") Alluxio是如何助力AI大模型訓(xùn)練的呢?
Alluxio是如何助力AI大模型訓(xùn)練的呢?
一、背景
隨著云原生技術(shù)的飛速發(fā)展,各大公有云廠商提供的云服務(wù)也變得越來(lái)越標(biāo)準(zhǔn)、可靠和易用。憑借著云原生技術(shù),用戶不僅可以在不同的云上低成本部署自己的業(yè)務(wù),而且還可以享受到每一個(gè)云廠商在特定技術(shù)領(lǐng)域上的優(yōu)勢(shì)服務(wù),因此多云架構(gòu)備受青睞。
知乎目前采用了多云架構(gòu),主要是基于以下考慮:
服務(wù)多活:將同一個(gè)服務(wù)部署到不同的數(shù)據(jù)中心,防止單一數(shù)據(jù)中心因不可抗力不能正常提供服務(wù),導(dǎo)致業(yè)務(wù)被 “一鍋端”;
容量擴(kuò)展:一般而言,在公司的服務(wù)器規(guī)模達(dá)到萬(wàn)臺(tái)時(shí),單一數(shù)據(jù)中心就很難支撐業(yè)務(wù)后續(xù)的擴(kuò)容需求了;
降本增效:對(duì)于同一服務(wù),不同云廠商對(duì)同一服務(wù)的定價(jià)和運(yùn)維的能力也不盡相同,我們期望能夠達(dá)到比較理想的狀態(tài),在云服務(wù)滿足我們需求的前提下,盡量享受到低廉的價(jià)格。
知乎目前有多個(gè)數(shù)據(jù)中心,主要的機(jī)房有以下兩個(gè):
在線機(jī)房:主要是部署知乎主站上直接面向用戶的服務(wù)(如評(píng)論、回答等),這部分服務(wù)對(duì)時(shí)延敏感
離線機(jī)房:主要是部署一些離線存儲(chǔ),計(jì)算相關(guān)的服務(wù),對(duì)時(shí)延不敏感,但是對(duì)吞吐要求高。
兩個(gè)數(shù)據(jù)中心之間通過(guò)專線連接,許多重要服務(wù)都依賴于專線進(jìn)行跨機(jī)房調(diào)用,所以維持專線的穩(wěn)定十分重要。專線流量是衡量專線是否穩(wěn)定的重要指標(biāo)之一,如果專線流量達(dá)到專線的額定帶寬,就會(huì)導(dǎo)致跨專線服務(wù)之間的調(diào)用出現(xiàn)大量的超時(shí)或失敗。
一般而言,服務(wù)的吞吐都不會(huì)特別高,還遠(yuǎn)遠(yuǎn)達(dá)不到專線帶寬的流量上限,甚至連專線帶寬的一半都達(dá)不到,但是在我們的算法場(chǎng)景中有一些比較特殊的情況:算法模型的訓(xùn)練在離線機(jī)房,依賴 HDFS 上的海量數(shù)據(jù)集,以及 Spark 集群和機(jī)器學(xué)習(xí)平臺(tái)進(jìn)行大規(guī)模分布式訓(xùn)練,訓(xùn)練的模型結(jié)果存儲(chǔ)在 HDFS 上,一個(gè)模型甚至能達(dá)到數(shù)十上百 GB;在模型上線時(shí),算法服務(wù)會(huì)從在線機(jī)房跨專線讀取離線 HDFS 上的模型文件,而算法服務(wù)一般有數(shù)十上百個(gè)容器,這些容器在并發(fā)讀取 HDFS 上的文件時(shí),很輕易就能將專線帶寬打滿,從而影響其他跨專線服務(wù)。

二、多 HDFS 集群
在早期,我們解決算法模型跨機(jī)房讀取的方式非常簡(jiǎn)單粗暴,部署一套新的 HDFS 集群到在線機(jī)房供算法業(yè)務(wù)使用,業(yè)務(wù)使用模型的流程如下:
1) 產(chǎn)出模型:模型由 Spark 集群或機(jī)器學(xué)習(xí)平臺(tái)訓(xùn)練產(chǎn)出,存儲(chǔ)到離線 HDFS 集群;
2) 拷貝模型:模型產(chǎn)出后,由離線調(diào)度任務(wù)定時(shí)拷貝需要上線的模型至在線 HDFS 集群;
3) 讀取模型:算法容器從在線 HDFS 集群讀取模型上線。
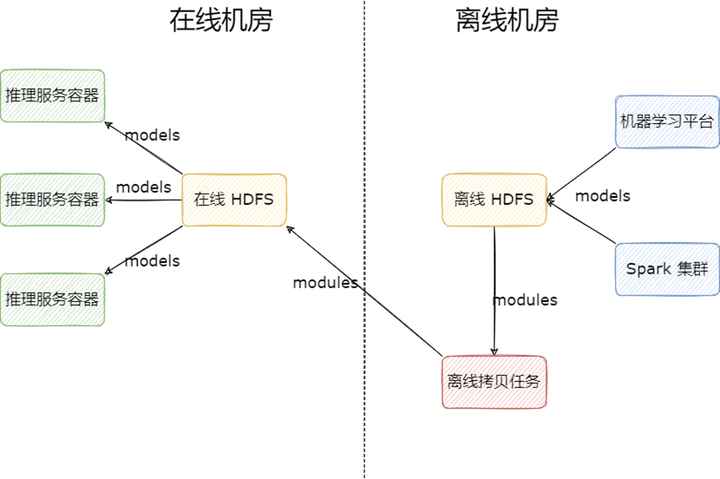
多 HDFS 集群的架構(gòu)雖然解決了專線流量的問(wèn)題,但是依然存在一些問(wèn)題:
多個(gè) HDFS 集群不便于維護(hù),增加運(yùn)維人員負(fù)擔(dān);
拷貝腳本需要業(yè)務(wù)自己實(shí)現(xiàn),每次新上線模型時(shí),都要同步修改拷貝腳本,不便維護(hù);
在線 HDFS 集群的文件需要業(yè)務(wù)定期手動(dòng)刪除以降低成本,操作風(fēng)險(xiǎn)高;
在線 HDFS 與離線 HDFS 之間文件視圖不一致,用戶在使用 HDFS 時(shí),需要明確知道自己使用的是哪個(gè) HDFS,需要保存多個(gè)地址,心智負(fù)擔(dān)高;
在超高并發(fā)讀取時(shí),比如算法一次性起上百個(gè)容器來(lái)讀取某個(gè)模型文件時(shí),會(huì)導(dǎo)致 DataNode 負(fù)載過(guò)高,雖然可以通過(guò)增加副本解決,但是也會(huì)帶來(lái)較高的存儲(chǔ)成本。
基于以上痛點(diǎn),我們自研了多云緩存服務(wù) —UnionStore。
三、自研組件 UnionStore
3.1 簡(jiǎn)介
UnionStore 顧名思義,就是聯(lián)合存儲(chǔ)的意思,它提供了標(biāo)準(zhǔn)的 S3 協(xié)議來(lái)訪問(wèn) HDFS 上的數(shù)據(jù),并且以對(duì)象存儲(chǔ)來(lái)作為跨機(jī)房緩存。UnionStore 目前在知乎有兩種使用場(chǎng)景:
模型上線場(chǎng)景:部署到在線機(jī)房,作為跨機(jī)房緩存使用:
用戶在向 UnionStore 請(qǐng)求讀取文件時(shí),會(huì)先檢查文件是否已經(jīng)上傳到對(duì)象存儲(chǔ)上:
如果對(duì)象存儲(chǔ)已經(jīng)存在該文件,則直接從對(duì)象存儲(chǔ)讀取文件返回給用戶;
如果對(duì)象存儲(chǔ)不存在該文件,UnionStore 會(huì)先將離線 HDFS 上的文件上傳到在線機(jī)房的對(duì)象存儲(chǔ)上,再?gòu)膶?duì)象存儲(chǔ)上讀取文件,返回給用戶,緩存期間用戶的請(qǐng)求是被 block 住的。這里相當(dāng)于是利用對(duì)象存儲(chǔ)做了一層跨機(jī)房緩存。
模型訓(xùn)練場(chǎng)景:部署到離線機(jī)房,作為 HDFS 代理使用,目的是為業(yè)務(wù)提供 S3 協(xié)議的 HDFS 訪問(wèn)方式,通過(guò) s3fs-fuse,業(yè)務(wù)就能掛載 HDFS 到本地目錄,讀取訓(xùn)練數(shù)據(jù)進(jìn)行模型的訓(xùn)練。
模型訓(xùn)練場(chǎng)景是我們 UnionStore 上線后的擴(kuò)展場(chǎng)景,之前我們嘗試過(guò)很多 HDFS 掛載 POSIX 的方式,但是效果都不太理想,主要體現(xiàn)在重試方面,而 UnionStore 正好提供了 S3 協(xié)議,s3fs-fuse 重試做的不錯(cuò),所以我們最后選擇了 UnionStore + s3fs-fuse 對(duì) HDFS 進(jìn)行本地目錄的掛載。
其工作流程如下:
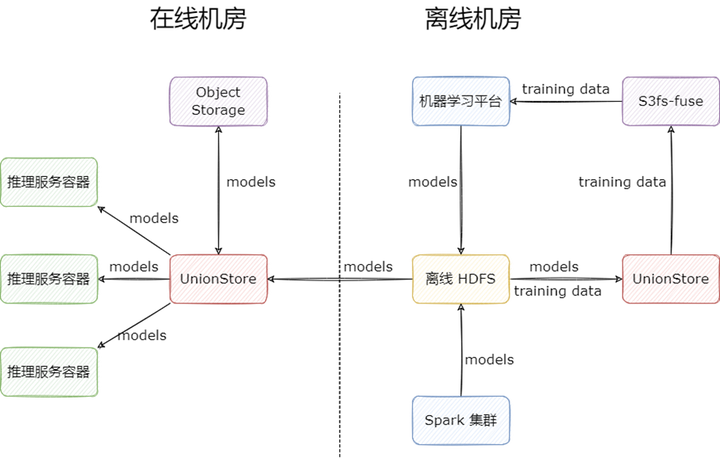
相比于之前多 HDFS 集群方案,UnionStore 的優(yōu)勢(shì)如下:
1) UnionStore 提供了 S3 協(xié)議,各編程語(yǔ)言對(duì) S3 協(xié)議的支持要比 HDFS 協(xié)議好,工具也相對(duì)來(lái)說(shuō)也更豐富;
2) UnionStore 會(huì)自動(dòng)緩存文件,無(wú)需用戶手動(dòng)拷貝模型,省去了拷貝腳本的開發(fā)與維護(hù);
3) 提供統(tǒng)一的文件視圖,因?yàn)樵獢?shù)據(jù)是實(shí)時(shí)請(qǐng)求 HDFS 的,所以文件視圖與 HDFS 強(qiáng)一致;
4) 下線了一個(gè) HDFS 集群,文件儲(chǔ)存能力由對(duì)象存儲(chǔ)提供,節(jié)省了大量的服務(wù)器成本;
5) 文件過(guò)期可依賴對(duì)象存儲(chǔ)本身提供的能力,無(wú)需自己實(shí)現(xiàn);
6) UnionStore 以云原生的方式提供服務(wù),部署在 k8s 上,每一個(gè)容器都是無(wú)狀態(tài)節(jié)點(diǎn),可以很輕易的擴(kuò)縮容,在高并發(fā)的場(chǎng)景下,由于存儲(chǔ)能力轉(zhuǎn)移到對(duì)象存儲(chǔ),在對(duì)象存儲(chǔ)性能足夠的情況下,不會(huì)遇到類似 DataNode 負(fù)載過(guò)高的問(wèn)題。
3.2 實(shí)現(xiàn)細(xì)節(jié)
UnionStore 的完整架構(gòu)圖如下:
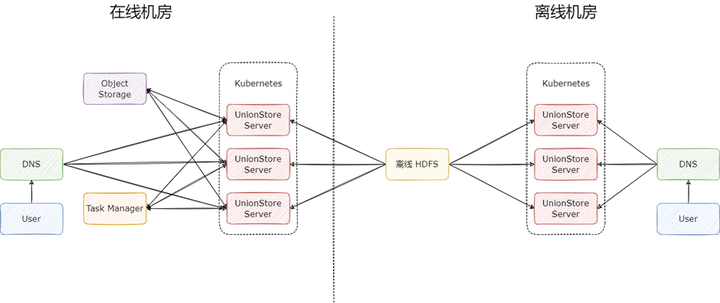
在使用對(duì)象存儲(chǔ)作為緩存時(shí),UnionStore 有三個(gè)核心組件:
UnionStore Server:無(wú)狀態(tài)節(jié)點(diǎn),每一個(gè)節(jié)點(diǎn)都能單獨(dú)提供服務(wù),一般會(huì)部署多個(gè),用于分?jǐn)偭髁?br />
Object Storage:對(duì)象存儲(chǔ),用于緩存 HDFS 上的數(shù)據(jù),一般是在哪個(gè)云廠商就使用對(duì)應(yīng)云廠商提供的對(duì)象存儲(chǔ),流量費(fèi)用幾乎可忽略;
Task Manager:任務(wù)管理器,用于存儲(chǔ)緩存任務(wù),可用 MySQL 和 Redis 實(shí)現(xiàn)。
基于這三個(gè)組件我們?cè)?UnionStore 上實(shí)現(xiàn)了一系列有用的功能。
文件校驗(yàn):文件被緩存至對(duì)象存儲(chǔ)后,如果 HDFS 上的文件做了修改,UnionStore 需要檢查到文件的變更,確保用戶不會(huì)讀取到錯(cuò)誤的文件。這里我們?cè)趯?HDFS 文件上傳至對(duì)象存儲(chǔ)時(shí),會(huì)將 HDFS 文件的大小,最后修改時(shí)間,checksum 等元信息存儲(chǔ)到對(duì)象存儲(chǔ)文件的 UserMetadata 上,用戶在讀取文件時(shí),會(huì)檢查這部分的信息,只有當(dāng)信息校驗(yàn)通過(guò)時(shí),才會(huì)返回對(duì)象存儲(chǔ)上的文件,如果校驗(yàn)未通過(guò),則會(huì)重新緩存這個(gè)文件,更新對(duì)象存儲(chǔ)上的緩存。
讀寫加速:對(duì)象存儲(chǔ)的單線程讀寫速度大約在 30-60MB/sec,遠(yuǎn)遠(yuǎn)小于 HDFS 的吞吐,如果不做特殊處理,是很難滿足業(yè)務(wù)的讀寫需求的。
在讀方面,我們利用對(duì)象存儲(chǔ)的 RangeRead 接口,多線程讀取對(duì)象存儲(chǔ)上的數(shù)據(jù)返回給用戶,達(dá)到了與 HDFS 相同的讀取速度。在寫方面,我們利用對(duì)象存儲(chǔ)的 MultiPartUpload 接口,多線程上傳 HDFS 上的文件,也能達(dá)到與 HDFS 相同的寫入速度。
文件僅緩存一次:因?yàn)?UnionStore Server 被設(shè)計(jì)成了無(wú)狀態(tài)節(jié)點(diǎn),所以它們之間是無(wú)法互相感知的。如果有多個(gè)請(qǐng)求同時(shí)打到不同的 Server 節(jié)點(diǎn)上來(lái)請(qǐng)求未緩存的文件,這個(gè)文件可能會(huì)被不同的 Server 多次緩存,對(duì)專線造成較大的壓力。我們引入了 Task Manager 這個(gè)組件來(lái)解決這個(gè)問(wèn)題:
Server 節(jié)點(diǎn)在接受到讀取未緩存文件的請(qǐng)求時(shí),會(huì)先將用戶的請(qǐng)求異步卡住,生成緩存任務(wù),提交到 Task Manager 的等待隊(duì)列中;
所有 Server 節(jié)點(diǎn)會(huì)不斷競(jìng)爭(zhēng)等待隊(duì)列里的任務(wù),只會(huì)有一個(gè)節(jié)點(diǎn)競(jìng)爭(zhēng)成功,此時(shí)該節(jié)點(diǎn)會(huì)將緩存任務(wù)放入運(yùn)行隊(duì)列,開始執(zhí)行,執(zhí)行期間向任務(wù)隊(duì)列匯報(bào)心跳;
每個(gè) Server 節(jié)點(diǎn)會(huì)定期檢查自己卡住的用戶請(qǐng)求,來(lái)檢查 Task Manager 里對(duì)應(yīng)的任務(wù),如果任務(wù)執(zhí)行成功,就會(huì)喚醒用戶請(qǐng)求,返回給用戶緩存后的文件;同時(shí),每個(gè) Server 都會(huì)定期檢查 Task Manager 里正在運(yùn)行的任務(wù),如果任務(wù)長(zhǎng)時(shí)間沒有更新心跳,則會(huì)將任務(wù)從運(yùn)行隊(duì)列里取出,重新放回等待隊(duì)列,再次執(zhí)行。
這里所有的狀態(tài)變更操作都發(fā)生在 Server 節(jié)點(diǎn),Task Manager 只負(fù)責(zé)存儲(chǔ)任務(wù)信息以及提供隊(duì)列的原子操作。
3.3 局限
UnionStore 項(xiàng)目在知乎運(yùn)行了兩年,早期并沒有出現(xiàn)任何問(wèn)題,但是隨著算法業(yè)務(wù)規(guī)模的不斷擴(kuò)大,出現(xiàn)了以下問(wèn)題:
1) 沒有元數(shù)據(jù)緩存,元數(shù)據(jù)強(qiáng)依賴 HDFS,在 HDFS 抖動(dòng)的時(shí)候,有些需要頻繁更新的模型文件會(huì)受影響,無(wú)法更新,在線服務(wù)不應(yīng)強(qiáng)依賴離線 HDFS;
2) 讀寫加速因?yàn)橛玫搅硕嗑€程技術(shù),對(duì) CPU 的消耗比較大,在早期業(yè)務(wù)量不大的時(shí)候,UnionStore 只需要幾百 Core 就能支撐整個(gè)公司的算法團(tuán)隊(duì)讀取數(shù)據(jù),但是隨著業(yè)務(wù)量不斷上漲,需要的 CPU 數(shù)也漲到了上千;
3) 對(duì)象存儲(chǔ)能力有上限,單文件上千并發(fā)讀取時(shí),也會(huì)面臨性能瓶頸;
4) UnionStore 只做到了緩存,而沒有做到高性能緩存,業(yè)務(wù)方的大模型往往需要讀取十多分鐘,極大影響模型的更新速度,制約業(yè)務(wù)的發(fā)展;
5) 無(wú)法做到邊緩存邊返回文件,導(dǎo)致第一次讀取文件的時(shí)間過(guò)長(zhǎng)。
另外還有一個(gè)關(guān)鍵點(diǎn),機(jī)器學(xué)習(xí)平臺(tái)為保證多活,也采用了多云架構(gòu),支持了多機(jī)房部署,在讀取訓(xùn)練數(shù)據(jù)時(shí),走的是 UnionStore 對(duì) HDFS 的直接代理,沒走緩存流程,因?yàn)橛?xùn)練數(shù)據(jù)大部分都是小文件,而且數(shù)量特別巨大,小文件都過(guò)一遍緩存會(huì)導(dǎo)致緩存任務(wù)在任務(wù)隊(duì)列里排隊(duì)時(shí)間過(guò)長(zhǎng),很難保證讀取的時(shí)效性,因此我們直接代理了 HDFS。按照這種使用方式,專線帶寬在訓(xùn)練數(shù)據(jù)規(guī)模擴(kuò)大時(shí),依然會(huì)成為瓶頸。
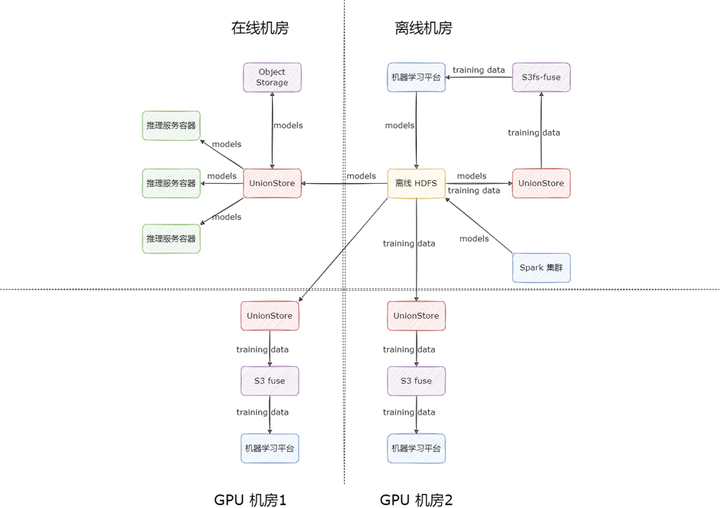
以上痛點(diǎn)使我們面臨兩個(gè)選擇:一是繼續(xù)迭代 UnionStore,讓 UnionStore 具備高性能緩存能力,比如支持本地 SSD 以及內(nèi)存緩存;二是尋找合適的開源解決方案,完美替代 UnionStore 的使用場(chǎng)景。基于人力資源的寶貴,我們選擇了其二。
四、利用 Alluxio 替代 UnionStore
1. 調(diào)研
我們調(diào)研了業(yè)內(nèi)主流的文件系統(tǒng),發(fā)現(xiàn) Alluxio 比較適合我們的場(chǎng)景,原因有以下幾點(diǎn):
1) 透明緩存:相較于其他文件系統(tǒng),Alluxio 可僅作為緩存使用,用于編排數(shù)據(jù),業(yè)務(wù)方無(wú)需將模型文件寫入到其他的文件系統(tǒng),只需要維持現(xiàn)狀,寫入 HDFS 即可;
2) 元數(shù)據(jù)與數(shù)據(jù)緩存:Alluxio 支持自定義緩存元數(shù)據(jù)與數(shù)據(jù),這樣在讀取已緩存文件時(shí),可完全不受 HDFS 影響;目前我們 UnionStore 的 QPS 大約在 20K-30K,緩存元數(shù)據(jù)可極大降低 NameNode 的壓力,反哺離線場(chǎng)景;
3) 豐富的 UFS 支持:支持除 HDFS 外的多種 UFS,比如對(duì)象存儲(chǔ),對(duì)我們的數(shù)據(jù)湖場(chǎng)景也提供了強(qiáng)有力的支撐;
4) 即席查詢加速:知乎 Adhoc 引擎采用的是 Spark 與 Presto,Alluxio 對(duì)這兩個(gè)引擎都有較好的支持;
5) 訪問(wèn)接口豐富:Alluxio 提供的 S3 Proxy 組件完全兼容 S3 協(xié)議,我們的模型上線場(chǎng)景從 UnionStore 遷移至 Alluxio 付出的成本幾乎可忽略不計(jì);另外 Alluxio 提供的 Alluxio fuse 具備本地元數(shù)據(jù)緩存與數(shù)據(jù)緩存,比業(yè)務(wù)之前使用的 S3 fuse 具有更好的性能,正好能滿足我們的模型訓(xùn)練場(chǎng)景。
6) 社區(qū)活躍:Alluxio 社區(qū)十分活躍,在我們調(diào)研期間交流群基本上都會(huì)有熱心的網(wǎng)友及時(shí)答復(fù), issue 很少有超過(guò)半天不回復(fù)的情況。
對(duì) Alluxio 的調(diào)研讓我們非常驚喜,它不僅滿足了我們的需求,還給我們 “額外贈(zèng)送” 了不少附加功能。我們?cè)趦?nèi)部對(duì) Alluxio 進(jìn)行了測(cè)試,以 100G 的文件做單線程讀取測(cè)試,多次測(cè)試取平均值,結(jié)果如下
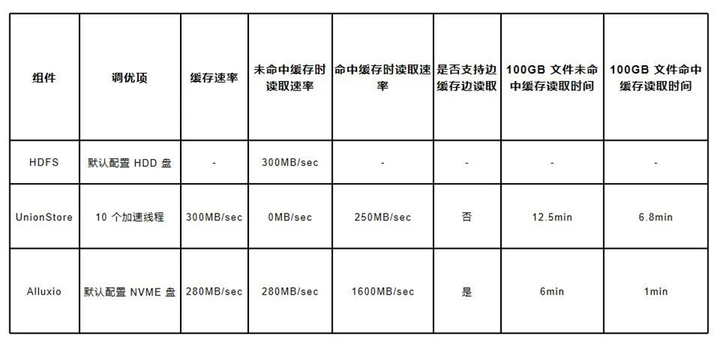
其中 HDFS 因?yàn)樯婕暗?OS 層面的緩存,波動(dòng)是最大的,從 200MB/sec - 500MB/sec 都有,而 UnionStore 與 Alluxio 在命中緩存時(shí)表現(xiàn)十分穩(wěn)定。
2. 集群規(guī)劃
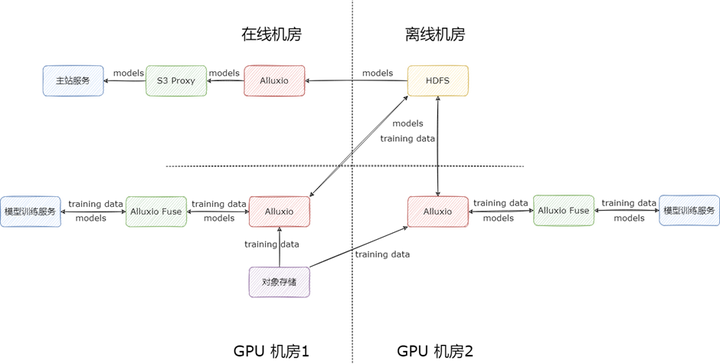
Alluxio 在我們的規(guī)劃中是每個(gè)機(jī)房部署一套,利用高性能 NVME 磁盤對(duì) HDFS 和對(duì)象存儲(chǔ)上的數(shù)據(jù)進(jìn)行緩存,為業(yè)務(wù)提供海量數(shù)據(jù)的加速服務(wù)。
依據(jù)業(yè)務(wù)的使用場(chǎng)景,我們將 Alluxio 集群分為兩類。
模型上線加速集群:Alluxio 集群緩存模型本身,利用 S3 Proxy 對(duì)外提供只讀服務(wù),加速模型的上線
模型訓(xùn)練加速集群:Alluxio 集群緩存模型訓(xùn)練數(shù)據(jù),利用 Alluxio fuse 對(duì) HDFS 上數(shù)據(jù)與元數(shù)據(jù)再做本地緩存,加速模型的訓(xùn)練;產(chǎn)出的模型直接通過(guò) Alluxio fuse 寫入 HDFS 進(jìn)行持久化存儲(chǔ)。
3. 模型上線場(chǎng)景適配
3.1 場(chǎng)景特點(diǎn)
我們的模型上線場(chǎng)景有以下特點(diǎn):
1) 用戶利用 S3 協(xié)議讀取模型文件;
2) 用戶將模型數(shù)據(jù)寫入到 HDFS 上后,需要立即讀取,數(shù)據(jù)產(chǎn)出與讀取的間隔在秒級(jí),幾乎無(wú)法提前預(yù)熱,存在緩存穿透的問(wèn)題;
3) 一份模型文件將由上百甚至上千個(gè)容器同時(shí)讀取,流量放大明顯,最大的單個(gè)模型讀取時(shí),峰值流量甚至能達(dá)到 1Tb/sec;
4) 模型文件只會(huì)在短時(shí)間內(nèi)使用,高并發(fā)讀取完畢后可視為過(guò)期;
5) 數(shù)萬(wàn)容器分散在上千個(gè) K8s 節(jié)點(diǎn)上,單個(gè)容器可用資源量較少。
針對(duì)模型上線場(chǎng)景,我們選擇了 S3 Proxy 來(lái)為業(yè)務(wù)提供緩存服務(wù),不使用 Alluxio Client 以及 Alluxio fuse 主要是基于以下考慮:
用戶原本就是利用 S3 協(xié)議讀取文件,換成 S3 Proxy 幾乎無(wú)成本;
業(yè)務(wù)方使用的語(yǔ)言有 Python,Golang,Java 三種,Alluxio Client 是基于 Java 實(shí)現(xiàn)的,其他語(yǔ)言使用起來(lái)比較麻煩;
受限于單個(gè)容器的資源限制,不適合在容器內(nèi)利用 CSI 等方式啟動(dòng) Alluxio fuse,因?yàn)?fuse 的性能比較依賴磁盤和內(nèi)存的緩存。
3.2 集群部署
首先是集群的部署方式,在這個(gè)場(chǎng)景下,我們的 Alluxio 集群采取了 “大集群輕客戶端” 的方式來(lái)部署,也就是提供足夠數(shù)量的 Worker 與 S3 Proxy 來(lái)支撐業(yè)務(wù)以 S3 協(xié)議發(fā)起的高并發(fā)請(qǐng)求,架構(gòu)圖如下
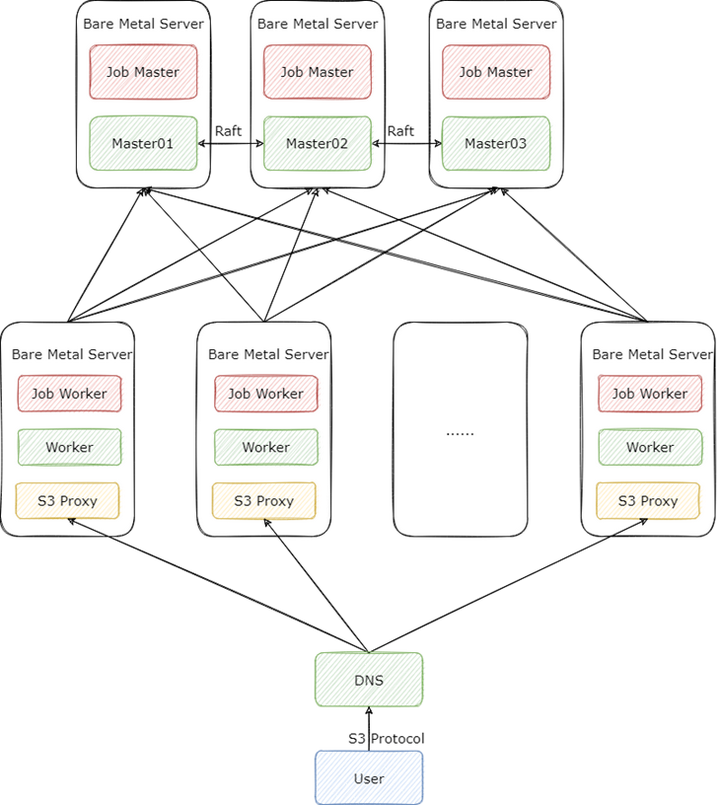
我們的集群版本是 2.9.2,在這個(gè)版本,S3 Proxy 有 v1 v2 兩種實(shí)現(xiàn),可通過(guò)配置 alluxio.proxy.s3.v2.version.enabled 進(jìn)行切換。v2 版本有一個(gè)很重要的功能,就是將 IO 操作與元數(shù)據(jù)操作進(jìn)行了分類,分別交給不同的線程池去處理。這樣做的好處是,讓元數(shù)據(jù)操作能夠快速執(zhí)行,不被 IO 線程卡住,因?yàn)橐话闱闆r下,元數(shù)據(jù)請(qǐng)求的 QPS 遠(yuǎn)遠(yuǎn)大于讀寫文件的 QPS。這個(gè)功能對(duì)我們非常有用,我們 UnionStore 的 QPS 在 25K 左右,其中 90% 的操作都是元數(shù)據(jù)訪問(wèn)。
整個(gè) Alluxio 集群我們采取了裸金屬機(jī)部署,Alluxio 也提供了 k8s 的部署方式,但是在我們的權(quán)衡之下,還是選擇了裸金屬機(jī)部署,原因如下:
1) 從我們的測(cè)試結(jié)果來(lái)看,Alluxio Worker 在” 火力全開 “的情況下是可以輕易打滿雙萬(wàn)兆網(wǎng)卡的,這個(gè)時(shí)候網(wǎng)卡是瓶頸;如果選擇 k8s 部署,當(dāng)有容器與 Alluxio Worker 調(diào)度到同一臺(tái) k8s 的節(jié)點(diǎn)時(shí),該容器容易受到 Alluxio Worker 的影響,無(wú)法搶占到足夠的網(wǎng)卡資源;
2) Alluxio Worker 依賴高性能磁盤做本地緩存,與其他服務(wù)混布容易收到其他進(jìn)程的磁盤 IO 影響,無(wú)法達(dá)到最佳性能;
3) 因?yàn)?Alluxio Worker 強(qiáng)依賴網(wǎng)卡,磁盤等物理資源,這些資源不適合與其他服務(wù)共享。強(qiáng)行以 k8s 部署,可能就是一個(gè) k8s 節(jié)點(diǎn)啟一個(gè) Alluxio Worker 的 DaemonSet,這其實(shí)也沒必要用 k8s 部署,因?yàn)榛谖覀冞^(guò)往的經(jīng)驗(yàn),容器內(nèi)搞存儲(chǔ),可能會(huì)遇到各類奇奇怪怪的問(wèn)題,這些問(wèn)題解決起來(lái)比較浪費(fèi)時(shí)間,影響正常的上線進(jìn)度。
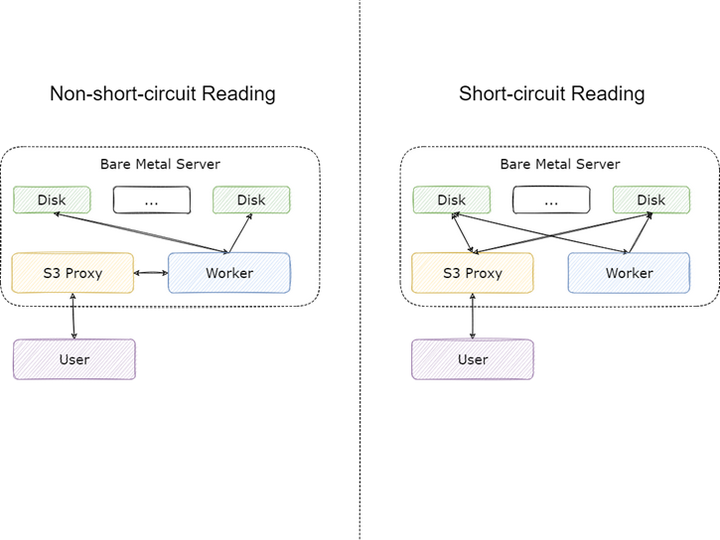
我們除了按照社區(qū)文檔的推薦將 Master 與 Job Master,Worker 與 Job Worker 部署到同一臺(tái)機(jī)器上,還另外將 S3 Proxy 與 Worker 進(jìn)行了混布。S3 Proxy 在用戶看起來(lái)雖然是服務(wù)端,但是對(duì) Alluxio 集群來(lái)說(shuō)它還是客戶端,而 Alluxio 對(duì)于客戶端有一個(gè)非常重要的優(yōu)化:
當(dāng) Client 與 Worker 在同一節(jié)點(diǎn)時(shí),就可以使用短路讀的功能,在短路讀開啟的情況下,Client 將不再利用網(wǎng)絡(luò)請(qǐng)求調(diào)用 Worker 上的 RPC 接口讀取數(shù)據(jù),而是直接讀本地磁盤上的數(shù)據(jù),能夠極大節(jié)省網(wǎng)卡資源。通過(guò) S3 Porxy 訪問(wèn) Alluxio 時(shí),流量主要分為以下幾個(gè)部分:
文件未緩存至 Alluxio:Worker 從 UFS 讀取數(shù)據(jù),任一 Worker 只要緩存了 UFS 的文件,這部分流量將不存在;
文件在遠(yuǎn)端 Worker 緩存:本地 Worker 從其他 Worker 讀取數(shù)據(jù)緩存到本地,S3 Proxy 暫時(shí)從遠(yuǎn)端 Worker 讀取,本地 Worker 緩存完畢后這部分流量將不存在;
文件在本地 Worker 緩存:S3 Proxy 從本地 Worker 讀取的流量,這部分流量在開啟短路讀后將不存在;
業(yè)務(wù)方從 S3 Proxy 讀取的流量,這部分流量無(wú)法避免。
其中 1,2 中的流量遠(yuǎn)小于 3,4 中的流量,短路讀能夠?qū)?3 的流量省下,節(jié)省約 30%-50% 的流量。
其次是集群的部署規(guī)模,在模型讀取這個(gè)場(chǎng)景,盡管每天的讀取總量可達(dá)數(shù) PB,但是因?yàn)槟P臀募芸炀蜁?huì)過(guò)期,所以 Worker 的容量并不需要很大,Worker 網(wǎng)卡的總帶寬能夠支持讀取流量即可。Worker 的數(shù)量可按照 流量峰值 /(2/3* 網(wǎng)卡帶寬) 來(lái)計(jì)算,這里網(wǎng)卡需要預(yù)留 1/3 的 buffer 來(lái)供 Worker 讀取 UFS 以及 Worker 互相同步數(shù)據(jù)使用。
最后是 Alluxio Master 的 HA 方式,我們選擇了 Raft,在我們的測(cè)試過(guò)程中,在上億的元數(shù)據(jù)以及數(shù)百 GB 堆的情況下,Master 主從切換基本上在 10 秒以內(nèi)完成,效率極高,業(yè)務(wù)近乎無(wú)感。
3.3 上線與調(diào)優(yōu)
我們的上線過(guò)程也是我們調(diào)優(yōu)的一個(gè)過(guò)程。
在初期,我們只將一個(gè)小模型的讀取請(qǐng)求從 UnionStore 切換到了 Alluxio S3 Proxy,效果如下:
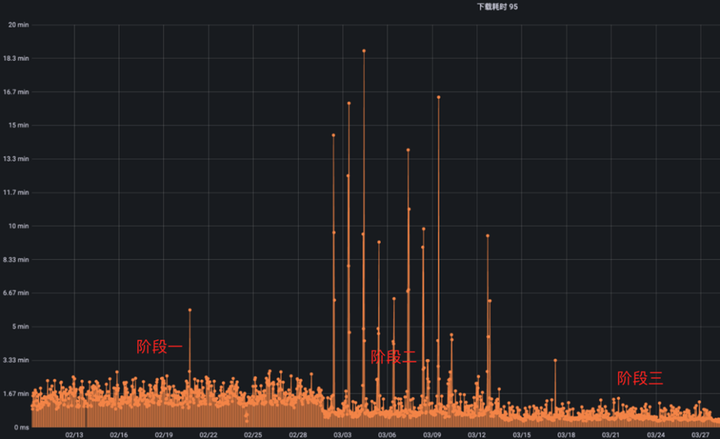
里面的每一條線段都代表著一個(gè)模型的讀取請(qǐng)求,線段的長(zhǎng)短代表讀取數(shù)據(jù)的花費(fèi)的時(shí)間。
其中階段一是我們內(nèi)部的 UnionStore 服務(wù),階段二是我們直接切換到 S3 Proxy 時(shí)的狀態(tài),可以很明顯的看到換成 S3 Proxy 了以后,模型讀取的平均速度有所上升,但是出現(xiàn)了尖刺,也就是偶爾有請(qǐng)求讀取的很慢。問(wèn)題出在模型讀取時(shí),總是冷讀,也就是模型數(shù)據(jù)沒有經(jīng)過(guò)預(yù)熱,在文件未預(yù)熱的情況下,從 Alluxio 讀數(shù)據(jù)最多只能達(dá)到與 HDFS 相同的速度,不能充分發(fā)揮緩存的能力。
而且通過(guò)測(cè)試,我們發(fā)現(xiàn) Alluxio 在并發(fā)請(qǐng)求同一個(gè)沒有經(jīng)過(guò)預(yù)熱的文件時(shí),性能會(huì)下降的十分嚴(yán)重,甚至達(dá)不到直接讀 HDFS 的速度。因此我們需要想辦法預(yù)熱文件。
預(yù)熱文件的手段一般有以下兩種:
1) 用戶在寫完文件后,手動(dòng)調(diào)用 Alluxio load 命令,提前將數(shù)據(jù)緩存,確保在讀取的時(shí)候,需要的文件已經(jīng)被緩存了;
2) 根據(jù) HDFS 的 audit log 或者利用 HDFS 的 inotify 來(lái)訂閱文件的變更,只要發(fā)現(xiàn)算法目錄下有文件變動(dòng)就加載緩存進(jìn) Alluxio。
方式 1 的問(wèn)題在于需要用戶深度參與,有額外的心智負(fù)擔(dān)和開發(fā)成本,其次是用戶調(diào)用 load 命令不可控,如果對(duì)一個(gè)超大目錄進(jìn)行 load,將會(huì)使所有緩存失效。
方式 2 也需要用戶提供監(jiān)聽的路徑,如果路徑是文件比較方便,只需要監(jiān)聽 close 請(qǐng)求即可,但是路徑是目錄的情況下,涉及到臨時(shí)文件,rename 等,十分復(fù)雜;每次用戶新增模型時(shí),都需要我們把路徑新加入監(jiān)控,有額外的溝通成本;另外由于我們這個(gè)場(chǎng)景,數(shù)據(jù)產(chǎn)出與讀取的間隔在秒級(jí),監(jiān)控文件變更鏈路太長(zhǎng),可能出現(xiàn)一些延遲,從而導(dǎo)致預(yù)熱方案失效。
基于以上缺點(diǎn),我們自己設(shè)計(jì)了一套緩存策略:
冷讀文件慢的本質(zhì)在于通過(guò) Alluxio 讀取未緩存文件時(shí),讀到哪一個(gè) block 才會(huì)去緩存這個(gè) block,沒有做到并發(fā)緩存 block。因此我們?cè)?S3 Proxy 上添加了一個(gè)邏輯,在讀取文件時(shí),會(huì)將文件按 block 進(jìn)行分段生成 cache block 任務(wù),平均提交到每一個(gè) Worker 來(lái)異步緩存。這樣的好處是,客戶端在讀取前面少量幾個(gè)未緩存的 block 后,后面的 block 都是已經(jīng)緩存完畢的,讀取速度十分快。此外,由于提前緩存了 block,緩存穿透的問(wèn)題也能有所緩解,HDFS 流量能夠下降 2 倍以上。
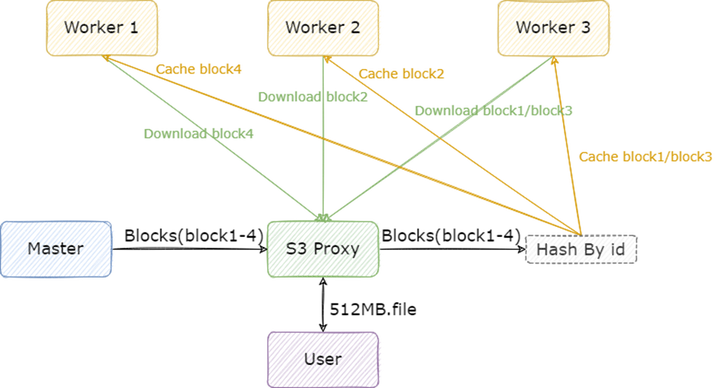
此緩存策略需要注意以下幾點(diǎn):
1) 緩存 block 需要異步,并且所有的異常都要處理掉,不要影響正常的讀取請(qǐng)求;
2) 緩存 block 時(shí),最好將 block id 與 Worker id 以某種方式(如 hash)進(jìn)行綁定,這樣能保證在對(duì)同一個(gè)文件進(jìn)行并發(fā)請(qǐng)求時(shí),對(duì)某一個(gè) block 的緩存請(qǐng)求都只打到同一個(gè) Worker 上,避免不同的 Worker 從 UFS 讀取同一個(gè) block,放大 UFS 流量;
3) S3 Proxy 需要對(duì)提交的 cache block 任務(wù)計(jì)數(shù),避免提交過(guò)多任務(wù)影響 Worker 正常的緩存邏輯,最好不要超過(guò)配置 alluxio.worker.network.async.cache.manager.threads.max 的一半,這個(gè)配置代表 Worker 處理異步緩存請(qǐng)求的最大線程數(shù),默認(rèn)值是兩倍的 CPU 數(shù);
4) S3 Proxy 需要對(duì)已經(jīng)提交緩存的 block 進(jìn)行去重,防止在高并發(fā)讀取同一個(gè)文件的情況下,多次提交同一個(gè) block 的緩存請(qǐng)求到 Worker,占滿 Worker 的異步緩存隊(duì)列。Worker 的異步緩存隊(duì)列大小由配置 alluxio.worker.network.async.cache.manager.queue.max 控制,默認(rèn)是 512。去重比較推薦使用 bitmap 按照 block id 做;
5) 在 Worker 異步緩存隊(duì)列沒滿的情況下,異步緩存的線程數(shù)將永遠(yuǎn)保持在 4 個(gè),需要修改代碼提高 Worker 異步緩存的最小線程數(shù),防止效率過(guò)低,可參考 #17179。
在上線了這個(gè)緩存策略后,我們進(jìn)入了階段三,可以看到,階段三的尖刺全部消失了,整體的速度略微有所提升。因?yàn)槲覀兪菍?duì)小文件(1GB 左右)進(jìn)行的緩存,所以提升效果不明顯。經(jīng)過(guò)我們測(cè)試,此緩存策略能夠提升讀取大文件(10GB 及以上)3-5 倍的速度,而且文件越大越明顯。
解決了緩存的問(wèn)題后,我們繼續(xù)切換更多模型的讀取到 S3 Proxy,效果如下:
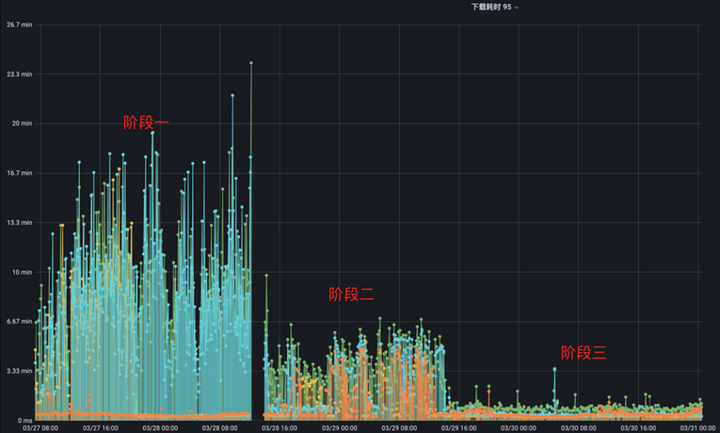
本次我們另外切換了三個(gè)模型的讀取請(qǐng)求到 S3 Proxy,其中橙色模型是我們之前已經(jīng)切換到 S3 Proxy 的模型,本次新增的模型最大達(dá)到了 10G,讀取流量峰值為 500Gb/sec。
這次我們同樣分為三個(gè)階段,階段一是橙色模型已經(jīng)切換到 S3 Proxy,其他模型都使用 UnionStore,因?yàn)槌壬P偷臄?shù)據(jù)量小,并且還用了 Alluxio 加速,所以它的讀取速度能夠比其他模型的讀取速度快上數(shù)十倍。
階段二是我們將其他模型也切換至 S3 Proxy 后的狀態(tài),可以看到其他模型讀取速度明顯變快了,但是橙色模型讀取速度受到其他模型的影響反而變慢了,這是一個(gè)非常奇怪的現(xiàn)象。最后我們定位到是元數(shù)據(jù)緩存沒有開啟的原因,在元數(shù)據(jù)緩存沒有開啟的情況下,Alluxio 會(huì)將客戶端的每一次請(qǐng)求都打到 HDFS 上,加上 S3 Proxy 也會(huì)頻繁對(duì)一些系統(tǒng)目錄做檢查,這樣就導(dǎo)致 Master 同步元數(shù)據(jù)的負(fù)擔(dān)非常重,性能甚至能下降上千倍。
在這個(gè)場(chǎng)景,我們本來(lái)是不打算開啟元數(shù)據(jù)緩存的,主要是擔(dān)心業(yè)務(wù)對(duì)已緩存修改文件進(jìn)行修改,導(dǎo)致讀取到錯(cuò)誤的文件,從而影響模型的上線。但是從實(shí)踐的結(jié)果來(lái)看,元數(shù)據(jù)緩存必須要開啟來(lái)提升 Master 的性能。
與業(yè)務(wù)方溝通過(guò)后,我們制定了元數(shù)據(jù)一致性的規(guī)范:
1) 元數(shù)據(jù)緩存設(shè)置為 1min;
2) 新增文件盡量寫入新目錄,以版本號(hào)的方式管理,不要在舊文件上修改或覆蓋;
3) 對(duì)于歷史遺留,需要覆蓋新文件的任務(wù),以及對(duì)元數(shù)據(jù)一致性要求比較高的任務(wù),我們?cè)?S3 Proxy 上提供特殊命令進(jìn)行元數(shù)據(jù)的同步,數(shù)據(jù)更新后,業(yè)務(wù)方自己調(diào)用命令同步元數(shù)據(jù)。
在開啟元數(shù)據(jù)緩存過(guò)后,我們來(lái)到了圖中的階段三,可以很明顯的看到所有模型數(shù)據(jù)的讀取速度有了飛躍式提升,相比于最開始沒有使用 S3 Proxy 讀取速度提升了 10+ 倍。這里需要注意的是,10+ 倍是指在 Alluxio 機(jī)器數(shù)量足夠多,網(wǎng)卡足夠充足的情況下能達(dá)到的效果,我們?cè)趯?shí)際使用過(guò)程中,用了 UnionStore 一半的資源達(dá)到了與 UnionStore 同樣的效果。
3.4 S3 Proxy 限速
我們?cè)谀P妥x取場(chǎng)景上線 Alluxio 的本意是為了提高業(yè)務(wù)方讀取模型的速度,但是因?yàn)橥ㄟ^(guò) Alluxio 讀數(shù)據(jù)實(shí)在是太快了,反而需要我們給它限速,非常的具有戲劇性。不限速將會(huì)面臨一個(gè)很嚴(yán)重的問(wèn)題:算法容器在讀取模型時(shí),如果文件較大,不僅會(huì)影響 S3 Proxy 所在物理機(jī)的網(wǎng)卡,也會(huì)導(dǎo)致該容器所在的 k8s 宿主機(jī)的網(wǎng)卡長(zhǎng)時(shí)間處于被占滿狀態(tài),從而影響這一節(jié)點(diǎn)上的其他容器。
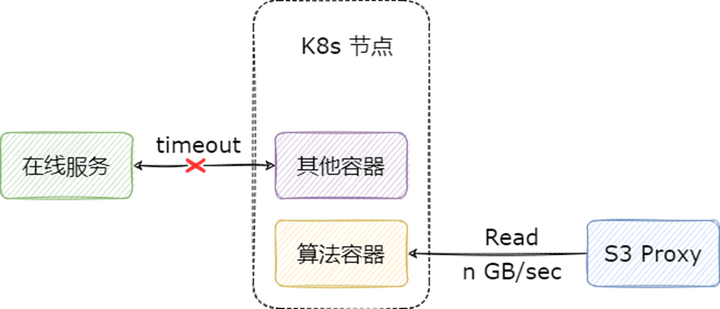
目前限速的實(shí)現(xiàn)主要有以下幾種方案:
Worker 端限速:優(yōu)點(diǎn)是對(duì)所有客戶端生效,缺點(diǎn)是對(duì)同節(jié)點(diǎn)客戶端短路讀不生效,在我們的場(chǎng)景,S3 Proxy 會(huì)走短路讀,不能滿足我們的需求。
客戶端限速:優(yōu)點(diǎn)是能夠同時(shí)對(duì) Alluxio fuse 和 S3 Proxy 生效,缺點(diǎn)是客戶端可以自己改配置繞過(guò)限制,同時(shí)服務(wù)端版本和客戶端版本可能存在不一致的情況,導(dǎo)致限速失效。
S3 Proxy 限速:只能對(duì) S3 Proxy 生效,對(duì)其他的客戶端以及 Worker 都不能生效。
因?yàn)槲覀儺?dāng)前的目標(biāo)就是替代 UnionStore,業(yè)務(wù)方訪問(wèn) Alluxio 的入口只有 S3 Proxy,因此客戶端限速和 S3 Proxy 限速都能滿足我們的需求,但是從實(shí)現(xiàn)的難易角度上考慮,我們最后選擇了從 S3 Proxy 層面限速。
我們支持了兩種限速策略,一方面是 S3 Proxy 進(jìn)程全局限速,用于保護(hù) Worker 網(wǎng)卡不被打滿;另一方面是單連接限速,用于保護(hù)業(yè)務(wù)容器所在 k8s 節(jié)點(diǎn)。限速策略我們已經(jīng)貢獻(xiàn)給了社區(qū),如果感興趣可以參考:#16866。
4. 模型訓(xùn)練場(chǎng)景適配
4.1 場(chǎng)景特點(diǎn)
我們的模型訓(xùn)練場(chǎng)景有以下特點(diǎn):
1) 因?yàn)榇蟛糠珠_源的模型訓(xùn)練框架對(duì)本地目錄支持最好,所以我們最好是為業(yè)務(wù)提供 POSIX 訪問(wèn)的方式;
2) 模型訓(xùn)練時(shí),主要瓶頸在 GPU,而內(nèi)存,磁盤,網(wǎng)卡,CPU 等物理資源比較充足;
3) GPU 機(jī)器不會(huì)運(yùn)行訓(xùn)練任務(wù)以外的任務(wù),不存在服務(wù)混布的情況;
4) 數(shù)據(jù)以快照形式管理,對(duì)元數(shù)據(jù)沒有一致性要求,但是需要有手段能夠感知 HDFS 上產(chǎn)生的新快照。
針對(duì)模型訓(xùn)練場(chǎng)景,毫無(wú)疑問(wèn)我們應(yīng)該選擇 Alluxio fuse 來(lái)提供緩存服務(wù):
1. Alluxio fuse 提供了 POSIX 訪問(wèn)方式;
2. Alluxio fuse 能夠利用內(nèi)存和磁盤做元數(shù)據(jù)緩存與數(shù)據(jù)緩存,能夠最大程度利用 GPU 機(jī)器上閑置的物理資源。
4.2 性能測(cè)試
在上線前,我們對(duì) fuse 用 fio 進(jìn)行了壓測(cè)。
Alluxio fuse 配置:

測(cè)試結(jié)果如下:
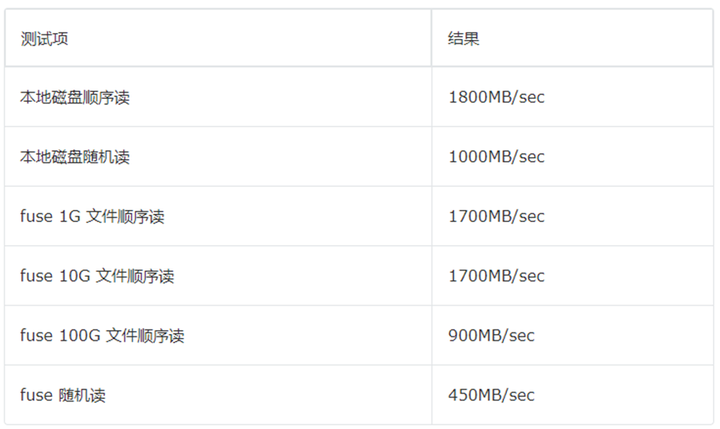
以上結(jié)果均針對(duì)數(shù)據(jù)已緩存至 fuse 本地磁盤的情況,1G 文件與 10G 文件讀取時(shí),速度是 100G 文件的兩倍,這是因?yàn)槿萜鞯膬?nèi)存為 40G,有充足的 pagecache 來(lái)緩存 1G 與 10G 的文件,但是 100G 的文件沒有充足的 pagecache,所以性能會(huì)下降,但是也能達(dá)到不錯(cuò)的速度,整體行為符合預(yù)期。
4.3 集群部署
Alluxio fuse 的部署方式我們選擇了以 DaemonSet 部署,通過(guò) host path 進(jìn)行映射,沒有選擇 CSI 部署,主要是基于以下考慮:
1) Alluxio fuse 高性能的核心在于數(shù)據(jù)緩存與元數(shù)據(jù)緩存,數(shù)據(jù)緩存需要消耗大量的磁盤,元數(shù)據(jù)緩存需要消耗大量的內(nèi)存,如果以 CSI 的形式進(jìn)行部署,每個(gè)容器只能分配到少量的磁盤與內(nèi)存給 Alluxio fuse 進(jìn)程;
2) 在模型進(jìn)行訓(xùn)練的時(shí)候,讀取的訓(xùn)練數(shù)據(jù)重復(fù)程度很高,如果每個(gè)容器起一個(gè) fuse 進(jìn)程,可能會(huì)導(dǎo)致同一機(jī)器緩存多份相同的文件,浪費(fèi)磁盤;
3) GPU 機(jī)器只跑訓(xùn)練任務(wù),所以 fuse 進(jìn)程可以 long running,無(wú)需考慮資源釋放的問(wèn)題;
4) host path 的部署方式可以很容易實(shí)現(xiàn)掛載點(diǎn)恢復(fù)。
這里對(duì)掛載點(diǎn)恢復(fù)做一個(gè)說(shuō)明,一般情況下,如果 Alluxio fuse 容器因?yàn)楦鞣N異常掛了,哪怕 fuse 進(jìn)程重新啟動(dòng)起來(lái),將目錄重新進(jìn)行掛載,但是在業(yè)務(wù)容器里的掛載點(diǎn)也是壞掉的,業(yè)務(wù)也讀不了數(shù)據(jù);但是如果做了掛載點(diǎn)恢復(fù),Alluxio fuse 容器啟動(dòng)起來(lái)以后,業(yè)務(wù)容器里的掛載點(diǎn)就會(huì)自動(dòng)恢復(fù),此時(shí)如果業(yè)務(wù)自身有重試邏輯,就能不受影響。
Alluxio fuse 進(jìn)程的掛載點(diǎn)恢復(fù)包括兩個(gè)部分,一部分是掛載點(diǎn)本身的恢復(fù),也就是 fuse 進(jìn)程每次重啟后要掛到同一個(gè)掛載點(diǎn);另一部分是客戶端緩存數(shù)據(jù)的恢復(fù),也就是 fuse 進(jìn)程每次重啟后緩存數(shù)據(jù)目錄要與原先保持一致,避免從 Alluxio 集群重復(fù)拉取已經(jīng)緩存到本地的文件。掛載點(diǎn)恢復(fù)在 CSI 里需要做一些額外的開發(fā)來(lái)支持,但是如果是以 host path 的方式映射,只要在業(yè)務(wù)容器里配置了 HostToContainer 即可,不需要額外的開發(fā)。
我們 fuse 進(jìn)程的部署架構(gòu)圖如下:
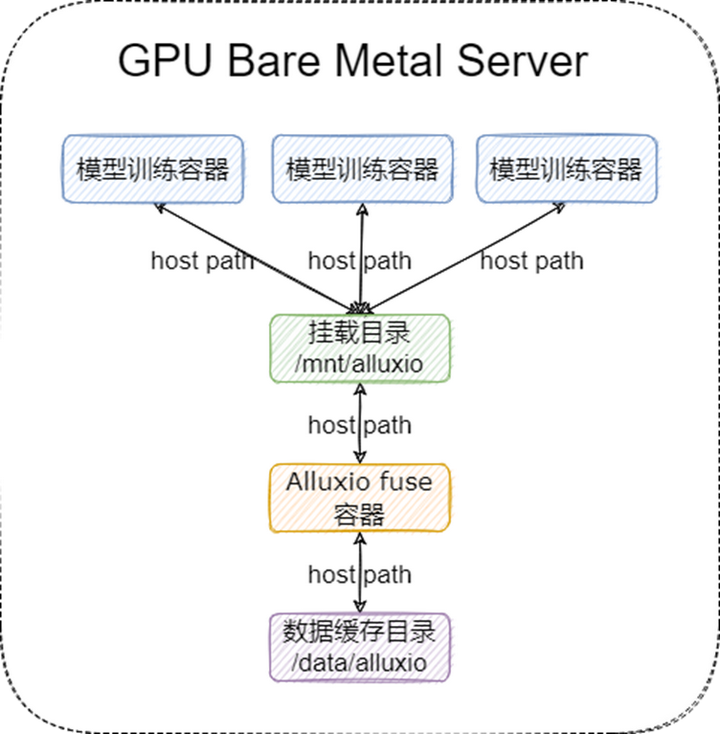
在這個(gè)場(chǎng)景下,我們的 Alluxio 集群采取了 “小集群重客戶端” 的方式來(lái)部署,即提供一個(gè)規(guī)模較小的 Alluxio 集群,只用來(lái)做數(shù)據(jù)的分發(fā),性能和緩存由 Alluxio fuse 自身保證。Alluxio 集群只需要提供高配置的 Master 和少量的 Worker 即可,集群整體的部署架構(gòu)如下:
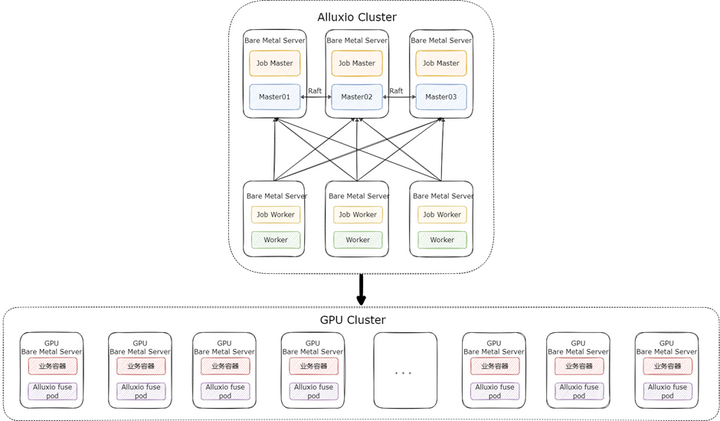
按照這種部署模式,3 臺(tái) Raft HA 的 Master 與 少量 Worker 就可支撐起 fuse 進(jìn)程大規(guī)模的部署。
4.4 Alluxio fuse 調(diào)優(yōu)
首先是元數(shù)據(jù)緩存,Alluxio fuse 可開啟元數(shù)據(jù)緩存,這里容易與 Master 對(duì) UFS 元數(shù)據(jù)的緩存弄混淆,我們簡(jiǎn)單做個(gè)說(shuō)明:
1) Alluxio Master 會(huì)緩存 UFS 的元數(shù)據(jù),決定是否更新元數(shù)據(jù)由客戶端配置的 alluxio.user.file.metadata.sync.interval 決定。假如這個(gè)值設(shè)置為 10min,客戶端在請(qǐng)求 Master 時(shí),如果 Master 在之前的 10min 內(nèi)已經(jīng)更新過(guò)元數(shù)據(jù),則 Master 會(huì)直接返回緩存的元數(shù)據(jù),而不會(huì)請(qǐng)求 UFS 拿最新的元數(shù)據(jù);否則將會(huì)返回 UFS 的最新的元數(shù)據(jù),并且更新 Master 的元數(shù)據(jù)
2) 用戶在用 Alluxio fuse 訪問(wèn) Alluxio 時(shí),會(huì)先看內(nèi)核緩存元數(shù)據(jù)是否失效(配置為 fuse 啟動(dòng)參數(shù) attr_timeout,entry_timeout),再看用戶空間元數(shù)據(jù)緩存是否失效(配置為 alluxio.user.metadata.cache.expiration.time),再看 Master 緩存是否失效(配置為 alluxio.user.file.metadata.sync.interval),只要有一層沒失效,都不能拿到 HDFS 的最新元數(shù)據(jù)。
所以建議在開啟 fuse 元數(shù)據(jù)緩存后,設(shè)置 alluxio.user.file.metadata.sync.interval=0 以便每次 fuse 在本地元數(shù)據(jù)緩存失效后,都能拿到 UFS 最新的元數(shù)據(jù)。
另外 fuse 的元數(shù)據(jù)緩存可以通過(guò)一些特殊的命令來(lái)更新(需要配置 alluxio.fuse.special.command.enabled=true):
元數(shù)據(jù)緩存可通過(guò)以下命令進(jìn)行強(qiáng)制刷新,假設(shè)我們的 mount 目錄為 /mnt/alluxio,利用以下命令可以刷新所有元數(shù)據(jù)緩存:
ls -l /mnt/alluxio/.alluxiocli.metadatacache.dropAll
利用以下命令可以刷新指定目錄(這里以 /user/test 為例)的元數(shù)據(jù)緩存
ls -l /mnt/alluxio/user/test/.alluxiocli.metadatacache.drop
在代碼中(以 python 為例),可以這樣清理元數(shù)據(jù):
import os print(os.path.getsize("/mnt/alluxio/user/test/.alluxiocli.metadatacache.drop"))
但是需要注意,內(nèi)核元數(shù)據(jù)緩存是清理不掉的,所以這里推薦內(nèi)核元數(shù)據(jù)緩存設(shè)置一個(gè)較小的值,比如一分鐘,用戶空間元數(shù)據(jù)緩存設(shè)置一個(gè)較大的值,比如一小時(shí),在對(duì)元數(shù)據(jù)有一致性要求的時(shí)候,手動(dòng)刷新用戶空間元數(shù)據(jù)緩存后,等待內(nèi)核元數(shù)據(jù)緩存失效即可。
元數(shù)據(jù)緩存和數(shù)據(jù)緩存同時(shí)開啟的情況下,清理元數(shù)據(jù)緩存的命令在使用上會(huì)有一些問(wèn)題,我們進(jìn)行了修復(fù),參考:#17029。
其次就是數(shù)據(jù)緩存,我們的 Alluxio fuse 因?yàn)槭怯?DeamonSet 的方式進(jìn)行的部署,所以數(shù)據(jù)緩存我們基本上可以用滿整臺(tái)物理機(jī)的磁盤,極大降低了 Alluxio Worker 的流量。
最后就是資源配置,因?yàn)槊總€(gè)機(jī)器只起一個(gè) fuse 進(jìn)程,所以可以適當(dāng)給 fuse 進(jìn)程多分配給一些 CPU 和內(nèi)存,CPU 可以適當(dāng)超賣,以處理突然激增的請(qǐng)求。 內(nèi)存方面,首先是堆內(nèi)存的配置,如果開啟了用戶空間元數(shù)據(jù)緩存,按照 緩存路徑量數(shù) * 2KB * 2 來(lái)設(shè)置 Xmx。另外 DirectoryMemory 可設(shè)置大一點(diǎn),一般 8G 夠用。
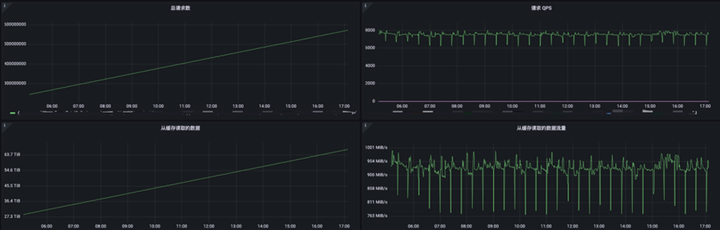
如果開啟了內(nèi)核數(shù)據(jù)緩存,還需要給容器留存一些空間來(lái)存放 pagecache,因?yàn)?kubernetes 計(jì)算容器內(nèi)存使用量會(huì)包含 pagecache 的使用量。關(guān)于 pagecache 是否會(huì)引起容器 OOM,我們查找了很多文檔都沒有得到準(zhǔn)確的結(jié)論,但是我們用如下配置進(jìn)行了壓測(cè),發(fā)現(xiàn)容器并不會(huì) OOM,并且 fuse 的表現(xiàn)十分穩(wěn)定:

4.5 上線結(jié)果
我們的算法模型訓(xùn)練切換至 Alluxio fuse 后,模型訓(xùn)練的效率達(dá)到了本地磁盤 90% 的性能,相比于原來(lái) UnionStore 的 s3fs-fuse 的掛載,性能提升了約 250%。
五、S3 Proxy 在大數(shù)據(jù)場(chǎng)景的應(yīng)用
回顧模型上線場(chǎng)景,我們不僅為算法業(yè)務(wù)提供了模型加速讀取的能力,還沉淀下來(lái)了一個(gè)與對(duì)象存儲(chǔ)協(xié)議兼容,但是下載速度遠(yuǎn)超普通對(duì)象存儲(chǔ)的組件,那就是 Alluxio S3 Proxy,所以我們現(xiàn)在完全可以做一些” 拿著錘子找釘子 “的一些事情。 這里介紹一下我們大數(shù)據(jù)組件的發(fā)布與上線流程,流程圖大致如下:
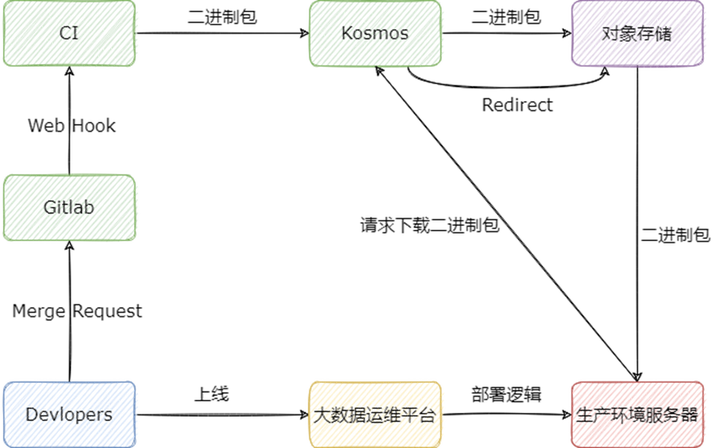
下面用文字簡(jiǎn)單描述:
1) 開發(fā)者修改代碼以后,將代碼合入對(duì)應(yīng)組件的 master 分支,此時(shí) Gitlab 將調(diào)用 CI 的 Web Hook,CI 會(huì)運(yùn)行對(duì)應(yīng)組件的打包編譯邏輯;
2) 組件打包成二進(jìn)制包后,CI 會(huì)向 Kosmos 注冊(cè)二進(jìn)制包的元信息,以及將二進(jìn)制包上傳至 Kosmos,Kosmos 在接受到二進(jìn)制包后,會(huì)上傳至對(duì)象存儲(chǔ);
3) 開發(fā)者在大數(shù)據(jù)運(yùn)維平臺(tái)選擇要上線的組件,以及組件的版本,大數(shù)據(jù)組件會(huì)自動(dòng)在生產(chǎn)環(huán)境的服務(wù)器上運(yùn)行部署邏輯;
4) 在部署邏輯運(yùn)行的過(guò)程中,會(huì)向 Kosmos 請(qǐng)求下載組件的二進(jìn)制包,Kosmos 將會(huì)直接返回對(duì)象存儲(chǔ)的只讀鏈接,供生產(chǎn)環(huán)境服務(wù)器進(jìn)行下載。
其中 Kosmos 是我們自研的包管理系統(tǒng),其誕生的背景可以參考:Flink 實(shí)時(shí)計(jì)算平臺(tái)在知乎的演進(jìn);另外我們的大數(shù)據(jù)運(yùn)維平臺(tái)也有相應(yīng)的專欄,感興趣可以查看:Ansible 在知乎大數(shù)據(jù)的實(shí)踐。
一方面,這個(gè)流程最大的問(wèn)題在于大規(guī)模上線節(jié)點(diǎn)時(shí),從對(duì)象存儲(chǔ)下載二進(jìn)制包速度過(guò)慢。比如我們要對(duì)所有的 DataNode 節(jié)點(diǎn)以及 NodeManager 節(jié)點(diǎn)做變更時(shí),每臺(tái)機(jī)器都需要下載數(shù)百 MB 甚至上 GB 的二進(jìn)制包,按照對(duì)象存儲(chǔ) 20-30MB/sec 的下載速度,每臺(tái)機(jī)器需要花費(fèi)約 30 秒的時(shí)間來(lái)進(jìn)行下載,占了整個(gè)部署邏輯約 2/3 的時(shí)間。如果按照 10000 臺(tái) DataNode 來(lái)計(jì)算,每?jī)膳_(tái)滾動(dòng)重啟(保證三副本一個(gè)副本可用),僅僅花費(fèi)在下載二進(jìn)制包上的時(shí)間就達(dá)到了 40+ 小時(shí),及其影響部署效率。
另一方面,對(duì)象存儲(chǔ)在不同的機(jī)房使用時(shí),也會(huì)面臨外網(wǎng)流量的問(wèn)題,造成比較高的費(fèi)用;所以這里對(duì) Kosmos 做了多機(jī)房改造,支持向不同的對(duì)象存儲(chǔ)上傳二進(jìn)制包,用戶在請(qǐng)求 Kosmos 時(shí),需要在請(qǐng)求上加上機(jī)房參數(shù),以便從 Kosmos 獲取同機(jī)房對(duì)象存儲(chǔ)的下載鏈接,如果用戶選錯(cuò)了機(jī)房,依然會(huì)使用外網(wǎng)流量。
上述問(wèn)題其實(shí)可以通過(guò)改造大數(shù)據(jù)運(yùn)維平臺(tái)來(lái)解決,比如將下載與部署邏輯解耦,在節(jié)點(diǎn)上以較高的并發(fā)下載二進(jìn)制包后再進(jìn)行滾動(dòng)部署,但是改造起來(lái)比較費(fèi)時(shí)費(fèi)力,更何況我們現(xiàn)在有了更高效下載文件的方式 — Alluxio S3 Proxy,所以更沒有動(dòng)力來(lái)做這個(gè)改造了。
我們將 Kosmos 的對(duì)象存儲(chǔ)掛載到 Alluxio 上,Kosmos 在被請(qǐng)求下載時(shí),返回 Alluxio S3 Proxy 的只讀鏈接,讓用戶從 S3 Proxy 讀取數(shù)據(jù),改造后的流程圖如下:

經(jīng)過(guò)我們的改造,Kosmos 幾乎所有的下載請(qǐng)求都能在 1-2 秒內(nèi)完成,相比于從對(duì)象存儲(chǔ)下載,快了 90% 以上,下圖是我們的生產(chǎn)環(huán)境中,Kosmos 分別對(duì)接對(duì)象存儲(chǔ)與 Alluxio 的下載速度對(duì)比,其中 Alluxio S3 Proxy 被我們限速至 600MB/sec:
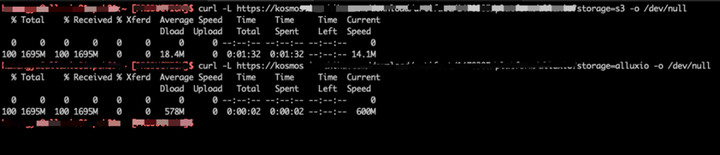
此外 Alluxio 我們也進(jìn)行了多機(jī)房部署,支持了 Kosmos 的多機(jī)房方案,哪怕是用戶選錯(cuò)了機(jī)房,也不會(huì)造成額外的外網(wǎng)流量,僅僅只是會(huì)請(qǐng)求其他機(jī)房的 Alluxio 集群,消耗一定的專線帶寬。
六、權(quán)限相關(guān)
Alluxio 在與 HDFS 對(duì)接時(shí),會(huì)繼承 HDFS 的文件權(quán)限系統(tǒng),而 HDFS 與 Alluxio 的用戶可能不一致,容易造成權(quán)限問(wèn)題。權(quán)限問(wèn)題比較重要,所以我們單獨(dú)用一個(gè)章節(jié)來(lái)做介紹。
我們通過(guò)研究代碼與測(cè)試,總結(jié)了基于 Alluxio 2.9.2 版本(HDFS 與 Alluxio 的認(rèn)證方式都是 SIMPLE),用戶與權(quán)限的映射關(guān)系,總覽圖如下:
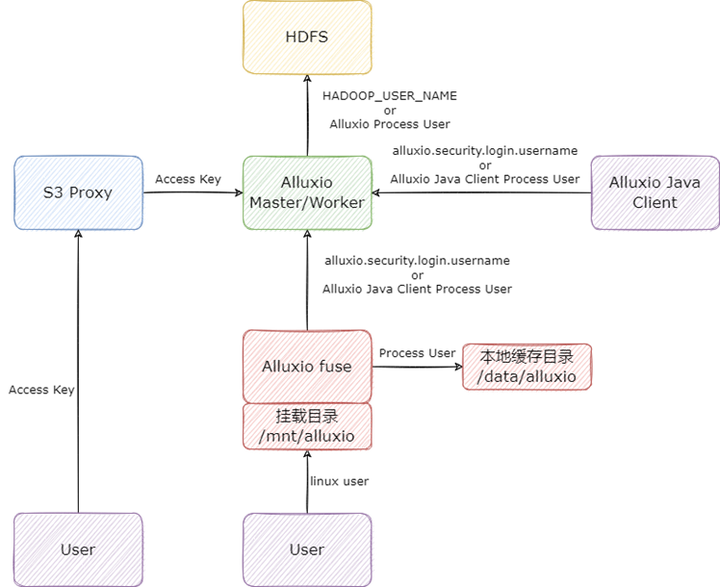
首先是 Alluxio Java Client 的用戶:Alluxio Java Client 與 Alluxio 交互時(shí),如果配置了 alluxio.security.login.username,Alluxio 客戶端將會(huì)以配置的用戶訪問(wèn) Alluxio 集群,否則將會(huì)以 Alluxio Java Client 的啟動(dòng)用戶訪問(wèn) Alluxio。
Alluxio Master/Worker 在與 HDFS 交互時(shí),如果 Master/Worker 在啟動(dòng)時(shí)配置了環(huán)境變量 HADOOP_USER_NAME(可在 alluxio-env.sh 配置),則 Master/Worker 將會(huì)以配置的用戶訪問(wèn) HDFS,否則將會(huì)以 Master/Worker 的進(jìn)程啟動(dòng)用戶訪問(wèn) HDFS。這里需要注意,Master 和 Worker 盡量配置一樣的 HDFS 用戶,否則一定會(huì)造成權(quán)限問(wèn)題。
在向 HDFS 寫入文件時(shí),Alluxio 會(huì)先以 Master/Worker 配置的 HDFS 用戶寫入文件,寫完以后會(huì)調(diào)用 HDFS 的 chown 命令,將文件的 owner 修改為 Alluxio Java Client 的用戶,這里我們舉例說(shuō)明:假設(shè) Alluxio 啟動(dòng)用戶為 alluxio,Alluxio Java Client 用戶為 test,在向 HDFS 寫入文件時(shí),Alluxio 會(huì)先將文件以 alluxio 賬號(hào)寫到 HDFS 上,再將文件 chown 變成 test 用戶,這時(shí)如果 alluxio 用戶不是 HDFS 超級(jí)用戶,在 chown 時(shí)會(huì)發(fā)生錯(cuò)誤(比較坑的一點(diǎn)是這個(gè)錯(cuò)誤 alluxio 不會(huì)拋出給客戶端),導(dǎo)致 Alluxio 上看到的文件 owner 是 test,但是 HDFS 上的文件 owner 時(shí) alluxio,造成元數(shù)據(jù)不一致。
其次是 S3 Proxy 的用戶,S3 Proxy 它也是一個(gè)比較特殊的 Alluxio Java Client,但同時(shí)它也是一個(gè) Server 端,這里主要是用戶請(qǐng)求 S3 Proxy 的 AK SK 與 HDFS 用戶的映射。S3 Proxy 默認(rèn)會(huì)將用戶的 AK 映射成訪問(wèn) Alluxio 集群的用戶,這里也可以自己實(shí)現(xiàn)映射關(guān)系,比如將 AK 映射成特定的用戶,S3 Proxy 里有相關(guān)插件。
最后是 Alluxio fuse 的用戶,Alluxio fuse 因?yàn)樯婕暗?linux 文件系統(tǒng),而且有多種與 linux 本地文件系統(tǒng)相關(guān)的實(shí)現(xiàn),所以比前面的更加復(fù)雜,這里我們只討論默認(rèn)情況,也就是 alluxio.fuse.auth.policy.class=alluxio.fuse.auth.LaunchUserGroupAuthPolicy 時(shí)的情況。用戶在訪問(wèn)掛載目錄時(shí),用的是當(dāng)前 linux 用戶,用戶看到掛載目錄里所有文件的 owner 都是 fuse 進(jìn)程啟動(dòng)用戶;fuse 在寫本地緩存目錄時(shí),用的是 fuse 進(jìn)程的啟動(dòng)用戶,此外 fuse 進(jìn)程與 Alluxio 集群交互時(shí)又完全遵循 Alluxio Java Client 的邏輯。
綜上所述,比較推薦的用戶設(shè)置方式為:
1) Alluxio 集群使用 alluxio 賬號(hào)啟動(dòng),并且將 alluxio 賬號(hào)設(shè)置為 HDFS 超級(jí)用戶;
2) S3 Proxy 用 alluxio 賬號(hào)啟動(dòng),用戶訪問(wèn)時(shí),AK 為 HDFS 賬號(hào);
3) Alluxio fuse 以 root 用戶啟動(dòng),防止寫本地?cái)?shù)據(jù)沒有權(quán)限,并且加上 allow_other 參數(shù),配置 alluxio.security.login.username 為 HDFS 用戶。
七、其他問(wèn)題
在上線過(guò)程中,我們遇到了很多問(wèn)題,其中大部分都跟配置項(xiàng)調(diào)優(yōu)有關(guān)。遇到這些問(wèn)題的原因主要還是因?yàn)?Alluxio 是面相通用設(shè)計(jì)的緩存系統(tǒng),而用戶的場(chǎng)景各式各樣,很難通過(guò)默認(rèn)配置完美適配,比如我們有多套 Alluxio 集群,每套集群用來(lái)解決不同的問(wèn)題,所以這些集群的配置都有些許差異。多虧 Alluxio 提供了許多靈活的配置,大部分問(wèn)題都能通過(guò)修改配置解決,所以這里只介紹一些讓我們印象深刻的 “代表”。
最大副本數(shù):在模型上線場(chǎng)景,緩存副本數(shù)我們不設(shè)上限,因?yàn)樵谒惴P驮谧x取時(shí),往往是一個(gè)大模型同時(shí)幾十個(gè)甚至上百個(gè)容器去讀,占用的存儲(chǔ)不多,但是讀取次數(shù)多,并且僅高并發(fā)讀取這一次,很少有再讀第二次的情況。所以這里對(duì)每一個(gè)緩存文件副本數(shù)不做限制,可以讓每個(gè) Worker 都緩存一份,這樣能夠達(dá)到最大的吞吐,擁有最好的性能。在模型訓(xùn)練場(chǎng)景,我們將緩存副本數(shù)設(shè)置為 3,一方面是因?yàn)橛?xùn)練數(shù)據(jù)量很大,需要節(jié)省存儲(chǔ),另一方面是 Alluxio fuse 的本地緩存會(huì)承擔(dān)大部分流量,所以對(duì)于 Worker 的吞吐要求相對(duì)較低。
S3 Proxy ListObjects 問(wèn)題:我們發(fā)現(xiàn) S3 Proxy 在實(shí)現(xiàn) ListObjects 請(qǐng)求時(shí),會(huì)忽略 maxkeys 參數(shù),列出大量不需要的目錄。比如我們請(qǐng)求的 prefix 是 /tmp/b, maxkeys 是 1,S3 Proxy 會(huì)遞歸列出 /tmp 下所有文件,再?gòu)乃形募锾暨x出滿足 prefix /tmp/b 的第一條數(shù)據(jù),這樣不僅性能差,也會(huì)導(dǎo)致可能出現(xiàn) OOM 的情況,我們采用臨時(shí)方案進(jìn)行的修復(fù),感興趣可以參考 #16926。這個(gè)問(wèn)題比較復(fù)雜,需要 Master 與 S3 Proxy 聯(lián)合去解決,可以期待 #16132 的進(jìn)展。
監(jiān)控地址沖突:我們監(jiān)控采用的是 Prometheus 方案,Alluxio 暴露了一部分指標(biāo),但是 JVM 指標(biāo)需要額外在 Master 或者 Worker 的啟動(dòng)參數(shù)中添加 agent 與端口暴露出來(lái),添加 agent 以后,因?yàn)?monitor 會(huì)繼承 Master 與 Worker 的啟動(dòng)參數(shù),所以 monitor 也會(huì)嘗試使用與 Master 和 Worker 同樣的指標(biāo)端口,這會(huì)出現(xiàn) ”Address already in use“ 的錯(cuò)誤,從而導(dǎo)致 monitor 啟動(dòng)失敗。具體可查看 #16657。
Master 異常加載 UFS 全量元數(shù)據(jù):如果一個(gè)路徑下有 UFS mount 路徑,在對(duì)這個(gè)路徑調(diào)用 getStatus 方法時(shí),Alluxio master 會(huì)遞歸同步這個(gè)路徑下的所有文件的元信息。比如 /a 路徑下的 /a/b 路徑是 UFS 的 mount 路徑,在調(diào)用 getStatus ("/a") 的時(shí)候,會(huì)導(dǎo)致 /a 下面的元數(shù)據(jù)被全量加載。如果 /a 是一個(gè)大路徑,可能會(huì)導(dǎo)致 Master 因?yàn)榧虞d了過(guò)多的元數(shù)據(jù)而頻繁 GC 甚至卡死。具體可查看 #16922。
Master 頻繁更新 access time:我們?cè)谑褂眠^(guò)程中,發(fā)現(xiàn) Master 偶爾會(huì)很卡,通過(guò) Alluxio 社區(qū)同學(xué)的幫助,定位到問(wèn)題來(lái)自 Master 頻繁更新文件的最后訪問(wèn)時(shí)間,通過(guò)合入 #16981,我們解決了這個(gè)問(wèn)題。
八、總結(jié)與展望
其實(shí)從 2022 年的下半年我們就開始調(diào)研 Alluxio 了,但是因?yàn)榉N種原因,中途擱置了一段時(shí)間,導(dǎo)致 Alluxio 推遲到今年才上線。在我們調(diào)研與上線的過(guò)程中,Alluxio 社區(qū)是我們最強(qiáng)大的外援,為我們提供了海量的幫助。
本次我們?cè)谒惴▓?chǎng)景對(duì) Alluxio 小試牛刀,取得的結(jié)果令人十分驚喜。
從性能上講,在算法模型上線的場(chǎng)景,我們將 UnionStore 用 Alluxio 替換后,最高能夠獲得數(shù)十倍的性能提升;在模型訓(xùn)練場(chǎng)景,我們配合 Alluxio fuse 的本地?cái)?shù)據(jù)緩存,能夠達(dá)到近似本地 NVME 磁盤的速度,相比于 UnionStore + s3fs-fuse 的方案,性能提升了 2-3 倍。
從穩(wěn)定性上講,在 HDFS 抖動(dòng)或者升級(jí)切主的時(shí)候,因?yàn)橛袛?shù)據(jù)緩存和元數(shù)據(jù)緩存,Alluxio 能夠在一定時(shí)間內(nèi)不受影響,正常提供服務(wù)。 從成本上講,Alluxio 相比于 UnionStore 每年為我們節(jié)省了數(shù)十萬(wàn)真金白銀,而且性能上還有盈余。
從長(zhǎng)遠(yuǎn)的發(fā)展來(lái)看,Alluxio 具有強(qiáng)大的可擴(kuò)展性,尤其是 Alluxio 的新一代架構(gòu) Dora ,能夠支持我們對(duì)海量小文件緩存的需求,這讓我們更有信心支撐算法團(tuán)隊(duì),面對(duì)即將到來(lái)的人工智能浪潮。 最后再次感謝 Alluxio 團(tuán)隊(duì),在我們上線的過(guò)程中為我們提供了大量的幫助與建議,也希望我們后續(xù)能夠在大數(shù)據(jù) OLAP 查詢加速場(chǎng)景以及分布式數(shù)據(jù)集編排領(lǐng)域繼續(xù)深入合作與交流。
【案例二:螞蟻】Alluxio 在螞蟻集團(tuán)大規(guī)模訓(xùn)練中的應(yīng)用
一、背景介紹
首先是我們?yōu)槭裁匆?Alluxio,其實(shí)我們面臨的問(wèn)題和業(yè)界基本上是相同的:
第一個(gè)是存儲(chǔ) IO 的性能問(wèn)題,目前 gpu 的模型訓(xùn)練速度越來(lái)越快,勢(shì)必會(huì)對(duì)底層存儲(chǔ)造成一定的壓力,如果底層存儲(chǔ)難以支持目前 gpu 的訓(xùn)練速度,就會(huì)嚴(yán)重制約模型訓(xùn)練的效率。
第二個(gè)是單機(jī)存儲(chǔ)容量問(wèn)題,目前我們的模型集合越來(lái)越大,那么勢(shì)必會(huì)造成單機(jī)無(wú)法存放的問(wèn)題。那么對(duì)于這種大模型訓(xùn)練,我們是如何支持的?
第三個(gè)是網(wǎng)絡(luò)延遲問(wèn)題,目前我們有很多存儲(chǔ)解決方案,但都沒辦法把一個(gè)高吞吐、高并發(fā)以及低延時(shí)的性能融合到一起,而 Alluxio 為我們提供了一套解決方案,Alluxio 比較小型化,隨搭隨用,可以和計(jì)算機(jī)型部署在同一個(gè)機(jī)房,這樣可以把網(wǎng)絡(luò)延時(shí)、性能損耗降到最低,主要出于這個(gè)原因我們決定把 Alluxio 引入螞蟻集團(tuán)。
以下是分享的核心內(nèi)容:總共分為 3 個(gè)部分,也就是 Alluxio 引入螞蟻集團(tuán)之后,我們主要從以下三個(gè)方面進(jìn)行了性能優(yōu)化:第一部分是穩(wěn)定性建設(shè)、 第二部分是性能優(yōu)化、第三部分是規(guī)模提升。
二、穩(wěn)定性建設(shè)
首先介紹為什么要做穩(wěn)定性的建設(shè),如果我們的資源是受 k8s 調(diào)度的,然后我們頻繁的做資源重啟或者遷移,那么我們就需要面臨集群頻繁的做 FO,F(xiàn)O 的性能會(huì)直接反映到用戶的體驗(yàn)上,如果我們的 FO 時(shí)間兩分鐘不可用,那么用戶可能就會(huì)看到有大量的報(bào)錯(cuò),如果幾個(gè)小時(shí)不可用,那用戶的模型訓(xùn)練可能就會(huì)直接 kill 掉,所以穩(wěn)定性建設(shè)是至關(guān)重要的,我們做的優(yōu)化主要是從兩塊進(jìn)行:一個(gè)是 worker register follower,另外一個(gè)是 master 遷移。
1.Worker Register Follower
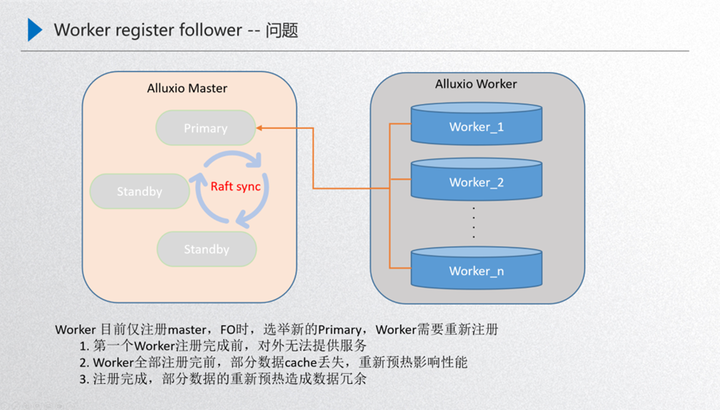
先介紹下這個(gè)問(wèn)題的背景:上圖是我們 Alluxio 運(yùn)行的穩(wěn)定狀態(tài),由 master 進(jìn)行元數(shù)據(jù)服務(wù),然后內(nèi)部通過(guò) raft 的進(jìn)行元數(shù)據(jù)一致性的同步,通過(guò) primary 對(duì)外提供元數(shù)據(jù)的服務(wù),然后通過(guò) worker 節(jié)點(diǎn)對(duì)外提供 data 數(shù)據(jù)的服務(wù),這兩者之間是通過(guò) worker 注冊(cè) primary 進(jìn)行一個(gè)發(fā)現(xiàn),也就是 worker 節(jié)點(diǎn)的發(fā)現(xiàn),這樣就可以保證在穩(wěn)定狀態(tài)下運(yùn)行。那如果這時(shí)候?qū)?primary 進(jìn)行了重啟,就需要做一次 FO 的遷移,也就是接下來(lái)這個(gè)過(guò)程,比如這時(shí)候?qū)?primary 進(jìn)行了重啟,那么內(nèi)部的 standby 就需要通過(guò) raft 進(jìn)行重新選舉,選舉出來(lái)之前,其實(shí) primary 的元數(shù)據(jù)和 worker 是斷聯(lián)的,斷連的狀態(tài)下就需要進(jìn)行 raft 的一致性選舉,進(jìn)行一次故障的轉(zhuǎn)移,接下來(lái)如果這臺(tái)機(jī)器選舉出來(lái)一個(gè)新的 primary,這個(gè)時(shí)候 work 就需要重新進(jìn)行一次發(fā)現(xiàn),發(fā)現(xiàn)之后注冊(cè)到 primary 里面,這時(shí)新的 primary 就對(duì)外提供元數(shù)據(jù)的服務(wù),而 worker 對(duì)外提供 data 數(shù)據(jù)的服務(wù),這樣就完成了一次故障的轉(zhuǎn)移,那么問(wèn)題點(diǎn)就發(fā)生在故障發(fā)生在做 FO 的時(shí)候,worker 發(fā)現(xiàn)新的 primary 后需要重新進(jìn)行一次注冊(cè),這個(gè)部分主要面臨三個(gè)問(wèn)題:
第一個(gè)就是首個(gè) worker 注冊(cè)前集群是不可用的,因?yàn)閯傞_始首個(gè) worker 恢復(fù)了新的 primary 領(lǐng)導(dǎo)能力,如果這個(gè)時(shí)候沒有 worker,其實(shí)整個(gè) primary 是沒有 data 節(jié)點(diǎn)的,也就是只能訪問(wèn)元數(shù)據(jù)而不能訪問(wèn) data 數(shù)據(jù)。
第二個(gè)是所有 worker 注冊(cè)過(guò)程中,冷數(shù)據(jù)對(duì)性能的影響。如果首個(gè) worker 注冊(cè)進(jìn)來(lái)了,這時(shí)就可以對(duì)外提供服務(wù),因?yàn)橛?data 節(jié)點(diǎn)了,而在陸續(xù)的注冊(cè)的過(guò)程當(dāng)中如果首個(gè)節(jié)點(diǎn)注冊(cè)進(jìn)來(lái)了,然后后續(xù)的節(jié)點(diǎn)在注冊(cè)的過(guò)程當(dāng)中,用戶訪問(wèn) worker2 的緩存 block 的時(shí)候,worker2 處于一種 miss 的狀態(tài),這時(shí)候 data 數(shù)據(jù)是丟失的,會(huì)從現(xiàn)存的 worker 中選舉出來(lái)到底層去讀文件,把文件讀進(jìn)來(lái)后重新對(duì)外提供服務(wù),但是讀的過(guò)程當(dāng)中,比如說(shuō) worker1 去 ufs 里面讀的時(shí)候,這就牽扯了一個(gè)預(yù)熱的過(guò)程,會(huì)把性能拖慢,這就是注冊(cè)當(dāng)中的問(wèn)題。
第三個(gè)是 worker 注冊(cè)完成之后的數(shù)據(jù)冗余清理問(wèn)題。注冊(cè)完成之后,其實(shí)還有一個(gè)問(wèn)題就是在注冊(cè)的過(guò)程當(dāng)中不斷有少量數(shù)據(jù)進(jìn)行了重新預(yù)熱,worker 全部注冊(cè)之后,注冊(cè)過(guò)程中重新緩存的這部分?jǐn)?shù)據(jù)就會(huì)造成冗余, 那就需要進(jìn)行事后清理,按照這個(gè)嚴(yán)重等級(jí)其實(shí)就是第一個(gè) worker 注冊(cè)前,這個(gè)集群不可用,如果 worker 規(guī)格比較小,可能注冊(cè)的時(shí)間 2-5 分鐘,這 2-5 分鐘這個(gè)集群可能就不可用,那用戶看到的就是大量報(bào)錯(cuò),如果 worker 規(guī)格比較大,例如一個(gè)磁盤有幾 tb 的體量,完全注冊(cè)上來(lái)需要幾個(gè)小時(shí)。那這幾個(gè)小時(shí)整個(gè)集群就不可對(duì)外提供服務(wù),這樣在用戶看來(lái)這個(gè)集群是不穩(wěn)定的,所以這個(gè)部分是必須要進(jìn)行優(yōu)化的。
我們目前的優(yōu)化方案是:把所有的 worker 向所有的 master 進(jìn)行注冊(cè),提前進(jìn)行注冊(cè),只要 worker 起來(lái)了 那就向所有的 master 重新注冊(cè)一遍,然后中間通過(guò)這種實(shí)時(shí)的心跳保持 worker 狀態(tài)的更新。那么這個(gè)優(yōu)化到底產(chǎn)生了怎樣效果?可以看下圖:
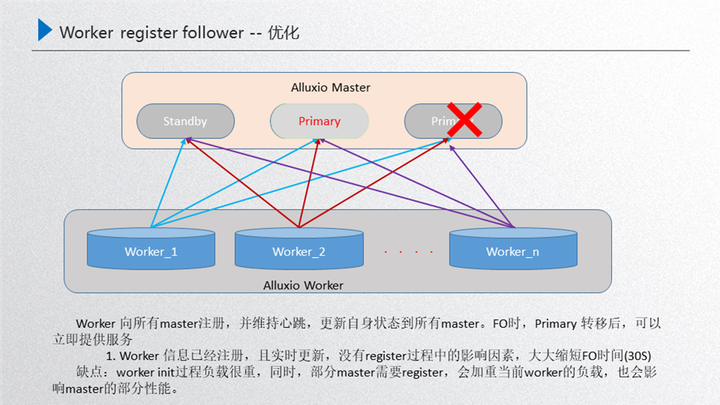
這個(gè)時(shí)候如果 primary 被重啟了,內(nèi)部通過(guò) raft 進(jìn)行選舉,選舉出來(lái)的這個(gè)新的 primary 對(duì)外提供服務(wù),primary 的選舉需要經(jīng)歷幾部分:第一部分就是 primary 被重啟之后,raft 進(jìn)行自發(fā)現(xiàn),自發(fā)現(xiàn)之后兩者之間進(jìn)行重新選舉,選舉出來(lái)之后這個(gè)新的 primary 經(jīng)過(guò) catch up 后就可以對(duì)外提供服務(wù)了,就不需要重新去獲取 worker 進(jìn)行一個(gè) register,所以這就可以把時(shí)間完全節(jié)省下來(lái),只需要三步:自發(fā)現(xiàn)、選舉、catch up。 這個(gè)方案的效率非常高,只需要 30 秒以內(nèi)就可以完成,這就大大縮短了 FO 的時(shí)間。另一個(gè)層面來(lái)說(shuō),這里也有一些負(fù)面的影響,主要是其中一個(gè) master 如果進(jìn)行了重啟,那么對(duì)外來(lái)說(shuō)這個(gè) primary 是可以提供正常服務(wù)的,然后這個(gè) standby 重啟的話,在對(duì)外提供服務(wù)的同時(shí),worker 又需要重新注冊(cè)這個(gè) block 的元數(shù)據(jù)信息,這個(gè) block 元數(shù)據(jù)信息其實(shí)流量是非常大的,這時(shí)會(huì)對(duì)當(dāng)前的 worker 有一定影響,而且對(duì)部分注冊(cè)上來(lái)的 master 性能也有影響,如果這個(gè)時(shí)候集群的負(fù)載不是很重的話,是完全可以忽略的,所以做了這樣的優(yōu)化。
2.Master 的遷移問(wèn)題
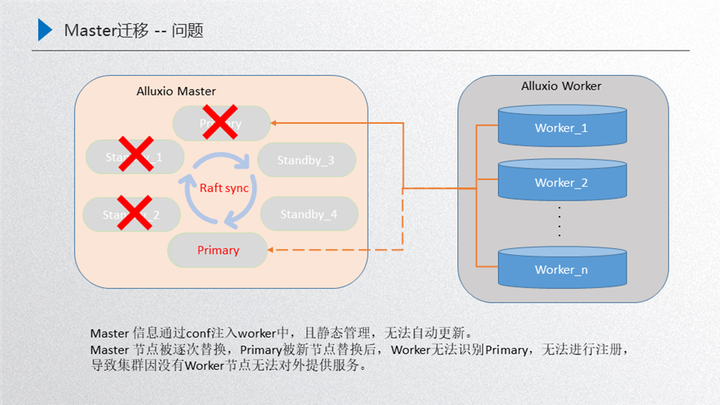
如圖所示,其實(shí)剛開始是由這三者 master 對(duì)外提供服務(wù), 這三者達(dá)到一個(gè)穩(wěn)定的狀態(tài),然后 worker 注冊(cè)到 primary 對(duì)外提供服務(wù),這個(gè)時(shí)候如果對(duì)機(jī)器做了一些騰挪,比如 standby3 把 standby1 替換掉,然后 standby4 把 standby2 替換掉,然后新的 primary 把老的 primary 替換掉,這個(gè)時(shí)候新的這個(gè) master 的集群節(jié)點(diǎn)就是由這三者組成:standby3、standby4、新的 primary,按照正常的流程來(lái)說(shuō),這個(gè) worker 是需要跟當(dāng)前這個(gè)新的集群進(jìn)行建聯(lián)的,維持一個(gè)正常的心跳,然后對(duì)外提供服務(wù),但是這時(shí)候并沒有,主要原因就是 worker 識(shí)別的 master 信息其實(shí)是一開始由 configer 進(jìn)行靜態(tài)注入的,在初始化的時(shí)候就已經(jīng)寫進(jìn)去了,而且后臺(tái)是靜態(tài)管理的,沒有動(dòng)態(tài)的更新,所以永遠(yuǎn)都不能識(shí)別這三個(gè)節(jié)點(diǎn), 識(shí)別的永遠(yuǎn)是三個(gè)老節(jié)點(diǎn),相當(dāng)于是說(shuō)這種場(chǎng)景直接把整個(gè)集群搞掛了,對(duì)外沒有 data 節(jié)點(diǎn)就不可提供服務(wù)了,恢復(fù)手段主要是需要手動(dòng)把這三個(gè)新節(jié)點(diǎn)注冊(cè)到 configer 當(dāng)中,重新把這個(gè) worker 重啟一遍,然后進(jìn)行識(shí)別,如果這個(gè)時(shí)候集群規(guī)模比較大,worker 節(jié)點(diǎn)數(shù)量比較多,那這時(shí)的運(yùn)維成本就會(huì)非常大,這是我們面臨的 master 遷移問(wèn)題,接下來(lái)看一下怎么應(yīng)對(duì)這種穩(wěn)定性:
我們的解決方案是在 primary 和 worker 之間維持了一個(gè)主心跳,如果 master 節(jié)點(diǎn)變更了就會(huì)通過(guò)主心跳同步當(dāng)前的 worker,實(shí)現(xiàn)實(shí)時(shí)更新 master 節(jié)點(diǎn),比如 standby3 把 standby1 替換掉了,這個(gè)時(shí)候 primary 會(huì)把當(dāng)前的這三個(gè)節(jié)點(diǎn):primary、standby2、standby3 通過(guò)主心跳同步過(guò)來(lái)給當(dāng)前的 worker,這個(gè)時(shí)候 worker 就是最新的,如果再把 standby4、standby2 替換,這時(shí)候又會(huì)把這三者之間的狀態(tài)同步過(guò)來(lái),讓他保持是最新的,如果接下來(lái)把新的 primary 加進(jìn)來(lái),就把這四者之間同步過(guò)來(lái),重啟之后進(jìn)行選舉,選舉出來(lái)之后 這就是新的 primary,由于 worker 節(jié)點(diǎn)最后的一步是存著這四個(gè)節(jié)點(diǎn),在這四個(gè)節(jié)點(diǎn)當(dāng)中便利尋找當(dāng)前的 leader,然后就可以識(shí)別新的 primary,再把這三個(gè)新的 master 同步過(guò)來(lái) 這樣就達(dá)到一個(gè)安全的迭代過(guò)程,這樣的情況下再受資源調(diào)度騰挪的時(shí)候,就可以穩(wěn)定的騰挪下去。以上兩部分就是穩(wěn)定性建設(shè)的內(nèi)容。
三、性能優(yōu)化
性能優(yōu)化我們主要進(jìn)行了 follower read only 的過(guò)程,首先給大家介紹一下背景,如圖所示:
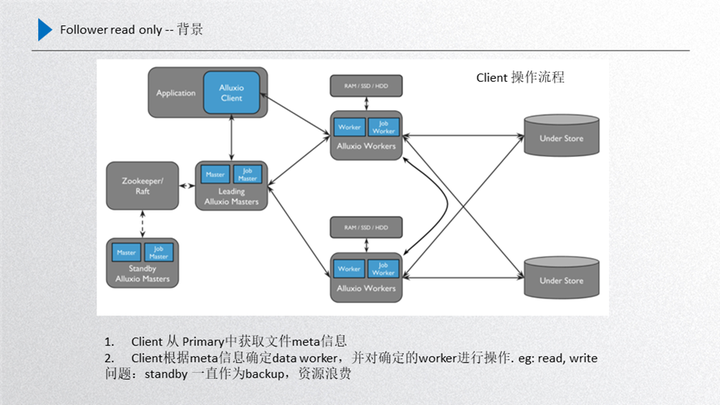
這個(gè)是當(dāng)前 Alluxio 的整體框架,首先 client 端從 leader 拿取到元數(shù)據(jù),根據(jù)元數(shù)據(jù)去訪問(wèn)正常的 worker,leader 和 standby 之間通過(guò) raft 進(jìn)行與元數(shù)據(jù)一致性的同步,leader 進(jìn)行元數(shù)據(jù)的同步只能通過(guò) leader 發(fā)起然后同步到 standby,所以說(shuō)他是有先后順序的。而 standby 不能通過(guò)發(fā)起新的信息同步到 leader,這是一個(gè)違背數(shù)據(jù)一致性原則的問(wèn)題。
另一部分就是當(dāng)前的這個(gè) standby 經(jīng)過(guò)前面的 worker register follower 的優(yōu)化之后,其實(shí) standby 和 worker 之間也是有一定聯(lián)系的,而且數(shù)據(jù)都會(huì)收集上來(lái),這樣就是 standby 在數(shù)據(jù)的完整性上已經(jīng)具備了 leader 的屬性,也就是數(shù)據(jù)基本上和 leader 是保持一致的。
而這一部分如果再把它作為 backup,即作為一種穩(wěn)定性備份的話,其實(shí)就是一種資源的浪費(fèi),想利用起來(lái)但又不能打破 raft 數(shù)據(jù)一致性的規(guī)則,這種情況下我們就嘗試是不是可以提供只讀服務(wù), 因?yàn)橹蛔x服務(wù)不需要更新 raft 的 journal entry,對(duì)一致性沒有任何的影響,這樣 standby 的性能就可以充分利用起來(lái),所以說(shuō)這里想了一些優(yōu)化的方案,而且還牽扯了一個(gè)業(yè)務(wù)場(chǎng)景,就是如果我們的場(chǎng)景適用于模型訓(xùn)練或者文件的 cache 加速的,那只有第一次預(yù)熱的時(shí)候數(shù)據(jù)才會(huì)有寫入,后面是只讀的,針對(duì)大量只讀場(chǎng)景應(yīng)用 standby 對(duì)整個(gè)集群的性能取勝是非常可觀的。
下面是詳細(xì)的優(yōu)化方案,如圖所示:
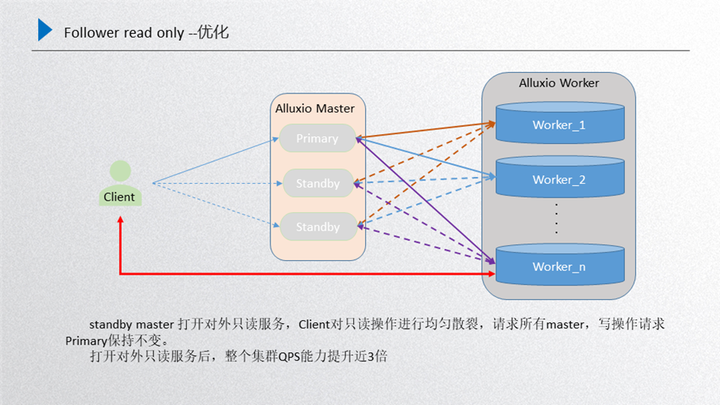
主要是針對(duì)前面進(jìn)行的總結(jié),所有的 worker 向所有的 standby 進(jìn)行注冊(cè),這時(shí)候 standby 的數(shù)據(jù)和 primary 的數(shù)據(jù)基本上是一致的,另一部分還是 primary 和 worker 之間維護(hù)的主心跳,這個(gè)時(shí)候如果 client 端再發(fā)起只讀請(qǐng)求的時(shí)候,就會(huì)隨機(jī)散列到當(dāng)前所有的 master 上由他們進(jìn)行處理,處理完成之后返回 client 端,對(duì)于寫的請(qǐng)求還是會(huì)發(fā)放到 primary 上去。然后在不打破 raft 一致性的前提下,又可以把只讀的性能提升,這個(gè)機(jī)器擴(kuò)展出來(lái),按照正常推理來(lái)說(shuō),只讀性能能夠達(dá)到三倍以上的擴(kuò)展,通過(guò) follower read 實(shí)際測(cè)驗(yàn)下來(lái)效果也是比較明顯的。這是我們引入 Alluxio 之后對(duì)性能的優(yōu)化。
四、規(guī)模提升
規(guī)模提升主要是橫向擴(kuò)展,首先看一下這個(gè)問(wèn)題的背景:如圖所示:
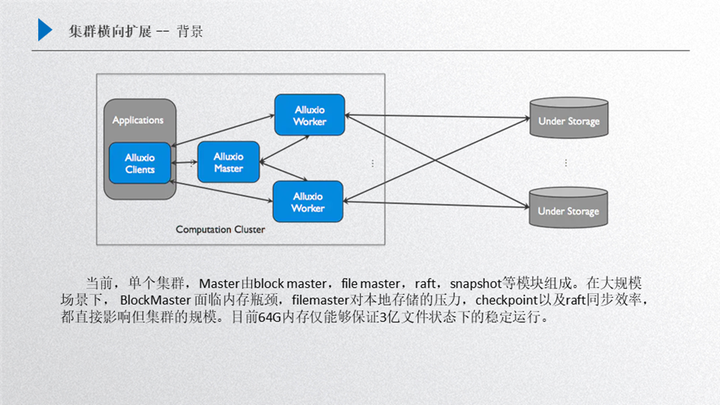
還是 Alluxio 的框架,master 里面主要包含了很多構(gòu)件元素,第一個(gè)就是 block master,第二個(gè)是 file master,另外還有 raft 和 snapshot,這個(gè)部分的主要影響因素就是在這四個(gè)方面:
Bblock master,如果我們是大規(guī)模集群創(chuàng)建下,block master 面臨的瓶頸就是內(nèi)存,它會(huì)侵占掉大量 master 的內(nèi)存,主要是保存的 worker 的 block 信息;
File master,主要是保存了 inode 信息,如果是大規(guī)模場(chǎng)景下,對(duì)本地存儲(chǔ)的壓力是非常大的
Raft 面臨的同步效率問(wèn)題;
snapshot 的效率,如果 snapshot 的效率跟不上,可以發(fā)現(xiàn)后臺(tái)會(huì)積壓非常多 journal entry,這對(duì)性能提升也有一定影響;
做了一些測(cè)試之后,在大規(guī)模場(chǎng)景下,其實(shí)機(jī)器規(guī)格不是很大的話,也就支持 3-6 個(gè)億這樣的規(guī)模,如果想支持 10 億甚至上百億這樣的規(guī)模,全部靠擴(kuò)大存儲(chǔ)機(jī)器的規(guī)格是不現(xiàn)實(shí)的,因?yàn)槟P陀?xùn)練的規(guī)模可以無(wú)限增長(zhǎng),但是機(jī)器的規(guī)格不可以無(wú)限擴(kuò)充,那么針對(duì)這個(gè)問(wèn)題我們是如何優(yōu)化的呢?
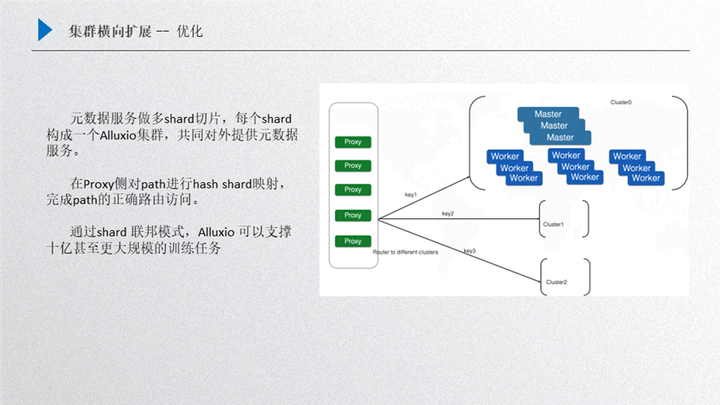
這個(gè)優(yōu)化我們主要借鑒了 Redis 的實(shí)現(xiàn)方案,就是可以在底層對(duì)元數(shù)據(jù)進(jìn)行分片,然后由多個(gè) cluster 集群對(duì)外提供服務(wù),這樣做的一個(gè)好處就是對(duì)外可以提供一個(gè)整體,當(dāng)然也可以采取不同的優(yōu)化策略,比如多個(gè)集群完全由用戶自己去掌控,把不同的數(shù)據(jù)分配到每一個(gè)集群上,但這樣對(duì)用戶的使用壓力就會(huì)比較大。先來(lái)介紹一下這個(gè)框架,首先我們把這個(gè)元數(shù)據(jù)進(jìn)行一個(gè)分片,比如用戶拿到的整體數(shù)據(jù)規(guī)模集合比較大,單集群放不下了,這時(shí)候會(huì)把大規(guī)模的數(shù)據(jù)集合進(jìn)行一個(gè)分片,把元數(shù)據(jù)進(jìn)行一些哈希(Hash)映射,把一定 hash 的值映射到其中某一個(gè) shard 上,這樣 cluster 這個(gè)小集群就只需要去緩存對(duì)應(yīng)部分 key 對(duì)應(yīng)的文件,這樣就可以在集群上面有目標(biāo)性的進(jìn)行選擇。
那么接下來(lái)其他的數(shù)據(jù)就會(huì)留給其他 cluster,把全量的 hash 分配到一個(gè)設(shè)定的集群規(guī)模上,這樣就可以通過(guò)幾個(gè) shard 把整個(gè)大的模型訓(xùn)練文件數(shù)量 cache 下來(lái),對(duì)外提供大規(guī)模的模型訓(xùn)練,然后我們的前端是增加了 proxy,proxy 其實(shí)內(nèi)部是維護(hù)一張 hash 映射表的,用戶過(guò)來(lái)的請(qǐng)求其實(shí)是通過(guò) proxy 進(jìn)行 hash 的映射查找,然后分配到固定的某一個(gè)集群上進(jìn)行處理,比如過(guò)來(lái)的一個(gè)文件請(qǐng)求通過(guò)計(jì)算它的 hash 映射可以判定 hash 映射路由到 cluster1 上面去,這樣其實(shí)就可以由 cluster1 負(fù)責(zé),其他 key 的映射分配到其他 cluster 上,把數(shù)據(jù)打散,這樣的好處有很多方面:
第一個(gè)就是元數(shù)據(jù)承載能力變大了;
第二個(gè)就把請(qǐng)求的壓力分配到多個(gè)集群上去,整體的 qps 能力、集群的吞吐能力都會(huì)得到相應(yīng)的提升;
第三個(gè)就是通過(guò)這種方案,理論上可以擴(kuò)展出很多的 cluster 集群,如果單個(gè)集群支持的規(guī)模是 3-6 個(gè)億,那三個(gè)集群支持的規(guī)模就是 9-18 億,如果擴(kuò)展的更多,對(duì)百億這種規(guī)模也可以提供一種支持的解決方案。
以上是我們對(duì)模型進(jìn)行的一些優(yōu)化。整個(gè)的框架包括穩(wěn)定性的建設(shè)、性能的優(yōu)化和規(guī)模的提升。
在穩(wěn)定建設(shè)方面:我們可以把整個(gè)集群做 FO 的時(shí)間控制在 30 秒以內(nèi),如果再配合一些其他機(jī)制,比如 client 端有一些元數(shù)據(jù)緩存機(jī)制,就可以達(dá)到一種用戶無(wú)感知的條件下進(jìn)行 FO,這種效果其實(shí)也是用戶最想要的,在他們無(wú)感知的情況下,底層做的任何東西都可以恢復(fù),他們的業(yè)務(wù)訓(xùn)練也不會(huì)中斷,也不會(huì)有感到任何的錯(cuò)誤,所以這種方式對(duì)用戶來(lái)說(shuō)是比較友好的。
在性能優(yōu)化方面:?jiǎn)蝹€(gè)集群的吞吐已經(jīng)形成了三倍以上提升,整個(gè)性能也會(huì)提升上來(lái),可以支持更大并發(fā)的模型訓(xùn)練任務(wù)。
在模型規(guī)模提升方面:模型訓(xùn)練集合越來(lái)越大,可以把這種模型訓(xùn)練引入進(jìn)來(lái),對(duì)外提供支持。
在 Alluxio 引入螞蟻適配這些優(yōu)化之后,目前運(yùn)行下來(lái)對(duì)各個(gè)方向業(yè)務(wù)的支持效果都是比較明顯的。另外目前我們跟開源社區(qū)也有很多的合作,社區(qū)也給我們提供很多幫助,比如在一些比較著急的問(wèn)題上,可以給我們提供一些解決方案和幫助,在此我們表示感謝!
【案例三:微軟】面向大規(guī)模深度學(xué)習(xí)訓(xùn)練的緩存優(yōu)化實(shí)踐
分享嘉賓:張虔熙 - 微軟高級(jí)研發(fā)工程師
導(dǎo)讀
近些年,隨著深度學(xué)習(xí)的崛起, Alluxio 分布式緩存技術(shù)逐步成為業(yè)界解決云上 IO 性能問(wèn)題的主流方案。不僅如此,Alluxio 還天然具備數(shù)據(jù)湖所需的統(tǒng)一管理和訪問(wèn)的能力。本文將分享面向大規(guī)模深度學(xué)習(xí)訓(xùn)練的緩存優(yōu)化,主要分析如今大規(guī)模深度學(xué)習(xí)訓(xùn)練的存儲(chǔ)現(xiàn)狀與挑戰(zhàn),說(shuō)明緩存數(shù)據(jù)編排在深度學(xué)習(xí)訓(xùn)練中的應(yīng)用,并介紹大規(guī)模緩存系統(tǒng)的資源分配與調(diào)度。
一、項(xiàng)目背景和緩存策略
首先來(lái)分享一下相關(guān)背景。
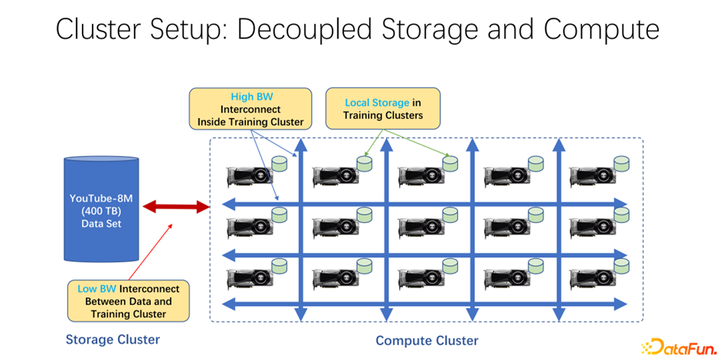
近年來(lái),AI 訓(xùn)練應(yīng)用越來(lái)越廣泛。從基礎(chǔ)架構(gòu)角度來(lái)看,無(wú)論是大數(shù)據(jù)還是 AI 訓(xùn)練集群中,大多使用存儲(chǔ)與計(jì)算分離的架構(gòu)。比如很多 GPU 的陣列放到一個(gè)很大的計(jì)算集群中,另外一個(gè)集群是存儲(chǔ)。也可能是使用的一些云存儲(chǔ),像微軟的 Azure 或者是亞馬遜的 S3 等。這樣的基礎(chǔ)架構(gòu)的特點(diǎn)是,首先,計(jì)算集群中有很多非常昂貴的 GPU,每臺(tái) GPU 往往有一定的本地存儲(chǔ),比如 SSD 這樣的幾十 TB 的存儲(chǔ)。這樣一個(gè)機(jī)器組成的陣列中,往往是用高速網(wǎng)絡(luò)去連接遠(yuǎn)端,比如 Coco、 image net、YouTube 8M 之類的非常大規(guī)模的訓(xùn)練數(shù)據(jù)是以網(wǎng)絡(luò)進(jìn)行連接的。
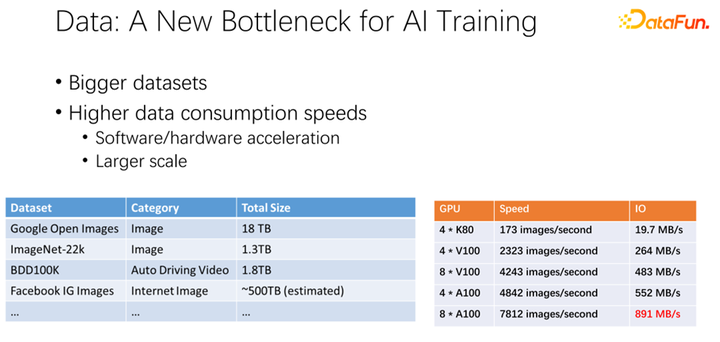
如上圖所示,數(shù)據(jù)有可能會(huì)成為下一個(gè) AI 訓(xùn)練的瓶頸。我們觀察到數(shù)據(jù)集越來(lái)越大,隨著 AI 應(yīng)用更加廣泛,也在積累更多的訓(xùn)練數(shù)據(jù)。同時(shí) GPU 賽道是非常卷的。比如 AMD、TPU 等廠商,花費(fèi)了大量精力去優(yōu)化硬件和軟件,使得加速器,類似 GPU、TPU 這些硬件越來(lái)越快。隨著公司內(nèi)加速器的應(yīng)用非常廣泛之后,集群部署也越來(lái)越大。這里的兩個(gè)表呈現(xiàn)了關(guān)于數(shù)據(jù)集以及 GPU 速度的一些變化。之前的 K80 到 V100、 P100、 A100,速度是非常迅速的。但是,隨著速度越來(lái)越快,GPU 變得越來(lái)越昂貴。我們的數(shù)據(jù),比如 IO 速度能否跟上 GPU 的速度,是一個(gè)很大的挑戰(zhàn)。
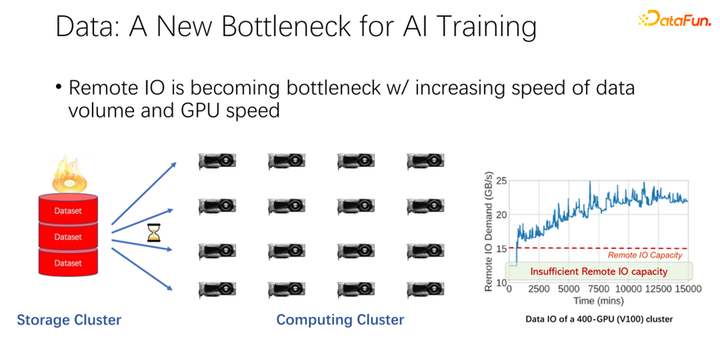
如上圖所示,在很多大公司的應(yīng)用中,我們觀察到這樣一個(gè)現(xiàn)象:在讀取遠(yuǎn)程數(shù)據(jù)的時(shí)候,GPU 是空閑的。因?yàn)?GPU 是在等待遠(yuǎn)程數(shù)據(jù)讀取,這也就意味著 IO 成為了一個(gè)瓶頸,造成了昂貴的 GPU 被浪費(fèi)。有很多工作在進(jìn)行優(yōu)化來(lái)緩解這一瓶頸,緩存就是其中很重要的一個(gè)優(yōu)化方向。這里介紹兩種方式。

第一種,在很多應(yīng)用場(chǎng)景中,尤其是以 K8s 加 Docker 這樣的基礎(chǔ) AI 訓(xùn)練架構(gòu)中,用了很多本地磁盤。前文中提到 GPU 機(jī)器是有一定的本地存儲(chǔ)的,可以用本地磁盤去做一些緩存,把數(shù)據(jù)先緩存起來(lái)。啟動(dòng)了一個(gè) GPU 的 Docker 之后,不是馬上啟動(dòng) GPU 的 AI 訓(xùn)練,而是先去下載數(shù)據(jù),把數(shù)據(jù)從遠(yuǎn)端下載到 Docker 內(nèi)部,也可以是掛載等方式。下載到 Docker 內(nèi)部之后再開始訓(xùn)練。這樣盡可能的把后邊的訓(xùn)練的數(shù)據(jù)讀取都變成本地的數(shù)據(jù)讀取。本地 IO 的性能目前來(lái)看是足夠支撐 GPU 的訓(xùn)練的。VLDB 2020 上面,有一篇 paper,CoorDL,是基于 DALI 進(jìn)行數(shù)據(jù)緩存。這一方式也帶來(lái)了很多問(wèn)題。首先,本地的空間是有限的,意味著緩存的數(shù)據(jù)也是有限的,當(dāng)數(shù)據(jù)集越來(lái)越大的時(shí)候,很難緩存到所有數(shù)據(jù)。另外,AI 場(chǎng)景與大數(shù)據(jù)場(chǎng)景有一個(gè)很大的區(qū)別是,AI 場(chǎng)景中的數(shù)據(jù)集是比較有限的。不像大數(shù)據(jù)場(chǎng)景中有很多的表,有各種各樣的業(yè)務(wù),每個(gè)業(yè)務(wù)的數(shù)據(jù)表的內(nèi)容差距是非常大的。在 AI 場(chǎng)景中,數(shù)據(jù)集的規(guī)模、數(shù)據(jù)集的數(shù)量遠(yuǎn)遠(yuǎn)小于大數(shù)據(jù)場(chǎng)景。所以常常會(huì)發(fā)現(xiàn),公司中提交的任務(wù)很多都是讀取同一個(gè)數(shù)據(jù)。如果每個(gè)人下載數(shù)據(jù)到自己本地,其實(shí)是不能共享的,會(huì)有非常多份數(shù)據(jù)被重復(fù)存儲(chǔ)到本地機(jī)器上。這種方式顯然存在很多問(wèn)題,也不夠高效。
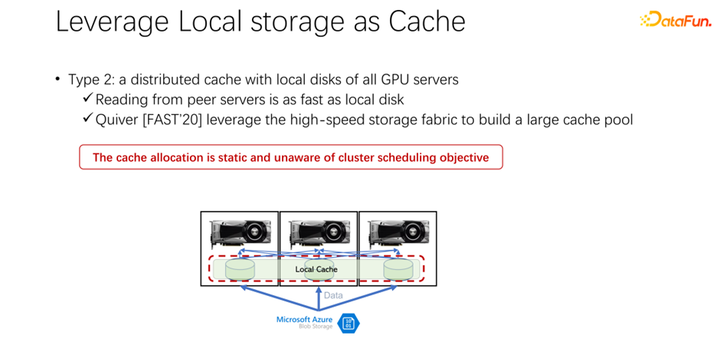
接下來(lái)介紹第二種方式。既然本地的存儲(chǔ)不太好,那么,是否可以使用像 Alluxio 這樣一個(gè)分布式緩存來(lái)緩解剛才的問(wèn)題,分布式緩存有非常大的容量來(lái)裝載數(shù)據(jù)。另外,Alluxio 作為一個(gè)分布式緩存,很容易進(jìn)行共享。數(shù)據(jù)下載到 Alluxio 中,其他的客戶端,也可以從緩存中讀取這份數(shù)據(jù)。這樣看來(lái),使用 Alluxio 可以很容易地解決上面提到的問(wèn)題,為 AI 訓(xùn)練性能帶來(lái)很大的提升。微軟印度研究院在 FAST2020 發(fā)表的名為 Quiver 的一篇論文,就提到了這樣的解決思路。但是我們分析發(fā)現(xiàn),這樣一個(gè)看似完美的分配方案,還是比較靜態(tài)的,并不高效。同時(shí),采用什么樣的 cache 淘汰算法,也是一個(gè)很值得討論的問(wèn)題。
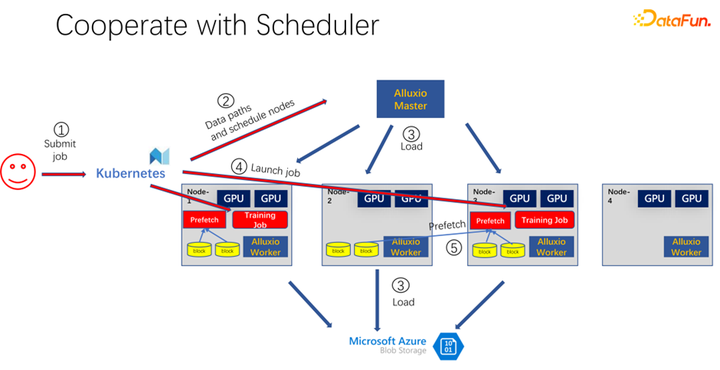
如上圖所示,是使用 Alluxio 作為 AI 訓(xùn)練的緩存的一個(gè)應(yīng)用。使用 K8s 做整個(gè)集群任務(wù)的調(diào)度和對(duì) GPU、CPU、內(nèi)存等資源的管理。當(dāng)有用戶提交一個(gè)任務(wù)到 K8s 時(shí),K8s 首先會(huì)做一個(gè)插件,通知 Alluxio 的 master,讓它去下載這部分?jǐn)?shù)據(jù)。也就是先進(jìn)行一些熱身,把作業(yè)可能需要的任務(wù),盡量先緩存一些。當(dāng)然不一定非得緩存完,因?yàn)?Alluxio 是有多少數(shù)據(jù),就使用多少數(shù)據(jù)。剩下的,如果還沒有來(lái)得及緩存,就從遠(yuǎn)端讀取。另外,Alluxio master 得到這樣的命令之后,就可以讓調(diào)度它的 worker 去遠(yuǎn)端。可能是云存儲(chǔ),也可能是 Hadoop 集群把數(shù)據(jù)下載下來(lái)。這個(gè)時(shí)候,K8s 也會(huì)把作業(yè)調(diào)度到 GPU 集群中。比如上圖中,在這樣一個(gè)集群中,它選擇第一個(gè)節(jié)點(diǎn)和第三個(gè)節(jié)點(diǎn)啟動(dòng)訓(xùn)練任務(wù)。啟動(dòng)訓(xùn)練任務(wù)之后,需要進(jìn)行數(shù)據(jù)的讀取。在現(xiàn)在主流的像 PyTorch、Tensorflow 等框架中,也內(nèi)置了 Prefetch,也就是會(huì)進(jìn)行數(shù)據(jù)預(yù)讀取。它會(huì)讀取已經(jīng)提前緩存的 Alluxio 中的緩存數(shù)據(jù),為訓(xùn)練數(shù)據(jù) IO 提供支持。當(dāng)然,如果發(fā)現(xiàn)有一些數(shù)據(jù)是沒有讀到的,Alluxio 也可以通過(guò)遠(yuǎn)端進(jìn)行讀取。Alluxio 作為一個(gè)統(tǒng)一的接口是非常好的。同時(shí)它也可以進(jìn)行數(shù)據(jù)的跨作業(yè)間的共享。
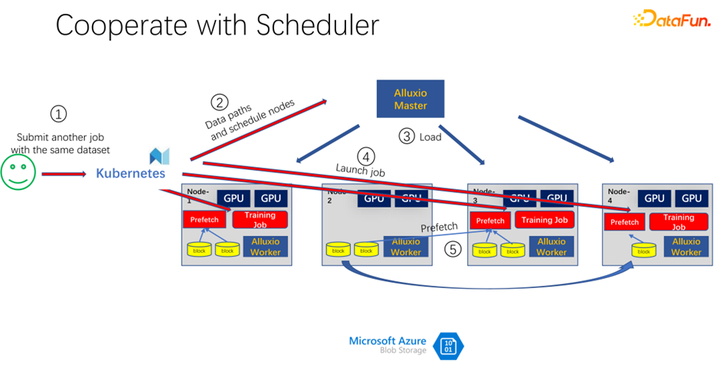
如上圖所示,比如又有一個(gè)人提交了同樣數(shù)據(jù)的另一個(gè)作業(yè),消耗的是同一個(gè)數(shù)據(jù)集,這個(gè)時(shí)候,當(dāng)提交作業(yè)到 K8s 的時(shí)候,Alluxio 就知道已經(jīng)有這部分?jǐn)?shù)據(jù)了。如果 Alluxio 想做的更好,甚至是可以知道,數(shù)據(jù)即將會(huì)被調(diào)度到哪臺(tái)機(jī)器上。比如這個(gè)時(shí)候調(diào)度到 node 1、node 3 和 node 4 上。node 4 的數(shù)據(jù),甚至可以做一些副本進(jìn)行拷貝。這樣所有的數(shù)據(jù),即使是 Alluxio 內(nèi)部,都不用跨機(jī)器讀,都是本地的讀取。所以看起來(lái) Alluxio 對(duì) AI 訓(xùn)練中的 IO 問(wèn)題有了很大的緩解和優(yōu)化。但是如果仔細(xì)觀察,就會(huì)發(fā)現(xiàn)兩個(gè)問(wèn)題。

第一個(gè)問(wèn)題就是緩存的淘汰算法非常低效,因?yàn)樵?AI 場(chǎng)景中,訪問(wèn)數(shù)據(jù)的模式跟以往有很大區(qū)別。第二個(gè)問(wèn)題是,緩存作為一種資源,與帶寬(即遠(yuǎn)程存儲(chǔ)的讀取速度)是一個(gè)對(duì)立的關(guān)系。如果緩存大,那么從遠(yuǎn)端讀取數(shù)據(jù)的機(jī)會(huì)就小。如果緩存很小,則很多數(shù)據(jù)都得從遠(yuǎn)端讀取。如何很好地調(diào)度分配這些資源也是一個(gè)需要考慮的問(wèn)題。
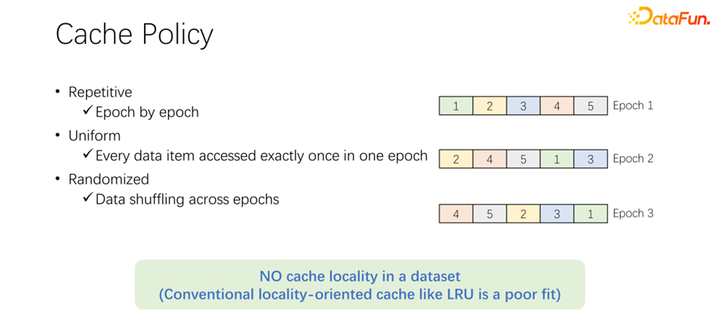
在討論緩存的淘汰算法之前,先來(lái)看一下 AI 訓(xùn)練中數(shù)據(jù)訪問(wèn)的過(guò)程。在 AI 訓(xùn)練中,會(huì)分為很多個(gè) epoch,不斷迭代地去訓(xùn)練。每一個(gè)訓(xùn)練 epoch,都會(huì)讀取每一條數(shù)據(jù),并且僅讀一次。為了防止訓(xùn)練的過(guò)擬合,在每一次 epoch 結(jié)束之后,下一個(gè) epoch 的時(shí)候,讀取順序會(huì)變化,會(huì)進(jìn)行一個(gè) shuffle。也就是每次每個(gè) epoch 都會(huì)把所有數(shù)據(jù)都讀取一次,但是順序卻不一樣。Alluxio 中默認(rèn)的 LRU 淘汰算法,顯然不能很好地應(yīng)用到 AI 訓(xùn)練場(chǎng)景中。因?yàn)?LRU 是利用緩存的本地性。本地性分為兩方面,首先是時(shí)間本地性,也就是現(xiàn)在訪問(wèn)的數(shù)據(jù),馬上可能還會(huì)即將訪問(wèn)。這一點(diǎn),在 AI 訓(xùn)練中并不存在。因?yàn)楝F(xiàn)在訪問(wèn)的數(shù)據(jù),在下一輪的時(shí)候才會(huì)訪問(wèn),而且下一輪的時(shí)候都會(huì)訪問(wèn)。沒有一個(gè)特殊的概率,一定是比其他數(shù)據(jù)更容易被訪問(wèn)。另一方面是數(shù)據(jù)本地性,還有空間本地性。也就是,為什么 Alluxio 用比較大的 block 緩存數(shù)據(jù),是因?yàn)槟硹l數(shù)據(jù)讀取了,可能周圍的數(shù)據(jù)也會(huì)被讀取。比如大數(shù)據(jù)場(chǎng)景中,OLAP 的應(yīng)用,經(jīng)常會(huì)進(jìn)行表的掃描,意味著周圍的數(shù)據(jù)馬上也會(huì)被訪問(wèn)。但是在 AI 訓(xùn)練場(chǎng)景中是不能應(yīng)用的。因?yàn)槊看味紩?huì) shuffle,每次讀取的順序都是不一樣的。因此 LRU 這種淘汰算法并不適用于 AI 訓(xùn)練場(chǎng)景。

不僅是 LRU,像 LFU 等主流的淘汰算法,都存在這樣一個(gè)問(wèn)題。因?yàn)檎麄€(gè) AI 訓(xùn)練對(duì)數(shù)據(jù)的訪問(wèn)是非常均等的。所以,可以采用最簡(jiǎn)單的緩存算法,只要緩存一部分?jǐn)?shù)據(jù)就可以,永遠(yuǎn)不用動(dòng)。在一個(gè)作業(yè)來(lái)了以后,永遠(yuǎn)都只緩存一部分?jǐn)?shù)據(jù)。永遠(yuǎn)都不要淘汰它。不需要任何的淘汰算法。這可能是目前最好的淘汰機(jī)制。如上圖中的例子。上面是 LRU 算法,下面是均等方法。在開始只能緩存兩條數(shù)據(jù)。我們把問(wèn)題簡(jiǎn)單一些,它的容量只有兩條,緩存 D 和 B 這兩條數(shù)據(jù),中間就是訪問(wèn)的序列。比如命中第一個(gè)訪問(wèn)的是 B,如果是 LRU,B 存在的緩存中命中了。下一條訪問(wèn)的是 C,C 并不在 D 和 B,LRU 的緩存中,所以基于 LRU 策略,會(huì)把 D 替換掉,C 保留下來(lái)。也就是這個(gè)時(shí)候緩存是 C 和 B。下一個(gè)訪問(wèn)的是 A,A 也不在 C 和 B 中。所以會(huì)把 B 淘汰掉,換成 C 和 A。下一個(gè)就是 D,D 也不在緩存中,所以換成 D 和 A。以此類推,會(huì)發(fā)現(xiàn)所有后面的訪問(wèn),都不會(huì)再命中緩存。原因是在進(jìn)行 LRU 緩存的時(shí)候,把它替換出來(lái),但其實(shí)在一個(gè) epoch 中已經(jīng)被訪問(wèn)一次,這個(gè) epoch 中就永遠(yuǎn)不會(huì)再被訪問(wèn)到了。LRU 反倒把它進(jìn)行緩存了,LRU 不但沒有幫助,反倒是變得更糟糕了。不如使用 uniform,比如下面這種方式。下面這種 uniform 的方式,永遠(yuǎn)在緩存中緩存 D 和 B,永遠(yuǎn)不做任何的替換。在這樣情況下,你會(huì)發(fā)現(xiàn)至少有 50% 的命中率。所以可以看到,緩存的算法不用搞得很復(fù)雜,只要使用 uniform 就可以了,不要使用 LRU、LFU 這類算法。
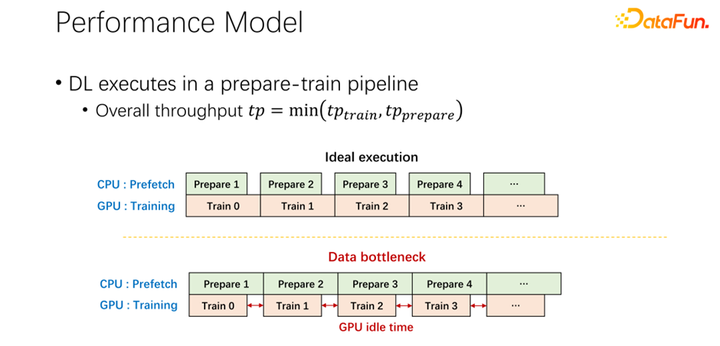
對(duì)于第二個(gè)問(wèn)題,也就是關(guān)于緩存和遠(yuǎn)程帶寬之間關(guān)系的問(wèn)題。現(xiàn)在所有主流的 AI 框架中都內(nèi)置了數(shù)據(jù)預(yù)讀,防止 GPU 等待數(shù)據(jù)。所以當(dāng) GPU 做訓(xùn)練的時(shí)候,其實(shí)是觸發(fā)了 CPU 預(yù)取下一輪可能用到的數(shù)據(jù)。這樣可以充分利用 GPU 的算力。但當(dāng)遠(yuǎn)程存儲(chǔ)的 IO 成為瓶頸的時(shí)候,就意味著 GPU 要等待 CPU 了。所以 GPU 會(huì)有很多的空閑時(shí)間,造成了資源的浪費(fèi)。希望可以有一個(gè)比較好的調(diào)度管理方式,緩解 IO 的問(wèn)題。

緩存和遠(yuǎn)程 IO 對(duì)整個(gè)作業(yè)的吞吐是有很大影響的。所以除了 GPU、CPU 和內(nèi)存,緩存和網(wǎng)絡(luò)也是需要調(diào)度的。在以往大數(shù)據(jù)的發(fā)展過(guò)程中,像 Hadoop、yarn、my source、K8s 等,主要都是調(diào)度 CPU、內(nèi)存、GPU。對(duì)于網(wǎng)絡(luò),尤其對(duì)于緩存的控制都不是很好。所以,我們認(rèn)為,在 AI 場(chǎng)景中,需要很好的調(diào)度和分配它們,來(lái)達(dá)到整個(gè)集群的最優(yōu)。
二、SiloD 框架

在 EuroSys 2023 發(fā)表了這樣一篇文章,它是一個(gè)統(tǒng)一的框架,來(lái)調(diào)度計(jì)算資源和存儲(chǔ)資源。
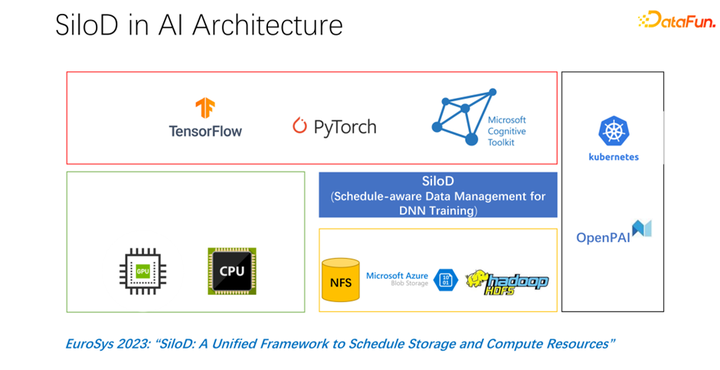
整體架構(gòu)如上圖所示。左下角是集群中的 CPU 和 GPU 硬件計(jì)算資源,以及存儲(chǔ)資源,如 NFS、云存儲(chǔ) HDFS 等。在上層有一些 AI 的訓(xùn)練框架 TensorFlow、PyTorch 等。我們認(rèn)為需要加入一個(gè)統(tǒng)一管理和分配計(jì)算和存儲(chǔ)資源的插件,也就是我們提出的 SiloD。
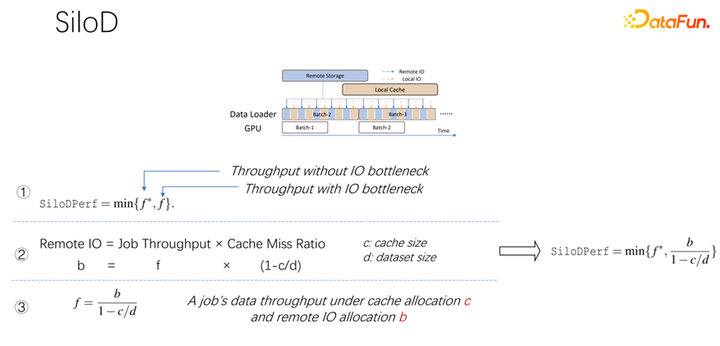
如上圖所示,一個(gè)作業(yè)可以達(dá)到什么樣的吞吐和性能,是由 GPU 和 IO 的最小值決定的。使用多少個(gè)遠(yuǎn)程 IO,就會(huì)使用多少遠(yuǎn)端的 networking。可以通過(guò)這樣一個(gè)公式算出訪問(wèn)速度。作業(yè)速度乘以緩存未命中率,也就是(1-c/d)。其中 c 就是緩存的大小,d 就是數(shù)據(jù)集。這也就意味著數(shù)據(jù)只考慮 IO 可能成為瓶頸的時(shí)候,大概的吞吐量是等于(b/(1-c/d)),b 就是遠(yuǎn)端的帶寬。結(jié)合以上三個(gè)公式,可以推出右邊的公式,也就是一個(gè)作業(yè)最終想達(dá)到什么樣的性能,可以這樣通過(guò)公式去計(jì)算沒有 IO 瓶頸時(shí)的性能,和有 IO 瓶頸時(shí)的性能,取二者中的最小值。
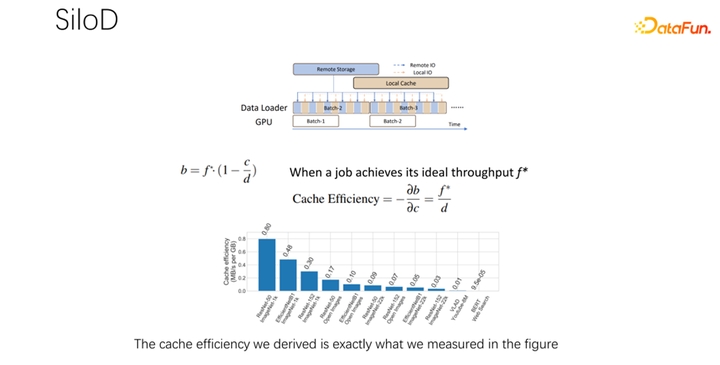
得到上面的公式之后,把它微分一下,就可以得到緩存的有效性,或者叫做緩存效率。即雖然作業(yè)很多,但在分配緩存的時(shí)候不能一視同仁。每一個(gè)作業(yè),基于數(shù)據(jù)集的不同,速度的不同,緩存分配多少是很有講究的。這里舉一個(gè)例子,就以這個(gè)公式為例,如果發(fā)現(xiàn)一個(gè)作業(yè),速度非常快,訓(xùn)練起來(lái)非常快,同時(shí)數(shù)據(jù)集很小,這時(shí)候就意味著分配更大的緩存,收益會(huì)更大。
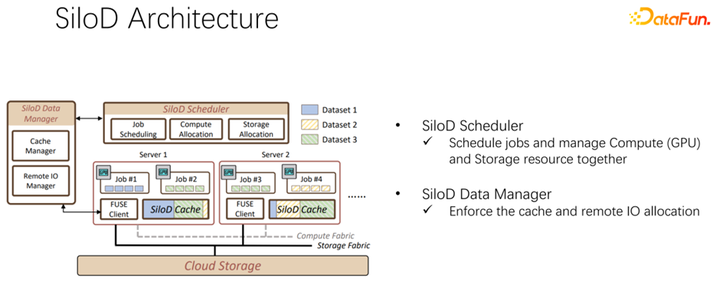
基于以上觀察,可以使用 SiloD,進(jìn)行緩存和網(wǎng)絡(luò)的分配。而且緩存的大小,是針對(duì)每個(gè)作業(yè)的速度,以及數(shù)據(jù)集整個(gè)的大小來(lái)進(jìn)行分配的。網(wǎng)絡(luò)也是如此。所以整個(gè)架構(gòu)是這樣的:除了主流的像 K8s 等作業(yè)調(diào)度之外,還有數(shù)據(jù)管理。在圖左邊,比如緩存的管理,要統(tǒng)計(jì)或者監(jiān)控分配整個(gè)集群中緩存的大小,每個(gè)作業(yè)緩存的大小,以及每個(gè)作業(yè)使用到的遠(yuǎn)程 IO 的大小。底下的作業(yè),和 Alluxio 方式很像,都可以都使用 API 進(jìn)行數(shù)據(jù)的訓(xùn)練。每個(gè) worker 上使用緩存對(duì)于本地的 job 進(jìn)行緩存支持。當(dāng)然它也可以在一個(gè)集群中跨節(jié)點(diǎn),也可以進(jìn)行共享。
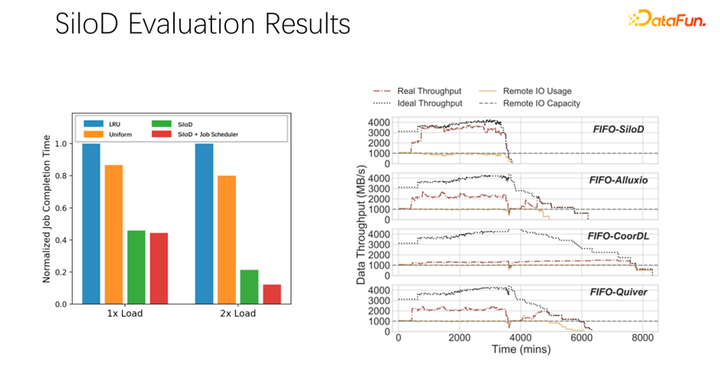
經(jīng)過(guò)初步測(cè)試和實(shí)驗(yàn),發(fā)現(xiàn)這樣一個(gè)分配方式可以使整個(gè)集群的使用率和吞吐量都得到非常明顯的提升,最高可以達(dá)到 8 倍的性能上的提升。可以很明顯的緩解作業(yè)等待、GPU 空閑的狀態(tài)。

對(duì)上述介紹進(jìn)行一下總結(jié): 第一,在 AI 或者深度學(xué)習(xí)訓(xùn)練場(chǎng)景中,傳統(tǒng)的 LRU、LFU 等緩存策略并不適合,不如直接使用 uniform。 第二,緩存和遠(yuǎn)程帶寬,是一對(duì)伙伴,對(duì)整體性能起到了非常大的作用。 第三,像 K8s、yarn 等主流調(diào)度框架,可以很容易繼承到 SiloD。 最后,我們?cè)?paper 中做了一些實(shí)驗(yàn),不同的調(diào)度策略,都可以帶來(lái)很明顯的吞吐量的提升。
三、分布式緩存策略以及副本管理
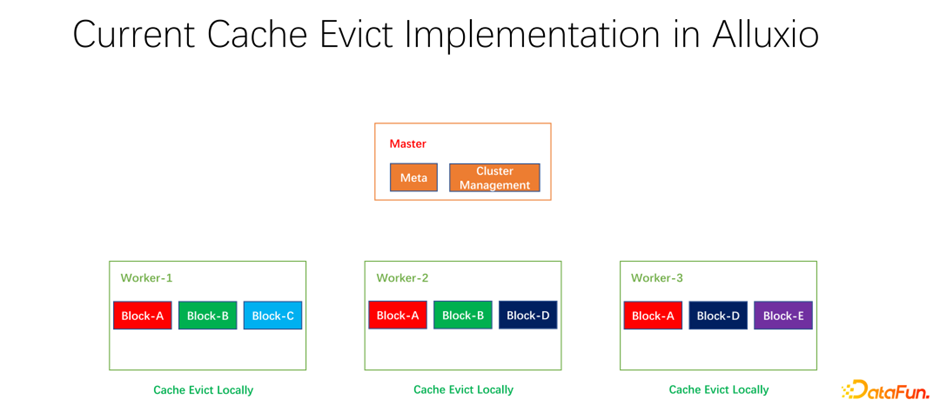
我們還做了一些開源的工作。分布式緩存策略以及副本管理這項(xiàng)工作,已經(jīng)提交給社區(qū),現(xiàn)在處于 PR 階段。Alluxio master 主要做 Meta 的管理和整個(gè) worker 集群的管理。真正緩存數(shù)據(jù)的是 worker。上面有很多以 block 為單位的塊兒去緩存數(shù)據(jù)。存在的一個(gè)問(wèn)題是,現(xiàn)階段的緩存策略都是單個(gè) worker 的,worker 內(nèi)部的每個(gè)數(shù)據(jù)在進(jìn)行是否淘汰的計(jì)算時(shí),只需要在一個(gè) worker 上進(jìn)行計(jì)算,是本地化的。
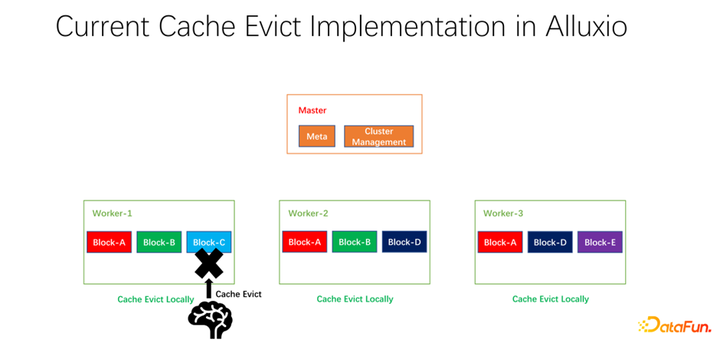
如上圖所示的例子,如果 worker 1 上有 block A, block B 和 block C,基于 LRU 算出來(lái) block C 是最長(zhǎng)時(shí)間沒有使用的,就會(huì)把 block C 淘汰。如果看一下全局的情況,就會(huì)發(fā)現(xiàn)這樣并不好。因?yàn)?block C 在整個(gè)集群中只有一個(gè)副本。把它淘汰之后,如果下面還有人要訪問(wèn) block C,只能從遠(yuǎn)端拉取數(shù)據(jù),就會(huì)帶來(lái)性能和成本的損失。我們提出做一個(gè)全局的淘汰策略。在這種情況下,不應(yīng)該淘汰 block C,而應(yīng)該淘汰副本比較多的。在這個(gè)例子中,應(yīng)該淘汰 block A,因?yàn)樗谄渌墓?jié)點(diǎn)上仍然有兩個(gè)副本,無(wú)論是成本還是性能都要更好。
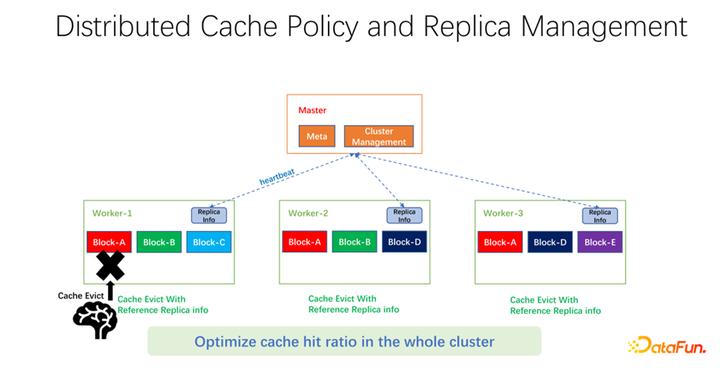
如上圖所示,我們做的工作是在每個(gè) worker 上維護(hù)副本信息。當(dāng)某一個(gè) worker,比如加了一個(gè)副本,或者減了一個(gè)副本,首先會(huì)向 master 匯報(bào),而 master 會(huì)把這個(gè)信息作為心跳返回值,返回給其它相關(guān)的 worker。其它 worker 就可以知道整個(gè)全局副本的實(shí)時(shí)變化。同時(shí),更新副本信息。所以當(dāng)進(jìn)行 worker 內(nèi)部的淘汰時(shí),可以知道每一個(gè) worker 在整個(gè)全局有多少個(gè)副本,就可以設(shè)計(jì)一些權(quán)重。比如仍然使用 LRU,但是會(huì)加上副本個(gè)數(shù)的權(quán)重,綜合考量淘汰和替換哪些數(shù)據(jù)。經(jīng)過(guò)我們初步的測(cè)試,在很多領(lǐng)域,無(wú)論是 big data,AI training 中都可以帶來(lái)很大的提升。所以不僅僅是優(yōu)化一臺(tái)機(jī)器上一個(gè) worker 的緩存命中。我們的目標(biāo)是使得整個(gè)集群的緩存命中率都得到提升。

最后,對(duì)全文進(jìn)行一下總結(jié)。首先,在 AI 的訓(xùn)練場(chǎng)景中,uniform 緩存淘汰算法要比傳統(tǒng)的 LRU、LFU 更好。第二,緩存和遠(yuǎn)端的 networking 也是一個(gè)需要被分配和調(diào)度的資源。第三,在進(jìn)行緩存優(yōu)化時(shí),不要只局限在一個(gè)作業(yè)或者一個(gè) worker 上,應(yīng)該統(tǒng)攬整個(gè)端到端全局的參數(shù),才能使得整個(gè)集群的效率和性能有更好的提升。
審核編輯:劉清
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7610瀏覽量
165864 -
緩存器
+關(guān)注
關(guān)注
0文章
63瀏覽量
11805 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8478瀏覽量
133811 -
MYSQL數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
0文章
96瀏覽量
9668 -
HDFS
+關(guān)注
關(guān)注
1文章
31瀏覽量
9797 -
AI大模型
+關(guān)注
關(guān)注
0文章
358瀏覽量
462
原文標(biāo)題:Alluxio助力AI大模型訓(xùn)練
文章出處:【微信號(hào):OSC開源社區(qū),微信公眾號(hào):OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論