 內核態?還是用戶態?哪一個更適合TCP/IP協議棧呢?
內核態?還是用戶態?哪一個更適合TCP/IP協議棧呢?
“TCP/IP協議棧到底是內核態的好還是用戶態的好?”
問題的根源在于,干嘛非要這么刻意地去區分什么內核態和用戶態。
引子
為了不讓本文成為干巴巴的說教,在文章開頭,我以一個實例分析開始。
最近一段時間,我幾乎每天深夜都在做一件事,對比mtcp,Linux內核協議棧的收包處理和TCP新建連接的性能,同時還了解了一下騰訊的F-Stack。這里指明,我的mtcp使用的是netmap作為底層支撐,而不是DPDK。
測試過程中,我確認了Linux內核協議棧的scalable問題,并且確認了用戶態協議棧是如何解決這個問題的。然而這并沒有讓我得出用戶態協議棧就一定比內核態協議棧好這么一個明確的結論。
具體怎么講呢?先來看一張圖,這張圖大致描述了我的測試結論:
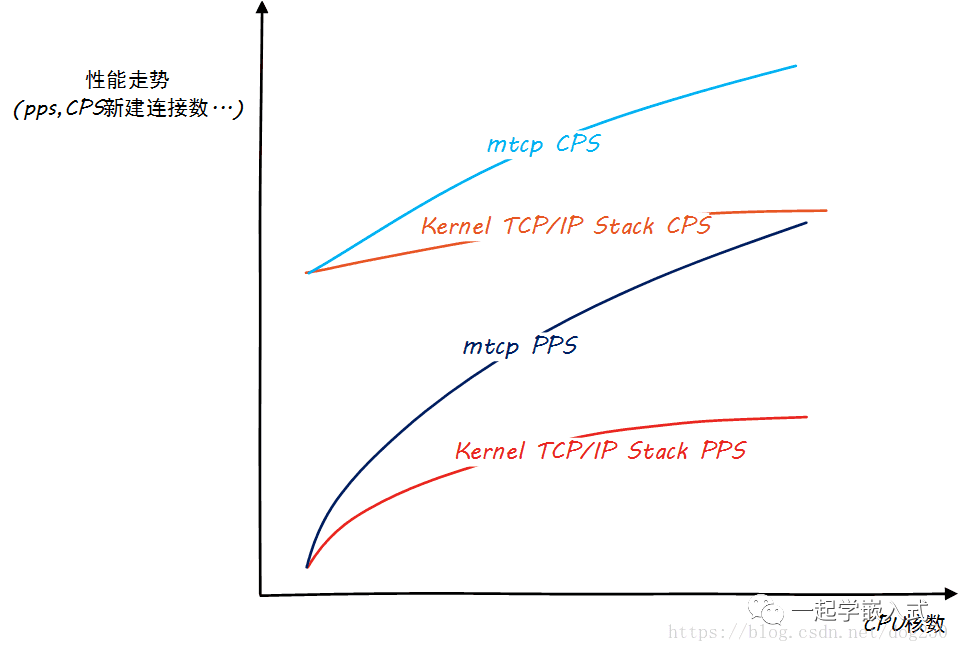
可以看出,Linux內核協議棧存在嚴重的scalable問題(可伸縮性),雖然我們看到用戶態協議棧性能也并非完美地隨著CPU核數的增加而線性擴展,但已經好太多了。 看到這個結論,我們不禁要問,Why?兩個問題:
為什么內核協議棧PPS曲線呈現嚴重上凸?
為什么內核協議棧的CPS(TCP每秒新建連接數)隨著CPU核數的增加幾乎沒有什么變化?
第一個問題好回答,就像《人月神話》里說的一樣,任何事情都不能完美線性擴展,因為溝通需要成本。好吧,當我巧妙繞開第一個問題后,我不得不深度解析第二個問題。
我們知道,Linux內核協議棧會將所有的Listener socket和已經建立連接的establish socket分別鏈接到兩個全局的hash表中,這意味著每一個CPU核都有可能操作這兩張hash表,作為搶占式SMP內核,Linux處理TCP新建連接時加鎖是必須的。
好在如今的新內核的鎖粒度已經細化到了hash slot,這大大提升了性能,然而面對hash到同一個slot的TCP syn請求來講,還是歇菜!
特別嚴重的是,如果用戶態服務器僅僅偵聽一個Nginx 80端口,那么這個機制就相當于一個全局的內核大鎖!對于Listener的slot鎖,那是為多個Listener而優化的(最多INET_LHTABLE_SIZE個bucket,即32個),對于僅有一個Listener的新建連接而言,不會起到任何作用。但是這個只是在頻繁啟停服務+reuseport的時候才會發生,無關我們描述的場景。
對于TCP新建連接測試,很顯然要頻繁操作那張 establish hash 表,握手完成后加鎖插入 hash 表,連接銷毀時加鎖從 hash 表刪除!
問題已經描述清楚了,要揭示答案了。
對于TCP CPS測試而言,會有頻繁的連接創建和鏈接銷毀的過程在執行,映射到代碼,那就是inet_hash和inet_unhash兩個函數會頻繁執行,我們看一下unhash:
void inet_unhash(struct sock *sk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
spinlock_t *lock;
int done;
if (sk_unhashed(sk))
return;
if (sk->sk_state == TCP_LISTEN)
lock = &hashinfo->listening_hash[inet_sk_listen_hashfn(sk)].lock;
else // 多核SMP且高壓力下,難免會有多個socket被hash到同一個slot
lock=inet_ehash_lockp(hashinfo,sk->sk_hash);
spin_lock_bh(lock);//這里是問題的根源
done=__sk_nulls_del_node_init_rcu(sk);
if(done)
sock_prot_inuse_add(sock_net(sk),sk->sk_prot,-1);
spin_unlock_bh(lock);
}
關于hash的過程就不贅述了,同樣會有一個spinlock的串行化過程。
這似乎解釋了為什么內核協議棧的CPS如此之低,但依然沒有解釋為什么內核協議棧的CPS如此不scalable,換句話說,為何其曲線上凸。
從曲線上看,虛線的斜率隨著CPU核數的增加而減小。而曲線的斜率和溝通成本是負相關的。這里的溝通成本就是沖突后的自旋!
不求完全定量化分析,我們只需要證明另外一件事即可,那就是隨著CPU核數的增加,slot沖突將會加劇,從而導致spinlock更加頻繁,即CPU核心和spinlock頻度是正相關的!!
這是顯然的,且這很容易理解。如果我們的hash函數是完美的,那么每一次hash都是不偏不倚的,最終的hash bucket分布將是概率均勻的。CPU核數的增加并不會改變這個結論:
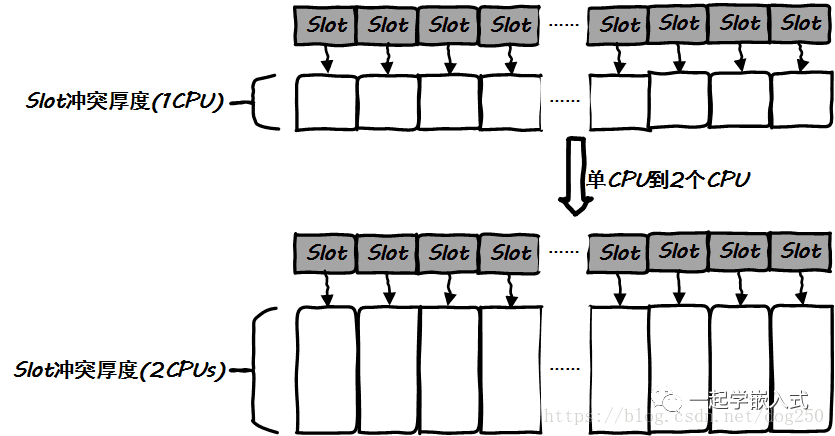
結論是,CPU核數的增加,只會加劇沖突,因此CPU核數越多,spinlock頻度就越高,明顯地二者正相關!spinlock隨著CPU核數的增加而增加,CPU核數增加的收益被同樣增加的spinlock成本完美抵消,所以說,隨著CPU核數的增加,CPS幾乎不會變化。
好了,這就是內核協議棧的缺陷,它能不能改進取決于你的決心,以上的描述沒有任何細節證明在內核態實現協議棧是不好的,相反,它只是證明了Linux內核如此這般的實現方法存在問題,僅此而已。
現在回到Linux內核協議棧CPS問題的spinlock,其也是一個NAK協議,沖突了就等,直到等到,這是一種完全消極的被動應對方式。注定會失去scalable!!
Linux內核里充斥著大量的這種被動邏輯,但卻沒有辦法去優化它們,因為一開始它們就這么存在著。典型的場景就是,TCP短鏈接加上nf_conntrack。二者全部都需要操作全局的spinlock,嗚呼,悲哀!
說一下HTTP。搞底層協議的一般不會太關注HTTP,但是HTTP請求頭里的Connection字段會對性能產生巨大的影響,如果你設置為close,那就意味著服務器在完成任務后就斷開TCP連接,如果你設置為Keep-Alive,就意味著你可以在同一個TCP連接中請求多個HTTP。
但這看起來也不是很有用。作為一個瀏覽器客戶端,誰管你服務器能撐得住多少CPS啊!就算我個人將Connection設置為Keep-Alive,別人不從,又能把他們怎樣?
ACK和NAK
一般認為NAK協議可以最大限度的節約空間,但是卻浪費了時間,然而在帶寬資源非常緊缺的TCP協議誕生伊始,多發一個字節都嫌多,為什么卻選擇了ACK而不是NAK?
答案正是空間換取scalable。后來的事實證明,TCP選擇了ACK,這是一個正確的選擇。
NAK表明你必須被動地等待壞消息,沒有消息就是好消息,但是要等多久呢?不得而知。而ACK的主動報送則可以讓你規劃下一步的動作。
有沒有深夜喝完酒和朋友分開的經歷。我酒量還可以,所以一般都是擔心朋友路上出點什么事情,一般我都會讓朋友到家后發個微信表明自己到家了,這樣我收到他的信息后就能安然入睡了。
如果這個時候用NAK協議會怎樣?對于一個本來就不可信的信道而言,就算他給我打了求救電話也有可能接不通,我要等到什么時候才能確保朋友已經安全到家?
TCP的ACK機制作為時鐘驅動其發送引擎源源不斷地發送數據,最終可以適應各種網絡環境,也正為如此,30多年前的TCP到現在還依然安好(PS:這里并不能讓我釋懷,因為我討厭TCP。我在這里說TCP的好話,僅僅是因為它選擇了ACK而不是NAK這件事是正確的,僅此而已)。
鄙視鏈
把內核態和用戶態做了一個界限分明的區分,于是一條鄙視鏈就形成了,或者說反過來就是是一條膜拜鏈。在內核態寫代碼的鄙視寫應用程序的,寫用戶態代碼的膜拜搞內核的(然后把Java和C都扯進來,搞C的鄙視搞Java的?)。
先不談鄙視鏈,也不談膜拜鏈。只要區分了內核態和用戶態,那么想要實現一個功能的時候,就必然面臨一個選擇,即在什么態實現它。緊接著而來的就是一場論戰,隨便舉幾個例子。
Linux 2.4內核中有個小型的WEB服務器,結果被鄙視了
現如今Facebook搞了個KTLS,旨在把SSL過程放在內核里以支持高性能HTTPS
我自己把OpenVPN數據通道移植進內核,見人就拿這事跟人家炫耀
騰訊F-Stack把BSD協議棧嫁接在用戶態,美其名曰高效,靈活
mtcp貌似也做了同樣的事
微軟的很多網絡服務都實現在內核態
無論怎么搞,套路基本就是原來在內核態實現的,現在移到用戶態,原來在用戶態實現的,現在移到內核態,就這么搞來搞去,其中有的很成功,有的就很失敗。
所謂的成功是因為這個移植解決了特定場景下的特定問題,比如用戶態協議棧的mmap+Polling 模式就解決了協議棧收包PPS吞吐率低的問題,然而很多移植都失敗了,這些失敗的案例很多都是為了移植而移植,故意搗騰的。
請注意,不要被什么用戶態協議棧所誤導,世界上沒有萬金油!
正文
很多人混淆了原因和結果,正如混淆目標和手段一樣常見。
我們都知道,Linux內核協議棧收包吞吐低,然而當你問起Linux內核協議棧為什么這樣時,回答大多是“切換開銷大”,“內存拷貝太多”,“cache miss太高”,“中斷太頻繁”…
但是注意,作為使用協議棧的業務方沒人會關注這些,實際上這些都是原因而不是結果,業務關注的就是收包吞吐低這個事實,為什么吞吐低這正是內核工程人員要查明并搞定的,上面那些關于切換,拷貝,cache miss,中斷之類的描述,其實都是造成收包吞吐低的原因而不是問題本身。
同時,優化掉這些問題并不是目的,目的只有一個,就是提高收包吞吐,優化掉這些問題全部是達到目的的手段。
手段和目的混淆非常常見,這也是為什么很難有手機賣過蘋果手機的原因。看看蘋果的廣告宣傳的是什么,是產品本身,而很多安卓機的廣告都是在拼數據,大肆宣傳什么CPU,內存等硬件采用了什么先進的技術,但是那些買手機拍視頻的網紅懂這些嗎?關注這些嗎?
回到協議棧話題。現在,我們優化的目標只有一個,那就是提高收包吞吐,我們的優化目標并不是什么避免切換,降低cache miss,避免頻繁中斷這些,這些只是達到目標的手段,如果有更好地手段,我們大可不關注這些。
同樣的,把協議棧移來移去的,并不是目標,沒有什么公司會把“將協議棧移植到用戶態”,“在內核態實現HTTP協議”這種作為KPI,這些都是手段而已,把協議棧在內核態用戶態移來移去除了能展示自己高超的水平之外,對整體目標是沒有幫助的。
那么很顯然,如果不用移植,能就地解決問題,那豈不更好?如果我有點石成金的本事,我干嘛還要通過辛勤地工作來讓我的老婆和女兒崇拜我?
接下來就要評估到底是用移植的手段,還是就地解決的手段來解決協議棧收包吞吐低的問題。在評估之前,首先我們要明確問題的原因到底出在哪里。嗯,上面已經列舉了一些了,切換開銷大,內存拷貝昂貴,cache miss高,中斷太頻繁…
原因知道了,自然就能對癥下藥了,現在的問題是,需要評估用戶態和內核態搞定這些問題的可行性,成本以及難度,來決定到底在什么態來解決問題,最終其實會發現用戶態實現一套協議棧是更容易的。
換句話說,如果能在內核態協議棧通過patch的方式解決這些問題,誰也不會去搞用戶態協議棧了。
不是內核態實現協議棧不好,而是內核態解決多核下的收包擴展性問題很難,因為Linux內核設計之初并沒有考慮多核擴展性。一旦面對多核,以下的問題是積重難返的:
任務切換
內存拷貝
CPU跳躍
鎖和中斷
內核,至少是Linux內核沒有提供任何基礎設施來完美解決上述問題,隨著CPU核數越來越多,為了應對上述很多問題將會導致越來越多的trick加入內核,內核將會變得越來越重。
簡而言之,如果能在內核態實現一個穩定的內核線程高效收包,那也并不是不可以,而不是說必須要搞在用戶態。然而,在內核態實現這個確實不易,正是因為用戶態完成同樣的工作更加簡單,才會出現大量的用戶態協議棧。
中斷和輪詢
現在來看一下中斷和輪詢背后的哲學。
中斷本質上是一種節約的思維影響下的產物,典型的“好萊塢法則”之實例。這是讓系統被動接收通知的方式,雖然在主觀上,這種方式可以讓系統“在沒有收到通知時干點別的”,但是在客觀現實看來,這段時間任何系統都沒法一心一意地去做所謂的“別的”。
都面試過吧,如果你不是什么太牛的人,那么一般很難拿到招聘方人員的聯系方式,面試完后一句“回去等通知吧”,會讓多少人能平常心態等通知的同時還能繼續自己的當前工作?(我之前不能,但現在確實可以了,我除外)這個時候,很多人都會想,如果能問一下就好了,然而并不能。
此外,有沒有這樣的經歷,當你專注地想做一件事時,最煩人的就是手機響。此時很多人都會手機靜音且扔遠一點,等事情做完了再去看一下。
對,這就是中斷和輪詢的特征。中斷是外界強加給你的信號,你必須被動應對,而輪詢則是你主動地在處理事情。對于中斷而言,其最大的影響就是打斷你當前工作的連續性,而輪詢則不會,完全在你自己的掌控之中。
對于我自己而言,我的手機基本上是常靜音的,微信則是全部“消息免打擾”,我會選擇在自己idle的時候主動去看手機消息,以此輪詢的方式治療嚴重的電話恐懼癥。
那么如何來治療Linux內核收包的電話恐懼癥呢?答案是暫時沒有辦法。
因為如果想中斷變輪詢,那就必然得有一個內核線程去主動poll網卡,而這種行為與當前的Linux內核協議棧是不相容的,這意味著你要重新在內核實現一套全新的協議棧,面臨著沒完沒了的panic,oops風險。
雖然Linux已經支持socket的busy polling模式,但這也只是緩解,而非根治!相反,完全在用戶態實現poll,則是一個非常干凈的方案。
關于內存拷貝,任務切換以及cache miss,試著用上面的思路去分析,最終的結論依然是在用戶態重新實現一個自主的處理進程,將會比修改內核協議棧的方式來的更加干凈。
幾乎所有的評估結論表明,用戶態協議棧是一個干凈的方案,但卻并不是唯一正確的方案,更沒有證據說用戶態協議棧是最好的方案。選擇在用戶態實現協議棧解決收包吞吐低的問題,完全是因為它比在內核態解決同樣的問題更加容易,僅此而已。
意義
這里聊一個哲學問題。
有人說內核就應該只負責控制平面,數據平面的操作全部應該交給用戶態。
好吧,這里又一個柏拉圖式的分類,實際上依然毫無意義。當然,引出類似概念的人肯定有十足的理由去說服別人相信他的分類是客觀的,有依據的,但那仍然不過是一種主觀的臆斷。
繼續說下去的話,也許最終的結論將是,只有微內核體系的操作系統才是最完美的操作系統。但事實上,我們都在用的幾乎所有操作系統,沒有一個是完全的微內核操作系統,微軟的 Windows 不是,而 Linux 更是一個宏內核系統,沒有微內核系統。
看來似乎只有一個說法能解釋這種矛盾,那就是完美的東西本來就是不存在的,我們看到的世界上所有的東西,都是柏拉圖眼中的影子,而完美則代表了抽象的本質,那是上帝的范疇,我們甚至無力去仰望!從小的時候,我們就被老師告知,世界上不存在完美的球形。
因此,如果微內核,宏內核根本就不存在,那么憑什么內核態就只能處理控制平面呢?如果內核態處理網絡協議棧這種做法是錯誤的,那為什么UNIX/Linux的內核網絡協議棧卻存在了40多年呢?嗯,存在的即是合理的。
世界是進化而來的,而不是設計而來的,即便是存在設計者,也是一個蹩腳的設計者,你看,我們人體本身不就存在很多bug嗎?因此,即便是上帝那里,存在的也是柏拉圖眼里的影子。
審核編輯:劉清
-
HTTP
+關注
關注
0文章
523瀏覽量
32538 -
Cache
+關注
關注
0文章
129瀏覽量
28949 -
DPI
+關注
關注
0文章
39瀏覽量
11683 -
LINUX內核
+關注
關注
1文章
317瀏覽量
22251 -
TCP通信
+關注
關注
0文章
146瀏覽量
4493
原文標題:TCP/IP協議棧在內核態的好還是用戶態的好
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
請問CPU與寄存器,內核態與用戶態及如何切換?
Microchip TCP/IP協議棧
Microchip TCP/IP精簡協議棧
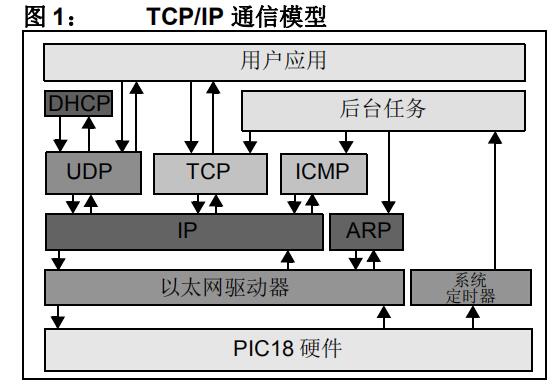
Microchip TCP/IP協議棧






 工商網監
工商網監
評論