") 淺談AI模型在漂移檢測(cè)中的應(yīng)用
淺談AI模型在漂移檢測(cè)中的應(yīng)用
人工智能應(yīng)用的開發(fā)過程中,AI 模型的泛化能力是一個(gè)非常重要的考量因素,理想情況下,基于訓(xùn)練數(shù)據(jù)集優(yōu)化得到的 AI 模型,不存在過擬合或欠擬合問題,可以直接遷移到新數(shù)據(jù)上用于推斷。
在這種設(shè)定下,訓(xùn)練數(shù)據(jù)集是從未知分布 P 中獨(dú)立同分布生成,且數(shù)據(jù)集是靜態(tài)、均衡且無偏的,1. 訓(xùn)練數(shù)據(jù)集中的樣本能夠全面描述目標(biāo)總體的底層特征,2. 數(shù)據(jù)總體的統(tǒng)計(jì)分布不會(huì)隨時(shí)間和外部環(huán)境因素改變。實(shí)際上,真實(shí)應(yīng)用場(chǎng)景無法滿足這種理想假設(shè),所以,在生產(chǎn)或運(yùn)營(yíng)環(huán)境中,如果 AI 模型的輸入數(shù)據(jù)和訓(xùn)練集來自不同統(tǒng)計(jì)分布時(shí),模型的性能將無法達(dá)到預(yù)期,甚至輸出不可靠的預(yù)測(cè)結(jié)果。
因此,在實(shí)際應(yīng)用中,可能出現(xiàn)以下兩種場(chǎng)景:
1.持續(xù)監(jiān)控并維護(hù) AI 模型,例如,定期使用新數(shù)據(jù)更新模型,必要時(shí)重新選擇特征輸入或更改模型以保證預(yù)測(cè)能力;
2.維持原 AI 模型,在出現(xiàn)置信度不夠高的預(yù)測(cè)結(jié)果時(shí),例如,針對(duì)未知類別的樣本,或異常值進(jìn)行預(yù)測(cè)時(shí),駁回模型推斷結(jié)果并預(yù)警。
本文將圍繞第一種場(chǎng)景,展開介紹如何結(jié)合數(shù)據(jù)開展漂移檢測(cè),以判定合適的時(shí)機(jī)對(duì)模型進(jìn)行更新。
引例:車載動(dòng)力電池的健康狀態(tài)估計(jì)
舉個(gè)簡(jiǎn)單的例子,針對(duì)電動(dòng)汽車電池的容量衰退問題,開發(fā)健康狀態(tài)估計(jì)算法。在駕駛條件下無法直接測(cè)量電池容量,基于歷史或?qū)嶒?yàn)數(shù)據(jù),構(gòu)建 AI 模型作為估計(jì)容量衰退趨勢(shì),以緩解里程焦慮。
在訓(xùn)練 AI 模型用于健康狀態(tài)(SoH)估計(jì)時(shí),模型的輸入包括電壓、電流、電池荷電狀態(tài) (SoC) 等信息,其中 SoC 這一狀態(tài)量,會(huì)受到外部環(huán)境溫度影響,而溫度波動(dòng)的統(tǒng)計(jì)分布又隨時(shí)間或空間而變化,從而間接影響到 SoH 估計(jì)的結(jié)果,這種現(xiàn)象稱為漂移,當(dāng)訓(xùn)練數(shù)據(jù)無法覆蓋到實(shí)際應(yīng)用中某些工況的溫度范圍,實(shí)際預(yù)測(cè)過程中采集的數(shù)據(jù)偏離原訓(xùn)練數(shù)據(jù)的統(tǒng)計(jì)分布,將導(dǎo)致模型預(yù)測(cè)準(zhǔn)確度下降。
因此,在生產(chǎn)環(huán)境中部署 AI 模型的同時(shí),引入漂移檢測(cè),監(jiān)控流數(shù)據(jù)是否發(fā)生漂移,以確定是否需要基于最近采集的數(shù)據(jù)執(zhí)行再訓(xùn)練(如下圖黃色箭頭所示)。
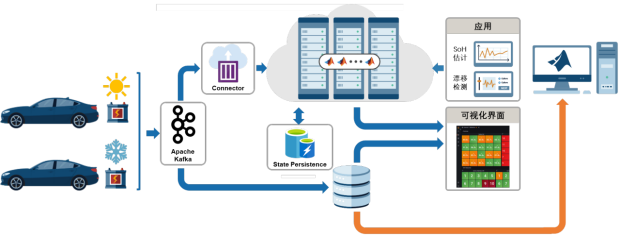
“數(shù)據(jù)漂移” 和 “概念漂移”
在監(jiān)控機(jī)器學(xué)習(xí)模型的性能,判斷是否需要對(duì)模型進(jìn)行維護(hù)時(shí),存在兩種可能的情況:
數(shù)據(jù)漂移:如果模型推斷時(shí),輸入的數(shù)據(jù)和訓(xùn)練數(shù)據(jù)存在明顯差異,模型性能無法達(dá)到預(yù)期,這種情況下,需要結(jié)合新數(shù)據(jù),對(duì)模型進(jìn)行再訓(xùn)練,調(diào)整可學(xué)習(xí)參數(shù)。
概念漂移:當(dāng)模型學(xué)習(xí)的概念依賴于某些未被考慮到特征/變量時(shí),例如,利用模型預(yù)測(cè)交通堵塞情況,但沒有考慮到與節(jié)假日相關(guān)的特征,或是當(dāng)輸入特征和模型預(yù)測(cè)的目標(biāo)概念之間,底層關(guān)系發(fā)生變化時(shí),這種情況下,需要評(píng)估是否需要更換模型,而不僅僅是重訓(xùn)練原模型。
MATLAB 的 Statistics and Machine Learning Toolbox,可支持:
1.根據(jù)批量數(shù)據(jù)檢測(cè)數(shù)據(jù)漂移:調(diào)用 detectdrift 函數(shù),通過置換檢驗(yàn)判斷目標(biāo)數(shù)據(jù)集相對(duì)于基準(zhǔn)數(shù)據(jù)集是否存在漂移。
2.根據(jù)流式數(shù)據(jù)檢測(cè)概念漂移:構(gòu)建 incrementalConceptDriftDetector 對(duì)象,指定使用 DDM,HDDMW 或 HDDMA 算法,根據(jù)實(shí)時(shí)輸入的數(shù)據(jù)流,調(diào)用 detectdrift 函數(shù)評(píng)估是否發(fā)生概念漂移。
本文將以電池 SoH 估計(jì)所使用的數(shù)據(jù)集為例,介紹基于批量數(shù)據(jù)的數(shù)據(jù)漂移檢測(cè),并簡(jiǎn)要說明如何開展流式數(shù)據(jù)的概念漂移檢測(cè)。
電池健康監(jiān)控系統(tǒng)中的漂移檢測(cè)
數(shù)據(jù)準(zhǔn)備
在分析工程大數(shù)據(jù)時(shí),一個(gè)常見的問題是,如何高效管理多個(gè)不同試驗(yàn)、工況、日期的多通道測(cè)量數(shù)據(jù),Predictive Maintenance Toolbox 提供了一個(gè)專用的對(duì)象 fileEnsembleDatastore 用于創(chuàng)建關(guān)于本地或遠(yuǎn)程數(shù)據(jù)集的索引,并根據(jù)自定義讀取函數(shù) ReadFcn,對(duì)數(shù)據(jù)集進(jìn)行增量式或批量式訪問。按照數(shù)據(jù)集中的不同變量類型,將不同變量分別定義為:數(shù)據(jù)變量(測(cè)量量)、獨(dú)立變量(時(shí)間戳、文件名等)或狀態(tài)變量(標(biāo)簽信息)。并通過 SelectedVariables 屬性,指定每次訪問數(shù)據(jù)集需要讀取的部分變量。此外,經(jīng)過特征提取后的數(shù)據(jù)可通過自定義 WriteToMemberFcn 函數(shù),再次寫回到 fileEnsembleDatastore 便于集中管理。關(guān)于如何使用 fileEnsembleDatastore,可查看文檔鏈接:File Ensemble Datastore with Measured Data[1]。
sample = read(fensemble);
time = sample.("Current"){:}.Time;
current = sample.("Current"){:}.Var1;
voltage = sample.("Voltage"){:}.Var1;
SoC = sample.("SoC_B1"){:}.Var1;
SoH = sample.("SoH"){:}.Var1;
tt = timetable(time,current,voltage,SoC,SoH);
figure
stackedplot(tt)
ans = 1×5 table
| Key | Current | Voltage | SoC_B1 | ? | |
| 1 |
360001×1 timetable |
360001×1 timetable |
360001×1 timetable |
? |
完整文件集一共由20組電池?cái)?shù)據(jù)組成,其中 key 代表各個(gè)文件的編號(hào)。
fileEnsembleDatastore 支持通過 read 或 readall 方法,將數(shù)據(jù)讀取到內(nèi)存。接下來,我們嘗試選取一組數(shù)據(jù)查看各個(gè)狀態(tài)量的時(shí)間序列:
prj = currentProject; location = fullfile(prj.RootFolder,"TrainingData","battery*.mat"); extension = '.mat'; fensemble = fileEnsembleDatastore(location,extension); fensemble.ReadFcn = @readBatteryData; fensemble.DataVariables = ["Current","Voltage","SoC_B1","SoH"]; fensemble.SelectedVariables = ["Current","Voltage","SoC_B1","SoH"]; preview(fensemble)
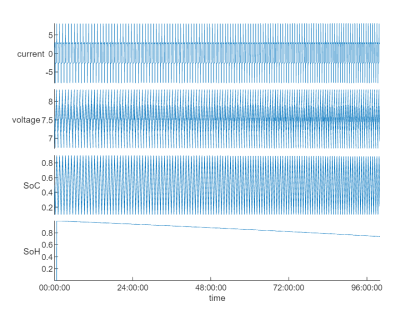
特征提取
從上圖信號(hào)波形構(gòu)建 AI 模型進(jìn)行預(yù)測(cè)或是判斷是否存在漂移,是非常困難的,因此,針對(duì)特征工程往往是必要的。利用 Diagnostic Feature Designer App 可通過交互式方式,對(duì)時(shí)間序列數(shù)據(jù)進(jìn)行可視化探查,并提取統(tǒng)計(jì)或時(shí)頻域特征,并導(dǎo)出函數(shù)用于后續(xù)處理。了解更多可參考:Explore Ensemble Data and Compare Features Using Diagnostic Feature Designer[2]。使用預(yù)先導(dǎo)出的 diagnosticFeatures_Historical 函數(shù),從基準(zhǔn)數(shù)據(jù)集中提取各種統(tǒng)計(jì)特征得到特征表:
batteryData = readall(fensemble); % 通過 readall 函數(shù)將所有數(shù)據(jù)讀入內(nèi)存 baselineData = batteryData(batteryData.key<=10,:); % 將編號(hào)前10的文件作為基準(zhǔn)數(shù)據(jù)集 baselineFeatures = diagnosticFeatures_Historical(baselineData); head(baselineFeatures)

size(baselineFeatures)
ans = 1×2
2000 20
特征表維度為 2000x20,通過將原始基準(zhǔn)數(shù)據(jù)分為 2000 個(gè)長(zhǎng)度分別為 1800s 的時(shí)間序列,并提取各個(gè)原始物理量的多個(gè)統(tǒng)計(jì)和頻域特征,表格中,前4列記錄的是文件編號(hào)和起止時(shí)間戳信息,在后續(xù)處理中,將重點(diǎn)關(guān)注第 5 列到最末列(20)的特征數(shù)據(jù)。
再?gòu)耐暾麛?shù)據(jù)集中,選取部分?jǐn)?shù)據(jù)作為目標(biāo)數(shù)據(jù)集,并提取特征:
idx = 15; % 范圍 11~19 targetData = batteryData(batteryData.key>idx,:); targetFeatures = diagnosticFeatures_Historical(targetData);
對(duì)比基準(zhǔn)數(shù)據(jù)集和目標(biāo)數(shù)據(jù)集,可視化各個(gè)特征的統(tǒng)計(jì)分布:
figure tiledlayout(4,4); for i = 5:width(baselineFeatures) nexttile; histogram(baselineFeatures{:,i},Normalization="pdf"); hold on histogram(targetFeatures{:,i},Normalization="pdf"); hold off xlabel(baselineFeatures.Properties.VariableNames{i},Interpreter="none"); end legend("baseline","target",location="northeastoutside")
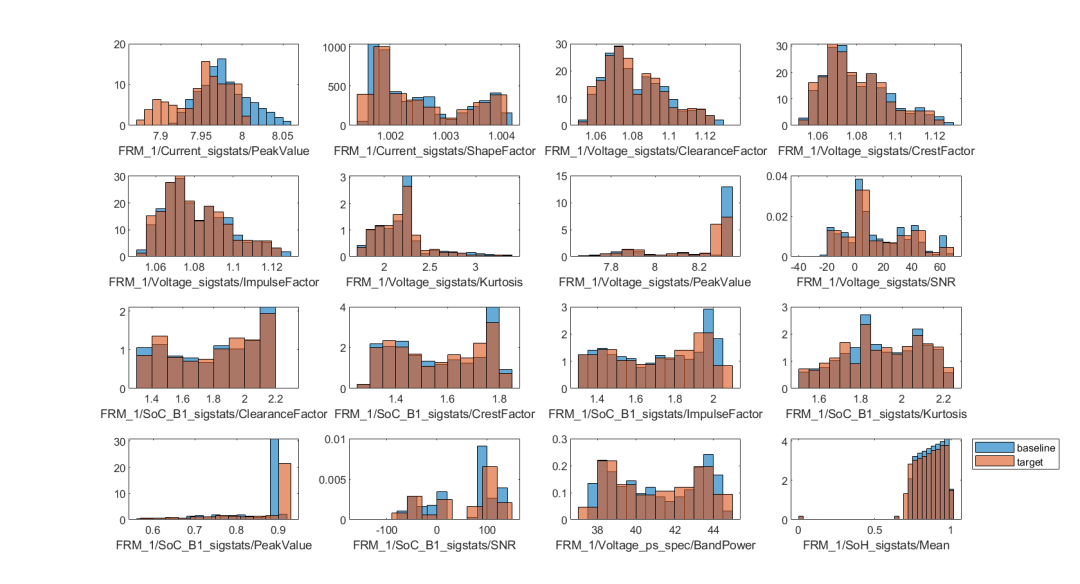
基于批量數(shù)據(jù)的漂移檢測(cè)
從上圖可以看出,部分特征,例如第一個(gè)特征電流峰值,可以從圖中看出,藍(lán)色基準(zhǔn)數(shù)據(jù)集的取值范圍更大,這一特征的均值略高于紅色目標(biāo)數(shù)據(jù)集的均值。如何定量或定性地判斷模型輸入數(shù)據(jù)/特征是否發(fā)生了漂移呢?針對(duì)批量數(shù)據(jù),detectdrift 采用置換檢驗(yàn)這一方法,推斷目標(biāo)數(shù)據(jù)相較于基準(zhǔn)數(shù)據(jù),是否發(fā)生數(shù)據(jù)漂移,detectdrift 函數(shù)調(diào)用方式如下:
DDiagnostics = detectdrift(baselineFeatures(:,5:end),targetFeatures(:,5:end)); % 前4列記錄的是文件編號(hào)和起止時(shí)間戳信息,檢測(cè)漂移時(shí)不需要考慮
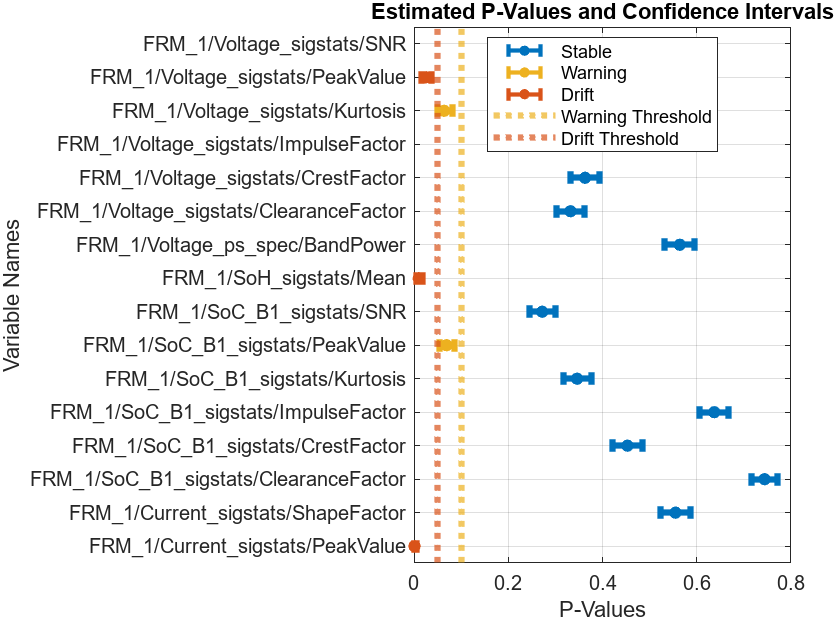
計(jì)算結(jié)果以 DriftDiagnostics 對(duì)象返回,其中記錄了上述計(jì)算中涉及到的相關(guān)屬性信息,針對(duì) DriftDiagnostics 對(duì)象的方法函數(shù)可以幫助我們理解檢測(cè)結(jié)果和推斷過程。例如,通過 summary 匯總各個(gè)特征的漂移狀態(tài)、p 值和置信區(qū)間:
summary(DDiagnostics)
Multiple Test Correction Drift Status:Drift
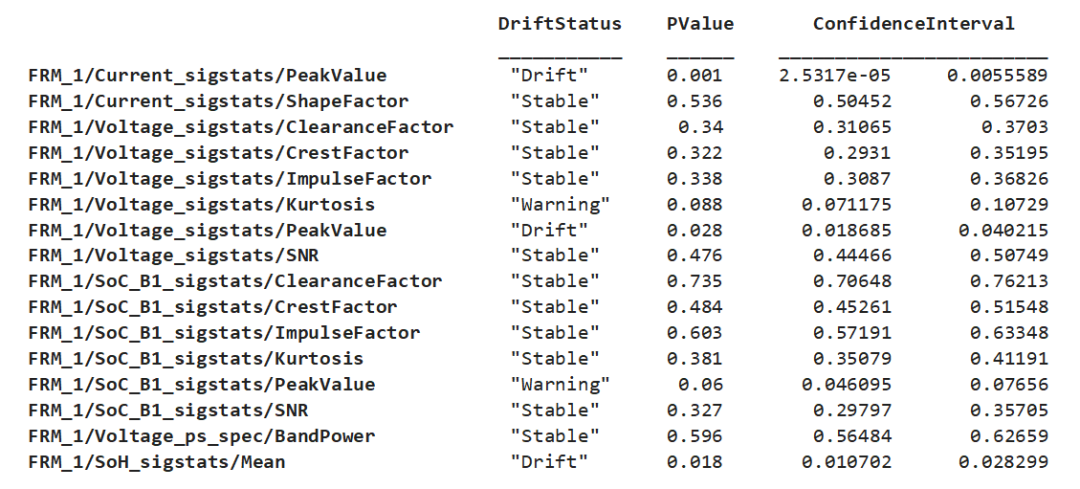
figure; plotDriftStatus(DDiagnostics)
【算法解析】
什么是置換檢驗(yàn)?這是一個(gè)非參數(shù)化統(tǒng)計(jì)顯著度檢驗(yàn)方法,適用于總體分布未知的數(shù)據(jù)集。實(shí)現(xiàn)過程如下:
提出零假設(shè):數(shù)據(jù)沒有發(fā)生漂移
選擇一個(gè)測(cè)試統(tǒng)計(jì)量,例如基準(zhǔn)數(shù)據(jù)m的個(gè)樣本均值 μ1和目標(biāo)數(shù)據(jù) n 個(gè)樣本均值 μ2的差值 t0=μ1-μ2,算法提供了 Wasserstein, Kolmogorov-Smirnov 等測(cè)試統(tǒng)計(jì)量供選擇
將兩組數(shù)據(jù)合并,對(duì)全部數(shù)據(jù)樣本進(jìn)行不放回抽樣,重新得到兩組樣本量分別為 m 和 n 的集合,分別計(jì)算測(cè)試統(tǒng)計(jì)量,得到t1=μ1-μ2
假設(shè)零假設(shè)成立,重復(fù)上述抽樣多次,將全部測(cè)試統(tǒng)計(jì)量 t0,t1,t2,...排序形成抽樣分布,并計(jì)算 p 值p=x/perm,x 為 t1,t2,... 中大于 t0的次數(shù),perm 為置換的次數(shù)
由于在樣本數(shù)量非常大的情況下,遍歷全部可能的組合,將限制計(jì)算速度,因此,算法將盡可能多地進(jìn)行抽樣,以估計(jì)測(cè)試統(tǒng)計(jì)量的分布
根據(jù)零假設(shè),測(cè)試統(tǒng)計(jì)量t1,t2,...,應(yīng)該與t0接近,當(dāng) t0被判定為區(qū)別于t1,t2,...的異常值時(shí),駁回零假設(shè),即判斷數(shù)據(jù)發(fā)生漂移
在假設(shè) x 符合二項(xiàng)分布的條件下,通過 [~,CI] = binofit(x,perm,0.05) 估計(jì) p 值的 95% 置信區(qū)間
detectdrift 函數(shù)中,默認(rèn)條件下,漂移閾值定義為 0.05,警告閾值定義為 0.1,當(dāng)計(jì)算得到的置信區(qū)間上限小于漂移閾值時(shí),判定漂移狀態(tài)出現(xiàn)
反之,當(dāng)置信區(qū)間下限大于警告閾值時(shí),判定狀態(tài)穩(wěn)定,介于二者之間,則發(fā)出警告
結(jié)果分析
為了方便理解,我們可以使用 DriftDiagnostics 的方法函數(shù) plotPermutationResults ,可視化指定特征的置換檢驗(yàn)結(jié)果:
figure tiledlayout(3,1) nexttile % stable plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(5)) nexttile % warning plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(6)) nexttile % drift plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(7))
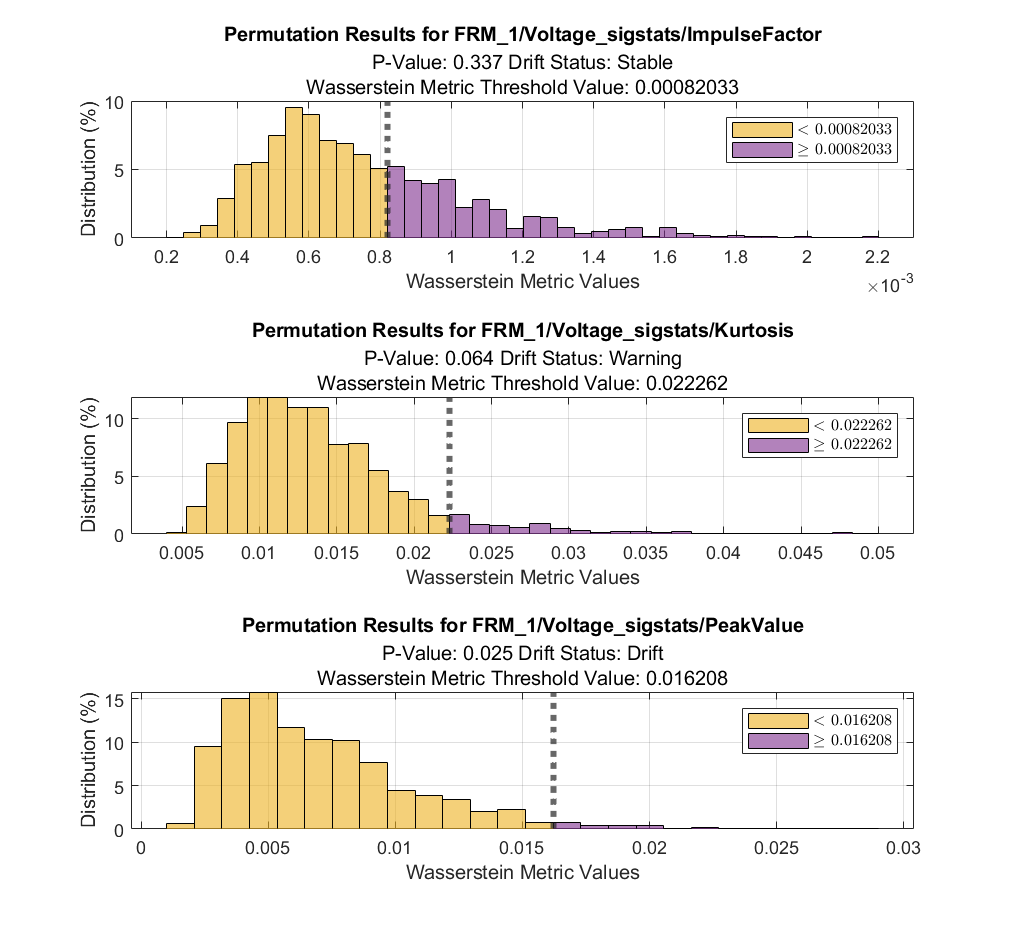
其中,灰色虛線代表使用原有的基準(zhǔn)數(shù)據(jù)集和目標(biāo)數(shù)據(jù)集計(jì)算得到的測(cè)試統(tǒng)計(jì)量,即,作為閾值,將置換組合后的測(cè)試統(tǒng)計(jì)量所形成抽樣分布劃分為兩部分,p 值代表大于閾值的部分占比。由以上直方圖,可以清晰看到原始測(cè)試統(tǒng)計(jì)量在置換組合的測(cè)試統(tǒng)計(jì)量抽樣分布中的位置。另外結(jié)合二項(xiàng)分布假設(shè)計(jì)算得到的置信區(qū)間,可以判定是否發(fā)生漂移。此外,plotHistogram,plotEmpiricalCDF 函數(shù)也可用于可視化輔助分析。
問題延申:基于流式數(shù)據(jù)的概念漂移檢測(cè)
如引例圖示,在實(shí)際生產(chǎn)環(huán)境中,通常需要采集流式數(shù)據(jù),如何根據(jù)有限且分布未知的數(shù)據(jù),監(jiān)控?cái)?shù)據(jù)或概念本身是否存在漂移,并對(duì)AI模型進(jìn)行維護(hù)呢?一方面,可以結(jié)合增量學(xué)習(xí)方法,根據(jù)模型準(zhǔn)確度在一定時(shí)間窗口內(nèi)準(zhǔn)確度的平均值和累積值,作為是否存在漂移問題的判定標(biāo)準(zhǔn)。另一方面,可以使用 incrementalConceptDriftDetector 對(duì)象定義漂移檢測(cè)模型,然后根據(jù)實(shí)時(shí)數(shù)據(jù)流更新檢測(cè)模型,并調(diào)用 detectdrift 函數(shù)檢測(cè)漂移。此外,如果將構(gòu)建機(jī)器學(xué)習(xí)模型的過程和漂移檢測(cè)合二為一,可以通過 incrementalDriftAwareLearner 創(chuàng)建可感知概念漂移的分類或回歸模型,根據(jù)輸入數(shù)據(jù)和漂移狀態(tài)的變化,自動(dòng)調(diào)整模型參數(shù)。
以下簡(jiǎn)要介紹第三種方式的實(shí)現(xiàn)步驟:
1.初始化基礎(chǔ)增量學(xué)習(xí)模型,例如樸素貝葉斯分類模型:
BaseLearner = incrementalClassificationNaiveBayes(MaxNumClasses=2,Metrics="classiferror");
2.定義概念漂移檢測(cè)算法,并將基礎(chǔ)模型和檢測(cè)器作為參數(shù),創(chuàng)建可感知漂移的增量學(xué)習(xí)模型:
dd = incrementalConceptDriftDetector("hddma");
idaMdl = incrementalDriftAwareLearner(BaseLearner,DriftDetector=dd,TrainingPeriod=5000);
3.根據(jù)輸入數(shù)據(jù)流 (XNew,YNew),先評(píng)估模型當(dāng)前性能指標(biāo)(updateMetrics),再調(diào)整模型參數(shù):
idaMdl = updateMetricsAndFit(idaMdl,XNew,YNew);
classficationError{j,:} = idal.Metrics{"ClassificationError",:};
4.記錄數(shù)據(jù)用于可視化:
plot(classficationError.Variables)
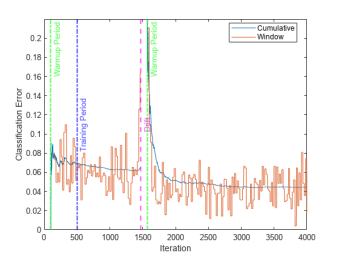
關(guān)于上述方法,可查看以下文檔鏈接了解更多:Construct drift-aware model for incremental learning[3]。
AI 模型在生產(chǎn)環(huán)境中使用時(shí),需要進(jìn)行持續(xù)性維護(hù),以確保性能,本文介紹了常用的漂移檢測(cè)方法,在某些場(chǎng)景下,原模型維持不變,在出現(xiàn)推斷結(jié)果置信度不夠高時(shí),例如,出現(xiàn)未知類別的樣本時(shí),需要駁回模型推斷結(jié)果并預(yù)警,這類問題一般定義為分布外檢測(cè)。針對(duì)深度學(xué)習(xí)的分布外檢測(cè)問題,可安裝附加功能包Deep Learning Toolbox Verification Library[4],并查看相關(guān)文檔。
-
matlab
+關(guān)注
關(guān)注
189文章
2999瀏覽量
233497 -
AI
+關(guān)注
關(guān)注
88文章
34588瀏覽量
276197 -
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247420 -
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50128
原文標(biāo)題:AI 模型運(yùn)維 - 淺談漂移檢測(cè)
文章出處:【微信號(hào):MATLAB,微信公眾號(hào):MATLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
淺談鎳氫電池在電動(dòng)航模中的應(yīng)用
防止AI大模型被黑客病毒入侵控制(原創(chuàng))聆思大模型AI開發(fā)套件評(píng)測(cè)4
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測(cè)模型
淺談電機(jī)模型
介紹在STM32cubeIDE上部署AI模型的系列教程
在X-CUBE-AI.7.1.0中導(dǎo)入由在線AI平臺(tái)生成的.h5模型報(bào)錯(cuò)怎么解決?
AI視覺檢測(cè)在工業(yè)領(lǐng)域的應(yīng)用
如何去識(shí)別和跟蹤模型漂移
在AI愛克斯開發(fā)板上用OpenVINO?加速YOLOv8目標(biāo)檢測(cè)模型

AI Transformer模型支持機(jī)器視覺對(duì)象檢測(cè)方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論