") 首個(gè)線性注意力Transformer大模型!1750億參數(shù),速度和精度更優(yōu)
首個(gè)線性注意力Transformer大模型!1750億參數(shù),速度和精度更優(yōu)
GPT 等大型語(yǔ)言模型(LLM)的成功離不開(kāi) Softmax 注意力機(jī)制,但這一機(jī)制也存在著成本高等一些缺點(diǎn)。
近日,上海人工智能實(shí)驗(yàn)室和 OpenNLPLab 的一個(gè)研究團(tuán)隊(duì)提出了一種新的大型語(yǔ)言模型 TransNormerLLM,其中完全拋棄了基于 Softmax 的注意力機(jī)制,而是使用了新提出的線性注意力。據(jù)介紹,TransNormerLLM 是首個(gè)基于線性注意力的大型語(yǔ)言模型(LLM),其在準(zhǔn)確度和效率方面的表現(xiàn)優(yōu)于傳統(tǒng)的基于 Softmax 注意力的模型。研究者也將發(fā)布其預(yù)訓(xùn)練模型的開(kāi)源版本。

論文:https://arxiv.org/abs/2307.14995
模型:https://github.com/OpenNLPLab/TransnormerLLM
大型語(yǔ)言模型已經(jīng)為自然語(yǔ)言處理(NLP)領(lǐng)域帶來(lái)了變革。它們能出色地處理許多不同類型的任務(wù),提升了在計(jì)算框架中使用人類語(yǔ)言進(jìn)行理解、生成和交互的能力。之前語(yǔ)言建模的發(fā)展主要圍繞 Transformer 架構(gòu),其中堪稱支柱的模型包括基本的 Transformer、GPT 系列、BERT 和 BART 等開(kāi)創(chuàng)性的模型。Transformer 架構(gòu)的成功立足于 softmax 注意力機(jī)制,該機(jī)制可以識(shí)別出數(shù)據(jù)驅(qū)動(dòng)的模型方案中輸入 token 之間的依賴關(guān)系,其還能感知全局位置,讓模型能有效處理自然語(yǔ)言的長(zhǎng)程動(dòng)態(tài)情況。
即便如此,傳統(tǒng)的 Transformer 依然存在局限。首要的一點(diǎn),它們有著對(duì)于序列長(zhǎng)度的二次時(shí)間復(fù)雜度,這會(huì)限制它們的可擴(kuò)展性并拖累訓(xùn)練和推理階段的計(jì)算資源和時(shí)間效率。為了將這種二次時(shí)間復(fù)雜性簡(jiǎn)化至線性復(fù)雜性,已經(jīng)有不少研究者提出了多種不同的序列建模方法。但是,這些方法卻難以用于 LLM,原因有二:1) 它們?cè)谡Z(yǔ)言建模任務(wù)上的表現(xiàn)往往不如人意;2) 它們?cè)谡鎸?shí)世界場(chǎng)景中并沒(méi)有展現(xiàn)出速度優(yōu)勢(shì)。
這篇論文提出的 TransNormerLLM 是首個(gè)基于線性注意力的 LLM,其在準(zhǔn)確度和效率方面都優(yōu)于傳統(tǒng)的 softmax 注意力。TransNormerLLM 的構(gòu)建基于之前的線性注意力架構(gòu) TransNormer,同時(shí)也做了一些修改讓性能更優(yōu)。TransNormerLLM 中關(guān)鍵性的改進(jìn)包括位置嵌入、線性注意力加速、門控機(jī)制、張量歸一化和推理加速。
其中值得格外注意的一項(xiàng)改進(jìn)是將 TransNormer 的 DiagAttention 替換成線性注意力,從而可提升全局的互動(dòng)性能。研究者還引入了帶指數(shù)衰減的 LRPE 來(lái)解決 dilution 問(wèn)題。此外,研究者還引入了 Lightning Attention(閃電注意力)這種全新技術(shù),并表示其可以將線性注意力在訓(xùn)練時(shí)的速度提升兩倍,并且其還能通過(guò)感知 IO 將內(nèi)存用量減少 4 倍。不僅如此,他們還簡(jiǎn)化了 GLU 和歸一化方法,而后者將整體的速度提升了 20%。他們還提出了一種穩(wěn)健的推理算法,可以在不同的序列長(zhǎng)度下保證數(shù)值穩(wěn)定和恒定的推理速度,由此能提升模型在訓(xùn)練和推理階段的效率。
為了驗(yàn)證 TransNormerLLM 的效果,研究者精心收集了一個(gè)大型語(yǔ)料庫(kù),其大小超過(guò) 6TB,token 數(shù)更是超過(guò) 2 萬(wàn)億。為了確保數(shù)據(jù)的質(zhì)量,他們還開(kāi)發(fā)了一種用于過(guò)濾所收集語(yǔ)料庫(kù)的自清理(self-cleaning)策略。如表 1 所示,研究者對(duì)原始 TransNormer 模型進(jìn)行了擴(kuò)展,得到了參數(shù)量從 3.85 億到 1750 億的多個(gè) TransNormerLLM 模型。然后他們基于新的大型語(yǔ)料庫(kù)進(jìn)行了全面實(shí)驗(yàn)和控制變量研究,結(jié)果表明新方法的性能優(yōu)于基于 softmax 注意力的方法并且還有更快的訓(xùn)練和推理速度。
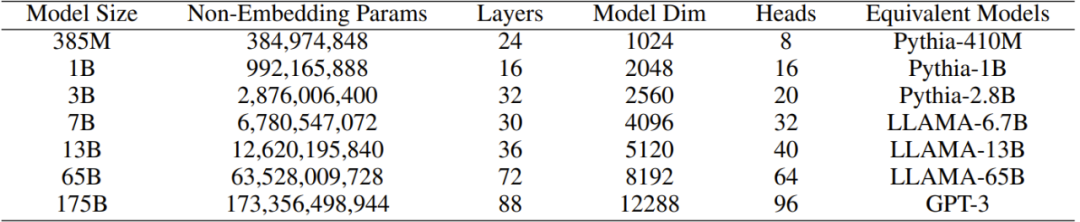
表 1:TransNormerLLM 模型的多種變體
為了促進(jìn) LLM 領(lǐng)域的研究,上海人工智能實(shí)驗(yàn)室和 OpenNLPLab 的這些研究者也將開(kāi)源自己的預(yù)訓(xùn)練模型,他們表示這是為了「讓研究者和實(shí)踐者基于我們的成果構(gòu)建應(yīng)用以及探索用于 LLM 的高效 transformer 結(jié)構(gòu)」。
TransNormerLLM
架構(gòu)改進(jìn)
下面將簡(jiǎn)單介紹 TransNormerLLM 的各個(gè)模塊以及研究者提出的一些改進(jìn)措施。
改進(jìn)一:位置編碼
TransNormer 中的較低層使用了 DiagAttention 來(lái)避免 dilution 問(wèn)題。但是,這會(huì)導(dǎo)致 token 之間缺乏全局互動(dòng)能力。為了解決這個(gè)問(wèn)題,研究者為 TransNormerLLM 使用了帶指數(shù)衰減的 LRPE(線性化相對(duì)位置編碼),從而可在較低層保留完整的注意力。研究者把這種方法稱為 LRPE-d。
改進(jìn)二:門控機(jī)制
門控可以增強(qiáng)模型的性能并使訓(xùn)練過(guò)程平滑。研究者為 TransNormerLLM 使用了來(lái)自論文《Transformer quality in linear time》的 Flash 方法并在 token 混合中使用了門控式線性注意力(GLA)的結(jié)構(gòu)。
為了進(jìn)一步提升模型速度,他們還提出了 Simple GLU(SGLU),其去除了原始 GLU 結(jié)構(gòu)的激活函數(shù),因?yàn)殚T本身就能引入非線性。
改進(jìn)三:張量歸一化
研究者使用了 TransNormer 中引入的 NormAttention。在 TransNormerLLM 中,他們使用一種新的簡(jiǎn)單歸一化函數(shù) SimpleRMSNorm(簡(jiǎn)寫為 SRMSNorm)替換了 RMSNorm。
整體結(jié)構(gòu)
圖 1 展示了 TransNormerLLM 的整體結(jié)構(gòu)。
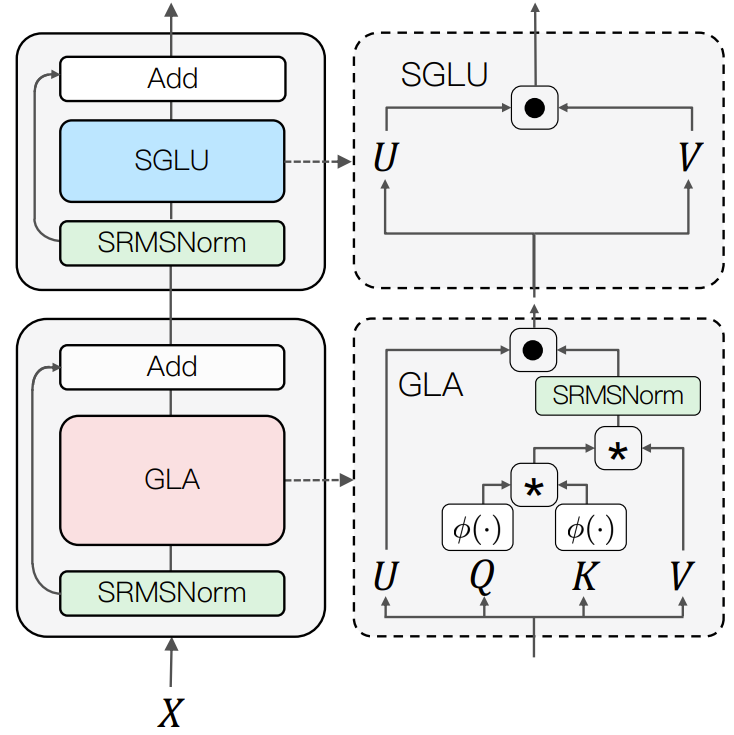
圖 1:新提出模型的整體架構(gòu)
在該結(jié)構(gòu)中,輸入 X 的更新通過(guò)兩個(gè)連續(xù)步驟完成:首先,其通過(guò)使用了 SRMSNorm 歸一化的門控式線性注意力(GLA)模塊。然后,再次通過(guò)使用了 SRMSNorm 歸一化的簡(jiǎn)單門控式線性單元(SGLU)模塊。這種整體架構(gòu)有助于提升模型的性能表現(xiàn)。下方給出了這個(gè)整體流程的偽代碼:
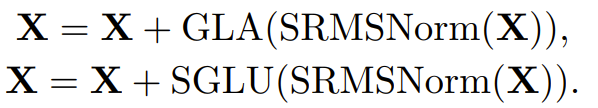
訓(xùn)練優(yōu)化
閃電注意力
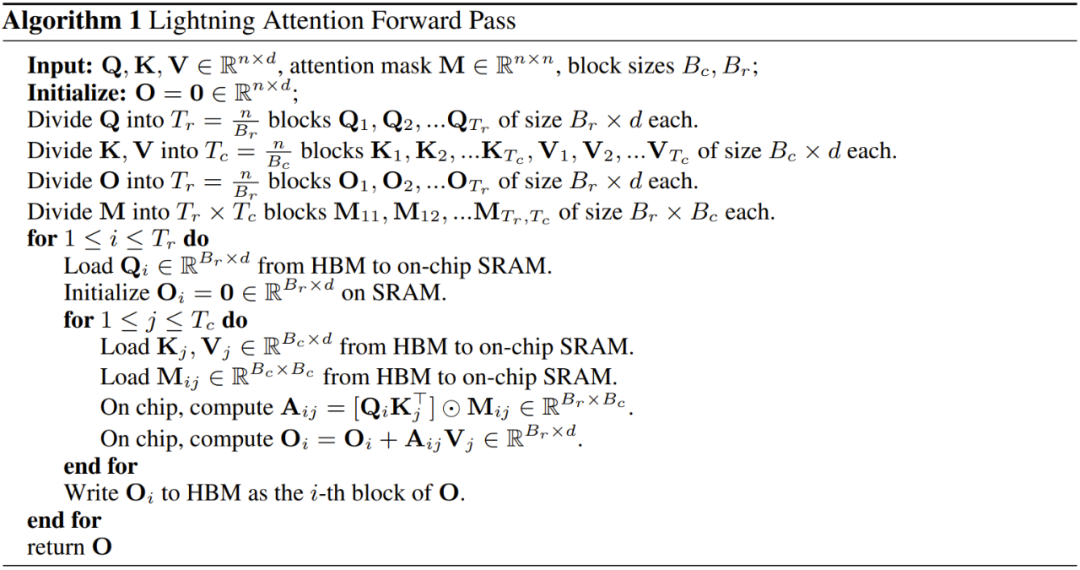
為了加快注意力計(jì)算速度,研究者引入了閃電注意力(Lightning Attention)算法,這能讓新提出的線性注意力更適合 IO(輸入和輸出)處理。
算法 1 展示了閃電注意力的前向通過(guò)的實(shí)現(xiàn)細(xì)節(jié),算法 2 則是后向通過(guò)的。研究者表示,他們還有一個(gè)可以更快計(jì)算梯度的實(shí)現(xiàn)版本,這會(huì)在未來(lái)發(fā)布。

模型并行化
為了在計(jì)算機(jī)集群上分散所有模型參數(shù)、梯度和優(yōu)化器狀態(tài)張量,研究者使用了全分片數(shù)據(jù)并行(FSDP/Fully Sharded Data Parallel)。這種策略性分區(qū)方法可減少對(duì)每個(gè) GPU 的內(nèi)存占用,從而優(yōu)化了內(nèi)存利用率。為了進(jìn)一步提高效率,他們使用了激活檢查點(diǎn)(Activation Checkpointing),這可減少后向通過(guò)過(guò)程中緩存在內(nèi)存中的激活數(shù)量。相反,當(dāng)計(jì)算這些梯度時(shí),這些梯度會(huì)被移除并重新計(jì)算。該技術(shù)有助于提升計(jì)算效率和節(jié)省資源。此外,為了在減少 GPU 內(nèi)存消耗的同時(shí)加快計(jì)算速度,研究者還使用了自動(dòng)混合精度(AMP)。
除了上述成果外,研究者還更進(jìn)一步通過(guò)對(duì)線性 transformer 執(zhí)行模型并行化而進(jìn)行了系統(tǒng)工程優(yōu)化,其靈感很大程度上來(lái)自于英偉達(dá)的 Megatron-LM 模型并行化,在傳統(tǒng)的 Transformer 模型中,每個(gè) transformer 層都有一個(gè)自注意力模塊,其后跟著一個(gè)兩層多層感知器(MLP)模塊。當(dāng)使用 Megatron-LM 模型并行性時(shí),是在這兩個(gè)模塊上獨(dú)立使用。類似地,TransNormerLLM 結(jié)構(gòu)也是由兩個(gè)主要模塊構(gòu)成:SGLU 和 GLA;這兩者的模型并行化分開(kāi)執(zhí)行。
穩(wěn)健推理
這讓 TransNormerLLM 能以 RNN 的形式執(zhí)行推理。算法 3 給出了這個(gè)過(guò)程的細(xì)節(jié)。但其中存在數(shù)值精度問(wèn)題。

為了避免這些問(wèn)題,研究者提出了穩(wěn)健推理算法,見(jiàn)算法 4。

原推理算法和穩(wěn)健推理算法得到的結(jié)果是一樣的。
語(yǔ)料庫(kù)
研究者從互聯(lián)網(wǎng)收集了大量可公開(kāi)使用的文本,總大小超過(guò) 700TB。收集到的數(shù)據(jù)經(jīng)由他們的數(shù)據(jù)預(yù)處理程序進(jìn)行處理,如圖 2 所示,留下 6TB 的干凈語(yǔ)料庫(kù),其中包含大約 2 萬(wàn)億 token。為了提供更好的透明度,幫助用戶更好理解,他們對(duì)數(shù)據(jù)源進(jìn)行了分門別類。表 2 給出了具體的類別情況。
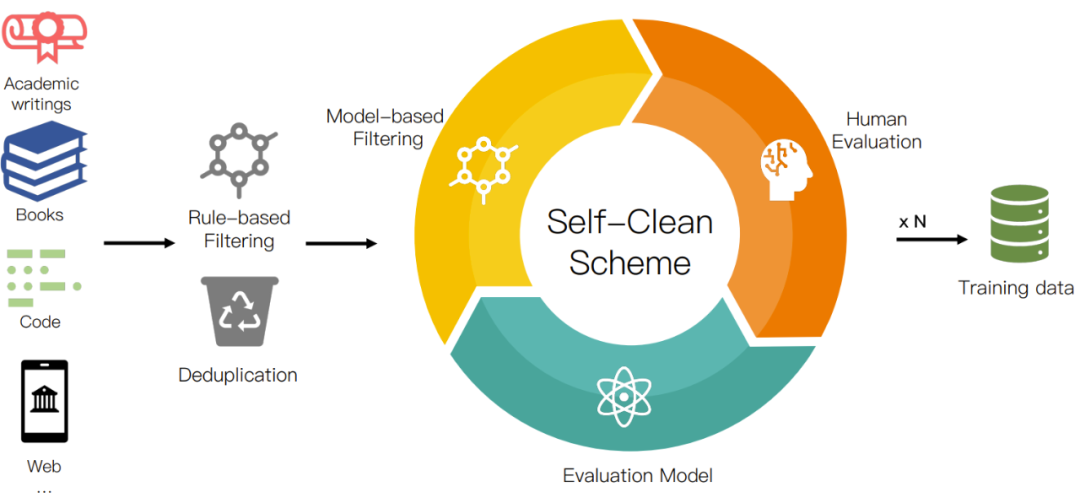
圖 2:數(shù)據(jù)預(yù)處理流程
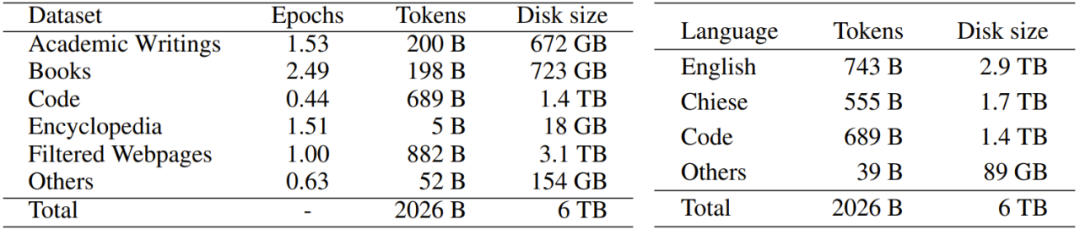
表 2:語(yǔ)料庫(kù)統(tǒng)計(jì)數(shù)據(jù)
實(shí)驗(yàn)
研究者在 Metaseq 框架中使用 PyTorch 和 Trition 實(shí)現(xiàn)了 TransNormerLLM。模型的訓(xùn)練使用了 Adam 優(yōu)化器,F(xiàn)SDP 也被用于高效地將模型擴(kuò)展到 NVIDIA A100 80G 集群。他們也適當(dāng)?shù)厥褂昧四P筒⑿屑夹g(shù)來(lái)優(yōu)化性能。
架構(gòu)消融實(shí)驗(yàn)

表 3:Transformer vs TransNormerLLM。在相同的配置下,當(dāng)模型參數(shù)數(shù)量為 385M 和 1B 時(shí),TransNormerLLM 的性能比 Transformer 分別好 5% 和 9%。
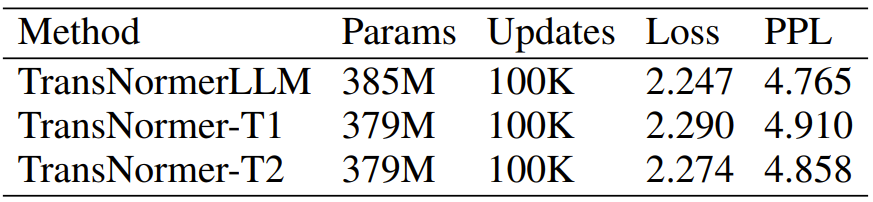
表 4:TransNormer vs TransNormerLLM。TransNormerLLM 的實(shí)驗(yàn)結(jié)果是最好的。

表 5:位置編碼組合使用 LRPE+LRPE-d 得到的結(jié)果最優(yōu)。

表 6:衰減溫度方面的消融實(shí)驗(yàn)結(jié)果。結(jié)果表明新方法更優(yōu)。

表 7:門控機(jī)制方面的消融實(shí)驗(yàn)結(jié)果。使用該門控機(jī)制的模型表現(xiàn)更好。
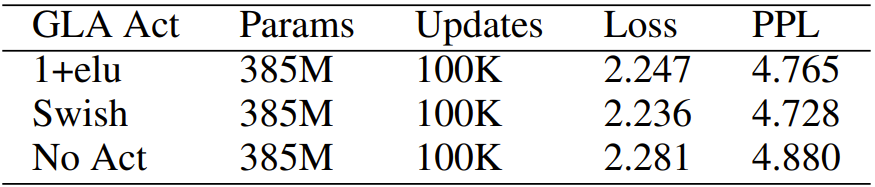
表 8:GLA 激活函數(shù)的消融實(shí)驗(yàn)結(jié)果。用不同激活函數(shù)得到結(jié)果差不多。

表 9:GLU 激活函數(shù)的消融實(shí)驗(yàn)結(jié)果。去除激活函數(shù)對(duì)結(jié)果沒(méi)有負(fù)面影響。
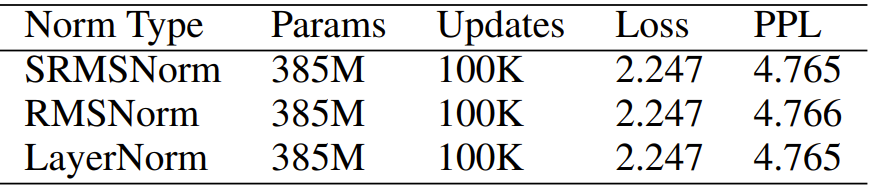
表 10:歸一化函數(shù)。使用以下歸一化函數(shù)的結(jié)果差異不大。
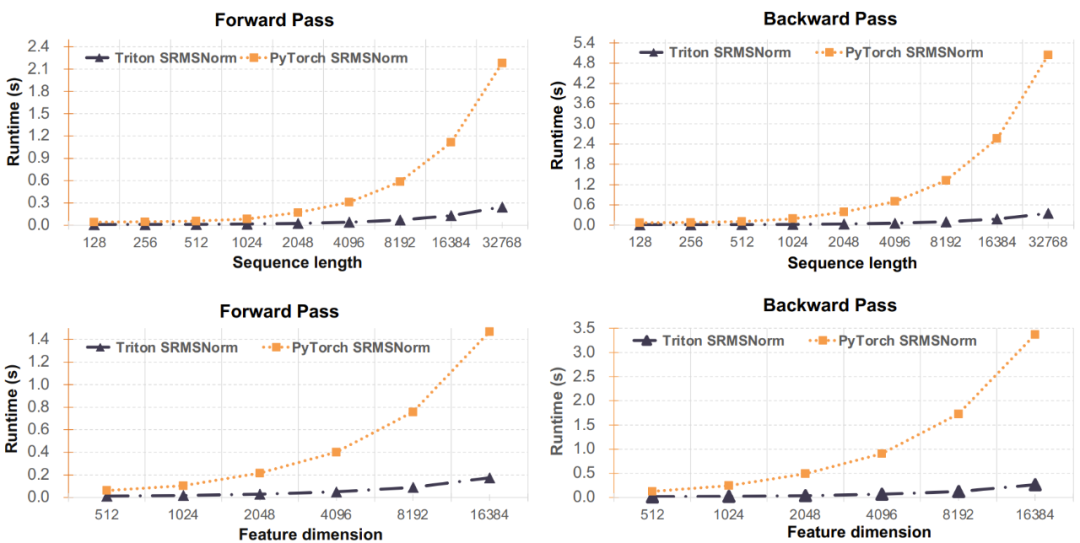
圖 3:對(duì) SRMSNorm 實(shí)現(xiàn)的性能評(píng)估
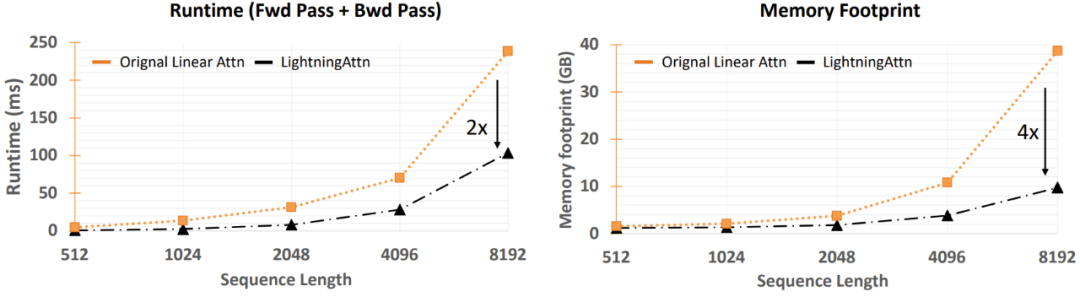
圖 4:線性注意力和閃電注意力之間的內(nèi)存和速度比較
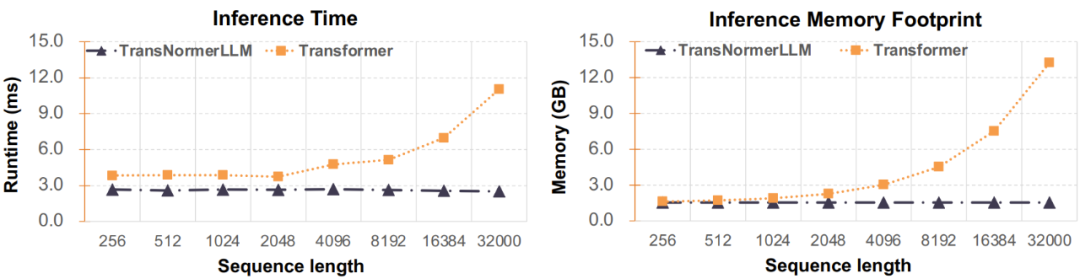
圖 5:推理時(shí)間和內(nèi)存占用情況
系統(tǒng)優(yōu)化
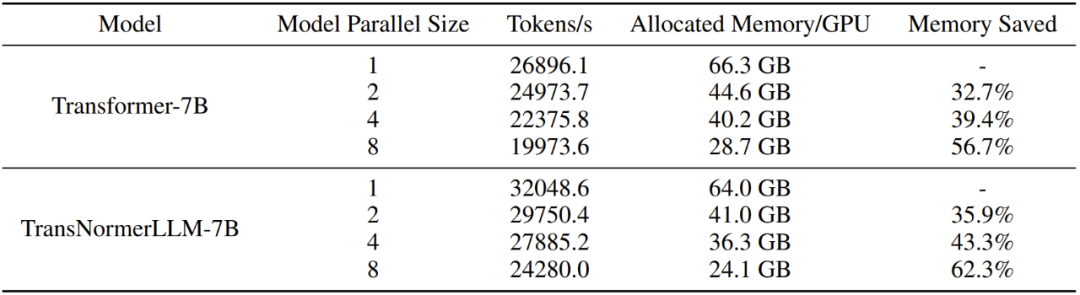
表 11:模型并行性性能
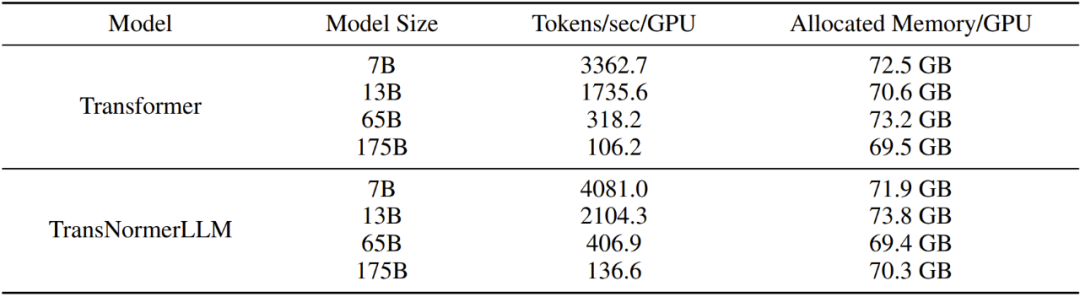
表 12:訓(xùn)練不同大小的模型的效率
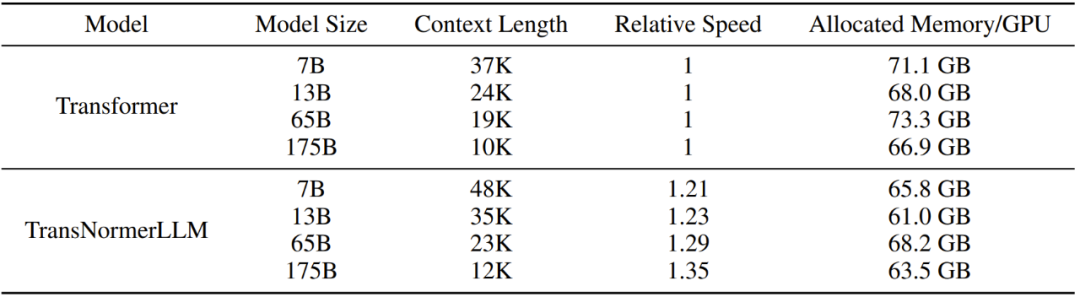
表 13:訓(xùn)練 Transformer 和 TransNormerLLM 的最大上下文長(zhǎng)度
-
線性
+關(guān)注
關(guān)注
0文章
200瀏覽量
25550 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10710 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6427 -
大模型
+關(guān)注
關(guān)注
2文章
3062瀏覽量
3908
原文標(biāo)題:放棄Softmax!首個(gè)線性注意力Transformer大模型!1750億參數(shù),速度和精度更優(yōu)
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
華為助力中國(guó)石油發(fā)布3000億參數(shù)昆侖大模型

如何使用MATLAB構(gòu)建Transformer模型

中國(guó)移動(dòng)與中國(guó)石油發(fā)布700億參數(shù)昆侖大模型
AMD發(fā)布10億參數(shù)開(kāi)源AI模型OLMo
一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)

Llama 3 模型與其他AI工具對(duì)比
未來(lái)AI大模型的發(fā)展趨勢(shì)
英偉達(dá)推出歸一化Transformer,革命性提升LLM訓(xùn)練速度
英偉達(dá)震撼發(fā)布:全新AI模型參數(shù)規(guī)模躍升至80億量級(jí)
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
Transformer語(yǔ)言模型簡(jiǎn)介與實(shí)現(xiàn)過(guò)程
llm模型有哪些格式
Transformer模型在語(yǔ)音識(shí)別和語(yǔ)音生成中的應(yīng)用優(yōu)勢(shì)
使用PyTorch搭建Transformer模型
Transformer 能代替圖神經(jīng)網(wǎng)絡(luò)嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論