 大模型外掛知識庫優化-大模型輔助向量召回
大模型外掛知識庫優化-大模型輔助向量召回
寫在前面
大模型時代,通常采用向量召回的方式從文檔庫里召回和用戶問題相關的文檔片段,輸入到LLM中來增強模型回答質量。
但是很多時候,用戶的問題是十分口語化的,描述的也比較模糊,這樣會影響向量召回的質量,進而影響模型回答效果。今天給大家帶來一篇來自戰士金大佬(@知乎戰士金)的博文-大模型輔助向量召回。接下來分享兩篇通過大模型的能力增強召回效果的文章,這兩篇文章的內容都已經加入了langchain的標準組件,易用性還是比較好的,但是都有一些特定的使用場景。
Paper1:https://arxiv.org/abs/2212.10496
Paper2:https://arxiv.org/abs/2305.06983
知乎:https://zhuanlan.zhihu.com/p/653808554
HYDE
HYDE論文-Precise Zero-Shot Dense Retrieval without Relevance Labels,文章中強調了該文章主要適用于Zero-Shot場景。Zero-Shot指的是模型沒有見過某個場景(或者某個數據集)的數據,就應用于該場景,和用數據訓練模型以及在語言模型上下文中加入示例相對應。Zero-Shot體現了模型的遷移能力,我猜大部分同學都是在zero shot場景上使用向量化模型的,比如從網上下載個向量化模型權重,直接在自己的業務場景上用。其實,如果自己的業務場景有數據,微調一下向量化模型,在對應業務場景下召回率能提升不少。
既然論文題目強調了zero-shot,論文看的比較多的同學一定能馬上反應過來,是不是在非zero shot(比如微調向量化模型)的場景下這方法效果就很一般呢?文章作者也給出了實驗結果,該方法在結合微調過的向量化模型時,效果就沒那么好了,非常依賴打輔助的LLM的能力。如果您有微調向量化模型的能力,這部分就可以跳過了。再強調一下,這篇文章是篇純討論召回的文章,最后的衡量指標也是nDCG和召回率這些指標,使用LLM單純是為了提高召回效果的。
langchain鏈接:https://python.langchain.com/docs/use_cases/question_answering/how_to/hyde
論文思路非常簡單:
- Step1:用LLM根據用戶query生成k個“假答案”。(大模型生成答案采用sample模式,保證生成的k個答案不一樣,不懂LLM生成答案原理的同學可以看我這篇文章。此時的回答內容很可能是存在知識性錯誤,因為如果能回答正確,那就不需要召回補充額外知識了對吧。不過不要緊,我們知識想通過大模型去理解用戶的問題,生成一些“看起來”還不錯的假答案)
- Step2:利用向量化模型,將生成的k的假答案和用戶的query變成向量。
- Step3:根據如下公式,將k+1個向量取平均:其中dk為第k個生成的答案,q為用戶問題,f為向量化操作。
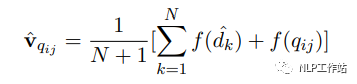
- Step4:利用融合向量v從文檔庫中召回答案。融合向量中既有用戶問題的信息,也有想要答案的模式信息,可以增強召回效果。
接下來我們從論文中挑一個比較重要的實驗結果進行討論。測試集為TREC DL19/20數據集,向量化模型使用的是Contriever模型,原始的該模型并未在TREC DL19/20數據集上訓練過。模型有上標FT指的是向量化模型在TREC DL相關的數據集上微調過的。黃框標出來的是未使用hyde技術的baseline結果。綠框標出來的是未微調的向量化模型使用hyde技術的實驗結果。紅框標出來的是微調過的向量化模型使用hyde技術的實驗結果。
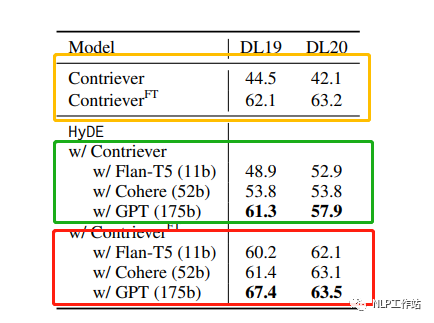
實驗指標為NDCG@10,可以發現,對于沒有微調過的向量戶化模型(zero shot場景),hyde還是非常有用的,并且隨著使用的LLM模型的增大,效果不斷變好(因為LLM的回答質量提高了)。非常有意思的一點是是對于微調過的向量化模型,如果使用比較小的LLM生成假答案(小于52B參數量),hdye技術甚至會帶來負面影響。
因為領域微調過的向量化模型性能已經不錯了,NDCG@10指標能達到60多,LLM生成的假答案的知識性錯誤帶來的負面影響大于回答模式信息帶來的正面影響。所以向量化模型模型還是能微調就微調吧。
FLARE
和上一篇文章相比,FLARE論文比較新一點,評估的指標是直接看最后LLM的回答效果的,而非是向第一篇文章那樣只討論召回準確率。這篇文章涉及到針對同一個問題的多次召回,因此比較適合長文本回答。如果您所面對的場景大部分問題用一兩句話就能回答,那收益就不是太大了。
langchain鏈接:https://python.langchain.com/docs/use_cases/question_answering/how_to/flare
對于大模型外掛知識庫,大家通常的做法是根據用戶query一次召回文檔片段,讓模型生成答案。只進行一次文檔召回在長文本生成的場景下效果往往不好,生成的文本過長,更有可能擴展出和query相關性較弱的內容,如果模型沒有這部分知識,容易產生模型幻覺問題。一種解決思路是隨著文本生成,多次從向量庫中召回內容。
有三種常用的多次召回策略:
- a. 每生成固定的n個token就召回一次。
- b. 每生成一個完整的句子就召回一次。
- c. 將用戶query一步步分解為子問題,需要解答當前子問題時候,就召回一次。
已有的多次召回方案比較被動,召回文檔的目的是為了得到模型不知道的信息,a、b策略并不能保證不需要召回的時候不召回,需要召回的時候觸發召回。c.方案需要設計特定的prompt工程,限制了其通用性。作者在本文里提出了兩種更主動的多次召回策略,讓模型自己決定啥時候觸發召回操作。
策略1
通過設計prompt以及提供示例的方式,讓模型知道當遇到需要查詢知識的時候,提出問題,并按照格式輸出,和toolformer的模式類似。提出問題的格式為[Serch(“模型自動提出的問題”)](稱其為主動召回標識)。利用模型生成的問題去召回答案。召回出答案后,將答案放到用戶query的前邊,然后去掉主動召回標識之后,繼續生成。當下一次生成主動召回標識之后,將上一次召回出來的內容從prompt中去掉。下圖展示了生成拜登相關答案時,觸發多次召回的例子,分別面對拜登在哪上學和獲得了什么學位的知識點上進行了主動召回標識的生成。

該方法也存在一些缺陷:
- 1.LLM不愿意生成主動召回標識。解決方法:對"["對應的logit乘2,增加生成"["的概率,"["為主動召回標識的第一個字,進而促進主動召回標識的生成。
- 2.過于頻繁的主動召回可能會影響生成質量。解決方法:在剛生成一次主動召回標識、得到召回后的文檔、去掉主動召回標識之后,接下來生成的幾個token禁止生成"["。
- 3.不微調該方案不太可靠,很難通過few shot的方式讓模型生成這種輸出模式。
策略2
策略1存在的第3點缺陷比較知名。因此作者提出了另外一個策略。該策略基于一個假設:模型生成的詞對應該的概率能夠表現生成內容的置信度。(傳統的chatgpt接口是用不了策略2的,因為得不到生成每個詞的概率。)
分為4個步驟:
- Step0:根據用戶的query,進行第一次召回,讓模型生成答案。
- Step1:之后,每生成64個token,用NLTK工具包從64個token里邊找到第一個完整句子,當作“假答案”,扔掉多余的token。(和第一篇文章思想一樣,利用LLM生成符合回答模式的“假答案”)
- Step2:如果“假答案”里有任意一個token對應的概率,低于某一閾值,那么就利用這個句子進行向量召回。觸發召回的“假答案”很可能包含事實性錯誤,降低召回準確率。設計了兩種方法解決這個問題。方法1:將“假答案”中生成概率低于某一閾值的token扔掉(低概率的token很有可能存在錯誤信息),然后再進行向量召回。方法2:利用大模型能力,對“假答案”中置信度低的內容進行提問,生成一個問題,用生成的問題進行向量召回。
- Step3:利用召回出來的文本,重新生成新的“真答案”,然后進行下一個句子的生成。
依然針對拜登的問題,下圖給出了例子。

接下來介紹一下實驗結果。先聲明一下,這篇文章用的召回器(向量化模型)是BM25,2009年被提出,基于統計學的原理,屬于一種詞袋模型,效果一般。筆者認為,如果用一些效果更好的基于神經網絡的召回器,本文提出的方法提升就沒那么大了。
召回器榜單:
中文:https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB
英文:MTEB Leaderboard - a Hugging Face Space by mteb
多次召回方案在更加開放的任務類型上提升比較小。如果是召回并回答一些模型不知道的垂類知識,FLARE效果提升應該是還不錯的。
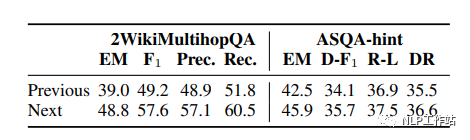
作者證明了用生成”假答案“進行召回(Next)效果比用前一句進行召回效果更好(印證了HYDE觀點)。
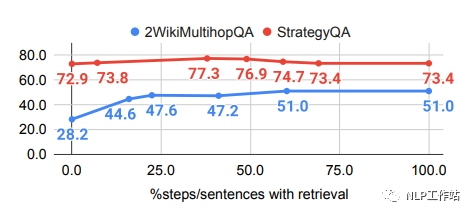
當一個句子里生成的所有單詞的概率都大于一個閾值t時,才不觸發召回文檔。當t=0%時,不觸發召回文檔;t=100%時,每次都觸發召回。下圖展示了不同的t的情況下LLM回答效果。可以發現t過大或者過小都不是最好的。總體上來看t=50%比較好。
總結
分享的這兩篇文章都需要多次調用LLM,來增強召回,雖然在一些場景下比較有效,不過開銷感覺有點太大了。其實最簡單有效的提高召回效果的方式就是在自己業務的數據集上微調一下向量化模型。
-
向量
+關注
關注
0文章
55瀏覽量
11853 -
數據集
+關注
關注
4文章
1223瀏覽量
25278 -
大模型
+關注
關注
2文章
3029瀏覽量
3830
原文標題:大模型外掛知識庫優化-大模型輔助向量召回
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于訓練階段使用知識庫+KNN檢索相關信息輔助學習方法
【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
領域知識庫的研究與設計
本體知識庫的模塊與保守擴充
介紹幾篇EMNLP'22的語言模型訓練方法優化工作
借助亞馬遜云科技大語言模型等多種服務打造下一代企業知識庫
如何基于亞馬遜云科技LLM相關工具打造知識庫
如何手擼一個自有知識庫的RAG系統
用騰訊ima和Deepseek建立個人微信知識庫






 工商網監
工商網監
評論