") 如何有效地監(jiān)控生產(chǎn)中的機器學習模型
如何有效地監(jiān)控生產(chǎn)中的機器學習模型

機器學習模型越來越多地用于做出重要的現(xiàn)實決策,從識別欺詐行為到在汽車中應用自動剎車。
一旦將模型部署到生產(chǎn)中,機器學習從業(yè)者的工作就遠遠沒有結束。您必須監(jiān)控您的模型,以確保它們在面對真實世界活動時繼續(xù)按預期執(zhí)行。然而,像使用傳統(tǒng)軟件那樣監(jiān)控機器學習系統(tǒng)是不夠的。
那么,如何有效地監(jiān)控生產(chǎn)中的機器學習模型?需要監(jiān)控哪些具體指標?哪些工具最有效?這篇文章將回答機器學習從業(yè)者的這些關鍵問題。
監(jiān)控機器學習模型的重要性
在機器學習的上下文中,監(jiān)控是指跟蹤已部署模型的行為以分析性能的過程。部署后監(jiān)控機器學習模型至關重要,因為模型在生產(chǎn)中可能會損壞和降級。部署不是一次性的行動,你會做而忘記。
為了確定在生產(chǎn)中更新模型的正確時間,必須有一個實時視圖,使利益相關者能夠不斷評估模型在實時環(huán)境中的性能。這有助于確保模型按預期運行。需要盡可能多地了解已部署的模型,以便在問題和源造成負面業(yè)務影響之前發(fā)現(xiàn)它們。
提高知名度聽起來很簡單,但事實并非如此。監(jiān)控機器學習模型是一項艱巨的任務。下一節(jié)將更深入地探討監(jiān)控機器學習模型的挑戰(zhàn)。
為什么機器學習系統(tǒng)監(jiān)控很難?
軟件開發(fā)人員多年來一直在將傳統(tǒng)軟件投入生產(chǎn),因此,評估使用機器學習模型進行同樣操作的難度是一個很好的起點。
必須承認,在生產(chǎn)中討論機器學習模型類似于討論機器學習系統(tǒng)。機器學習系統(tǒng)具有傳統(tǒng)軟件的挑戰(zhàn)和機器學習特有的幾個挑戰(zhàn)。要了解有關這些挑戰(zhàn)的更多信息,請參閱 Hidden Technical Debt in Machine Learning Systems 。
機器學習系統(tǒng)行為
在構建機器學習系統(tǒng)時,從業(yè)者主要熱衷于跟蹤系統(tǒng)的行為。三個組件決定系統(tǒng)的行為:
數(shù)據(jù)(特定于 ML ) :機器學習系統(tǒng)的行為取決于模型所基于的數(shù)據(jù)集,以及在生產(chǎn)過程中流入系統(tǒng)的數(shù)據(jù)。
模型(特定于 ML ) :該模型是基于數(shù)據(jù)訓練的機器學習算法的輸出。它代表了算法學習到的內(nèi)容。最好將模型視為一個管道,因為它通常由協(xié)調(diào)數(shù)據(jù)流入模型和從模型輸出的所有步驟組成。
The code :需要代碼來構建機器學習管道并定義模型配置以訓練、測試和評估模型。
正如 Christopher Samiullah 在 Deployment of Machine Learning Models 中所說,“如果沒有理解和跟蹤這些數(shù)據(jù)(以及模型)變化的方法,你就無法理解你的系統(tǒng)。”
代碼、模型和數(shù)據(jù)中指定的規(guī)則會影響整個系統(tǒng)的行為。回想一下,數(shù)據(jù)來自一個永不停息的來源——“真實世界”——它是不斷變化的,因此它是不可預測的。
機器學習系統(tǒng)面臨的挑戰(zhàn)
在構建機器學習系統(tǒng)時,這并不像說“我們有兩個額外的維度”那么簡單。由于以下挑戰(zhàn),代碼和配置給機器學習系統(tǒng)帶來了更多的復雜性和敏感性:
Entanglements :輸入數(shù)據(jù)分布的任何變化都會影響目標函數(shù)的近似值,這可能會影響模型所做的預測。換句話說,改變?nèi)魏问虑槎紩淖円磺小R虼耍仨氉屑殰y試任何功能工程和選擇代碼。
Configurations :模型配置中的缺陷(例如,超參數(shù)、版本和功能)可以從根本上改變系統(tǒng)的行為,傳統(tǒng)的軟件測試無法捕捉到。換句話說,機器學習系統(tǒng)可以預測不正確但有效的輸出,而不會引發(fā)異常。
與傳統(tǒng)軟件系統(tǒng)相比,這些因素使監(jiān)控機器學習系統(tǒng)變得極其困難,而傳統(tǒng)軟件系統(tǒng)受代碼中規(guī)定的規(guī)則控制。另一個需要考慮的因素是參與開發(fā)機器學習系統(tǒng)的利益相關者的數(shù)量。這被稱為 responsibility challenge 。
責任挑戰(zhàn)
通常,讓多個利益相關者參與一個項目可能會非常有益。每個利益相關者都可以根據(jù)他們的專業(yè)知識深入了解需求和約束,使團隊能夠減少和發(fā)現(xiàn)項目風險。
然而,基于業(yè)務領域和職責,每個利益相關者可能對“監(jiān)控”的含義有完全不同的理解。數(shù)據(jù)科學家和工程師之間的區(qū)別就是一個例子。
數(shù)據(jù)科學家的觀點
數(shù)據(jù)科學家最關心的是實現(xiàn)功能目標,例如輸入數(shù)據(jù)、模型的變化以及模型所做的預測。監(jiān)控功能目標需要對傳遞到模型中的數(shù)據(jù)、模型本身的度量以及對模型所做預測的了解。
數(shù)據(jù)科學家可能更關心模型在生產(chǎn)環(huán)境中的準確性。為了獲得這樣的洞察力,最好能實時獲得真正的標簽,這只是有時的情況。因此,數(shù)據(jù)科學家經(jīng)常使用代理值來獲得其模型的可見性。
工程師的觀點
另一方面,工程師通常負責實現(xiàn)操作目標,以確保機器學習系統(tǒng)的資源是健康的。這需要監(jiān)控傳統(tǒng)軟件應用程序度量,這在傳統(tǒng)軟件開發(fā)中是典型的。示例包括:
延遲
IO /內(nèi)存/磁盤使用
系統(tǒng)可靠性(正常運行時間)
可聽性
盡管利益相關者的目標和責任存在差異,但對機器學習系統(tǒng)的充分監(jiān)控考慮到了這兩個角度。然而,仍然需要全方位的良好理解。為了實現(xiàn)這一成就,所有利益相關者聚集在一起,確保條款明確,以便所有團隊成員使用相同的語言仍然至關重要。
生產(chǎn)中需要監(jiān)控哪些內(nèi)容?
監(jiān)測分為兩個級別:功能性和操作性。
功能級別監(jiān)控
在功能層面,數(shù)據(jù)科學家(或/和機器學習工程師)將監(jiān)控三個不同的類別:輸入數(shù)據(jù)、模型和輸出預測。監(jiān)測每一個類別可以讓數(shù)據(jù)科學家更好地了解模型的性能。
輸入數(shù)據(jù)
模型取決于作為輸入接收的數(shù)據(jù)。如果模型接收到它不期望的輸入,則模型可能會崩潰。監(jiān)控輸入數(shù)據(jù)是檢測功能性能問題并在其影響機器學習系統(tǒng)性能之前消除這些問題的第一步。從輸入數(shù)據(jù)角度監(jiān)控的項目包括:
Data quality :為了維護數(shù)據(jù)完整性,您必須在生產(chǎn)數(shù)據(jù)看到機器學習模型之前驗證它,使用基于數(shù)據(jù)財產(chǎn)的度量。換句話說,確保數(shù)據(jù)類型是等效的。有幾個因素可能會影響您的數(shù)據(jù)完整性;例如源數(shù)據(jù)模式的改變或數(shù)據(jù)丟失。這些問題改變了數(shù)據(jù)管道,使得模型不再接收預期的輸入。
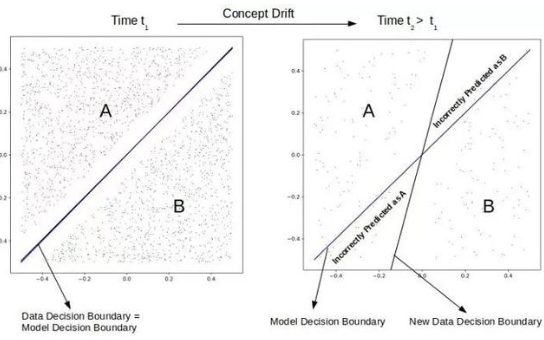
Data drift :可以監(jiān)測訓練數(shù)據(jù)和生產(chǎn)數(shù)據(jù)之間分布的變化,以檢查漂移:這是通過檢測特征值的統(tǒng)計財產(chǎn)隨時間的變化來實現(xiàn)的。數(shù)據(jù)來自一個永不停止、不斷變化的來源,稱為真實世界。隨著人們的行為發(fā)生變化,您正在解決的業(yè)務案例周圍的環(huán)境和環(huán)境可能會發(fā)生變化。此時,是時候更新機器學習模型了。
模型
機器學習系統(tǒng)的核心是機器學習模型。為了使系統(tǒng)驅動業(yè)務價值,模型必須保持高于閾值的性能水平。為了實現(xiàn)這一目標,必須監(jiān)控可能影響模型性能的各個方面,例如模型漂移和版本。
Model drift :模型漂移是由于真實環(huán)境的變化而導致的模型預測能力的衰減。應使用統(tǒng)計測試來檢測漂移,并監(jiān)測預測性能,以評估模型隨時間的性能。
Versions :始終確保正確的型號在生產(chǎn)中運行。應跟蹤版本歷史和預測。
輸出
要了解模型的性能,還必須了解模型在生產(chǎn)環(huán)境中輸出的預測。機器學習模型被投入生產(chǎn)以解決問題。因此,監(jiān)控模型的輸出是確保其根據(jù)用作 KPI 的指標執(zhí)行的一種有價值的方法。例如:
Ground truth: 對于某些問題,您可以獲取地面真相標簽。例如,如果使用一個模型向用戶推薦個性化廣告(您預測用戶是否會點擊該廣告),并且用戶點擊以暗示該廣告是相關的,那么您幾乎可以立即獲得基本事實。在這種情況下,可以根據(jù)實際解決方案評估模型預測的聚合,以確定模型的性能。然而,在大多數(shù)機器學習用例中,根據(jù)地面真相標簽評估模型預測是困難的,需要一種替代方法。
Prediction drift: 當無法獲取地面真相標簽時,必須監(jiān)控預測。如果預測的分布發(fā)生了劇烈變化,那么就有可能出了問題。例如,如果你正在使用一個模型來預測信用卡欺詐交易,而被認定為欺詐的交易比例突然上升,那么情況就發(fā)生了變化。也許輸入數(shù)據(jù)結構已經(jīng)改變,系統(tǒng)中的其他一些微服務行為不當,或者世界上有更多的欺詐行為。
操作級別監(jiān)控
在操作層面,操作工程師關心的是確保機器學習系統(tǒng)的資源是健康的。當資源不健康時,工程師負責采取行動。他們還將監(jiān)控三個類別的機器學習應用程序:系統(tǒng)、管道和成本。
ML 系統(tǒng)性能
其思想是不斷了解機器學習模型如何與整個應用程序堆棧一致。這個領域的問題將影響整個系統(tǒng)。能夠深入了解模型性能的系統(tǒng)性能指標包括:
內(nèi)存使用
延遲
管道
應該監(jiān)控兩個關鍵管道:數(shù)據(jù)管道和模型管道。未能監(jiān)控數(shù)據(jù)管道可能會引發(fā)數(shù)據(jù)質(zhì)量問題,導致系統(tǒng)崩潰。關于模型,您希望跟蹤和監(jiān)視可能導致模型在生產(chǎn)中失敗的因素,例如模型依賴關系。
成本
從數(shù)據(jù)存儲到模型訓練等等,機器學習涉及到財務成本。雖然機器學習系統(tǒng)可以為企業(yè)創(chuàng)造大量價值,但也有可能利用機器學習變得極其昂貴。不斷監(jiān)控機器學習應用程序的成本是確保成本保持的一個負責任的步驟。
例如,您可以使用 AWS 或 GCP 等云供應商設置預算,因為他們的服務跟蹤您的賬單和支出。當預算達到上限時,云提供商將發(fā)送警報通知團隊。
如果您在本地托管機器學習應用程序,監(jiān)控系統(tǒng)使用情況和成本可以更好地了解應用程序的哪個組件成本最高,以及您是否可以做出某些妥協(xié)以降低成本。
用于監(jiān)控機器學習模型的工具
現(xiàn)在開始機器學習模型監(jiān)控比以往任何時候都容易。一些企業(yè)已經(jīng)開發(fā)了一些工具來簡化生產(chǎn)中監(jiān)控機器學習系統(tǒng)的過程。無需重新安裝車輪。
用于監(jiān)視系統(tǒng)的工具取決于要監(jiān)視的特定項目。在最終決定之前,值得瀏覽一下,以找到最適合您的產(chǎn)品。下面列出了一些您可能希望開始的解決方案。
普羅米修斯和格拉法納
Prometheus 是一個用于事件監(jiān)視和警報的開源系統(tǒng)。它的工作原理是從插入指令的作業(yè)中抓取實時度量,并將抓取的樣本作為時間序列數(shù)據(jù)存儲在本地。
Grafana 是一個開源分析和交互式可視化 web 應用程序,可與 Prometheus 合作使用,以可視化收集的數(shù)據(jù)。
簡單地說,您可以結合普羅米修斯和 Grafana 的力量來創(chuàng)建儀表板,使您能夠跟蹤生產(chǎn)中的機器學習系統(tǒng)。您還可以使用這些儀表板設置警報,在發(fā)生意外事件時通知您。
如果您使用 NVIDIA Triton Inference Server 在生產(chǎn)中部署、運行和擴展 AI 模型,您可以利用 NVIDIA Triton 以 Prometheus 格式導出的運營指標。您可以使用 NVIDIA Triton 從運行推斷的系統(tǒng)中收集 GPU / CPU 使用、內(nèi)存和延遲指標。這些度量對于擴展和負載平衡請求非常有用,從而滿足應用程序 SLA 。
了解有關 Prometheus 和 Grafana 的更多信息。
顯然人工智能
顯然,人工智能是一種開源的 Python 工具,用于在生產(chǎn)環(huán)境中分析、監(jiān)控和調(diào)試機器學習模型。聯(lián)合創(chuàng)始人 Emeli Dral 和 Elena Samuylova 撰寫了有關模型監(jiān)控的信息性文章,包括:
Monitoring Machine Learning Models in Production
Machine Learning Monitoring: What It Is, and What We Are Missing
要了解更多信息,請參閱 Evidently AI documentation 。
Amazon SageMaker 型號監(jiān)視器
一眼望去, Amazon SageMaker 模型監(jiān)視器可以提醒您模型質(zhì)量的任何偏差,以便采取糾正措施,如再培訓、審計上游系統(tǒng)或修復質(zhì)量問題。開發(fā)人員可以利用無代碼監(jiān)控功能或通過編碼進行自定義分析。有關詳細信息,請參閱 Amazon SageMaker documentation 。
機器學習模型監(jiān)控的最佳實踐
部署模型只是您作為機器學習實踐者職責的一部分。您工作的其他部分涉及確保模型在實時環(huán)境中按預期運行,這需要監(jiān)控機器學習系統(tǒng)。監(jiān)控機器學習時需要遵循的一些常規(guī)最佳實踐包括:
部署階段未啟動監(jiān)控
構建機器學習模型通常需要多次迭代才能獲得可接受的設計。因此,跟蹤和監(jiān)控度量和日志是模型開發(fā)的重要組成部分,一旦開始實驗,就應該強制執(zhí)行。
嚴重退化是一個危險信號,需要調(diào)查
模型的性能應該會降低。然而,突然的大幅度下降是令人擔憂的原因,應立即進行調(diào)查。
創(chuàng)建故障排除框架
應鼓勵團隊記錄其故障排除框架。從警報到故障排除的系統(tǒng)對模型維護非常有效。
創(chuàng)建行動計劃
在不可避免的情況下,你的機器學習系統(tǒng)出現(xiàn)了中斷,應該有一個框架來應對。一旦團隊收到問題警報,框架應將團隊從警報轉移到行動,然后最終調(diào)試問題,以確保模型得到有效維護。
當?shù)孛嬲嫦嗖豢捎脮r使用代理
不斷了解機器學習模型在生產(chǎn)環(huán)境中的性能至關重要。如果無法根據(jù)實際情況評估模型,那么預測漂移等代理就足夠了。
我還有漏掉什么嗎?你可在 NVIDIA Developer Forums 中留下評論。
接下來是什么?
監(jiān)控機器學習系統(tǒng)是機器學習生命周期中一個困難但重要的部分。在生產(chǎn)中,模型的性能有時與預期不同。因此,需要進行適當?shù)谋O(jiān)測,以在問題可能造成重大損害之前發(fā)現(xiàn)問題。
一個薄弱的監(jiān)控系統(tǒng)可能會導致 1 )模型在生產(chǎn)過程中性能不佳而沒有監(jiān)督, 2 )企業(yè)擁有的模型不再提供商業(yè)價值,或 3 )未發(fā)現(xiàn)的錯誤隨著時間的推移而爆發(fā)。
-
NVIDIA
+關注
關注
14文章
5292瀏覽量
106188 -
AI
+關注
關注
88文章
34918瀏覽量
278127 -
機器學習
+關注
關注
66文章
8500瀏覽量
134445
發(fā)布評論請先 登錄

如何使用TensorFlow構建機器學習模型

如何更有效地使用局部放電監(jiān)控?
從利用認知 API 到構建出自定義的機器學習模型面臨哪些挑戰(zhàn)?
什么是機器學習? 機器學習基礎入門
R語言機器學習算法的性能分析比較
機器學習被高估了?
如何評估機器學習模型的性能?機器學習的算法選擇
除靜電設備在生產(chǎn)中的運用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論