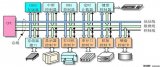
 內存內核中發生頁面遷移的典型場景
內存內核中發生頁面遷移的典型場景
1. 概述
頁面遷移(page migrate)最早是為NUMA系統提供一種將進程頁面遷移到指定內存節點的能力用來提升訪問性能。后來在內核中廣泛被使用,如內存規整、CMA、內存hotplug等。
頁面遷移對上層應用業務來說是不可感知的,因為其遷移的是物理頁面,而應用只訪問的是虛擬內存。內核遷移完成后,更新修改對應頁表指向遷移后的頁面即可。當然了這里說的不可感知是指業務不太關注,也不需要做對應修改。實際上有些場景發生頁面遷移是業務性能是有影響的,下面會詳細描述。
2. 典型場景
我們列舉2個內核中發生頁面遷移的典型場景。
2.1 NUMA Balancing引起的頁面遷移
在典型 NUMA 中,存在多個 node, 本地 CPU 訪問本地 node 節點對應的 memory 性能會快一些。
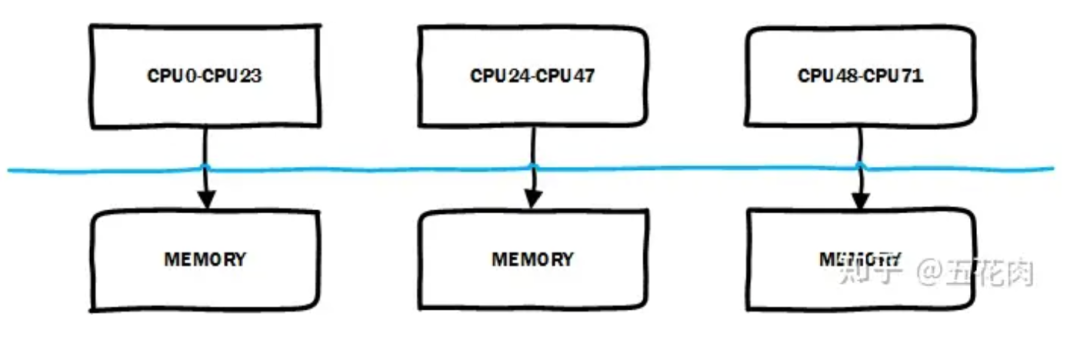
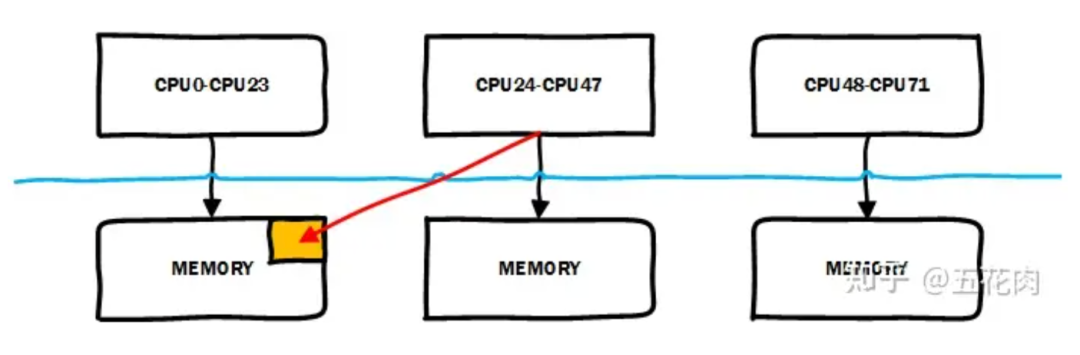
Linux 的 NUMA 自動均衡機制會嘗試將內存遷移到正在訪問它的 CPU 節點所在的 node。如下圖所示,CPU24 ~ CPU47訪問不是本地 node 對應的 memory,性能會比較慢,系統會將其遷移到本地 node 對應的 memory 以提升訪問性能。
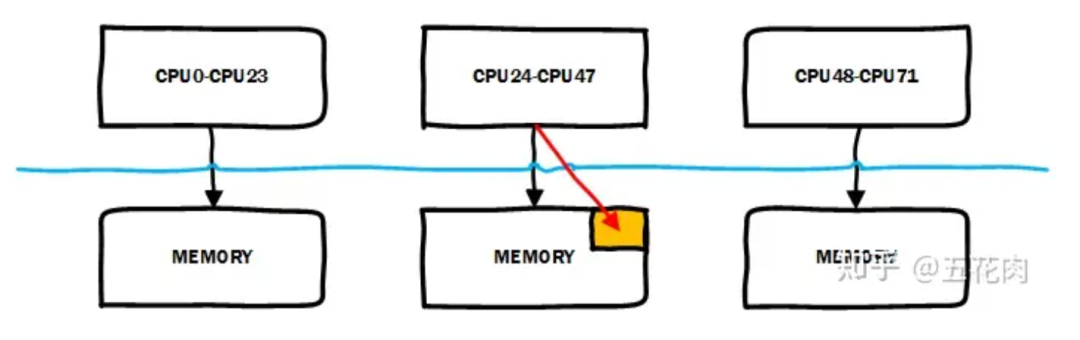
遷移后如下圖:
2.2 內存碎片整理
系統使用一段時候后,由于內存碎片的原因,較難滿足連續內存需求,如果需要分配連續大塊內存,需要進行內存規整以形成大塊連續內存,頁面遷移是內存碎片整理的基礎。
3. 實現分析
3.1 遷移模式
內核中通過接口migrate_pages實現頁而遷移, 分為3個模式。
| 模式 | 簡介 | 應用場景 |
|---|---|---|
| MIGRATE_ASYNC | 異步遷移,過程中不會發生阻塞 | 內存分配slowpath |
| MIGRATE_SYNC_LIGHT | 輕度同步遷移,允許大部分的阻塞操作,唯獨不允許臟頁的回寫操作 | kcompactd觸發的規整 |
| MIGRATE_SYNC | 同步遷移,遷移過程會發生阻塞,若需要遷移的某個page正在writeback或被locked會等待它完成 | sysfs主動觸發的內存規整 |
| MIGRATE_SYNC_NO_COPY | 同步遷移,但不等待頁面的拷貝過程。頁面的拷貝通過回調migratepage(),過程可能會涉及DMA | migrate_vma_pages |
3.2 實現流程
內核文檔有描述這個API是怎么工作的。不過這個描述著實是不太友好, 不容易在腦海形成畫面。

我們通過結合代碼實現,把這個轉化為流程圖:
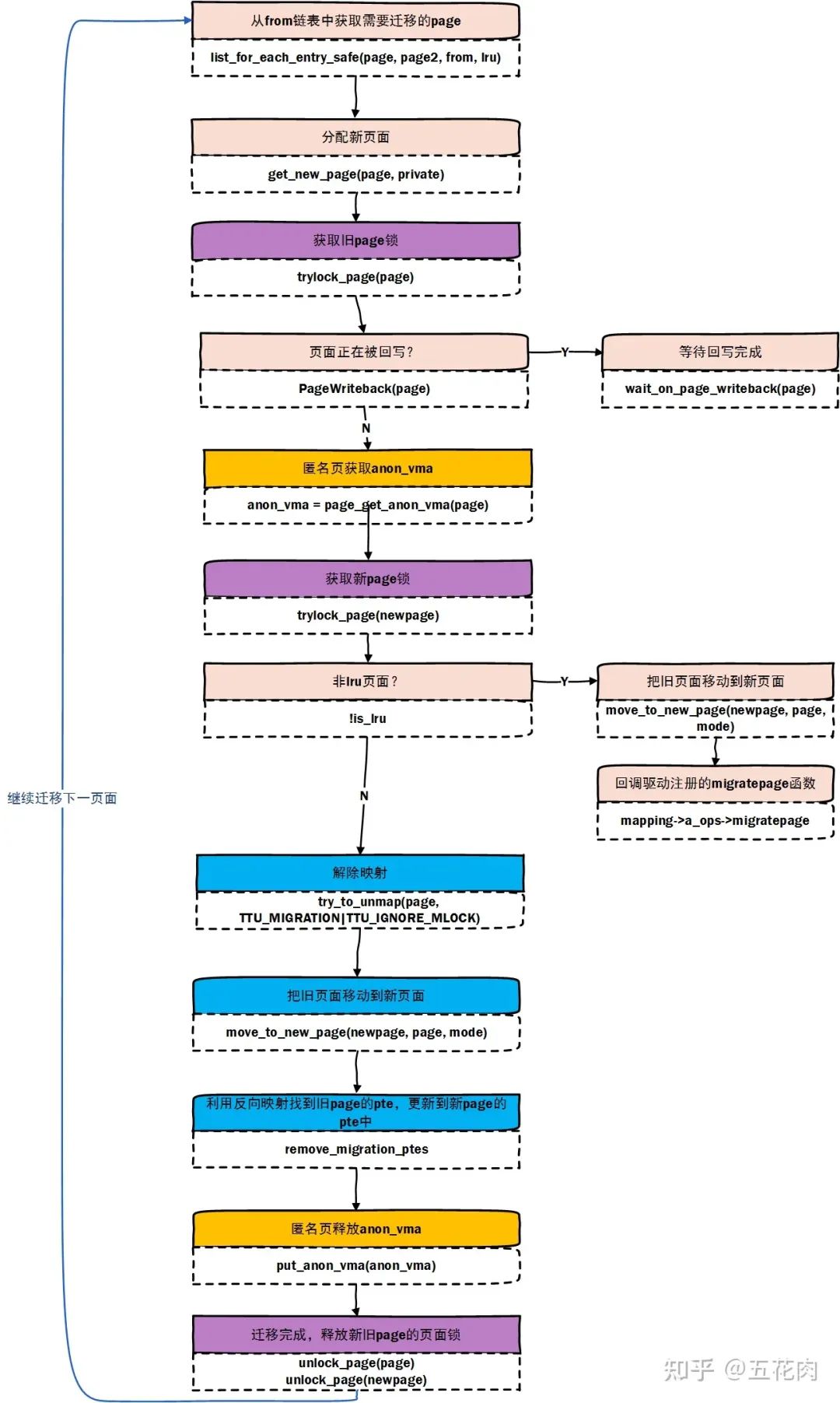
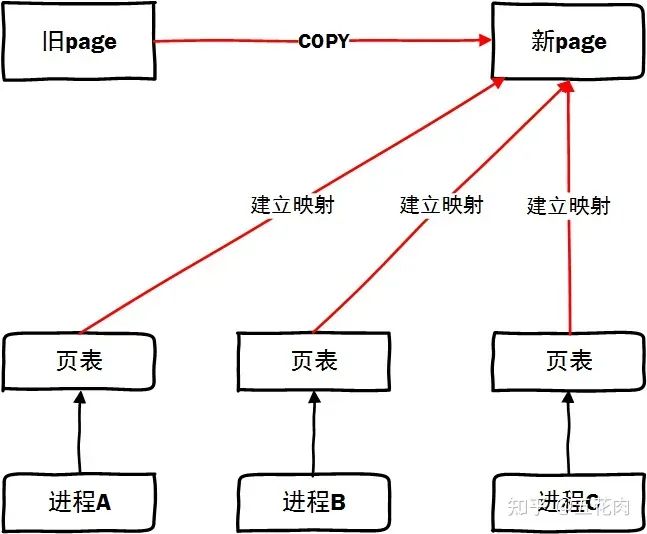
總結一下,頁面遷移過程本質就是分配一個 new_page, 解除原有 page 映射,把舊 page 復制到新 page 并建立新 page 的映射。
4. 頁面遷移過程用戶態訪問處理
到這里可能會有疑問:如果在頁面遷移過程中,應用發生發訪問這個遷移中的頁面,會發生什么?
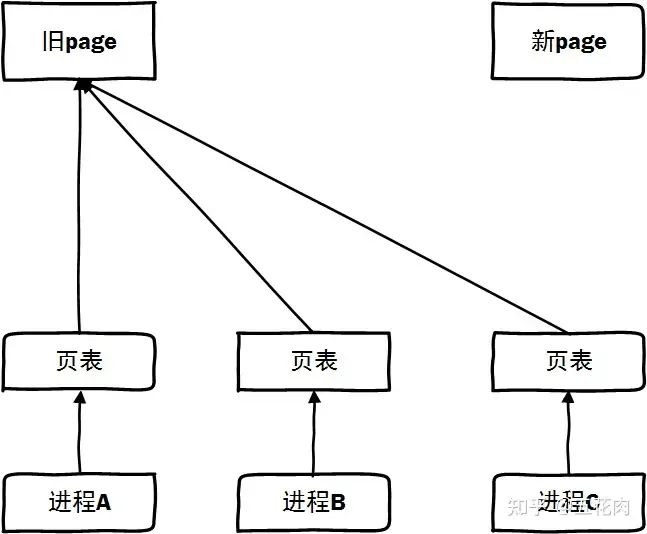
情景1: 舊頁面的頁表還未解映射, 此時發生缺頁可以正常訪問原來頁面。
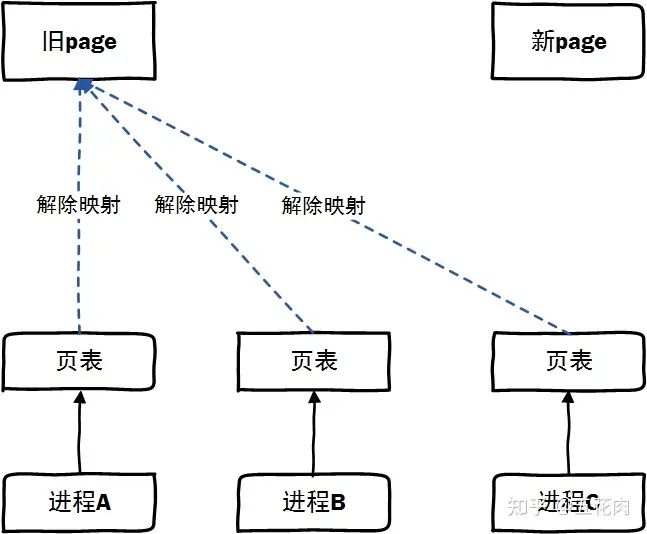
情景2: 舊頁面解除了映射,但新頁面還未建立映射。這時訪問會發生等待,需要等新頁面建立映射并copy完成頁面后才能訪問。
情景3: 完成了頁面遷移動作,可以正常訪問新頁面了。
下面我們重點分析一下,當舊頁面解除了映射,且新頁面未建立映射這個過程中發生了用戶態訪問,內核的處理流程是怎樣的。
首先我們看一下舊頁面解除了映射的過程:
staticbooltry_to_unmap_one(structpage*page,structvm_area_struct*vma, unsignedlongaddress,void*arg) { ... if(PageHWPoison(page)&&!(flags&TTU_IGNORE_HWPOISON)){ ... }elseif(pte_unused(pteval)&&!userfaultfd_armed(vma)){ ... }elseif(IS_ENABLED(CONFIG_MIGRATION)&& (flags&(TTU_MIGRATION|TTU_SPLIT_FREEZE))){ // 頁面遷移會設置TTU_MIGRATION標記,走到這個分支來 swp_entry_tentry; pte_tswp_pte; if(arch_unmap_one(mm,vma,address,pteval)解除映射后,再次發生映射就走到do_swap_page中了。
vm_fault_tdo_swap_page(structvm_fault*vmf) { ... //獲取到這是一個在遷移過程的的PTE的標識 entry=pte_to_swp_entry(vmf->orig_pte); if(unlikely(non_swap_entry(entry))){//不是傳統的Swapentry if(is_migration_entry(entry)){//是遷移標記進來的 /*等待migration的完成。本質是在等待舊page釋放其page lock *最終調用到wait_on_page_bit_common */ migration_entry_wait(vma->vm_mm,vmf->pmd,vmf->address); } ... }總結一下:
頁面遷移前,首先會獲取舊頁面和新頁面的頁面鎖PG_lock,在解除映射的時候傳入了由于頁面遷移導致的解映射標記TTU_MIGRATION,設置了此標記會生成一個帶頁面遷移標識的swap_entry設置到pte中。在設置好的那一刻走,應用進程無法很順利地訪問這個頁面了,需要通過do_swap_entry路徑。
假如此時應用進程訪問了這個頁面,會走進到do_swap_entry,取出帶遷移標識的swap_entry,識別到這個標識,會等待頁面鎖釋放。頁面鎖只有在頁面遷移完成后才會被釋放,也就是會發生等待直到頁面遷移完成。
5. 用戶態如何避免發生頁面遷移
上面我們已經知道,如果有頁面遷移過程中發生用戶態訪問,很可能是需要發生等待其遷移完成, 這個過程需要一定耗時。而有時的場景我們是需要避免此種時延抖動,那有什么辦法呢?
方法就是讓這個頁面短時間內變得不可移動。
intmigrate_page_move_mapping(structaddress_space*mapping, structpage*newpage,structpage*page,intextra_count) { ... if(page_count(page)!=expected_count) return-EAGAIN; ... returnMIGRATEPAGE_SUCCESS; }可以看到當發生頁面復制過程中,如果 page 的引用計數不符合預期(期望為0)時,這時系統認為有人在使用,不適用做遷移。那么,我們只需要增加 page 的引用計數就可以。
可以在不想被遷移的時間段開始前通過pin_user_pages這樣的接口,結束時unpin就可以了。接口最終會調到try_grab_page增加引用計數。
bool__must_checktry_grab_page(structpage*page,unsignedintflags) { ... refs=GUP_PIN_COUNTING_BIAS;//#defineGUP_PIN_COUNTING_BIAS(1U<編輯:黃飛
-
cpu
+關注
關注
68文章
10995瀏覽量
214849 -
內存
+關注
關注
8文章
3096瀏覽量
74828 -
CMA
+關注
關注
0文章
27瀏覽量
9916 -
虛擬內存
+關注
關注
0文章
77瀏覽量
8175
原文標題:圖解|內存頁面遷移技術
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux內存管理之頁面回收
走進Linux內存系統探尋內存管理的機制和奧秘
Linux內核內存規整總結


鴻蒙OS開發:【一次開發,多端部署】(典型布局場景)
鴻蒙OS開發:典型頁面場景【一次開發,多端部署】(設置應用頁面)
鴻蒙OS開發:典型頁面場景【一次開發,多端部署】實戰(設置典型頁面)
HarmonyOS Next 應用元服務開發-應用接續動態配置遷移按需遷移頁面
Linux內存系統:內存使用場景
內存之旅——如何提升CMA利用率?
一文解析Linux內存系統
基于內存關聯分析的內存預拷貝遷移策略
Linux內核中的頁面分配機制






 工商網監
工商網監
評論