 基于DL Streamer與YOLOv8模型實現多路視頻流實時分析
基于DL Streamer與YOLOv8模型實現多路視頻流實時分析
作為眾多 AI 應用場景的基座,基于流媒體的視覺分析一直是傳統 AI 公司的核心能力之一。但想要搭建一套完整的視頻分析系統其實并不容易,其中會涉及多個圖像處理環節的開發工作,例如視頻流拉取、圖像編解碼、AI 模型前后處理、AI 模型推理,以及視頻流推送等常見任務模塊。其中每一個模塊都需要領域專家在指定的硬件平臺進行開發和優化,并且如何高效地將他們組合起來也是一個問題。在這篇文章中,我們將探討如何利用 Intel 的 DL Streamer 工具套件打造一套支持多路視頻流接入的視頻分析系統,利用 OpenVINO 部署并加速 YOLOv8 推理任務。
(復制鏈接到瀏覽器打開)
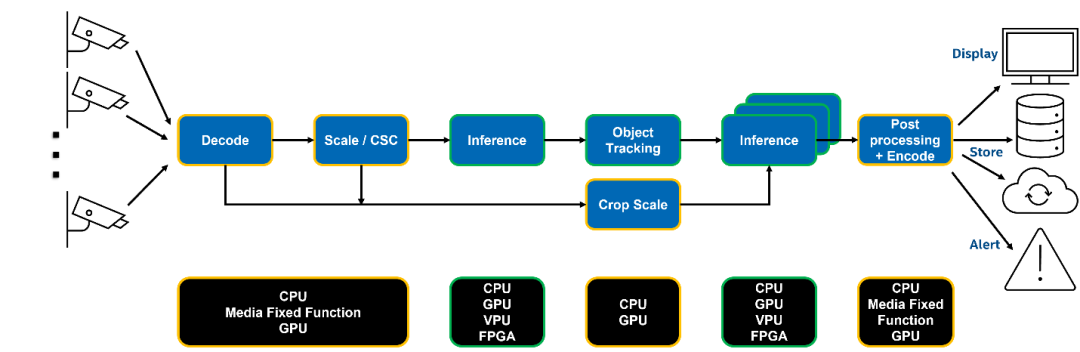
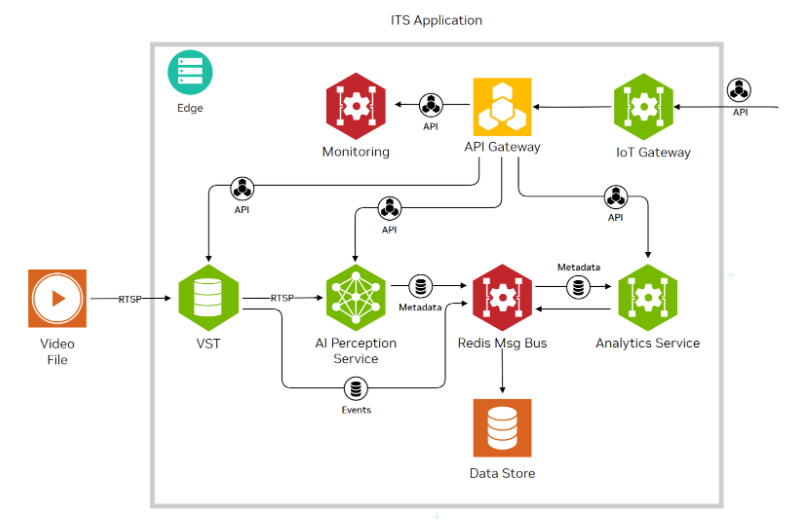
圖1:典型的視頻分析系統流水線
Intel DL Streamer 工具套件
DL Streamer 是一套開源的流媒體分析系統框架,它基于著名的 GStreamer 多媒體框架所打造,可以幫助開發者快速構建復雜的媒體分析流水線。開發者只需要通過命令行的方式就可以輕松完成一套支持多路的分析系統搭建。此外,在這個過程中,DL Streamer 會幫助我們將每個模塊部署在指定的硬件加速平臺,以獲得更好的性能與更高的資源利用率。
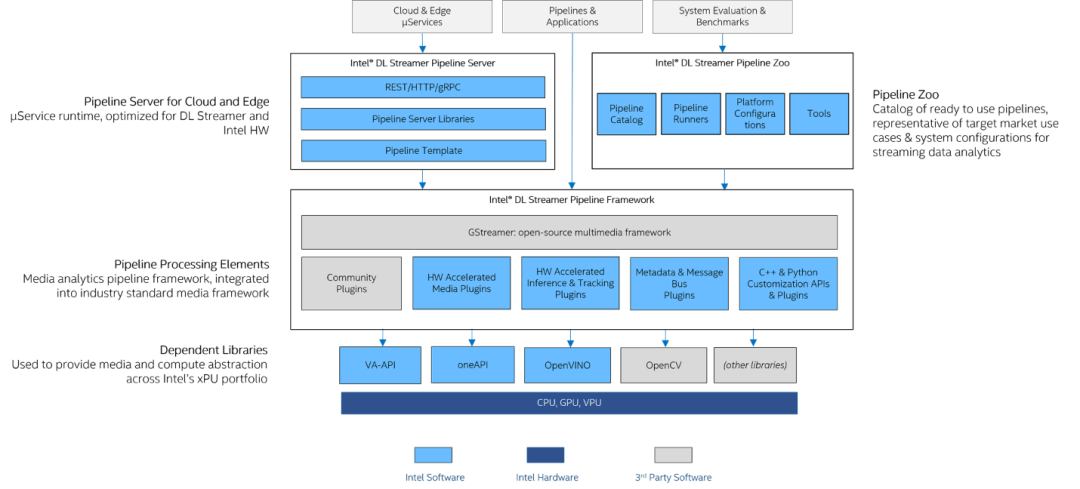
圖2:DL Streamer 架構圖
01Intel DL Streamer Pipeline Framework 用于構建最基礎的視頻分析流水線,其中利用 VA-API 庫提升 GPU 的硬件編解碼能力,基于 OpenVINO 實現對于 AI 推理任務的加速。此外還支持 C++和 Python API 接口調用方式,便于開發者與自有系統進行集成。
02Intel DL Streamer Pipeline Server 可以將構建好的視頻分析流水線以微服務的方式部署在多個計算節點上,并提供對外的 REST APIs 接口調用。
03Intel DL Streamer Pipeline Zoo 則被作為性能評估與調式的工具,其中集成了一些即開即用的示例,方便開發者測試。
本文中分享的 demo 是一個基于 DL Streamer 的最小化示例,僅使用Intel DL Streamer Pipeline Framework 進行任務開發。
開發流程
1、YOLOv8 模型優化與轉換
首先我們需要對模型進行性能優化,這里我們才利用量化技術來壓縮模型體積。由于目前 Ultralytics 庫已經直接支持 OpenVINO IR 格式的模型導出,所以我們可以直接調用以下接口將 YOLOv8 預訓練權轉化為OpenVINO IR,并通過 NNCF 工具進行后訓練量化。
det_model = YOLO(f"../model/{DET_MODEL_NAME}.pt")
out_dir = det_model.export(format="openvino", dynamic=True, half=True)
左滑查看更多
此外由于我們需要使用 vaapi-surface-sharing backend,來實現從解碼-前處理-推理在 GPU 設備上的 zero-copy,標準 YOLOv8 模型的部分前處理任務沒有辦法支持 vaapi-surface-sharing
因此我們需要將部分前處理任務以模型算子的形式提前集成到模型結構中,這里可以利用 OpenVINO 的 Preprocessing API 來進行前處理任務中轉置和歸一化操作的集成。具體方法如下:
input_layer = model.input(0)
model.reshape({input_layer.any_name: PartialShape([1, 3, 640, 640])})
ppp = PrePostProcessor(model)
ppp.input().tensor().set_color_format(ColorFormat.BGR).set_layout(Layout("NCHW"))
ppp.input().preprocess().convert_color(ColorFormat.RGB).scale([255, 255, 255])
model = ppp.build()
左滑查看更多
2、 集成 YOLOv8 后處理任務
由于 DLStreamer 目前沒有直接支持 YOLOv8 的后處理任務,所以我們需要在其源碼中新增 YOLOv8 后處理任務的 C++ 實現。
并重新編譯 DLStreamer 源碼。相較之前 YOLO 系列的模型,YOLOv8 模型的原始輸出會一些特殊,他的輸出數據結構為(1, 84, 8400),其中8400代表識別對象的數量,84 代表 4 個坐標信息 +80 種類別,而通常情況下坐標信息和類別信息都是在最后一個維度里,所以為了在 C++ 應用中更方便的地模型輸出進行遍歷,我們首先需要做一個維度轉置的操作,將其輸出格式變為(1, 8400, 84),接下來就可以通過常規 YOLO 模型的后處理方式,來解析并過濾 YOLOv8 模型輸出。
cv::Mat outputs(object_size, max_proposal_count, CV_32F, (float *)data); cv::transpose(outputs, outputs);
左滑查看更多
3、構建 DL Streamer Pipeline
其實 DL Streamer Pipeline 的構建非常簡單,我們只需要記住每一個 element 模塊的功能,并按從“輸入 -> 解碼 -> 推理 -> 編碼/輸出”的次序將他們組合起來就可以了,以下就是一個單通道的示例。
gst-launch-1.0 filesrc location=./TownCentreXVID.mp4 ! decodebin ! video/x-raw(memory:VASurface) ! gvadetect model=./models/yolov8n_int8_ppp.xml model_proc=./dlstreamer_gst/samples/gstreamer/model_proc/public/yolo-v8.json pre-process-backend=vaapi-surface-sharing device=GPU ! queue ! meta_overlay device=GPU preprocess-queue-size=25 process-queue-size=25 postprocess-queue-size=25 ! videoconvert ! fpsdisplaysink video-sink=ximagesink sync=false
左滑查看更多
除推理部分的任務外,DL Streamer 中大部分的模塊都是復用 GStreamer 的element,這里需要特別注意的是,為了實現在 GPU 硬解碼和推理任務之間的 zero-copy,解碼的輸出需要為video/x-raw(memory:VASurface)格式,并且推理的任務的前處理任務需要調用 vaapi-surface-sharing backend ,以此來將前處理的任務負載通過 GPU 來進行加速。
此外這邊也會用到 DL Streamer 2.0 API 中新增的meta_overlay 模塊將結果信息,以 bounding box 的形態添加在原始視頻流中,并利用 fpsdisplaysink 模塊統計實時 FPS 性能后,一并作為結果可視化進行輸出展示。如果本機不支持可視化播放,我們也可以通過拼接以下指令:
vaapih264enc ! h264parse ! mpegtsmux ! rtpmp2tpay ! udpsink host=192.168.3.9 port=5004
將結果畫面編碼后,通過 udp 協議推流,并用例如 VLC 這樣的工具,在另一臺設備播放。
如果不需要可視化呈現,我們也可以通過 gvametapublish 模塊將原始結果輸出到一個 json 文件中,或通過 MQTT 協議推送這些原始的結果數據。gvametapublish模塊的使用方法可以查詢:
https://dlstreamer.github.io/elements/gvametapublish.html(復制鏈接到瀏覽器打開)
4、多通道 Pipeline 優化
為了方便多通道任務同屏展示,我們通過 compositor模塊將多個通道的檢測結果進行拼接。在多路推理性能優化方面,可以利用以下指令,將多個同一時刻內的多個 stream 輸入,打包為一個 batch,送入 GPU 進行推理,以激活 GPU 在吞吐量上的優勢,而 infer request 的數量則會根據接入視頻的通道數動態調整。
nireq=$((${STREAM}*2)) gpu-throughput-streams=${STREAM} batch-size=${NUM_PANES} model-instance-id=1
左滑查看更多
此外,為了避免重復創建模型對象,可以將每個通道里的model-instance-id都設為統一值,這樣 OpenVINO 只會為我們初始化一個模型對象。
如何運行示例
為了方便在不同硬件平臺進行移植,同時降低部署門檻,這里我們已經將所有的示例代碼打包進了 docker 鏡像內,大家可以通過以下幾條簡單的指令,快速復現整個方法。
1、初始化環境
這一步主要為了可以在容器內訪問 host 的 GPU 資源,以及開啟視頻流展示的權限,如果當前硬件中存在多個 GPU 設備,我們可以通過修改 GPU driver 的編號來調整映射到容器內的 GPU 資源,例如這可以把renderD128修改為 renderD129
$ xhost local:root $ setfacl -m user:1000:r ~/.Xauthority $ DEVICE=${DEVICE:-/dev/dri/renderD128} $ DEVICE_GRP=$(ls -g $DEVICE | awk '{print $3}' | xargs getent group | awk -F: '{print $3}')
左滑查看更多
2、拉取 docker 鏡像
$ docker pull snake7gun/dlstreamer-yolov8-2023.0:latest
左滑查看更多
3、運行容器
將之前設置 host 環境映射到容器內,并初始化容器內環境。
$ docker run -it --rm --net=host -e no_proxy=$no_proxy -e https_proxy=$https_proxy -e socks_proxy=$socks_proxy -e http_proxy=$http_proxy -v ~/.Xauthority:/home/dlstreamer/.Xauthority -v /tmp/.X11-unix -e DISPLAY=$DISPLAY --device $DEVICE --group-add $DEVICE_GRP snake7gun/dlstreamer-yolov8-2023.0 /bin/bash $ source /home/dlstreamer/dlstreamer_gst/scripts/setup_env.sh
左滑查看更多
4、執行多路示例
運行示例,這里可以將 shell 腳本后的視頻文件替換為 IP 攝像頭 RTSP 地址,或是 webcam 的編號。由于gvawatermark模塊在 iGPU 上的性能表現要優于meta_overlay ,而在 dGPU 上則相反,因此這里準備了兩套 pipeline,分別為pipeline-igpu.sh 以及pipeline-dgpu.sh ,大家可以根據自己的硬件環境進行切換。
$ cd dlstreamer_gst/demo/ $ ./pipeline-igpu.sh ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4 ~/TownCentreXVID.mp4
左滑查看更多
效果展示
本方案已經在2023 年度的 Intel Innovation 大會上進行了展示,該 demo 基于英特爾第 12 代酷睿 處理器的 iGPU 平臺,在 9 路 1080p h.265 攝像頭輸入的情況下,保證每路的實時分析性能可以達到 15fps,也就是大部分攝像頭的幀率上限。
審核編輯:湯梓紅
-
英特爾
+關注
關注
61文章
10182瀏覽量
174133 -
視頻
+關注
關注
6文章
1970瀏覽量
73744 -
AI
+關注
關注
88文章
34553瀏覽量
276098 -
模型
+關注
關注
1文章
3500瀏覽量
50112 -
OpenVINO
+關注
關注
0文章
114瀏覽量
428
原文標題:基于 DL Streamer 與 YOLOv8 模型實現多路視頻流實時分析 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于YOLOv8實現自定義姿態評估模型訓練

【愛芯派 Pro 開發板試用體驗】yolov8模型轉換
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

YOLOv8版本升級支持小目標檢測與高分辨率圖像輸入
AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

教你如何用兩行代碼搞定YOLOv8各種模型推理

三種主流模型部署框架YOLOv8推理演示
YOLOv8實現任意目錄下命令行訓練
基于YOLOv8的自定義醫學圖像分割

基于OpenCV DNN實現YOLOv8的模型部署與推理演示
使用NVIDIA JetPack 6.0和YOLOv8構建智能交通應用
RV1126 yolov8訓練部署教程





 工商網監
工商網監
評論