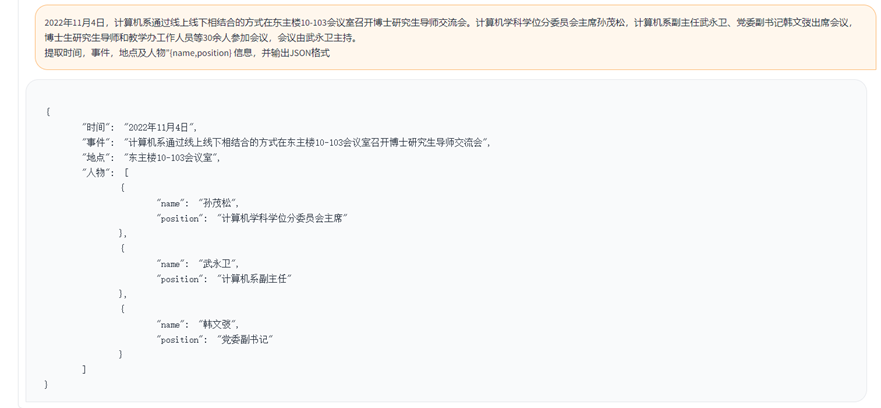
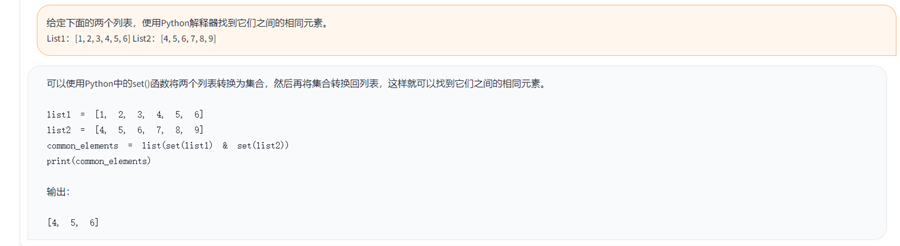
 嘉楠開源通用大語言模型Toucan中的INT4量化技術解析
嘉楠開源通用大語言模型Toucan中的INT4量化技術解析

ChatGPT與其之后不斷涌現的大語言模型(LLM)迅速席卷了整個時代。隨著計算機對人類自然語言的領悟程度突飛猛進,我們與計算機的交互方式正在迅速而深刻地改變著,這也即將帶來一場既廣泛又具有極強創新性的商業模式轉型。
嘉楠科技(Canaan)是一家領先的ASIC芯片設計公司,也是第一家在美上市的中國自主知識產權AI芯片公司。嘉楠科技希望通過ASIC技術“提升社會運行效率,改善人類生活方式”,并成為區塊鏈和AI高性能計算的領導者。
2023年6月30日,嘉楠科技正式發布參數量70億的通用大語言模型Toucan-7B及INT4量化版本的Toucan-7B-4bit。其中,Toucan-7B基于LLaMA預訓練權重進行指令微調,能夠實現文案寫作、代碼解析、信息抽取等各種通用自然語言處理任務。Toucan-7B-4bit基于當前最新量化技術對Toucan-7B實現極低損失的INT4量化。此外,Toucan-7B是基于GTX-3090單卡GPU實現所有的實驗流程,是真正方便每位開發者所使用的通用LLM模型。
Toucan模型精度
評估大語言模型的效果本身就是一個復雜的課題。目前還沒有公認的、嚴格的科學評估標準。
Toucan采用開源的專業中文測試集BELLE進行效果評估,涵蓋數學推理、代碼解析、文本分類等多個維度。ChatGPT的表現作為參考基準。通過人工評估ChatGPT的表現,可以直觀地判斷不同模型的優劣。
ChatGLM(清華開源LLM模型)是國內首批開源的通用大語言模型,也是最優秀的中文大語言模型之一。因此,在Toucan的評估過程中,我們將主要以ChatGLM的表現作為參考,來衡量不同模型的效果,從而給出一個相對公正的評估結果。

如上表所示,Toucan-7B的效果略微優于ChatGLM-6B,并且Toucan-7B-4bit模型的效果也能夠達到與ChatGLM-6B持平的水準。此外,我們可以發現:Toucan的強項是code任務與re-write任務,并且rewrite能力評分甚至超過ChatGPT。
上述對比驗證了Toucan在多個維度上展現出色的語言理解與生成能力,這說明Toucan作為通用語言模型,具有較強的應用潛力。當然,大語言模型之間的對比評估是一個復雜的過程,不存在一個模型在所有方面都占絕對優勢。我們會繼續致力于完善評估方案,以更全面地判斷模型的優劣。
Toucan模型INT4量化
如上節所述,Toucan-7B-4bit模型基于當前最前沿的INT4量化技術,實現了對Toucan-7B模型的近乎無損量化。本節對Toucan-7B-4bit模型中所使用的INT4量化技術進行簡單介紹。
Toucan-7B-4bit模型中使用了GPTQ和VS-Quant兩種IN4量化技術。GPTQ是一種one-shot PTQ 方法。不同于之前使用統計手段(如 kl-divergence)獲得最小/最大值量化參數,GPTQ 先計算權重的Hessian 矩陣,再結合此矩陣和局部量化結果,逐步迭代權重。在物理意義上,Hessian 矩陣對角線數值,表示多元函數沿坐標軸方向的曲率。因此相對于統計量化方法,GPTQ 更具有說服力。VS-Quant技術使用更細粒度的縮放因子,為每個小向量(16-64個元素)使用一個獨立的縮放因子,這可以提高每個元素的有效精度。并通過兩級量化和訓練,可以用低比特寬的整數來表示這些向量縮放因子。
這里4bit量化技術主要用于減小模型尺寸,降低顯存容量和帶寬占用,計算時需要反量化成fp16再進行計算。LLM推理,通常都是帶寬和顯存容量受限,計算并不是問題。
我們將Toucan-7B-4bit模型和Toucan-7B-fp16模型的實測顯存占用量進行了對比:
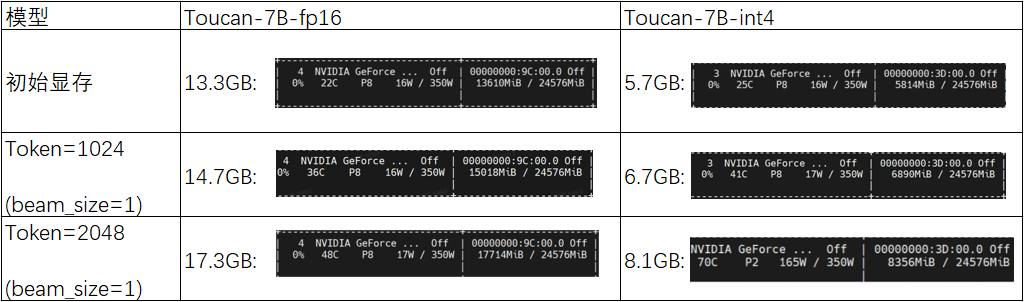
通過上表對比可以發現:在初始階段,Toucan-7B-fp16模型的顯存占用量為13.3GB,而Toucan-7B-int4模型的顯存占用量僅為5.7GB;隨著模型迭代推理的逐步進行,當Token長度達到1024時,Toucan-7B-fp16模型的顯存占用量上至14.7GB,而Toucan-7B-int4模型的顯存占用量仍維持在6.7GB;當達到模型支持的最大輸入長度2048時,Toucan-7B-fp16模型的顯存占用量達到了17.3GB,而Toucan-7B-int4模型的顯存占用量僅為8.1GB。
Toucan-7B-int4模型可以在低顯存占用的情況下大語言模型推理,這對采用消費級顯卡的用戶更為友好。在Toucan開源倉庫中,嘉楠科技開源了Toucan-7B-4bit模型的量化參數生成代碼以及量化模型推理代碼,感興趣的開發者可進行詳細閱讀相關內容。
Toucan單顯卡訓練
Toucan詳細技術文檔及代碼見該開源倉庫如下:
https://github.com/kendryte/Toucan-LLM:
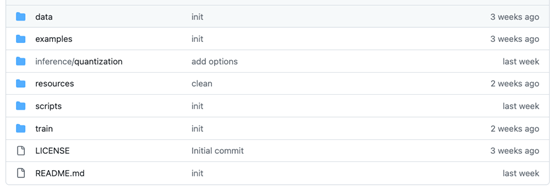
如上圖所示,為Toucan開源倉庫的目錄結構。在Toucan開源倉庫中,更新了全參數微調訓練代碼、基于Gradio的推理代碼、INT4量化代碼,以及模型合并代碼。微調后的浮點模型也有開源,可下載合并后使用。
啟動訓練:bash train/run.sh
推理:pythonscripts/demo.py
模型權重合并:
pythonscripts/apply_delta.py--base/path_to_llama/llama-7b-hf--target./save_path/toucan-7b--delta/path_to_delta/toucan-7b-delta/
Toucan模型能力展示
因為篇幅所限,我們在這里僅展示Toucan的部分能力。感興趣的讀者可以去Github-Toucan-LLM了解更多。
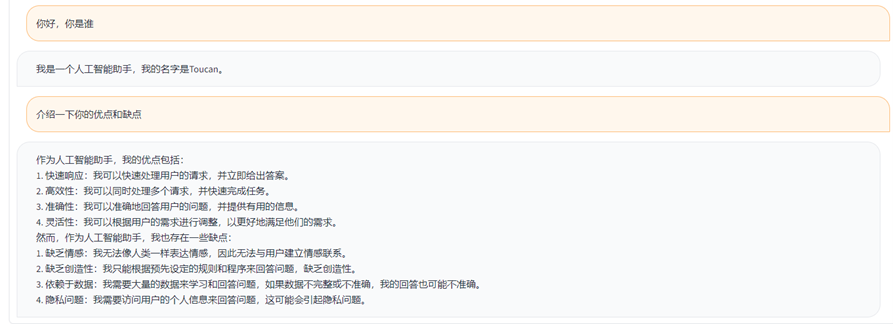
(1)自我介紹
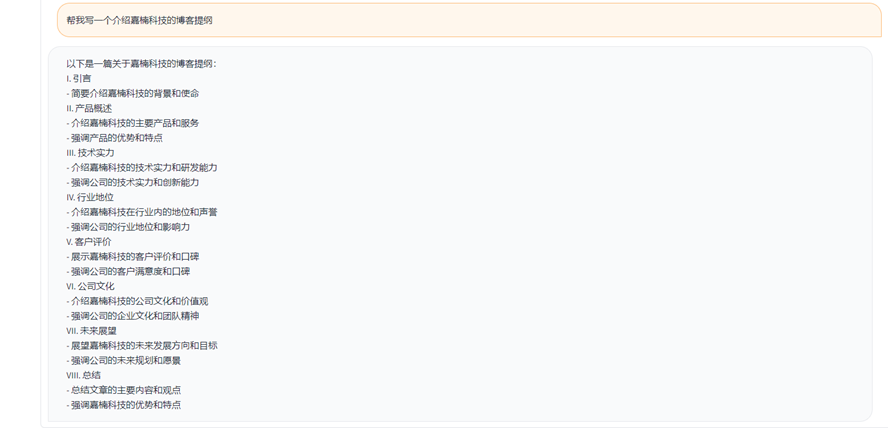
(2)寫作助手
(3)信息抽取
(4)代碼解析
加入我們
我們相信開源對技術進步具有重要意義,也希望Toucan能為推進開源大語言模型貢獻一份力量。我們歡迎和鼓勵開發者在Toucan代碼庫的基礎上進行創造,無論是模型效果的提升還是應用場景的拓展。
在LLM時代,我們仍處在技術快速進步的早期階段。加入開源力量。在開放、協作的開源社區中,每一份貢獻都將變成技術進步的階梯。
我們期待您的加入,與我們一同推動LLM和其他前沿技術的開源之旅!
審核編輯:湯梓紅
-
asic
+關注
關注
34文章
1245瀏覽量
122339 -
芯片設計
+關注
關注
15文章
1085瀏覽量
55632 -
AI
+關注
關注
88文章
35041瀏覽量
279221 -
開源
+關注
關注
3文章
3673瀏覽量
43794 -
語言模型
+關注
關注
0文章
561瀏覽量
10781
原文標題:嘉楠開源通用大語言模型Toucan 且INT4量化效果媲美ChatGLM
文章出處:【微信號:CanaanTech,微信公眾號:嘉楠科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
香蕉派 BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片設計
香蕉派開發板BPI-CanMV-K230D-Zero 嘉楠科技 RISC-V開發板公開發售
為什么無法在GPU上使用INT8 和 INT4量化模型獲得輸出?
使用 NPU 插件對量化的 Llama 3.1 8b 模型進行推理時出現“從 __Int64 轉換為無符號 int 的錯誤”,怎么解決?
華秋電子與嘉楠科技合作,推廣勘智全系AI產品
重磅!華秋電子與嘉楠科技正式簽訂合作協議
華秋電子與嘉楠科技簽訂合作協議,7月起嘉楠系列產品陸續上線華秋商城
華秋電子與嘉楠科技正式簽訂合作協議,在開源生態、媒體社區等多領域開展深入合作
嘉楠科技旗下全球首款RIS-V架構商用邊緣AI芯片,華秋商城現貨在售中
NCNN+Int8+yolov5部署和量化

華秋電子與嘉楠科技正式簽訂合作協議
深度解析MegEngine 4 bits量化開源實現
英偉達:5nm實驗芯片用INT4達到INT8的精度
類GPT模型訓練提速26.5%,清華朱軍等人用INT4算法加速神經網絡訓練






 工商網監
工商網監
評論