 基于NXP微控制器i.MX RT1170的多人體實時檢測算法和系統
基于NXP微控制器i.MX RT1170的多人體實時檢測算法和系統
恩智浦的i.MX RT系列跨界處理器,為在設備端實現智能運算提供了更高性價比的方案,解鎖了在嵌入式應用中部署人工智能算法的新途徑。
恩智浦的工程師們從多種角度,做了很多有創新的嘗試和工作,為客戶提供了豐富的選項,也很好地展示了i.MX RT產品的高性能和高擴展適應性。
本文及隨后的一些小文將分別介紹這些精彩的成果。

引 言
多目標檢測是機器學習重要的研究領域之一,可以廣泛應用于機器人,安防和工業監控等領域。
針對多目標檢測任務,目前比較流行的是基于卷積神經網絡(Conventional Neural Network,CNN)的算法,例如Yolo,SSD和RetinaNet等。
然而,目前已有CNN方法均不適用于嵌入式平臺的部署,這是因為目標檢測是一個比較繁重的任務,而現有的檢測模型過于復雜,對平臺的算力和內存的需求很高,因此無法將其部署在嵌入式平臺。
本文基于開源算法,提出了一種輕量化的目標檢測網絡,大量運用深度可分離卷積以及全新的尺度變換結構,使得模型計算復雜度和結構得到極大簡化,進而使多目標檢測在MCU上的實現成為可能。
提出的檢測算法在NXP微控制器i.MX RT1170上的部署實驗結果表明:該算法極大降低了對于ROM和RAM的消耗,運行時間得到大幅度優化,檢測速度最高可達10FPS,并且模型精度可以媲美開源的YoloV3-tiny,YoloV4-tiny等模型。
實時多人體檢測算法
1. 網絡結構設計
本文采用的網絡結構設計主要分為兩部分,第一部分為網絡主體結構,用來逐層提取樣本的有效特征。該主體結構借鑒了MobileNetV2的輕量特性,并充分考慮了模型在部署方面對于ROM和RAM的優化。
網絡主要特點概括如下:
(1)大量運用深度可分離卷積來減少參數量,進而減少ROM的消耗。深度可分離卷積相對于傳統的卷積可以大大較少參數規模。例如對于一個輸入有8個通道,輸出有16個通道的傳統3*3卷積, 其參數量為16*8*3*3=1152;而深度可分離卷積參數量僅有8*3*3+1*1*8*16=200。
(2)模型結構設計上遵循的是加大網絡模型深度,縮小每層的寬度,這樣帶來的好處是減少每層推理所需要的內存占用。這是因為在嵌入式設備中,運行內存極為緊張,而優化過的模型可以減少RAM的使用。
(3)考慮到模型部署需要用到8位整型量化,這里我們采用Relu激活函數。這是因為目前還沒有任何研究表明哪種激活函數具有更高的精度,但對于量化來說,顯然Relu會比pRelu(圖1),leakyRelu或者sigmoid等函數具有更快的推理時間和更低的量化損失。
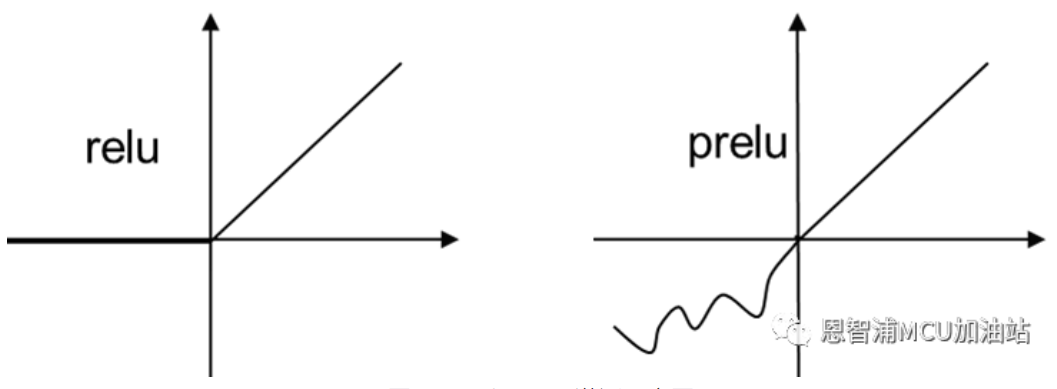 圖1 Relu和pRelu激活示意圖
圖1 Relu和pRelu激活示意圖
(4)網絡設計中尺度變換結構采用了1*1,3*3和5*5三種卷積核尺寸,進而同時兼顧不同大小目標的定位精度;同時,我們提出的尺度預測結構更為簡單,減少了網絡模型部署的難度。
2. 網絡模型融合壓縮與量化
對于訓練后的網絡模型,可以通過網絡模型的融合壓縮以及量化技術,加快其在嵌入式設備上的推理時間。
因為本文設計網絡中為了使每層數據分布更加均勻(有助于減少整型量化中的損失),采用了Batchnorm對數據進行約束。此外,Batchnorm還可以將輸入分布更多的分散在非飽和區,進而減小梯度彌散,加快收斂過程。模型訓練結束后,Batchnorm中參數就固化了,可以將其參數融合進卷積層中,最終避免Batchnorm層在實際模型推理中的時間消耗。
模型量化的目的是為了加快模型在MCU上的推理時間,這是因為大多數MCU內核采用Arm Cortex-M 架構,其對定點乘法運算的速度要比浮點運算快得多。此外,模型量化還可以節省模型對于ROM和RAM的需求。
本文采用全8位整型量化的方式對模型進行推理加速。
3. 實驗結果分析
本文提出的模型針對目前較為流行的開源公版模型YoloV3-Tiny和YoloV4-Tiny進行對比,實驗結果如下:
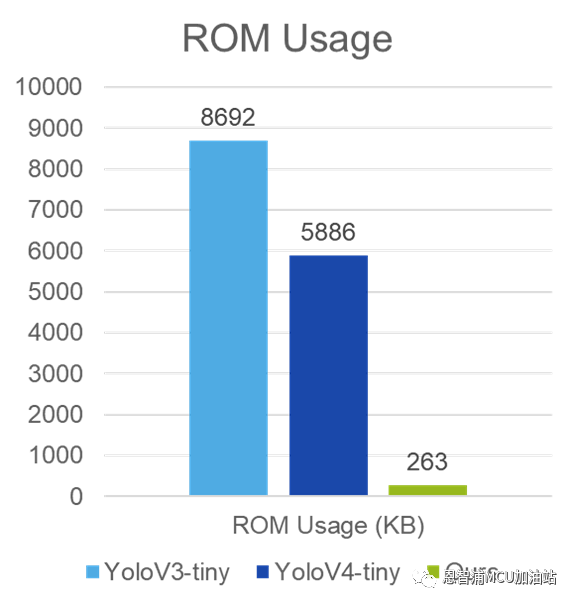
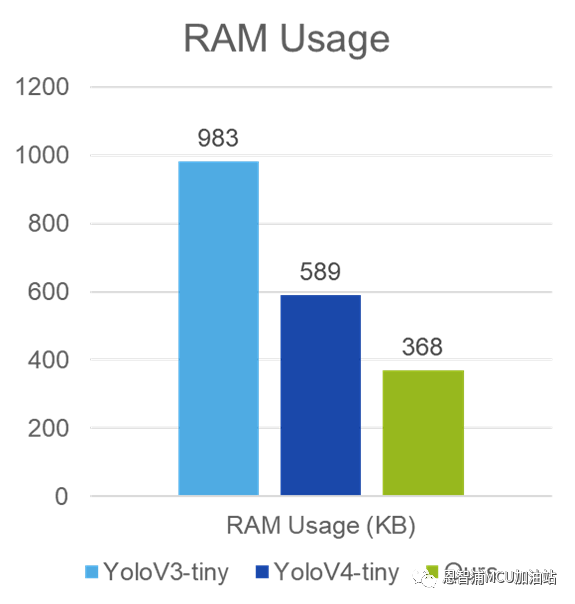
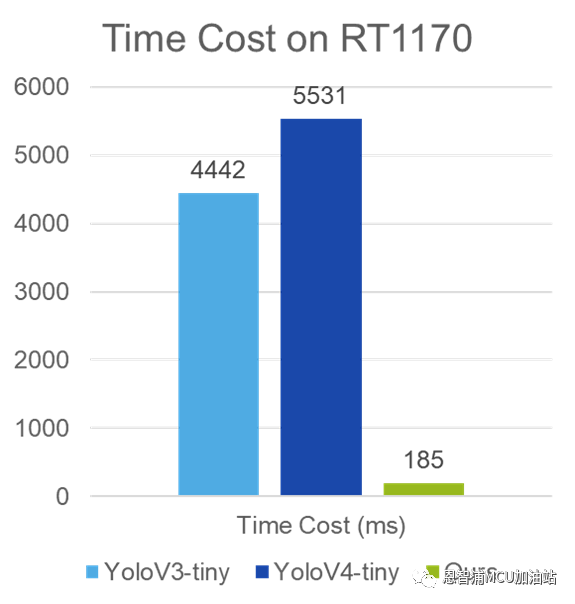 圖2 模型對比實驗圖
圖2 模型對比實驗圖
如圖2所示,該模型極大地降低了ROM和RAM的占用,這對于內存大小較為緊張的嵌入式設備來說意義重大。
而在推理時間上,本文提出的模型具有更為突出的優勢。作者在NXP微控制器i.MX RT1170(ARM Cortex-M7,1GHz)上的實驗結果表明,相比開源模型動輒幾秒鐘的推理時間,我們提出的網絡模型將時間消耗控制在200ms以內,使其部署在微控制器上更加高效。
注意,圖2中的時間消耗對比是假設YoloV3-Tiny和YoloV4-Tiny均進行8位整型量化,并且直接使用未經修改的開源算法得到的推理時間。實際上,直接使用開源的、未經修改的YoloV3-Tiny和YoloV4-Tiny等網絡結構,由于其復雜結構,部署難度較高。而本文提出網絡模型在結構上進行了極大優化,可以利用現有開源工具進行量化部署。
對于模型預測精度,作者進行了如圖3的測試對比實驗。在多個樣本集上,本文提出模型的預測精度可以媲美開源的YoloV3-Tiny和YoloV4-Tiny等模型。
 圖3 模型預測效果對比圖
圖3 模型預測效果對比圖
基于i.MX RT1170的實時多人體檢測系統
神經網絡模型在邊緣設備上的部署,是深度學習技術落地的一大關鍵部分。本文以多人體檢測模型為例,分享如何將現有的神經網絡模型,部署到NXP的微控制器i.MX RT1170EVK開發板上,并實現實時多人體檢測系統。
部署流程如圖4所示,首先需要將訓練的模型進行模型框架轉換,這是因為開源的量化工具僅支持少量的模型框架。
第二步需要對模型進行融合優化,然后利用量化工具將模型進行量化,并轉換為MCU可以執行的代碼;最后對模型的預處理和后處理進行編程實現,這樣攝像頭抓取的圖像數據就可以進行預處理后送入量化模型,然后根據模型輸出特征圖進行后處理,提取出有效的候選框作為預測框。
 圖4 神經網絡邊緣設備部署流程圖
圖4 神經網絡邊緣設備部署流程圖
本文采用NXP i.MX RT1170EVK開發板進行多人體檢測系統的實現。
i.MX RT1170是NXP的一款跨界MCU,采用主頻達1GHz的Cortex?-M7內核和主頻達400MHz的Cortex-M4,這里我們僅使用M7內核。
此外,RT1170EVK上搭載了MIPI接口的OV5640攝像頭,分辨率達到720*1280,同時配有5.5寸高清顯示屏,分辨率同樣達到720*1280。
這里我們采用FreeRTOS系統進行攝像頭的實時讀取和LCD的實時顯示,攝像頭和LCD的分辨率均設為最高的720*1280,刷新率均設為15FPS。
系統實現流程如圖5所示,攝像頭抓取的圖像經過PXP轉換,然后進行預處理送入模型,最后經過后處理將預測框顯示在LCD上。
 圖5 人體檢測系統實現流程
圖5 人體檢測系統實現流程
最終,基于i.MX RT1170的人體檢測系統可以實現快速精準的多人體位置預測,測試視頻如下。
此外,本文算法的一大優勢在于運行時間可控,并不會因為被檢測人體數量的多少而改變。模型的速度決定了最遠檢測距離。以下測試結果分別是算法在10FPS,5FPS和3FPS速度下的最遠檢測距離。

圖6 算法檢測距離與速度
結束語
本文給出的多人體檢測算法和系統,為在NXP的MCU上部署多目標檢測任務帶來了更多的可能性。
結合深度學習模型網絡的優化,以及模型融合量化等技術,可以在保證模型精度的同時,實現在嵌入式平臺上推理速度的最優化,進而才能將深度學習技術更好的落地。
來源: 恩智浦MCU加油站
免責聲明:本文為轉載文章,轉載此文目的在于傳遞更多信息,版權歸原作者所有。本文所用視頻、圖片、文字如涉及作品版權問題,請聯系小編進行處理
審核編輯 黃宇
-
微控制器
+關注
關注
48文章
7925瀏覽量
153864 -
NXP
+關注
關注
61文章
1336瀏覽量
187771 -
ROM
+關注
關注
4文章
578瀏覽量
87096 -
RAM
+關注
關注
8文章
1391瀏覽量
116961 -
算法
+關注
關注
23文章
4702瀏覽量
94938
發布評論請先 登錄
基于i.MX RT1170的兩輪車數字儀表盤參考設計 全面的技術解讀
i.MX RT1170的GPIO外設的使用
i.MX RT1170:VGLite移植RT-Thread Nano過程講解(下)
如何禁用i.MX RT1170 MCU中的M4內核?
是否可以將SPI接口顯示器與I.MX RT1170一起使用?
i.MX RT1170自定義引導加載程序,如何在i.MX RT處理器上完成?
恩智浦i.MX RT1170開創GHz MCU時代
恩智浦i.MX RT1170在將該系列帶上了更高的層面
i.MX RT開發筆記-08 | i.MX RT1062嵌套中斷向量控制器NVIC(按鍵中斷檢測)

來數數!這款i.MX RT1170智能廚房解決方案,用到了哪些NXP的黑科技?
I.MX RT1170配套PMIC PF5020使用方法
i.MX RT1170評估套件快速入門:這份保姆級教程,請收藏!

在i.MXRT1060和RT1170上使用高效神經網絡進行多人檢測
恩智浦i.MX RT1170 uSDHC eMMC啟動時間






 工商網監
工商網監
評論