") Kubernetes集群中如何選擇工作節(jié)點(diǎn)
Kubernetes集群中如何選擇工作節(jié)點(diǎn)
簡(jiǎn)要概述:本文討論了在Kubernetes集群中選擇較少數(shù)量的較大節(jié)點(diǎn)和選擇較多數(shù)量的較小節(jié)點(diǎn)之間的利弊。
當(dāng)創(chuàng)建一個(gè)Kubernetes集群時(shí),最初的問題之一是:“我應(yīng)該使用什么類型的工作節(jié)點(diǎn),以及需要多少個(gè)?”
如果正在構(gòu)建一個(gè)本地集群,是應(yīng)該采購(gòu)一些上一代的高性能服務(wù)器,還是利用數(shù)據(jù)中心中閑置的幾臺(tái)老舊機(jī)器呢?
或者,如果正在使用像Google Kubernetes Engine(GKE)這樣的托管式Kubernetes服務(wù),是應(yīng)該選擇八個(gè)n1-standard-1實(shí)例還是兩個(gè)n1-standard-4實(shí)例來實(shí)現(xiàn)所需的計(jì)算能力呢?
目錄
集群容量
Kubernetes工作節(jié)點(diǎn)中的預(yù)留資源
工作節(jié)點(diǎn)中的資源分配和效率
彈性和復(fù)制
擴(kuò)展增量和前導(dǎo)時(shí)間
拉取容器鏡像
Kubelet和擴(kuò)展Kubernetes API
節(jié)點(diǎn)和集群限制
存儲(chǔ)
總結(jié)和結(jié)論
集群容量
一般來說,Kubernetes集群可以被看作是將一組獨(dú)立的節(jié)點(diǎn)抽象為一個(gè)大的“超級(jí)節(jié)點(diǎn)”。
這個(gè)超級(jí)節(jié)點(diǎn)的總計(jì)算能力(包括CPU和內(nèi)存)是所有組成節(jié)點(diǎn)的能力之和。
有多種實(shí)現(xiàn)這一目標(biāo)的方法。例如,假設(shè)您需要一個(gè)總計(jì)算能力為8個(gè)CPU核心和32GB內(nèi)存的集群。以下是兩種可能的集群設(shè)計(jì)方式:
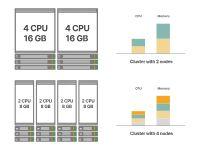
Kubernetes集群中的小型節(jié)點(diǎn)與大型節(jié)點(diǎn)
這兩種選擇都會(huì)得到相同容量的集群。
左邊的選擇使用了四個(gè)較小的節(jié)點(diǎn),而右邊的選擇使用了兩個(gè)較大的節(jié)點(diǎn)。
問題是:哪種方法更好呢?
為了做出明智的決策,讓我們深入了解如何在工作節(jié)點(diǎn)中分配資源。
Kubernetes工作節(jié)點(diǎn)中的預(yù)留資源
Kubernetes集群中的每個(gè)工作節(jié)點(diǎn)都是一個(gè)運(yùn)行kubelet(Kubernetes代理)的計(jì)算單元。
kubelet是一個(gè)連接到控制平面的二進(jìn)制文件,用于將節(jié)點(diǎn)的當(dāng)前狀態(tài)與集群的狀態(tài)同步。
例如,當(dāng)Kubernetes調(diào)度程序?qū)⒁粋€(gè)Pod分配給特定節(jié)點(diǎn)時(shí),它不會(huì)直接向kubelet發(fā)送消息。相反,它會(huì)創(chuàng)建一個(gè)Binding對(duì)象并將其存儲(chǔ)在etcd中。
kubelet定期檢查集群的狀態(tài)。一旦它注意到將一個(gè)新分配的Pod分配給其節(jié)點(diǎn),它就會(huì)開始下載Pod的規(guī)范并創(chuàng)建它。
通常將kubelet部署為SystemD服務(wù),并作為操作系統(tǒng)的一部分運(yùn)行。
kubelet、SystemD和操作系統(tǒng)需要資源,包括CPU和內(nèi)存,以確保正確運(yùn)行。
因此,并不是所有工作節(jié)點(diǎn)的資源都僅用于運(yùn)行Pod。
CPU和內(nèi)存資源通常分配如下:
操作系統(tǒng)。Kubelet。Pods。驅(qū)逐閾值。
Kubernetes節(jié)點(diǎn)中的資源分配
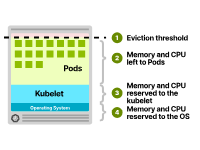
您可能想知道這些組件分配了哪些資源。雖然具體配置可能會(huì)有所不同,但CPU分配通常遵循以下模式:
第一個(gè)核心的6%。后續(xù)核心的1%(最多2個(gè)核心)。接下來的兩個(gè)核心的0.5%(最多4個(gè)核心)。四個(gè)核心以上的任何核心的0.25%。內(nèi)存分配可能如下:
小于1GB內(nèi)存的機(jī)器分配255 MiB內(nèi)存。前4GB內(nèi)存的25%。接下來的4GB內(nèi)存的20%(最多8GB)。接下來的8GB內(nèi)存的10%(最多16GB)。接下來的112GB內(nèi)存的6%(最多128GB)。超過128GB的任何內(nèi)存的2%。最后,驅(qū)逐閾值通常保持在100MB。
驅(qū)逐閾值 驅(qū)逐閾值代表內(nèi)存使用的閾值。如果一個(gè)節(jié)點(diǎn)超過了這個(gè)閾值,kubelet將開始驅(qū)逐Pod,因?yàn)楫?dāng)前節(jié)點(diǎn)的內(nèi)存不足。
考慮一個(gè)具有8GB內(nèi)存和2個(gè)虛擬CPU的實(shí)例。資源分配如下:
70毫核虛擬CPU和1.8GB供kubelet和操作系統(tǒng)使用(通常一起打包)。保留100MB用于驅(qū)逐閾值。剩余的6.1GB內(nèi)存和1930毫核可以分配給Pod。只有總內(nèi)存的75%用于執(zhí)行工作負(fù)載。
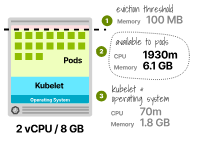
但這還不止于此。
您的節(jié)點(diǎn)可能需要在每個(gè)節(jié)點(diǎn)上運(yùn)行一些Pod(例如DaemonSets)以確保正確運(yùn)行,而這些Pod也會(huì)消耗內(nèi)存和CPU資源。
例如,Kube-proxy、諸如Fluentd或Fluent Bit的日志代理、NodeLocal DNSCache或CSI驅(qū)動(dòng)程序等。
這是一個(gè)固定的成本,無(wú)論節(jié)點(diǎn)大小如何,您都必須支付。
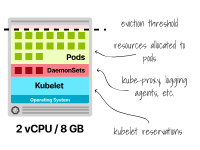
帶有DaemonSets的Kubernetes節(jié)點(diǎn)中的資源分配 考慮到這一點(diǎn),讓我們來看一下"較少數(shù)量的較大節(jié)點(diǎn)"和"較多數(shù)量的較小節(jié)點(diǎn)"這兩種截然相反的方法的利弊。
請(qǐng)注意,本文中的"節(jié)點(diǎn)"始終指的是工作節(jié)點(diǎn)。關(guān)于控制平面節(jié)點(diǎn)的數(shù)量和大小的選擇是一個(gè)完全不同的主題。
工作節(jié)點(diǎn)中的資源分配和效率
隨著更大實(shí)例的使用,kubelet預(yù)留的資源會(huì)減少。
讓我們來看兩種極端情況。
您想要為一個(gè)請(qǐng)求0.3個(gè)vCPU和2GB內(nèi)存的應(yīng)用部署七個(gè)副本。
在第一種情況下,您將為一個(gè)單獨(dú)的工作節(jié)點(diǎn)提供資源以部署所有副本。在第二種情況下,您在每個(gè)節(jié)點(diǎn)上部署一個(gè)副本。為簡(jiǎn)單起見,我們假設(shè)這些節(jié)點(diǎn)上沒有運(yùn)行任何DaemonSets。
七個(gè)副本所需的總資源為2.1個(gè)vCPU和14GB內(nèi)存(即7 x 300m = 2.1個(gè)vCPU和7 x 2GB = 14GB)。
一個(gè)4個(gè)vCPU和16GB內(nèi)存的實(shí)例能夠運(yùn)行這些工作負(fù)載嗎?
我們來計(jì)算一下CPU的預(yù)留:
第一個(gè)核心的6%=60m+ 第二個(gè)核心的1%=10m+ 剩余核心的0.5%=10m 總計(jì)=80m
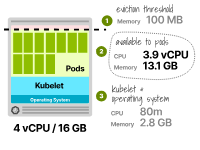
用于運(yùn)行Pod的可用CPU為3.9個(gè)vCPU(即4000m - 80m)——綽綽有余。
接下來,我們來看一下kubelet預(yù)留的內(nèi)存:
前4GB內(nèi)存的25%=1GB 接下來的4GB內(nèi)存的20%=0.8GB 接下來的8GB內(nèi)存的10%=0.8GB 總計(jì)=2.8GB
分配給Pod的總內(nèi)存為16GB -(2.8GB + 0.1GB)——這里的0.1GB考慮到了100MB的驅(qū)逐閾值。
最后,Pod可以使用最多13.1GB的內(nèi)存。
帶有2個(gè)vCPU和16GB內(nèi)存的Kubernetes節(jié)點(diǎn)中的資源分配
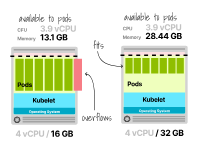
不幸的是,這還不夠(即7個(gè)副本需要14GB的內(nèi)存,但您只有13.1GB),您應(yīng)該為部署這些工作負(fù)載提供更多內(nèi)存的計(jì)算單元。
如果使用云提供商,下一個(gè)可用的增量計(jì)算單元是4個(gè)vCPU和32GB內(nèi)存。
帶有2個(gè)vCPU和16GB內(nèi)存的節(jié)點(diǎn)不足以運(yùn)行七個(gè)副本
 太好了!
太好了!
接下來,讓我們看一下另一種情況,即我們嘗試找到適合一個(gè)副本的最小實(shí)例,該副本的請(qǐng)求為0.3個(gè)vCPU和2GB內(nèi)存。
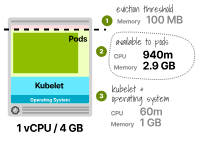
我們嘗試使用具有1個(gè)vCPU和4GB內(nèi)存的實(shí)例類型。
預(yù)留的CPU總共為6%或60m,可用于Pod的CPU為940m。
由于該應(yīng)用僅需要300m的CPU,這足夠了。
kubelet預(yù)留的內(nèi)存為25%或1GB,再加上額外的0.1GB的驅(qū)逐閾值。
Pod可用的總內(nèi)存為2.9GB;由于該應(yīng)用僅需要2GB,這個(gè)值足夠了。
太棒了!
帶有2個(gè)vCPU和16GB內(nèi)存的Kubernetes節(jié)點(diǎn)中的資源分配 現(xiàn)在,讓我們比較這兩種設(shè)置。
第一個(gè)集群的總資源只是一個(gè)單一節(jié)點(diǎn) — 4個(gè)vCPU和32GB。
第二個(gè)集群有七個(gè)實(shí)例,每個(gè)實(shí)例都有1個(gè)vCPU和4GB內(nèi)存(總共為7個(gè)vCPU和28GB內(nèi)存)。
在第一個(gè)示例中,為Kubernetes預(yù)留了2.9GB的內(nèi)存和80m的CPU。
而在第二個(gè)示例中,預(yù)留了7.7GB(1.1GB x 7個(gè)實(shí)例)的內(nèi)存和360m(60m x 7個(gè)實(shí)例)的CPU。
您已經(jīng)可以注意到,在配置較大的節(jié)點(diǎn)時(shí),資源的利用效率更高。
在單一節(jié)點(diǎn)集群和多節(jié)點(diǎn)集群之間比較資源分配情況
但還有更多。
較大的實(shí)例仍然有空間來運(yùn)行更多的副本 — 但有多少個(gè)呢?
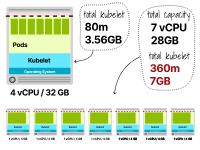
預(yù)留的內(nèi)存為3.66GB(3.56GB的kubelet + 0.1GB的驅(qū)逐閾值),可用于Pod的總內(nèi)存為28.44GB。預(yù)留的CPU仍然是80m,Pods可以使用3920m。此時(shí),您可以通過以下方式找到內(nèi)存和CPU的最大副本數(shù):
TotalCPU3920/ PodCPU300 ------------------ MaxPod13.1
您可以為內(nèi)存重復(fù)進(jìn)行計(jì)算:
總內(nèi)存28.44/ Pod內(nèi)存2 最大Pod14.22
以上數(shù)字表明,內(nèi)存不足可能會(huì)在CPU之前用盡,而在4個(gè)vCPU和32GB工作節(jié)點(diǎn)中最多可以托管13個(gè)Pod。
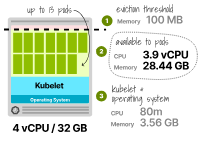
為2個(gè)vCPU和32GB工作節(jié)點(diǎn)計(jì)算Pod容量 那么第二種情況呢?
是否還有空間進(jìn)行擴(kuò)展?
實(shí)際上并沒有。
雖然這些實(shí)例仍然具有更多的CPU,但在部署第一個(gè)Pod后,它們只有0.9GB的可用內(nèi)存。
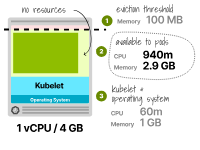
為1個(gè)vCPU和4GB工作節(jié)點(diǎn)計(jì)算Pod容量 總之,不僅較大的節(jié)點(diǎn)能更好地利用資源,而且還可以最小化資源的碎片化并提高效率。
這是否意味著您應(yīng)該始終提供較大的實(shí)例?
讓我們來看另一個(gè)極端情況:節(jié)點(diǎn)意外丟失時(shí)會(huì)發(fā)生什么?
彈性和復(fù)制
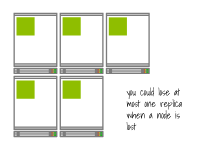
較少數(shù)量的節(jié)點(diǎn)可能會(huì)限制您的應(yīng)用程序的有效復(fù)制程度。
例如,如果您有一個(gè)由5個(gè)副本組成的高可用應(yīng)用程序,但只有兩個(gè)節(jié)點(diǎn),那么有效的復(fù)制程度將降低為2。
這是因?yàn)檫@五個(gè)副本只能分布在兩個(gè)節(jié)點(diǎn)上,如果其中一個(gè)節(jié)點(diǎn)失敗,可能會(huì)一次性失去多個(gè)副本。
具有兩個(gè)節(jié)點(diǎn)和五個(gè)副本的集群的復(fù)制因子為兩個(gè)

另一方面,如果您至少有五個(gè)節(jié)點(diǎn),每個(gè)副本都可以在一個(gè)單獨(dú)的節(jié)點(diǎn)上運(yùn)行,而單個(gè)節(jié)點(diǎn)的故障最多會(huì)導(dǎo)致一個(gè)副本失效。
因此,如果您有高可用性要求,您可能需要在集群中擁有一定數(shù)量的節(jié)點(diǎn)。
具有五個(gè)節(jié)點(diǎn)和五個(gè)副本的集群的復(fù)制因子為五 您還應(yīng)該考慮節(jié)點(diǎn)的大小。
當(dāng)較大的節(jié)點(diǎn)丟失時(shí),一些副本最終會(huì)被重新調(diào)度到其他節(jié)點(diǎn)。
如果節(jié)點(diǎn)較小,僅托管了少量工作負(fù)載,則調(diào)度器只會(huì)重新分配少數(shù)Pod。
雖然您不太可能在調(diào)度器中遇到任何限制,但重新部署許多副本可能會(huì)觸發(fā)集群自動(dòng)縮放器。
并且根據(jù)您的設(shè)置,這可能會(huì)導(dǎo)致進(jìn)一步的減速。
讓我們來探討一下原因。
擴(kuò)展增量和前導(dǎo)時(shí)間
您可以使用水平擴(kuò)展器(即增加副本數(shù)量)和集群自動(dòng)縮放器(即增加節(jié)點(diǎn)計(jì)數(shù))的組合來擴(kuò)展部署在Kubernetes上的應(yīng)用程序。
假設(shè)您的集群達(dá)到總?cè)萘浚?jié)點(diǎn)大小如何影響自動(dòng)縮放?
首先,您應(yīng)該知道,當(dāng)集群自動(dòng)縮放器觸發(fā)自動(dòng)縮放時(shí),它不會(huì)考慮內(nèi)存或可用的CPU。
換句話說,總體上使用的集群不會(huì)觸發(fā)集群自動(dòng)縮放器。
相反,當(dāng)一個(gè)Pod因資源不足而無(wú)法調(diào)度時(shí),集群自動(dòng)縮放器會(huì)創(chuàng)建更多的節(jié)點(diǎn)。
此時(shí),自動(dòng)縮放器會(huì)調(diào)用云提供商的API,為該集群提供更多的節(jié)點(diǎn)。
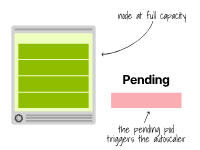
集群自動(dòng)縮放器在Pod由于資源不足而處于掛起狀態(tài)時(shí)提供新的節(jié)點(diǎn)。
集群自動(dòng)縮放器在Pod由于資源不足而處于掛起狀態(tài)時(shí)提供新的節(jié)點(diǎn)。

不幸的是,通常情況下,配置節(jié)點(diǎn)是比較緩慢的。
要?jiǎng)?chuàng)建一個(gè)新的虛擬機(jī)可能需要幾分鐘的時(shí)間。
提供較大或較小實(shí)例的配置時(shí)間是否會(huì)改變?
不,通常情況下,無(wú)論實(shí)例的大小如何,配置時(shí)間都是恒定的。
此外,集群自動(dòng)縮放器不限于一次添加一個(gè)節(jié)點(diǎn);它可能會(huì)一次添加多個(gè)節(jié)點(diǎn)。
我們來看一個(gè)例子。
有兩個(gè)集群:
第一個(gè)集群有一個(gè)4個(gè)vCPU和32GB的單一節(jié)點(diǎn)。第二個(gè)集群有13個(gè)1個(gè)vCPU和4GB的節(jié)點(diǎn)。一個(gè)具有0.3個(gè)vCPU和2GB內(nèi)存的應(yīng)用程序部署在集群中,并擴(kuò)展到13個(gè)副本。
這兩種設(shè)置都已達(dá)到總?cè)萘?/p>
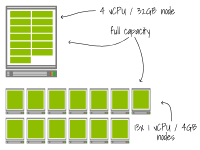
當(dāng)部署擴(kuò)展到15個(gè)副本時(shí)會(huì)發(fā)生什么(即增加兩個(gè)副本)?
在兩個(gè)集群中,集群自動(dòng)縮放器會(huì)檢測(cè)到由于資源不足,額外的Pod無(wú)法調(diào)度,并進(jìn)行如下配置:
對(duì)于第一個(gè)集群,增加一個(gè)具有4個(gè)vCPU和32GB內(nèi)存的額外節(jié)點(diǎn)。對(duì)于第二個(gè)集群,增加兩個(gè)具有1個(gè)vCPU和4GB內(nèi)存的節(jié)點(diǎn)。由于在為大型實(shí)例或小型實(shí)例提供資源時(shí)沒有時(shí)間差異,這兩種情況下節(jié)點(diǎn)將同時(shí)可用。
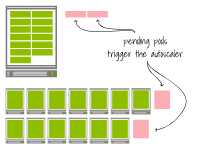
然而,你能看出另一個(gè)區(qū)別嗎?
第一個(gè)集群還有空間可以容納11個(gè)額外的Pod,因?yàn)榭側(cè)萘渴?3個(gè)。
而相反,第二個(gè)集群仍然達(dá)到了最大容量。
你可以認(rèn)為較小的增量更加高效和更便宜,因?yàn)槟阒惶砑铀璧牟糠帧?/p>
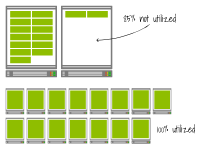 但是讓我們觀察一下當(dāng)您再次擴(kuò)展部署時(shí)會(huì)發(fā)生什么——這次擴(kuò)展到17個(gè)副本(即增加兩個(gè)副本)。
但是讓我們觀察一下當(dāng)您再次擴(kuò)展部署時(shí)會(huì)發(fā)生什么——這次擴(kuò)展到17個(gè)副本(即增加兩個(gè)副本)。
第一個(gè)集群在現(xiàn)有節(jié)點(diǎn)上創(chuàng)建了兩個(gè)額外的Pod。而第二個(gè)集群已經(jīng)達(dá)到了容量上限。Pod處于待定狀態(tài),觸發(fā)了集群自動(dòng)縮放器。最終,又會(huì)多出兩個(gè)工作節(jié)點(diǎn)。
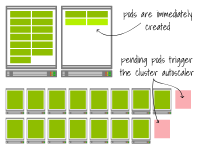
在第一個(gè)集群中,擴(kuò)展幾乎是瞬間完成的。
而在第二個(gè)集群中,您必須等待節(jié)點(diǎn)被配置完畢,然后才能讓Pod開始提供服務(wù)。
換句話說,在前者的情況下,擴(kuò)展速度更快,而在后者的情況下,需要更多的時(shí)間。
通常情況下,由于配置時(shí)間在幾分鐘范圍內(nèi),您應(yīng)該謹(jǐn)慎考慮何時(shí)觸發(fā)集群自動(dòng)縮放器,以避免產(chǎn)生更長(zhǎng)的Pod等待時(shí)間。
換句話說,如果您能夠接受(潛在地)沒有充分利用資源的情況,那么通過使用較大的節(jié)點(diǎn),您可以實(shí)現(xiàn)更快的擴(kuò)展。
但事情并不止于此。
拉取容器鏡像也會(huì)影響您能夠多快地?cái)U(kuò)展工作負(fù)載,這與集群中的節(jié)點(diǎn)數(shù)量有關(guān)。
拉取容器鏡像
在Kubernetes中創(chuàng)建Pod時(shí),其定義存儲(chǔ)在etcd中。
kubelet的工作是檢測(cè)到Pod分配給了它的節(jié)點(diǎn)并創(chuàng)建它。
kubelet將會(huì):
從控制平面下載定義。
調(diào)用容器運(yùn)行時(shí)接口(CRI)來創(chuàng)建Pod的沙箱。CRI會(huì)調(diào)用容器網(wǎng)絡(luò)接口(CNI)來將Pod連接到網(wǎng)絡(luò)。
調(diào)用容器存儲(chǔ)接口(CSI)來掛載任何容器卷。
在這些步驟結(jié)束時(shí),Pod就已經(jīng)存在了,kubelet可以繼續(xù)檢查活躍性和就緒性探針,并更新控制平面以反映新Pod的狀態(tài)。
kubelet與CRI、CSI和CNI接口需要注意的是,當(dāng)CRI在Pod中創(chuàng)建容器時(shí),它必須首先下載容器鏡像。
這當(dāng)然是在當(dāng)前節(jié)點(diǎn)上的容器鏡像沒有緩存的情況下。
讓我們來看一下這如何影響以下兩個(gè)集群的擴(kuò)展:
第一個(gè)集群有一個(gè)4個(gè)vCPU和32GB的單一節(jié)點(diǎn)。第二個(gè)集群有13個(gè)1個(gè)vCPU和4GB的節(jié)點(diǎn)。讓我們部署一個(gè)使用基于OpenJDK的容器鏡像的應(yīng)用程序,該應(yīng)用程序使用0.3個(gè)vCPU和2GB內(nèi)存,容器鏡像大小為1GB(僅基礎(chǔ)鏡像大小為775MB)的13個(gè)副本。
對(duì)這兩個(gè)集群會(huì)發(fā)生什么?
在第一個(gè)集群中,容器運(yùn)行時(shí)只下載一次鏡像并運(yùn)行13個(gè)副本。在第二個(gè)集群中,每個(gè)容器運(yùn)行時(shí)都會(huì)下載并運(yùn)行鏡像。在第一個(gè)方案中,只需要下載1GB的鏡像。
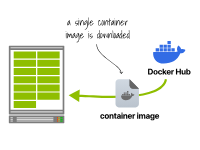
容器運(yùn)行時(shí)下載一次容器鏡像并運(yùn)行13個(gè)副本 然而,在第二個(gè)方案中,您需要下載13GB的容器鏡像。
由于下載需要時(shí)間,第二個(gè)集群在創(chuàng)建副本方面比第一個(gè)集群要慢。
此外,它會(huì)使用更多的帶寬并發(fā)起更多的請(qǐng)求(即至少每個(gè)鏡像層一個(gè)請(qǐng)求,共計(jì)13次),這使得它更容易受到網(wǎng)絡(luò)故障的影響。
13個(gè)容器運(yùn)行時(shí)中的每一個(gè)都會(huì)下載一個(gè)鏡像 需要注意的是,這個(gè)問題會(huì)與集群自動(dòng)縮放器緊密關(guān)聯(lián)。
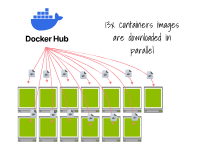
如果您的節(jié)點(diǎn)較小:
集群自動(dòng)縮放器會(huì)同時(shí)配置多個(gè)節(jié)點(diǎn)。
一旦準(zhǔn)備好,每個(gè)節(jié)點(diǎn)都開始下載容器鏡像。
最終,Pod被創(chuàng)建。
當(dāng)您配置較大的節(jié)點(diǎn)時(shí),容器鏡像很可能已經(jīng)在節(jié)點(diǎn)上緩存,Pod可以立即開始運(yùn)行。
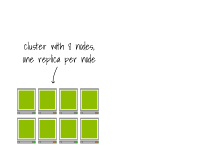 想象一下?lián)碛?個(gè)節(jié)點(diǎn)的集群,每個(gè)節(jié)點(diǎn)上有一個(gè)副本。
想象一下?lián)碛?個(gè)節(jié)點(diǎn)的集群,每個(gè)節(jié)點(diǎn)上有一個(gè)副本。
最終,Pod會(huì)被創(chuàng)建在節(jié)點(diǎn)上。
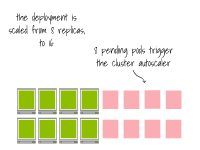
想象一下?lián)碛?個(gè)節(jié)點(diǎn)的集群,每個(gè)節(jié)點(diǎn)上有一個(gè)副本。
該集群已經(jīng)滿載;將副本擴(kuò)展到16個(gè)會(huì)觸發(fā)集群自動(dòng)縮放器。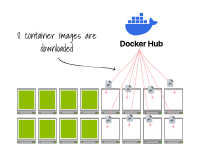
一旦節(jié)點(diǎn)被配置完畢,容器運(yùn)行時(shí)會(huì)下載容器鏡像。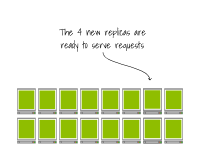 最終,Pod會(huì)在節(jié)點(diǎn)上創(chuàng)建。
最終,Pod會(huì)在節(jié)點(diǎn)上創(chuàng)建。
所以,您是否應(yīng)該始終配置較大的節(jié)點(diǎn)?
未必如此。
您可以通過容器注冊(cè)表代理來減輕節(jié)點(diǎn)下載相同容器鏡像的情況。
在這種情況下,鏡像仍然會(huì)被下載,但是從當(dāng)前網(wǎng)絡(luò)中的本地注冊(cè)表中下載。
或者您可以使用諸如spegel之類的工具來預(yù)熱節(jié)點(diǎn)的緩存。
使用Spegel,節(jié)點(diǎn)是可以廣告和共享容器鏡像層的對(duì)等體。
在這種情況下,容器鏡像將從其他工作節(jié)點(diǎn)下載,Pod幾乎可以立即啟動(dòng)。
但是,容器帶寬并不是您必須控制的唯一帶寬。
Kubelet與Kubernetes API的擴(kuò)展
kubelet被設(shè)計(jì)為從控制平面中獲取信息。
因此,在規(guī)定的間隔內(nèi),kubelet會(huì)向Kubernetes API發(fā)出請(qǐng)求,以檢查集群的狀態(tài)。
但是控制平面不是會(huì)向kubelet發(fā)送指令嗎?
拉取模型更容易擴(kuò)展,因?yàn)椋?/p>
控制平面不需要將消息推送到每個(gè)工作節(jié)點(diǎn)。
節(jié)點(diǎn)可以以自己的速度獨(dú)立地查詢API服務(wù)器。
控制平面不需要保持與kubelet的連接打開。
請(qǐng)注意,也有顯著的例外情況。例如,諸如kubectl logs和kubectl exec之類的命令需要控制平面連接到kubelet(即推送模型)。
但是Kubelet不僅僅是為了查詢信息。
它還向主節(jié)點(diǎn)報(bào)告信息。
例如,kubelet每十秒向集群報(bào)告一次節(jié)點(diǎn)的狀態(tài)。
此外,當(dāng)準(zhǔn)備探針失敗時(shí)(以及應(yīng)從服務(wù)中刪除pod端點(diǎn)),kubelet會(huì)通知控制平面。
而且kubelet會(huì)通過容器指標(biāo)將控制平面保持更新。
換句話說,kubelet會(huì)通過從控制平面發(fā)出請(qǐng)求(即從控制平面和向控制平面)來保持節(jié)點(diǎn)正常運(yùn)行所需的狀態(tài)。
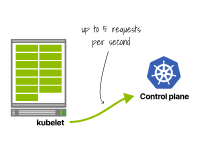
在Kubernetes 1.26及更早版本中,kubelet每秒可以發(fā)出多達(dá)5個(gè)請(qǐng)求(在Kubernetes >1.27中已放寬此限制)。
所以,假設(shè)您的kubelet正以最大容量運(yùn)行(即每秒5個(gè)請(qǐng)求),當(dāng)您運(yùn)行幾個(gè)較小的節(jié)點(diǎn)與一個(gè)單一的大節(jié)點(diǎn)時(shí)會(huì)發(fā)生什么?
讓我們看看我們的兩個(gè)集群:
第一個(gè)集群有一個(gè)4個(gè)vCPU和32GB的單一節(jié)點(diǎn)。
第二個(gè)集群有13個(gè)1個(gè)vCPU和4GB的節(jié)點(diǎn)。
第一個(gè)集群生成5個(gè)每秒的請(qǐng)求。
一個(gè)kubelet每秒發(fā)出5個(gè)請(qǐng)求
第二個(gè)集群每秒發(fā)出65個(gè)請(qǐng)求(即13 x 5)。
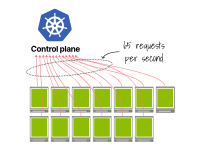
13個(gè)kubelet每秒各自發(fā)出5個(gè)請(qǐng)求
當(dāng)您運(yùn)行具有許多較小節(jié)點(diǎn)的集群時(shí),您應(yīng)該將API服務(wù)器的擴(kuò)展性擴(kuò)展到處理更頻繁的請(qǐng)求。
而反過來,這通常意味著在較大的實(shí)例上運(yùn)行控制平面或運(yùn)行多個(gè)控制平面。
節(jié)點(diǎn)和集群限制
Kubernetes集群的節(jié)點(diǎn)數(shù)量是否有限制?
Kubernetes被設(shè)計(jì)為支持多達(dá)5000個(gè)節(jié)點(diǎn)。
然而,這并不是一個(gè)嚴(yán)格的限制,正如Google團(tuán)隊(duì)所演示的,允許您在15,000個(gè)節(jié)點(diǎn)上運(yùn)行GKE集群。
對(duì)于大多數(shù)用例來說,5000個(gè)節(jié)點(diǎn)已經(jīng)是一個(gè)很大的數(shù)量,可能不會(huì)是影響您決定選擇較大還是較小節(jié)點(diǎn)的因素。
相反,您可以運(yùn)行在節(jié)點(diǎn)中運(yùn)行的最大Pod數(shù)可能會(huì)引導(dǎo)您重新思考集群架構(gòu)。
那么,在Kubernetes節(jié)點(diǎn)中,您可以運(yùn)行多少個(gè)Pod?
大多數(shù)云提供商允許您在每個(gè)節(jié)點(diǎn)上運(yùn)行110到250個(gè)Pod。
如果您自己配置集群,則默認(rèn)為110。
在大多數(shù)情況下,這個(gè)數(shù)字不是kubelet的限制,而是云提供商對(duì)重復(fù)預(yù)定IP地址的風(fēng)險(xiǎn)的容忍度。
為了理解這是什么意思,讓我們退后一步,看看集群網(wǎng)絡(luò)是如何構(gòu)建的。
在大多數(shù)情況下,每個(gè)工作節(jié)點(diǎn)都被分配一個(gè)具有256個(gè)地址的子網(wǎng)(例如10.0.1.0/24)。
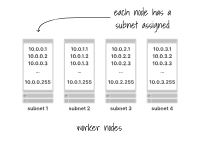
每個(gè)工作節(jié)點(diǎn)都被分配一個(gè)子網(wǎng)
其中兩個(gè)是受限制的,您可以使用254來運(yùn)行您的Pods。
考慮這種情況,其中在同一個(gè)節(jié)點(diǎn)上有254個(gè)Pod。
您創(chuàng)建了一個(gè)更多的Pod,但已經(jīng)耗盡了可用的IP地址,它保持在掛起狀態(tài)。
為了解決這個(gè)問題,您決定將副本數(shù)減少到253。
那么掛起的Pod會(huì)在集群中被創(chuàng)建嗎?
可能不會(huì)。
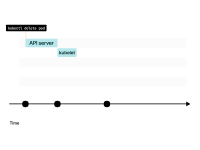
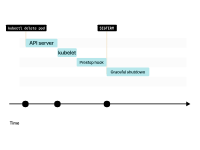
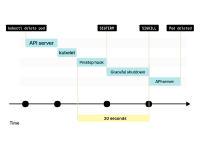
當(dāng)您刪除Pod時(shí),其狀態(tài)會(huì)變?yōu)椤罢诮K止”。
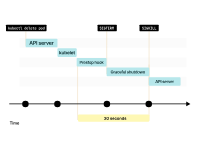
kubelet向Pod發(fā)送SIGTERM信號(hào)(以及調(diào)用preStop生命周期鉤子(如果存在)),并等待容器優(yōu)雅地關(guān)閉。
如果容器在30秒內(nèi)沒有終止,kubelet將發(fā)送SIGKILL信號(hào)到容器,并強(qiáng)制進(jìn)程終止。
在此期間,Pod仍未釋放IP地址,流量仍然可以到達(dá)它。
當(dāng)Pod最終被刪除時(shí),IP地址被釋放。
kubelet通知控制平面Pod已成功刪除。IP地址終于被釋放。
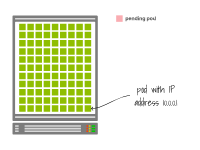
想象一下您的節(jié)點(diǎn)正在使用所有可用的IP地址。
當(dāng)一個(gè)Pod被刪除時(shí),kubelet會(huì)收到變更通知。
如果Pod有一個(gè)preStop鉤子,首先會(huì)調(diào)用它。然后,kubelet會(huì)向容器發(fā)送SIGTERM信號(hào)。
默認(rèn)情況下,進(jìn)程有30秒的時(shí)間來退出,包括preStop鉤子。如果在這之前進(jìn)程沒有退出,kubelet會(huì)發(fā)送SIGKILL信號(hào),強(qiáng)制終止進(jìn)程。
kubelet會(huì)通知控制平面Pod已成功刪除。IP地址最終被釋放。
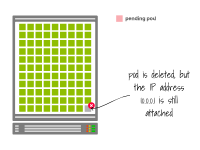
當(dāng)一個(gè)Pod被刪除時(shí),IP地址不會(huì)立即釋放。您必須等待優(yōu)雅的關(guān)閉。
這是一個(gè)好主意嗎?
好吧,沒有其他可用的IP地址 - 所以您沒有選擇。
想象一下,您的節(jié)點(diǎn)正在使用所有可用的IP地址。
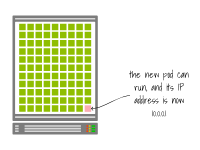
一旦Pod被刪除,IP地址就可以被重新使用。
kubelet通知控制平面Pod已成功刪除。IP地址終于被釋放。
此時(shí),掛起的Pod可以被創(chuàng)建,并且分配給它與上一個(gè)相同的IP地址。
想象一下,您的節(jié)點(diǎn)正在使用所有可用的IP地址。
下一頁(yè)
那后果會(huì)怎樣?
還記得我們提到過,Pod應(yīng)該優(yōu)雅地關(guān)閉并處理所有未處理的請(qǐng)求嗎?
嗯,如果Pod被突然終止(即沒有優(yōu)雅的關(guān)閉),并且IP地址立即分配給另一個(gè)Pod,那么所有現(xiàn)有的應(yīng)用程序和Kubernetes組件可能仍然不知道這個(gè)更改。
入口控制器將流量路由到一個(gè)IP地址。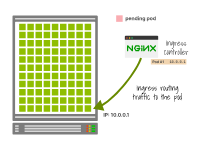
如果IP地址在沒有等待優(yōu)雅關(guān)閉的情況下被回收并被一個(gè)新的Pod使用,入口控制器可能仍然會(huì)將流量路由到該IP地址。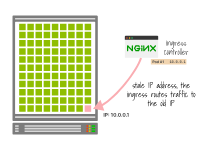
因此,一些現(xiàn)有的流量可能會(huì)錯(cuò)誤地發(fā)送到新的Pod,因?yàn)樗c舊的Pod具有相同的IP地址。
為了避免這個(gè)問題,您可以分配較少的IP地址(例如110)并使用剩余的IP地址作為緩沖區(qū)。
這樣,您可以相當(dāng)肯定地確保不會(huì)立即重新使用相同的IP地址。
存儲(chǔ)
計(jì)算單元對(duì)可以附加的磁盤數(shù)量有限制。
例如,在Azure上,具有2個(gè)vCPU和8GB內(nèi)存的Standard_D2_v5實(shí)例最多可以附加4個(gè)數(shù)據(jù)磁盤。
如果您希望將StatefulSet部署到使用Standard_D2_v5實(shí)例類型的工作節(jié)點(diǎn)上,您將無(wú)法創(chuàng)建超過四個(gè)副本。
這是因?yàn)镾tatefulSet中的每個(gè)副本都附加有一個(gè)磁盤。
一旦創(chuàng)建第五個(gè)副本,Pod將保持掛起狀態(tài),因?yàn)闊o(wú)法將持久卷聲明綁定到持久卷。
為什么呢?
因?yàn)槊總€(gè)持久卷都是一個(gè)附加的磁盤,所以您在該實(shí)例中只能有4個(gè)。
那么,您有哪些選擇?
您可以提供一個(gè)更大的實(shí)例。
或者您可以使用不同的子路徑字段重新使用相同的磁盤。
讓我們看一個(gè)例子。
下面的持久卷需要一個(gè)具有16GB空間的磁盤:
如果您將此資源提交到集群,您將看到創(chuàng)建了一個(gè)持久卷并綁定到它。
$kubectlgetpv,pvc
持久卷與持久卷聲明之間存在一對(duì)一的關(guān)系,因此您無(wú)法有更多的持久卷聲明來使用相同的磁盤。
apiVersion:apps/v1 kind:Deployment metadata: name:app1 spec: selector: matchLabels: name:app1 template: metadata: labels: name:app1 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
如果您想在您的Pod中使用該聲明,可以這樣做:
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
您可以有另一個(gè)使用相同持久卷聲明的部署:
但是,通過這種配置,兩個(gè)Pod將在同一個(gè)文件夾中寫入其數(shù)據(jù)。
您可以通過在subPath中使用子目錄來解決此問題。
apiVersion:apps/v1 kind:Deployment metadata: name:app2 spec: selector: matchLabels: name:app2 template: metadata: labels: name:app2 spec: volumes: -name:pv-storage persistentVolumeClaim: claimName:shared containers: -name:main image:busybox volumeMounts: -mountPath:'/data' name:pv-storage
subPath: app2
部署將在以下路徑上寫入其數(shù)據(jù):
對(duì)于第一個(gè)部署,是/data/app1
對(duì)于第二個(gè)部署,是/data/app2
這個(gè)解決方法并不是完美的,有一些限制:
所有部署都必須記住使用subPath。如果需要寫入卷,您應(yīng)該選擇可以從多個(gè)節(jié)點(diǎn)訪問的Read-Write-Many卷。這些通常需要昂貴的提供。此外,對(duì)于StatefulSet,相同的解決方法無(wú)法起作用,因?yàn)檫@將為每個(gè)副本創(chuàng)建全新的持久卷聲明(和持久卷)。
總結(jié)和結(jié)論
那么,在集群中是使用少量大節(jié)點(diǎn)還是許多小節(jié)點(diǎn)?
這取決于情況。
反正,什么是小的,什么是大的?
這取決于您在集群中部署的工作負(fù)載。
例如,如果您的應(yīng)用程序需要10GB內(nèi)存,那么運(yùn)行一個(gè)具有16GB內(nèi)存的實(shí)例等于“運(yùn)行一個(gè)較小的節(jié)點(diǎn)”。
對(duì)于只需要64MB內(nèi)存的應(yīng)用程序來說,相同的實(shí)例可能被認(rèn)為是“大的”,因?yàn)槟梢匀菁{多個(gè)這樣的實(shí)例。
那么,對(duì)于具有不同資源需求的混合工作負(fù)載呢?
在Kubernetes中,沒有規(guī)定所有節(jié)點(diǎn)必須具有相同的大小。
您完全可以在集群中使用不同大小的節(jié)點(diǎn)混合。
這可能讓您在這兩種方法的優(yōu)缺點(diǎn)之間進(jìn)行權(quán)衡。
-
cpu
+關(guān)注
關(guān)注
68文章
10997瀏覽量
214921 -
節(jié)點(diǎn)
+關(guān)注
關(guān)注
0文章
220瀏覽量
24740 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9563瀏覽量
86905 -
容器
+關(guān)注
關(guān)注
0文章
503瀏覽量
22309 -
kubernetes
+關(guān)注
關(guān)注
0文章
236瀏覽量
8896
原文標(biāo)題:在 Kubernetes 集群中,如何正確選擇工作節(jié)點(diǎn)資源大小
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Kubernetes架構(gòu)和核心組件組成 Kubernetes節(jié)點(diǎn)“容器運(yùn)行時(shí)”技術(shù)分析
阿里云上Kubernetes集群聯(lián)邦
Kubernetes Ingress 高可靠部署最佳實(shí)踐
Kubernetes 從懵圈到熟練:集群服務(wù)的三個(gè)要點(diǎn)和一種實(shí)現(xiàn)
如何部署基于Mesos的Kubernetes集群
淺談Kubernetes集群的高可用方案

Kubernetes 集群的功能
Kubernetes集群內(nèi)服務(wù)通信機(jī)制介紹
Kubernetes集群的關(guān)閉與重啟
Kubernetes的集群部署
Kubernetes中的邏輯組件
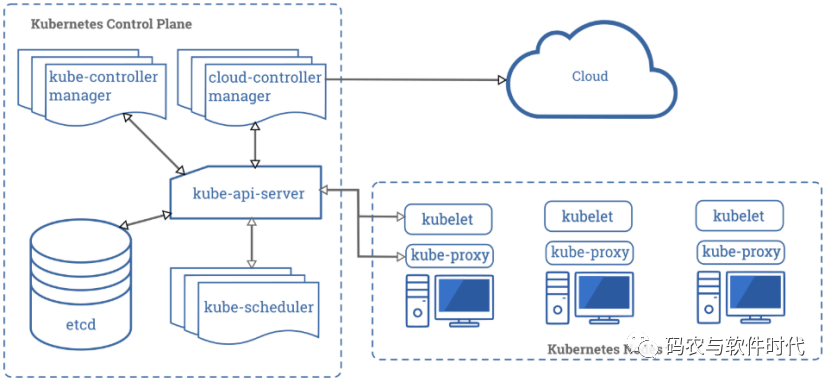
Kubernetes是怎樣工作的?
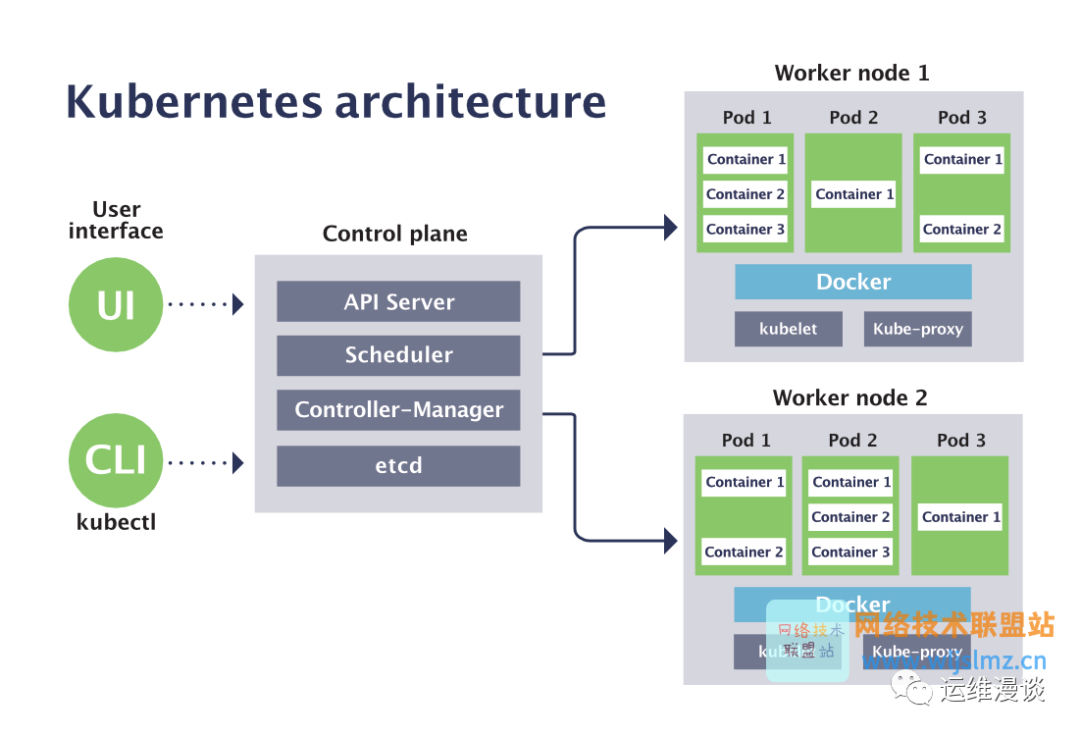
使用Velero備份Kubernetes集群





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論