 用STM32Cube.AI部署ONNX模型實操示例:風扇堵塞檢測
用STM32Cube.AI部署ONNX模型實操示例:風扇堵塞檢測
在之前的文章中,我們介紹了沒有AI基礎知識的工程師如何使用NanoEdge AI快速訓練一個用于風扇異常檢測的模型
該模型根據來自電機控制板的電流信號,檢測風扇過濾單元的堵塞百分比。我們知道,當風扇發生堵塞時,電機的電流信號形狀會與正常時不同,而傳統算法很難有效地處理這種差異。因此,機器學習算法成為解決該問題的明智選擇。對于機器學習算法,我們通常使用scikit-learn庫來訓練模型。今天我們將展示如何自行訓練機器學習模型,然后使用STM32Cube.AI 將其部署到同一設備上,以便讓大家充分了解兩種工具的不同之處。

NanoEdgeAI是一款端到端工具,允許對數據進行一些預處理,并進行訓練和算法選擇,而STM32Cube.AI 則需要工程師具備一定的AI建模經驗,因為STM32Cube.AI 暫不支持模型訓練。
硬件和軟件準備

用于驅動風扇的P-NUCLEO-IHM03電機控制套件包括一塊NUCLEO-G431RB主板、一塊電機控制擴展板,以及一臺無刷電機。
在軟件準備方面,您需要配置anaconda環境,并安裝sklearn、pandas、ONNX等必要的庫。
讓我們回顧一下創建AI項目的一些關鍵步驟,然后據此逐步演示如何基于STM32Cube.AI 從零開始創建AI項目。
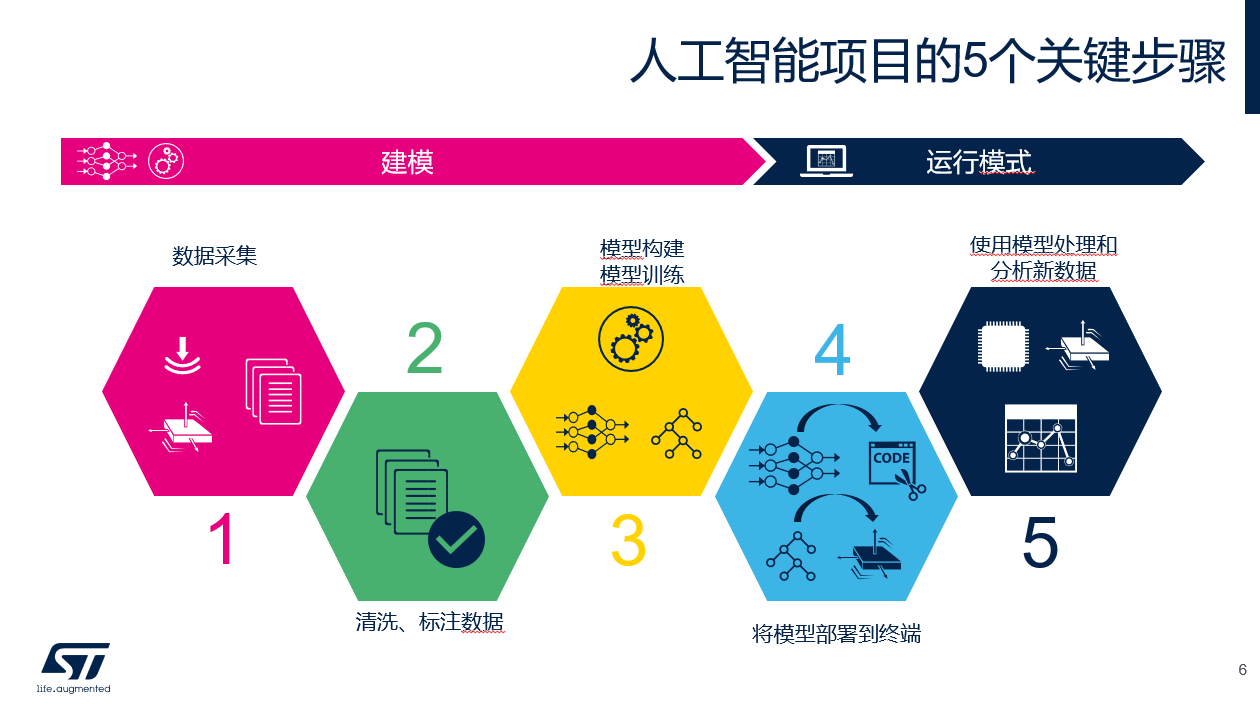
在步驟1中,用戶需要收集用于機器學習模型創建的數據。該數據集的一部分(訓練數據集)將用于訓練模型,另一部分(測試數據集)稍后將用于評估所構建模型的性能。機器學習的數據集中的典型比率為:訓練數據集占80%,測試數據集占20%。我們此次試驗用的數據集與之前NanoedgeAI訓練模型使用的數據是一樣的。
在步驟2中,用戶需要對數據進行標記;基本上,我們需要告訴機器收集的數據屬于哪一類(例如“跑步”、“散步”、“靜止”……) 分類指的是根據您認為重要的屬性對數據進行分組:這種屬性在機器學習領域被稱為“類”。
接下來,在步驟3中,用戶使用預先準備的數據集訓練機器學習模型。該任務也稱為“擬合”。訓練結果的準確性在很大程度上取決于用于訓練的數據的內容和數量。
在步驟4中,用戶將訓練過的機器學習模型嵌入到系統中。對于在計算機上執行的機器學習,用戶可以利用Python庫直接執行模型。對于在MCU等器件上運行的機器學習,用戶可以在執行之前將該庫轉換為C代碼。
最后在步驟5中,用戶驗證機器學習模型。如果驗證結果與預期的結果不匹配,則用戶必須確定上述步驟中需要改進的部分,以及如何改進。比如增加數據,更改模型,調整模型超參數等。
至此,我們已經幫大家重新梳理了一次AI項目的建模過程。接下來我們將按照這樣的過程完成我們今天的實驗。
首先,導入一些必要的庫
為了便于對比,我們使用了之前NanoEdgeAI訓練模型中使用的數據集。我們使用pandas從csv文件讀取數據,然后用于模型訓練。
在訓練之前,讓我們先來了解一下該數據集。讓我們打印出數據集的維度。

可以看到,該數據集一共有119條數據和128個特征,最后一列實際上是我們的數據標簽。
接下來,我們將數據集分為訓練集和測試集,訓練集用于訓練模型,測試集用于檢驗模型的泛化能力。我們將80%的數據用于訓練,20%的數據用于測試

一旦數據集準備就緒,我們就可以開始訓練模型。

訓練完成后,我們可以在測試集上驗證模型的性能。我們發現,該模型在測試集上可以達到約83%的準確率。

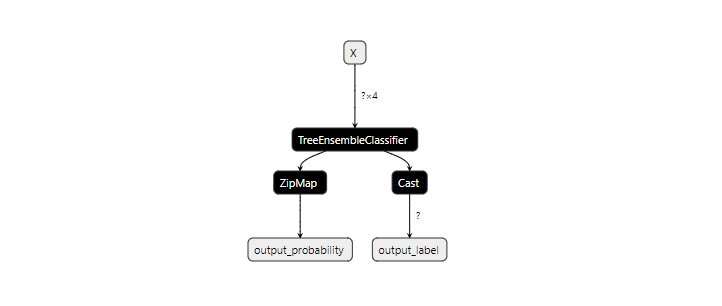
最后,我們保存經過訓練的模型,將得到一個ONNX格式的文件random_forest.onnx

我們使用netron查看模型的結構如下
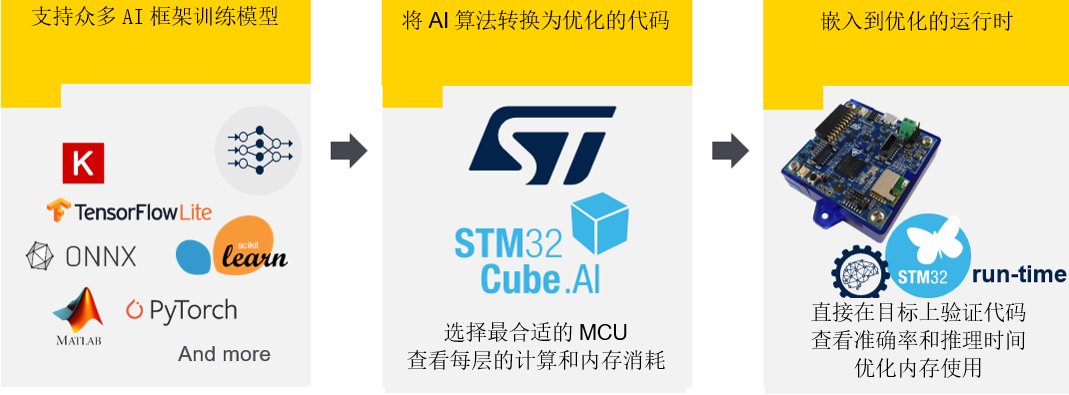
STM32Cube集成使得STM32Cube.AI 用戶能夠有效地在廣泛的STM32微控制器系列產品之間移植模型,并且(在相似型號適用于不同產品的情況下)在STM32產品之間輕松遷移。
該插件擴展了STM32CubeMX功能,可自動轉換訓練好的AI模型,生成的優化庫集成到用戶項目中,而不是人工構建代碼,并支持將深度學習解決方案嵌入到廣泛的STM32微控制器產品組合中,從而為每個產品添加新的智能化功能。
STM32Cube.AI 原生支持各種深度學習框架,如Keras、TensorFlow? Lite、ConvNetJs,并支持可導出為ONNX標準格式的所有框架,如PyTorch?、Microsoft? Cognitive Toolkit、MATLAB?等。
此外,STM32Cube.AI 支持來自廣泛ML開源庫Scikit-Learn的標準機器學習算法,如隨機森林、支持向量機(SVM)、K-Means。
現在,我們準備將模型部署到MCU。我們使用STM32Cube.AI 的命令行模式將模型轉換為經過優化的C代碼。我們運用以下命令執行模型轉換。
stm32ai generate -m random_forest.onnx
如果轉換成功,我們將看到以下消息。
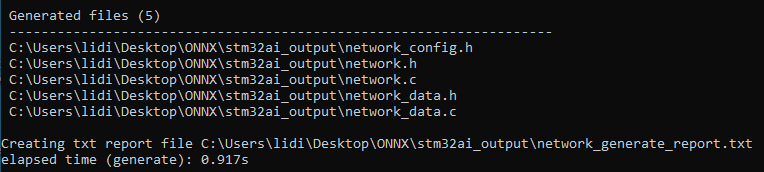
在stm32ai_output文件夾中,我們將看到有以下文件生成。其中,network.c/.h包含關于模型拓撲的一些信息,而network_data.c/.h則記錄了關于模型權重的一些信息。
此時,我們準備好將生成的模型集成到stm32項目中。在CLI模式下,我們需要手動添加STM32Cube.AI 的運行環境到項目,所以我們可以調用network.h中的函數來運行模型。
當然,STM32Cube.AI 提供一種更簡便的方式來集成AI模型。假設您的項目從一個ioc文件開始,我們可以將AI模型添加到cubeMX的代碼生成階段,然后一起生成代碼。
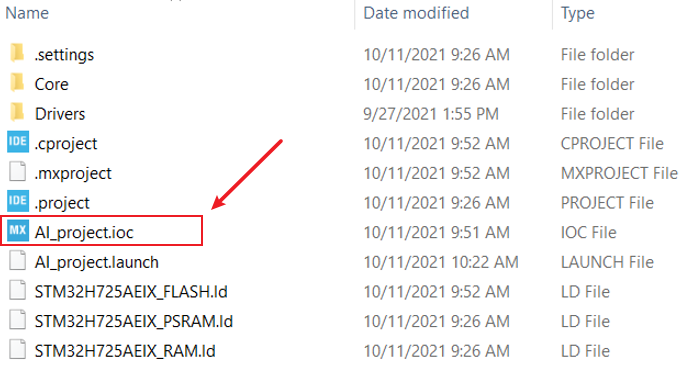
啟用cubeMX中的AI功能如下,選擇對應的STM32Cube.AI 的版本。
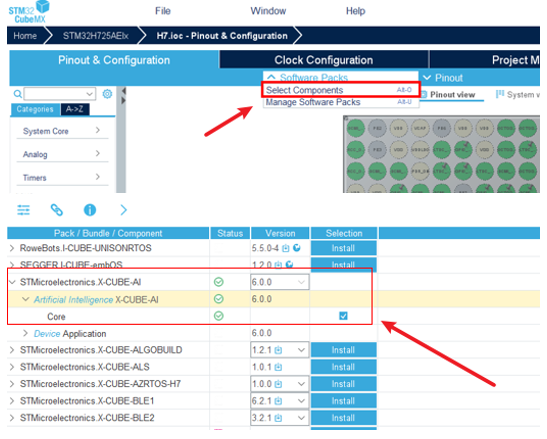
我們可借此將AI模型集成到項目中。
就這樣,在我們生成代碼后,AI模型轉化為優化的C代碼,然后與STM32Cube.AI 運行環境的對應版本一起集成到項目中。
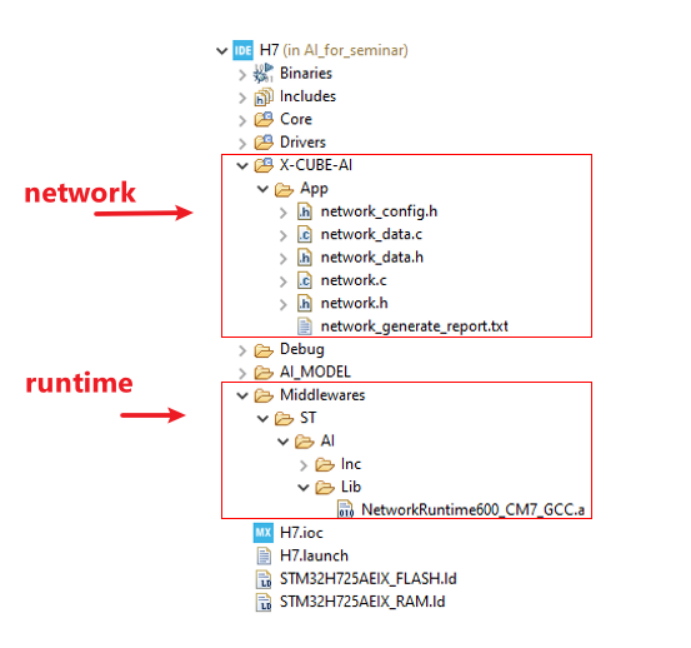
這樣,我們就可以調用network.h中的函數將模型運行起來。
最終,我們通過這種方式順利地將模型集成到了項目中。通過比較這兩種不同的方法,我們可以發現STM32Cube.AI 和NanoEdgeAI之間的差異。NanoEdgeAI更簡單、高效,而STM32Cube.AI 則更加靈活且可定制。
來源:意法半導體中國
審核編輯:湯梓紅
-
電機
+關注
關注
143文章
9265瀏覽量
148649 -
AI
+關注
關注
88文章
34588瀏覽量
276210 -
模型
+關注
關注
1文章
3500瀏覽量
50128
發布評論請先 登錄
意法半導體STM32Cube.AI生態系統加強對高效機器學習的支持

使用cube-AI分析模型時報錯的原因有哪些?
STM CUBE AI錯誤導入onnx模型報錯的原因?
如何在STM32f4系列開發板上部署STM32Cube.AI,
輕松實現一鍵部署AI模型至RT-Thread系統
X-CUBE-AI STM32Cube擴展包精選資料推薦
請問STM32WL可以與STM32Cube.AI一起使用嗎?
ST MCU邊緣AI開發者云 - STM32Cube.AI
STM32Cube.AI庫的高級特性

STM32Cube.AI將神經網絡轉換為STM32的優化代碼
如何基于STM32Cube.AI 從零開始創建AI項目
意法半導體發布STM32Cube.AI開發工具
STM32Cube.AI v7.3能夠在推理時間和RAM之間找到完美的平衡
如何在OpenMV生態系統中集成STM32Cube.AI生成的代碼






 工商網監
工商網監
評論