") 直接飛行時間(DToF)視頻的深度一致超分辨率重建
直接飛行時間(DToF)視頻的深度一致超分辨率重建

1. 摘要
直接飛行時間(dToF)傳感器因其測量精度高、結(jié)構(gòu)緊湊、響應(yīng)速度快和低功耗,被視為下一代設(shè)備3D傳感的理想選擇。但由于制造限制,其數(shù)據(jù)空間分辨率較低(例如iPhone dToF約為20×30),需要進行超分辨處理才能供下游任務(wù)使用。
本文提出了一種利用高分辨率RGB圖像來增強低分辨率dToF數(shù)據(jù)的方法。不同于傳統(tǒng)的每幀融合RGB和深度的方法,我們采用了多幀融合策略,以減少低分辨率dToF圖像的空間模糊。此外,我們還利用了dToF傳感器提供的深度直方圖信息,這是一種dToF特有的特征,來進一步改善空間分辨率。
為了在復(fù)雜的室內(nèi)動態(tài)環(huán)境下評估我們的模型,我們提供了大規(guī)模dToF傳感器數(shù)據(jù)集——DyDToF,這是第一個具有動態(tài)對象和遵循物理成像過程的RGB-dToF視頻數(shù)據(jù)集。我們相信隨著dToF深度傳感在移動設(shè)備上成為主流,我們提出的方法和數(shù)據(jù)集將促進行業(yè)的發(fā)展。
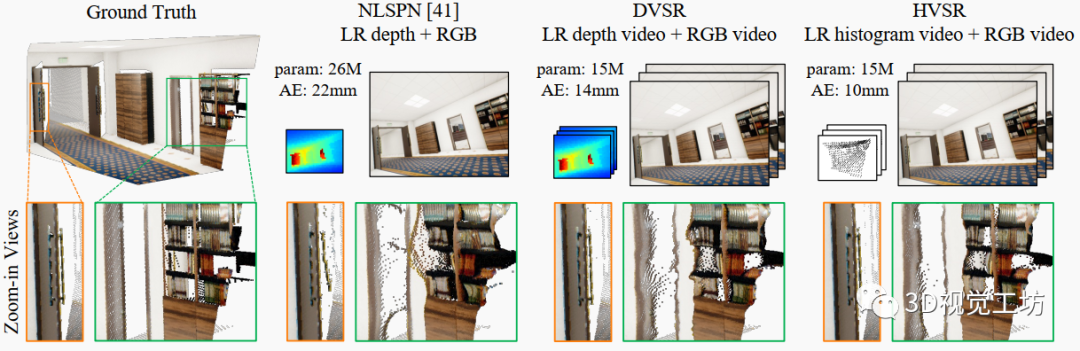
圖1. 我們第一個提出了多幀方法,dToF深度視頻超分辨率(DVSR)和直方圖視頻超分辨率(HVSR),利用高分辨率RGB幀引導(dǎo)進行低分辨率dToF傳感器視頻進行超分辨處理。深度預(yù)測的點云可視化顯示,通過利用多幀相關(guān)性,與單幀深度增強網(wǎng)絡(luò)相比,DVSR預(yù)測的幾何形狀更好,而參數(shù)更少;HVSR通過利用dToF直方圖信息進一步改善了幾何形狀的保真度并減少了飛點。除每幀估計的改進外,我們強烈建議讀者查看補充視頻,其可視化了整個序列中時間穩(wěn)定性的顯著提高。(視頻鏈接:https://www.youtube.com/watch?v=77LTIDqhBjA&ab_channel=ZhanghaoSun)
2. 方法提出
在移動設(shè)備上進行深度估計,對導(dǎo)航、游戲和增強/虛擬現(xiàn)實至關(guān)重要。以前出現(xiàn)的深度估計傳感器·包括:雙目攝像和結(jié)構(gòu)光等傳感器,以及間接飛行時間傳感器。最近,dToF傳感器因其精度高、體積小、功耗低而受關(guān)注。但由于制造限制,其空間分辨率很低,每個像素都整合了場景局部區(qū)域的深度,導(dǎo)致高分辨率重建存在明顯的空間模糊。以前基于RGB圖像引導(dǎo)的深度補全和超分辨率方法,要么假設(shè)存在高分辨采樣,要么使用簡化成像模型,直接應(yīng)用到dToF數(shù)據(jù)效果不佳。如圖1第2列所示,預(yù)測遭受幾何畸變和飛點的影響。另一限制是它們僅處理單幀,而實際應(yīng)用需要視頻流輸入,存在一定的時間連貫需求。逐幀處理RGB-depth視頻會忽略時間相關(guān)性,導(dǎo)致深度估計中顯著的時間抖動。
本文提出從兩個方面解決dToF數(shù)據(jù)的空間模糊:利用RGB-dToF視頻序列中的多幀信息融合和dToF直方圖信息。我們設(shè)計了dToF視頻超分辨網(wǎng)絡(luò)DVSR,輸入是高分辨率RGB圖像序列和低分辨率dToF深度圖,輸出是高分辨率深度圖序列。受RGB視頻處理算法的啟發(fā),我們放寬多視圖約束,使用容錯的多幀對齊。相比逐幀處理,我們的網(wǎng)絡(luò)明顯提升了精度和時間連貫性。與逐幀處理基線相比,DVSR顯著提高了預(yù)測精度和時間一致性,如圖1第3列所示。
此外,dToF傳感器可提供每個像素的深度直方圖。我們設(shè)計了匹配該直方圖的流程,將其融入網(wǎng)絡(luò),形成直方圖視頻超分辨框架HVSR。這進一步消除了空間模糊。如圖1第4列所示,與DVSR相比,HVSR的估計質(zhì)量進一步提高。
深度網(wǎng)絡(luò)的訓(xùn)練和測試數(shù)據(jù)集也很重要。以前,真實采集和高質(zhì)量合成數(shù)據(jù)集都被廣泛使用。但是,它們都不包含具有大量動態(tài)對象的RGB-D視頻序列。為此,我們引入了DyDToF,這是一個具有動態(tài)動物(例如貓和狗)和dToF模擬器的多樣化室內(nèi)場景的合成數(shù)據(jù)集。我們綜合了RGB圖像序列、深度圖、表面法線圖、材料反照率和相機姿態(tài)序列。據(jù)我們所知,這是第一個提供動態(tài)室內(nèi) RGB 深度視頻數(shù)據(jù)集。我們將基于物理的虛擬 dToF 傳感器集成到 DyDToF 數(shù)據(jù)集中,并分析(1)所提出的視頻處理框架如何推廣到動態(tài)場景,以及(2)低級數(shù)據(jù)模式如何促進網(wǎng)絡(luò)訓(xùn)練和評估。
總結(jié)一下,我們的貢獻有:
引入RGB引導(dǎo)的dToF視頻深度超分辨率以解決這種移動3D傳感器固有的空間模糊性。
提出基于神經(jīng)網(wǎng)絡(luò)的RGB-dToF視頻超分辨率算法,可以高效利用視頻中包含的豐富多幀信息和獨特的dToF直方圖。
提出第一個具有動態(tài)物體和基于物理的dToF傳感器模擬的室內(nèi)RGB-D數(shù)據(jù)集。我們的算法在所提出的數(shù)據(jù)集上進行了系統(tǒng)評估,以驗證精度和時間一致性的顯著提升。
3. dToF基礎(chǔ)簡介
本節(jié)簡要介紹低分辨率dToF傳感器的圖像形成模型,并詳細闡述它與以前的深度增強任務(wù)的不同之處。
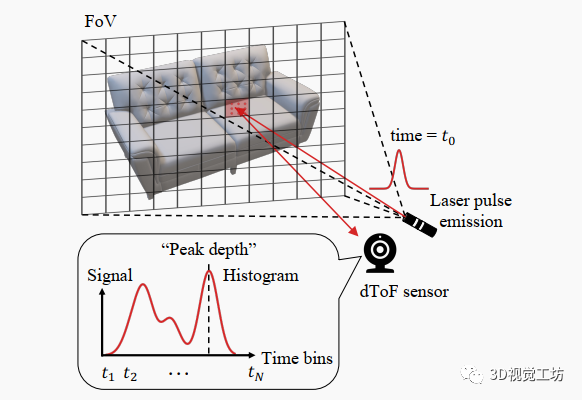
圖2. 直接飛行時間(dToF)傳感器工作原理。每個dToF像素記錄一個包含F(xiàn)oV內(nèi)補丁深度信息的直方圖,導(dǎo)致空間模糊。dToF傳感器可以在“峰值檢測”模式或直方圖模式下運行。
如圖2所示,短光脈沖由脈沖激光器生成并發(fā)射到場景中。脈沖會散射,一部分光子將反射回dToF檢測器,觸發(fā)到達事件并記錄時間戳。根據(jù)激光發(fā)射和接收之間的時間差,場景深度由比例關(guān)系確定,其中是時間差,是光速。每個dToF像素捕獲其各自的視場(FoV)內(nèi)的所有場景點反射的光,該FoV由整體傳感器FoV和空間分辨率確定。因此,它通常在多個時間槽記錄光子到達事件。第k個時間槽中的信號幅度可以表示為
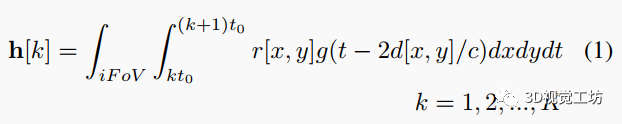
其中是時間槽大小,是時間槽數(shù)(由dToF像素電路確定),是激光脈沖時間形狀,、是FoV內(nèi)場景點的深度和輻射度。我們稱單個dToF像素記錄的維信號為“直方圖”。我們在下面的模擬和合成數(shù)據(jù)生成中使用這個圖像形成模型。與傳統(tǒng)的深度超分任務(wù)相似,這里我們假設(shè)低空間分辨率是輸入數(shù)據(jù)中的唯一退化。
dToF數(shù)據(jù)可以以兩種模式處理:“峰值檢測”模式和直方圖模式。在第一種模式下,在每個像素處執(zhí)行直方圖峰值檢測。只有具有最強信號的峰值深度值被發(fā)送到后處理網(wǎng)絡(luò)。在第二種模式下,利用直方圖中包含的更多信息。在這兩種模式下,dToF數(shù)據(jù)都包含相對精確的深度信息,而側(cè)向空間信息只在低分辨率下已知(例如,所需分辨率的16倍更低)。這種空間模糊性使得深度超分任務(wù)比傳統(tǒng)的稀疏深度補全任務(wù)更具挑戰(zhàn)性。
4. 方法詳解
我們的網(wǎng)絡(luò)輸入是T幀序列。每幀包含一個空間分辨率為的RGB圖像和一個空間分辨率為的dToF數(shù)據(jù),其中是下采樣因子(我們在所有實驗中使用)。在直方圖模式下,每個幀的dToF數(shù)據(jù)在時間維度上具有個時間槽,導(dǎo)致的數(shù)據(jù)量。在兩種模式下,我們的網(wǎng)絡(luò)預(yù)測一個高分辨率的深度圖序列。
4.1 dToF深度視頻超分辨率
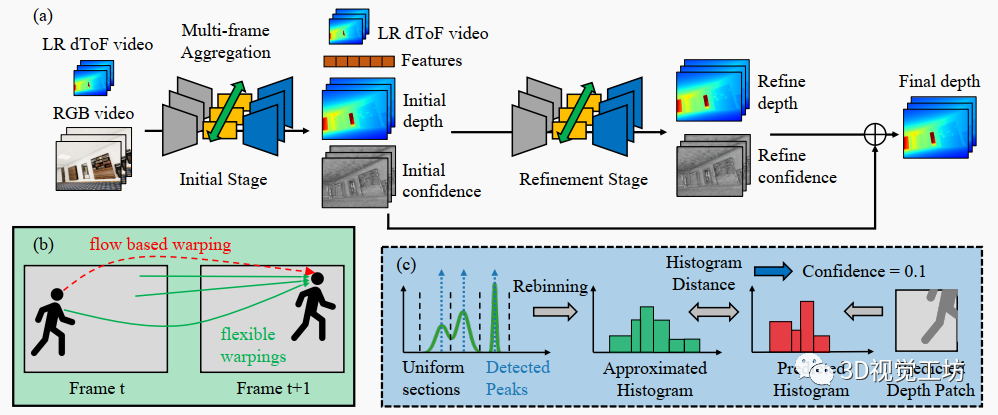
圖3. (a)所提出的dToF視頻超分辨率框架。它通常遵循兩階段預(yù)測策略,其中兩個階段都預(yù)測一個深度圖和置信圖,并融合以獲得最終預(yù)測。特征在幀之間進行對齊和聚合,可以是雙向的或僅前向的。(b)基于靈活變形的多幀特征聚合示意圖。與嚴格遵循估計的光流不同,來自多個候選位置的特征在幀之間進行變形。(c)所提出的直方圖處理流程示意圖。完整直方圖通過峰值檢測和再分箱進行壓縮以產(chǎn)生近似直方圖。在置信預(yù)測階段,計算輸入直方圖與預(yù)測深度值生成的直方圖之間的直方圖距離,以估計預(yù)測的置信度。
整體RGB-dToF視頻超分辨率(DVSR)網(wǎng)絡(luò)架構(gòu)如圖3(a)所示。該網(wǎng)絡(luò)以遞歸方式操作,其中多幀信息以僅前向或雙向傳播。在每幀中,我們執(zhí)行兩階段處理以預(yù)測高分辨率深度圖(與RGB引導(dǎo)具有相同分辨率)。在第一階段,dToF傳感器數(shù)據(jù)與RGB引導(dǎo)融合以生成初始高分辨率深度預(yù)測和置信度圖。第一階段的處理結(jié)果和dToF傳感器數(shù)據(jù)作為輸入饋入第二階段細化網(wǎng)絡(luò),以生成第二個深度預(yù)測和置信度圖。根據(jù)置信度圖,對初始和第二個深度預(yù)測進行融合以生成最終預(yù)測。除特征提取器和解碼器外,每個階段都包含一個多幀傳播模塊和一個融合骨干網(wǎng)絡(luò),以充分交換時間信息并在時間上穩(wěn)定深度估計。詳細的網(wǎng)絡(luò)架構(gòu)在補充材料中提供。
以前的單目深度視頻處理算法通常對多視圖幾何提出“硬”圖心約束。在立體視頻處理中也采用“硬”對應(yīng)搜索和運動對準(zhǔn)。相反,我們給網(wǎng)絡(luò)選擇多個有用對應(yīng)項的自由性。我們對預(yù)訓(xùn)練的光流估計器進行聯(lián)合微調(diào),而不對估計的流施加監(jiān)督。我們還在基于光流的變形后包含可變形卷積模塊,以挑選多個特征聚合候選項(如圖3(b)所示)。這一操作進一步增加了靈活性,并補償流估計中的錯誤。這一設(shè)計選擇至少提供兩個好處:首先,該算法可以輕松推廣到靜態(tài)和這一設(shè)計選擇至少提供兩個好處:首先,該算法可以輕松推廣到靜態(tài)和動態(tài)環(huán)境。其次,幀之間的對應(yīng)檢測不需要準(zhǔn)確。盡管深度學(xué)習(xí)方法最近有進展,但仍缺少輕量、快速且準(zhǔn)確的流估計器。特別是,為了在幀之間準(zhǔn)確變形深度值,需要3D場景流估計,這比2D光流估計更具挑戰(zhàn)性。最先進的場景流估計器在準(zhǔn)確性和僅限于剛體運動方面仍然存在比較低的問題。
4.2 dToF直方圖視頻超分辨率
基于深度視頻超分辨率網(wǎng)絡(luò),我們進一步提出了一個直方圖視頻超分辨率(HVSR)網(wǎng)絡(luò),以利用dToF傳感器提供的獨特直方圖信息。即使使用強大的機器,處理完整的直方圖數(shù)據(jù)也不可行。因此,我們首先在直方圖的時間維度上執(zhí)行簡單的壓縮操作。對直方圖進行再分箱以在單目深度估計中強制網(wǎng)絡(luò)關(guān)注順序關(guān)系和更重要的深度范圍的技術(shù)已被提出。如圖3(c)所示,這里我們提出了一個類似的直方圖壓縮策略:首先,我們閾值直方圖以去除低于噪聲水平的信號。然后,將直方圖均勻劃分為段,并在每個段內(nèi)檢測峰值。然后,我們將直方圖再分箱為由部分邊界和峰值定義的個時間槽。這個的數(shù)據(jù)量輸入神經(jīng)網(wǎng)絡(luò)。
我們在兩個方面利用壓縮后的直方圖:首先,將檢測到的個峰值作為兩階段網(wǎng)絡(luò)的輸入進行連接。其次,我們計算直方圖匹配誤差來促進置信度預(yù)測。預(yù)測的高分辨率深度圖被劃分為補丁,每個補丁對應(yīng)一個dToF像素。將補丁內(nèi)的深度值根據(jù)圖像形成模型(等式1)轉(zhuǎn)換為直方圖。然后,將預(yù)測的直方圖與輸入的dToF直方圖進行比較。我們根據(jù)Wasserstein距離定義這兩個直方圖之間的差異。
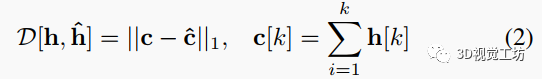
較大的表示對應(yīng)補丁內(nèi)的預(yù)測不太可靠,應(yīng)該在細化中被賦予較低的置信度。直方圖匹配誤差被輸入到網(wǎng)絡(luò)兩階段中的置信度預(yù)測層。
4.3 實現(xiàn)細節(jié)
我們在TarTanAir大規(guī)模RGB-D視頻數(shù)據(jù)集上訓(xùn)練所提出的dToF深度和直方圖視頻超分辨率網(wǎng)絡(luò)。我們使用14個場景進行訓(xùn)練,每個場景有300、600、600、600幀。我們從真值深度圖按照圖像形成模型(等式1)模擬dToF原始數(shù)據(jù)。由于TarTanAir數(shù)據(jù)集僅提供RGB圖像,我們使用平均灰度圖像來逼近輻射度。我們在所提出的DyDToF數(shù)據(jù)集中解決了這個問題,以獲得更真實的dToF模擬。
我們使用每幀的Charbonnier損失與和梯度損失對網(wǎng)絡(luò)進行監(jiān)督。
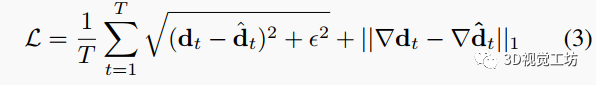
其中分別是第幀的真值和估計深度圖,是梯度算子。在訓(xùn)練過程中,我們將數(shù)據(jù)集中的長序列劃分為較短的幀序列。對于每個視頻片段,我們將深度值裁剪到[0,40]并歸一化到[0,1]。在所有實驗中,我們將空間超分辨率因子設(shè)置為16,壓縮直方圖中的時間槽數(shù)設(shè)置為4。我們總共訓(xùn)練大約15萬次迭代,批量大小為32。我們使用Adam優(yōu)化器,學(xué)習(xí)率為,以及學(xué)習(xí)率衰減因子為0.2的多步學(xué)習(xí)率衰減調(diào)度器。在8×Nvidia Tesla-V100 GPU上訓(xùn)練大約需要2天。
5. 結(jié)果展示
我們在多個RGB-D數(shù)據(jù)集上對所提出的dToF視頻超分辨率網(wǎng)絡(luò)進行評估。由于沒有現(xiàn)成的算法直接適用于dToF傳感器超分任務(wù),我們重新訓(xùn)練了兩種最新的每幀深度增強/補全網(wǎng)絡(luò)NLSPN和PENet,使用相同的訓(xùn)練設(shè)置作為我們的基線。另一個基線是我們將所提出的DVSR網(wǎng)絡(luò)以每幀方式操作。我們使用三個指標(biāo)評估深度超分辨結(jié)果:每幀絕對誤差(AE)(更低更好)、每幀指標(biāo)(更高更好)和時間端點誤差(TEPE)(更低更好)。
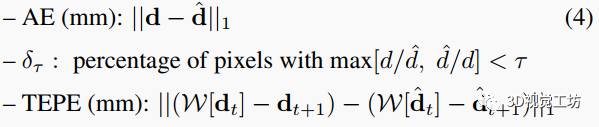
其中是從第幀到第幀的變形運算。我們使用真值光流進行這種變形,并使用PyTorch3D中的遮擋感知變形模塊來避免遮擋導(dǎo)致的偽像。
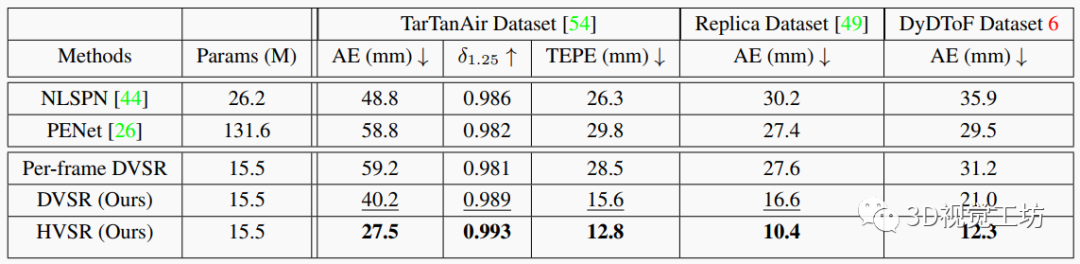
表1. 在TarTanAir、Replica和DyDToF數(shù)據(jù)集上的定量比較。粗體表示最佳結(jié)果,下劃線表示第二佳結(jié)果。我們的網(wǎng)絡(luò)在合成的TarTanAir數(shù)據(jù)集上訓(xùn)練,其包含靜態(tài)場景,但泛化良好到真實場景的Replica數(shù)據(jù)集和動態(tài)場景的DyDToF數(shù)據(jù)集。
TarTanAir數(shù)據(jù)集評估。我們在TarTanAir數(shù)據(jù)集中使用4個場景進行評估,每個場景分別有300、600、600、600幀。如表1所示,兩個視頻處理網(wǎng)絡(luò)一致優(yōu)于每幀基線,盡管參數(shù)更少。這驗證了多幀信息聚合的有效性,因為當(dāng)以每幀方式操作時,所提出的網(wǎng)絡(luò)性能較差。通過利用dToF直方圖信息,HVSR進一步提升了估計質(zhì)量。
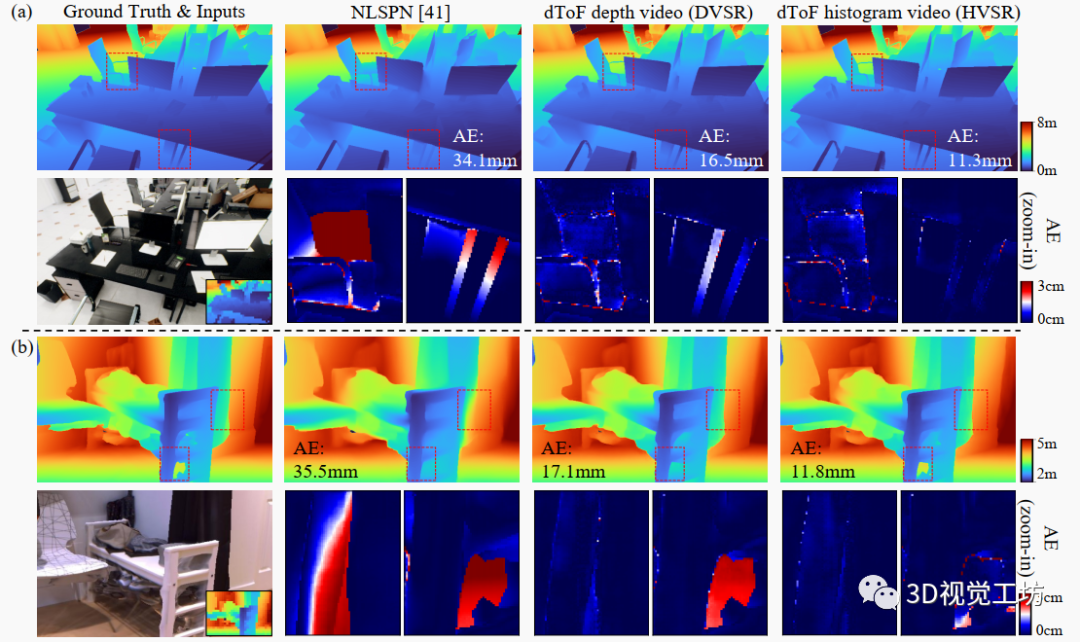
圖4. 在TarTanAir場景(a)和Replica場景(b)上的定性比較。DVSR和HVSR相比每幀基線明顯優(yōu)越,尤其是在放大區(qū)域。請參閱補充視頻或項目頁面以獲得更好的時間可視化。
我們在圖4(a)中進行定性比較。與每幀基線相比,視頻處理網(wǎng)絡(luò)取得了更高的深度質(zhì)量,特別是在細結(jié)構(gòu)(如椅子扶手和薄枕頭)方面(更好的可視化在放大的邊界框中)。顯然,在多幀中聚合信息可以緩解處理中的空間模糊性,因為細結(jié)構(gòu)在一幀中可能不可見,但在其鄰近幀中可能出現(xiàn)。
Replica數(shù)據(jù)集評估。Replica是一個真實捕獲的室內(nèi)3D數(shù)據(jù)集,具有真實的場景紋理和高質(zhì)量幾何。我們使用相同的數(shù)據(jù)合成流水線從真值深度和RGB圖像生成低分辨率的dToF數(shù)據(jù)。我們在表1第二列中展示了我們的網(wǎng)絡(luò)(無微調(diào))在Replica數(shù)據(jù)集上的跨數(shù)據(jù)集泛化能力。由于Replica數(shù)據(jù)集中沒有真值光流,我們不評估時間指標(biāo)。我們還在圖4(b)中進行定性比較。
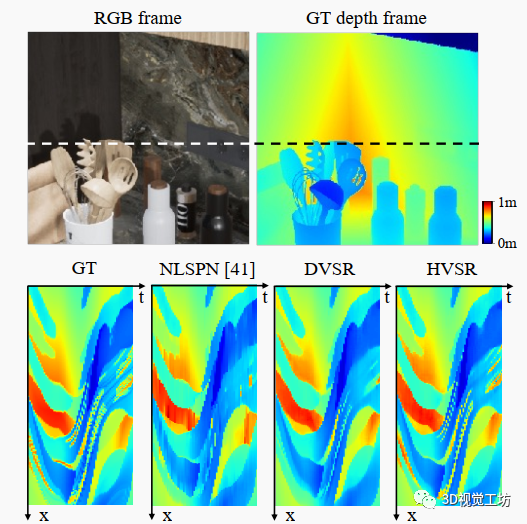
圖5. x-t切片(沿虛線)用于時間穩(wěn)定性可視化。與視頻處理結(jié)果相比,每幀基線的時間輪廓更加嘈雜,而HVSR揭示了更多細節(jié)。
時間穩(wěn)定性。我們還在圖5中可視化估計深度圖的x-t切片的時間穩(wěn)定性。每幀處理引入明顯的時間抖動,在x-t切片上可視化為嘈雜/模糊偽像。DVSR和HVSR都具有清晰的x-t切片,展示了它們的高時間穩(wěn)定性,而HVSR進一步揭示了DVSR預(yù)測中不可見的細結(jié)構(gòu)。請參閱補充視頻或項目頁面以獲得更好的時間可視化。
6. DyDToF RGB-dToF視頻數(shù)據(jù)集
由于缺乏動態(tài)RGB-D視頻數(shù)據(jù)集,我們引入了DyDToF,其中室內(nèi)環(huán)境中插入了動物動畫。數(shù)據(jù)集概述如圖6所示。該數(shù)據(jù)集包含100個序列(總共45k幀)的RGB圖像、深度圖、法線圖、材料反照率和相機姿態(tài),這些都是從Unreal Engine與開源插件EasySynth生成的。我們使用約30種動物網(wǎng)格(包括狗、貓、鳥等)和約50種相關(guān)動畫生成數(shù)據(jù)集,并將它們放置在20個室內(nèi)環(huán)境中(包括學(xué)校、辦公室、公寓等)。所有3D資產(chǎn)都從公開可用的資源中購買。

圖6. DyDToF數(shù)據(jù)集概述。(a)我們將動態(tài)動物模型插入到各種高質(zhì)量的室內(nèi)環(huán)境地圖中。(b)我們生成RGB圖像、深度圖、法線圖、材料反照率和相機姿態(tài)序列。
6.1 動態(tài)對象評估
我們在DyDToF數(shù)據(jù)集上進行了類似評估,重點關(guān)注動態(tài)對象的深度估計。定量比較如表1第3列所示。我們還在圖7(a)中展示了一幅來自吠叫狗動畫的幀,進行定性比較。雖然TarTanAir數(shù)據(jù)集包含非常有限的動態(tài)對象,但所提出的視頻網(wǎng)絡(luò)推廣到動態(tài)場景的效果很好。我們將此歸因于我們靈活的、容錯的多幀對齊模塊。請參閱我們的補充材料中的消融研究。
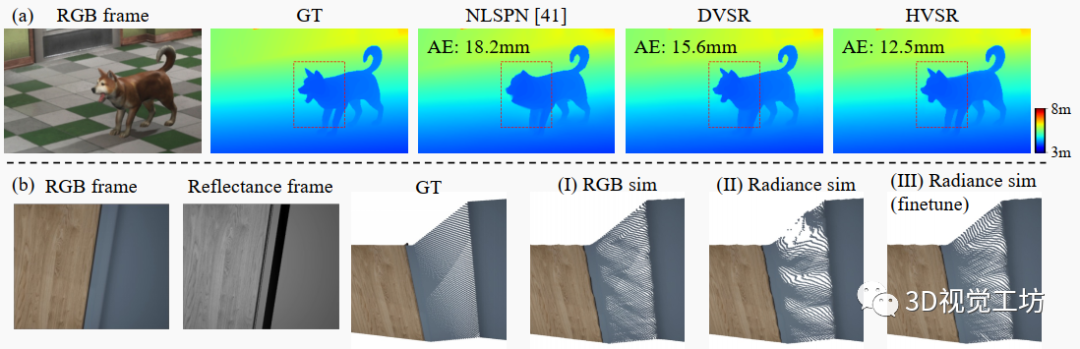
圖7. 在DyDToF數(shù)據(jù)集上的評估。(a)提出的網(wǎng)絡(luò)DVSR和HVSR在具有動態(tài)對象的情況下表現(xiàn)良好,而每幀基線遭受畸變和模糊的影響。(b) 在TarTanAir數(shù)據(jù)集上訓(xùn)練的HVSR在RGB圖像強度與渲染方程計算的輻射度之間存在不匹配時會失敗(II)。通過在DyDToF數(shù)據(jù)集上進行微調(diào),這種偽像大大得到緩解,DyDToF數(shù)據(jù)集采用了更真實的dToF模擬(III)。
6.2 更真實的dToF模擬
如第5節(jié)所述,由于TarTanAir數(shù)據(jù)集不提供材料反照率和表面法線,我們用RGB圖像逼近輻射度。根據(jù)渲染方程,實際輻射度由材料反照率、觀察方向和表面法線確定。
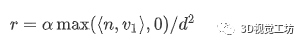
由于我們假設(shè)dToF傳感器中的激光器和接收器共定位,因此觀察方向與激光照明方向平行。
我們在DyDToF數(shù)據(jù)集中使用這個公式生成更真實的dToF模擬,并微調(diào)在TarTanAir數(shù)據(jù)集上預(yù)訓(xùn)練的網(wǎng)絡(luò)。我們在圖7(b)中展示一個極端情況,其中架子的一側(cè)面具有非常低的輻射度,因為表面法線與dToF激光發(fā)射方向近乎垂直。由于光源與攝像頭不共定位,RGB圖像中不存在此效應(yīng)。如第3列(I)所示,當(dāng)在dToF直方圖模擬中使用RGB圖像時,預(yù)訓(xùn)練的HVSR推廣良好。但是,當(dāng)在dToF模擬中使用物理正確的輻射度時,預(yù)訓(xùn)練的HVSR失敗,出現(xiàn)大的幾何畸變(II)。通過在DyDToF上微調(diào)HVSR,它適應(yīng)了預(yù)測的直方圖與基礎(chǔ)幾何之間更真實的關(guān)系,并避免失敗(III)。
7. 多幀融合消融研究
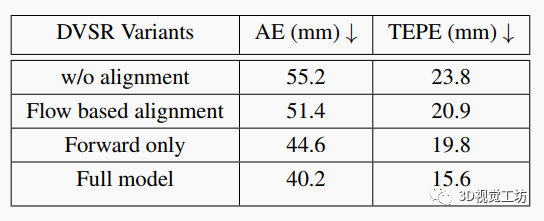
表2. 多幀融合模塊的消融研究。
我們首先比較各種多幀融合模塊,如表2所示。在最簡單的情況下,多個幀的特征被連接而不對齊。這顯著降低了性能,因為不同空間位置的特征被融合在一起。基于流的對齊使用預(yù)訓(xùn)練(固定)的光流估計器對齊幀之間的特征。但是,這種方法受到流估計不準(zhǔn)確和前景-背景混合的基本問題的影響。我們提出的框架中的靈活變形避免了這些問題,并給網(wǎng)絡(luò)選擇從變形特征中挑選有用信息的自由度。我們的完整多幀融合模塊利用雙向傳播。但是,這禁止在線操作,因為需要未來信息。為此,我們用僅前向傳播替換雙向傳播。如表2第三行所示,這也犧牲了性能,但與每幀處理基線和其他低效對齊策略相比,它仍實現(xiàn)了一致的改進。
8. 結(jié)論
本文針對dToF傳感器的數(shù)據(jù)特點,設(shè)計了視頻深度超分辨網(wǎng)絡(luò)。多幀融合可明顯提升精度、時間連貫性和對動態(tài)場景的泛化。使用傳感器的直方圖信息也可進一步改善細節(jié)。我們構(gòu)建的第一室內(nèi)動態(tài)RGB-D數(shù)據(jù)集——DyDToF,能更好地反映實際應(yīng)用場景,并具有dToF傳感器的仿真。它不僅限于dToF傳感器應(yīng)用,還有可能為通用動態(tài)場景3D重建和新視圖合成算法確立新的基準(zhǔn)。
-
傳感器
+關(guān)注
關(guān)注
2564文章
52773瀏覽量
765199 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25343 -
dToF
+關(guān)注
關(guān)注
2文章
98瀏覽量
8419
原文標(biāo)題:?CVPR2023 | 直接飛行時間(DToF)視頻的深度一致超分辨率重建
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Analog Devices Inc. ADTF3175 100萬像素飛行時間模塊數(shù)據(jù)手冊
FX3板是否兼容2k和4k分辨率的視頻數(shù)據(jù)流?
ADSD3500飛行時間深度成像信號處理器技術(shù)手冊
飛行時間質(zhì)譜儀數(shù)據(jù)讀出解決方案

如何在輸入電壓范圍確定的情況下最大的使用AD的分辨率?
重磅新品 | 美芯晟發(fā)布全集成直接飛行時間(dToF)傳感器MT3801

如何提高透鏡成像的分辨率
請問TVP5158分辨率D1與HalfD1是如何轉(zhuǎn)換的?
請問ISO7720的時間分辨率有多少?
HDMI接口支持哪些視頻分辨率
視頻處理器的分辨率是如何管理的

艾邁斯歐司朗發(fā)布新一代單區(qū)直接飛行時間(dToF)傳感器TMF8806
視頻超分技術(shù)是指什么?

Arm精銳超級分辨率技術(shù)解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論