 為什么有多核處理器?從多核到眾核處理器
為什么有多核處理器?從多核到眾核處理器
其實“多核”這個詞已經流行很多年了,世界上第一款商用的非嵌入式多核處理器是2002年IBM推出的POWER4。當然,多核這個詞匯的流行主要歸功與AMD和Intel的廣告,Intel與AMD的真假四核之爭,以及如今的電腦芯片市場上全是多核處理器的事實。接下來,學術界的研究人員開始討論未來成百上千核的處理器了。有一個與多核匹配的詞叫片上網絡(Networks on Chip),講的是多核里的網絡式互連結構,甚至有人預測未來將互連網集成到片上這種概念了。當然,這樣的名詞是很吸引眼球的,不過什么東西都得從實際出發,這篇文章也就簡單地分析了為什么有多核這個事情,以及多核系統的挑戰。
為什么有多核處理器?
事先需要提及的是,一個常見誤區就是多核和眾核處理器的發展來源于應用和市場驅動。實際上,應用和市場希望單核處理器的壽命越來越長,而物理限制是多核以及未來眾核處理器出現和發展的動力。之后我們來談論一下,首先,為什么有多核處理器?從Intel 80286到Intel Pentium 4大概二十多年的時間都是單核處理器的天下,為什么最近幾年單核處理器卻銷聲匿跡了?是什么導致了多核時代的到來?
這里需要知道一個經驗定律和三個限制,他們是多核處理器的最本質緣由。這個定理就是摩爾定律。Gordon Moore博士是Intel的創始人之一。早在他參與創建Intel之前的1965年,他就提出,在至少十年內,每個芯片上集成的晶體管數(集成度)會每兩年翻一番。后來,大家把這個周期縮短到十八個月。這個指數規律的發展速度是令人難以置信的,大家都聽過那個國王按幾何級數賞賜大臣谷粒,從而使得國庫被掏空的傳說。而摩爾定律講得就是現實中晶體管數量幾何級數倍增的故事,更令人難以置信的是這個速度保持到今天已經快五十年了。人類歷史上應該還沒有任何技術是指數發展這么久的。題外話一句,若干年前,互聯網骨干網帶寬曾經這么指數了幾年,曾有人將其總結為一個定律忽悠一堆人研究光纖通訊,后來發現帶寬沒法按照指數定律漲了,許多搞光電的人也就找不到工作了。扯遠了點,整個IT產業之所以風光了這么多年,摩爾定律是本質的因素。
當無數的硅公硅婆和軟件民工們將晶體管數目的增長轉換為計算機等IT產品的性能時,摩爾定律也就有了兩個推論,每十八個月,計算機等IT 產品的性能會翻一番;相同性能的計算機等 IT 產品,每十八個月價錢會降一半。后面這個推論很可怕的一件事情,他說,如果你IT產品像菜市場的商販一年年復一年的賣同樣的東西,那么你IT產品的價錢會指數下降。從某種意義上來說摩爾定律逼迫著所有的IT企業不斷的按指數規律提高產品的性能,并且創新出新的產品。但不幸的是,這種從晶體管數轉換為性能增長的過程日趨困難。
時至今日,集成度還在以摩爾定律的速度增長,但是性能的增長遇到了三個物理規律的限制。第一是功耗,第二是互連線延時,第三是設計復雜度。
功耗限制:晶體管的主要工作就以翻轉提供信息計算,要讓晶體管翻轉就是給他們提供能量,而他們一翻轉就要發熱。從Intel 80286到Pentium 4的路線一直是讓晶體管翻轉得越來越快(約兩千倍的差別),處理器頻率隨之不斷上升,也就是意味單位時間提供給芯片的能量——功耗,會逐步上升,發熱也越來越厲害。一個很明顯的現象是,286不需要散熱,但是Pentium IV卻需要散熱片加強勁的風扇。這種靠不斷增加翻轉速度的方式帶來的最大好處是同一個程序,你什么優化也不做,買一個下一代的芯片就可以讓程序跑快很多。但是與此同時,翻轉速度的上升帶來功耗的急劇增長,所散熱超過了風扇散熱的熱預算。不幸地是,散熱的能力卻不能夠同步增長,這限制了處理器所發熱的總功耗,從而使得傳統地提高處理器頻率的老法子不再具有可擴展性。單核處理器的性能發展走到了盡頭。那摩爾定律提供的多余的處理器怎么辦呢?最簡單的辦法就是用來增加單片集成處理器核的數量而不是性能。
互聯線延遲:芯片上除了晶體管就是互連線。它的主要工作是把一個晶體管干活兒的結果給另一個晶體管,是個車間搬運工的角色。曾幾何時,晶體管是很慢的,所以沒人在乎這種搬運工帶來的任何延時影響。但是隨著晶體管越來越小,越來越快,互連線的延遲并不隨之變塊,這就成了問題了。以前晶體管每翻轉一次的時間互連線能夠把數據從芯片的一頭送到另一頭,而如今這種對角線傳輸得花好幾個晶體管翻轉的時間。摩爾定律說晶體管集成度越來越高,但是互連線卻相對的越來越慢了。這帶來的最大問題是干一件事情需要花的步驟更多了,打個比方就是工廠里的流水線級數越來越多,很多步驟都花在把東西從一個車間搬到另一個車間上。在Pentium IV的時候,干一件事情(執行一條指令)要花20級流水線。流水線級數長不是什么好事,因為一旦當流水線級前面處理的東西出了問題,后面正在處理的那些東西就得重頭來做。當年AMD Athon之所有能夠在與Intel Pentium 4爭奪中占領一席之地,就是因為雖然AMD的晶體管翻得慢,但流水線級數少,因此那種重頭來做的機會和代價都小,因此性能還很高。克服互聯線延遲增加的最好辦法就是把一個大廠房分成很多個小廠房,事情都在一個小廠房里解決,這樣運輸的距離就變短了。換句話說,使用較小的核組成一個多核的芯片,而不是以往的單核芯片。
設計復雜度:隨著晶體管數量的增加,芯片設計的設計空間、設計復雜度和驗證難度都是大幅度增加的。話說Intel六核的iCore7上集成了超過十億個晶體管,其設計難度之大可想而知。如果采用多個重復設計處理器核,那么設計的復雜度就會大大降低,從而使得設計成本降低,出錯的機會也減小了。
總結一下,多核系統的出現是摩爾定律與物理規律限制相互作用的結果,三個主要的限制是:功耗、互連、設計復雜度。一個處理器上的晶體管數越來越多,但是他們卻因為功耗和互連線的限制并不能直接提供很高的性能,那么怎么辦呢?一個最簡單的辦法就是用在一個處理器中集成多個簡單的處理器核。這樣既把多出來的晶體管用上了,而每個處理器核就像前一代的處理器一樣簡單,因此不必提高他們的翻轉速度,各個處理器核只需要自己交換數據,因此沒有很長的連線延遲。這也就是Intel放棄Pentium IV采用Core 2結構的緣由,也是本篇文章最本質的原理。
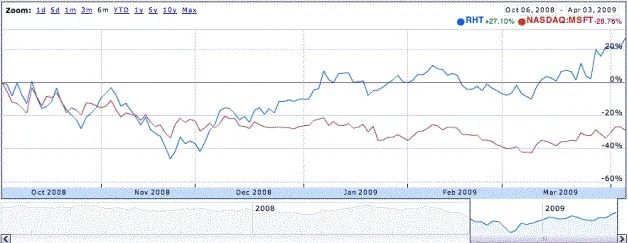
從單核到多核乃至未來眾核的變化并不是芯片設計公司根據客戶需求,市場趨勢做出的主動選擇,而是在物理規律限制不得已的情況下被逼走上的道路。這意味著以前那種處理器頻率越來越高的時代已經一去不復返了。在那個已經過去的黃金時代,程序員不需要怎么優化程序,因為優化程序所花的功夫和時間還不一定值得去市場上買一個新款處理器。這也就使得Microsoft敢于做越來越慢的軟件。他不怕因為軟件太慢賣不出去,因為處理器的翻轉速度的增長會使得他本來很慢的軟件,不久就會快得可以接受。但是這個故事已經結束了,現在的新款處理器跑老程序并不會快到哪里去,而當你買了新處理器還得對老程序作進一步的優化才能利用上新增的晶體管。這可能也就是微軟的Vista按照老路子設計,但賣得沒那么好的原因,也帶來了微軟裁員5000人,但是linux卻還是比較紅火的結果。下面這個圖是09年初Redhat Linux和Windows的股票走勢,可以比較明顯的看出來,當處理器速度不再翻倍的時候,當人們沒錢總是換硬件的時候,微軟的表現就不是那么好了。因為Windows Vista是微軟沿用了以前處理器發展規律設計的操作系統,因此并不叫座。微軟公司不得不花大力氣重寫了他們的內核代碼,推出了Windows 7來收拾Vista的殘局。
多核雖然說著容易,做起來也不難,但是難得卻不在多核本身上,下面的內容簡單地揭開了多核設計貌似困難實則簡單地面紗,同時也指出多核之難不在核上,而在互連與編程兩大挑戰。
多核處理器是什么樣子的?
多核處理器的發展其實很大程度上是一個學術界最早提出但是由工業界引領的題目,從本質上來說設計一個多核處理器本身沒有什么有深度的挑戰,難點其實是互連和編程的問題。不過在我們深入了解這兩個問題前還是先回顧一下多核處理器的發展之路,目的是看看人們怎么從單核走到多核的。
多核的點子最早學術界提出的。典型的有四個:斯坦福的Hydra(1996),斯坦福的Imagine (2000),MIT的RAW(2002),以及UT奧斯丁的TRIPS(2003)。在這個問題上,是不得不佩服美國的創造力,要知道直到在2000年左右,所有的人都還在為處理器頻率按照摩爾定律翻翻而狂熱,美國的頂尖研究員就早已看到了這條路的盡頭并指出未來處理器的發展之路。
如果從學術界多核處理器的發展上學到一點最關鍵的內容的話,那就是:做一個多核的處理器不是一件有理論困難的事情。曾有人據此預測說多核設計給了學術界一次超越工業界的機會,就像當年一個隨便的學生project做出來的RISC處理器就能勝過工業界的CISC處理器一樣。但是就目前看來這件事情并沒有如期發生。真正的難點并不在處理器設計上,當工業界用各自不同的方式實現多核處理器后,一個重要經驗就是:真正的難點在提供一個多核平臺上的編程環境。
在介紹多核處理器的設計的時候我們將學術和工業界的研究情況結合在一起。多核處理器架構的學術深度是有限的,但是工業界的實現卻是多種多樣的,SUN、IBM、Intel、AMD、甚至ARM都相繼設計并推出了了自己的多核處理器。面對不同的客戶市場,不同的公司推出的不同多核處理器具有截然不同的特點。
多核處理器的設計依照大致可以分為三類:總線或者交換開關互連的或和設計,流處理器和圖形處理器,以及網絡互連的處理器:
以總線或交換開關為基本互連架構的多核設計
最初的多核處理器集成的處理器核數量較小,典型的特點就是互連方式是以總線和交換開關為主,而每個核結構相似功能較為強大。這種設計也該可以看作傳統一個主板上多處理器結構在片上的集成,主要的創新來源于摩爾定律指導下半導體技術進步帶來的集成度提高,體系結構的創新并不明顯。這種結構的始祖(當然也是片上多核的始祖)是Hydra。
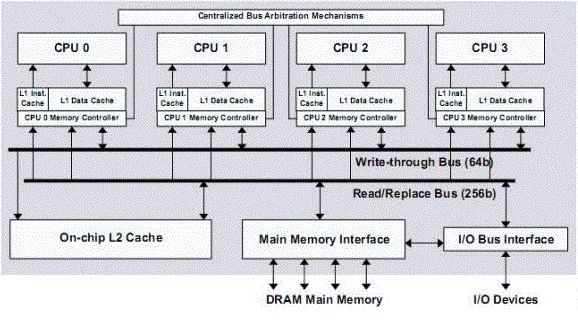
斯坦福的Hydra處理器是最早提出的片上多核處理器。Hydra發明后成立了一家公司,然后這個公司被SUN公司購買(后來SUN又被Oracle買了,不過那是后話),Hydra也就成為了現在SUN主流處理器Niagara的原型。不僅如此,現在Intel的雙核、四核處理器也是采用了和Hydra類似的結構。Hydra的出發點也就是看到了多發射超標量處理器架構的末日,然后將多個簡單的處理器核集成在了一個芯片上,互連方式還是最簡單的總線互連,每個處理器通過總線廣播的方式發送信息,也通過總線偵聽來接受其他處理器。這種方法設計簡單、有效,可以重用復雜的處理器設計,并且借用版級總線設計的協議,是一種多核發展初級階段的重要一步。下圖就是Hydra的示意圖,可以看到這其實就是一個集成在片上的總線帶動的多處理器。這種結構的發展也有不同的階段和變體:最初只有處理器核、總線和緩存集成在片上;后來存儲和I/O控制器也集成了進到片上來;圖中的總線之下的L2緩存有時候也會被放在總線與處理器之間;片上與片外的連接也不一定要是處理器與存儲器的接口,而可以成為兩個或多個多核處理器的接口。 Hydra引領的以總線為主的片上多核設計方案也成為了工業界第一代雙核甚至四核處理器設計的雛形。
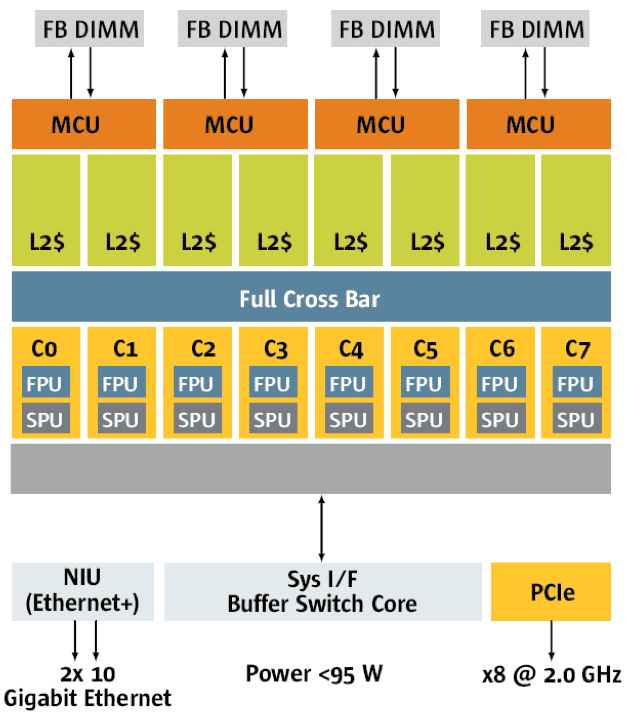
最早的雙核處理器以及Intel的第一代四核處理器都是這種設計。總線可以替換為交換開關,來實現類似的功能。如下圖所示的是SUN在2007年推出的八核Niagara 2,其互連結構就是交換開關。
這種結構有以下這些特點:
? 從存儲器讀寫的角度來講這種設計統稱為UMA(Uniform Memory Access)。每個處理器核訪問存儲的路徑都是一樣的,總線(或者交換開關)被不同的處理器核交替使用從而達到訪問共享存儲的目的。這種存儲訪問結構自然地支持了內存空間在各個處理器核之間共享已經基于總線偵聽的緩存一致性協議。
? 各個處理器核類似于傳統的單核處理器,具有較為強大的計算功能,只是作了一些裁剪來優化功耗等要素。也就是說,就算單線程應用程序沒有任何改變,也能在新的多核處理器上運行,性能有可能有所提高。
? 從編程上來講類似于傳統的多處理器編程,再加上內存空間共享,并控制了多線程編程的復雜度。比如說,像Linux之類的操作系統很早就支持多處理器,可以無縫地在多核處理器上運行,并從容地調配多個應用程序進程。其實,最早多核處理器的性能提升大部分就來自于應用程序能夠各自獨享一個核所帶來的獨占優勢
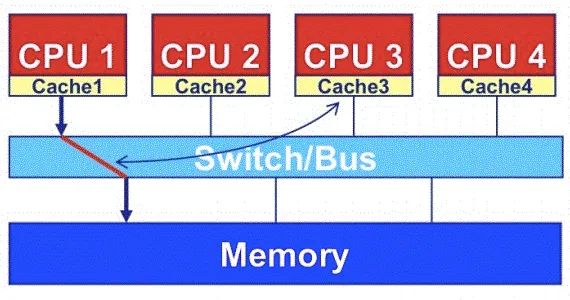
這種結構的明顯劣勢來自于總線或者交換開關成為系統瓶頸,這個瓶頸體現在系統性能和功耗兩個方面:從系統性能上來講這種體系結構的核心:總線或者交換開關仍舊依賴全局金屬互聯線,其性能并不能隨著半導體技術進步而提高。這種全局性地互連要求所有的通信都先匯聚到同一個地方然后又再傳播出去,其效率之低也是可想而知的。從延遲上講,電信號需要給長達整個芯片邊長的金屬線充電,其電阻電容很大,充電時間很長,因此信號延遲很大;從吞吐率上來講,所有的信號傳輸都要通過這個總線或者交換開關,其帶寬是無法適應處理器核數量的增長的。同樣的壞消息來自于功耗。無論是連接多個核的總線還是四通八達的交換開關,其功耗都不是可以擴展的。上述的不可擴展性決定了,基于片上總線或者交換開關的體系結構終究不能支持片上多核隨著摩爾定律而擴展到片上眾核,人們不得不放棄這種簡單的結構而選擇流處理器或者片上網絡等較為復雜的體系結構。
Hydra的故事雖然簡單,但是卻發生在1996,可以說在那個年代是極其具有前瞻性的。一句題外話,在那個年代,ISCA(International Symposium on Computer Architecture,計算機體系結構最牛的學術會議 )還基本上是Cache Architecture的天下,所有的體系結構研究者還在考慮怎么樣提高單核的性能。反觀今日,當世界上所有人都在討論多核的時候,我們是不是應該前瞻性地考慮一下下一個熱點是什么呢?
流處理器以及GPGPU(通用圖形處理器)
流處理器以及GPGPU代表的路徑是完全繞開了傳統處理器設計而針對新的應用借鑒其他專用處理器(GPU)而展開的全新設計。具體地講,Hydra面對的應用還是超標量處理器所面對的傳統應用,大量的程序循環和跳轉,不規則的內存地址訪問。而隨著計算技術不斷升入到人們的生活當中,另一種計算模式異軍凸顯,這就是大規模的數據并行計算模式。比較通俗一點的應用就是圖像和視頻的處理以及綜合,比如視頻的編解碼,動畫的合成等。在數字通訊的年代這種計算越發重要,像無線基站或者手機上各種通訊協議棧的處理。在單核的年代,進行這種計算的處理器叫DSP(Digital Signal Processor),以有別于CPU這種擅長控制和跳轉的處理器。DSP的結構與普通的CPU的超標量結構不同,大量采用了SIMD(Single Instruction Multiple Data)或者VLIW(Very Long Instruction Word)的結構,以實現在同一個處理器流程通路下的數據乃至指令的并行。那么就像Hydra是超標量CPU在多核時代的領頭羊一樣,斯坦福這個信息工業的圣地也誕生了DSP在多核時代的領頭羊Imagine。
這里可能需要叉開話題來講一下并行的基本分類了。一般地講,并行處理有三個分類:數據并行、指令并行和線程并行。線程是一串串行執行的指令,每條指令操作一個或多個數據。在此基礎上,實現并行的方式有三種:
一種是多個這樣的串行指令序列同時執行,就是Hydra為代表的線程并行模式;
第二種數據并行是同一條指令應用在并行的數據上。比如本來是一條加法指令計算C=A+B,同時將加法應用到一組A和一組B上得到一組C上就是數據并行。SIMD和即將講到的Imagine都利用了這種并行;
第三種是指令并行,也就是說在同一時間發射多條指令,同時計算不同數據多個不同運算,VLIW就是這樣一種并行方式。但是由于實現VLIW的編譯器難度太高,使得直接實現大規模可擴展的指令并行比較困難。
回到多核處理器的學術路徑上來。Imagine是斯坦福的一個數據并行的多核處理器。Imagine有8個ALU單元被同一個控制器所控制,同時對大量的并行數據進行同樣的操作。這種處理器的模式后來被稱為流處理器。后面我們講到的Nvidia的Fermi就是這種數據并行流處理器的一種實現實例。下面這個圖即是Imagine的結構框圖,可以看到它是多么像一個大型的SIMD單元啊。實際上它也即是48個ALU單元分成了8個SIMD簇。但是不可否認的是,就這樣一個看似簡單的設計提供了極高的數據并行度,使得它在處理一系列與多媒體有關的應用上得心應手,發揮了更多晶體管所帶來的性能優勢。
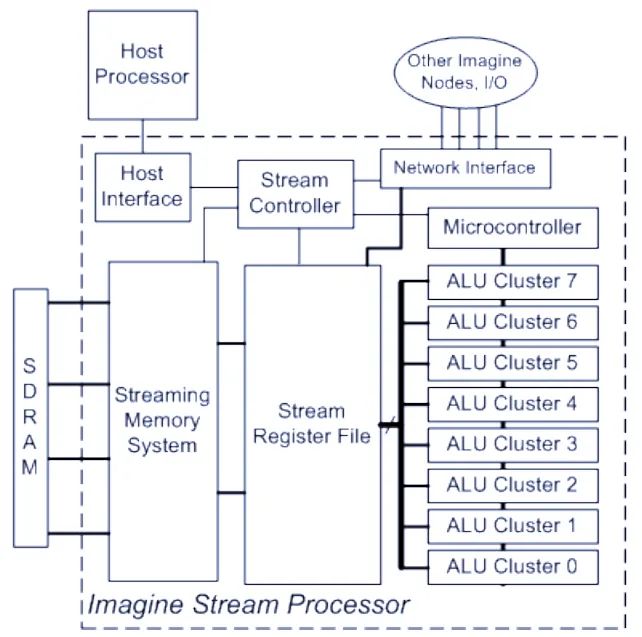
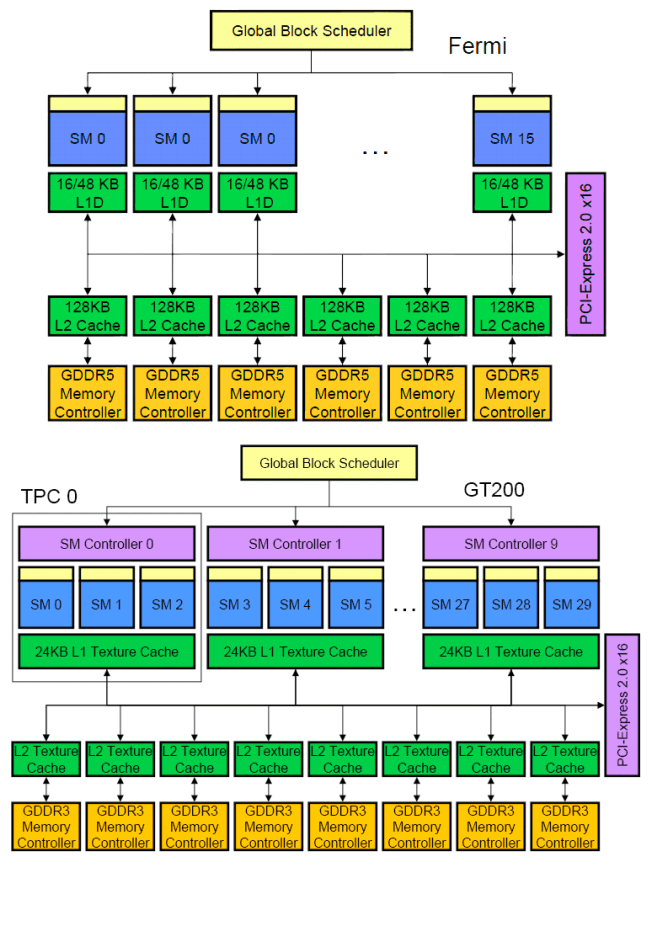
接下來我們來GPU處理器結構:Nvida的Fermi以及前一代的GT200,然后我們就可以發現他們和Imagine驚人的相似之處:每一個處理器核是一個簡單的ALU陣列。當然,在Nvidia的名詞里,處理器核叫Streaming Multiprocessor(SM),每個Fermi的SM里有32個32位ALU、32個單精度的浮點運算單元還有一些特殊運算單元;每個GT200的SM里的運算單元少地多。SM相當于Imagine里地ALU Cluster,能夠執行SIMD的操作,但是絕對和Intel以及AMD里面的處理器核相去甚遠。通用處理器中的每個核里有龐大的指令池和寄存器堆,執行繁雜的指令預取,分支預測,條件跳轉等操作,雖然計算單元不如SM多,但是計算精度較高(64位)。換句話說,如果你的程序沒有那么寬的單指令多數據并行,那么不要指望SM比傳統處理器核快。
片上存儲是為流數據簡化(也算是優化)過的。在傳統的GT200中,這種存儲就叫texture cache,在Imagine里叫Stream memory。在圖形圖像中,大部分的操作是流水線化的,所以這種cache不需要支持不同SM之間存儲共享(即使需要,必需程序員顯式指定,而不是處理器代勞),部分的緩存甚至是私有的,就連地址空間都是獨立的。這對于流處理器來說,沒有任何問題。我們把流處理想象成一個巨大的SIMD,不同的data之間沒有任何共享,texture cache就夠用了。但是一旦有了分支、線程并行、數據交換、信號鎖,這種cache就會讓程序員頭痛,于是Fermi做了一些優化,使得片上緩存至少在地址上是共享了,但是并不完全支持緩存一致性。只有當程序員顯示使用同步信號量,存儲的順序核一致性才是可以保證的。
這里需要澄清一個很明顯的誤區就是在GPU上編程能夠成百倍地提高CPU的性能,這個觀點在Nvidia推出CUDA的時候被狠狠吹捧了一番,不過后來大家發現GPGPU的能力其實非常有限:
1. 首先,只有存在大量規則數據并行的應用程序,GPU才能發揮其巨大優勢。程序中的分支跳轉以及線程間的數據共享都是GPU的軟肋,就算能夠被支持,效率也不高。說直白一點,如果誰想在GPU上做Web Server,那基本上是癡人說夢。
2. 其次,GPU需要對應用程序進行大量優化,以挖掘其并行性。這個優化過程需要對GPU結構和被優化的程序本身有著深刻地理解。這和在通用處理器編程中打開幾個優化選項的難度不可同日而語。另一方面,通用處理器的編程工具鏈經過若干年來的積累已經能夠自動完成很多優化功能使得程序員可以站在巨人的肩膀上,而對于GPU來說,這樣的肩膀還不厚實。直白地說,如果需要在非圖形圖像應用上釋放GPU的潛力,花錢花時間和請高人都是必不可少的。
3. 最后,就算對于GPU擅長的應用,如果對CPU和GPU程序都做優化,性能的差別也僅僅在一個數量級之內。ISCA有篇文章探討了這個問題,一個粗淺的結論是,對于作者考察的幾個例子來說,優化過的GPU程序在Nvidia GTX280上,比在Intel Core i7 960上平均快了2.5倍。
如果結合上面探討的兩種類型的多核處理器設計,有一個很明顯的問題是,到底用少數幾個強大的單核,還是很多簡單的單核最能優化處理器設計呢?問題的困境是:如果每個核很強大,其能提供的總指令吞吐率與其功耗或面積成本呈亞線性關系,投入產出效率較低,但是如果每個核很簡單,那么單線程的性能很低,而不幸的是每個應用程序總是有一部分沒法并行化,這部分將最終決定整個程序的性能。
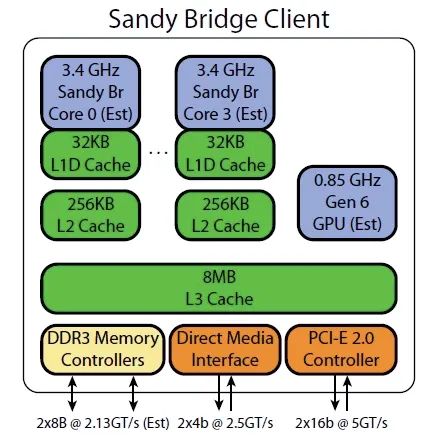
這篇文章給了一個很有意思的討論。問題的一個直白答案是取決于程序的并行性:一個程序到底有多大部分是必需串行執行的?如果這個部分很大,那么少數幾個強大的單核是比較理想的方案,而如果這個部分很小,那么傾向于使用更多的較簡單的核。最為理想的方案是一個異構多核的設計,這樣串行的部分能在一個強大的單核上加速,而可以并行的部分則通過很多很小的核來提速。這個思想的一個很明顯體現就是Intel的Sandy Bridge處理器,這個處理器沒有遵循以往不斷增加核數量的規律,其設計中里既有強大的傳統處理器核又有類似GPU的處理器,期望做到異構多核來實現性能的提升,下圖就是Sandy Bridge的系統結構:
網絡互連為主的處理器
無論是總線和交換開關的設計,還是流處理器,就沒法從本質上改變多核乃至眾核處理器設計上的不可擴展性。改變這種傳統的互連,人們提出了使用片上網絡的辦法,使得未來眾多的處理器核通過分布式的通訊方式相互溝通,從而避免了集中的互連設計帶來的系統性能瓶頸以及較大的功耗開銷。不過當片上集成核的數量不斷增加時,如何把這個功能組織起來,并不是一個簡單的事情,無論是學術界還是工業界都做了許多的嘗試,從目前開來實際結果都不太理想。
第一個真正采用網絡來連接片上很多核的是2002年MIT一組研究人員提出來的RAW眾核處理器。MIT的RAW處理器第一次應用了片上網絡的概念。這個設計后來成立了一家公司叫Tilera。RAW的出發點在于看到傳統單核處理器中的瓶頸在于操作數網絡(scalar operand network)。這個網絡把各個ALU中計算出來的數值中間結果存儲到寄存器堆,又把寄存器堆里的數給ALU就行操作。隨著金屬互聯線延遲的增加,這個移動操作數回路成為系統瓶頸,成為了導致ALU中晶體管性能提高并不能外化為處理器性能的絆腳石。
解決這個問題的辦法是用操作數網絡把計算單元(ALU)組織起來,而不是傳統意義上的操作數網絡為ALU服務。每個操作數通過網絡進入到一組ALU里,經過漫長流水線的處理和計算輸出出來到網絡中,然后送到臨近的另一組ALU里,而不必繞回去。這樣把每組ALU看成一個“核”,這樣就構成了片上網絡。下圖就是RAW中每個處理器核的結構:
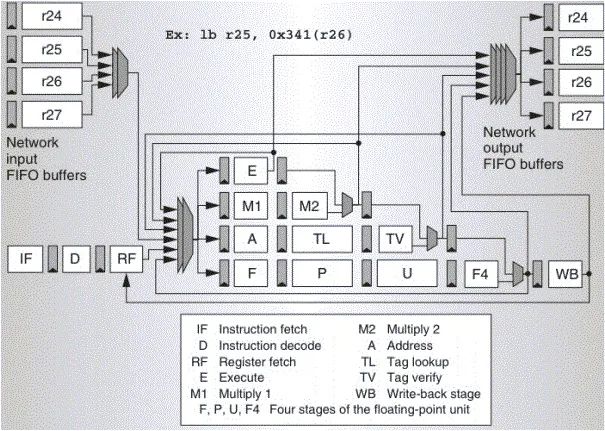
圖中可以看到,與其他商業多核處理器不同的是,RAW的片上網絡深入到了處理器流水線的內部。接著,既然ALU可以編程,那么操作數網絡也可以編程,這樣就達成了一個軟件可以控制的計算、通信眾核系統。當然其網絡設計就是一個普通的Mesh網格網絡,如下圖所示,沒啥特殊的。不過這個Mesh其實是由若干個不同功能的網絡聯合而成,各自負責操作數、片上存儲以及I/O等片上通訊的需求。
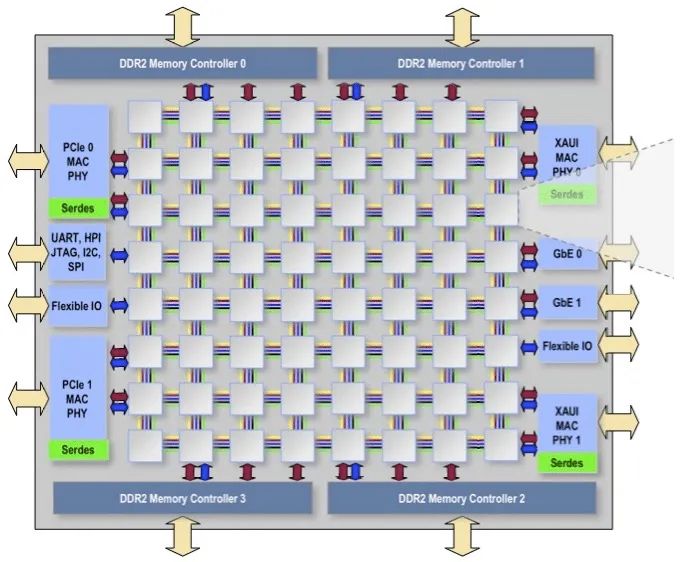
RAW的難點在于對于應用程序需要就行網絡和計算的雙重優化,否則程序運行的效率較低。這使得編譯器中指令調度不光考慮運算單元的成本,還有通訊的成本,搜索空間和復雜度大大提高。
接下來介紹IBM的Cell處理器,算是工業界探索異構多核設計的先河吧。Cell的來頭還是蠻大的,是IBM,SONY和Toshiba三家大公司為未來的消費電子設計的核心計算引擎。其最典型的應用就是索尼的PS3。Cell的設計采用了環形的片上互連、異構的片上多核、以及片上系統的集成,然后在IBM的90納米、65納米和45納米工藝條件下做了實現,應該說是代表了當時業界的最先進水平。不過不幸的是IBM在2009年年底的時候停止了對Cell的進一步研發,而基于Cell的索尼PS3銷售上沒有敵過任天堂的Wii(截止2010年9月低,Wii在全世界銷售了七千六百萬臺,而PS3僅有四千兩百萬臺)。這背后的原因在于什么呢?
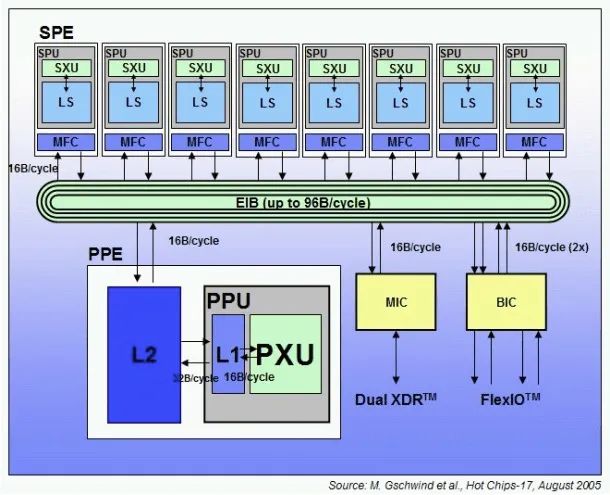
首先我們來看IBM Cell處理器的設計,其中包含了一個Power processing element(PPE)作為主處理器(其性能相當于64位的Power PC),加上八個Synergistic Processing Elements (SPE)作為協處理器(其性能相當于普通的RISC處理器和一個128位的SIMD),這些處理單元通過一個環形網絡就行互連,達到超過200GB每秒的帶寬。光從這些數據上來講,這個多核處理器符合前面講述的異構并行原理,并且技術也不差。最為不幸的是這個處理器太難編程了。每個協處理器有一個私有的局部存儲器(256KB)大小,這個存儲器幾乎需要程序員來手動調度,它既沒有類似于緩存的自動預取,又不與PPE的存儲單元共享地址空間。如果要協調好PPE與SPE的工作,除非程序的工作模式是固定的。這樣的結果就是處理器理論性能很高,但是實際程序優化起來并不容易,很多程序僅僅能夠使用一個類似于PowerPC的PPE。沒有多少廉價程序員能夠理解如此繁雜的體系結構,愿意在上面做開發。這可能就是Cell最終被IBM停止開發的原因吧。
Intel是最能理解編程的簡易性對于一個處理器生命的至關重要性,在當年以x86為代表的CISC和以MIPS、SPARC為代表RISC結構出現爭端的時候,Intel為了保證程序的兼容性,保持了x86指令向下兼容。盡管犧牲了一定性能卻贏得了軟件開發者和客戶的認可,而隨著半導體技術的推進這些性能犧牲被歷史所抹平。針對RAW和Cell都面臨的問題,Intel推出了一個保持存儲一致性和x86指令集的多核設計:Larabee,作為未來GPGPU時代眾核編程的抬頭兵。不過這個設計從2008年透出風聲到2009年底就被宣布第一代產品難產了。
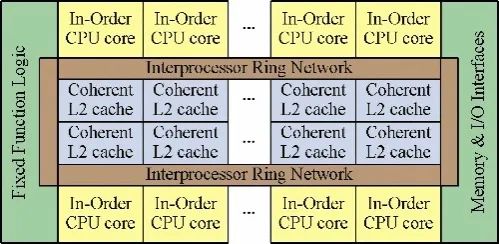
Larabee的設計野心就是編程的容易性,16(甚至32)個x86的處理器核通過一個環形的片上網絡連接在一起,分布式的的片上緩存保持完全的一致性,沒有任何特殊的專用硬件單元來增加編程的難度。大部分的優化可以通過軟件來完成。完成這樣一個設計難度在于兩個方面:
1. 眾核的片上緩存一致性是個難題,現在片上緩存一致性的核的數量支持到8已經很不容易。如果要拓展到16或者32的話,要不性能很低,要不就是得放棄部分一致性的特點,從而使得編程的難度增加。
2. Larabee如果想要達到超過Nvidia或者AMD同類GPU產品的性能,必需有一套支持圖形圖像常見應用的開發工具鏈,而這個的開發不是一朝一夕之功。
在摩爾定律的作用下,任何的耽擱都會導致產品的流產,Larabee開發的艱巨性決定了其性能跟不上摩爾定律,從而其第一代產品被迫下線。
小結
在本文的結尾總結一下所探討的這些多核乃至眾核處理器,可以看到其中的挑戰其實并不是在處理器設計本身,而在互連與編程這個兩個方面。一個未來會成功的眾核處理器提供給開發者一個向下兼容的簡單編程模型,并且盡量將互連的影響盡可能的化解。這個目標并不容易實現,很有可能人們不得不最終放棄傳統的編程模型,而直接面對眾核處理器的互連和編程挑戰。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19658瀏覽量
232464 -
摩爾定律
+關注
關注
4文章
638瀏覽量
79545 -
晶體管
+關注
關注
77文章
9897瀏覽量
140005 -
多核處理器
+關注
關注
0文章
109瀏覽量
20148
原文標題:從多核到眾核處理器
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多核處理器設計九大要素
典型的支持多核處理器的RTOS功能解析
多核處理器啟動的基本原理是什么?如何實現呢
看看一個多核處理器系統是如何啟動的
多核處理器架構及調試
多核處理器及其對系統結構設計的影響
多核處理器會取代FPGA嗎?





 工商網監
工商網監
評論