") 時(shí)間序列的基礎(chǔ)模型像自然語(yǔ)言處理那樣存在嗎
時(shí)間序列的基礎(chǔ)模型像自然語(yǔ)言處理那樣存在嗎

時(shí)間序列預(yù)測(cè)領(lǐng)域在最近的幾年有著快速的發(fā)展,比如N-BEATS、N-HiTS、PatchTST和TimesNet。
大型語(yǔ)言模型(LLM)最近在ChatGPT等應(yīng)用程序中變得非常流行,因?yàn)樗鼈兛梢赃m應(yīng)各種各樣的任務(wù),而無(wú)需進(jìn)一步的訓(xùn)練。
這就引出了一個(gè)問(wèn)題: 時(shí)間序列的基礎(chǔ)模型能像自然語(yǔ)言處理那樣存在嗎? 一個(gè)預(yù)先訓(xùn)練了大量時(shí)間序列數(shù)據(jù)的大型模型,是否有可能在未見(jiàn)過(guò)的數(shù)據(jù)上產(chǎn)生準(zhǔn)確的預(yù)測(cè)?
通過(guò)Azul Garza和Max Mergenthaler-Canseco提出的 TimeGPT-1 ,作者將llm背后的技術(shù)和架構(gòu)應(yīng)用于預(yù)測(cè)領(lǐng)域,成功構(gòu)建了第一個(gè)能夠進(jìn)行零樣本推理的時(shí)間序列基礎(chǔ)模型。
在本文中,我們將探索TimeGPT背后的體系結(jié)構(gòu)以及如何訓(xùn)練模型。然后,我們將其應(yīng)用于預(yù)測(cè)項(xiàng)目中,以評(píng)估其與其他最先進(jìn)的方法(如N-BEATS, N-HiTS和PatchTST)的性能。
TimeGPT
TimeGPT是為時(shí)間序列預(yù)測(cè)創(chuàng)建基礎(chǔ)模型的第一次嘗試。
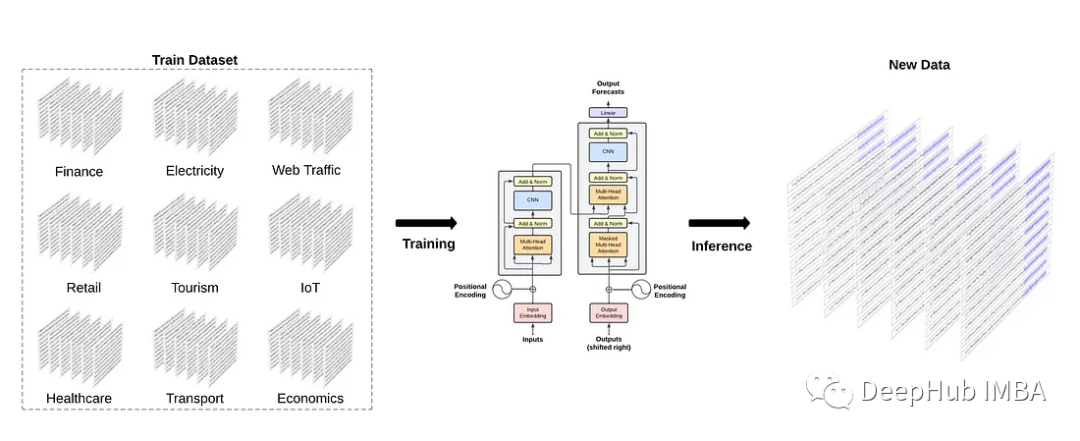
從上圖中,我們可以看到TimeGPT背后的一般思想是在來(lái)自不同領(lǐng)域的大量數(shù)據(jù)上訓(xùn)練模型,然后對(duì)未見(jiàn)過(guò)的數(shù)據(jù)產(chǎn)生零樣本的推斷。
這種方法依賴(lài)于遷移學(xué)習(xí),遷移學(xué)習(xí)是指模型利用在訓(xùn)練過(guò)程中獲得的知識(shí)解決新任務(wù)的能力。這種方式只有當(dāng)模型足夠大,并且在大量數(shù)據(jù)上進(jìn)行訓(xùn)練時(shí)才有效。
為此,作者對(duì)TimeGPT進(jìn)行了超過(guò)1000億個(gè)數(shù)據(jù)點(diǎn)的訓(xùn)練,這些數(shù)據(jù)點(diǎn)都來(lái)自開(kāi)源的時(shí)間序列數(shù)據(jù)。該數(shù)據(jù)集涵蓋了廣泛的領(lǐng)域,從金融、經(jīng)濟(jì)和天氣,到網(wǎng)絡(luò)流量、能源和銷(xiāo)售。
但是這里作者沒(méi)有披露用于管理1000億個(gè)數(shù)據(jù)點(diǎn)的公共數(shù)據(jù)的來(lái)源。
這種多樣性對(duì)于基礎(chǔ)模型的成功至關(guān)重要,因?yàn)樗梢詫W(xué)習(xí)不同的時(shí)間模式,因此可以更好地進(jìn)行泛化。
例如,我們可以預(yù)期天氣數(shù)據(jù)具有日季節(jié)性(白天比晚上熱)和年季節(jié)性,而汽車(chē)交通數(shù)據(jù)可以具有日季節(jié)性(白天路上的汽車(chē)比晚上多)和周季節(jié)性(一周內(nèi)路上的汽車(chē)比周末多)。
為了保證模型的魯棒性和泛化能力,預(yù)處理被保持在最低限度。事實(shí)上只有缺失的值被填充,其余的保持原始形式。雖然作者沒(méi)有具體說(shuō)明數(shù)據(jù)輸入的方法,但我懷疑使用了某種插值技術(shù),如線性、樣條或移動(dòng)平均插值。
然后作者對(duì)模型進(jìn)行多天的訓(xùn)練,在此期間對(duì)超參數(shù)和學(xué)習(xí)率進(jìn)行優(yōu)化。雖然作者沒(méi)有透露訓(xùn)練需要多少天和gpu資源,但我們確實(shí)知道該模型是在PyTorch中實(shí)現(xiàn)的,并且它使用Adam優(yōu)化器和學(xué)習(xí)率衰減策略。
TimeGPT利用Transformer架構(gòu)。

從上圖中,我們可以看到TimeGPT使用了完整的編碼器-解碼器Transformer架構(gòu)。
輸入可以包括歷史數(shù)據(jù)窗口,也可以包括外生數(shù)據(jù)窗口,如準(zhǔn)時(shí)事件或其他系列。
輸入被饋送到模型的編碼器部分。然后編碼器內(nèi)部的注意力機(jī)制從輸入中學(xué)習(xí)不同的屬性。然后將其輸入解碼器,解碼器使用學(xué)習(xí)到的信息進(jìn)行預(yù)測(cè)。預(yù)測(cè)序列在達(dá)到用戶設(shè)置的預(yù)測(cè)范圍長(zhǎng)度時(shí)結(jié)束。
值得注意的是,作者已經(jīng)在TimeGPT中實(shí)現(xiàn)了適形預(yù)測(cè),允許模型根據(jù)歷史誤差估計(jì)預(yù)測(cè)間隔。
考慮到TimeGPT是為時(shí)間序列構(gòu)建基礎(chǔ)模型的第一次嘗試,它具有一系列廣泛的功能。
TimeGPT的功能總結(jié):
首先 ,TimeGPT是一個(gè)預(yù)先訓(xùn)練的模型,這意味著可以生成預(yù)測(cè),而不需要對(duì)數(shù)據(jù)進(jìn)行特定的訓(xùn)練。盡管如此,還是可以根據(jù)我們的數(shù)據(jù)對(duì)模型進(jìn)行微調(diào)。
其次 ,該模型支持外生變量來(lái)預(yù)測(cè)我們的目標(biāo),也就是說(shuō)可以處理多變量預(yù)測(cè)任務(wù)。
最后 ,使用保形預(yù)測(cè),TimeGPT可以估計(jì)預(yù)測(cè)區(qū)間。這反過(guò)來(lái)又允許模型執(zhí)行異常檢測(cè)。如果一個(gè)數(shù)據(jù)點(diǎn)落在99%的置信區(qū)間之外,那么模型將其標(biāo)記為異常。
所有這些任務(wù)都可以通過(guò)零樣本推理或一些微調(diào)來(lái)實(shí)現(xiàn),這是時(shí)間序列預(yù)測(cè)領(lǐng)域范式的根本轉(zhuǎn)變。
現(xiàn)在我們對(duì)TimeGPT有了更扎實(shí)的了解,了解了它是如何工作的,以及它是如何訓(xùn)練的,讓我們來(lái)看看實(shí)際的模型。
TimeGPT進(jìn)行預(yù)測(cè)
現(xiàn)在讓我們將TimeGPT應(yīng)用于預(yù)測(cè)任務(wù),并將其性能與其他模型進(jìn)行比較。
在撰寫(xiě)本文時(shí),TimeGPT只能通過(guò)API訪問(wèn),并且還處于封閉測(cè)試階段。我提交申請(qǐng),并獲得了免費(fèi)使用該模型兩周的授權(quán)。
如前所述,該模型是在來(lái)自公開(kāi)可用數(shù)據(jù)的1000億個(gè)數(shù)據(jù)點(diǎn)上進(jìn)行訓(xùn)練的。由于作者沒(méi)有指定使用的實(shí)際數(shù)據(jù)集,我認(rèn)為在已知的基準(zhǔn)數(shù)據(jù)集(如ETT或weather)上測(cè)試模型是不合理的,因?yàn)槟P涂赡茉谟?xùn)練期間看到了這些數(shù)據(jù)。
因此,我使用了自己的數(shù)據(jù)集,數(shù)據(jù)集現(xiàn)在在GitHub上公開(kāi)可用,最重要的是TimeGPT沒(méi)有在這些數(shù)據(jù)上進(jìn)行訓(xùn)練。
導(dǎo)入庫(kù)并讀取數(shù)據(jù)
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, NBEATS, PatchTST
from neuralforecast.losses.numpy import mae, mse
from nixtlats import TimeGPT
%matplotlib inline
然后,為了訪問(wèn)TimeGPT模型從文件中讀取API密鑰。
with open("data/timegpt_api_key.txt", 'r') as file:
API_KEY = file.read()
然后讀取數(shù)據(jù)。
df = pd.read_csv('data/medium_views_published_holidays.csv')
df['ds'] = pd.to_datetime(df['ds'])
df.head()

從上圖中,我們可以看到數(shù)據(jù)集的格式與我們使用Nixtla的其他開(kāi)源庫(kù)時(shí)的格式相同。
我們有一個(gè)unique_id列來(lái)標(biāo)記不同的時(shí)間序列,但在本例中,我們只有一個(gè)序列。
y列表示我的博客每天的瀏覽量,published是一個(gè)簡(jiǎn)單的標(biāo)志,用來(lái)標(biāo)記某一天有新文章發(fā)布(1)或沒(méi)有文章發(fā)布(0)。一般來(lái)說(shuō)當(dāng)新內(nèi)容發(fā)布時(shí),瀏覽量通常會(huì)增加一段時(shí)間。
最后,列is_holiday表示美國(guó)是否有假日。在假期很少有人會(huì)訪問(wèn)。
現(xiàn)在讓我們把我們的數(shù)據(jù)可視化。
published_dates = df[df['published'] == 1]
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df['ds'], df['y'])
ax.scatter(published_dates['ds'], published_dates['y'], marker='o', color='red', label='New article')
ax.set_xlabel('Day')
ax.set_ylabel('Total views')
ax.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()

從上圖中,我們可以看到一些有趣的行為。首先,紅點(diǎn)表示新發(fā)表的文章,并且?guī)缀蹙o隨其后的是訪問(wèn)高峰。
我們還注意到2021年的活動(dòng)減少,這反映在日瀏覽量減少上。最后在2023年,我們注意到一篇文章發(fā)表后,訪問(wèn)量出現(xiàn)了一些異常高峰。
放大數(shù)據(jù),我們還發(fā)現(xiàn)了明顯的每周季節(jié)性。

從上圖中,可以看到周末訪問(wèn)的訪客比平時(shí)少。
考慮到所有這些,讓我們看看如何使用TimeGPT進(jìn)行預(yù)測(cè)。
首先,將數(shù)據(jù)集分成訓(xùn)練集和測(cè)試集。在這里為測(cè)試集保留168個(gè)時(shí)間步長(zhǎng),這對(duì)應(yīng)于24周的每日數(shù)據(jù)。
train = df[:-168]
test = df[-168:]
然后使用7天的預(yù)測(cè)范圍,因?yàn)槲覍?duì)預(yù)測(cè)整個(gè)星期的每日視圖感興趣。
該API沒(méi)有附帶驗(yàn)證的實(shí)現(xiàn)。因此我們創(chuàng)建自己的循環(huán),一次生成七個(gè)預(yù)測(cè),直到我們對(duì)整個(gè)測(cè)試集進(jìn)行預(yù)測(cè)。
future_exog = test[['unique_id', 'ds', 'published', 'is_holiday']]
timegpt = TimeGPT(token=API_KEY)
timegpt_preds = []
for i in range(0, 162, 7):
timegpt_preds_df = timegpt.forecast(
df=df.iloc[:1213+i],
X_df = future_exog[i:i+7],
h=7,
finetune_steps=10,
id_col='unique_id',
time_col='ds',
target_col='y'
)
preds = timegpt_preds_df['TimeGPT']
timegpt_preds.extend(preds)
在上面的代碼塊中必須傳遞外生變量的未來(lái)值,因?yàn)樗鼈兪庆o態(tài)變量,我們知道未來(lái)假期的日期,
這里我們還使用finetune_steps參數(shù)對(duì)TimeGPT進(jìn)行了微調(diào)。
一旦循環(huán)完成就可以將預(yù)測(cè)結(jié)果添加到測(cè)試集中。TimeGPT一次生成7個(gè)預(yù)測(cè),直到獲得168個(gè)預(yù)測(cè),因此我們可以評(píng)估它預(yù)測(cè)下周每日瀏覽量的能力。
test['TimeGPT'] = timegpt_preds
test.head()

與N-BEATS, N-HiTS和PatchTST對(duì)比
現(xiàn)在我們用其他方法來(lái)進(jìn)行對(duì)比,這里使用了N-BEATS, N-HiTS和PatchTST。
horizon = 7
models = [NHITS(h=horizon,
input_size=5*horizon,
max_steps=50),
NBEATS(h=horizon,
input_size=5*horizon,
max_steps=50),
PatchTST(h=horizon,
input_size=5*horizon,
max_steps=50)]
然后,我們初始化NeuralForecast對(duì)象并指定數(shù)據(jù)的頻率,在本例中是每天。
nf = NeuralForecast(models=models, freq='D')
在7個(gè)時(shí)間步驟的24個(gè)窗口上運(yùn)行執(zhí)行驗(yàn)證,以獲得與用于TimeGPT的測(cè)試集一致的預(yù)測(cè)。
preds_df = nf.cross_validation(
df=df,
static_df=future_exog ,
step_size=7,
n_windows=24
)
然后合并結(jié)果,這樣就得到了一個(gè)包含所有模型預(yù)測(cè)的單一DataFrame。
preds_df['TimeGPT'] = test['TimeGPT']

下面開(kāi)始評(píng)估每個(gè)模型的性能。在度量性能指標(biāo)之前,可視化一下測(cè)試集中每個(gè)模型的預(yù)測(cè)。

每個(gè)模型之間有很多重疊。我們確實(shí)注意到N-HiTS預(yù)測(cè)的兩個(gè)峰值在現(xiàn)實(shí)中沒(méi)有實(shí)現(xiàn)。此外PatchTST似乎經(jīng)常預(yù)測(cè)不足。但是TimeGPT似乎通常與實(shí)際數(shù)據(jù)重疊得很好。
但是評(píng)估每個(gè)模型性能的唯一方法是度量性能指標(biāo)。在這里使用平均絕對(duì)誤差(MAE)和均方誤差(MSE)。另外我們做的一個(gè)動(dòng)作是將預(yù)測(cè)四舍五入為整數(shù),因?yàn)樾?shù)在每日訪問(wèn)量上下文中是沒(méi)有意義的。
preds_df = preds_df.round({
'NHITS': 0,
'NBEATS': 0,
'PatchTST': 0,
'TimeGPT': 0
})
data = {'N-HiTS': [mae(preds_df['NHITS'], preds_df['y']), mse(preds_df['NHITS'], preds_df['y'])],
'N-BEATS': [mae(preds_df['NBEATS'], preds_df['y']), mse(preds_df['NBEATS'], preds_df['y'])],
'PatchTST': [mae(preds_df['PatchTST'], preds_df['y']), mse(preds_df['PatchTST'], preds_df['y'])],
'TimeGPT': [mae(preds_df['TimeGPT'], preds_df['y']), mse(preds_df['TimeGPT'], preds_df['y'])]}
metrics_df = pd.DataFrame(data=data)
metrics_df.index = ['mae', 'mse']
metrics_df.style.highlight_min(color='lightgreen', axis=1)

從上圖中可以看到TimeGPT是表現(xiàn)最好,它實(shí)現(xiàn)了最低的MAE和MSE,其次是N-BEATS, PatchTST和N-HiTS。
這是一個(gè)令人興奮的結(jié)果,因?yàn)門(mén)imeGPT從未見(jiàn)過(guò)這個(gè)數(shù)據(jù)集,并且只進(jìn)行了幾個(gè)步驟的微調(diào)。雖然這不是一個(gè)詳盡的實(shí)驗(yàn),但我相信它確實(shí)展示了潛在的基礎(chǔ)模型在預(yù)測(cè)領(lǐng)域的潛力。
對(duì)TimeGPT的看法
TimeGPT是時(shí)間序列預(yù)測(cè)的第一個(gè)基礎(chǔ)模型。它利用了Transformer架構(gòu),并在1000億個(gè)數(shù)據(jù)點(diǎn)上進(jìn)行了預(yù)訓(xùn)練,以便對(duì)新的未見(jiàn)過(guò)的數(shù)據(jù)進(jìn)行零樣本推斷。該模型結(jié)合保形預(yù)測(cè)技術(shù),無(wú)需特定數(shù)據(jù)集的訓(xùn)練即可生成預(yù)測(cè)區(qū)間并進(jìn)行異常檢測(cè)。
雖然TimeGPT的簡(jiǎn)短實(shí)驗(yàn)證明是令人興奮的,但原始論文在許多重要概念仍然含糊不清。
比如我們不知道使用了哪些數(shù)據(jù)集來(lái)訓(xùn)練和測(cè)試模型,因此我們無(wú)法真正驗(yàn)證TimeGPT的性能結(jié)果,如下所示。

從上表中可以看到TimeGPT在每月和每周頻率上表現(xiàn)最好,N-HiTS和TFT通常排名第二或第三。因?yàn)槲覀儾恢朗褂昧耸裁磾?shù)據(jù),所以我們無(wú)法驗(yàn)證這些指標(biāo)。
雖然TimeGPT看起來(lái)很好,但是它還是有2個(gè)問(wèn)題要面對(duì):
1、 當(dāng)涉及到如何訓(xùn)練模型以及如何調(diào)整模型來(lái)處理時(shí)間序列數(shù)據(jù)時(shí)缺乏透明度,可以認(rèn)為是沒(méi)有任何的可解釋性。
2、 這個(gè)模型是用于商業(yè)用途的,這也就是為什么論文缺少細(xì)節(jié),無(wú)法讓人通過(guò)論文來(lái)復(fù)制TimeGPT。當(dāng)然這并沒(méi)有錯(cuò),因?yàn)楫吘故且嶅X(qián)的。但這就導(dǎo)致論文缺乏可重復(fù)性,沒(méi)人或再去研究和改進(jìn)他。
雖然是這樣,但是我還是覺(jué)得這能激發(fā)時(shí)間序列基礎(chǔ)模型的新工作和研究,并且我們最終能看到這些模型的開(kāi)源版本,就像我們?cè)贚LM中看到的那樣。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7256瀏覽量
91869 -
模型
+關(guān)注
關(guān)注
1文章
3521瀏覽量
50424 -
應(yīng)用程序
+關(guān)注
關(guān)注
38文章
3337瀏覽量
59038 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14157
發(fā)布評(píng)論請(qǐng)先 登錄
python自然語(yǔ)言
自然語(yǔ)言處理技術(shù)介紹
自然語(yǔ)言處理怎么最快入門(mén)?
【推薦體驗(yàn)】騰訊云自然語(yǔ)言處理

自然語(yǔ)言處理怎么最快入門(mén)_自然語(yǔ)言處理知識(shí)了解
自然語(yǔ)言處理的優(yōu)點(diǎn)有哪些_自然語(yǔ)言處理的5大優(yōu)勢(shì)
基于深度學(xué)習(xí)的自然語(yǔ)言處理對(duì)抗樣本模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論