 人工智能中的處理器如何選擇
人工智能中的處理器如何選擇

Q應對 AI 發展帶來的計算挑戰,什么樣的處理器才是最佳選擇?
為長期運行的計算密集型 AI 訓練和大規模 AI 推理選擇合適的 CPU 或 GPU,本質上是要為您的應用選擇適宜的計算解決方案。相比傳統 x86 處理器成本高、能耗大,最新的 Ampere 云原生處理器助力打造高能效、高性能的 AI 推理應用,是其理想的替代方案,同時也是用于 AI 訓練和大語言模型(LLM)推理 GPU 的高性價比之選。
從 20 世紀 50 年代的首個實例,到如今更為復雜的機器學習、深度學習,甚至是生成式 AI 技術,高性能計算的需求始終是驅動 AI 計算發展的引擎,但模型的研究和訓練往往需要投入高昂的成本。
目前,AI 技術已進入廣泛應用的階段,也出現了為 AI 推理超額配置計算的情況,這導致了高昂的成本支出(無論是硬件的單位成本,還是硬件運行的電力成本)。因此,為不同類型的 AI 工作負載采用 GPU-Only 虛擬機的做法,正在被能夠大幅降低 AI 計算能耗的其他方案所替代。
與傳統計算相比,運行 AI 需要更高的能耗。Bloomberg 對此進行了詳細介紹:ChatGPT3 的參數量達到 1,750 億,消耗了高達 1.287 千兆瓦時電量,相當于120 戶美國家庭一年的耗電量。而類似 ChatGPT4 這樣的新模型(預計參數量達到 1.7 萬億),將比 ChatGPT3 消耗更高的電量。
由于 AI 帶來的能耗需求飆升,配置適度算力并減少所需的計算量是行業迫在眉睫的需求。云原生計算可助力降低運行成本,為配置硬件層面的適度算力奠定基礎,滿足當前和未來的計算需求,并降低能耗。
配置適度算力,滿足計算和效率需求
云原生處理器是 CPU 架構的一項創新,是 AI 推理切實可靠的新選擇,可替代高成本、高能耗的傳統 x86 處理器。為 AI 應用程序配置適度算力,意味著您可以決定使用 CPU-Only,或是將云原生處理器的能效、可擴展性和計算性能與 GPU 的并行計算能力相結合。
如您希望擁有價值及能效更高的 AI 解決方案,告別傳統方案導致的高成本和高能耗,可遵循以下 3 項簡單準則:
保持靈活性,滿足未來的計算需求
僅部署可滿足應用程序性能需求的計算量,并盡可能多地使用通用處理器,而非專用處理器。此舉有助于保持靈活性,以便滿足未來的計算需求。
將 CPU-Only 的 AI 推理
從傳統 x86 處理器轉移至云原生處理器
相比傳統的 x86 處理器,您可以借助 Ampere 云原生處理器帶來的性能增益,在 CPU-Only 的情況下部署更廣泛的 AI 工作負載。
GPU 與高能效的云原生處理器相結合
將 GPU 與高能效的云原生處理器相結合,以處理任務更繁重的 AI 訓練或 LLM 推理工作負載。
若您想了解關于 Ampere 云原生處理器能效的更多精彩內容,請參閱指南:《云原生處理器助力數據中心效率勁升三倍》
僅部署您所需的計算量
在 AI 技術發展的研究和訓練階段,GPU 是所有 AI 應用(包括建模和推理)的首選處理器。雖然 GPU 推動了 AI 的發展,但對于許多 AI 應用而言,GPU 提供的算力已經過剩,尤其是針對離線(batch)推理或批量推理而言。
離線推理(Batch Inference)應用是算力要求較低的工作負載,不需要 GPU 的處理能力:為此而購買 GPU,猶如為了 5 公里的上班路程購置豪華跑車——這顯然是大材小用。當把同樣昂貴的 GPU 硬件分別用于運行大型和小型模型時,小模型可能僅用了 GPU 能力的一小部分。在這些情況下,CPU 可以代替 GPU,幫助您節省能耗、空間和成本。
在處理離線推理時,那些遵循默認做法而采用 GPU 方案的客戶,至少錯過了兩種更合適的優化方案。
方案一
將 GPU 替換成適用于 AI 推理的高性能云原生處理器。
適用于 AI 推理的高性能云原生處理器。
方案二
將 GPU 與云原生處理器進行結合,以實現更高效的 LLM 推理和訓練工作。
這正是我們所定義的"適度算力"。
以下模型呈現了如何為 AI 應用程序配置適度算力,同時也對比了性能、計算需求與所需功耗。根據模型,CPU-Only 解決方案是純 AI 推理計算的優選項,而需要更高性能的應用程序,可以在 CPU 和 GPU 的組合上運行。
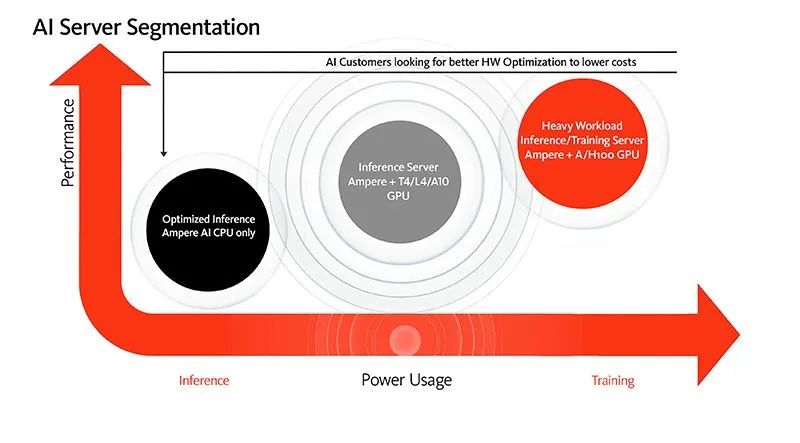
當然,CPU 的選擇也決定著您將付出的能耗以及獲得的每瓦性能。而云原生處理器的性能優勢和 Ampere 優化的 AI 軟件,讓 CPU 成為運行 AI 推理工作負載的理想之選。
將 AI 推理全部遷移至云原生處理器
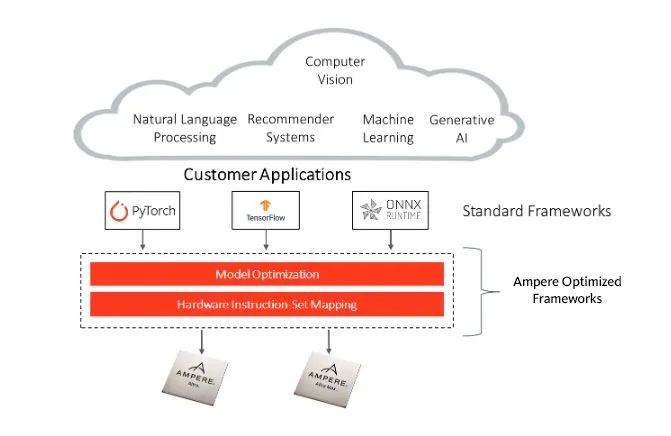
歡迎加入云原生社區,這里匯聚了眾多開發和設計人員。他們發現僅使用 Ampere 云原生處理器,也能夠實現高效的 AI 推理。Ampere 優化的 AI 框架支持所有在最流行 AI 框架中開發的模型,包括 PyTorch、TensorFlow 和 ONNX Runtime,這種豐富的集成提供了無縫的體驗,且無需修改 API 或進行額外的模型編碼。
Ampere 優化的 AI 框架
相比傳統的 x86 處理器,Ampere Altra 系列云原生處理器在 AI 推理方面擁有顯著的性能優勢,包括:
針對計算機視覺工作負載,性能最高可提升 4 倍*。
針對常見的NLP 工作負載,每瓦性能最高可提升 3 倍*。
Ampere AI 優化軟件可提供更高效的 AI 推理。基于 Ampere 處理器的 AI 和 ML 推理工作負載,可通過 Ampere AI 解決方案的軟件框架進行優化。通過使用 Ampere AI 解決方案,基于 CPU 的推理工作負載能夠獲得在成本、性能、可擴展性和能效等方面的優勢,同時用戶能夠使用常見的標準 AI 框架進行編程。這套框架易于使用,無需轉換代碼,并且免費。
借助 fp16 數據格式的獨特支持,Ampere Altra 系列處理器可實現最佳的推理性能——與 fp32 數據格式相比,fp16 數據格式可提供高達 2 倍的額外*加速,并且精度損失微乎其微。
將 GPU 與高能效 CPU 結合,
開展 AI 訓練和推理
在需要使用 GPU 的 AI 應用中,繁重的 AI 工作負載由 GPU 處理,而 CPU 則需要充當系統主機。在這樣的應用中,因為 GPU 決定了系統性能,所以無論使用哪種 CPU,它們的性能始終相同。
CPU 之間的區別在于其整體效率。與傳統 x86 CPU 相比,云原生處理器將為您帶來高能效,幫助顯著降低系統的總體能耗*,并提供同等的性能。
采用云原生處理器,每臺服務器可以節省數百瓦電力,這足以讓您在每個機架上再增加一臺服務器。雖然看似收益頗微,但實際上通過每機架增加一臺服務器,整個數據中心的計算密度將大幅提升。此外,在服務器層面節省能耗還可以減少對冷卻系統的依賴,從而節省更多成本,并進一步降低能耗。
云原生處理器與 GPU 相結合,有助于實現目標性能,并降低能耗和總體成本。
未來的 AI:強大、高效、開放
隨著 AI 加速涌入我們的生活和工作,我們需要克服的最關鍵障礙,是如何降低 AI 大規模應用的成本,而適度算力以及模型優化能夠帶來規模效率。
為計算配置適度算力,不僅需要確保硬件解決方案能滿足當前的計算需求,還需要能夠支持應用程序擴展,并經得起未來的算力需求考驗。Ampere 云原生處理器為您提供廣泛的選擇,既能滿足您當前的需求,同時具備靈活性,可輕松滿足您未來的需求。無論您是選擇 CPU-Only 的方案,還是 GPU 與 CPU 相結合的解決方案,云原生架構都擁有性能和效率優勢,契合您當前和未來的計算需求。
為云計算而生,Ampere 云原生處理器為行業提供可預測的卓越性能、平臺可擴展性和空前的能效。
歡迎您與我們的專業銷售團隊洽談合作,獲取更多信息,或通過我們的開發者體驗計劃試用 Ampere System。
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19852瀏覽量
234183 -
cpu
+關注
關注
68文章
11063瀏覽量
216479 -
AI
+關注
關注
88文章
34779瀏覽量
277067 -
人工智能
+關注
關注
1805文章
48899瀏覽量
247941 -
ChatGPT
+關注
關注
29文章
1589瀏覽量
8955
原文標題:創芯課堂|用于人工智能(AI)的最佳處理器怎么選?
文章出處:【微信號:AmpereComputing,微信公眾號:安晟培半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論