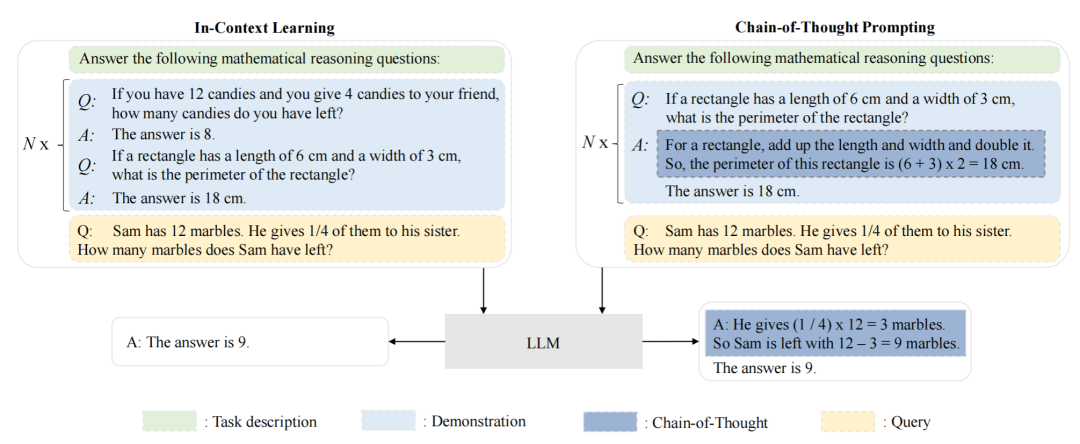
情境學(xué)習(xí) ( ICL ) 與思維鏈 ( CoT ) 提示的比較研究
五、插件
由于預(yù)訓(xùn)練語言模型(LLM)是在大量純文本語料庫上進(jìn)行訓(xùn)練,因此在非文本生成方面(如數(shù)值計算)的表現(xiàn)可能不佳。此外,LLM的能力受限于預(yù)訓(xùn)練數(shù)據(jù),無法捕捉最新信息。為了解決這些問題,ChatGPT引入了外部插件機(jī)制,以幫助ChatGPT獲取最新信息、進(jìn)行計算或使用第三方服務(wù),類似于LLM的"眼睛和耳朵",從而廣泛擴(kuò)展LLM的能力范圍。
截至2023年5月,ChatGPT進(jìn)行更新,包括網(wǎng)絡(luò)瀏覽功能和70個測試版插件。這一更新有望徹底改變ChatGPT的使用方式,涵蓋從娛樂和購物到求職和天氣預(yù)報等各個領(lǐng)域。ChatGPT建立了一個社區(qū),供插件開發(fā)者構(gòu)建ChatGPT插件,并在語言模型顯示的提示符中列出啟用的插件,并提供指導(dǎo)文檔,以指導(dǎo)模型如何使用每個插件。
ChatGPT插件部分展示
六、系統(tǒng)工程
OpenAI聯(lián)合創(chuàng)始人兼首席執(zhí)行官Sam Altman表示,GPT-4是迄今為止人類最復(fù)雜的軟件系統(tǒng)。隨著預(yù)訓(xùn)練語言模型(LLM)的發(fā)展,研發(fā)和工程之間的界限變得模糊不清。LLM的訓(xùn)練需要廣泛的大規(guī)模數(shù)據(jù)處理和分布式并行訓(xùn)練經(jīng)驗。開發(fā)LLM的研究人員必須解決復(fù)雜的工程問題,并與工程師緊密合作或成為工程師本身。
GPU為算力核心服務(wù)器為重要載體
一、服務(wù)器:AI算力的重要載體
服務(wù)器是指具備較高計算能力的計算機(jī),可以為多個用戶提供服務(wù)。與個人電腦不同,個人電腦通常只為一個用戶提供服務(wù)。服務(wù)器與主機(jī)也有所不同,主機(jī)是通過終端設(shè)備提供給用戶使用,而服務(wù)器則通過網(wǎng)絡(luò)給客戶端用戶提供服務(wù)。
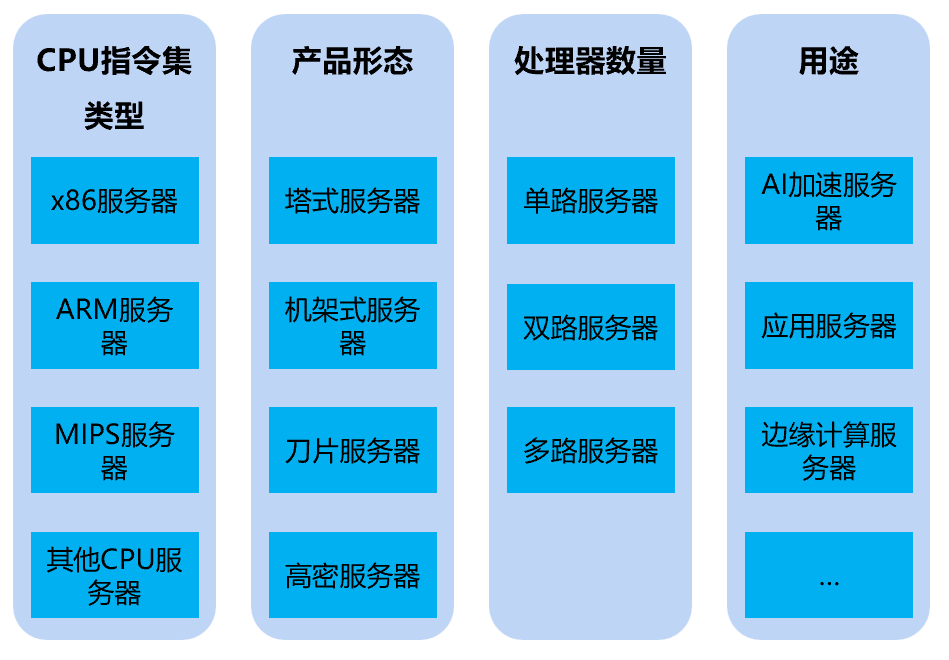
服務(wù)器的主要分類
AI服務(wù)器是專門用于進(jìn)行人工智能(AI)計算的服務(wù)器。既可以支持本地應(yīng)用程序和網(wǎng)頁,也可以為云和本地服務(wù)提供復(fù)雜的AI模型和服務(wù)。其主要作用是為各種實時AI應(yīng)用提供實時計算服務(wù)。根據(jù)應(yīng)用場景的不同,AI服務(wù)器可以分為訓(xùn)練和推理兩種類型。訓(xùn)練型服務(wù)器對芯片算力要求更高,而推理型服務(wù)器對算力的要求相對較低。

NVIDIA A100服務(wù)器
藍(lán)海大腦高性能大模型訓(xùn)練平臺利用工作流體作為中間熱量傳輸?shù)拿浇椋瑢崃坑蔁釁^(qū)傳遞到遠(yuǎn)處再進(jìn)行冷卻。支持多種硬件加速器,包括CPU、GPU、FPGA和AI等,能夠滿足大規(guī)模數(shù)據(jù)處理和復(fù)雜計算任務(wù)的需求。采用分布式計算架構(gòu),高效地處理大規(guī)模數(shù)據(jù)和復(fù)雜計算任務(wù),為深度學(xué)習(xí)、高性能計算、大模型訓(xùn)練、大型語言模型(LLM)算法的研究和開發(fā)提供強(qiáng)大的算力支持。具有高度的靈活性和可擴(kuò)展性,能夠根據(jù)不同的應(yīng)用場景和需求進(jìn)行定制化配置。可以快速部署和管理各種計算任務(wù),提高了計算資源的利用率和效率。

1、全球服務(wù)器市場
根據(jù)Counterpoint的報告,預(yù)計到2022年,全球服務(wù)器市場的收入將同比增長17%,達(dá)到1117億美元。在該市場中,主要的服務(wù)器公司包括戴爾、惠普、聯(lián)想、浪潮和超微以及ODM廠商如富士康、廣達(dá)、緯創(chuàng)和英業(yè)達(dá)。ODM Direct的增長速度比整體市場高出3個百分點,因此ODM Direct將成為大規(guī)模數(shù)據(jù)中心部署的硬件選擇。根據(jù)IDC的數(shù)據(jù)預(yù)測,2022年市場規(guī)模約為183億美元,而2023年市場規(guī)模將達(dá)到211億美元。在市場份額方面,浪潮信息占據(jù)了20.2%的份額,其次是戴爾、HPE、聯(lián)想和華為,它們的市場份額分別為13.8%、9.8%、6.1%和4.8%。
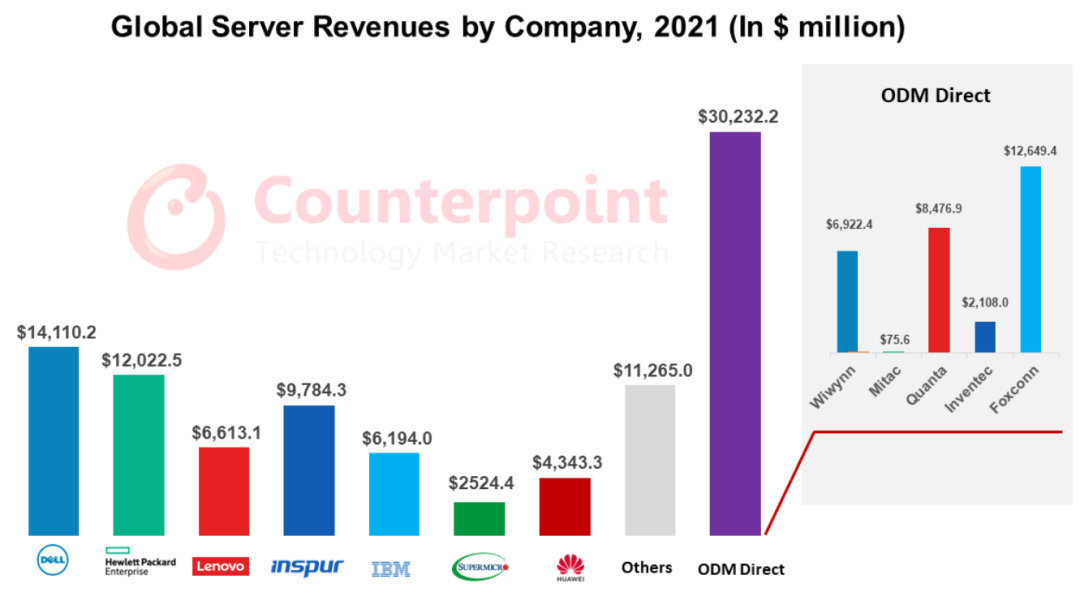
2021年全球各服務(wù)器公司收入(單位:百萬美元)
2、中國服務(wù)器市場
據(jù)數(shù)據(jù)顯示,2022年中國服務(wù)器市場規(guī)模達(dá)到273.4億美元。在這個市場中,浪潮以28.1%的市場份額位居第一,收入達(dá)到530.63億美元。根據(jù)IDC的數(shù)據(jù),2022年中國加速服務(wù)器市場規(guī)模達(dá)到67億美元,同比增長24%。浪潮、新華三和寧暢是市場中的前三名,它們占據(jù)了市場份額的60%以上。互聯(lián)網(wǎng)行業(yè)仍然是采購加速服務(wù)器的最大行業(yè),占據(jù)了整體市場接近一半的份額。
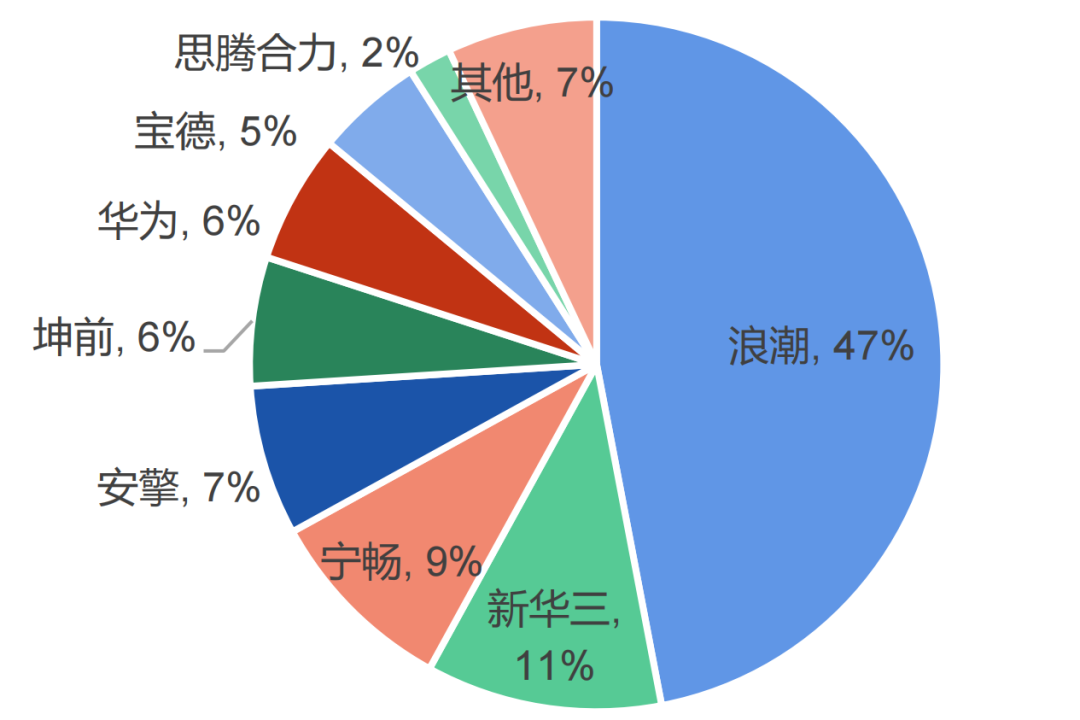
2022年中國AI服務(wù)器市場份額
二、GPU:AI算力的核心
在訓(xùn)練大型模型時,超大規(guī)模的計算能力是必不可少的,而GPU是其中的核心。沒有GPU卡,訓(xùn)練大型模型幾乎是不可能的。
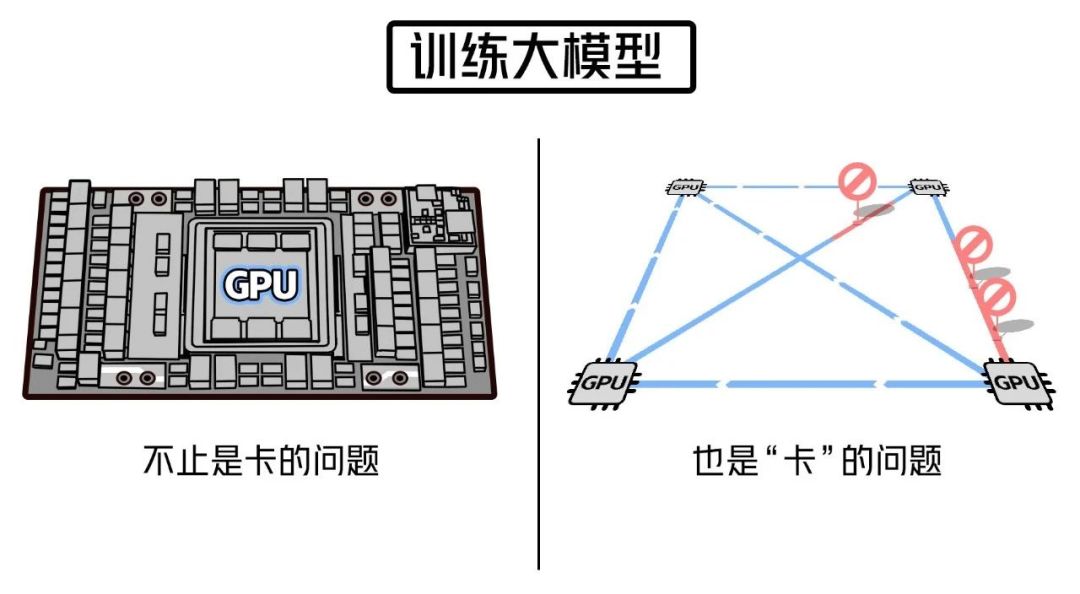
AI芯片是算力的核心也被稱為AI加速器或計算卡,專門用于處理人工智能應(yīng)用中的大量計算任務(wù)(而其他非計算任務(wù)則由CPU負(fù)責(zé))。隨著數(shù)據(jù)量的急劇增長、算法模型的復(fù)雜化以及處理對象的異構(gòu)性,對計算性能的要求也越來越高。
據(jù)數(shù)據(jù)顯示,2022年我國的AI服務(wù)器中,GPU服務(wù)器占據(jù)89%的份額。目前,GPU是最廣泛應(yīng)用的AI芯片之一。除了GPU,AI芯片還包括現(xiàn)場可編程門陣列(FPGA)、專用集成電路(ASIC)和神經(jīng)擬態(tài)芯片(NPU)等。GPU是一種通用型芯片,而ASIC是一種專用型芯片,而FPGA則處于兩者之間,具有半定制化的特點。
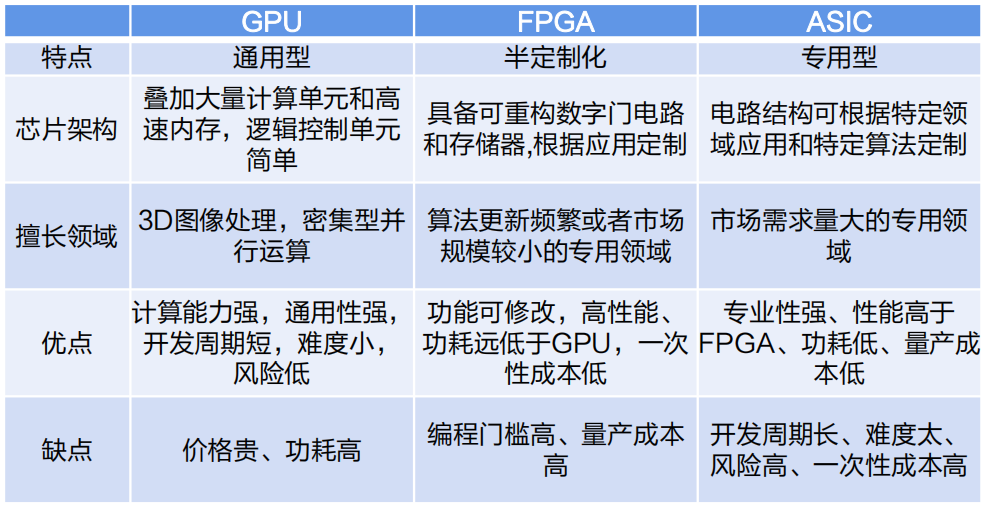
不同AI芯片之間對比
圖形處理器(GPU)是一種專門用于執(zhí)行繪圖運算的微處理器,也被稱為顯示核心、視覺處理器、顯示芯片或圖形芯片。它擁有數(shù)百或數(shù)千個內(nèi)核,并經(jīng)過優(yōu)化,能夠并行執(zhí)行大量計算任務(wù)。盡管GPU在游戲中以3D渲染而聞名,但它們在運行分析、深度學(xué)習(xí)和機(jī)器學(xué)習(xí)算法方面尤為有用。相比傳統(tǒng)的CPU,GPU可以使某些計算速度提高10倍至100倍。GPGPU是一種將GPU的圖形處理能力應(yīng)用于通用計算領(lǐng)域的處理器。
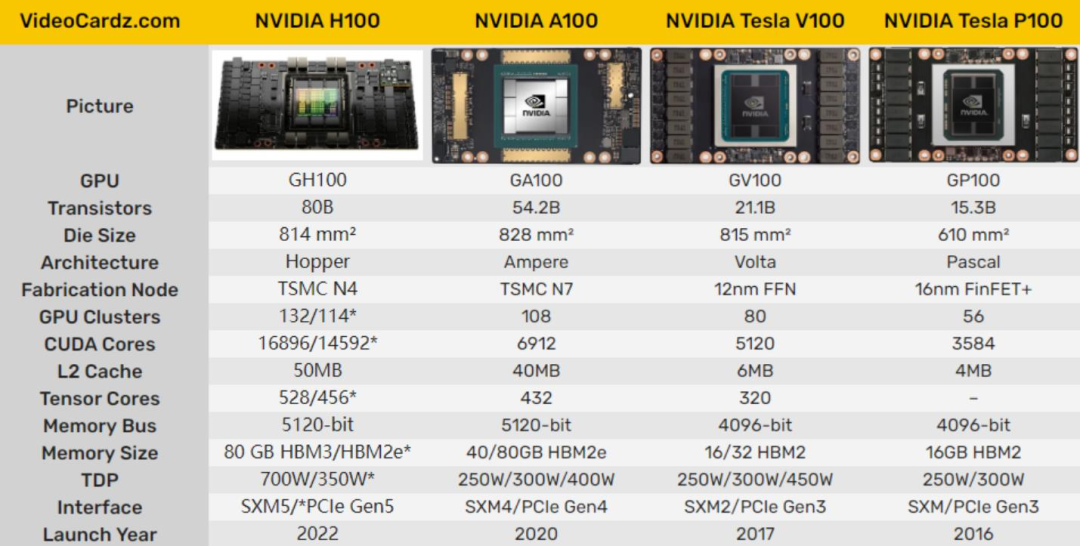
英偉達(dá)數(shù)據(jù)中心GPU類別
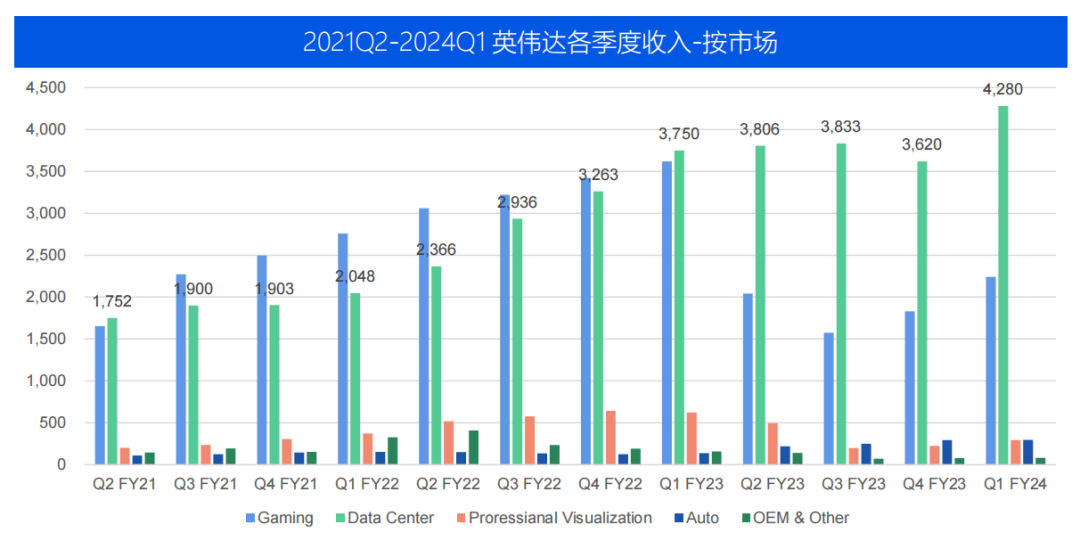
在2023年,英偉達(dá)的全球收入達(dá)到269.7億美元。其中,圖形業(yè)務(wù)部門的收入約為119億美元,而計算與網(wǎng)絡(luò)部門的收入為151億美元。在2023年第一季度(Q1 FY24),英偉達(dá)的數(shù)據(jù)中心業(yè)務(wù)營收達(dá)到42.8億美元,創(chuàng)下歷史新高,同比增長14%,環(huán)比增長18%。
三、英偉達(dá)大模型訓(xùn)練GPU全系列介紹
自O(shè)penAI發(fā)布ChatGPT以來,生成式人工智能技術(shù)一直是備受關(guān)注的熱門趨勢。這項技術(shù)需要強(qiáng)大的算力來生成文本、圖像、視頻等內(nèi)容。在這個背景下,算力成為人工智能領(lǐng)域的必備條件,而英偉達(dá)作為芯片巨頭所生產(chǎn)的人工智能芯片在其中扮演著至關(guān)重要的角色。英偉達(dá)先后推出V100、A100和H100等多款用于AI訓(xùn)練的芯片,并為了符合美國標(biāo)準(zhǔn),推出了A800和H800這兩款帶寬縮減版產(chǎn)品,在中國大陸市場銷售。
V100是英偉達(dá)公司推出的高性能計算和人工智能加速器,屬于Volta架構(gòu)系列。它采用16nm FinFET工藝,擁有5120個CUDA核心和16GB到32GB的HBM2顯存。V100還配備Tensor Cores加速器,可提供高達(dá)120倍的深度學(xué)習(xí)性能提升。此外,V100支持NVLink技術(shù),實現(xiàn)高速的GPU到GPU通信,加速大規(guī)模模型的訓(xùn)練速度。V100被廣泛應(yīng)用于各種大規(guī)模AI訓(xùn)練和推理場景,包括自然語言處理、計算機(jī)視覺和語音識別等領(lǐng)域。
A100是英偉達(dá)推出的一款強(qiáng)大的數(shù)據(jù)中心GPU,采用全新的Ampere架構(gòu)。它擁有高達(dá)6,912個CUDA核心和40GB的高速HBM2顯存。A100還包括第二代NVLink技術(shù),實現(xiàn)快速的GPU到GPU通信,提升大型模型的訓(xùn)練速度。此外,A100還支持英偉達(dá)自主研發(fā)的Tensor Cores加速器,可提供高達(dá)20倍的深度學(xué)習(xí)性能提升。A100廣泛應(yīng)用于各種大規(guī)模AI訓(xùn)練和推理場景,包括自然語言處理、計算機(jī)視覺和語音識別等領(lǐng)域。
在大模型訓(xùn)練中,V100和A100都是非常強(qiáng)大的GPU。以下是它們的主要區(qū)別和優(yōu)勢:
1、架構(gòu)
V100和A100在架構(gòu)上有所不同。V100采用Volta架構(gòu),而A100則采用全新的Ampere架構(gòu)。Ampere架構(gòu)相對于Volta架構(gòu)進(jìn)行一些改進(jìn),包括更好的能源效率和全新的Tensor Core加速器設(shè)計等,這使得A100在某些場景下可能表現(xiàn)出更出色的性能。
2、計算能力
A100配備高達(dá)6,912個CUDA核心,比V100的5120個CUDA核心更多。這意味著A100可以提供更高的每秒浮點運算數(shù)(FLOPS)和更大的吞吐量,從而在處理大型模型和數(shù)據(jù)集時提供更快的訓(xùn)練速度。
3、存儲帶寬
V100的內(nèi)存帶寬約為900 GB/s,而A100的內(nèi)存帶寬達(dá)到了更高的1555 GB/s。高速內(nèi)存帶寬可以降低數(shù)據(jù)傳輸瓶頸,提高訓(xùn)練效率,因此A100在處理大型數(shù)據(jù)集時可能表現(xiàn)更出色。
4、存儲容量
V100最高可擁有32GB的HBM2顯存,而A100最高可擁有80GB的HBM2顯存。由于大模型通常需要更多內(nèi)存來存儲參數(shù)和梯度,A100的更大內(nèi)存容量可以提供更好的性能。
5、通信性能
A100支持第三代NVLink技術(shù),實現(xiàn)高速的GPU到GPU通信,加快大模型訓(xùn)練的速度。此外,A100還引入Multi-Instance GPU (MIG)功能,可以將單個GPU劃分為多個相互獨立的實例,進(jìn)一步提高資源利用率和性能。
總的來說,A100在處理大型模型和數(shù)據(jù)集時可能比V100表現(xiàn)更優(yōu)秀,但是在實際應(yīng)用中,需要結(jié)合具體場景和需求來選擇合適的GPU。
數(shù)據(jù)中心算力瓶頸光模塊需求放量
即使單卡的性能再強(qiáng)大,如果網(wǎng)絡(luò)性能無法跟上,也只能無奈地等待。而且,隨著集群規(guī)模的擴(kuò)大,網(wǎng)絡(luò)帶來的算力損耗也會變得更加明顯。傳統(tǒng)的網(wǎng)絡(luò)架構(gòu)在傳輸數(shù)據(jù)時需要經(jīng)過多層協(xié)議棧的處理:需要反復(fù)停下來檢查、分揀和打包數(shù)據(jù),這使得通信效率非常低下。
一、英偉達(dá)布局InfiniBand
數(shù)據(jù)通信設(shè)備是指能夠?qū)崿F(xiàn)IP網(wǎng)絡(luò)接入終端、局域網(wǎng)、廣域網(wǎng)間連接、數(shù)據(jù)交換以及提供相關(guān)安全防護(hù)功能的通信設(shè)備,包括交換機(jī)、路由器和WLAN等。交換機(jī)和路由器是其中最重要的設(shè)備。這些網(wǎng)絡(luò)設(shè)備構(gòu)成了互聯(lián)網(wǎng)基礎(chǔ)的物理設(shè)施層,是信息化建設(shè)所必需的基礎(chǔ)架構(gòu)產(chǎn)品。
網(wǎng)絡(luò)設(shè)備制造服務(wù)行業(yè)的上游主要包括芯片、PCB、電源和各類電子元器件等生產(chǎn)商。直接下游是各網(wǎng)絡(luò)設(shè)備品牌商。而終端下游涵蓋了運營商、政府、金融、教育、能源、電力、交通、中小企業(yè)、醫(yī)院等各個行業(yè)。
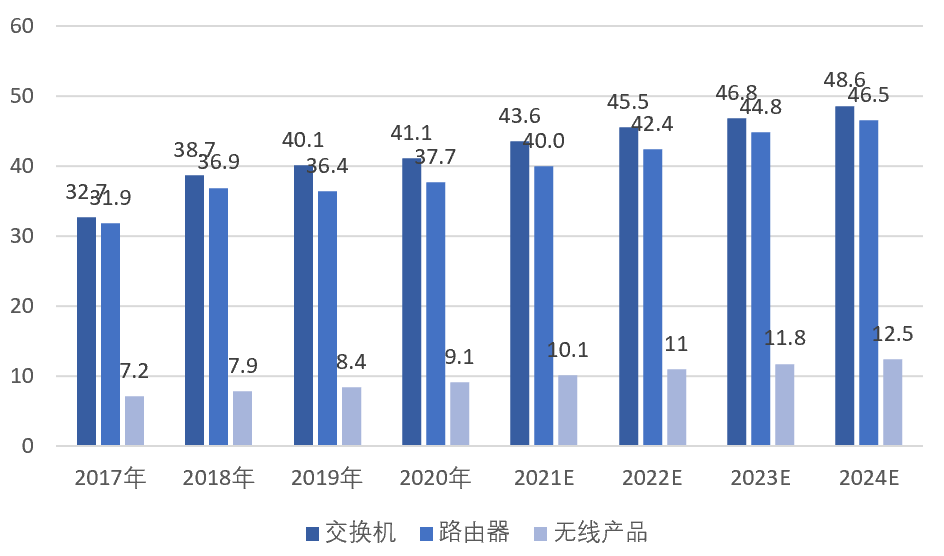
2017-2024年中國網(wǎng)絡(luò)設(shè)備市場規(guī)模統(tǒng)計(億美元)
在網(wǎng)絡(luò)設(shè)備行業(yè)中,競爭格局呈現(xiàn)出高度集中的情況。思科、華為、新華三等少數(shù)幾家企業(yè)占據(jù)絕大部分的市場份額,形成寡頭競爭的市場格局。隨著人工智能和高性能計算需求的不斷增長,對多節(jié)點、多GPU系統(tǒng)的高速通信需求也日益提升。為構(gòu)建強(qiáng)大、能夠滿足業(yè)務(wù)速度要求的端到端計算平臺,快速且可擴(kuò)展的互連網(wǎng)絡(luò)變得至關(guān)重要。
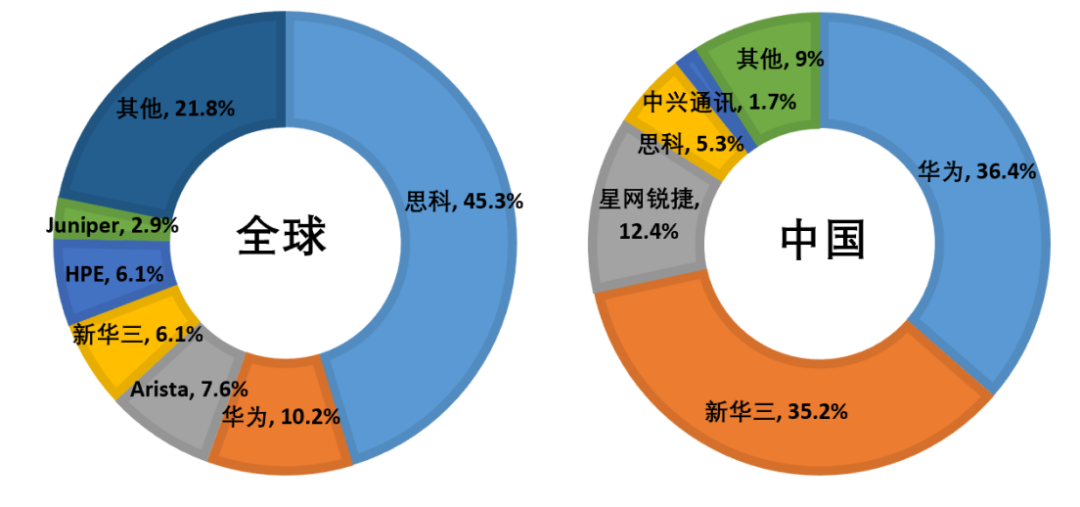
2021年全球及中國交換機(jī)行業(yè)市場份額情況
在人工智能領(lǐng)域中,通信已經(jīng)成為算力的瓶頸。盡管AI加速器可以通過簡化或刪除其他部分來提高硬件的峰值計算能力,但卻難以解決內(nèi)存和通信方面的難題。不論是芯片內(nèi)部、芯片間還是AI加速器之間的通信,都已經(jīng)成為AI訓(xùn)練過程中的限制因素。
在過去的20年中,計算設(shè)備的算力提高了90,000倍,存儲器從DDR發(fā)展到GDDR6x,接口標(biāo)準(zhǔn)從PCIe1.0a升級到NVLink3.0。然而,與此相比,通信帶寬的增長只有30倍。
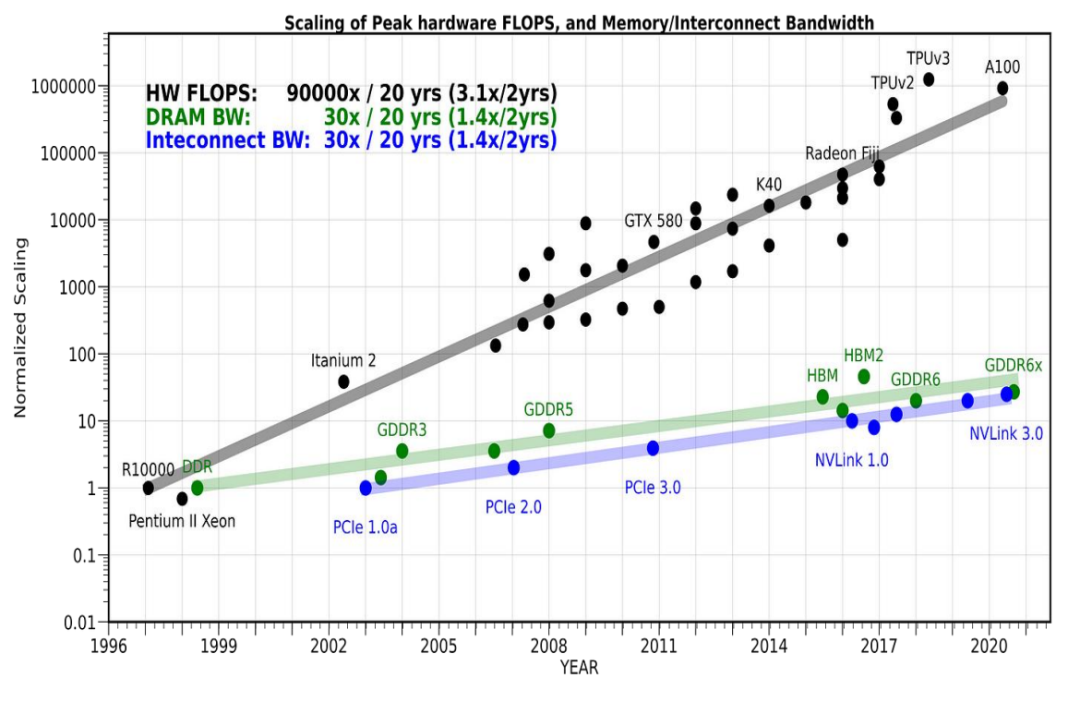
通信帶寬的提升速度遠(yuǎn)低于計算提升的速度
NVLink是NVIDIA開發(fā)的一種高帶寬、高能效、低延遲、無損的GPU到GPU互連技術(shù)。它具備彈性特性,包括鏈路級錯誤檢測和數(shù)據(jù)包回放機(jī)制,確保數(shù)據(jù)的可靠傳輸。
與上一代相比,第四代NVLink可將全局操作的帶寬提升3倍,并提高通用帶寬50%。單個NVIDIA H100 Tensor Core GPU最多支持18個NVLink連接,多GPU之間的總帶寬可達(dá)900GB/s,是PCIe 5.0的7倍。

NVLink 鏈接圖
NVSwitch是英偉達(dá)開發(fā)的一種技術(shù),包括位于節(jié)點內(nèi)部和外部的交換機(jī),用于連接多個GPU在服務(wù)器、集群和數(shù)據(jù)中心環(huán)境中的使用。每個節(jié)點內(nèi)的NVSwitch具有64個第四代NVLink鏈路端口,可以加速多個GPU之間的連接。新一代的NVSwitch技術(shù)將交換機(jī)的總吞吐量從上一代的7.2Tb/s提升到13.6Tb/s。
英偉達(dá)結(jié)合全新的NVLink和NVSwitch技術(shù),構(gòu)建了大型的NVLink Switch系統(tǒng)網(wǎng)絡(luò),實現(xiàn)了前所未有的通信帶寬水平。該系統(tǒng)最多支持256個GPU,并且互連節(jié)點能夠提供57.6TB的多對多帶寬,為高達(dá)1 exaFLOP級別的FP8稀疏計算提供了強(qiáng)大的計算能力。
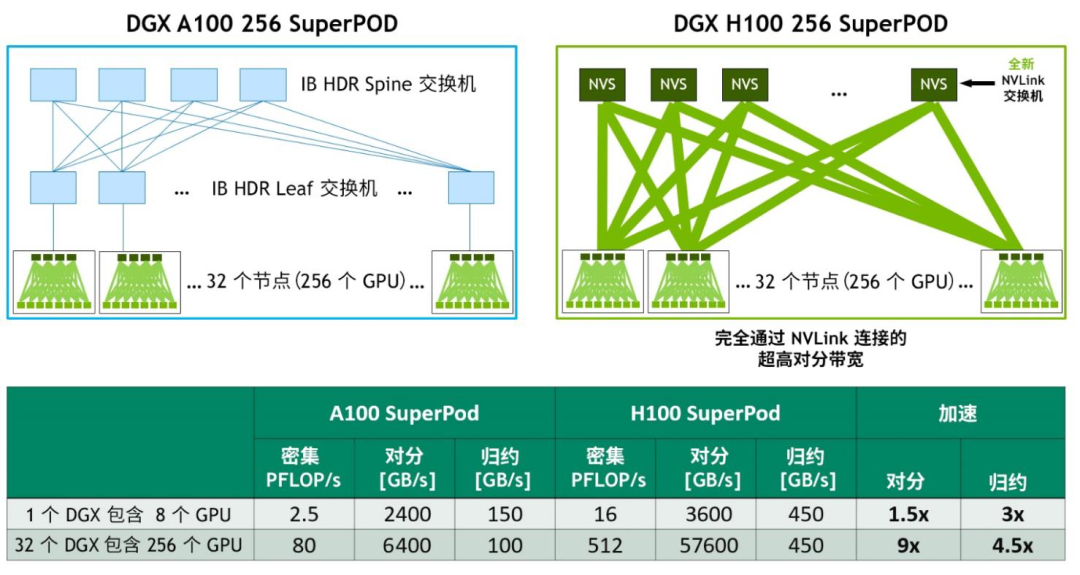
基于 DGX A100 與 DGX H100 的 32 節(jié)點、256 GPU NVIDIA SuperPOD對比
InfiniBand是一種用于高性能計算的計算機(jī)網(wǎng)絡(luò)通信標(biāo)準(zhǔn),具有高帶寬和低延遲的特點。主要應(yīng)用于高性能計算、高性能集群應(yīng)用服務(wù)器和高性能存儲等領(lǐng)域。為了加強(qiáng)在InfiniBand領(lǐng)域的投入,英偉達(dá)在2019年以69億美元收購了Mellanox。這一新架構(gòu)為AI開發(fā)者和科學(xué)研究人員提供了超強(qiáng)的網(wǎng)絡(luò)性能和豐富的功能。通過這一技術(shù),用戶可以獲得更快速、更可靠的網(wǎng)絡(luò)連接,以支持他們在人工智能領(lǐng)域的工作和研究。
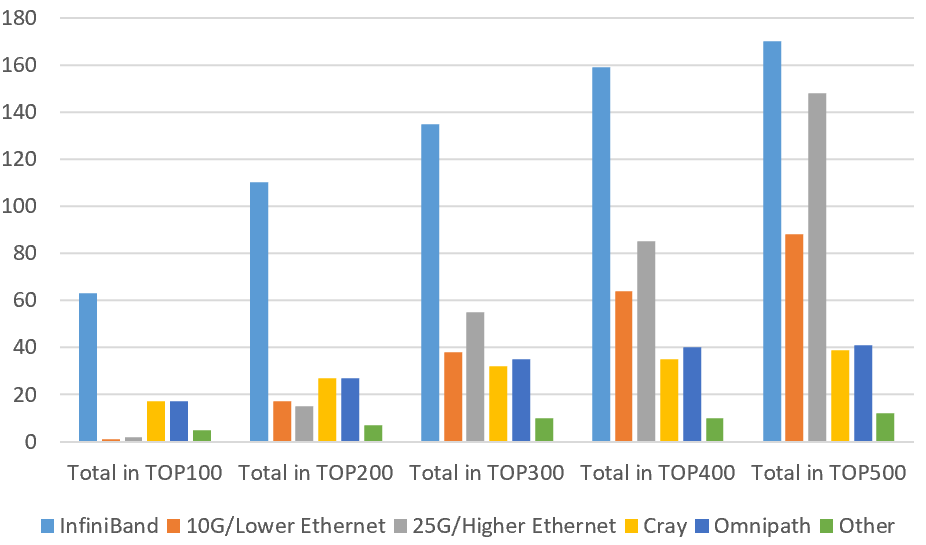
InfiniBand廣泛應(yīng)用于全球超算中心
二、光模塊:網(wǎng)絡(luò)核心器件,AI訓(xùn)練提振800G需求
預(yù)計英偉達(dá)的H100 GPU與800G光模塊在計算力網(wǎng)絡(luò)中的比例將根據(jù)不同層級而有所不同。在服務(wù)器層,預(yù)計GPU與800G光模塊的比例將為1:1;在交換機(jī)層,預(yù)計該比例將為1:2。考慮到核心層交換機(jī)、管理網(wǎng)絡(luò)、存儲網(wǎng)絡(luò)等因素,以及安裝率的相關(guān)考慮,整體而言,預(yù)計英偉達(dá)H100 GPU與800G光模塊的比例將大約在1:2至1:4之間。這種配置將確保在計算力網(wǎng)絡(luò)中實現(xiàn)高效的通信和數(shù)據(jù)傳輸。
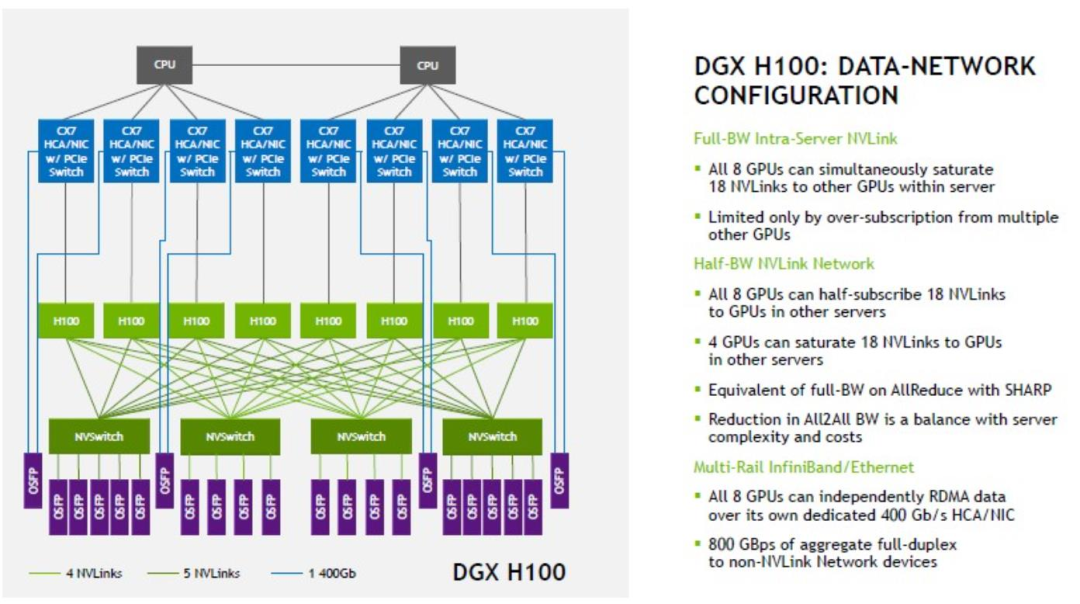
DGX H100 數(shù)據(jù)網(wǎng)絡(luò)配置圖
2023年5月,英偉達(dá)推出DGX GH200,GH200是將 256 個NVIDIA Grace Hopper超級芯片完全連接,旨在處理用于大 規(guī)模推薦系統(tǒng)、生成式人工智能和圖形分析的太字節(jié)級模型。NVLink交換系統(tǒng)采用兩級、無阻塞、胖樹結(jié)構(gòu)。如下圖:L1和L2層分為96和32臺交換機(jī),承載Grace Hopper超級芯片 的計算底板使用NVLink fabric第一層的定制線纜連接到NVLink交換機(jī)系統(tǒng)。LinkX電纜擴(kuò)展了NVLink fabric的第二層連 接。我們預(yù)計GH200的推出將進(jìn)一步促進(jìn)800G光模塊的需求增長。
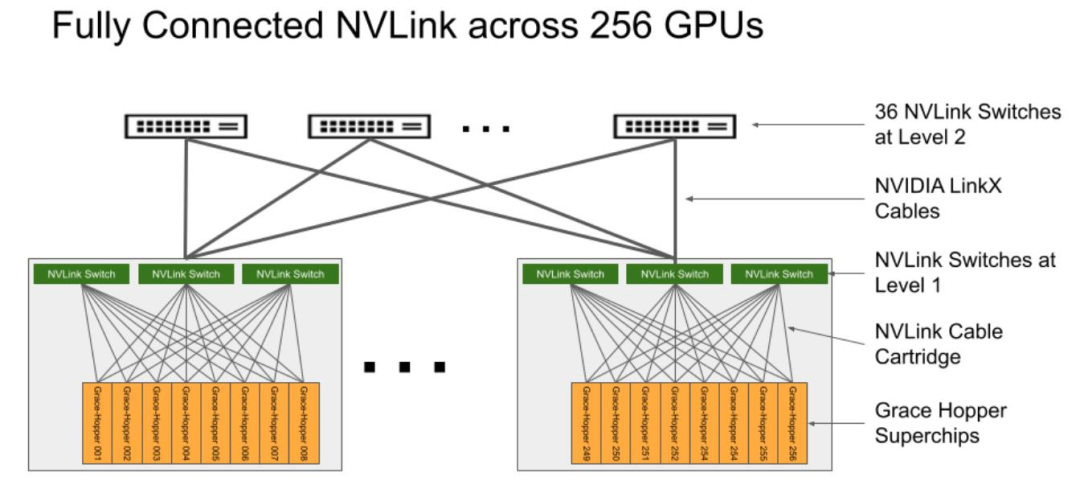
DGX GH200通過NVLink將256個GPU完全聯(lián)接
爭奪AI入場券中國大公司競逐GPU
全球范圍內(nèi),英偉達(dá)GPU的競爭非常激烈。然而,海外巨頭在GPU采購方面比較早,并且采購量更大,近年來的投資也相對連續(xù)。中國的大型公司對于GPU的需求和投資動作比海外巨頭更為急迫。以百度為例,今年向英偉達(dá)下單的GPU訂單數(shù)量高達(dá)上萬塊。盡管百度的規(guī)模要小得多,去年的營收僅為1236億元人民幣,相當(dāng)于Google的6%。然而,這顯示出中國大公司在GPU領(lǐng)域的迅速發(fā)展和巨大需求。
據(jù)了解,字節(jié)、騰訊、阿里和百度是中國投入最多的AI和云計算科技公司。在過去,它們累計擁有上萬塊A100 GPU。其中,字節(jié)擁有的A100數(shù)量最多。不計算今年的新增訂單,字節(jié)擁有接近10萬塊A100和前代產(chǎn)品V100。成長期的公司商湯也宣稱,其“AI大裝置”計算集群中已經(jīng)部署了2.7萬塊GPU,其中包括1萬塊A100。即使是看似與AI無關(guān)的量化投資公司幻方,也購買1萬塊A100。
從總數(shù)來看,這些GPU似乎足夠供各公司訓(xùn)練大型模型使用。根據(jù)英偉達(dá)官方網(wǎng)站的案例,OpenAI在訓(xùn)練具有1750億參數(shù)的GPT-3時使用了1萬塊V100,但訓(xùn)練時間未公開。根據(jù)英偉達(dá)的估算,如果使用A100來訓(xùn)練GPT-3,需要1024塊A100進(jìn)行一個月的訓(xùn)練,而A100相比V100性能提升4.3倍。
中國的大型公司過去采購的大量GPU主要用于支撐現(xiàn)有業(yè)務(wù)或在云計算平臺上銷售,不能自由地用于開發(fā)大模型或滿足客戶對大模型的需求。這也解釋了中國AI從業(yè)者對計算資源估算存在巨大差異。清華智能產(chǎn)業(yè)研究院院長張亞勤在4月底參加清華論壇時表示:“如果將中國的算力加起來,相當(dāng)于50萬塊A100,可以輕松訓(xùn)練五個模型。”
AI公司曠視科技的CEO印奇在接受《財新》采訪時表示,中國目前可用于大型模型訓(xùn)練的A100總數(shù)只有約4萬塊。這反映了中國和外國大型公司在計算資源方面的數(shù)量級差距,包括芯片、服務(wù)器和數(shù)據(jù)中心等固定資產(chǎn)投資。最早開始測試ChatGPT類產(chǎn)品的百度,在過去幾年的年度資本開支在8億到20億美元之間,阿里在60億到80億美元之間,騰訊在70億到110億美元之間。
與此同時,亞馬遜、Meta、Google和微軟這四家美國科技公司的自建數(shù)據(jù)中心的年度資本開支最低也超過150億美元。在過去三年的疫情期間,海外公司的資本開支持續(xù)增長。亞馬遜去年的資本開支已達(dá)到580億美元,Meta和Google分別為314億美元,微軟接近240億美元。而中國公司的投資在2021年后開始收縮。騰訊和百度去年的資本開支同比下降超過25%。
中國公司若想長期投入大模型并賺取更多利潤,需要持續(xù)增加GPU資源。就像OpenAI一樣,他們面臨著GPU不足的挑戰(zhàn)。OpenAI的CEO Sam Altman在與開發(fā)者交流時表示,由于GPU不夠,他們的API服務(wù)不夠穩(wěn)定,速度也不夠快。
在獲得更多GPU之前,GPT-4的多模態(tài)能力無法滿足每個用戶的需求。同樣,微軟也面臨類似的問題。微軟與OpenAI合作密切,他們的新版Bing回答速度變慢,原因是GPU供應(yīng)跟不上用戶增長的速度。
微軟Office 365 Copilot嵌入了大型模型的能力,目前還沒有大規(guī)模開放,只有600多家企業(yè)在試用。考慮到全球近3億的Office 365用戶數(shù)量,中國大公司如果想利用大型模型創(chuàng)造更多服務(wù),并支持其他客戶在云上進(jìn)行更多大型模型的訓(xùn)練,就需要提前儲備更多的GPU資源。
AI大模型訓(xùn)練常用顯卡
目前,在AI大型模型訓(xùn)練方面,A100、H100以及其特供中國市場的減配版A800、H800幾乎沒有替代品。根據(jù)量化對沖基金Khaveen Investments的測算,到2022年,英偉達(dá)在數(shù)據(jù)中心GPU市場的占有率將達(dá)到88%,而AMD和英特爾將瓜分剩下的市場份額。
英偉達(dá)GPU目前的不可替代性源于大模型的訓(xùn)練機(jī)制,其中關(guān)鍵步驟包括預(yù)訓(xùn)練和微調(diào)。預(yù)訓(xùn)練是為模型打下基礎(chǔ),相當(dāng)于接受通識教育直至大學(xué)畢業(yè);微調(diào)則是為了優(yōu)化模型以適應(yīng)具體場景和任務(wù),提升其工作表現(xiàn)。
預(yù)訓(xùn)練階段特別需要大量計算資源,對單個GPU的性能和多卡之間的數(shù)據(jù)傳輸能力有非常高的要求。目前只有A100和H100能夠提供預(yù)訓(xùn)練所需的高效計算能力,盡管價格昂貴,但實際上是最經(jīng)濟(jì)的選擇。在AI商業(yè)應(yīng)用仍處于早期階段,成本直接影響著服務(wù)的可用性。
過去的一些模型,如VGG16可以識別貓是貓,其參數(shù)量僅為1.3億,當(dāng)時一些公司會使用消費級顯卡(如RTX系列)來運行AI模型。然而,隨著GPT-3等大型模型的發(fā)布,參數(shù)規(guī)模已經(jīng)達(dá)到1750億。由于大型模型需要巨大的計算資源,使用更多低性能的GPU來組合計算力已經(jīng)不再可行。
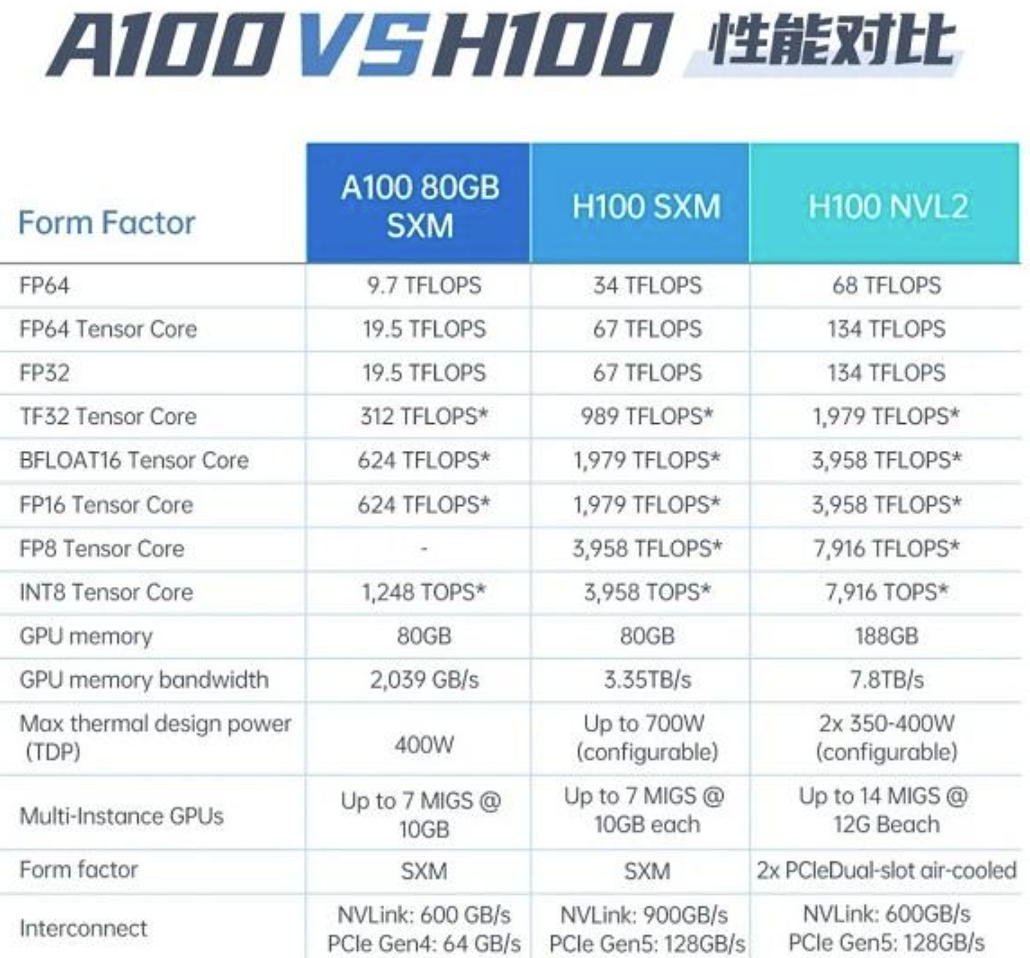
在使用多個GPU進(jìn)行訓(xùn)練時,需要在芯片之間傳輸數(shù)據(jù)并同步參數(shù)信息,這導(dǎo)致部分GPU處于閑置狀態(tài),無法充分發(fā)揮工作能力。因此,使用性能較低的GPU越多,計算力的損耗就越大。OpenAI在使用1萬塊V100 GPU進(jìn)行GPT-3訓(xùn)練時,算力利用率不到50%。而A100和H100既具有單卡高算力,又具備提升卡間數(shù)據(jù)傳輸?shù)母邘捘芰Α100的FP32算力達(dá)到19.5 TFLOPS(1 TFLOPS相當(dāng)于每秒進(jìn)行一萬億次浮點運算),而H100的FP32算力更高,達(dá)到134 TFLOPS,是競爭對手AMD MI250的約4倍。
A100、H100 還提供高效數(shù)據(jù)傳輸能力,盡可能減少算力閑置。英偉達(dá)的獨家秘籍是自 2014 年起陸續(xù)推出的 NVLink、NVSwitch 等通信協(xié)議技術(shù)。用在 H100 上的第四代 NVLink 可將同一服務(wù)器內(nèi)的 GPU 雙向通信帶寬提升至 900 GB/s(每秒傳輸 900GB 數(shù)據(jù)),是最新一代 PCle(一種點對點高速串行傳輸標(biāo)準(zhǔn))的 7 倍多。
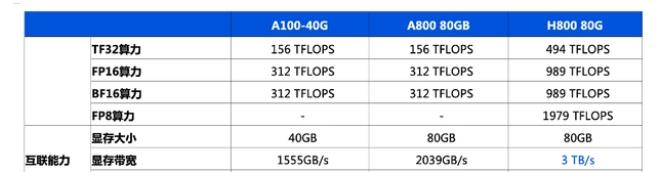
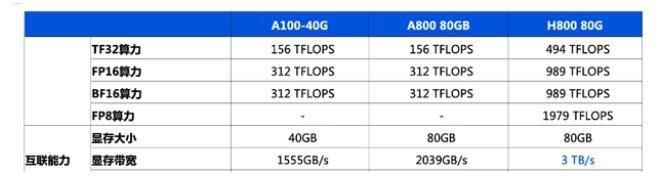
去年美國商務(wù)部對GPU的出口規(guī)定主要限制了算力和帶寬兩個方面:算力上限為4800 TOPS,帶寬上限為600 GB/s。A800和H800的算力與原版相當(dāng),但帶寬有所降低。
A800的帶寬從A100的600GB/s降至400GB/s,H800的具體參數(shù)尚未公開,據(jù)報道,它的帶寬僅為H100(900 GB/s)的約一半。執(zhí)行相同的AI任務(wù)時,H800可能比H100多花費10%至30%的時間。一位AI工程師推測,H800的訓(xùn)練效果可能不如A100,但價格更高。

大模型訓(xùn)練工作站常用配置
盡管如此,A800和H800的性能仍然超過其他大公司和創(chuàng)業(yè)公司的同類產(chǎn)品。受限于性能和更專用的架構(gòu),各公司推出的AI芯片或GPU芯片主要用于AI推理,難以勝任大型模型的預(yù)訓(xùn)練任務(wù)。簡而言之,AI訓(xùn)練是創(chuàng)建模型,而AI推理是使用模型,因此訓(xùn)練對芯片性能的要求更高。
除了性能差距外,NVIDIA的更大競爭優(yōu)勢在于其軟件生態(tài)系統(tǒng)。早在2006年,NVIDIA推出了計算平臺CUDA,它是一個并行計算軟件引擎,開發(fā)者可以使用CUDA更高效地進(jìn)行AI訓(xùn)練和推理,充分發(fā)揮GPU的計算能力。如今,CUDA已成為AI基礎(chǔ)設(shè)施的標(biāo)準(zhǔn),主流的AI框架、庫和工具都是基于CUDA進(jìn)行開發(fā)的。
而其他GPU和AI芯片如果要接入CUDA,就需要自己提供適配軟件,但它們只能獲得部分CUDA的性能,并且更新迭代的速度較慢。一些AI框架如PyTorch正在嘗試打破CUDA的軟件生態(tài)壟斷,提供更多的軟件功能以支持其他廠商的GPU,但對開發(fā)者的吸引力有限。一位AI從業(yè)者提到,他所在的公司曾考慮使用一家非NVIDIA的GPU廠商,對方的芯片和服務(wù)報價更低,也承諾提供更及時的支持,但他們最終判斷,使用其他GPU會導(dǎo)致整體訓(xùn)練和開發(fā)成本高于使用NVIDIA,并且還需要承擔(dān)結(jié)果的不確定性和花費更多的時間。“雖然A100的價格高,但實際使用起來是最經(jīng)濟(jì)的。”他說道。
對于那些有意抓住大型模型機(jī)會的大型科技公司和領(lǐng)先的創(chuàng)業(yè)公司來說,金錢通常不是問題,時間才是最寶貴的資源。在短期內(nèi),唯一可能影響NVIDIA數(shù)據(jù)中心GPU銷量的因素可能只有臺積電的產(chǎn)能。
H100/800和A100/800芯片都采用了臺積電的4納米和7納米制程。根據(jù)臺灣媒體報道,今年英偉達(dá)向臺積電增加了1萬片數(shù)據(jù)中心GPU訂單,并且下達(dá)了超急件,生產(chǎn)時間可以縮短最多50%。通常情況下,臺積電生產(chǎn)A100芯片需要數(shù)月時間。目前的生產(chǎn)瓶頸主要在于先進(jìn)封裝的產(chǎn)能不足,缺口達(dá)到了10%至20%,需要逐步提升產(chǎn)能,可能需要3至6個月的時間。
自從并行計算適用的GPU被引入深度學(xué)習(xí)領(lǐng)域以來,硬件和軟件一直是推動AI發(fā)展的動力。GPU的計算能力與模型和算法的發(fā)展相互促進(jìn):模型的發(fā)展推動了對計算能力的需求增長,而計算能力的增長則使得原本難以實現(xiàn)的大規(guī)模訓(xùn)練成為可能。在以圖像識別為代表的上一波深度學(xué)習(xí)熱潮中,中國的AI軟件能力已經(jīng)與全球最前沿水平不相上下;而目前的難點在于計算能力——設(shè)計和制造芯片需要積累更長的時間,涉及到復(fù)雜的供應(yīng)鏈和眾多的專利壁壘。
審核編輯黃宇
-
AI
+關(guān)注
關(guān)注
87文章
31711瀏覽量
270507 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3854瀏覽量
92076 -
Agi
+關(guān)注
關(guān)注
0文章
88瀏覽量
10259 -
高性能計算
+關(guān)注
關(guān)注
0文章
84瀏覽量
13448 -
大模型
+關(guān)注
關(guān)注
2文章
2603瀏覽量
3215 -
A800
+關(guān)注
關(guān)注
0文章
14瀏覽量
280 -
H800
+關(guān)注
關(guān)注
0文章
9瀏覽量
268
發(fā)布評論請先 登錄
相關(guān)推薦
英偉達(dá)a100和h100哪個強(qiáng)?英偉達(dá)A100和H100的區(qū)別
英偉達(dá)將向中國推出芯片A800可替代被禁的A100
英偉達(dá)推出A800 GPU,為了能賣給中國客戶,對A100“砍了一刀”...
英偉達(dá)確認(rèn):對華特供「低配版」A800芯片,可替代A100
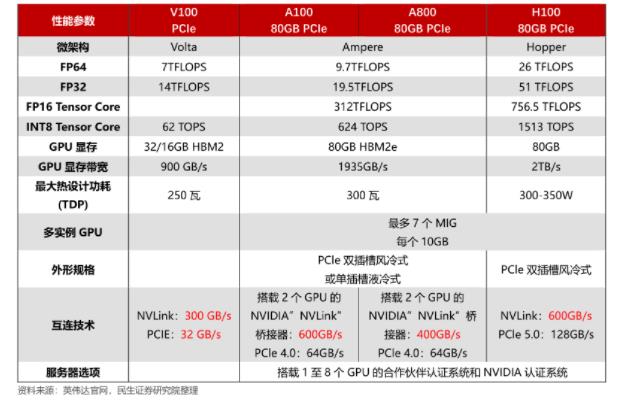
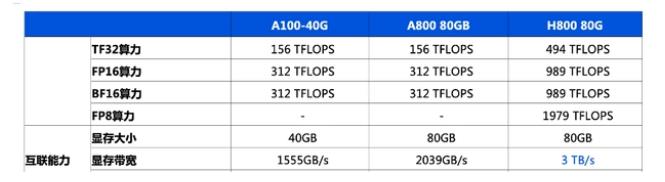
英偉達(dá)h800和a100參數(shù)對比
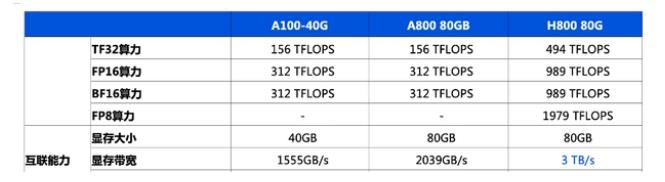
英偉達(dá)h800和a800的區(qū)別
英偉達(dá)h800和a100的區(qū)別
英偉達(dá)h800和h100的區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論