") 人大發(fā)表迄今為止最大最全的大模型綜述
人大發(fā)表迄今為止最大最全的大模型綜述
今年3月末,我們在arXiv網(wǎng)站發(fā)布了大語言模型綜述文章《A Survey of Large Language Models》的第一個版本V1,該綜述文章系統(tǒng)性地梳理了大語言模型的研究進展與核心技術(shù),討論了大量的相關(guān)工作。自大語言模型綜述的預(yù)印本上線以來,受到了廣泛關(guān)注,收到了不少讀者的寶貴意見。
 在發(fā)布V1版本后的3個月時間內(nèi),為了提升該綜述的質(zhì)量,我們在持續(xù)更新相關(guān)的內(nèi)容,連續(xù)進行了多版的內(nèi)容修訂(版本號目前迭代到V11),論文篇幅從V1版本的51頁、416篇參考文獻擴增到了V11版本的85頁、610篇參考文獻。V11版本是我們自五月中下旬開始策劃進行大修的版本,詳細更新日志請見文章結(jié)尾,已于6月末再次發(fā)布于arXiv網(wǎng)站。相較于V1版本,V11版本的大語言模型綜述有以下新亮點:
在發(fā)布V1版本后的3個月時間內(nèi),為了提升該綜述的質(zhì)量,我們在持續(xù)更新相關(guān)的內(nèi)容,連續(xù)進行了多版的內(nèi)容修訂(版本號目前迭代到V11),論文篇幅從V1版本的51頁、416篇參考文獻擴增到了V11版本的85頁、610篇參考文獻。V11版本是我們自五月中下旬開始策劃進行大修的版本,詳細更新日志請見文章結(jié)尾,已于6月末再次發(fā)布于arXiv網(wǎng)站。相較于V1版本,V11版本的大語言模型綜述有以下新亮點:- 新增了對LLaMA模型及其衍生模型組成的LLaMA家族介紹;
- 新增了具體實驗分析,包括指令微調(diào)數(shù)據(jù)集組合方式實驗以及部分模型綜合能力評測;
- 新增了大語言模型提示設(shè)計提示指南以及相關(guān)實驗,總結(jié)了提示設(shè)計的原則、經(jīng)驗;
- 新增了參數(shù)高效適配和空間高效適配章節(jié),總結(jié)了大語言模型相關(guān)的輕量化技術(shù);
- 增加了對于規(guī)劃(planning)的相關(guān)工作介紹;
- 增補了許多脈絡(luò)梳理內(nèi)容,以及大量最新工作介紹;

- 論文鏈接:https://arxiv.org/abs/2303.18223
- GitHub項目鏈接:https://github.com/RUCAIBox/LLMSurvey
- 中文翻譯版本鏈接:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
1. 引言
大語言模型目前已經(jīng)成為學(xué)界研究的熱點。我們統(tǒng)計了arXiv論文庫中自2018年6月以來包含關(guān)鍵詞"語言模型"以及自2019年10月以來包含關(guān)鍵詞"大語言模型"的論文數(shù)量趨勢圖。結(jié)果表明,在ChatGPT發(fā)布之后,相關(guān)論文的數(shù)量呈現(xiàn)出爆發(fā)式增長,這充分證明大語言模型在學(xué)術(shù)界的影響力日益凸顯,吸引了越來越多的研究者投入到這一領(lǐng)域。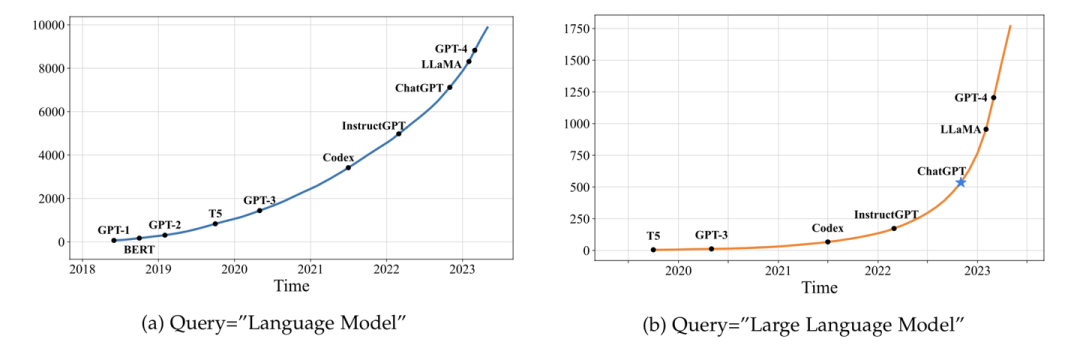
2. 總覽
相較于小模型,大模型擴展了模型大小、訓(xùn)練數(shù)據(jù)大小和總計算量,顯著提升了語言模型的能力。在總覽章節(jié)中,我們新增了擴展法則(scaling law)的討論,其中重點介紹了KM擴展法則和Chinchilla擴展法則,這兩個法則對于理解大語言模型的性能提升提供了重要參考。- KM 擴展法則
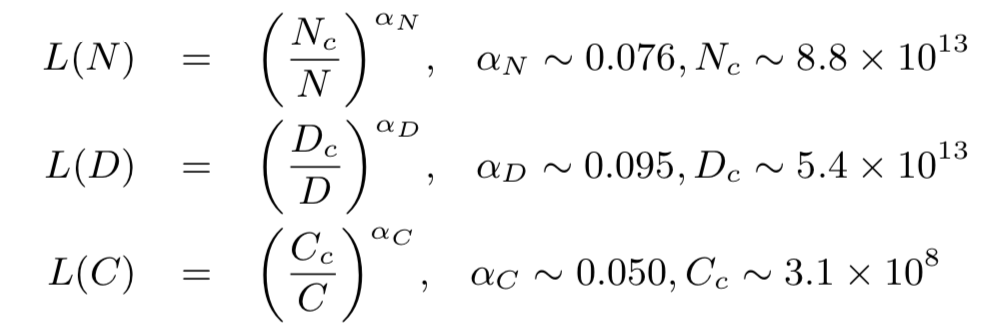
-
Chinchilla擴展法則
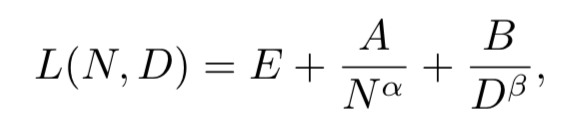 此外,我們新增了一部分關(guān)于OpenAI GPT系列語言模型的技術(shù)演進階段的介紹(并附圖)。這一部分將幫助讀者了解GPT系列模型如何從最初的GPT開始,逐步演變成例如ChatGPT和GPT-4等更先進的大語言模型。
此外,我們新增了一部分關(guān)于OpenAI GPT系列語言模型的技術(shù)演進階段的介紹(并附圖)。這一部分將幫助讀者了解GPT系列模型如何從最初的GPT開始,逐步演變成例如ChatGPT和GPT-4等更先進的大語言模型。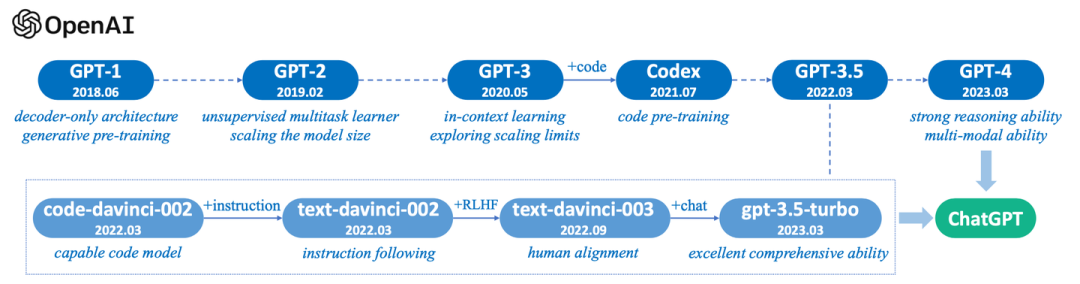 針對GPT系列的核心“預(yù)測下一個詞”,還進一步加入了一些Ilya Sutskever的采訪記錄:
針對GPT系列的核心“預(yù)測下一個詞”,還進一步加入了一些Ilya Sutskever的采訪記錄:
3. 大語言模型相關(guān)資源
我們對于最新符合條件的模型進行了補充,持續(xù)更新了現(xiàn)有的10B+的模型圖: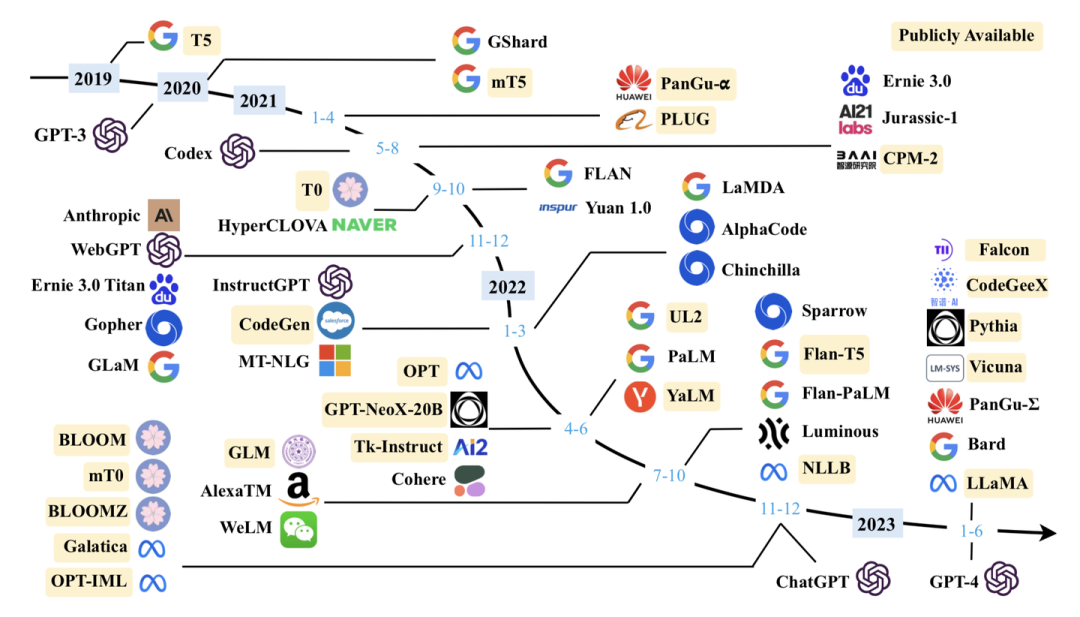 2023年2月,Meta發(fā)布了LLaMA大語言模型。受益于其強大的基座能力,LLaMA的發(fā)布引起了開源社區(qū)的對其進行擴展的熱潮,大量的研究人員基于LLaMA進行指令微調(diào)或者繼續(xù)預(yù)訓(xùn)練,從而催生了大量高質(zhì)量的開源大語言模型。為了幫助讀者了解LLaMA家族模型的發(fā)展脈絡(luò),我們增加了LLaMA家族模型的發(fā)展介紹,并繪制了一個簡要的LLaMA家族演化圖來展示LLaMA家族模型的發(fā)展歷程,以及各個衍生模型之間的關(guān)聯(lián)。
2023年2月,Meta發(fā)布了LLaMA大語言模型。受益于其強大的基座能力,LLaMA的發(fā)布引起了開源社區(qū)的對其進行擴展的熱潮,大量的研究人員基于LLaMA進行指令微調(diào)或者繼續(xù)預(yù)訓(xùn)練,從而催生了大量高質(zhì)量的開源大語言模型。為了幫助讀者了解LLaMA家族模型的發(fā)展脈絡(luò),我們增加了LLaMA家族模型的發(fā)展介紹,并繪制了一個簡要的LLaMA家族演化圖來展示LLaMA家族模型的發(fā)展歷程,以及各個衍生模型之間的關(guān)聯(lián)。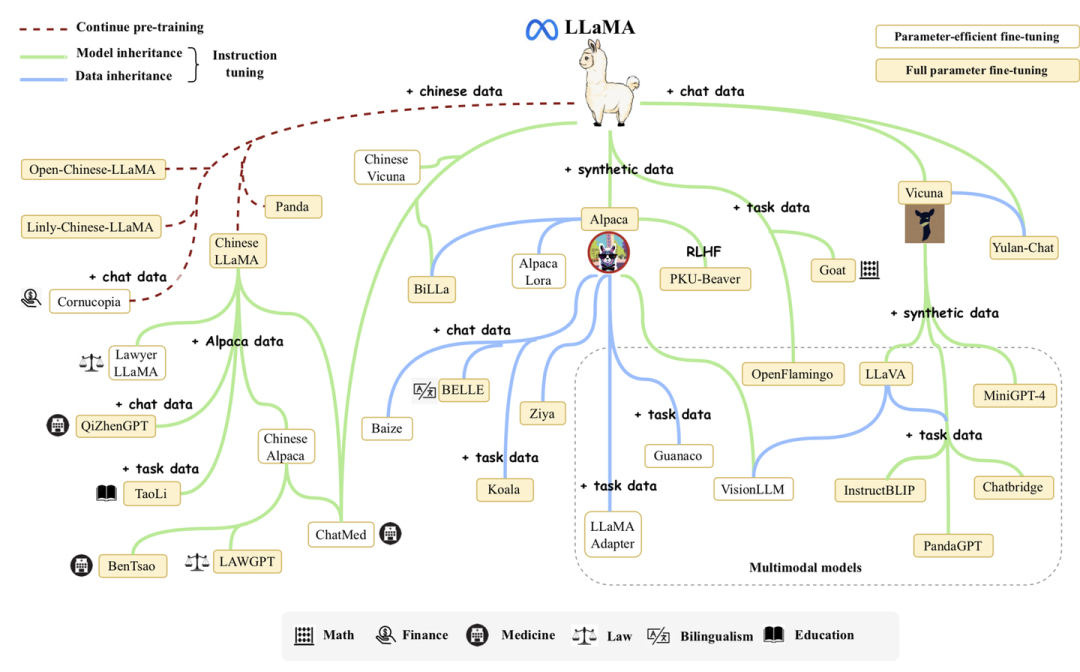
4. 大語言模型預(yù)訓(xùn)練技術(shù)
在預(yù)訓(xùn)練技術(shù)章節(jié),我們大幅補充了大模型預(yù)訓(xùn)練各方面的技術(shù)細節(jié)。在模型架構(gòu)部分,我們補充了三種主流模型架構(gòu)的對比圖,包括因果編碼器、前綴解碼器和編碼器-解碼器架構(gòu),從而直觀的展示這三種架構(gòu)的差異和聯(lián)系。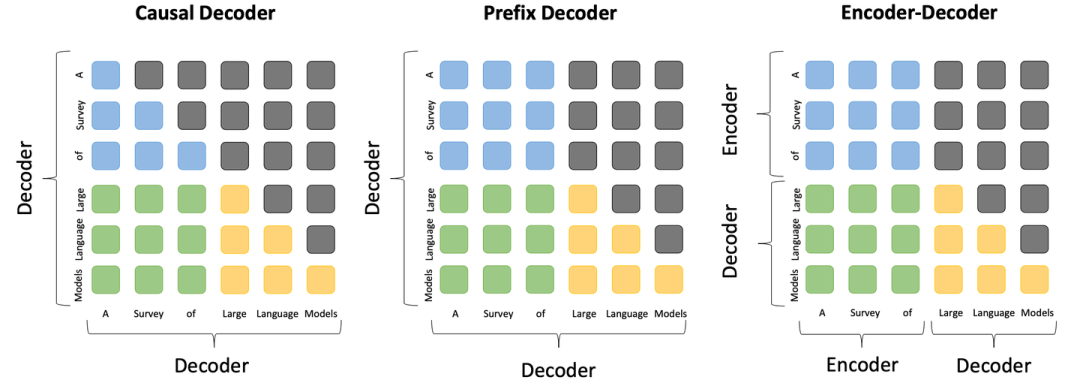 此外,我們詳細補充了模型架構(gòu)的各組件細節(jié),包括分詞、歸一化方法、歸一化位置、位置編碼、注意力與偏置等等,并提供了Transformer架構(gòu)多種配置的詳細公式表。在最后的討論章節(jié),我們針對研究者廣泛關(guān)注的長文本編碼與生成挑戰(zhàn)進行了討論。
此外,我們詳細補充了模型架構(gòu)的各組件細節(jié),包括分詞、歸一化方法、歸一化位置、位置編碼、注意力與偏置等等,并提供了Transformer架構(gòu)多種配置的詳細公式表。在最后的討論章節(jié),我們針對研究者廣泛關(guān)注的長文本編碼與生成挑戰(zhàn)進行了討論。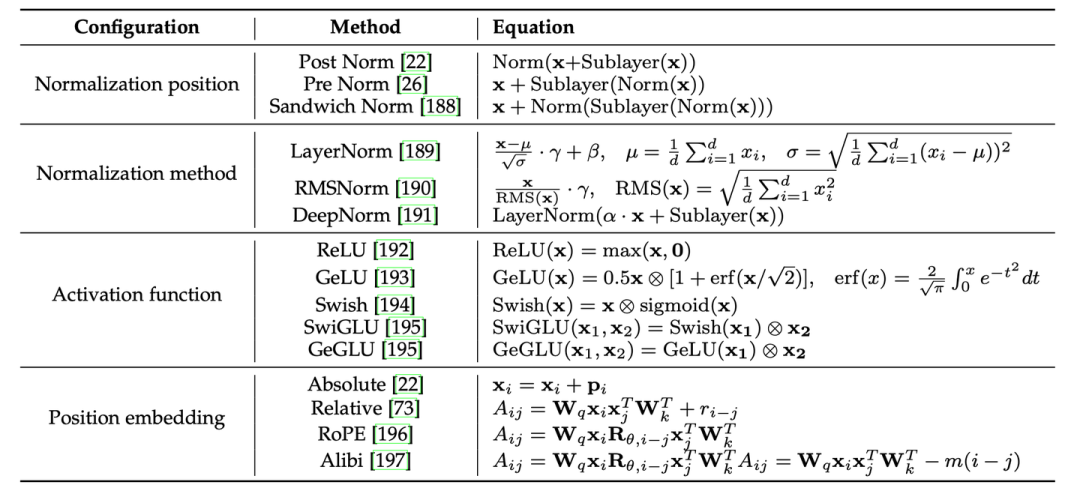 針對預(yù)訓(xùn)練數(shù)據(jù)的詞元化問題(tokenization),我們補充介紹了BPE、WordPiece和Unigram三種常用算法:
針對預(yù)訓(xùn)練數(shù)據(jù)的詞元化問題(tokenization),我們補充介紹了BPE、WordPiece和Unigram三種常用算法:
5. 大語言模型適配技術(shù)
在適配技術(shù)章節(jié),我們擴充了指令微調(diào)的技術(shù)細節(jié),包括指令收集方法、指令微調(diào)的作用、指令微調(diào)的結(jié)果和對應(yīng)分析。首先,我們按照任務(wù)指令、聊天指令、合成指令三類分別介紹了指令數(shù)據(jù)的收集方法,并收集了的指令集合。
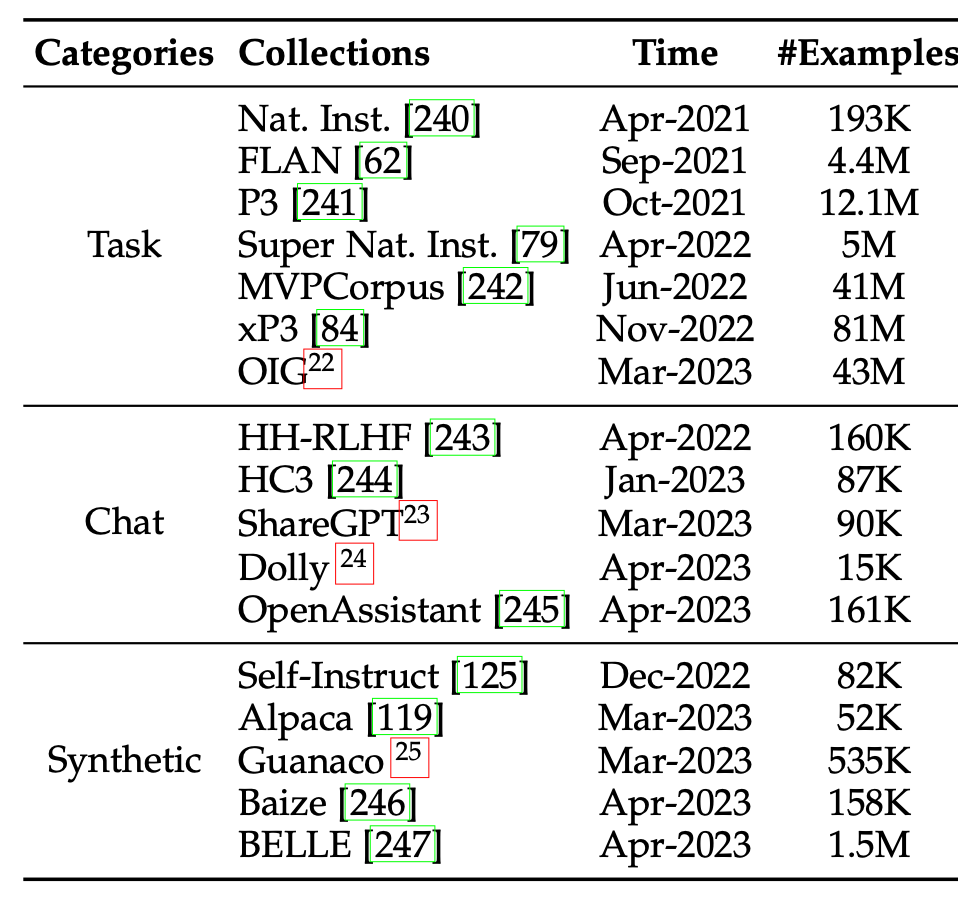
并且更新了指令集合的創(chuàng)建方式示意圖:
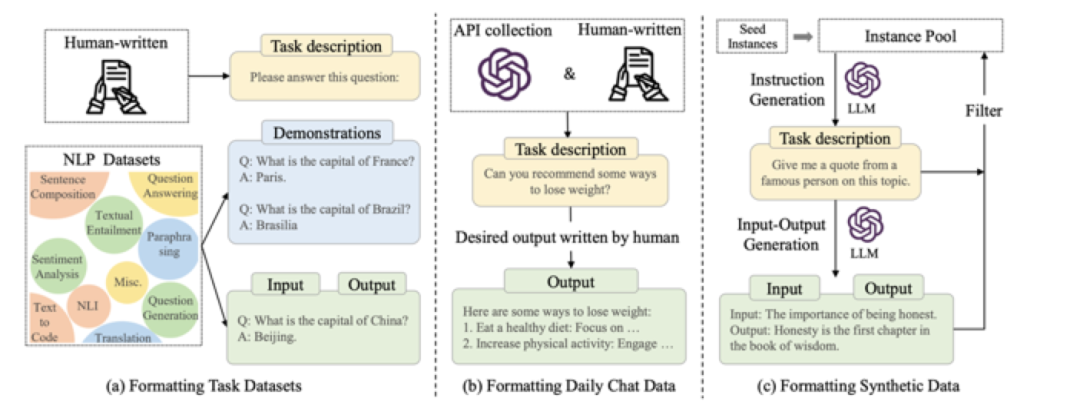 其次,為了探究不同指令數(shù)據(jù)對模型性能的影響,我們給出了不同數(shù)據(jù)混合策略下指令微調(diào)模型的實驗結(jié)果供讀者參考。為了讓讀者更好地上手指令微調(diào),還給出了指令微調(diào)大模型的資源參考表,并給出了指令微調(diào)的實用建議。
其次,為了探究不同指令數(shù)據(jù)對模型性能的影響,我們給出了不同數(shù)據(jù)混合策略下指令微調(diào)模型的實驗結(jié)果供讀者參考。為了讓讀者更好地上手指令微調(diào),還給出了指令微調(diào)大模型的資源參考表,并給出了指令微調(diào)的實用建議。 隨著大語言模型的關(guān)注度日漸上升,如何更輕量地微調(diào)和使用大語言模型也成為了業(yè)界關(guān)注的熱點,為此,我們新增參數(shù)高效適配章節(jié)和空間高效適配章節(jié)。在參數(shù)高效適配章節(jié),我們介紹了常見的參數(shù)高效適配技術(shù),包括Adapter Tuning、Prefix Tuning、Prompt Tuning、LoRA等等,并列舉了近期結(jié)合這些技術(shù)在大模型上的具體實踐。
隨著大語言模型的關(guān)注度日漸上升,如何更輕量地微調(diào)和使用大語言模型也成為了業(yè)界關(guān)注的熱點,為此,我們新增參數(shù)高效適配章節(jié)和空間高效適配章節(jié)。在參數(shù)高效適配章節(jié),我們介紹了常見的參數(shù)高效適配技術(shù),包括Adapter Tuning、Prefix Tuning、Prompt Tuning、LoRA等等,并列舉了近期結(jié)合這些技術(shù)在大模型上的具體實踐。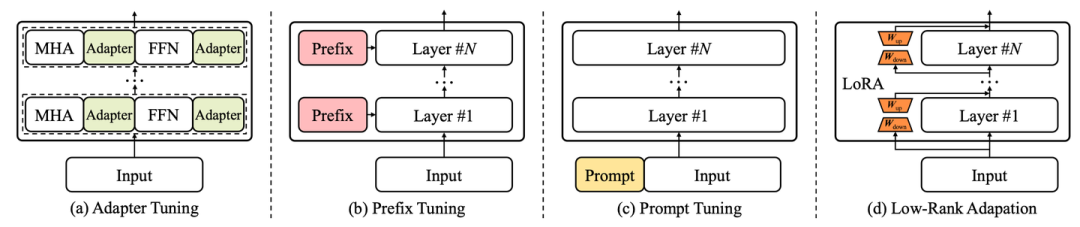 同時由于大語言模型參數(shù)量巨大,在推理時需要占用大量的內(nèi)存(顯存),導(dǎo)致它們在實際應(yīng)用中部署成本較高。為此,我們介紹了空間高效適配技術(shù),討論了如何通過模型壓縮方法(模型量化)來減少大語言模型的內(nèi)存占用,從而使其可以在資源有限的情況下使用。下面總結(jié)了我們討論的一些核心結(jié)論:
同時由于大語言模型參數(shù)量巨大,在推理時需要占用大量的內(nèi)存(顯存),導(dǎo)致它們在實際應(yīng)用中部署成本較高。為此,我們介紹了空間高效適配技術(shù),討論了如何通過模型壓縮方法(模型量化)來減少大語言模型的內(nèi)存占用,從而使其可以在資源有限的情況下使用。下面總結(jié)了我們討論的一些核心結(jié)論:
6. 大語言模型使用技術(shù)
我們將大語言模型在推理階段如何執(zhí)行上下文學(xué)習(xí)的機制分析劃分為兩類,即任務(wù)識別和任務(wù)學(xué)習(xí)。在任務(wù)識別部分,介紹了大語言模型如何從示例中識別任務(wù)并使用預(yù)訓(xùn)練階段習(xí)得的知識加以解決;在任務(wù)學(xué)習(xí)部分,介紹了大語言模型如何從示例中學(xué)習(xí)解決新任務(wù)。除了上下文學(xué)習(xí)和思維鏈提示,我們還介紹了另一類使用大語言模型的重要范式,即基于提示對復(fù)雜任務(wù)進行規(guī)劃。根據(jù)相關(guān)工作,我們總結(jié)出了基于規(guī)劃的提示的總體框架。這類范式通常包含三個組件:任務(wù)規(guī)劃者、規(guī)劃執(zhí)行者和環(huán)境。隨后,我們從規(guī)劃生成,反饋獲取和規(guī)劃完善三個方面介紹了這一范式的基本做法。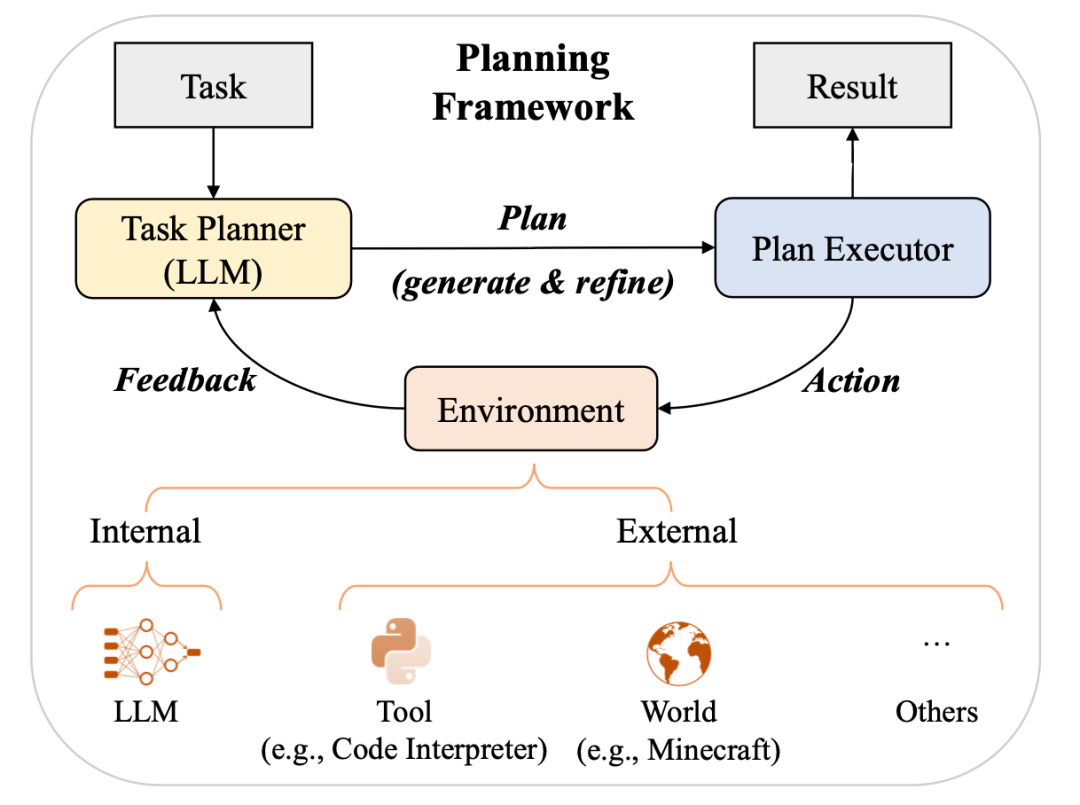
7. 大語言模型能力評估
考慮到大語言模型的條件語言生成能力日益增長,我們介紹了已有工作對大語言模型時代語言生成自動評測可靠性問題的討論。對于大語言模型的高級能力,我們增補了最新的相關(guān)工作,并總結(jié)了大語言模型高級能力評測的常用數(shù)據(jù)集供讀者參考。此外,隨著大語言模型通用能力的提升,一系列工作提出了更具挑戰(zhàn)性的基于面向人類測試的綜合評測基準來評測大語言模型,我們增加了這些代表性評測基準的介紹。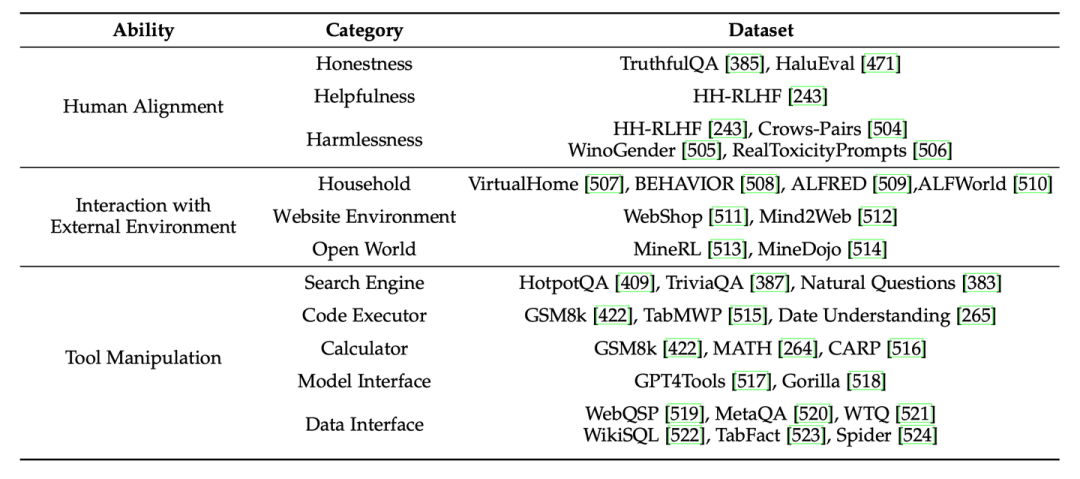 在大語言模型時代,開源和閉源的大語言模型不斷涌現(xiàn),我們對部分熱門開源模型和閉源模型進行了細粒度的能力評測,涵蓋了評測章節(jié)總結(jié)的8大基礎(chǔ)和高級能力對應(yīng)的27個代表性任務(wù)。進一步,我們對開源模型和閉源模型的評測結(jié)果進行了細致的分析。為了更好地說明大模型的現(xiàn)有問題,我們對于關(guān)鍵問題都進行了note形式的總結(jié):
在大語言模型時代,開源和閉源的大語言模型不斷涌現(xiàn),我們對部分熱門開源模型和閉源模型進行了細粒度的能力評測,涵蓋了評測章節(jié)總結(jié)的8大基礎(chǔ)和高級能力對應(yīng)的27個代表性任務(wù)。進一步,我們對開源模型和閉源模型的評測結(jié)果進行了細致的分析。為了更好地說明大模型的現(xiàn)有問題,我們對于關(guān)鍵問題都進行了note形式的總結(jié):
8. 大語言模型提示設(shè)計使用指南
在大語言模型時代,提示成為了人與機器交互的重要形式。然而,如何編寫好的提示是一門對技巧和經(jīng)驗要求很高的手藝。為了讓讀者能夠快速上手大語言模型的提示設(shè)計,我們給出了一個實用的提示設(shè)計指南。我們詳細介紹了提示的關(guān)鍵組件,并討論了一些關(guān)鍵的提示設(shè)計原則。一個完整的提示通常包含四個關(guān)鍵組成因素,即任務(wù)描述、輸入數(shù)據(jù)、上下文信息和提示風(fēng)格。為了更好的展示這些組成因素,我們給出了直觀的提示樣例表。
增加了相關(guān)提示的示意圖:
 除此之外,我們還總結(jié)了一些關(guān)鍵的提示設(shè)計原則,包括清晰表述任務(wù)目標、將復(fù)雜任務(wù)進行分解以及使用模型友好的格式。進一步我們基于這些設(shè)計原則,展示了一系列有用的提示設(shè)計小貼士。最后,我們結(jié)合多種常見任務(wù),基于ChatGPT具體實驗了不同提示對模型性能的影響,供讀者在使用提示執(zhí)行具體任務(wù)時參考。
除此之外,我們還總結(jié)了一些關(guān)鍵的提示設(shè)計原則,包括清晰表述任務(wù)目標、將復(fù)雜任務(wù)進行分解以及使用模型友好的格式。進一步我們基于這些設(shè)計原則,展示了一系列有用的提示設(shè)計小貼士。最后,我們結(jié)合多種常見任務(wù),基于ChatGPT具體實驗了不同提示對模型性能的影響,供讀者在使用提示執(zhí)行具體任務(wù)時參考。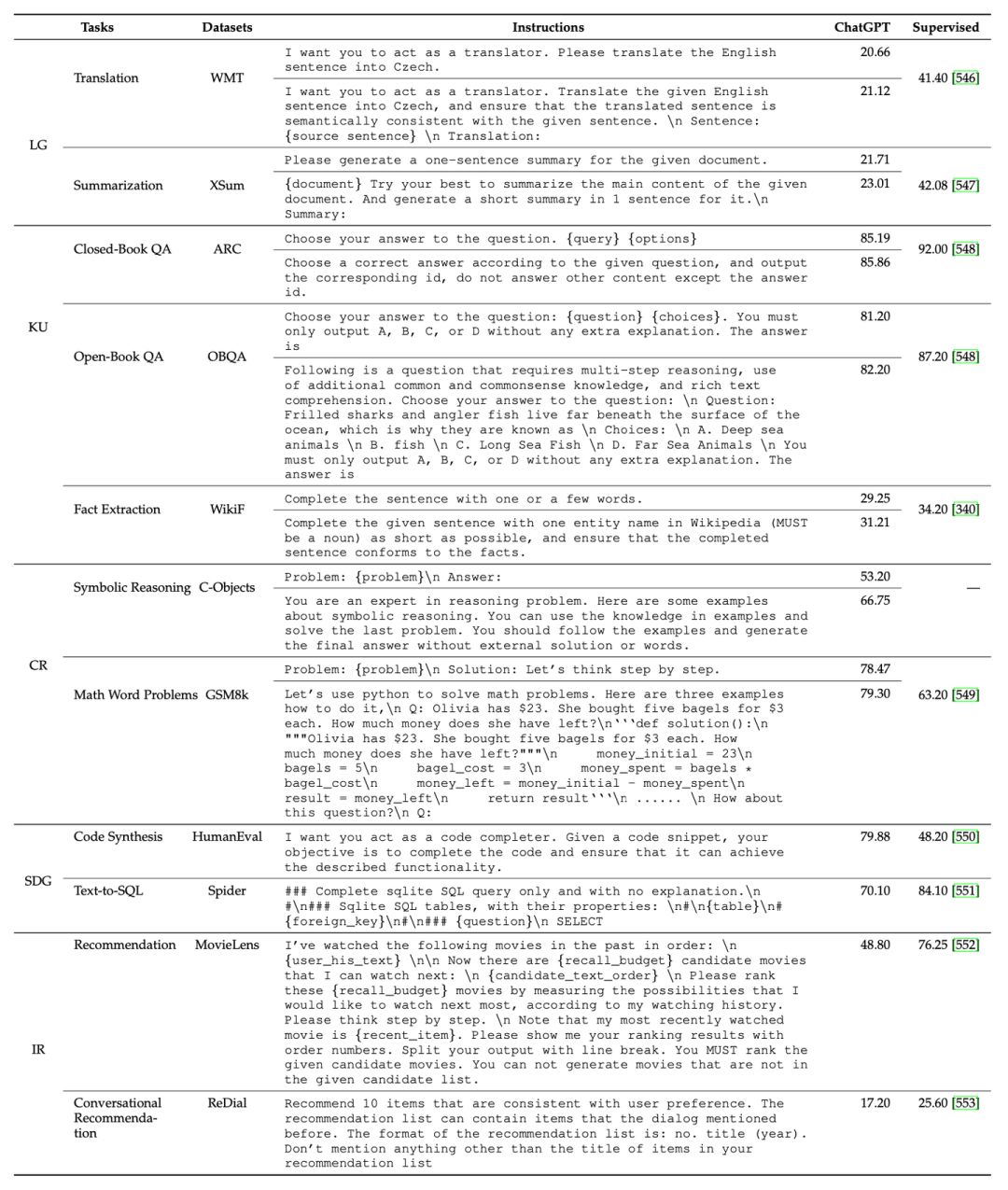
9. 大語言模型領(lǐng)域應(yīng)用
隨著大語言模型關(guān)注度的逐漸提升,研究者和工業(yè)界從業(yè)人員也嘗試將大語言模型應(yīng)用到各種專業(yè)領(lǐng)域中。為了系統(tǒng)地介紹這些應(yīng)用實踐,我們將綜述中大語言模型的領(lǐng)域應(yīng)用部分獨立成了專門的章節(jié)。具體而言,我們擴充介紹了原有將大語言模型應(yīng)用到醫(yī)療、教育、法律領(lǐng)域的相關(guān)研究,并新增了金融和科學(xué)研究領(lǐng)域的相關(guān)工作介紹。10. 尋求建議與算力
一篇高質(zhì)量的長篇綜述文章需要大量的時間投入,所參與的老師和學(xué)生為此付出了很多的時間。盡管我們已經(jīng)盡力去完善這篇綜述文章,但由于能力所限,難免存在不足和錯誤之處,仍有很大的改進空間。我們的最終目標是使這篇綜述文章成為一個“know-how”的大模型技術(shù)指南手冊,讓大模型的秘密不再神秘、讓技術(shù)細節(jié)不再被隱藏。盡管我們深知目前這篇綜述離這個目標的距離還比較遠,我們愿意在之后的版本中竭盡全力去改進。特別地,對于預(yù)訓(xùn)練、指令微調(diào)、提示工程的內(nèi)在原理以及實戰(zhàn)經(jīng)驗等方面,我們非常歡迎讀者為我們貢獻想法與建議,可以通過GitHub提交PR或者郵件聯(lián)系我們的作者。對于所有被采納的技術(shù)細節(jié),我們都將在論文的致謝部分中“實名+實際貢獻”進行致謝。同時,我們自己也在圍繞大模型綜述的部分內(nèi)容開展相關(guān)的實驗探索(如能力評測、指令微調(diào)等),以保證綜述中的討論能夠有據(jù)可循。由于算力所限,目前能開展的實驗局限于小尺寸模型和少量比較方法。在此,我們也向社會尋求算力支持,我們將承諾所獲得的算力資源將完全用于該綜述文章的編寫,所有使用外部算力所獲得的技術(shù)經(jīng)驗,將完全在綜述文章中對外發(fā)布。我們將在綜述的致謝部分和GitHub項目主頁對于算力提供商進行致謝。針對本綜述文章的算力資源支持事宜,煩請致信 batmanfly@qq.com 聯(lián)系我們。我們的綜述文章自發(fā)布以來,收到了廣泛網(wǎng)友的大量修改意見,在此一并表示感謝。也希望大家一如既往支持與關(guān)注我們的大模型綜述文章,您們的點贊與反饋將是我們前行最大的動力。11. 本次修訂的參與學(xué)生名單
學(xué)生作者:周昆(添加了指令微調(diào)實驗的任務(wù)設(shè)置與結(jié)果分析,具體安排了實驗細節(jié),添加了能力評測實驗的實驗設(shè)置與結(jié)果分析,協(xié)助整理code,添加了提示指南部分的實驗設(shè)置與結(jié)果分析,添加了表13)、李軍毅(添加了指令微調(diào)實驗的數(shù)據(jù)集、改進策略和實驗設(shè)置和實驗表8,添加了能力評測實驗的模型、任務(wù)和數(shù)據(jù)集,以及實驗表11,添加了提示指南的設(shè)計原則和表12表14)、唐天一(添加第五章文字細節(jié),添加圖1、3、10,表6、7)、王曉磊(添加第六章6.1文字細節(jié),新增6.3)、侯宇蓬(添加第四章文字細節(jié))、閔映乾(添加第三章少數(shù)模型,LLaMA相關(guān)討論,圖4)、張北辰(添加第七章、第九章文字細節(jié),添加表10)、董梓燦(添加圖7表、4和第四章文字細節(jié))、陳昱碩(表7實驗)、陳志朋(添加第七章、第九章文字細節(jié),表11實驗)、蔣錦昊(更新圖8)學(xué)生志愿者:成曉雪(表11實驗)、王禹淏(表11實驗)、鄭博文(表11實驗)、胡譯文(中文校對)、侯新銘(中文校對)、尹彥彬(中文校對)、曹展碩(中文校對)附件:更新日志
| 版本 | 時間 | 主要更新內(nèi)容 |
|---|---|---|
| V1 | 2023年3月31日 | 初始版本 |
| V2 | 2023年4月9日 | 添加了機構(gòu)信息。修訂了圖表 1 和表格 1,并澄清了大語言模型的相應(yīng)選擇標準。改進了寫作。糾正了一些小錯誤。 |
| V3 | 2023年4月11日 | 修正了關(guān)于庫資源的錯誤 |
| V4 | 2023年4月12日 | 修訂了圖1 和表格 1,并澄清了一些大語言模型的發(fā)布日期 |
| V5 | 2023年4月16日 | 添加了關(guān)于 GPT 系列模型技術(shù)發(fā)展的章節(jié) |
| V6 | 2023年4月24日 | 在表格 1 和圖表 1 中添加了一些新模型。添加了關(guān)于擴展法則的討論。為涌現(xiàn)能力的模型尺寸添加了一些解釋(第 2.1 節(jié))。在圖 4 中添加了用于不同架構(gòu)的注意力模式的插圖。在表格 4 中添加了詳細的公式。 |
| V7 | 2023年4月25日 | 修正了圖表和表格中的一些拷貝錯誤 |
| V8 | 2023年4月27日 | 在第 5.3 節(jié)中添加了參數(shù)高效適配章節(jié) |
| V9 | 2023年4月28日 | 修訂了第 5.3 節(jié) |
| V10 | 2023年5 月7 日 | 修訂了表格 1、表格 2 和一些細節(jié) |
| V11 | 2023年6月29日 | 第一章:添加了圖1,在arXiv上發(fā)布的大語言論文趨勢圖;第二章:添加圖3以展示GPT的演變及相應(yīng)的討論;第三章:添加圖4以展示LLaMA家族及相應(yīng)的討論;第五章:在5.1.1節(jié)中添加有關(guān)指令調(diào)整合成數(shù)據(jù)方式的最新討論, 在5.1.4節(jié)中添加有關(guān)指令調(diào)整的經(jīng)驗分析, 在5.3節(jié)中添加有關(guān)參數(shù)高效適配的討論, 在5.4節(jié)中添加有關(guān)空間高效適配的討論;第六章:在6.1.3節(jié)中添加有關(guān)ICL的底層機制的最新討論,在6.3節(jié)中添加有關(guān)復(fù)雜任務(wù)解決規(guī)劃的討論;第七章:在7.2節(jié)中添加用于評估LLM高級能力的代表性數(shù)據(jù)集的表格10,在7.3.2節(jié)中添加大語言模型綜合能力pint測;第八章:添加提示設(shè)計;第九章:添加關(guān)于大語言模型在金融和科學(xué)研究領(lǐng)域應(yīng)用的討論。 |
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10709 -
大模型
+關(guān)注
關(guān)注
2文章
3062瀏覽量
3905
原文標題:人大發(fā)表迄今為止最大最全的大模型綜述
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
35億美元!諾基亞獲迄今為止數(shù)額最大5G合同
手下的高額訂單。據(jù)外媒最新公布的消息,來自芬蘭的諾基亞公司日前獲得了迄今為止數(shù)額最大的5G合同,價值高達35億美元。
努比亞Z18S將于10月31日發(fā)布 官方稱迄今為止最全面的全面屏
近日,努比亞手機總經(jīng)理倪飛在微博宣布了一個重磅消息,努比亞將于10月31日舉辦新品發(fā)布會,并表示:“6周年誠意之作,迄今為止,最全面的全面屏!”而倪飛的微博小尾巴變成了“努比亞X 護眼雙屏”可見屆時將發(fā)布新手機努比亞X,該機搭載兩個屏幕,它就是此前曝光的努比亞Z18S。
小米宣布將于12月8日在紐約舉辦迄今為止最大的聚會
近日,據(jù)外媒Phonearena報道,經(jīng)過Reddit確認,小米宣布將于當(dāng)?shù)貢r間12月8日在紐約舉辦活動,活動的具體時間和地址尚未確定,不過這家中國廠商聲稱,這將是它“迄今為止最大的聚會”。小米還表示將在活動中展示它最新和最偉大的產(chǎn)品,與會者能夠見到美國團隊、特別嘉賓,甚
為什么iPhone4是蘋果迄今為止最為人稱道的產(chǎn)品
它是蘋果在智能手機上的一次跨越,也是喬布斯最后一款作品,它是3G時代的重要推動者,也加速了移動互聯(lián)網(wǎng)時代到來。本期極客博物館,我們就來聊聊蘋果迄今為止最為人稱道的產(chǎn)品——iPhone 4。
驍龍865沒有集成卻是迄今為止最先進的5G移動平臺
高通表示,驍龍865沒有集成并不影響其性能,反而驍龍865是迄今為止最先進的5G移動平臺,單以集成與否來衡量芯片強弱是沒道理的。
發(fā)表于 12-05 09:19
?1438次閱讀
Intel全力打磨的獨立顯卡 將是迄今為止印度打造的最大硅片
Intel正全力打磨“三進宮”的獨立顯卡產(chǎn)品,首席架構(gòu)師Raja Koduri本周發(fā)推文確認,Xe HP(高性能Xe核心)由印度團隊設(shè)計,已達成里程碑,預(yù)計將是迄今為止印度打造的最大硅片,甚至是世界最大的硅片,堪稱“爸爸級”。
比亞迪拿下荷蘭巨額訂單 是迄今為止歐洲最大的純電動大巴訂單
據(jù)國內(nèi)媒體報道,12月6日,比亞迪中標荷蘭259臺純電動大巴訂單,與歐洲公交運營商凱奧雷斯(Keolis)荷蘭分公司簽署協(xié)議。據(jù)比亞迪介紹,此次訂單涉及比亞迪巴士家族多款車型,并且這也是迄今為止歐洲最大的純電動大巴訂單。
發(fā)表于 12-09 13:35
?1573次閱讀
5G將是迄今為止最安全的無線傳輸技術(shù)
來自Light Reading的報道稱,無線行業(yè)人士認為,5G將是迄今為止最安全的無線傳輸技術(shù)。但是不斷有研究報告稱,研究人員持續(xù)在5G標準中發(fā)現(xiàn)漏洞。
發(fā)表于 12-09 14:43
?1409次閱讀
Facebook發(fā)布概念眼鏡_迄今為止最薄的VR顯示器
據(jù)外媒報道,F(xiàn)acebook近日發(fā)布了一項新產(chǎn)品消息——一款基于折疊全息光學(xué)技術(shù)的概念眼鏡,事實證明它或許是“迄今為止最薄的VR顯示器”。Facebook的AR/VR研發(fā)部門展示了這款全新VR顯示器的兩個亮點功能:基于偏振的光學(xué)“折疊”和全息鏡頭。
發(fā)表于 08-31 17:36
?1101次閱讀
MIT打造出號稱迄今為止最精確的原子鐘
據(jù)外媒報道,日前,美國麻省理工學(xué)院(MIT)的研究者們打造出號稱是迄今為止最精確的原子鐘。
三星電子開始量產(chǎn)迄今為止最先進的數(shù)據(jù)中心SSD
三星電子宣布,已經(jīng)開始量產(chǎn)該公司迄今為止最為先進的數(shù)據(jù)中心SSD,型號為“PM9A3”。
三星開始量產(chǎn)迄今為止最強的數(shù)據(jù)中心SSD
三星電子宣布,已經(jīng)開始量產(chǎn)該公司迄今為止最為先進的數(shù)據(jù)中心SSD,型號為“PM9A3”。
iPhone13缺芯減產(chǎn)?供應(yīng)商辟謠 今年迄今為止沒有削減訂單
蘋果組件供應(yīng)商聲稱今年迄今為止沒有削減訂單,但是由于芯片短缺問題,蘋果產(chǎn)品的生產(chǎn)的確會面臨挑戰(zhàn)。
發(fā)表于 10-14 10:56
?2156次閱讀
研究人員發(fā)現(xiàn)了迄今為止最快的半導(dǎo)體
科學(xué)家們發(fā)現(xiàn)了他們所說的迄今為止最快、最高效的半導(dǎo)體。盡管這種新材料是用地球上最稀有的元素之一制成,但研究人員表示,有可能會發(fā)現(xiàn)由更豐富的材料制成的替代物,其運行速度相當(dāng)快。
Stability AI推出迄今為止更小、更高效的1.6B語言模型
Stability AI 宣布推出迄今為止最強大的小語言模型之一 Stable LM 2 1.6B。






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論