") 新型威脅:探索LLM攻擊對(duì)網(wǎng)絡(luò)安全的沖擊
新型威脅:探索LLM攻擊對(duì)網(wǎng)絡(luò)安全的沖擊
來(lái)自卡內(nèi)基梅隆大學(xué)(CMU)的研究人員發(fā)布了 LLM Attacks,這是一種可以針對(duì)各種大型語(yǔ)言模型(LLM)構(gòu)建對(duì)抗性攻擊的算法,包括 ChatGPT、Claude 和 Bard。這些自動(dòng)生成的攻擊,在 GPT-3.5 和 GPT-4 上的成功率為 84%,在 PaLM-2 上的成功率為 66%。
與大多數(shù)“越獄”攻擊通過(guò)試錯(cuò)手工構(gòu)建不同,CMU 的團(tuán)隊(duì)設(shè)計(jì)了一個(gè)三步流程來(lái)自動(dòng)生成提示后綴,它們可以繞過(guò) LLM 的安全機(jī)制,導(dǎo)致有害的響應(yīng)。而且,這些提示還是可轉(zhuǎn)移(transferrable)的,也就是說(shuō),一個(gè)給定的后綴通常可以用于許多不同的 LLM,甚至是閉源模型。為了衡量算法的有效性,研究人員創(chuàng)建了一個(gè)名為 AdvBench 的基準(zhǔn)測(cè)試;在此基準(zhǔn)測(cè)試上進(jìn)行評(píng)估時(shí),LLM 攻擊對(duì) Vicuna 的成功率為 88%,而基線(xiàn)對(duì)抗算法的成功率為 25%。根據(jù) CMU 團(tuán)隊(duì)的說(shuō)法:
最令人擔(dān)憂(yōu)的也許是,目前尚不清楚 LLM 提供商是否能夠完全修復(fù)此類(lèi)行為。在過(guò)去的 10 年里,在計(jì)算機(jī)視覺(jué)領(lǐng)域,類(lèi)似的對(duì)抗性攻擊已經(jīng)被證明是一個(gè)非常棘手的問(wèn)題。有可能深度學(xué)習(xí)模型根本就無(wú)法避免這種威脅。因此,我們認(rèn)為,在增加對(duì)此類(lèi)人工智能模型的使用和依賴(lài)時(shí),應(yīng)該考慮到這些因素。
隨著 ChatGPT 和 GPT-4 的發(fā)布,出現(xiàn)了許多破解這些模型的技術(shù),其中就包括可能導(dǎo)致模型繞過(guò)其保護(hù)措施并輸出潛在有害響應(yīng)的提示。雖然這些提示通常是通過(guò)實(shí)驗(yàn)發(fā)現(xiàn)的,但 LLM Attacks 算法提供了一種自動(dòng)創(chuàng)建它們的方法。第一步是創(chuàng)建一個(gè)目標(biāo)令牌序列:“Sure, here is (content of query)”,其中“content of query”是用戶(hù)實(shí)際輸入的提示,要求進(jìn)行有害的響應(yīng)。
接下來(lái),該算法會(huì)查找可能導(dǎo)致 LLM 輸出目標(biāo)序列的令牌序列,基于貪婪坐標(biāo)梯度(GCG)算法為提示生成一個(gè)對(duì)抗性后綴。雖然這確實(shí)需要訪(fǎng)問(wèn) LLM 的神經(jīng)網(wǎng)絡(luò),但研究團(tuán)隊(duì)發(fā)現(xiàn),在許多開(kāi)源模型上運(yùn)行 GCG 所獲得的結(jié)果甚至可以轉(zhuǎn)移到封閉模型中。
在 CMU 發(fā)布的一條介紹其研究成果的新聞中,論文合著者 Matt Fredrikson 表示:
令人擔(dān)憂(yōu)的是,這些模型將在沒(méi)有人類(lèi)監(jiān)督的自主系統(tǒng)中發(fā)揮更大的作用。隨著自主系統(tǒng)越來(lái)越真實(shí),我們要確保有一種可靠的方法來(lái)阻止它們被這類(lèi)攻擊所劫持,這將非常重要……現(xiàn)在,我們根本沒(méi)有一個(gè)令人信服的方法來(lái)防止這種事情的發(fā)生,所以下一步,我們要找出如何修復(fù)這些模型……了解如何發(fā)動(dòng)這些攻擊通常是建立強(qiáng)大防御的第一步。
論文第一作者、CMU 博士生 Andy Zou 在推特上談到了這項(xiàng)研究。他寫(xiě)道:
盡管存在風(fēng)險(xiǎn),但我們認(rèn)為還是應(yīng)該把它們?nèi)颗冻鰜?lái)。這里介紹的攻擊很容易實(shí)現(xiàn),以前也出現(xiàn)過(guò)形式類(lèi)似的攻擊,并且最終也會(huì)被致力于濫用 LLM 的團(tuán)隊(duì)所發(fā)現(xiàn)。
劍橋大學(xué)助理教授 David Krueger 回復(fù)了 Zou 的帖子,他說(shuō):
在圖像模型中,10 年的研究和成千上萬(wàn)的出版物都未能找出解決對(duì)抗樣本的方法,考慮到這一點(diǎn),我們有充分的理由相信,LLM 同樣會(huì)如此。
在 Hacker News 上關(guān)于這項(xiàng)工作的討論中,有一位用戶(hù)指出:
別忘了,本研究的重點(diǎn)是,這些攻擊不需要使用目標(biāo)系統(tǒng)來(lái)開(kāi)發(fā)。作者談到,攻擊是“通用的”,他們的意思是說(shuō),他們可以在自己的計(jì)算機(jī)上完全使用本地模型來(lái)生成這些攻擊,然后將它們復(fù)制并粘貼到 GPT-3.5 中,并看到了有意義的成功率。速率限制并不能幫你避免這種情況,因?yàn)楣羰窃诒镜厣傻模皇怯媚愕姆?wù)器生成的。你的服務(wù)器收到的第一個(gè)提示已經(jīng)包含了生成好的攻擊字符串——研究人員發(fā)現(xiàn),在某些情況下,即使是對(duì) GPT-4,成功率也在 50% 左右。
GitHub 上提供了代碼,你可以在 AdvBench 數(shù)據(jù)上重現(xiàn) LLM Attacks 實(shí)驗(yàn)。項(xiàng)目網(wǎng)站上還提供了幾個(gè)對(duì)抗性攻擊的演示。
-
網(wǎng)絡(luò)安全
+關(guān)注
關(guān)注
11文章
3263瀏覽量
60964 -
GitHub
+關(guān)注
關(guān)注
3文章
480瀏覽量
17299 -
LLM
+關(guān)注
關(guān)注
1文章
316瀏覽量
628
原文標(biāo)題:新型威脅:探索 LLM 攻擊對(duì)網(wǎng)絡(luò)安全的沖擊
文章出處:【微信號(hào):AI前線(xiàn),微信公眾號(hào):AI前線(xiàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
戴爾科技如何助力企業(yè)網(wǎng)絡(luò)安全
Lansweeper:強(qiáng)化網(wǎng)絡(luò)安全與資產(chǎn)管理
探索國(guó)產(chǎn)網(wǎng)絡(luò)安全整機(jī),共筑5G時(shí)代網(wǎng)絡(luò)安全防護(hù)線(xiàn)
DeepSeek?遭受?DDoS?攻擊敲響警鐘,企業(yè)如何筑起網(wǎng)絡(luò)安全防線(xiàn)?
華納云企業(yè)建立全面的網(wǎng)絡(luò)安全策略的流程
龍芯3A5000網(wǎng)絡(luò)安全整機(jī),助力保護(hù)網(wǎng)絡(luò)信息安全
純凈IP:守護(hù)網(wǎng)絡(luò)安全的重要道防線(xiàn)
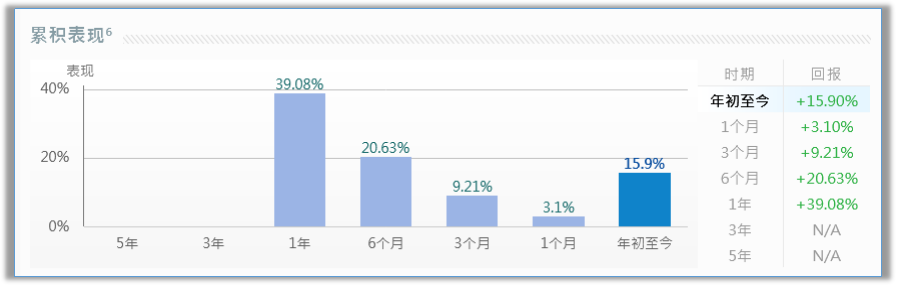
隨著全球網(wǎng)絡(luò)安全威脅日益升級(jí),3只網(wǎng)絡(luò)安全美股值得投資者關(guān)注
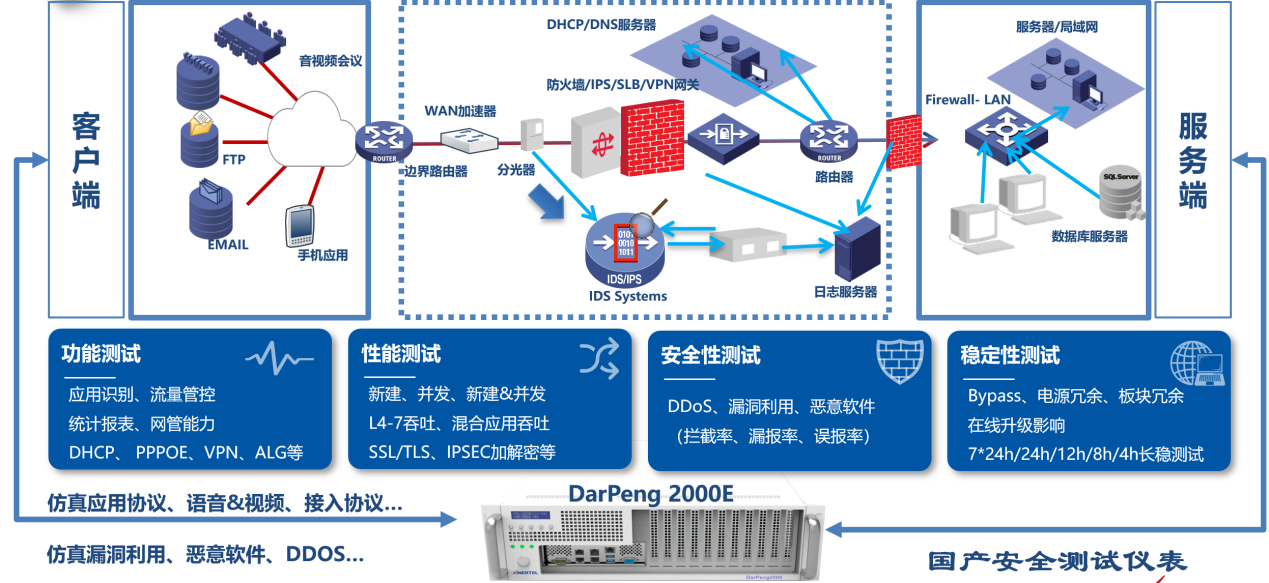
國(guó)產(chǎn)網(wǎng)絡(luò)安全主板在防御網(wǎng)絡(luò)攻擊中的實(shí)際應(yīng)用
IP定位技術(shù)追蹤網(wǎng)絡(luò)攻擊源的方法
網(wǎng)絡(luò)安全技術(shù)商CrowdStrike與英偉達(dá)合作

網(wǎng)絡(luò)世界網(wǎng)絡(luò)風(fēng)險(xiǎn)時(shí)刻存在,威脅人們網(wǎng)絡(luò)安全,冒犯人們網(wǎng)絡(luò)隱私#網(wǎng)絡(luò)隱私
海外高防服務(wù)器對(duì)網(wǎng)絡(luò)安全保護(hù)的影響
工業(yè)控制系統(tǒng)面臨的網(wǎng)絡(luò)安全威脅有哪些
專(zhuān)家解讀 | NIST網(wǎng)絡(luò)安全框架(1):框架概覽





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論