 PCIe相關問題解答
PCIe相關問題解答

PCIe設備的數據流有哪些,分別是什么場景?
PCIe設備的數據流主要為4大類:
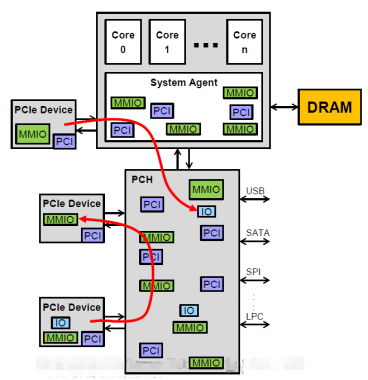
1.CPU發起的,訪問PCIe設備配置空間的數據流。這種數據流主要是BIOS/Linux PCIedriver 對設備進行初始化、資源分配時,讀寫配置空間的。包括PCIe 枚舉,BAR空間分配, MSI 分配等。 設備驅動通過 pci_wirte_config() / pci_read_config() 發起配置空間訪問。 lspci /setpci 也是對應到配置空間訪問。
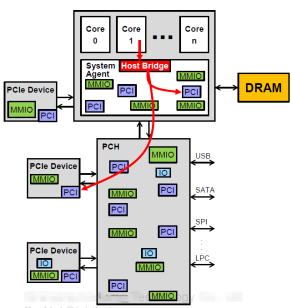
2.CPU發起的,訪問PCIe設備MMIO/IO的數據流。將Bar空間mmap 到系統地址空間后,設備驅動可通過地址訪問PCIe設備的 Bar/ MMIO 空間。 一般的,設備會將特定的寄存器和存儲實現在MMIO空間內。CPU可使用 iowrite32() / ioread32() 等方式訪問 MMIO空間。這是一種效率較低的PCIe使用方式.
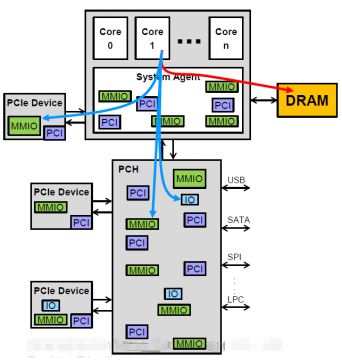
3.PCIe設備發起的,訪問 HostMemory 的 DMA數據流。這種數據流由PCIe設備的DMAEngine 發起,是一種常見的、高性能的PCIe數據流。CPU通過配置 PCIe設備內的DMAEngine (通過MMIO寄存器),啟動設備PCIeDMA。網卡,GPU等PCIe設備,數據通路均有PCIeDMA完成。
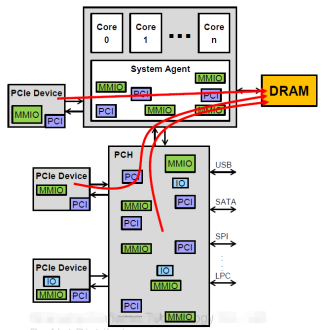
4.PCIe設備發起的,訪問PCIe設備MMIO/IO的數據流, 亦稱P2P (Peer to Peer)。同(3)類似,也是利用PCIe設備的DMAengine, 但是數據訪問的是其他PCIe設備的MMIO地址空間而非HostMemory. CPU須配置橋片端口路由地址。 GDR (GPU directRDMA) 就是利用這種數據流,避免主機內存的數據拷貝。
CPU訪問設備內存(Bar空間)和訪問主機內存,有什么不同?
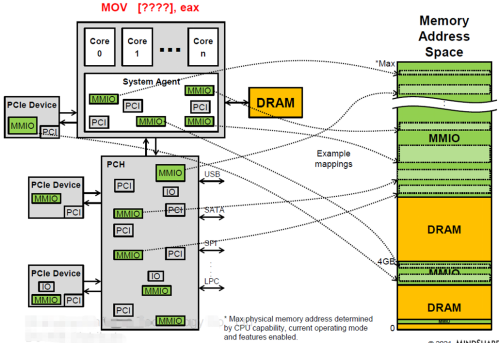
Prefetchable MMIO 映射到系統地址空間后,軟件可以通過地址對PCIeMMIO空間進行直接訪問(CPU使用MOV指令),這一點與系統內存訪問在操作上是一致的。
RootComplex 會根據CPU訪問的地址決定數據訪問路由,對于系統內存地址空間,數據會被路由到iMC(integrated Memory Controller) 訪問DDR;對于MMIO地址空間,數據會被路由到HostBridge 轉換為 TLP發起對設備的PCIe通信。
一般的,HostMemory 分配都是Cacheable(writeback) 的,而 MMIO通常是Uncacheable的,加之兩者帶寬和通信機理的不同,導致了CPU使用地址直接訪問PCIeMMIO空間無法達到訪問系統內存的性能,也無法用滿PCIe帶寬。使用memcpy() 在HostMemory 和MMIO 地址拷貝數據也是一種低效方式。
對于連續的MMIO空間訪問,可以通過支持writecombine的方式( mmap_wc() )來提升性能。
為什么需要使用PCIe DMA,在設備與主機間搬運數據?
PCIe DMA 能夠實現高性能的數據搬運。
1.CPU僅需要配置DMAEngine, 大塊的數據搬運過程無需CPU參與,CPU占用率低;
2.DMAEngine 是全硬件化的通信方式,TLPpayload 大overhead小,PCIe鏈路使用率高;
3.支持descriptor的DMA能夠實現用戶態數據的零拷貝,減小內存帶寬消耗;
4.支持多隊列的DMA,能夠提高系統并行度,支持多核,多進程應用,硬件解決IO搶占和調度問題,軟件編程簡單;
如何使用PCIe設備的中斷?
PCIe協議定義了三種中斷:INTx (legacy), MSI, MSIX
1.INTx中斷是相對古老的PCIe設備中斷方式,整個系統僅支持8個INTx 中斷,所有設備共用。PCIe中的INTx 中斷是通過PCIemessage發送到 switch和 IOAPIC的。CPU收到 IOAPIC轉發到 localAPIC 的 INTx 中斷后,需要查詢ISR確定中斷源設備,并進一步查詢中斷含義,才能執行中斷處理函數。中斷數量少,中斷查詢復雜,響應延遲大,與數據流不保序等問題的存在,是INTx的主要缺陷。
2.MSI是實現在配置空間的消息中斷,每個PCIefunction可支持最多32個MSI中斷。MSI中斷是一筆PCIe寫報文,向APIC地址域寫入特定的數據,觸發CPU中斷。因為其通過PCIewriteTLP 實現,中斷與業務數據的保序性容易實現,硬件處理RacingCondition的代價更小。MSI中斷可以具備特定的含義,設備之間不耦合,中斷響應快。
3.MSIx是實現在Bar空間的消息中斷,優點與MSI類似,但其數量支持更多,每個function最多可以支持2K條中斷向量。
MSI和MSIx 是目前主流的中斷實現方式,在虛擬化的場景下,中斷可以通過IOMMU 實現remap和 posting, 進一步提升系統性能。
網卡接收方向性能低,進行調優有哪些思路?
網卡收包性能性能調優,需先識別出性能瓶頸,可通過performance監控工具(如IntelPCM),查看 CPU利用率,內存帶寬使用,PCIe流量等。
一般的,優化方向包括:
1.確定NUMA的親和性,保證CPU/Memory/PCIe 三者的親和性
2.確定PCIe全鏈路的帶寬匹配,確保內存帶寬(讀+寫雙向)有余量
4.查看并打開IDO/RO (需注意應用場景無保序風險)
5.DMAEngine 參數的調優,Batch操作的閾值配置(隊列doorbell, completion notify等)
6.中斷頻率的調優和控制(一般在20K/100k 每秒,需結合應用和CPU)
7.DDIO和 cacheable /uncacheable 內存空間的分配
具體原理和操作可參考課程中的有關介紹。
審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
11063瀏覽量
216478 -
Linux
+關注
關注
87文章
11496瀏覽量
213240 -
PCIe
+關注
關注
16文章
1331瀏覽量
84901 -
dma
+關注
關注
3文章
576瀏覽量
102869 -
數據流
+關注
關注
0文章
123瀏覽量
14770
原文標題:PCIe 課程典型問題解答
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監
評論