 如何在無人機上部署YOLOv4物體檢測器
如何在無人機上部署YOLOv4物體檢測器
1
代碼編譯
準備工作
-
推薦使用Ubuntu 18.04
-
CUDA >= 10.0:https://developer.nvidia.com/cuda-toolkit-archive
-
OpenCV >= 2.4:https://opencv.org/releases.html
-
cuDNN >= 7.0 for CUDA >= 10.0https://developer.nvidia.com/rdp/cudnn-archive
-
GPU with CC >= 3.0:https://en.wikipedia.org/wiki/CUDA#GPUs_supported
-
GCC
Linux上編譯
下載YOLOv4源碼,推薦使用Ubuntu 18.04:
sudo apt-get install -y git
git clone https://github.com/AlexeyAB/darknet.git
配置
Makefile文件中的參數,然后運行make -j8進行編譯,具體參數解釋如下:
-
使用
uselib來運行YOLO,輸入指令如下:LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib test.mp4 -
在自己的代碼中嵌入YOLO,請參考例程:https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp
-
運行
LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov4.cfg yolov4.weights zed_camera
-
GPU=1使用CUDA和GPU(CUDA默認路徑為/usr/local/cuda) -
CUDNN=1使用cuDNN v5-v7加速網絡(cuDNN默認路徑/usr/local/cudnn) -
CUDNN_HALF=1使用Tensor Cores(可用GPU為Titan V / Tesla V100 / DGX-2或者更新的)檢測速度3x,訓練速度2x -
OPENCV=1使用OpenCV 4.x/3.x/2.4.x,運行檢測視頻和攝像機 -
DEBUG=1編譯調試版本 -
OPENMP=1使用OpenMP利用多CPU加速 -
LIBSO=1編譯darknet.so -
ZED_CAMERA=1增加ZED-3D相機的支持(需要先安裝好ZED SDK)
常見編譯問題
/bin/sh: 1: nvcc: not found
首先確保CUDA正確安裝,并且在路徑/usr/local/cuda下,然后輸入如下指令:
echo "PATH=/usr/local/cuda/bin:$PATH" >> ~/.bashrc
source ~/.bashrc
include/darknet.h10: fatal error: cudnn.h: No such file or directory
首先下載cuDNN,https://developer.nvidia.com/rdp/cudnn-archive,需要根據自己的CUDA版本選擇,然后解壓,輸入指令:
sudo cp -r cudnn-10.1-linux-x64-v7.6.5.32/cuda /usr/local/cudnn
2運行代碼
預訓練模型
所有模型都是在MS-COCO數據集上訓練,模型包括兩個文件(cfg和weights)
R表示在RTX 2070設備上的FPS,V表示在Tesla V100設備上的FPS
百度網盤打包下載,鏈接:https://pan.baidu.com/s/1QQPB27n18XeRDnhHA2Gxuw,提取碼:uill
-
width=608 height=608:65.7 AP@0.5 | 43.5 AP@0.5:0.95 - 34(R) FPS / 62(V) FPS- 128.5 BFlops -
width=512 height=512:64.9 AP@0.5 | 43.0 AP@0.5:0.95 - 45(R) FPS / 83(V) FPS- 91.1 BFlops -
width=416 height=416:62.8 AP@0.5 | 41.2 AP@0.5:0.95 - 55(R) FPS / 96(V) FPS- 60.1 BFlops -
width=320 height=320:60.0 AP@0.5 | 38.0 AP@0.5:0.95 - 63(R) FPS / 123(V) FPS- 35.5 BFlops
-
width=416 height=416:33.1 AP@0.5 - 370(R) FPS- 3.5 BFlops
-
width=416 height=416:45.5 AP@0.5 - 55(R) FPS- 3.7 BFlops
-
width=608 height=608:65.4 AP@0.5 | 43.2 AP@0.5:0.95 - 32(R) FPS- 100.5 BFlops
-
width=608 height=608:60.6 AP@0.5 - 38(R) FPS- 141.5 BFlops
-
width=416 height=416:55.3 AP@0.5 - 66(R) FPS- 65.9 BFlops
-
width=416 height=416:33.1 AP@0.5 - 345(R) FPS- 5.6 BFlops
-
yolov4.cfg- 245 MB:yolov4.weights
-
yolov3-tiny-prn.cfg- 18.8 MB:yolov3-tiny-prn.weights
-
enet-coco.cfg (EfficientNetB0-Yolov3)- 18.3 MB:enetb0-coco_final.weights
-
csresnext50-panet-spp-original-optimal.cfg- 217 MB:csresnext50-panet-spp-original-optimal_final.weights
-
yolov3-spp.cfg- 240 MB:yolov3-spp.weights
-
yolov3.cfg- 236 MB:yolov3.weights
-
yolov3-tiny.cfg- 33.7 MB:yolov3-tiny.weights
可以在如下路徑找到所有的cfg文件:darknet/cfg/
運行指令介紹
需要將訓練好的weights文件放到darknet根目錄下,運行如下指令:
-
檢測單張圖像
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25
-
檢測給定路徑的單張圖像(參數最后的路徑需要寫待檢測圖像的路徑)
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output /home/jario/Pictures/h1.jpg
-
檢測給定路徑的單個視頻
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output test.mp4
-
檢測給定路徑的單個視頻,并將檢測結果保存為視頻
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -out_filename res.avi
-
利用攝像機實時檢測(YOLOv4)
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -c 0
-
利用攝像機實時檢測(YOLOv3-Tiny)
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -c 0
-
在GPU1上檢測給定路徑的單個視頻
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -i 1 test.mp4
-
檢測列表
data/train.txt中圖像,并將結果保存在result.json
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output -dont_show -out result.json < data/train.txt
-
檢測列表
data/train.txt中圖像,并將結果保存在result.txt
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output < data/train.txt > result.txt3
如何訓練
如何構建自己的訓練數據
下載數據集標注工具,下載地址:(https://pan.baidu.com/s/1EE52cDStjIxsRgM_a9pWQQ) (password: 4b2q) 或者Spire Web.
數據集管理軟件github地址:https://github.com/jario-jin/spire-image-manager
打開標注軟件 SpireImageTools_x.x.x.exe
首先點擊Tools->Setting...,填寫一個 save path (所有的標注文件都會存儲在這個文件夾中)
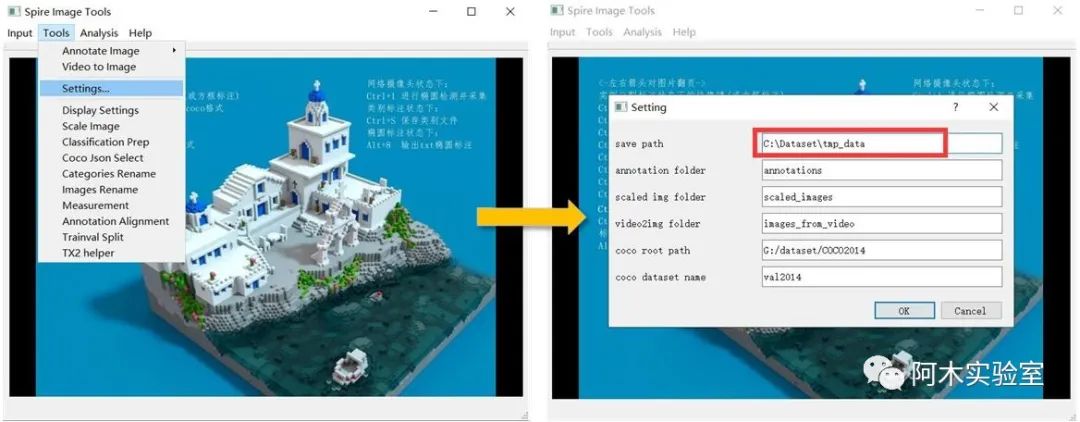
如果采集的數據集是視頻 (如果采集的是圖像,則調過這一步驟),點擊 Input->Video, 選擇要標注的視頻。
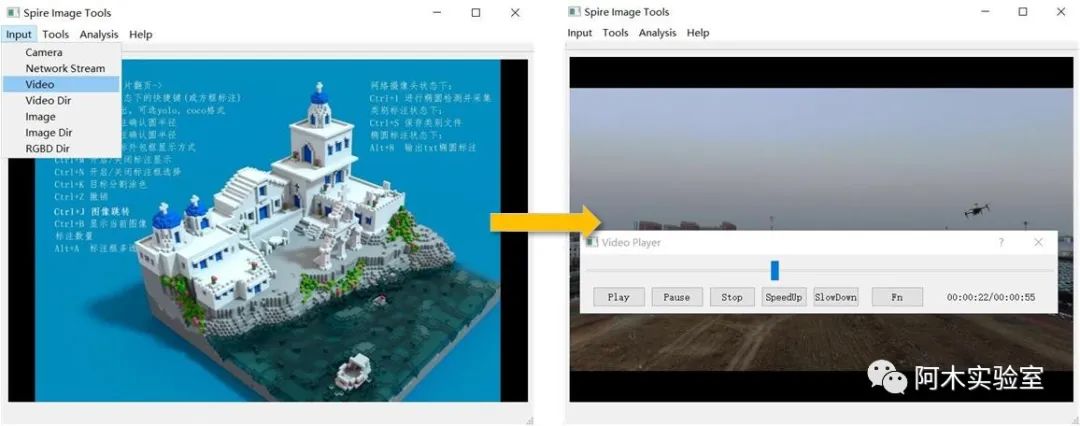
然后,點擊Tools->Video to Image
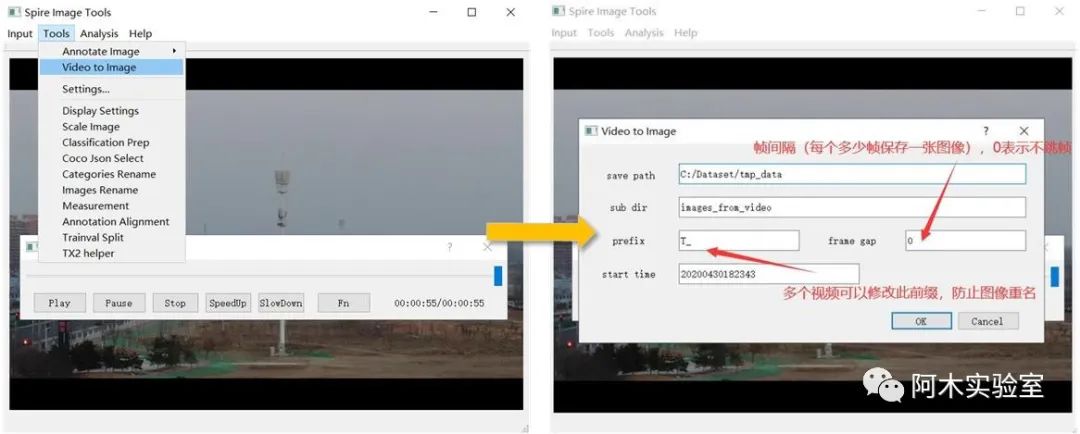
點擊OK 后,等待完成,結果會存儲在
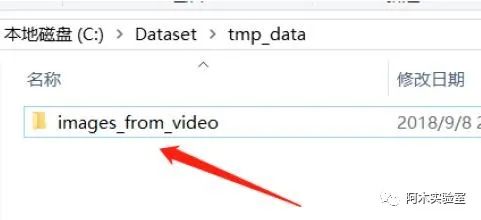
打開需要標注的圖像
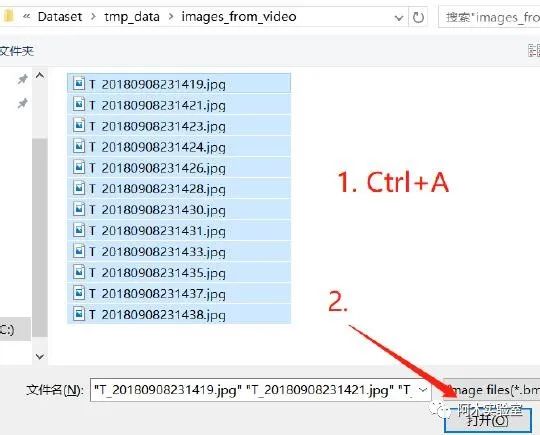
Input->Image Dir, 找到需要標注的圖像所在文件夾 Ctrl+A,全選,打開
點擊,Tools->Annotate Image->Instance Label,開始標注圖像
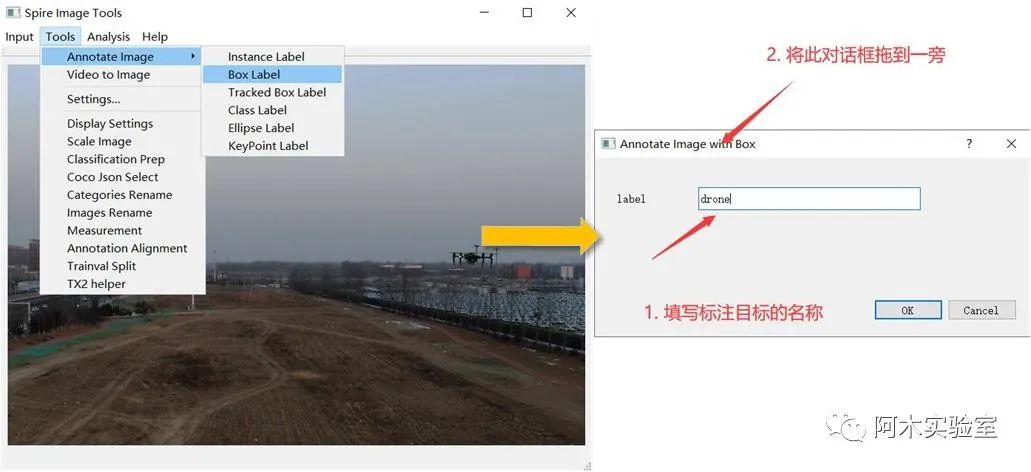
在 label 中填寫待標注目標名稱,然后將對話框拖到一邊在主窗口中開始標注,鼠標滾輪放大縮小圖像,按住左鍵移動可視圖像區域不斷點擊左鍵將目標框包圍, 使用 Yolo 訓練時,點擊 2 個點即可

標注時,如果點錯,按鼠標右鍵可以取消 標注完成后,如果不滿意,可以點擊綠色邊框(邊框會變紅,如下圖所示),按Delete 刪除

將標注輸出為 Yolo 格式,準備訓練
在標注完成之后,按下 Ctrl+O
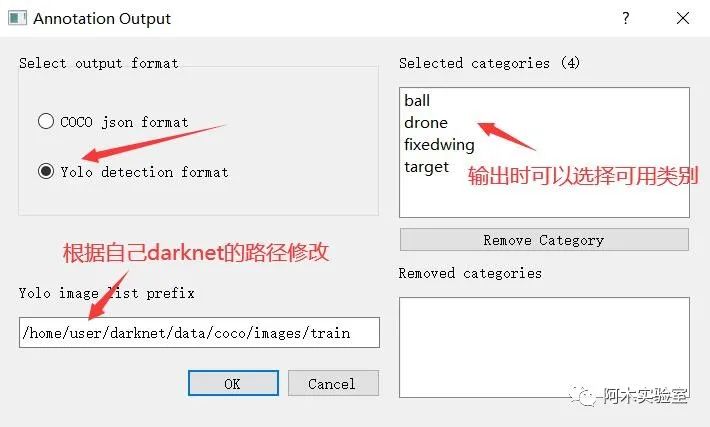
點擊確定后
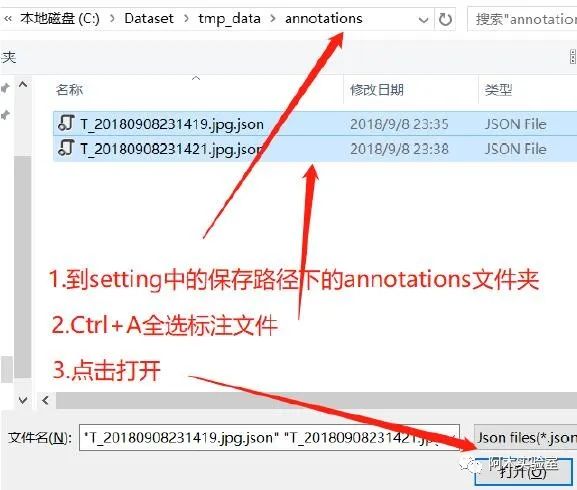
然后將下面 4 個文件取出用于 Yolo 訓練
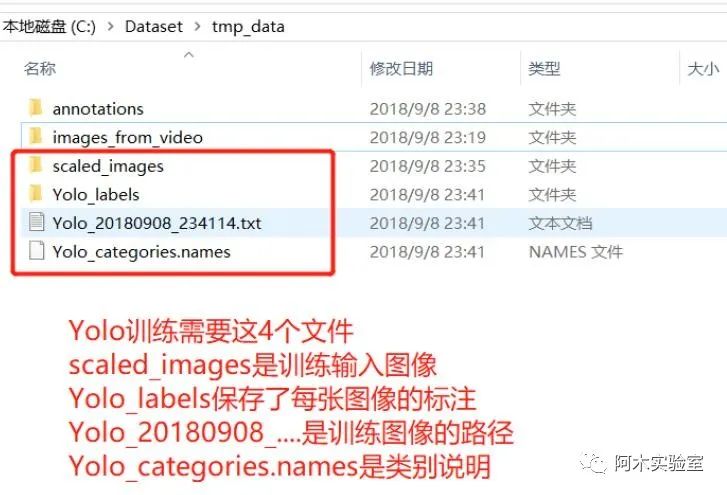
開始訓練YOLO
使用YOLOv4和YOLOv3:
-
針對選擇的模型,下載預訓練權重:
百度網盤打包下載,鏈接:https://pan.baidu.com/s/1CNVyyjoph7YVSXGT3vjbfQ,提取碼:4usc
-
對于
yolov4.cfg,yolov4-custom.cfg(162 MB):yolov4.conv.137 -
對于
csresnext50-panet-spp.cfg(133 MB):csresnext50-panet-spp.conv.112 -
對于
yolov3.cfg, yolov3-spp.cfg(154 MB):darknet53.conv.74 -
對于
yolov3-tiny-prn.cfg , yolov3-tiny.cfg(6 MB):yolov3-tiny.conv.11 -
對于
enet-coco.cfg (EfficientNetB0-Yolov3)(14 MB):enetb0-coco.conv.132
-
將
cfg/yolov4-custom.cfg拷貝一份,重命名為yolov4-obj.cfg(obj可以是自定義名稱)
-
修改batch為
batch=64 -
修改subdivisions為
subdivisions=16 -
修改max_batches為(
類別數量*2000,但不要小于4000),如訓練3個類別max_batches=6000 -
修改steps為max_batches的0.8與0.9,如
steps=4800,5400 -
修改
classes=80為自定義數據集的類別數量,主要需要修改3處(3個[yolo]層):
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L610
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L696
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L783
-
修改
filters=255為filters=(classes+5)x3,在3個[yolo]層的前一個[convolutional]層,分別為:
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L603
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L689
-
https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L776
-
如果使用
[Gaussian_yolo]層,修改filters=57為filters=(classes+9)x3,在3個[Gaussian_yolo]層的前一個[convolutional]層,分別為:
-
https://github.com/AlexeyAB/darknet/blob/6e5bdf1282ad6b06ed0e962c3f5be67cf63d96dc/cfg/Gaussian_yolov3_BDD.cfg#L604
-
https://github.com/AlexeyAB/darknet/blob/6e5bdf1282ad6b06ed0e962c3f5be67cf63d96dc/cfg/Gaussian_yolov3_BDD.cfg#L696
-
https://github.com/AlexeyAB/darknet/blob/6e5bdf1282ad6b06ed0e962c3f5be67cf63d96dc/cfg/Gaussian_yolov3_BDD.cfg#L789
-
例如,如果
classes=1,則filters=18;如果classes=2,則filters=21。注意:不要在cfg文件中直接寫:filters=(classes+5)x3)
-
在
darknet/data路徑下創建obj.names,其中每一行是一個目標類別名稱
-
將數據集標注得到的文件
Yolo_categories.names重命名為obj.names,并放到darknet/data下
-
在
darknet/data路徑下創建obj.data:教程 darknet 路徑為
/home/user/darknet,本文以此為例,請根據自己的路徑進行修改。在 /home/user/darknet/cfg/ 文件夾下新建一個文件,名字叫 obj.data 在里面寫入:
classes = 1
train = /home/user/darknet/data/coco/Yolo_20180908_234114.txt
valid = /home/user/darknet/data/coco/Yolo_20180908_234114.txt
names = data/obj.names
backup = backup
eval = coco
注意:classes 為類別數量,對于單類檢測問題,寫 1
5. 將圖像文件(.jpg)與標注文件放入到如下路徑darknetdatacoco路徑下
-
將
scaled_images里的圖像拷貝到/home/user/darknet/data/coco/images/train下 -
將
Yolo_labels里的標注文件拷貝到/home/user/darknet/data/coco/images/train下 -
將
Yolo_20180908_234114.txt拷貝到/home/user/darknet/data/coco下
6. 開始訓練
-
訓練指令:
./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137(對于最新100次迭代的最新權重
yolo-obj_last.weights會保存在darknetackup)(對于每1000次迭代的權重
yolo-obj_xxxx.weights會保存在darknetackup)(關閉Loss的顯示窗口
./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137 -dont_show)(通過瀏覽器查看訓練過程
./darknet detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -dont_show -mjpeg_port 8090 -map,然后打開Chrome瀏覽器,輸入http://ip-address:8090)(如果需要在訓練中計算mAP,每4期計算一次,需要在
obj.data文件中設置valid=valid.txt,運行:./darknet detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map)
7. 訓練結束,結果保存在darknetackupyolo-obj_final.weights
-
如果訓練中斷,可以選擇一個保存的權重繼續訓練,使用
./darknet detector train data/obj.data yolo-obj.cfg backupyolo-obj_2000.weights
注意:在訓練中,如果
avg(loss)出現nan,則訓練出了問題,如果是其他字段出現nan,這種情況是正常的。注意:如果需要改變cfg文件中的width=或height=,新的數字需要被32整除。注意:訓練完成后,檢測指令為:./darknet detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights。注意:如果出現Out of memory,需要修改cfg文件中的subdivisions=16為32或64。
訓練YOLOv3-Tiny
訓練YOLOv3-Tiny與選了YOLOv4、YOLOv3基本相同,主要有以下小區別:
-
下載yolov3-tiny預訓練權重,運行命令
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15 -
新建自定義
cfg文件yolov3-tiny-obj.cfg(可以復制cfg/yolov3-tiny.cfg為yolov3-tiny-obj.cfg) -
運行訓練命令:
./darknet detector train data/obj.data yolov3-tiny-obj.cfg yolov3-tiny.conv.15
多GPU訓練
-
首先在1塊GPU上訓練1000次
./darknet detector train cfg/coco.data cfg/yolov4.cfg yolov4.conv.137 -
停止訓練,使用權重
darknet/backup/yolov4_1000.weights,在多塊GPU上訓練,運行./darknet detector train cfg/coco.data cfg/yolov4.cfg /backup/yolov4_1000.weights -gpus 0,1,2,3
注意:如果出現
nan,應該降低學習率,如4塊GPUlearning_rate=0.00065(learning_rate=0.00261/GPUs),還應該增加cfg文件中的burn_in=為原先的4x,如burn_in=4000
訓練常見程序問題
注意:如果出現如下錯誤
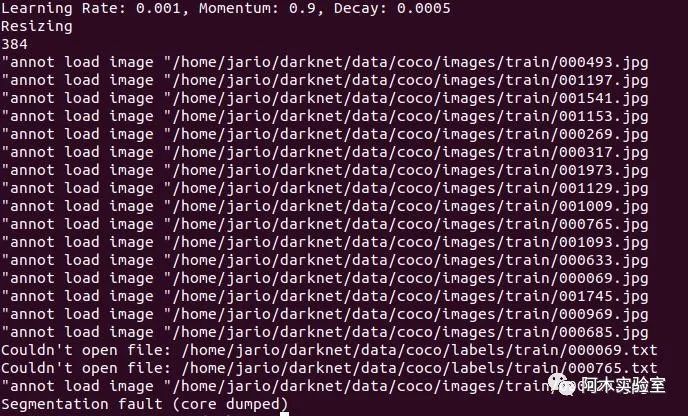
需要修改源碼/home/user/darknet/src/data.c將如下代碼
list *get_paths(char *filename)
{
char *path;
FILE *file = fopen(filename, "r"); if(!file) file_error(filename); list *lines = make_list(); while((path=fgetl(file))) { list_insert(lines, path); } fclose(file); return lines;}修改為:
void ltrim(char *s)
{
char *p; p = s;
while (*p == ' ' || *p == ' ' || *p == ' ') { p++; } strcpy(s,p);
}
void rtrim(char *s)
{
int i;
i = strlen(s) - 1;
while ((s[i] == ' ' || s[i] == ' ' || s[i] == ' ') && i >= 0 ) { i--; } s[i+1] = '';
}
void _trim(char *s)
{
ltrim(s);
rtrim(s);
}
list *get_paths(char *filename)
{
char *path;
FILE *file = fopen(filename, "r"); if(!file) file_error(filename); list *lines = make_list(); while((path=fgetl(file))) {
_trim(path); list_insert(lines, path);
}
fclose(file); return lines;
}
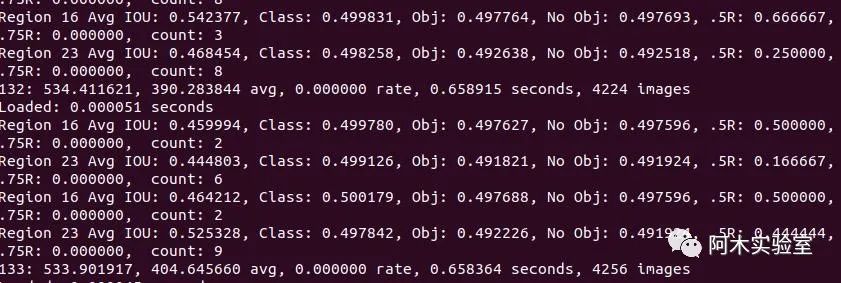
保存,make -j8重新編譯 下面為正常訓練時畫面
何時應該停止訓練
通常情況下,為每個類別迭代2000次是足夠的,且總的迭代次數不能低于4000次。但是如果想要更加精確的停止時間,可以參考以下說明:
-
在訓練過程中,你會看到一系列訓練誤差,當0.XXXXXXX avg這個參數不再下降時,就該停止訓練了
Region Avg IOU: 0.798363, Class: 0.893232, Obj: 0.700808, No Obj: 0.004567, Avg Recall: 1.000000, count: 8 Region Avg IOU: 0.800677, Class: 0.892181, Obj: 0.701590, No Obj: 0.004574, Avg Recall: 1.000000, count: 89002: 0.211667,0.60730 avg, 0.001000 rate, 3.868000 seconds, 576128 images Loaded: 0.000000 seconds
-
9002- 迭代數量(batch數量)
-
0.60730 avg- 平均損失(誤差),越低越好
如果發現0.XXXXXXX avg在很多次迭代后都不再降低,則是時候該停止訓練了。最終的平均損失從0.05(對于小模型和簡單訓練數據)到3.0(對于大模型和復雜訓練數據)不等。
-
當訓練停止之后,可以從
darknetackup中取出最新保存的訓練權重.weights,并選擇它們中檢測效果最好的
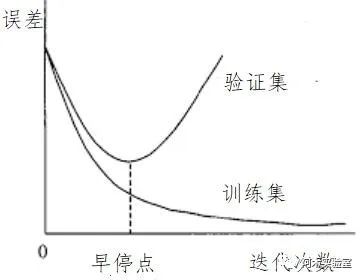
例如,當訓練9000次停止后,效果最好的模型可能是之前保存權重中的一個(7000,8000,9000),這是因為過擬合(Overfiting)現象。過擬合的表現可以解釋為,在訓練圖像上檢測效果很好,但是在其他圖像上效果不佳,這時候就該盡早停止訓練(早停點)。
2.1 首先,你需要在obj.data中指定驗證數據集valid=valid.txt,如果你沒有準備驗證數據集,可以簡單的復制data rain.txt為datavalid.txt。
2.2 如果你在迭代9000次之后停止訓練,驗證之前的模型權重可以使用如下命令:
-
./darknet detector map data/obj.data cfg/yolo-obj.cfg backupyolo-obj_7000.weights
-
./darknet detector map data/obj.data cfg/yolo-obj.cfg backupyolo-obj_8000.weights
-
./darknet detector map data/obj.data cfg/yolo-obj.cfg backupyolo-obj_9000.weights
然后對比每個權重(7000,8000,9000)最后一行輸出,選擇mAP(mean average precision)最高權重,或者對比IoU(intersect over union)進行選擇。
例如,yolo-obj_8000.weights的mAP最高,則使用這個權重。或者在訓練時加上-map參數:
./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137 -map
結果如下圖所示,mAP每4期(Epoch)通過obj.data中設置的驗證集valid=valid.txt上計算一次(1期=train_txt中圖像數量 / batch次迭代)。
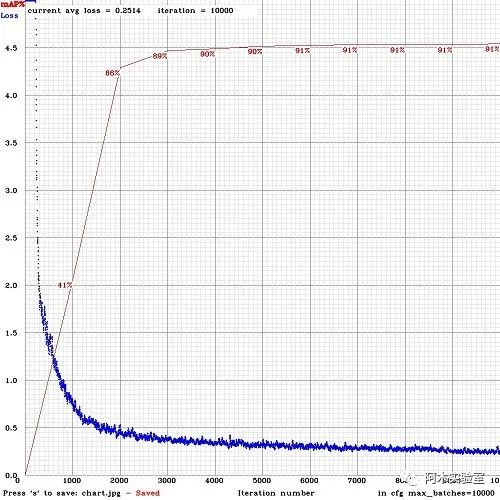
運行訓練好的模型,進行目標檢測,執行:
./darknet detector test data/obj.data cfg/yolo-obj.cfg yolo-obj_8000.weights
如何提升檢測效果
訓練之前提升檢測效果的技巧
-
設置
.cfg文件中random=1,可以使用多分辨率輸入增加檢測效果:link -
在
.cfg文件中增加網絡的輸入分辨率(設置任意可以被32整除的數字,如,height=608,width=608),可以增加精度 -
檢查圖像每個目標是否都被標記,圖像中的所有目標都必須被正確標記,推薦使用數據管理工具檢查:spire-image-manager
-
Loss很大,mAP很低,是不是訓練錯了?在訓練中使用
-show_imgs參數,能夠可視化目標框真值,檢查數據集是否出了問題。 -
對于每一個你要檢測的物體,在訓練數據集中至少需要有一個實例與之相似,包括:形狀、物體側面、相對大小、旋轉角度、傾斜方位角、光照等。因此,你的訓練數據集需要包含具有不同對象屬性的圖像:比例、旋轉、光照、不同側面、不同背景等。建議對每一類物體收集2000張不同圖像,并迭代訓練2000*類別數量次。
-
推薦在訓練數據集中包含帶有不希望檢測的非標記目標的圖像。負樣本圖像不需要方框標記(空
.txt文件),越多越好。 -
標注目標的最佳方式是:僅標注物體的可見部分,或標注物體的可見和重疊部分,或標注比整個物體稍多一點的部分(有一點間隙),標注你想讓檢測器檢測的部分。
-
如果單幅圖像中的物體很多,需要在
[yolo]層或[region]層中修改參數max=200或者更高(全局最大目標檢測數量為0,0615234375*(width*height))。
如果想要檢測小目標(圖像被縮放到416*416后,小于16*16的目標)
-
全模型 - 5個yolo層:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg
-
小模型 - 3個yolo層:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3-tiny_3l.cfg
-
YOLOv4 - 3個yolo層:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-custom.cfg
-
train_network_width * train_obj_width / train_image_width ~= detection_network_width * detection_obj_width / detection_image_width -
train_network_height * train_obj_height / train_image_height ~= detection_network_height * detection_obj_height / detection_image_height
也就是,對于測試數據集中的每個物體,訓練數據集中必須至少有一個具有相同類與大約相同相對大小的物體。如果訓練數據中僅有占圖像面積80-90%的物體,則訓練后的網絡不能夠檢測占圖像面積1-10%的物體。
-
在https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L895修改`layers= 23`
-
在https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L892修改`stride=4`
-
在https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L989修改`stride=4`
-
如果想要同時檢測大目標與小目標,可以使用修改模型:
-
如果你訓練的數據類別需要區分左右目標(如檢測左右手,交通信號中的左右方向),則不能使用左右翻轉圖像增強,在cfg文件中設置
flip=0:https://github.com/AlexeyAB/darknet/blob/3d2d0a7c98dbc8923d9ff705b81ff4f7940ea6ff/cfg/yolov3.cfg#L17 -
一般規則 - 您的訓練數據集應包含待檢測目標的相對大小的集合:
-
如果想加速訓練(損失檢測精度),可以在cfg文件layer-136中設置參數
stopbackward=1 -
注意
物體的模型、側面、光照、尺度、方位角等屬性,從神經網絡的內部角度來看,這些是不同的物體。因此,你想檢測的物體越多,就應該使用越復雜的網絡模型。 -
如果想要外包矩形框更加精確,可以在
[yolo]層中增加3個參數:ignore_thresh=.9 iou_normalizer=0.5 iou_loss=giou,這會增加mAP@0.9,同時降低mAP@0.5。 -
如果你比較熟悉檢測網絡了,可以重新計算自定義數據集的錨框(Anchor):
./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416,然后設置cfg文件中3個[yolo]層9個錨框。同時需要改變每個[yolo]層中的錨框索引mask=,第一層有大于60*60的錨框,第二層有大于30*30的錨框,第三層相同。也需要改變每個[yolo]層之前的filters=(classes + 5)*。如果許多計算出的錨框不適合在適當的層下 - 那么就嘗試使用默認錨框。
訓練之后提升檢測效果的技巧
-
增加cfg文件中網絡輸入的分辨率,如,
height=608,width=608,或height=832,width=832,這樣可以檢測更小的目標。
如何將訓練好的模型部署到無人機上
TX2上的準備工作
-
推薦使用Ubuntu 18.04(可以使用JetPack刷機)
-
CMake >= 3.8:https://cmake.org/download/
-
CUDA >= 10.0:https://developer.nvidia.com/cuda-toolkit-archive
-
cuDNN >= 7.0 for CUDA >= 10.0https://developer.nvidia.com/rdp/cudnn-archive
-
OpenCV >= 2.4:https://opencv.org/releases.html
-
GCC
-
ROS Melodic:http://wiki.ros.org/melodic/Installation
使用JetPack為TX2安裝CUDA與cuDNN
-
下載JetPack,地址:https://developer.nvidia.com/embedded/jetpack
-
進入 sdkmanager-[version].[build].deb 所在的路徑,其中version和build代表相應各自的編號,安裝Debian包:
sudo apt install ./sdkmanager-[version].[build].deb
-
安裝好之后,在Terminal中輸入
sdkmanager
-
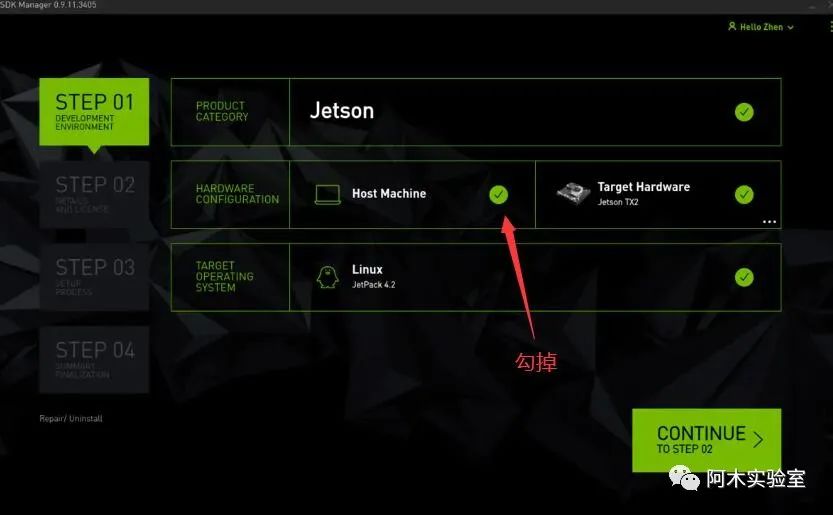
在 Product Category 中選擇 Jetson.
-
在 Hardware Configuration 中選擇 target hardware(Jetson TX2),勾掉host machine
-
在 Target Operating System 中選擇 JetPack 的版本.
-
點擊CONTINUE進入下一步
-
使用NVIDIA賬號登錄
-
選擇開發環境
-
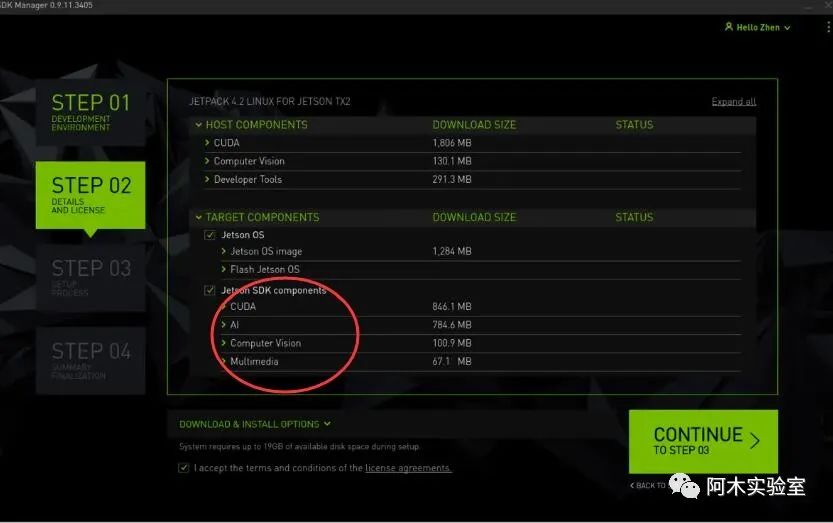
檢查下載組件(如果僅安裝CUDA和cuDNN,則只勾選紅圈內的選項)、選擇存儲路徑以及接收條款
-
保證Host計算機與TX2在同一局域網內,輸入TX2的IP地址就可以安裝
部署Darknet-ROS
-
下載darknet_ros源碼
cd ~
cd catkin_ws/src
git clone --recursive https://github.com/leggedrobotics/darknet_ros.git
cd ../
-
編譯
catkin_make -DCMAKE_BUILD_TYPE=Release
-
將訓練好的cfg和weights加載到darknet_ros中
將/home/user/darknet/cfg/yolov3-tiny.cfg和/home/user/darknet/backup中剛剛訓練好的參數 分別拷貝到/home/user/catkin_ws/src/darknet_ros/darknet_ros/yolo_network_config中的cfg和weights兩個文件夾中 在/home/user/catkin_ws/src/darknet_ros/darknet_ros/config文件夾中新建yolov3-tiny-obj.yaml
里面寫入
yolo_model:
config_file:
name: yolov3-tiny-obj.cfg
weight_file:
name: yolov3-tiny-obj.weights
threshold:
value: 0.3
detection_classes:
names:
- drone
注意,在
yolov3-tiny-obj.yaml文件中,需要指定剛才拷貝的cfg和weights文件以及names為自己訓練的類別
在/home/user/catkin_ws/src/darknet_ros/darknet_ros/launch文件夾中,復制一份darknet_ros.launch,重命名為obj_det.launch修改里面的
為
注意:這正式剛才編寫的yaml文件
roslaunch darknet_ros obj_det.launch
注意:進行檢測,需要先打開一個ros_web_cam節點,以提供攝像頭數據
最后,給一張YOLOv4檢測結果的樣張吧

-
檢測器
+關注
關注
1文章
871瀏覽量
47799 -
Linux
+關注
關注
87文章
11351瀏覽量
210511 -
無人機
+關注
關注
230文章
10529瀏覽量
182655 -
編譯
+關注
關注
0文章
662瀏覽量
33071
原文標題:如何在無人機上部署YOLOv4物體檢測器
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【YOLOv5】LabVIEW+YOLOv5快速實現實時物體識別(Object Detection)含源碼
無人機+探地雷達=地雷探測器?
超聲波感應器用于無人機應用的原因
無人機上多種傳感器有什么功用
【羅姆傳感器評估板試用體驗連載】無人機感知系統
NDIR氣體檢測器解決方案和PID氣體檢測器解決方案
基于Tengine實現yolov4的cpu推理講解
基于Tengine實現yolov4的cpu推理

Nvidia Jetson Nano面罩Yolov4探測器

深入淺出Yolov3和Yolov4
在樹莓派上部署YOLOv5進行動物目標檢測的完整流程





 工商網監
工商網監
評論