") 英偉達(dá)提出了同時(shí)對未知物體進(jìn)行6D追蹤和3D重建的方法
英偉達(dá)提出了同時(shí)對未知物體進(jìn)行6D追蹤和3D重建的方法
如今,計(jì)算機(jī)視覺社區(qū)已經(jīng)廣泛展開了對物體姿態(tài)的 6D 追蹤和 3D 重建。本文中英偉達(dá)提出了同時(shí)對未知物體進(jìn)行 6D 追蹤和 3D 重建的方法。該方法假設(shè)物體是剛體,并且需要視頻的第一幀中的 2D 物體掩碼。
除了這兩個(gè)要求之外,物體可以在整個(gè)視頻中自由移動(dòng),甚至經(jīng)歷嚴(yán)重的遮擋。英偉達(dá)的方法在目標(biāo)上與物體級 SLAM 的先前工作類似,但放松了許多常見的假設(shè),從而能夠處理遮擋、反射、缺乏視覺紋理和幾何線索以及突然的物體運(yùn)動(dòng)。
英偉達(dá)方法的關(guān)鍵在于在線姿態(tài)圖優(yōu)化過程,同時(shí)進(jìn)行神經(jīng)重建過程和一個(gè)內(nèi)存池以促進(jìn)兩個(gè)過程之間的通信。相關(guān)論文已被 CVPR 2023 會(huì)議接收。

-
論文地址:https://arxiv.org/abs/2303.14158
-
項(xiàng)目主頁:https://bundlesdf.github.io/
-
項(xiàng)目代碼:https://github.com/NVlabs/BundleSDF
本文的貢獻(xiàn)可以總結(jié)如下:
-
一種用于新穎未知?jiǎng)討B(tài)物體的因果 6 自由度姿態(tài)跟蹤和 3D 重建的新方法。該方法利用了并發(fā)跟蹤和神經(jīng)重建過程的新穎共同設(shè)計(jì),能夠在幾乎實(shí)時(shí)的在線環(huán)境中運(yùn)行,同時(shí)大大減少了跟蹤漂移。
-
引入了混合 SDF 表示來處理動(dòng)態(tài)物體為中心的環(huán)境中由于噪聲分割和交互引起的不確定自由空間的挑戰(zhàn)。
-
在三個(gè)公共基準(zhǔn)測試中進(jìn)行的實(shí)驗(yàn)顯示了本文方法與主流方法的最先進(jìn)性能。
英偉達(dá)方法的魯棒性在下圖 1 中得到了突出顯示。



與相關(guān)工作的對比
此前的 6D 物體姿態(tài)估計(jì)旨在推斷出目標(biāo)物體在相機(jī)幀中的三維平移和三維旋轉(zhuǎn)。最先進(jìn)的方法通常需要實(shí)例或類別級別的物體 CAD 模型進(jìn)行離線訓(xùn)練或在線模板匹配,這限制了它們在新穎未知物體上的應(yīng)用。盡管最近有幾項(xiàng)研究工作放寬了假設(shè)并旨在快速推廣到新穎未見的物體,但它們?nèi)匀恍枰A(yù)先捕獲測試物體的姿態(tài)參考視圖,而英偉達(dá)的設(shè)定中并不假設(shè)這一點(diǎn)。
除了單幀姿態(tài)估計(jì)之外,6D 物體姿態(tài)跟蹤利用時(shí)間信息在整個(gè)視頻中估計(jì)每幀物體姿態(tài)。與單幀姿態(tài)估計(jì)方法類似,這些方法在不同的假設(shè)條件上進(jìn)行,例如訓(xùn)練和測試使用相同的物體,或者在相同類別的物體上進(jìn)行預(yù)訓(xùn)練。
然而,與所有以往工作不同的是,英偉達(dá)的追蹤和重建協(xié)同設(shè)計(jì)采用了一種新穎的神經(jīng)表示,不僅在實(shí)驗(yàn)證實(shí)中實(shí)現(xiàn)了更強(qiáng)大的跟蹤能力,還能夠輸出額外的形狀信息。
此外,雖然 SLAM(同時(shí)定位與地圖構(gòu)建)方法解決的是與本研究類似的問題,但其專注于跟蹤相機(jī)相對于大型靜態(tài)環(huán)境的姿態(tài)。動(dòng)態(tài) SLAM 方法通常通過幀 - 模型迭代最近點(diǎn)(ICP)與顏色相結(jié)合、概率數(shù)據(jù)關(guān)聯(lián)或三維水平集似然最大化來跟蹤動(dòng)態(tài)物體。模型通過將觀察到的 RGBD 數(shù)據(jù)與新跟蹤的姿態(tài)聚合實(shí)時(shí)重建。
相比之下,英偉達(dá)的方法利用一種新穎的神經(jīng)對象場表示,允許自動(dòng)融合,同時(shí)動(dòng)態(tài)矯正歷史跟蹤的姿態(tài)以保持多視角一致性。英偉達(dá)專注于物體為中心的場景,包括動(dòng)態(tài)情景,其中常常缺乏紋理或幾何線索,并且交互主體經(jīng)常引入嚴(yán)重遮擋,這些是在傳統(tǒng) SLAM 中很少發(fā)生的困難。與物體級 SLAM 研究中研究的靜態(tài)場景相比,動(dòng)態(tài)交互還允許觀察物體的不同面以進(jìn)行更完整的三維重建。
方法概覽
英偉達(dá)方法的概述如下圖所示。給定單目 RGBD 輸入視頻以及僅在第一幀中感興趣物體的分割掩碼,該方法通過后續(xù)幀跟蹤物體的 6D 姿態(tài)并重建物體的紋理 3D 模型。所有處理都是因果的(無法訪問未來幀的信息)。英偉達(dá)假設(shè)物體是剛體,但適用于無紋理的物體。
此外不需要物體的實(shí)例級 CAD 模型,也不需要物體的類別級先驗(yàn)知識(shí)(例如事先在相同的物體類別上訓(xùn)練)。
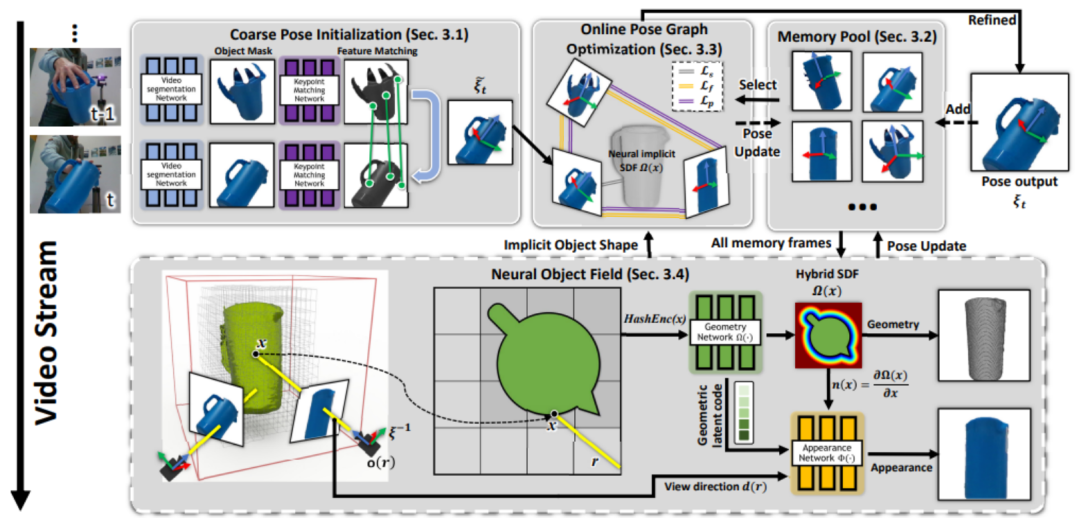
整個(gè)框架的流程可以概括為:首先在連續(xù)的分割圖像之間匹配特征,以獲得粗略的姿態(tài)估計(jì)(第 3.1 節(jié))。其中一些具有姿態(tài)的幀被存儲(chǔ)在內(nèi)存池中,以便稍后使用和優(yōu)化(第 3.2 節(jié))。從內(nèi)存池的子集動(dòng)態(tài)創(chuàng)建姿態(tài)圖(第 3.3 節(jié));在線優(yōu)化與當(dāng)前姿態(tài)一起優(yōu)化圖中的所有姿態(tài)。
然后,這些更新的姿態(tài)被存儲(chǔ)回內(nèi)存池中。最后,內(nèi)存池中的所有具有姿態(tài)的幀用于學(xué)習(xí)基于 SDF 表示的神經(jīng)物體場(在單獨(dú)并行的線程中),該對象場建模物體的幾何和視覺紋理(第 3.4 節(jié)),同時(shí)調(diào)整它們先前估計(jì)的姿態(tài),以魯棒化 6D 物體姿態(tài)跟蹤。
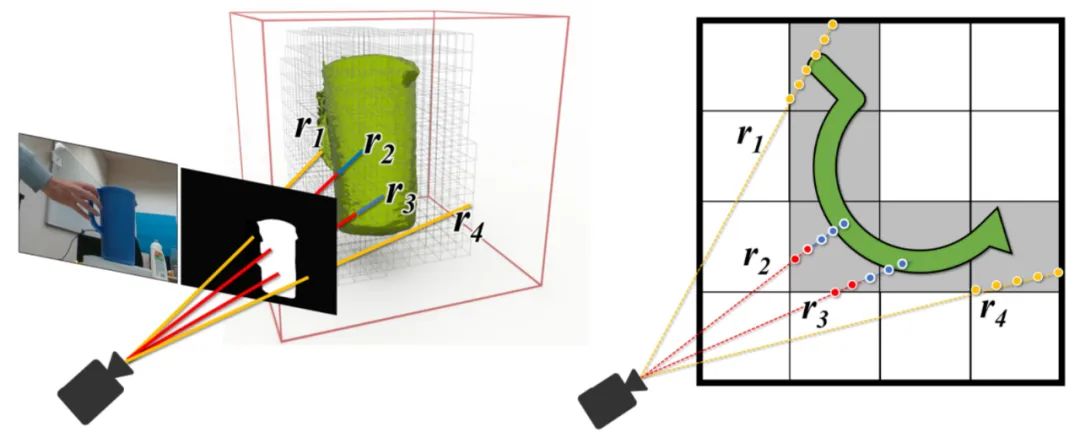
在這項(xiàng)工作中,一個(gè)獨(dú)特的挑戰(zhàn)在于交互者引入的嚴(yán)重遮擋,導(dǎo)致了多視幾何不再一致。并且完美的物體分割掩碼通常無法得到。為此,英偉達(dá)進(jìn)行了獨(dú)特的建模以增加魯棒性。
下面左圖:使用視頻分割網(wǎng)絡(luò)(第 3.1 節(jié))預(yù)測的二值掩碼進(jìn)行高效的射線追蹤的 Octree 體素表示,該物體分割掩碼由于來自神經(jīng)網(wǎng)絡(luò)的預(yù)測難免存在錯(cuò)誤。射線可以落在掩碼內(nèi)部(顯示為紅色)或外部(黃色)。右圖:神經(jīng)體積的 2D 俯視示意圖,以及沿著射線進(jìn)行的混合 SDF 建模的點(diǎn)采樣。藍(lán)色樣本接近表面。
實(shí)驗(yàn)和結(jié)果
數(shù)據(jù)集:英偉達(dá)考慮了三個(gè)具有截然不同的交互形式和動(dòng)態(tài)場景的真實(shí)世界數(shù)據(jù)集。有關(guān)野外應(yīng)用和靜態(tài)場景的結(jié)果,請參閱項(xiàng)目頁面。
-
HO3D:該數(shù)據(jù)集包含了人手與 YCB 物體交互的 RGBD 視頻,由近距離捕捉的 Intel RealSense 相機(jī)進(jìn)行拍攝。
-
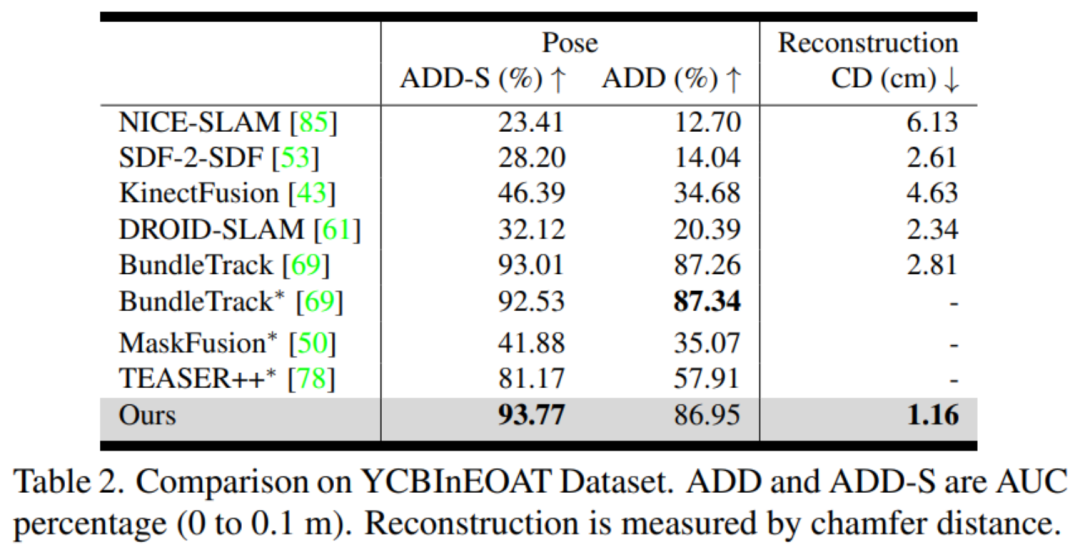
YCBInEOAT:該數(shù)據(jù)集包含了雙臂機(jī)器人操作 YCB 物體的第一視角的 RGBD 視頻,由中距離捕捉的 Azure Kinect 相機(jī)進(jìn)行拍攝。操作類型包括:(1)單臂拾取和放置,(2)手內(nèi)操作,以及(3)雙臂之間的拾取和交接。
-
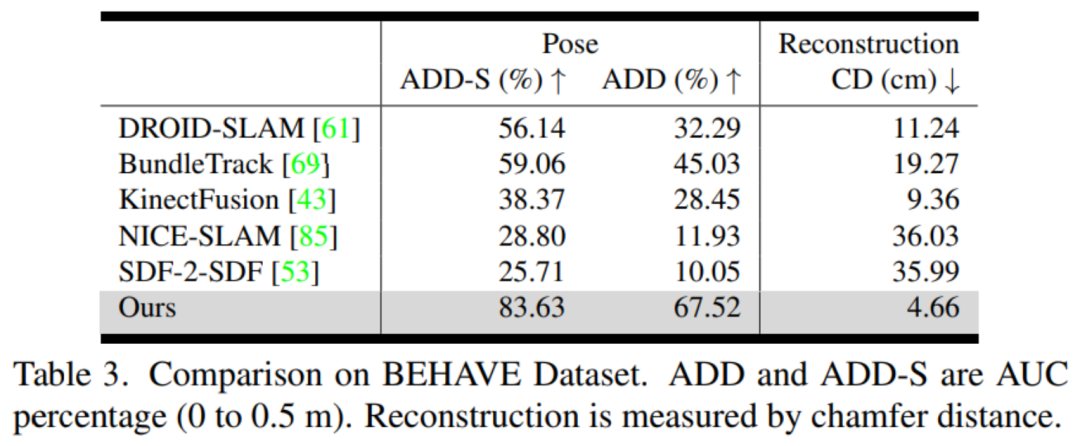
BEHAVE:該數(shù)據(jù)集包含人體與物體交互的 RGBD 視頻,由 Azure Kinect 相機(jī)的預(yù)校準(zhǔn)多視圖系統(tǒng)遠(yuǎn)距離捕捉。然而,我們將評估限制在單視圖設(shè)置下,該設(shè)置經(jīng)常發(fā)生嚴(yán)重遮擋。
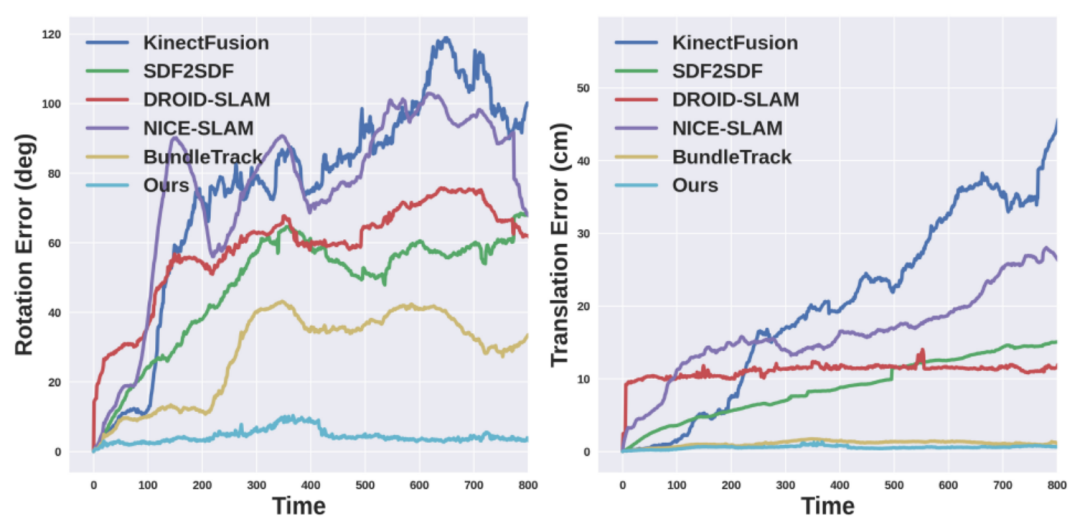
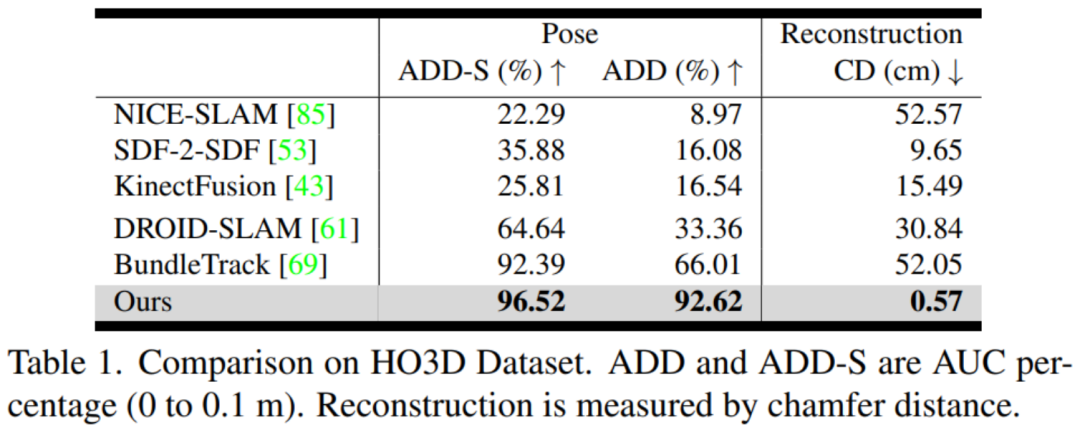
評估指標(biāo):英偉達(dá)分別評估姿態(tài)估計(jì)和形狀重建。對于 6D 物體姿態(tài),他們使用物體幾何來計(jì)算 ADD 和 ADD-S 指標(biāo)的曲線下面積(AUC)百分比。對于 3D 形狀重建,英偉達(dá)計(jì)算最終重建網(wǎng)格與地面真實(shí)網(wǎng)格之間在每個(gè)視頻的第一幀定義的規(guī)范坐標(biāo)系中的 Chamfer 距離。
對比方法:英偉達(dá)使用官方的開源實(shí)現(xiàn)和最佳調(diào)整參數(shù)與 DROID-SLAM (RGBD) [61]、NICE-SLAM [85]、KinectFusion [43]、BundleTrack [69] 和 SDF-2-SDF [53] 進(jìn)行比較。此外還包括它們在排行榜上的基準(zhǔn)結(jié)果。

團(tuán)隊(duì)介紹
該論文來自于英偉達(dá)研究院。其中論文一作是華人溫伯文,博士畢業(yè)于羅格斯大學(xué)計(jì)算機(jī)系。曾在谷歌 X,F(xiàn)acebook Reality Labs, 亞馬遜和商湯實(shí)習(xí)。研究方向?yàn)闄C(jī)器人感知和 3D 視覺。

-
3D
+關(guān)注
關(guān)注
9文章
2955瀏覽量
110161 -
通信
+關(guān)注
關(guān)注
18文章
6184瀏覽量
137483 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3927瀏覽量
93268
原文標(biāo)題:對未知物體進(jìn)行6D追蹤和3D重建,英偉達(dá)方法取得新SOTA,入選CVPR 2023
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于空間3D圓擬合圓孔參數(shù)測量
3D掃描的結(jié)構(gòu)光
LIS2DE12TR如何在4D/6D模式下運(yùn)行
PYNQ框架下如何快速完成3D數(shù)據(jù)重建
使用結(jié)構(gòu)光的3D掃描介紹
3D掃描到底是如何進(jìn)行的?
視覺處理,2d照片轉(zhuǎn)3d模型
一種基于深度神經(jīng)網(wǎng)絡(luò)的迭代6D姿態(tài)匹配的新方法
英偉達(dá)再出新研究成果 可以渲染合成交互式3D環(huán)境的AI技術(shù)
3D的感知技術(shù)及實(shí)踐

無需實(shí)例或類級別3D模型的對新穎物體的6D姿態(tài)追蹤
英偉達(dá)新方法入選CVPR 2023:對未知物體的6D姿態(tài)追蹤和三維重建
基于未知物體進(jìn)行6D追蹤和3D重建的方法

基于3D形狀重建網(wǎng)絡(luò)的機(jī)器人抓取規(guī)劃方法
使用Python從2D圖像進(jìn)行3D重建過程詳解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論