") 淺聊Rust程序內(nèi)存布局
淺聊Rust程序內(nèi)存布局
淺聊Rust程序內(nèi)存布局
內(nèi)存布局看似是底層和距離應(yīng)用程序開發(fā)比較遙遠(yuǎn)的概念集合,但其對(duì)前端應(yīng)用的功能實(shí)現(xiàn)頗具現(xiàn)實(shí)意義。從WASM業(yè)務(wù)模塊至Nodejs N-API插件,無(wú)處不涉及到FFI跨語(yǔ)言互操作。甚至,做個(gè)文本數(shù)據(jù)的字符集轉(zhuǎn)換也得FFI調(diào)用操作系統(tǒng)鏈接庫(kù)libiconv,因?yàn)檫@意味著更小的.exe/.node發(fā)布文件。而C ABI與內(nèi)存布局正是跨(計(jì)算機(jī))語(yǔ)言數(shù)據(jù)結(jié)構(gòu)的基礎(chǔ)。
大約兩個(gè)月前,在封裝FFI閉包(不是函數(shù)指針)過(guò)程中,我重新梳理了Rust內(nèi)存布局知識(shí)點(diǎn)。然后,就有沖動(dòng)寫這么一篇長(zhǎng)文。今恰逢國(guó)慶八天長(zhǎng)假,匯總我之所知與大家分享。開始正文...
存儲(chǔ)寬度size與對(duì)齊位數(shù)alignment— 內(nèi)存布局的核心參數(shù)
變量值在內(nèi)存中的存儲(chǔ)信息包含兩個(gè)重要屬性
首字節(jié)地址address
存儲(chǔ)寬度size
而這兩個(gè)值都不是在分配內(nèi)存那一刻的“即興選擇”。而是,遵循著一組規(guī)則:
address與size都必須是【對(duì)齊位數(shù)alignment】的自然數(shù)倍。比如說(shuō),
對(duì)齊位數(shù)alignment等于1字節(jié)的變量值可保存于任意內(nèi)存地址address上。
對(duì)齊位數(shù)alignment等于2字節(jié)且有效數(shù)據(jù)長(zhǎng)度等于3字節(jié)的變量值
存儲(chǔ)寬度size等于0字節(jié)的變量值可接受任意正整數(shù)作為其對(duì)齊位數(shù)alignment— 慣例是1字節(jié)。
僅能保存于偶數(shù)位的內(nèi)存地址address上。
存儲(chǔ)寬度size也得是4字節(jié) — 從有效長(zhǎng)度3字節(jié)到存儲(chǔ)寬度4字節(jié)的擴(kuò)容過(guò)程被稱作“對(duì)齊”。
對(duì)齊位數(shù)alignment必須是2的自然數(shù)次冪。即,alignment = 2 ^ N且N是? 29的自然數(shù)。
存儲(chǔ)寬度size是有效數(shù)據(jù)長(zhǎng)度加對(duì)齊填充位數(shù)的總和字節(jié)數(shù) — 這一點(diǎn)可能有點(diǎn)兒反直覺(jué)。
address,size與alignment的計(jì)量單位都是“字節(jié)”。
正是因?yàn)閍ddress,size與alignment之間存在倍數(shù)關(guān)系,所以程序?qū)?nèi)存空間的利用一定會(huì)出現(xiàn)冗余與浪費(fèi)。這些被浪費(fèi)掉的“邊角料”則被稱作【對(duì)齊填充alignment padding】。對(duì)齊填充的計(jì)量單位也是字節(jié)。根據(jù)“邊角料”出現(xiàn)的位置不同,對(duì)齊填充alignment padding又分為
小端填充Little-Endian padding—0填充位出現(xiàn)在有效數(shù)據(jù)右側(cè)的低位
大端填充Big-Endian padding—0填充位出現(xiàn)在有效數(shù)據(jù)左側(cè)的高位
文字抽象,圖直觀。一圖抵千詞,請(qǐng)看圖

延伸理解:借助于對(duì)齊位數(shù),物理上一維的線性內(nèi)存被重構(gòu)為了邏輯上N維的存儲(chǔ)空間。不嚴(yán)謹(jǐn)?shù)刂v,一個(gè)數(shù)據(jù)類型 ? 對(duì)應(yīng)一個(gè)對(duì)齊位數(shù)值 ? 按一個(gè)【單位一】將內(nèi)存空間均分一遍 ? 形成一個(gè)僅存儲(chǔ)該數(shù)據(jù)類型值(且只存在于算法與邏輯中)的維度空間。然后,在保存該數(shù)據(jù)類型的新值時(shí),只要
選擇進(jìn)入正確的維度空間
跳過(guò)已被占用的【單位一】(這些【單位一】是在哪一個(gè)維度空間被占用、是被誰(shuí)占用和怎么占用并不重要)
尋找連續(xù)出現(xiàn)且數(shù)量足夠的【單位一】
就行了。
如果【對(duì)齊位數(shù)alignment】與【存儲(chǔ)寬度size】在編譯時(shí)已知,那么該類型就是【靜態(tài)分派】Fixed Sized Type。于是,
類型的對(duì)齊位數(shù)可由std::()讀取
類型的存儲(chǔ)寬度可由std::()讀取
若【對(duì)齊位數(shù)alignment】與【存儲(chǔ)寬度size】在運(yùn)行時(shí)才可計(jì)算知曉,那么該類型就是【動(dòng)態(tài)分派】Dynamic Sized Type。于是,
值的對(duì)齊位數(shù)可由std::(&T)讀取
值的存儲(chǔ)寬度可由std::(&T)讀取
存儲(chǔ)寬度size的對(duì)齊計(jì)算
若變量值的有效數(shù)據(jù)長(zhǎng)度payload_size正好是該變量類型【對(duì)齊位數(shù)alignment】的自然數(shù)倍,那么該變量的【存儲(chǔ)寬度size】就是它的【有效數(shù)據(jù)長(zhǎng)度payload_size】。即,size = payload_size;。 否則,變量的【存儲(chǔ)寬度size】就是既要大于等于【有效數(shù)據(jù)長(zhǎng)度payload_size】,又是【對(duì)齊位數(shù)alignment】自然數(shù)倍的最小數(shù)值。
這個(gè)計(jì)算過(guò)程的偽碼描述是
variable.size = variable.payload_size.next_multiple_of(variable.alignment);
這個(gè)計(jì)算被稱作“(自然數(shù)倍)對(duì)齊”。
簡(jiǎn)單內(nèi)存布局
基本數(shù)據(jù)類型
基本數(shù)據(jù)類型包括bool,u8,i8,u16,i16,u32,i32,u64,i64,u128,i128,usize,isize,f32,f64和char。它們的內(nèi)存布局在不同型號(hào)的設(shè)備上略有差異
在非x86設(shè)備上,存儲(chǔ)寬度size= 對(duì)齊位數(shù)alignment(即,倍數(shù)N = 1)
在x86設(shè)備上,因?yàn)樵O(shè)備允許的最大對(duì)齊位數(shù)不能超過(guò)4字節(jié),所以alignment ? 4 Byte
u64與f64的size = alignment * 2(即,N = 2)。
u128與i128的size = alignment * 4(即,N = 4)。
其它基本數(shù)據(jù)類型依舊size = alignment(即,倍數(shù)N = 1)。
FST瘦指針
瘦指針的內(nèi)存布局與usize類型是一致的。因此,在不同設(shè)備和不同架構(gòu)上,其性能表現(xiàn)略有不同
在非x86的
32位架構(gòu)上,size = alignment = 4 Byte(N = 1)
64位架構(gòu)上,size = alignment = 8 Byte(N = 1)
在x86的
size = 8 Byte
alignment = 4 Byte—x86設(shè)備最大對(duì)齊位數(shù)不能超過(guò)4字節(jié)
N = 2
32位架構(gòu)上,size = alignment = 4 Byte(N = 1)
64位設(shè)備上,
DST胖指針
胖指針的存儲(chǔ)寬度size是usize類型的兩倍,對(duì)齊位數(shù)卻與usize相同。就依賴于設(shè)備/架構(gòu)的性能表現(xiàn)而言,其與瘦指針行為一致:
在非x86的
size = 16 Byte
alignment = 8 Byte
N = 2
size = 8 Byte
alignment = 4 Byte
N = 2
32位架構(gòu)上,
64位架構(gòu)上,
在x86的
size = 16 Byte
alignment = 4 Byte—x86設(shè)備最大對(duì)齊位數(shù)不能超過(guò)4字節(jié)
N = 4
size = 8 Byte
alignment = 4 Byte
N = 2
32位架構(gòu)上,
64位設(shè)備上,
數(shù)組[T; N],切片[T]和str
str就是滿足UTF-8編碼規(guī)范的增強(qiáng)版[u8]切片。 存儲(chǔ)寬度size是全部元素存儲(chǔ)寬度之和
array.size = std::() * array.len(); 對(duì)齊位數(shù)alignment與單個(gè)元素的對(duì)齊位數(shù)一致。
array.alignment = std::();
()單位類型
存儲(chǔ)寬度size=0 Byte 對(duì)齊位數(shù)alignment=1 Byte 所有零寬度數(shù)據(jù)類型都是這樣的內(nèi)存布局配置。 來(lái)自【標(biāo)準(zhǔn)庫(kù)】的零寬度數(shù)據(jù)類型包括但不限于:
()單位類型 — 模擬“空”。
std::PhantomData— 繞過(guò)“泛型類型形參必須被使用”的編譯規(guī)則。進(jìn)而,成就類型狀態(tài)設(shè)計(jì)模式中的Phantom Type。
std::PhantomPinned— 禁止變量值在內(nèi)存中“被挪來(lái)挪去”。進(jìn)而,成就異步編程中的“自引用結(jié)構(gòu)體self-referential struct”。
自定義數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局
復(fù)合數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局描繪了該數(shù)據(jù)結(jié)構(gòu)(緊內(nèi)一層)字段的內(nèi)存位置“擺放”關(guān)系(比如,間隙與次序等)。在層疊嵌套的數(shù)據(jù)結(jié)構(gòu)中,內(nèi)存布局都是就某一層數(shù)據(jù)結(jié)構(gòu)而言的。它既承接不了來(lái)自外層父數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局,也決定不了更內(nèi)層子數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局,更代表不了整個(gè)數(shù)據(jù)結(jié)構(gòu)內(nèi)存布局的總覽。舉個(gè)例子,
#[repr(C)] struct Data { id: u32, name: String } #[repr(C)]僅只代表最外層結(jié)構(gòu)體Data的兩個(gè)字段id和name是按C內(nèi)存布局規(guī)格“擺放”在內(nèi)存中的。但,#[repr(C)]并不意味著整個(gè)數(shù)據(jù)結(jié)構(gòu)都是C內(nèi)存布局的,更改變不了name字段的String類型是Rust內(nèi)存布局的事實(shí)。若你的代碼意圖是定義完全C ABI的結(jié)構(gòu)體,那么【原始指針】才是該用的類型。
use ::{c_char, c_uint}; #[repr(C)] struct Data { id: c_uint, name: *const c_char // 注意對(duì)比 }
內(nèi)存布局核心參數(shù)
自定義數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局包含如下五個(gè)屬性
alignment
定義:數(shù)據(jù)結(jié)構(gòu)自身的對(duì)齊位數(shù)
規(guī)則:
alignment=2的n次冪(n是? 29的自然數(shù))
不同于基本數(shù)據(jù)類型alignment = size,自定義數(shù)據(jù)結(jié)構(gòu)alignment的算法隨不同的數(shù)據(jù)結(jié)構(gòu)而相異。
size
定義:數(shù)據(jù)結(jié)構(gòu)自身的寬度
規(guī)則:size必須是alignment自然數(shù)倍。若有效數(shù)據(jù)長(zhǎng)度payload_size不足size,就添補(bǔ)空白【對(duì)齊填充位】湊足寬度。
field.alignment
定義:每個(gè)字段的對(duì)齊位數(shù)
規(guī)則:field.alignment=2的n次冪(n是? 29的自然數(shù))
field.size
定義:每個(gè)字段的寬度
規(guī)則:field.size必須是field.alignment自然數(shù)倍。若有效數(shù)據(jù)長(zhǎng)度f(wàn)ield.payload_size不足field.size,就添補(bǔ)空白【對(duì)齊填充位】湊足寬度。
field.offset
定義:每個(gè)字段首字節(jié)地址相對(duì)于上一層數(shù)據(jù)結(jié)構(gòu)首字節(jié)地址的偏移字節(jié)數(shù)
規(guī)則:
field.offset必須是field.alignment自然數(shù)倍。若不足,就墊入空白【對(duì)齊填充位】和向后推移當(dāng)前字段的起始位置。
前一個(gè)字段的field.offset + field.size ?后一個(gè)字段的field.offset
自定義枚舉類enum的內(nèi)存布局一般與枚舉類分辨因子discriminant的內(nèi)存布局一致。更復(fù)雜的情況,請(qǐng)見(jiàn)下文章節(jié)。
預(yù)置內(nèi)存布局方案
編譯器內(nèi)置了四款內(nèi)存布局方案,分別是
默認(rèn)Rust內(nèi)存布局 — 沒(méi)有元屬性注釋
C內(nèi)存布局#[repr(C)]
數(shù)字類型·內(nèi)存布局#[repr(u8 / u16 / u32 / u64 / u128 / usize / i8 / i16 / i32 / i64 / i128 / isize)]
僅適用于枚舉類。
支持與C內(nèi)存布局混搭使用。比如,#[repr(C, u8)]。
透明·內(nèi)存布局#[repr(transparent)]
僅適用于單字段數(shù)據(jù)結(jié)構(gòu)。
預(yù)置內(nèi)存布局方案對(duì)比
相較于C內(nèi)存布局,Rust內(nèi)存布局面向內(nèi)存空間利用率做了優(yōu)化— 省內(nèi)存。具體的技術(shù)手段包括Rust編譯器
重排了字段的存儲(chǔ)順序,以盡可能多地消減掉“邊角料”(對(duì)齊填充)占用的字節(jié)位數(shù)。于是,在源程序中字段聲明的詞法次序經(jīng)常不同于【運(yùn)行時(shí)】它們?cè)趦?nèi)存里的實(shí)際存儲(chǔ)順序。
允許多個(gè)零寬度字段共用一個(gè)內(nèi)存地址。甚至,零寬度字段也被允許與普通(有數(shù)據(jù))字段共享內(nèi)存地址。
以C ABI中間格式為橋的C內(nèi)存布局雖然實(shí)現(xiàn)了Rust跨語(yǔ)言數(shù)據(jù)結(jié)構(gòu),但它卻更費(fèi)內(nèi)存。這主要出于兩個(gè)方面原因:
C內(nèi)存布局未對(duì)字段存儲(chǔ)順序做優(yōu)化處理,所以字段在源碼中的詞法順序就是它們?cè)趦?nèi)存條里的存儲(chǔ)順序。于是,若 @程序員 沒(méi)有拿著算草紙和數(shù)著比特位“人肉地”優(yōu)化每個(gè)數(shù)據(jù)結(jié)構(gòu)定義,那么由對(duì)齊填充位冗余造成的內(nèi)存浪費(fèi)不可避免。
C內(nèi)存布局不支持零寬度數(shù)據(jù)類型。零寬度數(shù)據(jù)類型是Rust語(yǔ)言設(shè)計(jì)的重要?jiǎng)?chuàng)新。相比之下,
(參見(jiàn)C17規(guī)范的第6.7.2.1節(jié))無(wú)字段結(jié)構(gòu)體會(huì)導(dǎo)致標(biāo)準(zhǔn)C程序出現(xiàn)U.B.,除非安裝與開啟GNU的C擴(kuò)展。
Cpp編譯器會(huì)強(qiáng)制給無(wú)字段結(jié)構(gòu)體安排一個(gè)字節(jié)寬度,除非該數(shù)據(jù)結(jié)構(gòu)被顯式地標(biāo)記為[[no_unique_address]]。
以費(fèi)內(nèi)存為代價(jià),C內(nèi)存布局賦予Rust數(shù)據(jù)結(jié)構(gòu)的另一個(gè)“超能力”就是:“僅通過(guò)變換【指針類型】就可將內(nèi)存上的一段數(shù)據(jù)重新解讀為另一個(gè)數(shù)據(jù)類型的值”。比如,void * / std::c_void被允許指向任意數(shù)據(jù)類型的變量值例程。但在Rust內(nèi)存布局下,需要調(diào)用專門的標(biāo)準(zhǔn)庫(kù)函數(shù)std::transmute()才能達(dá)到相同的目的。 除了上述鮮明的差別之外,C與Rust內(nèi)存布局都允許【對(duì)齊位數(shù)alignment】參數(shù)被微調(diào),而不一定總是全部字段alignment中的最大值。這包括但不限于:
修飾符align(x)增加alignment至指定值。例如,#[repr(C, align(8))]將C內(nèi)存布局中的【對(duì)齊位數(shù)】上調(diào)至8字節(jié)
修飾符packed(x)減小alignment至指定值。例如,#[repr(packed)]將默認(rèn)Rust內(nèi)存布局中的【對(duì)齊位數(shù)】下調(diào)至1字節(jié)
結(jié)構(gòu)體struct的C內(nèi)存布局
結(jié)構(gòu)體算是最“中規(guī)中矩”的數(shù)據(jù)結(jié)構(gòu)。無(wú)論是否對(duì)結(jié)構(gòu)體的字段重新排序,只要將它們一個(gè)不落地鋪到內(nèi)存上就完成一多半功能了。所以,結(jié)構(gòu)體存儲(chǔ)寬度struct.size是全部字段size之和再(自然數(shù)倍)對(duì)齊于【結(jié)構(gòu)體對(duì)齊位數(shù)struct.alignment】的結(jié)果。有點(diǎn)抽象上偽碼
struct.size = struct.fields().map(|field| field.size).sum() // 第一步,求全部字段寬度值之和 .next_multiple_of(struct.alignment); // 第二步,求既大于等于【寬度值之和】,又是`struct.alignment`自然數(shù)倍的最小數(shù)值 相較于Rust內(nèi)存布局優(yōu)化算法的錯(cuò)綜復(fù)雜,我好似只能講清楚C內(nèi)存布局的始末: 首先,結(jié)構(gòu)體自身的對(duì)齊位數(shù)struct.alignment就是全部字段對(duì)齊位數(shù)field.alignment中的最大值。
struct.alignment = struct.fields().map(|field| field.alignment).max(); 其次,聲明一個(gè)(可修改的)游標(biāo)變量offset_cursor以實(shí)時(shí)跟蹤(參照于結(jié)構(gòu)體首字節(jié)地址的)字節(jié)偏移量。游標(biāo)變量的初始值為0表示該游標(biāo)與結(jié)構(gòu)體的內(nèi)存起始位置重合。
let mut offset_cursor = 0; 接著,沿著源碼中字段的聲明次序,逐一處理各個(gè)字段:
【對(duì)齊】若游標(biāo)變量值offset_cursor不是當(dāng)前字段對(duì)齊位數(shù)field.alignment的自然數(shù)倍(即,未對(duì)齊),就計(jì)算既大于等于offset_cursor又是field.alignment自然數(shù)倍的最小數(shù)值。并將計(jì)算結(jié)果更新入游標(biāo)變量offset_cursor,以插入填充位對(duì)齊和向后推移字段在內(nèi)存中的”擺放“位置。
if offset_cursor.rem_euclid(field.alignment) > 0 { offset_cursor = offset_cursor.next_multiple_of(field.alignment); }
【定位】當(dāng)前游標(biāo)的位置就是該字段的首字節(jié)偏移量
field.offset = offset_cursor;
跳過(guò)當(dāng)前字段寬度f(wàn)ield.size— 遞歸算法求值子數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)寬度。字段子數(shù)據(jù)結(jié)構(gòu)的內(nèi)存布局對(duì)上一層父數(shù)據(jù)結(jié)構(gòu)是黑盒的。
offset_cursor += field.size
繼續(xù)處理下一個(gè)字段。
然后,在結(jié)構(gòu)體內(nèi)全部字段都被如上處理之后,
【對(duì)齊】若游標(biāo)變量值offset_cursor不是結(jié)構(gòu)體對(duì)齊位數(shù)struct.alignment的自然數(shù)倍(即,未對(duì)齊),就計(jì)算既大于等于offset_cursor又是struct.alignment自然數(shù)倍的最小數(shù)值。并將計(jì)算結(jié)果更新入游標(biāo)變量offset_cursor,以增補(bǔ)填充位對(duì)齊和擴(kuò)容有效數(shù)據(jù)長(zhǎng)度至結(jié)構(gòu)體存儲(chǔ)寬度。
if offset_cursor.rem_euclid(struct.alignment) > 0 { offset_cursor = offset_cursor.next_multiple_of(struct.alignment); }
【定位】當(dāng)前游標(biāo)值就是整個(gè)結(jié)構(gòu)體的寬度(含全部對(duì)齊填充位)
struct.size = offset_cursor;
至此,結(jié)構(gòu)體的C內(nèi)存布局結(jié)束。然后,std::GlobalAlloc就能夠拿著這套“策劃案”向操作系統(tǒng)申請(qǐng)內(nèi)存空間去了。由此可見(jiàn),每次【對(duì)齊】處理都會(huì)在有效數(shù)據(jù)周圍“埋入”大量空白“邊角料”(學(xué)名:對(duì)齊填充位alignment padding)。但出于歷史原因,為了完成與其它計(jì)算機(jī)語(yǔ)言的FFI互操作,這些浪費(fèi)還是必須的。下面附以完整的偽碼輔助理解
// 1. 結(jié)構(gòu)體的【對(duì)齊位數(shù)】就是它的全部字段【對(duì)齊位數(shù)】中的最大值。 struct.alignment = struct.fields().map(|field| field.alignment).max(); // 2. 聲明一個(gè)游標(biāo)變量,以實(shí)時(shí)跟蹤(相對(duì)于結(jié)構(gòu)體首字節(jié)地址)的偏移量。 let mut offset_cursor = 0; // 3. 按照字段在源代碼中的詞法聲明次序,逐一遍歷每個(gè)字段。 for field in struct.fields_in_declaration_order() { if offset_cursor.rem_euclid(field.alignment) > 0 { // 4. 需要【對(duì)齊】當(dāng)前字段 offset_cursor = offset_cursor.next_multiple_of(field.alignment); } // 5. 【定位】字段的偏移量就是游標(biāo)變量的最新值。 field.offset = offset_cursor; // 6. 在跳過(guò)當(dāng)前字段寬度的字節(jié)長(zhǎng)度(含對(duì)齊填充字節(jié)數(shù)) offset_cursor += field.size; } if offset_cursor.rem_euclid(struct.alignment) > 0 { // 7. 需要【對(duì)齊】結(jié)構(gòu)體自身 offset_cursor = offset_cursor.next_multiple_of(struct.alignment); } // 8. 【定位】結(jié)構(gòu)體的寬度(含對(duì)齊填充字節(jié)數(shù))就是游標(biāo)變量的最新值。 struct.size = offset_cursor;
聯(lián)合體union的C內(nèi)存布局
形象地講,聯(lián)合體是給內(nèi)存中同一段字節(jié)序列準(zhǔn)備了多套“數(shù)據(jù)視圖”,而每套“數(shù)據(jù)視圖”都嘗試將該段字節(jié)序列解釋為不同數(shù)據(jù)類型的值。所以,無(wú)論在聯(lián)合體內(nèi)聲明了幾個(gè)字段,都僅有一個(gè)字段值會(huì)被保存于物理存儲(chǔ)之上。從原則上講,聯(lián)合體union的內(nèi)存布局一定與占用內(nèi)存最多的字段一致,以確保任何字段值都能被容納。從實(shí)踐上講,有一些細(xì)節(jié)處理需要斟酌:
聯(lián)合體的對(duì)齊位數(shù)union.alignment等于全部字段對(duì)齊位數(shù)中的最大值(同結(jié)構(gòu)體)。
union.alignment = union.fields().map(|field| field.alignment).max();
聯(lián)合體的存儲(chǔ)寬度union.size是最長(zhǎng)字段寬度值longest_field.size(自然數(shù)倍)對(duì)齊于聯(lián)合體自身對(duì)齊位數(shù)union.alignment的結(jié)果。有點(diǎn)抽象上偽碼
union.size = union.fields().map(|field| field.size).max() // 第一步,求最長(zhǎng)字段的寬度值 .next_multiple_of(union.alignment); // 第二步,求既大于等于【最長(zhǎng)字段寬度值】,又是`union.alignment`自然數(shù)倍的最小數(shù)值
舉個(gè)例子,聯(lián)合體Example0內(nèi)包含了u8與u16類型的兩個(gè)字段,那么Example0的內(nèi)存布局就一定與u16的內(nèi)存布局一致。再舉個(gè)例子,
use ::mem; #[repr(C)] union Example1 { f1: u16, f2: [u8; 4], } println!("alignment = {1}; size = {0}", mem::(), mem::()) 看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
字段f1的
存儲(chǔ)寬度size是2字節(jié)。
對(duì)齊位數(shù)alignment也是2字節(jié),因?yàn)榛緮?shù)據(jù)類型的【對(duì)齊位數(shù)alignment】就是它的【存儲(chǔ)寬度size】。
字段f2的
存儲(chǔ)寬度size是4字節(jié),因?yàn)閿?shù)組的【存儲(chǔ)寬度size】就是全部元素存儲(chǔ)寬度之和。
對(duì)齊位數(shù)alignment是1字節(jié),因?yàn)閿?shù)組的【對(duì)齊位數(shù)alignment】就是元素的【對(duì)齊位數(shù)alignment】。
聯(lián)合體Example1的
對(duì)齊位數(shù)alignment就是2字節(jié),因?yàn)槿∽畲笾?/p>
存儲(chǔ)寬度size是4字節(jié),因?yàn)榈萌∽畲笾?/p>
再來(lái)一個(gè)更復(fù)雜點(diǎn)兒的例子,
use ::mem; #[repr(C)] union Example2 { f1: u32, f2: [u16; 3], } println!("alignment = {1}; size = {0}", mem::(), mem::()) 同樣,在看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
字段f1的存儲(chǔ)寬度與對(duì)齊位數(shù)都是4字節(jié)。
字段f2的
對(duì)齊位數(shù)是2字節(jié)。
存儲(chǔ)寬度是6字節(jié)。
聯(lián)合體Example2的
對(duì)齊位數(shù)alignment是4字節(jié) — 取最大值,沒(méi)毛病。
存儲(chǔ)寬度size是8字節(jié),因?yàn)椴粌H得取最大值6字節(jié),還得向Example2.alignment自然數(shù)倍對(duì)齊。于是,才有了額外2字節(jié)的【對(duì)齊填充】和擴(kuò)容【聯(lián)合體】有效長(zhǎng)度6字節(jié)至存儲(chǔ)寬度8字節(jié)。你猜對(duì)了嗎?
不經(jīng)意的巧合
思維敏銳的讀者可以已經(jīng)注意到:單字段【結(jié)構(gòu)體】與單字段【聯(lián)合體】的內(nèi)存布局是相同的,因?yàn)閿?shù)據(jù)結(jié)構(gòu)自身的內(nèi)存布局就是唯一字段的內(nèi)存布局。不信的話,執(zhí)行下面的例程試試
use ::mem; #[repr(C)] struct Example3 { f1: u16 } #[repr(C)] union Example4 { f1: u16 } // struct 內(nèi)存布局 等同于 union 的內(nèi)存布局 assert_eq!(mem::(), mem::()); assert_eq!(mem::(), mem::()); // struct 內(nèi)存布局 等同于 u16 的內(nèi)存布局 assert_eq!(mem::(), mem::()); assert_eq!(mem::(), mem::());
枚舉類enum的C內(nèi)存布局
突破“枚舉”字面含義的束縛,Rust的創(chuàng)新使Rust enum與傳統(tǒng)計(jì)算機(jī)語(yǔ)言中的同類項(xiàng)都不同。Rust枚舉類
既包括:C風(fēng)格的“輕裝”枚舉 — 僅標(biāo)記狀態(tài),卻不記錄細(xì)節(jié)數(shù)據(jù)。
也支持:Rust風(fēng)格的“重裝”枚舉 — 標(biāo)記狀態(tài)的同時(shí)也記錄細(xì)節(jié)數(shù)據(jù)。
在Rust References一書中,
“輕裝”枚舉被稱為“無(wú)字段·枚舉類 field-less enum”或“僅單位類型·枚舉類 unit-only enum”。
“重裝”枚舉被別名為“伴字段·枚舉類enum with fields”。
在Cpp程序中,需要借助【標(biāo)準(zhǔn)庫(kù)】的Tagged Union數(shù)據(jù)結(jié)構(gòu)才能模擬出同類的功能來(lái)。欲了解更多技術(shù)細(xì)節(jié),推薦讀我的另一篇文章。
禁忌:C內(nèi)存布局的枚舉類必須至少包含一個(gè)枚舉值。否則,編譯器就會(huì)報(bào)怨:error[E0084]: unsupported representation for zero-variant enum。
“輕裝”枚舉類的內(nèi)存布局
因?yàn)椤拜p裝”枚舉值的唯一有效數(shù)據(jù)就是“記錄了哪個(gè)枚舉項(xiàng)被選中的”分辨因子discriminant,所以枚舉類的內(nèi)存布局就是枚舉類【整數(shù)類型】分辨因子的內(nèi)存布局。即,
LightEnum.alignment = discriminant.alignment; // 對(duì)齊位數(shù) LightEnum.size = discriminant.size; // 存儲(chǔ)寬度 別慶幸!故事遠(yuǎn)沒(méi)有看起來(lái)這么簡(jiǎn)單,因?yàn)椤菊麛?shù)類】是一組數(shù)字類型的總稱(餒餒的“集合名詞”)。所以,它包含但不限于
| Rust | C | 存儲(chǔ)寬度 |
|---|---|---|
| u8 / i8 | unsigned char / char | 單字節(jié) |
| u16 / i16 | unsigned short / short | 雙字節(jié) |
| u32 / i32 | unsigned int / int | 四字節(jié) |
| u64 / i64 | unsigned long / long | 八字節(jié) |
| usize / isize | 沒(méi)有概念對(duì)等項(xiàng),可能得元編程了 | 等長(zhǎng)于目標(biāo)架構(gòu)“瘦指針”寬度 |
維系FFI兩端Rust和C枚舉類分辨因子都采用相同的整數(shù)類型才是最“坑”的,因?yàn)?/p>
C / Cpp enum實(shí)例可存儲(chǔ)任意類型的整數(shù)值(比如,char,short,int和long)— 部分原因或許是C系語(yǔ)法靈活的定義形式:“typedef enum塊 + 具名常量”。所以,C / Cpp enum非常適合被做成“比特開關(guān)”。但在Rust程序中,就不得不引入外部軟件包bitflags了。
C內(nèi)存布局Rust枚舉類分辨因子discriminant只能是i32類型— 【存儲(chǔ)寬度size】是固定的4字節(jié)。
Rust內(nèi)存布局·枚舉類·分辨因子discriminant的整數(shù)類型是編譯時(shí)由rustc決定的,但最寬支持到isize類型。
這就對(duì)FFI - C端的程序設(shè)計(jì)提出了額外的限制條件:至少,由ABI接口導(dǎo)出的枚舉值得用int類型定義。否則,Rust端FFI函數(shù)調(diào)用就會(huì)觸發(fā)U.B.。FFI門檻稍有上升。 扼要?dú)w納:
FFI - Rust端C內(nèi)存布局的枚舉類對(duì)FFI - C端枚舉值的【整數(shù)類型】提出了“確定性假設(shè)invariant”:枚舉值的整數(shù)類型是int且存儲(chǔ)寬度等于4字節(jié)。
C端 @程序員 必須硬編碼所有枚舉值的數(shù)據(jù)類型,以滿足該假設(shè)。
FFI跨語(yǔ)言互操作才能成功“落地”,而不是發(fā)生U.B.。
來(lái)自C端的遷就固然令人心情愉悅,但新應(yīng)用程序難免要對(duì)接兼容遺留系統(tǒng)與舊鏈接庫(kù)。此時(shí),再給FFI - C端提要求就不那么現(xiàn)實(shí)了 — 深度改動(dòng)“屎山”代碼風(fēng)險(xiǎn)巨大,甚至你可能都沒(méi)有源碼。【數(shù)字類型·內(nèi)存布局】正是解決此棘手問(wèn)題的技術(shù)方案:
以【元屬性】#[repr(整數(shù)類型名)]注釋枚舉類定義
明確指示Rust編譯器采用給定【整數(shù)類型】的內(nèi)存布局,組織【分辨因子discriminant】的數(shù)據(jù)存儲(chǔ),而不總是遵循i32內(nèi)存布局。
從C / Cpp整數(shù)類型至Rust內(nèi)存布局元屬性的映射關(guān)系包括但不限于
| C | Rust 元屬性 |
|---|---|
| unsigned char / char | #[repr(u8)] / #[repr(i8)] |
| unsigned short / short | #[repr(u16)] / #[repr(i16)] |
| unsigned int / int | #[repr(u32)] / #[repr(i32)] |
| unsigned long / long | #[repr(u64)] / #[repr(i64)] |
舉個(gè)例子,
use ::mem; #[repr(C)] enum Example5 { // ”輕裝“枚舉類,因?yàn)?A(), // field-less variant B {}, // field-less variant C // unit variant } println!("alignment = {1}; size = {0}", mem::(), mem::()); 上面代碼定義的是C內(nèi)存布局的“輕裝”枚舉類Example5,因?yàn)樗拿總€(gè)枚舉值不是“無(wú)字段”,就是“單位類型”。于是,Example5的內(nèi)存布局就是i32類型的alignment = size = 4 Byte。 再舉個(gè)例子,
use ::mem; #[repr(u8)] enum Example6 { // ”輕裝“枚舉類,因?yàn)?A(), // field-less variant B {}, // field-less variant C // unit variant } println!("alignment = {1}; size = {0}", mem::(), mem::()); 上面代碼定義的是【數(shù)字類型·內(nèi)存布局】的“輕裝”枚舉類Example6。它的內(nèi)存布局是u8類型的alignment = size = 1 Byte。
“重裝”枚舉類的內(nèi)存布局
【“重裝”枚舉類】絕對(duì)是Rust語(yǔ)言設(shè)計(jì)的一大創(chuàng)新,但同時(shí)也給FFI跨語(yǔ)言互操作帶來(lái)了嚴(yán)重挑戰(zhàn),因?yàn)樵谄渌?jì)算機(jī)語(yǔ)言中沒(méi)有概念對(duì)等的核心語(yǔ)言元素“接得住它”。對(duì)此,在做C內(nèi)存布局時(shí),編譯器rustc會(huì)將【“重裝”枚舉類】“降維”成一個(gè)雙字段結(jié)構(gòu)體:
第一個(gè)字段是:剝?nèi)チ怂凶侄蔚摹尽拜p裝”枚舉】,也稱【分辨因子枚舉類Discriminant enum】。
第二個(gè)字段是:由枚舉值variant內(nèi)字段fields拼湊成的【結(jié)構(gòu)體struct】組成的【聯(lián)合體union】。
前者記錄選中項(xiàng)的“索引值” — 誰(shuí)被選中;后者記憶選中項(xiàng)內(nèi)的值:根據(jù)索引值,以對(duì)應(yīng)的數(shù)據(jù)類型,讀/寫聯(lián)合體實(shí)例的字段值。 文字描述著實(shí)有些晦澀與抽象。邊看下圖,邊再體會(huì)。一圖抵千詞!(關(guān)鍵還是對(duì)union數(shù)據(jù)類型的理解)
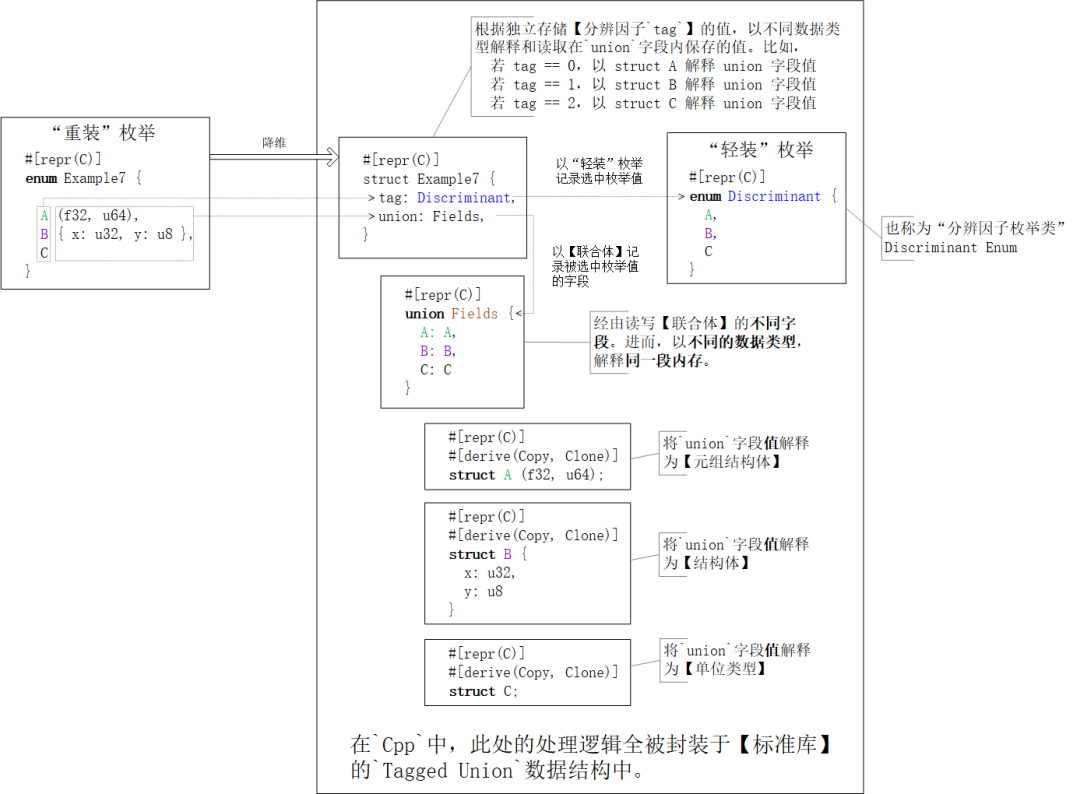
上圖中有三個(gè)很細(xì)節(jié)的知識(shí)點(diǎn)容易被讀者略過(guò),所以在這里特意強(qiáng)調(diào)一下:
保存枚舉值字段的結(jié)構(gòu)體struct A / B / C都既派生了trait Copy,又派生了trait Clone,因?yàn)?/p>
union數(shù)據(jù)結(jié)構(gòu)要求它的每個(gè)字段都是可復(fù)制的
同時(shí),trait Copy又是trait Clone的subtrait
降維后結(jié)構(gòu)體struct Example7內(nèi)的字段名不重要,但字段排列次序很重要。因?yàn)樵贑 ABI中,結(jié)構(gòu)體字段的存儲(chǔ)次序就是它們?cè)谠创a中的聲明次序,所以Cpp標(biāo)準(zhǔn)庫(kù)中的Tagged Union數(shù)據(jù)結(jié)構(gòu)總是,根據(jù)約定的字段次序,
將第一個(gè)字段解釋為“選中項(xiàng)的索引號(hào)”,
將第二個(gè)字段解讀為“選中項(xiàng)的數(shù)據(jù)值”。
C內(nèi)存布局的分辨因子枚舉類enum Discriminant的分辨因子discriminant依舊是i32類型值,所以FFI - C端的枚舉值仍舊被要求采用int整數(shù)類型。
舉個(gè)例子,
use ::mem; #[repr(C)] enum Example8 { Variant0(u8), Variant1, } println!("alignment = {1}; size = {0}", mem::(), mem::()) 看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
enum被“降維”成struct
就C內(nèi)存布局而言,struct的alignment是全部字段alignment中的最大值。
字段union.Variant0是單字段元組結(jié)構(gòu)體,且字段類型是基本數(shù)據(jù)類型。所以,union.Variant0.alignment = union.Variant0.size = 1 Byte
字段union.Variant1是單位類型。所以,union.Variant1.alignment = 1 Byte和union.Variant1.size = 0 Byte
于是,union.alignment = 1 Byte
字段tag是C內(nèi)存布局的“輕裝”枚舉類。所以,tag.alignment = tag.size = 4 Byte
字段union是union數(shù)據(jù)結(jié)構(gòu)。所以,union的alignment也是全部字段alignment中的最大值。
于是,struct.alignment = 4 Byte
struct的size是全部字段size之和。
union.Variant0.size = 1 Byte
union.Variant1.size = 0 Byte
于是,union.size = 1 Byte
字段tag是C內(nèi)存布局的“輕裝”枚舉類。所以,tag.size = 4 Byte
字段union是union數(shù)據(jù)結(jié)構(gòu)。union的size是全部字段size中的最大值。
于是,不精準(zhǔn)地struct.size ≈ 5 Byte(約等)
此刻struct.size并不是struct.alignment的自然數(shù)倍。所以,需要給struct增補(bǔ)“對(duì)齊填充位”和向struct.alignment自然數(shù)倍對(duì)齊
于是,struct.size = 8 Byte(直等)
哎!看見(jiàn)沒(méi),C內(nèi)存布局還是比較費(fèi)內(nèi)存的,一少半都是空白“邊角料”。 【“重裝”枚舉類】同樣會(huì)遇到FFI - ABI兩端【Rust枚舉類分辨因子discriminant】與【C枚舉值】整數(shù)類型一致約定的難點(diǎn)。為了遷就C端遺留系統(tǒng)和舊鏈接庫(kù)對(duì)枚舉值【整數(shù)類型】的選擇,Rust編譯器依舊選擇“降維”處理enum。但,這次不是將enum變形成struct,而是跳過(guò)struct封裝和直接以u(píng)nion為“話事人”。同時(shí),將【分辨因子·枚舉值】作為union字段子數(shù)據(jù)結(jié)構(gòu)的首個(gè)字段:
對(duì)元組枚舉值,分辨因子就是子數(shù)據(jù)結(jié)構(gòu)第0個(gè)元素
對(duì)結(jié)構(gòu)體枚舉值,分辨因子就子數(shù)據(jù)結(jié)構(gòu)第一個(gè)字段。注:字段名不重要,字段次序更重要。
文字描述著實(shí)有些晦澀與抽象。邊看下圖,邊對(duì)比上圖,邊體會(huì)。一圖抵千詞!
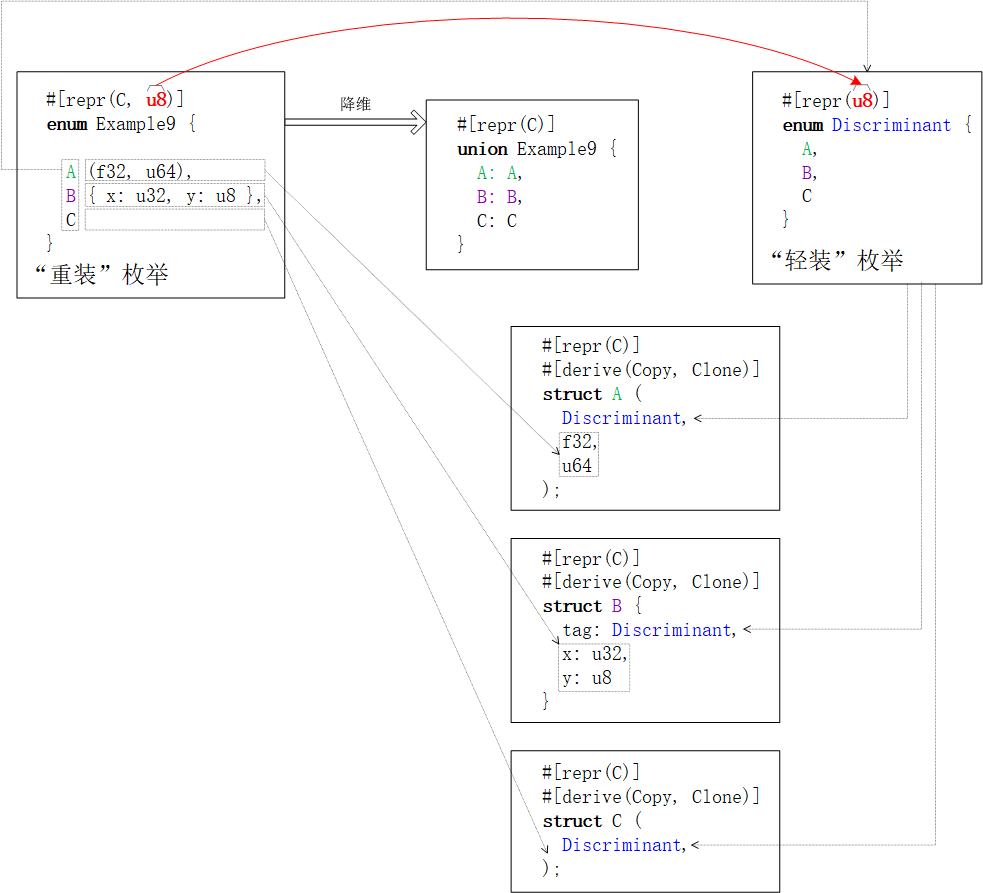
由上圖可見(jiàn),C與【數(shù)字類型】的混合內(nèi)存布局
既保證了降級(jí)后union與struct數(shù)據(jù)結(jié)構(gòu)繼續(xù)滿足C ABI的存儲(chǔ)格式要求。
又確保了【Rust端枚舉類分辨因子】與【C端枚舉值】之間整數(shù)類型的一致性。
舉個(gè)例子,假設(shè)目標(biāo)架構(gòu)是32位系統(tǒng),
use ::mem; #[repr(C, u16)] enum Example10 { Variant0(u8), Variant1, } println!("alignment = {1}; size = {0}", mem::(), mem::()) 看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
enum被“降維”成union
union的alignment是全部字段alignment中的最大值。
第一個(gè)字段是u16類型的分辨因子枚舉值。所以,Variant0.0.alignment = Variant0.0.size = 2 Byte
第二個(gè)字段是u8類型數(shù)字。所以,Variant0.1.alignment = Variant0.1.size = 1 Byte
于是,union.Variant0.alignment = 2 Byte
字段union.Variant0是雙字段元組結(jié)構(gòu)體。所以,struct的alignment是全部字段alignment中的最大值。
字段union.Variant1是單字段元組結(jié)構(gòu)體且唯一字段就是u16分辨因子枚舉值。所以,union.Variant1.alignment = union.Variant1.size = 2 Byte
于是,union.alignment = 2 Byte
union的size是全部字段size中的最大值。
第一個(gè)字段是u16類型的分辨因子枚舉值。所以,Variant0.0.size = 2 Byte
第二個(gè)字段是u8類型數(shù)字。所以,Variant0.1.size = 1 byte
于是,不精準(zhǔn)地union.Variant0.size ≈ 3 Byte(約等)
此刻union.Variant0.size不是union.Variant0.alignment的自然數(shù)倍。所以,需要對(duì)union.Variant0增補(bǔ)“對(duì)齊填充位”和向union.Variant0.alignment自然數(shù)倍對(duì)齊
于是,union.Variant0.size = 4 Byte(直等)
字段union.Variant0是雙字段元組結(jié)構(gòu)體。所以,struct的size是全部字段size之和。
字段union.Variant1是單字段元組結(jié)構(gòu)體且唯一字段就是u16分辨因子枚舉值。所以,union.Variant1.size = 2 Byte
于是,union.size = 4 Byte
哎!看見(jiàn)沒(méi),C 內(nèi)存布局還是比較費(fèi)內(nèi)存的,一少半的“邊角料”。
新設(shè)計(jì)方案好智慧
優(yōu)化掉了一層struct封裝。即,從enum ? struct ? union縮編至enum ? union
將被優(yōu)化掉的struct的職能(— 記錄選中項(xiàng)的“索引值”)合并入了union字段的子數(shù)據(jù)結(jié)構(gòu)中。于是,聯(lián)合體的每個(gè)字段
既要,保存枚舉值的字段數(shù)據(jù) — 舊職能
還要,記錄枚舉值的“索引號(hào)” — 新職能
但有趣的是,比較上一版數(shù)據(jù)存儲(chǔ)設(shè)計(jì)方案,C內(nèi)存布局卻沒(méi)有發(fā)生變化。邏輯描述精簡(jiǎn)了但物理實(shí)質(zhì)未變,這太智慧了!因此,由Cpp標(biāo)準(zhǔn)庫(kù)提供的Tagged Union數(shù)據(jù)結(jié)構(gòu)依舊“接得住”Rust端【“重裝”枚舉值】。
僅【數(shù)字類型·內(nèi)存布局】的“重裝”枚舉類
若不以C加【數(shù)字類型】的混合內(nèi)存布局來(lái)組織枚舉類enum Example9的數(shù)據(jù)存儲(chǔ),而僅保留【數(shù)字類型】?jī)?nèi)存布局,那么上例中被降維后的【聯(lián)合體】與【結(jié)構(gòu)體】就都會(huì)缺省采用Rust內(nèi)存布局。參見(jiàn)下圖:
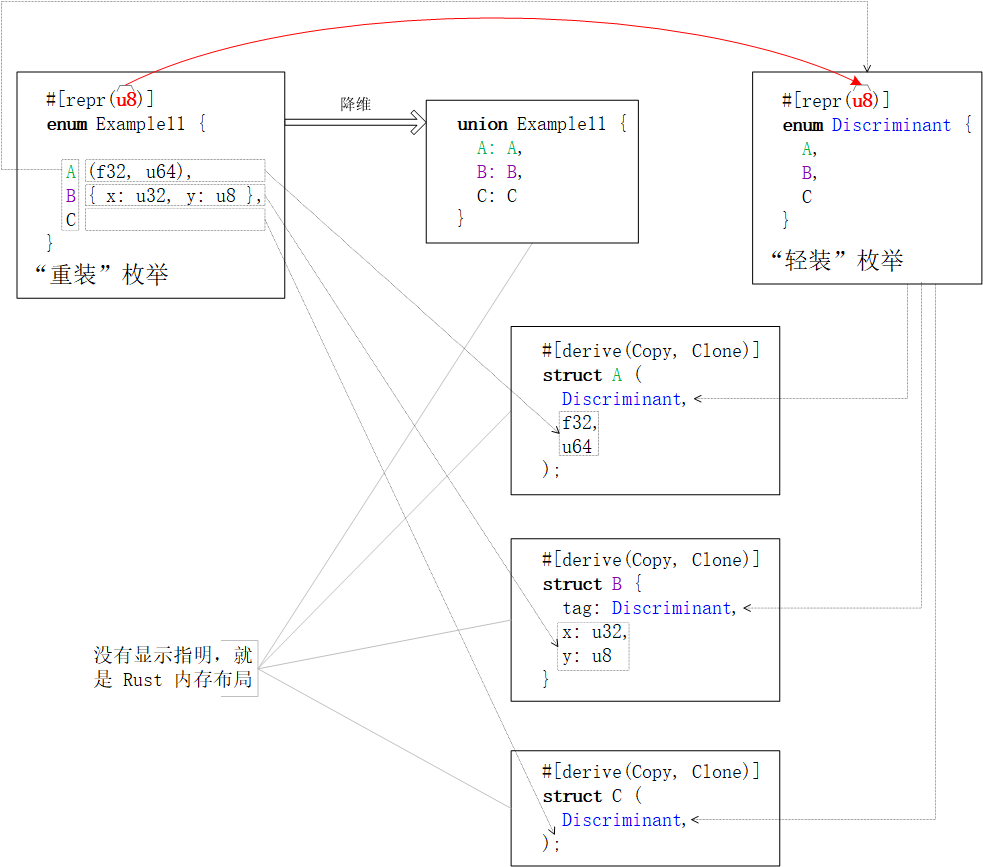
補(bǔ)充于最后,思維活躍的讀者這次千萬(wàn)別想太多了。沒(méi)有#[repr(transparent, u16)]的內(nèi)存布局組合,因?yàn)椤就该鳌?nèi)存布局】向來(lái)都是“孤來(lái)孤往”的。
數(shù)字類型·內(nèi)存布局
僅【枚舉類】支持【數(shù)字類型·內(nèi)存布局】。而且,將無(wú)枚舉值的枚舉類注釋為【數(shù)字類型·內(nèi)存布局】會(huì)導(dǎo)致編譯失敗。舉個(gè)例子
#[repr(u16)] enum Example12 { // 沒(méi)有任何枚舉值 } 會(huì)導(dǎo)致編譯失敗error[E0084]: unsupported representation for zero-variant enum。
透明·內(nèi)存布局
“透明”不是指“沒(méi)有”,而是意味著:在層疊嵌套數(shù)據(jù)結(jié)構(gòu)中,外層數(shù)據(jù)結(jié)構(gòu)的【對(duì)齊位數(shù)】與【存儲(chǔ)寬度】等于(緊)內(nèi)層數(shù)據(jù)結(jié)構(gòu)的【對(duì)齊位數(shù)】和【存儲(chǔ)寬度】。因此,它僅適用于
單字段的結(jié)構(gòu)體 — 結(jié)構(gòu)體的【對(duì)齊位數(shù)】與【存儲(chǔ)寬度】等于唯一字段的【對(duì)齊位數(shù)】和【存儲(chǔ)寬度】。
struct.alignment = struct.field.alignment; struct.size = struct.field.size;
單枚舉值且單字段的“重裝”枚舉類 — 枚舉類的【對(duì)齊位數(shù)】與【存儲(chǔ)寬度】等于唯一枚舉值內(nèi)唯一字段的【對(duì)齊位數(shù)】和【存儲(chǔ)寬度】。
HeavyEnum.alignment = HeavyEnum::variant.field.alignment; HeavyEnum.size = HeavyEnum::variant.field.size;
單枚舉值的“輕裝”枚舉類 — 枚舉類的【對(duì)齊位數(shù)】與【存儲(chǔ)寬度】等于單位類型的【對(duì)齊位數(shù)】和【存儲(chǔ)寬度】。
LightEnum.alignment = 1; LightEnum.size = 0;
原則上,數(shù)據(jù)結(jié)構(gòu)中的唯一字段必須是非零寬度的。但是,若【透明·內(nèi)存布局】數(shù)據(jù)結(jié)構(gòu)涉及到了
類型狀態(tài)設(shè)計(jì)模式
異步多線程
,那么Rust內(nèi)存布局的靈活性也允許:結(jié)構(gòu)體和“重裝”枚舉值額外包含任意數(shù)量的零寬度字段。比如,
std::PhantomData為類型狀態(tài)設(shè)計(jì)模式,提供Phantom Type支持。
std::PhantomPinned為自引用數(shù)據(jù)結(jié)構(gòu),提供!Unpin支持。
舉個(gè)例子,
use ::{marker::PhantomData, mem}; #[repr(transparent)] enum Example13 { // 含`Phantom Type`的“重裝”枚舉類 Variant0 ( f32, // 普通有數(shù)據(jù)字段 PhantomData // 零寬度字段。泛型類型形參未落實(shí)到有效數(shù)據(jù)上。 ) } println!("alignment = {1}; size = {0}", mem::>(), mem::>()) 看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
因?yàn)镋xample14.Variant0.1字段是零寬度數(shù)據(jù)類型PhantomData,所以它的 和不參與內(nèi)存布局計(jì)算。
alignment = 1 Byte
size = 0 Byte
首字節(jié)地址address與Example10.Variant0.0字段重疊。
因?yàn)椤就该鳌?nèi)存布局】,所以 外層枚舉類的
【對(duì)齊位數(shù)】Example14.alignment = Example10::Variant0.0.alignment = 4 Byte
【存儲(chǔ)寬度】Example14.size = Example10::Variant0.0.size = 4 Byte
不同于【數(shù)字類型·內(nèi)存布局】,【透明·內(nèi)存布局】不被允許與其它內(nèi)存布局混合使用。比如,
#[repr(C, u16)]是合法的
#[repr(C, transparent)]和#[repr(transparent, u16)]就會(huì)導(dǎo)致語(yǔ)編譯失敗
其它類型的內(nèi)存布局
trait Object與由胖指針&dyn Trait/Box引用的變量值的【內(nèi)存布局】相同。
閉包Closure沒(méi)有固定的【內(nèi)存布局】。
微調(diào)內(nèi)存布局
只有Rust與C內(nèi)存布局具備微調(diào)能力,且只能修改【對(duì)齊位數(shù)alignment】參數(shù)值。另外,不同數(shù)據(jù)結(jié)構(gòu)可做的微調(diào)操作也略有不同:
struct,union,enum數(shù)據(jù)結(jié)構(gòu)可上調(diào)對(duì)齊位數(shù)
僅struct,union被允許下調(diào)對(duì)齊位數(shù)
數(shù)據(jù)結(jié)構(gòu)【對(duì)齊位數(shù)alignment】值的增加與減少需要使用不同的元屬性修飾符
#[repr(align(新·對(duì)齊位數(shù)))]增加對(duì)齊位數(shù)至新值。將小于等于數(shù)據(jù)結(jié)構(gòu)原本對(duì)齊位數(shù)的值輸入align(x)修飾符是無(wú)效的。
#[repr(packed(新·對(duì)齊位數(shù)))]減少對(duì)齊位數(shù)至新值。將大于等于數(shù)據(jù)結(jié)構(gòu)原本對(duì)齊位數(shù)的值輸入packed(x)修飾符也是無(wú)效的。
align(x)與packed(x)修飾符的實(shí)參是【目標(biāo)】字節(jié)數(shù),而不是【增量】字節(jié)數(shù)。所以,#[repr(align(8))]指示編譯器增加對(duì)齊數(shù)至8字節(jié),而不是增加8字節(jié)。另外,新對(duì)齊位數(shù)必須是2的自然數(shù)次冪。
禁忌
同一個(gè)數(shù)據(jù)類型不被允許既增加又減少對(duì)齊位數(shù)。即,align(x)與packed(x)修飾符不能共同注釋一個(gè)數(shù)據(jù)類型定義。
減小對(duì)齊位數(shù)的外層數(shù)據(jù)結(jié)構(gòu)禁止包含增加對(duì)齊位數(shù)的子數(shù)據(jù)結(jié)構(gòu)。即,#[repr(packed(x))]數(shù)據(jù)結(jié)構(gòu)不允許嵌套包含#[repr(align(y))]子數(shù)據(jù)結(jié)構(gòu)。
枚舉類內(nèi)存布局的微調(diào)
首先,枚舉類不允許下調(diào)對(duì)齊位數(shù)。 其次,上調(diào)枚舉類的對(duì)齊位數(shù)也會(huì)觸發(fā)“內(nèi)存布局重構(gòu)”的負(fù)作用。編譯器會(huì)效仿Newtypes 設(shè)計(jì)模式重構(gòu)#[repr(align(x))] enum枚舉類為嵌套包含了enum的#[repr(align(x))] struct元組結(jié)構(gòu)體。一圖抵千詞,請(qǐng)參閱下圖。
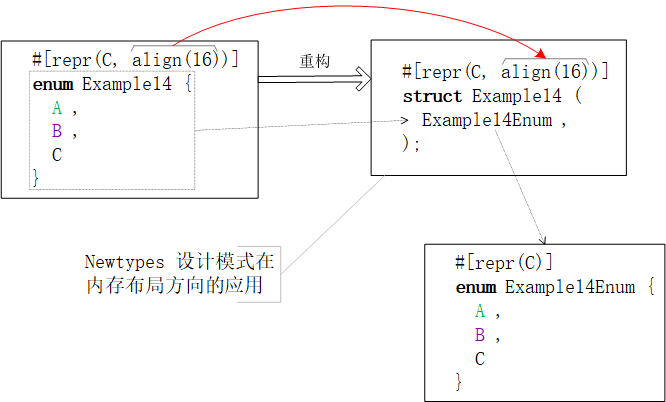
由上圖可見(jiàn),在內(nèi)存布局重構(gòu)之后,C內(nèi)存布局繼續(xù)保留在枚舉類上,而align(16)修飾符僅對(duì)外層的結(jié)構(gòu)體有效。所以,從底層實(shí)現(xiàn)來(lái)講,枚舉類是不支持內(nèi)存布局微調(diào)的,僅能借助外層的Newtypes數(shù)據(jù)結(jié)構(gòu)間接限定。 以上面的數(shù)據(jù)結(jié)構(gòu)為例,
use ::mem; #[repr(C, align(16))] enum Example15 { A, B, C } println!("alignment = {1}; size = {0}", mem::(), mem::()) 看答案之前,不防先心算一下,程序向標(biāo)準(zhǔn)輸出打印的結(jié)果是多少。演算過(guò)程如下:
因?yàn)镃內(nèi)存布局,所以枚舉類的分辨因子是i32類型和枚舉類的存儲(chǔ)寬度size = 4 Byte。
但,align(16)將內(nèi)存空間占用強(qiáng)制地從alignment = size = 4 Byte提升到alignment = size = 16 Byte。
結(jié)束語(yǔ)
這次分享的內(nèi)容比較多,感謝您耐心地讀到文章結(jié)束。文章中問(wèn)答式例程的輸出結(jié)果,您猜對(duì)了幾個(gè)呀? 內(nèi)存布局是一個(gè)非常宏大技術(shù)主題,這篇文章僅是拋磚引玉,講的粒度比較粗,涉及的具體數(shù)據(jù)結(jié)構(gòu)也都很基礎(chǔ)。更多FFI和內(nèi)存布局的實(shí)踐經(jīng)驗(yàn)沉淀與知識(shí)點(diǎn)匯總,我將在相關(guān)技術(shù)線的后續(xù)文章中陸續(xù)分享。
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7638瀏覽量
90352 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3115瀏覽量
75059 -
程序
+關(guān)注
關(guān)注
117文章
3825瀏覽量
82559 -
函數(shù)指針
+關(guān)注
關(guān)注
2文章
57瀏覽量
3950 -
Rust
+關(guān)注
關(guān)注
1文章
233瀏覽量
6987
原文標(biāo)題:程序內(nèi)存布局
文章出處:【微信號(hào):Rust語(yǔ)言中文社區(qū),微信公眾號(hào):Rust語(yǔ)言中文社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何在Rust中使用Memcached
Rust GUI實(shí)踐之Rust-Qt模塊
Rust語(yǔ)言如何與 InfluxDB 集成
如何在Rust中讀寫文件
Rust 語(yǔ)言中的 RwLock內(nèi)部實(shí)現(xiàn)原理
淺談程序的內(nèi)存布局
【原創(chuàng)】聊一聊內(nèi)存指針操作
怎樣去使用Rust進(jìn)行嵌入式編程呢
RUST在嵌入式開發(fā)中的應(yīng)用是什么
Rust原子類型和內(nèi)存排序
Rust語(yǔ)言助力Android內(nèi)存安全漏洞大幅減少
JVM內(nèi)存布局詳解
Rust的內(nèi)部工作原理


Rust開源社區(qū)推出龍架構(gòu)原生適配版本





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論