 如何設計出一種可以從人臉圖像上移除口罩的ML工具呢?
如何設計出一種可以從人臉圖像上移除口罩的ML工具呢?

今天的大街上戴口罩的人越來越多,你可能會想:他們摘了口罩都長什么樣呢?至少我們 STRV 機器學習(ML)團隊就有這樣的疑問。作為一個機器學習團隊,我們很快意識到問題比想象中更容易解決。
想知道我們是如何設計出一種可以從人臉圖像上移除口罩的 ML 工具的嗎?
本文將指導你完成構建深度學習 ML 模型的整個過程——從初始設置、數據收集和選擇適當的模型,到訓練和微調。
在深入研究之前,我們先來定義任務的性質。我們試圖解決的問題可以看作是 圖像修復,也就是恢復受損圖像或填充缺失部分的過程。下面就是圖像修復的例子:輸入的圖像有一些白色缺失,經過處理這些缺失被補足了。
使用部分卷積進行圖像修復的示例
解決完定義的問題后我們再提一點:除了本文之外,我們還準備了一個 GitHub 帳戶,其中包含你需要的所有內容實現,以及 Jupyter Notebook“mask2face.ipynb”,你可以在其中運行本文提到的所有內容。只需單擊幾下,即可訓練你自己的神經網絡。
接下來,讓我們正式開始吧。
一、準備工作
如果你想在計算機上執行本文所述的所有步驟,可以克隆此項目。
首先,我們來為 Python 項目準備虛擬環境。你可以使用你喜歡的任何虛擬環境,只要確保從 environment.yml 和 requirements.txt 安裝所有必需的依賴項即可。如果你熟悉 Conda,還可以在克隆的 GitHub 項目目錄中運行以下命令來初始化 Conda 環境:
conda env create -f environment.yml conda activate mask2face
現在,你已經有了一個帶有所有必需依賴項的環境,接下來我們來定義目標和目的。對于這個項目,我們想要創建一個 ML 模型,該模型可以向我們展示戴口罩的人摘下口罩的樣子。我們的模型有一個輸入——戴口罩的人的圖像;一個輸出——摘下口罩的人的圖像。
二、實現 1. 高層 ML 管道
下圖很好地展示了整個項目的高層管道。
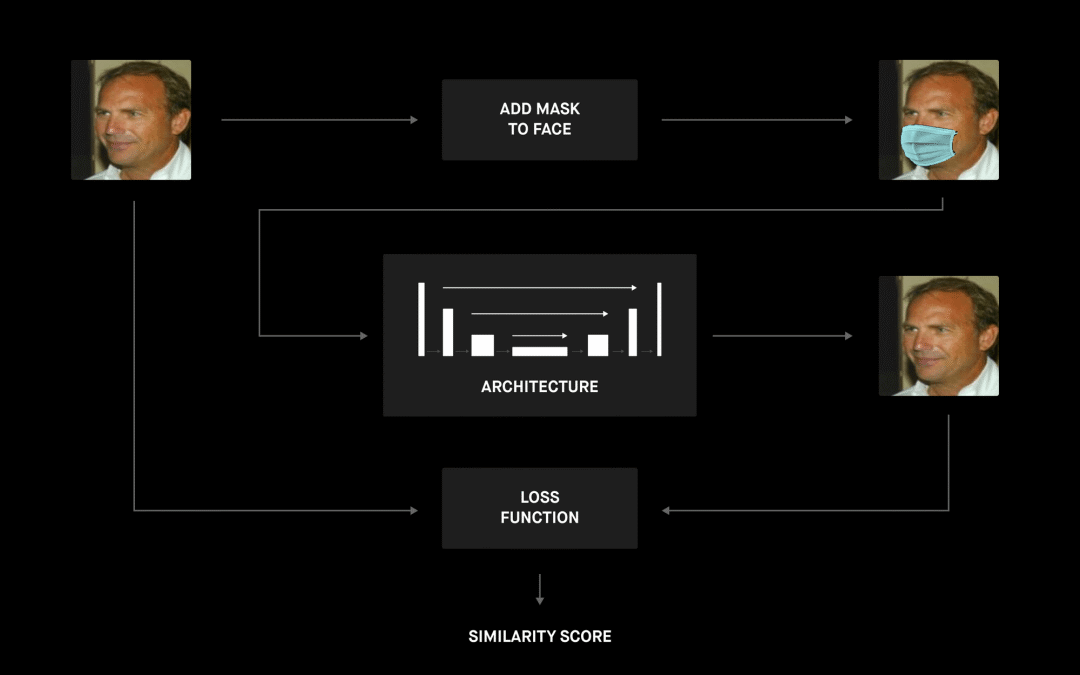
我們從一個帶有預先計算的面部界標的面部數據集開始,該數據集是通過口罩生成器處理的,它使用這些界標將口罩放在臉上。現在我們有了帶有成對圖像(戴和不戴口罩)的數據集,我們就可以繼續定義 ML 模型的架構了。管道的最后一部分是找到最佳損失函數和組成各個部分的所有必要腳本,以便我們可以訓練和評估模型。
2. 數據生成
要想訓練這個深度學習模型,我們需要采用大量數據,也就是大量輸入和輸出的圖像對。當然,要收集每個人戴口罩 / 不戴口罩的輸入和輸出圖像是不切實際的。
當前,市面上有很多人臉圖像數據集,主要用于訓練人臉檢測算法。我們可以采用這樣的數據集,在人臉上繪制口罩——于是我們就有了圖像對。
我們嘗試了兩個數據集。其中一個數據庫是馬薩諸塞大學[1] 的現實世界人臉標記數據集。這里是它的 104MB gzip 壓縮 tar 文件,其中包含整個數據集,超過 5,000 張圖片。這個數據集非常適合我們的情況,因為它包含的圖像主要都是人臉。但對于最終結果,我們使用了 CelebA 數據集,它更大(200,000 個樣本),并且包含更高質量的圖像。
接下來,我們需要定位面部界標,以便將口罩放置在正確的位置。為此,我們使用了一個預訓練的 dlib 面部界標檢測器。你可以使用其他任何類似的數據集,只要確保你可以找到預計算的面部界標點或自己計算界標。
3. 口罩生成器
一開始,我們做了一個口罩生成器的簡單實現,將一個多邊形放置在臉上,使多邊形頂點與面部界標的距離隨機化。這樣我們就可以快速生成一個簡單的數據集,并測試項目背后的想法是否可行。一旦確定它確實有效,我們就開始尋找一種更強大的解決方案,以更好地反映現實場景。
GitHub 上有一個很棒的項目 Mask The Face,已經解決了口罩生成問題。它從臉部界標點估計口罩位置,估計臉部傾斜角度以從數據庫中選擇最合適的口罩,最后將口罩放置在臉上。可用的口罩數據庫包括了手術口罩、有各種顏色和紋理的布口罩、幾種呼吸器,甚至是防毒面罩。
import matplotlib.pyplot as plt import matplotlib.image as mpimg from utils.data_generator import DataGenerator from utils.configuration import Configuration # You can update configuration.json to change behavior of the generator configuration = Configuration() dg = DataGenerator(configuration) # Generate images dg.generate_images() # Plot a few examples of image pairs n_examples = 5 inputs, outputs = dg.get_dataset_examples(n_examples) f, axarr = plt.subplots(2, n_examples, figsize=(20,10)) for i in range(len(inputs)): axarr[1, i].imshow(mpimg.imread(inputs[i])) axarr[0, i].imshow(mpimg.imread(outputs[i]4. 架構
現在我們已經準備好了數據集,是時候搭建深度神經網絡模型架構了。在這項工作中,絕對沒有人可以聲稱有一個客觀的“最佳”選項。
選擇合適架構的過程總是取決于許多因素,例如時間要求(你要實時處理視頻還是要離線預處理一批圖像?)、硬件需求(模型應在搭載高性能 GPU 的群集上運行,還是要在低功耗移動設備上運行?)等等。每次你都要尋找正確的參數,并針對你的具體情況進行設置。
5. 卷積神經網絡
卷積神經網絡(CNN)是一種利用卷積核過濾器的神經網絡架構。它適用于各種問題,例如時間序列分析、自然語言處理和推薦系統,但主要用于各種圖像相關的用途,例如對象分類、圖像分割、圖像分析和圖像修復。
CNN 的核心是能夠檢測輸入圖像視覺特征的卷積層。當我們一層層堆疊多個卷積層時,它們傾向于檢測不同的特征。第一層通常會提取更復雜的特征,例如邊角或邊緣。當你深入 CNN 時,卷積層將開始檢測更高級的特征,例如對象、面部等。
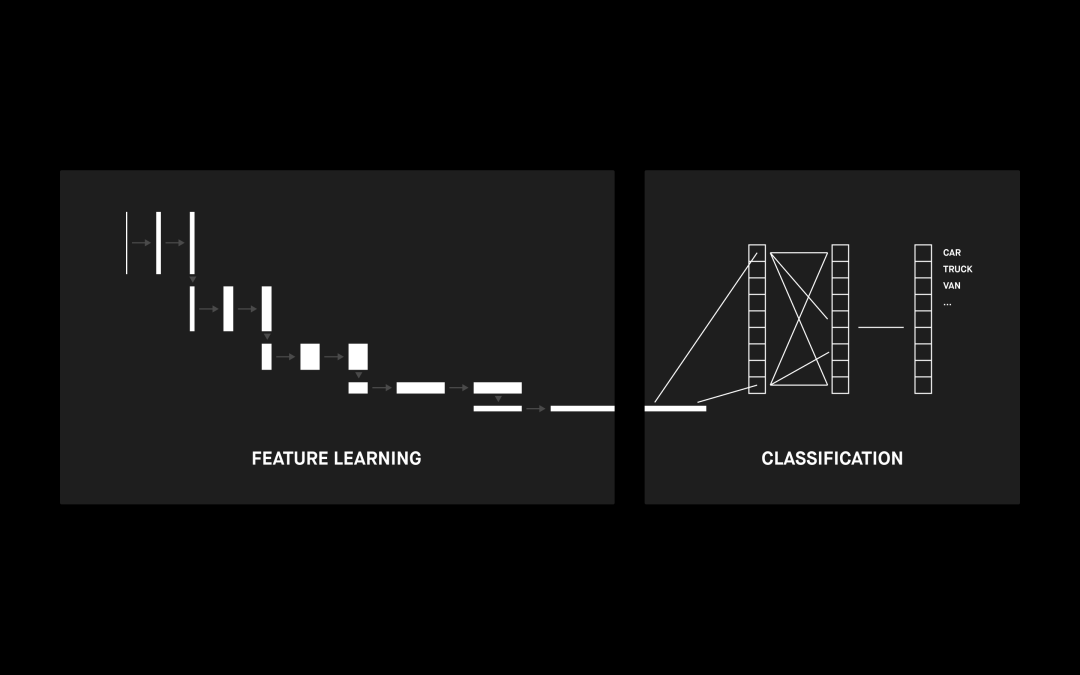
CNN 架構示例
上圖顯示了用于圖像檢測的 CNN 示例。這并不是我們要解決的問題,但 CNN 架構是任何修復架構的必要組成部分。
6.ResNet 塊
在討論修復架構之前,我們先來談談起作用的構建塊,它們稱為 ResNet 塊或殘差塊。在傳統的神經網絡或 CNN 中,每一層都連接到下一層。在具有殘差塊的網絡中,每一層也會連接到下一層,但還會再連接兩層或更多層。我們引入了 ResNet 塊以進一步提高性能,后文會具體介紹。
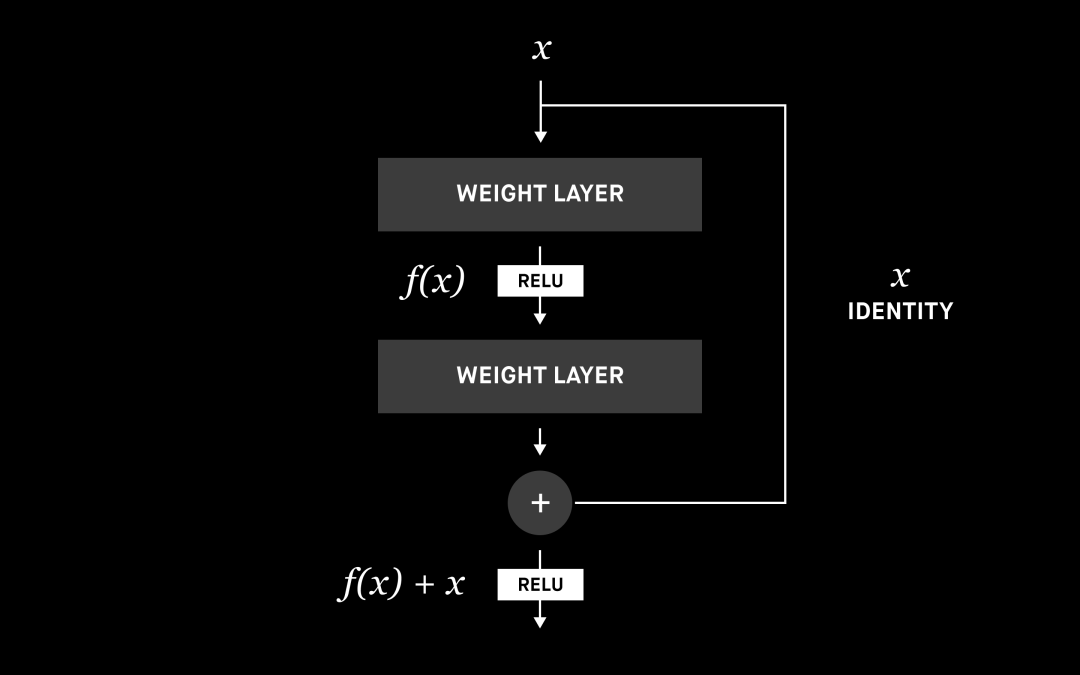
ResNet 構建塊 [7]
神經網絡能夠估計任何函數,我們可以認為增加層數可以提高估計的準確性。但由于諸如梯度消失或維數詛咒之類的問題,層數增加到一定程度就不會繼續提升性能了,甚至會讓性能倒退。這就是為什么有很多研究致力于解決這些問題,而性能最好的解決方案之一就是殘差塊。
殘差塊允許使用跳過連接或標識函數,將信息從初始層傳遞到下一層。通過賦予神經網絡使用標識函數的能力,相比單純地增加層數,我們可以構建性能更好的網絡。你可以在參考資料中閱讀有關 ResNet 及其變體的更多信息。[8]
7. 編碼器 - 解碼器
編碼器 - 解碼器架構由兩個單獨的神經網絡組成:編碼器提取輸入(嵌入)的一個固定長度表示,而解碼器從該表示生成輸出。
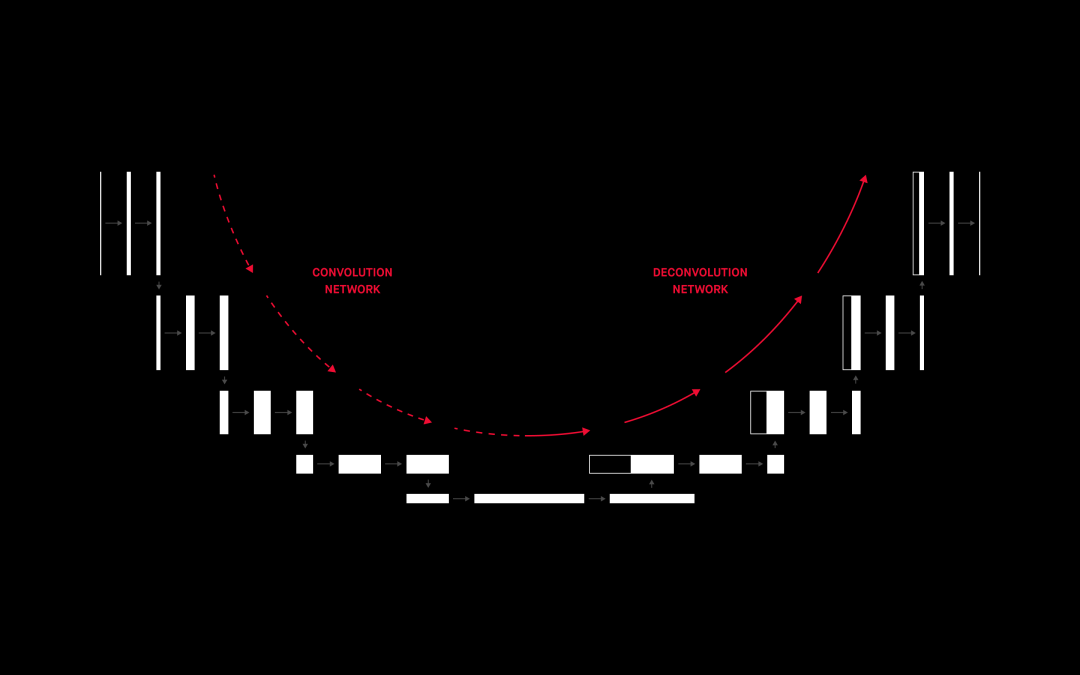
用于圖像分割的編碼器 - 解碼器網絡 [6]
你會注意到,編碼器部分與上一節中描述的 CNN 非常相似。經過驗證的分類 CNN 通常用作編碼器的基礎,甚至直接用作編碼器,只是沒有最后一個(分類)層。這個架構可以用來生成新圖像,這正是我們所需要的。但它的性能卻不是那么好,因此我們來看一下更好的東西。
8.U-net
U-net 最初是為圖像分割而開發的卷積神經網絡架構[2],但它在其他許多任務(例如圖像修復或圖像著色)中也展示了自己的能力。
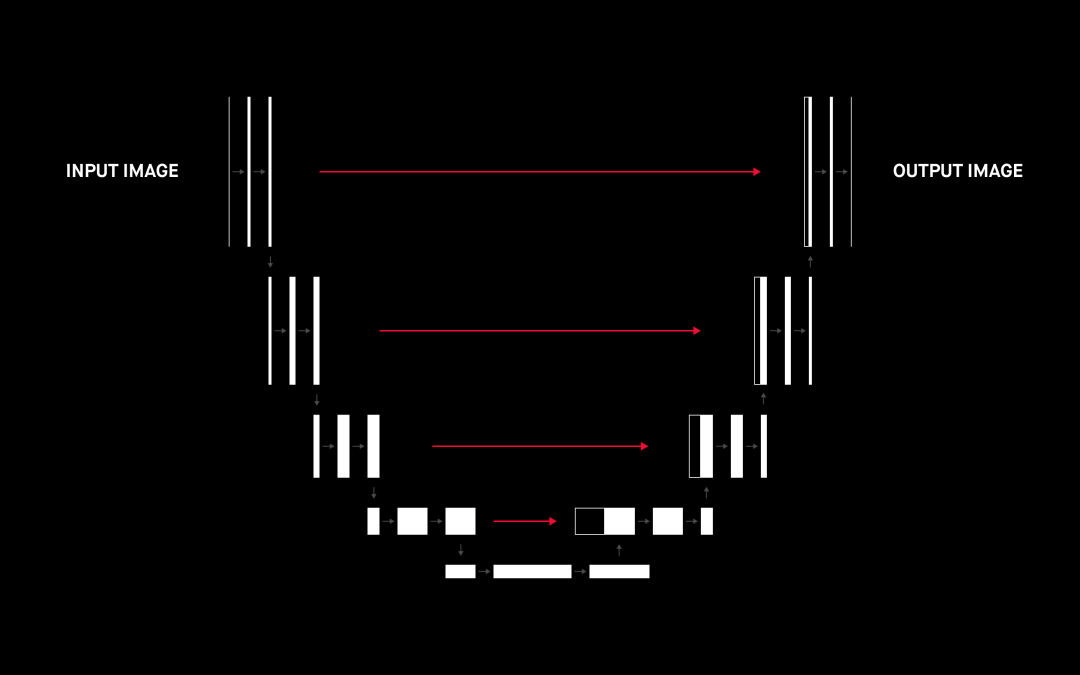
原始文章中的 U-net 架構 [2]
我們前面之所以提到 ResNet 塊有一個重要原因。事實上,將 ResNet 塊與 U-net 架構結合使用對整體性能的影響最大。你可以在下圖中看到添加 ResNet 塊的架構。
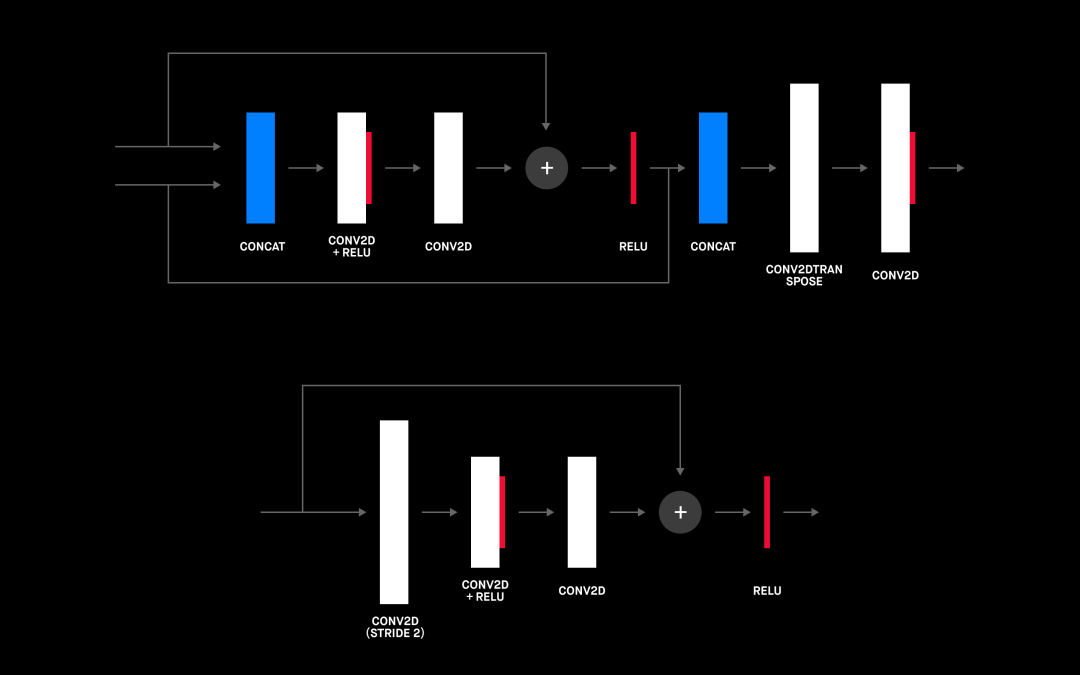
U-net 中使用的 Upscale ResNet 塊(頂部)和 downscale resNet 塊(底部)
當你將上面的 U-net 架構與上一節中的編碼器 - 解碼器架構進行比較時,它們看起來非常相似,但有一個關鍵的區別:U-net 實現了一種稱為“跳過連接”的功能,該功能將 identity 從反卷積塊傳播到另一側對應的上采樣塊(上圖中的灰色箭頭)。這是對編碼器 - 解碼器架構的兩處顯著改進。
首先,已知跳過連接可以加快學習過程并幫助解決梯度消失問題[5];其次,它們可以將信息從編碼器直接傳遞到解碼器,從而有助于減少下采樣期間的信息丟失。我們可以認為它們能傳播我們希望保持不變的口罩外部圖像的所有部分,同時還有助于生成口罩下面的臉部圖像。
這正是我們所需要的!跳過連接將有助于保留我們要傳播到輸出的部分輸入,而 U-net 的編碼器 - 解碼器部分將檢測到口罩并將其替換為下面的嘴部圖像。
9. 損失函數
如何選擇損失函數是你需要解決的最重要的問題之一,使用正確的損失函數可能會得到性能出色的模型,反之就會得到令人失望的模型。這就是我們花很多時間選擇最佳模型的原因所在。下面,我們來討論幾種選項。
均方誤差(MSE)和均值絕對誤差(MAE)
MSE 和 MAE 都是損失函數,都基于我們模型生成的圖像將口罩應用到面部之前。這似乎正是我們所需要的,但我們并不打算訓練可以像素級完美重現口罩下隱藏內容的模型。
我們希望我們的模型理解口罩下面是嘴巴和鼻子,甚至可能要理解來自那些未被隱藏的事物(例如眼睛)所包含的情感,從而生成悲傷的、快樂的或可能是驚訝的面孔。這意味著,即使不能完美地捕獲每個像素,實際上也可以產生一個很好的結果;更重要的是,它可以學習如何在任何臉部上泛化,而不僅僅是對訓練數據集中的面孔進行泛化。
結構相似性指數(SSIM)
SSIM 是用于度量兩個圖像之間相似度的度量標準,由 Wang 等人在 2004 年提出[3]。它專注于解決 MSE/MAE 所存在的問題。它提供了一個數值表達式,用來展示兩張圖像之間的相似度。它通過對比圖像之間的三個測量值來做到這一點:亮度、對比度和結構。最終得分是所有三個測量值的加權組合,分數從 0 到 1,1 表示圖像完全相同。
MSE 存在的問題:左上圖是未經修改的原始圖像;其他圖像均有不同形式的失真。原始圖像與其他圖像之間的均方誤差大致相同(大約 480),而 SSIM 的變化很大。例如,模糊圖像和分割后的圖像與原始圖像的相似度絕對不如其他圖像,但 MSE 幾乎相同——盡管面部特征和細節丟失了。另一方面,偏色圖像和對比度拉伸的圖像與人眼中的原始圖像非常相似(SSID 指標也是一樣),但 MSE 表示不同意這個結論。
三、結果 訓練
我們使用 ADAM 優化器和 SSIM 損失函數,通過 U-net 架構對模型進行訓練,將數據集分為測試部分(1,000 張圖像)、訓練部分(其余 80%的數據集)和驗證部分(其余 80%的數據集)。我們的第一個實驗為幾張測試圖像生成了不錯但不太清晰的輸出圖像。是時候嘗試使用架構和損失函數來提高性能了,下面是我們嘗試的一些更改:卷積過濾器的層數和大小。
更多的卷積過濾器和更深的網絡意味著更多的參數(大小為[8、8、256] 的 2D 卷積層具有 59 萬個參數,大小為[4、4、512] 的層具有 230 萬個參數)和更多的訓練時間。由于每層中過濾器的深度和數量是我們模型架構的構造器的輸入參數,因此使用不同的值進行實驗非常容易。
嘗試一段時間后,我們發現對我們而言,以下設置可以達到性能和模型大小之間的最佳平衡:
# Train model with different number of layers and filter sizes from utils.architectures import UNet from utils.model import Mask2FaceModel # Feel free to experiment with the number of filters and their sizes filters = (64, 128, 128, 256, 256, 512) kernels = ( 7, 7, 7, 3, 3, 3) input_image_size=(256, 256, 3) architecture = UNet.RESNET training_epochs = 20 batch_size = 12 model = Mask2FaceModel.build_model(architecture=architecture, input_size=input_image_size, filters=filters, kernels=kernels) model.summary() model.train(epochs=training_epochs, batch_size=batch_size, loss_function='ssim_l1_loss'
我們做了一些實驗,上面代碼塊中的設置對我們來說是最好的。
現在,我們已經通過上述調整對模型進行了訓練和調整,
如你所見,給定的網絡在我們的測試數據上生成了很好的結果。這個網絡具有泛化能力,并且似乎 可以很好地識別情緒,從而生成微笑或悲傷的面孔。另一方面,這里當然也有改進的空間。
四、進一步改進的想法
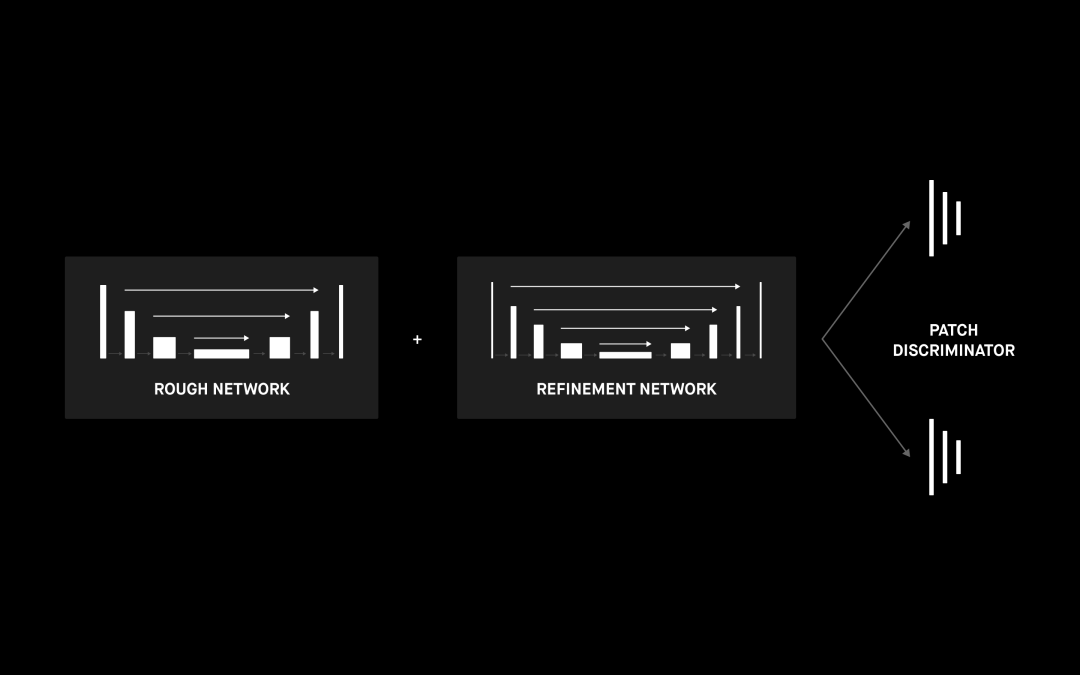
雖說使用 ResNet 塊的 U-net 網絡效果很好,但我們也可以看到生成的摘口罩圖像不是很清晰。一種解決方法是用一個提煉網絡擴展我們的網絡,如[4] 中和下圖中所述。此外還可以進行其他一些改進。
1. 改善數據集
根據我們實驗中獲取的經驗。數據集的選擇可以對結果產生重大影響。下一步,我們將合并不同的數據集以使樣本具有更大的多樣性,從而更好地模擬現實世界的數據。另一項可行改進是調整將口罩與面部組合的方式,使它們看起來更自然。[12] 是很好的靈感來源。
2. 變分自動編碼器
我們已經提到了編碼器 - 解碼器架構,其中編碼器部分將輸入圖像映射到嵌入中。我們可以將嵌入視為多維潛在空間中的單點。在許多方面,變分自動編碼器與編碼器 - 解碼器是很像的;主要的區別可能是變分自動編碼器的映射是圍繞潛在空間的一點完成的多元正態分布。這意味著編碼在設計上是連續的,可以實現更好的隨機采樣和內插。這可能會極大地改善網絡輸出生成圖像的平滑度。
3. 生成對抗網絡
GAN 能夠生成與真實照片無法區分的結果,這主要歸功于完全不同的學習方法。我們當前的模型試圖將訓練過程中的損失降到最低,而 GAN 還是由兩個獨立的神經網絡組成:生成器和鑒別器。生成器生成輸出圖像,而鑒別器嘗試確定圖像是真實圖像還是由生成器生成。
在學習過程中,兩個網絡都會動態更新,讓表現越來越好,直到最后鑒別器無法確定所生成的圖像是否真實,生成器所生成的圖像就與真實圖像無法區分了。
GAN 的結果很好,但在訓練過程中通常會出現收斂問題,而且訓練時間很長。由于參數眾多,GAN 模型通常也要復雜得多,因此不太適合導出到手機上。
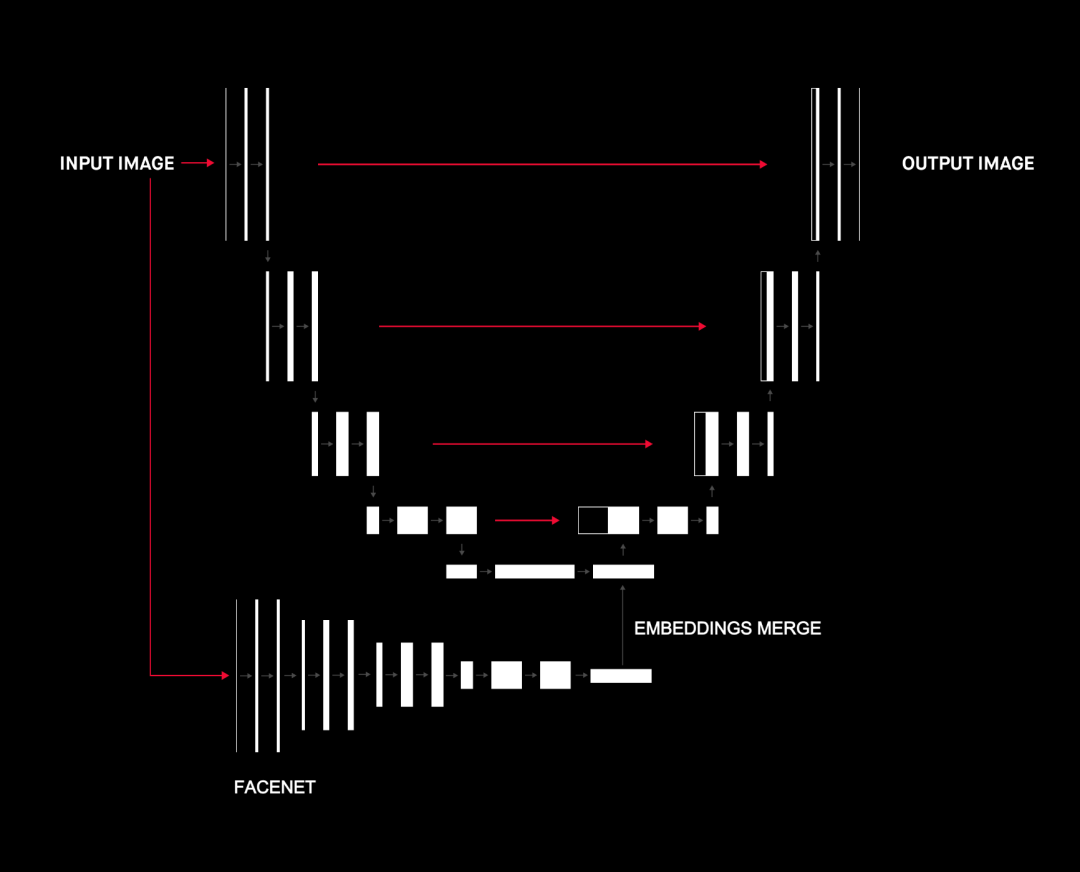
4.Concat ImageNet 和 FaceNet 嵌入
在許多方面,U-net 的瓶頸層都可以用作特征提取嵌入。[10]、[11] 等文章建議,將不同網絡的嵌入并置可以提高整體性能。
我們嘗試將嵌入(瓶頸層)與 ImageNet 和 FaceNet 的兩種不同嵌入結合在一起。我們期望這可以添加有關人臉及其特征的更多信息,以幫助 U-net 的上采樣部分進行人臉修復。這無疑提高了性能,但另一方面,它使整個模型更加復雜,并且與“訓練”部分中提到的其他改進相比,其性能提升要小得多。
五、總結
這種人臉重建面臨許多挑戰。我們發現,要想獲得最佳結果,就需要一種創新的方法來融合各種數據集和技術。我們必須適當地解決諸如遮擋、照明和姿勢多樣性等具體問題。問題無法解決的話,在傳統的手工解決方案和深度神經網絡中都會有顯著的精度下降,方案最后可能只能處理一類照片。
但正是這些挑戰讓我們發現這個項目非常具有吸引力。
我們著手創建 Mask2Face 的原因是要為我們的 ML 部門打造一個典型示例。我們觀察世界上正在發生的事情(口罩檢測),并尋找不怎么常見的路徑(摘下口罩)。任務越難,學到的經驗越多。ML 的核心目標是解決看似不可能的問題,我們希望一直遵循這一理念。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1173瀏覽量
41896 -
編碼器
+關注
關注
45文章
3789瀏覽量
137800 -
虛擬機
+關注
關注
1文章
966瀏覽量
29280 -
機器學習
+關注
關注
66文章
8500瀏覽量
134459 -
python
+關注
關注
56文章
4826瀏覽量
86580
原文標題:如何利用AI識別口罩下的人臉?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
《DNK210使用指南 -CanMV版 V1.0》第四十二章 人臉口罩佩戴檢測實驗
怎么解決口罩狀態下 iphone 的人臉識別呢?
介紹一種Arm ML嵌入式評估套件
是否可以在Sensortile.box工具上運行多種神經網絡呢
一種基于Haar小波變換的彩色圖像人臉檢測方法
一種基于變分自編碼器的人臉圖像修復方法








 工商網監
工商網監
評論